
Multi-Provider Generative AI Gateway on AWSでLiteLLM Proxy ServerをECSにデプロイしてみた
LiteLLM Proxy Server (LLM Gateway) を、Amazon Elastic Container Services(ECS)またはAmazon Elastic Kubernetes Service(EKS)にデプロイ可能なMulti-Provider Generative AI Gateway on AWSをECSへのデプロイを試してみたので紹介します。
Multi-Provider Generative AI Gateway on AWSとは
このプロジェクトは、AWS上のAmazon Elastic Container Service(ECS)およびElastic Kubernetes Service(EKS)プラットフォームへのLiteLLMのシンプルなTerraformデプロイを提供します。ほとんどのユーザーがすぐにLiteLLMを使い始められるように、デフォルト設定を事前に整えることを目指しています。
また、LiteLLM に加えて、AWS Bedrock インターフェイス (デフォルトの OpenAI インターフェイスの代わりに)、AWS Bedrock マネージドプロンプトのサポート、チャット履歴、Okta Oauth 2.0 JWT トークン認証のサポートなどの追加機能も提供します。
LiteLLM を初めてご利用になる方のためにご説明すると、LiteLLM はすべての LLM プロバイダーにアクセスできる一貫したインターフェースを提供するため、異なるモデルを試すためにコードを編集する必要はありません。LiteLLM を使用すると、ユーザー、チーム、API キーレベルで、社内の LLM の使用状況を一元的に管理および追跡できます。予算とレート制限の設定、特定のモデルへのアクセス制限、複数のプロバイダーにわたる再試行/フォールバックルーティングロジックの設定が可能です。プロンプトキャッシュなどのコスト削減策も提供しています。また、すべての LLM プロバイダーで AWS Bedrock Guardrails のサポートなどのセキュリティ機能も提供しています。さらに、管理者がユーザーとチームを設定できる UI を提供し、ユーザーはチャットインターフェースで API キーを生成してさまざまな LLM をテストできます。
※ Project OverviewをGoogle翻訳した内容です。
アーキテクチャ
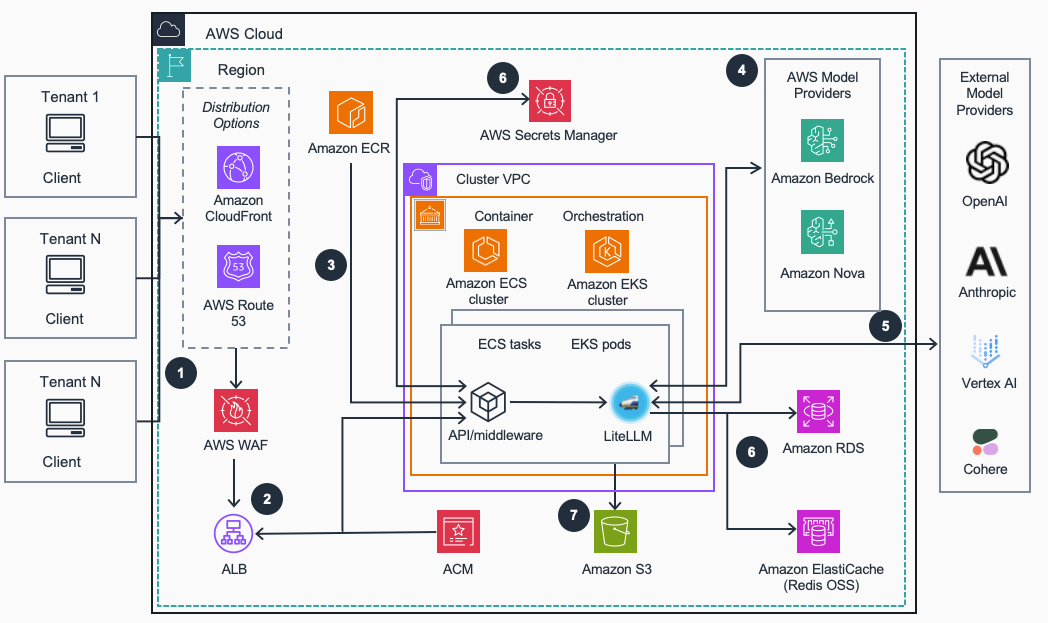
※ 構成図はArchitectureより引用しました。以下の説明もリンク先の内容を元に変更追記したものです。
- リクエストの受付: クライアントアプリケーションからのリクエストは、Route 53またはCloudFrontを経由し、WAFによって一般的なWebの脆弱性から保護されます。
- リクエストルーティングと負荷分散: ALBはまず、リクエストパスに基づき、トラフィックを適切なコンテナに振り分けます。特定のパス(例:
/bedrock/...)はAPI/ミドルウェアのコンテナへ、それ以外のパスはLiteLLM本体のコンテナへルーティングされます。その後、ルーティング先のコンテナ群に対してトラフィックを分散させることで、負荷分散も行います。通信はCertificate Manager (ACM)によって発行された証明書で暗号化されます。 - ホスティング: LiteLLMとAPI/ミドルウェアのコンテナイメージは、デプロイプロセス中にビルドされ、Elastic Container Registry(ECR)に保存されます。これらのイメージは、ECSまたはEKS上でコンテナとしてホスティングされます。
- LiteLLM本体は、さまざまなLLMプロバイダーと対話するためのOpenAI互換の統一インターフェイスを提供します。管理画面(Admin UI)もLiteLLM本体が提供する機能です。
- API/ミドルウェアは、LiteLLM本体とは別のコンテナとして動作し、追加の機能を提供します。具体的には、Amazon BedrockのネイティブAPI(Converse API)を模倣したエンドポイントを提供することでboto3からの直接利用を可能にしたり、Bedrock Managed Promptsやセッション管理によるチャット履歴機能などをサポートします。これにより、LiteLLMの基本的な機能に加え、AWSネイティブな開発体験と高度な機能を実現します。
- Bedrock: Bedrockは、基盤モデルへのアクセス、ガードレールによる安全性確保、プロンプトのキャッシュ、リクエストのルーティングといった機能を提供し、ゲートウェイを強化します。
- 外部モデルプロバイダー: OpenAI, Anthropic, Google Vertex AIなどの外部LLMプロバイダーも、LiteLLMの管理画面を通じて設定することで、統一されたインターフェイスから利用できます。
- バックエンドサービス: LiteLLMは以下のAWSサービスと統合されています。
- ElastiCache (Redis): アプリケーション設定の共有やプロンプトのキャッシュに使用されます。
- Relational Database Service (RDS): LiteLLMが発行する仮想APIキーやその他の設定情報を永続化します。
- Secrets Manager: 外部LLMプロバイダーのAPIキーなどの機密情報を安全に保管します。
- ロギング: LiteLLMおよびAPI/ミドルウェアのアプリケーションログは、専用のS3バケットに保存され、トラブルシューティングやアクセス分析に利用できます。
試してみる
Guidance for Multi-Provider Generative AI Gateway on AWSに沿って、進めていきます。
事前準備
Prerequisitesに沿って、事前準備を行います。
まずは、必要となるCLIツールが入ってるか確認し、不足してるものがあればインストールします。今回はECSを利用するため、kubectl CLIは利用しません。
aws --version
docker --version
terraform --version
yq --version
aws-cli/2.27.26 Python/3.13.3 Darwin/24.5.0 exe/x86_64
Docker version 27.5.1-rd, build 0c97515
Terraform v1.12.1
on darwin_arm64
yq (https://github.com/mikefarah/yq/) version v4.45.1
今回はカスタムドメインを利用しないため、ドメイン関連の設定はスキップします。カスタムドメインを利用する場合は、Public Domain in Amazon Route 53あたりの手順を参考にしてください。
次に必要なBedrockモデルへのアクセスが有効になっていない場合は、アクセスを有効化します。有効化の手順は、基盤モデルにアクセスを追加または削除するを参考にしてください。
事前準備の最後に、コードをcloneして、.envファイルをテンプレートからコピーします。
git clone https://github.com/aws-solutions-library-samples/guidance-for-multi-provider-generative-ai-gateway-on-aws
cd guidance-for-multi-provider-generative-ai-gateway-on-aws
cp .env.template .env
ECSへのデプロイ
Amazon ECS Deployment に沿って、ECSへのデプロイを試してみます。
まずは、環境変数を指定します。
今回デフォルト(.env.template)から変えた値は、以下の変数です。
- LITELLM_VERSION: デプロイするLiteLLMのバージョン。今回は現時点で最新のstableを指定
- 参考: LiteLLMのバージョン一覧
- TERRAFORM_S3_BUCKET_NAME: tfstateを格納するS3バケット名を指定。存在しないバケット名を指定した場合は作成されます。
- DESIRED_CAPACITY、MIN_CAPACITY、MAX_CAPACITY、ECS_VCPUS、RDS_INSTANCE_CLASS: 今回は検証目的なので、可用性等は考慮せず、リソースサイズを小さく設定
今回利用した.envファイル
# LITELLM_VERSION eg: main-v1.56.5
# Get it from https://github.com/berriai/litellm/pkgs/container/litellm/versions?filters%5Bversion_type%5D=tagged
LITELLM_VERSION="v1.72.0-stable"
TERRAFORM_S3_BUCKET_NAME="" # Must be globally unique
BUILD_FROM_SOURCE="false"
HOSTED_ZONE_NAME=""
CREATE_PRIVATE_HOSTED_ZONE_IN_EXISTING_VPC="false"
RECORD_NAME=""
CERTIFICATE_ARN=""
OKTA_ISSUER=""
OKTA_AUDIENCE="api://default"
OPENAI_API_KEY="placeholder"
AZURE_OPENAI_API_KEY="placeholder"
AZURE_API_KEY="placeholder"
ANTHROPIC_API_KEY="placeholder"
GROQ_API_KEY="placeholder"
COHERE_API_KEY="placeholder"
CO_API_KEY="placeholder"
HF_TOKEN="placeholder"
HUGGINGFACE_API_KEY="placeholder"
DATABRICKS_API_KEY="placeholder"
GEMINI_API_KEY="placeholder"
CODESTRAL_API_KEY="placeholder"
MISTRAL_API_KEY="placeholder"
AZURE_AI_API_KEY="placeholder"
NVIDIA_NIM_API_KEY="placeholder"
XAI_API_KEY="placeholder"
PERPLEXITYAI_API_KEY="placeholder"
GITHUB_API_KEY="placeholder"
DEEPSEEK_API_KEY="placeholder"
AI21_API_KEY="placeholder"
LANGSMITH_API_KEY=""
LANGSMITH_PROJECT=""
LANGSMITH_DEFAULT_RUN_NAME=""
DEPLOYMENT_PLATFORM="ECS"
EXISTING_VPC_ID=""
EXISTING_EKS_CLUSTER_NAME=""
DISABLE_OUTBOUND_NETWORK_ACCESS="false"
CREATE_VPC_ENDPOINTS_IN_EXISTING_VPC="false"
INSTALL_ADD_ONS_IN_EXISTING_EKS_CLUSTER="false"
DESIRED_CAPACITY="1" #Number of ECS or EKS instances to run by default (for horizontal scaling)
MIN_CAPACITY="1"
MAX_CAPACITY="2"
ECS_CPU_TARGET_UTILIZATION_PERCENTAGE="50"
ECS_MEMORY_TARGET_UTILIZATION_PERCENTAGE="40"
ECS_VCPUS="0.5"
EKS_ARM_INSTANCE_TYPE="t4g.medium"
EKS_X86_INSTANCE_TYPE="t3.medium"
EKS_ARM_AMI_TYPE="AL2_ARM_64"
EKS_X86_AMI_TYPE="AL2_x86_64"
CPU_ARCHITECTURE="" #If empty, defaults to the architecture of your deployment machine "x86" or "arm"
PUBLIC_LOAD_BALANCER="true"
RDS_INSTANCE_CLASS="db.t4g.micro"
RDS_ALLOCATED_STORAGE_GB="20"
REDIS_NODE_TYPE="cache.t3.micro"
REDIS_NUM_CACHE_CLUSTERS="2" #Number of cache clusters (primary and replicas) the replication group will have
EC2_KEY_PAIR_NAME=""
DISABLE_SWAGGER_PAGE="false"
DISABLE_ADMIN_UI="false"
LANGFUSE_PUBLIC_KEY=""
LANGFUSE_SECRET_KEY=""
LANGFUSE_HOST="" # Optional, defaults to https://cloud.langfuse.com
FAKE_LLM_LOAD_TESTING_ENDPOINT_CERTIFICATE_ARN=""
FAKE_LLM_LOAD_TESTING_ENDPOINT_HOSTED_ZONE_NAME=""
FAKE_LLM_LOAD_TESTING_ENDPOINT_RECORD_NAME=""
# CloudFront and Route53 Configuration
USE_ROUTE53="false"
USE_CLOUDFRONT="true"
CLOUDFRONT_PRICE_CLASS="PriceClass_100"
では、以下のコマンドでデプロイします。利用するAWSプロファイル名とリージョンを指定しています。コマンドの実行によってさまざまなリソースが作成されるため、ガイドによると25-30分程度かかるようです。途中でECRの情報などが表示されますが、q(macOSの場合)で閉じないと次の処理に進んでないように見えました。ECRを作成し、コンテナイメージをビルド&プッシュしてからTerraformでの各リソース作成に入るため、実行後に放置する場合はTerraformの実行まで進んでるのを確認してからがよいかもしれません。
設定した変数がおかしいなどで、エラーになった場合も再実行すればそのまま実行できました。ただし、LiteLLMの設定ファイルである、config/config.yamlが存在する場合はそのまま利用するような処理になっています。config.yamlの内容は、deploy.shで基本の設定ファイルと地域ごとの設定ファイルをマージして作成しているため、リージョンが誤っていたなどでリージョンを変えた際にはconfig.yamlを削除してからデプロイを再実行するほうがよさそうです。
AWS_PROFILE={プロファイル名} AWS_DEFAULT_REGION=ap-northeast-1 ./deploy.sh
実行中は処理に関するログが色々表示されます。実行完了時のログの最後には、次のような情報が表示されます。作成したリソース情報やServiceURLも表示されています。ServiceURLを開くことで、LiteLLMのAPI定義や管理画面にアクセスできます。また、LLM利用時のリクエスト先のURLとしても、ServiceURLは利用します。
Apply complete! Resources: 121 added, 0 changed, 0 destroyed.
Outputs:
ConfigBucketName = "litellm-config-{バケットサフィックス}"
LitellmEcsCluster = "litellm-stack-cluster"
LitellmEcsTask = "LiteLLMService"
ServiceURL = "https://{ドメイン}.cloudfront.net"
cloudfront_auth_secret = <sensitive>
cloudfront_distribution_id = "{ディストリビューションID}"
cloudfront_domain_name = "{ドメイン}.cloudfront.net"
eks_cluster_name = ""
eks_deployment_name = ""
vpc_id = "vpc-{VPCID}"
Deployment successful. Extracting outputs...
{
"service":
...省略
}
Validating CloudFront deployment...
✓ CloudFront distribution created successfully: {ディストリビューションID}
✓ CloudFront domain: {ドメイン}.cloudfront.net
Note: CloudFront distribution deployment may take 15-30 minutes to complete globally
✓ Deployment completed successfully
動作確認
デプロイされたLiteLLMの管理画面を開き、動くことを確認してみます。
ServiceURLに記載されてるURLを開くことで、OpenAPI形式のAPI定義が表示されます。上部には、管理画面とコストマップへのリンクがあります。コストマップはLiteLLMが公開してるモデル情報一覧ページです。モデルごとの最大トークンや費用などがまとめられています。
リンクLiteLLM Admin Panel on /uiから管理画面を開きます。ユーザーIDはadminで、パスワードは、Secrets ManagerのLiteLLMMasterSaltというプレフィックスを持つシークレットに保存されている値を利用します。
ログインできると、ダッシュボードが表示されます。
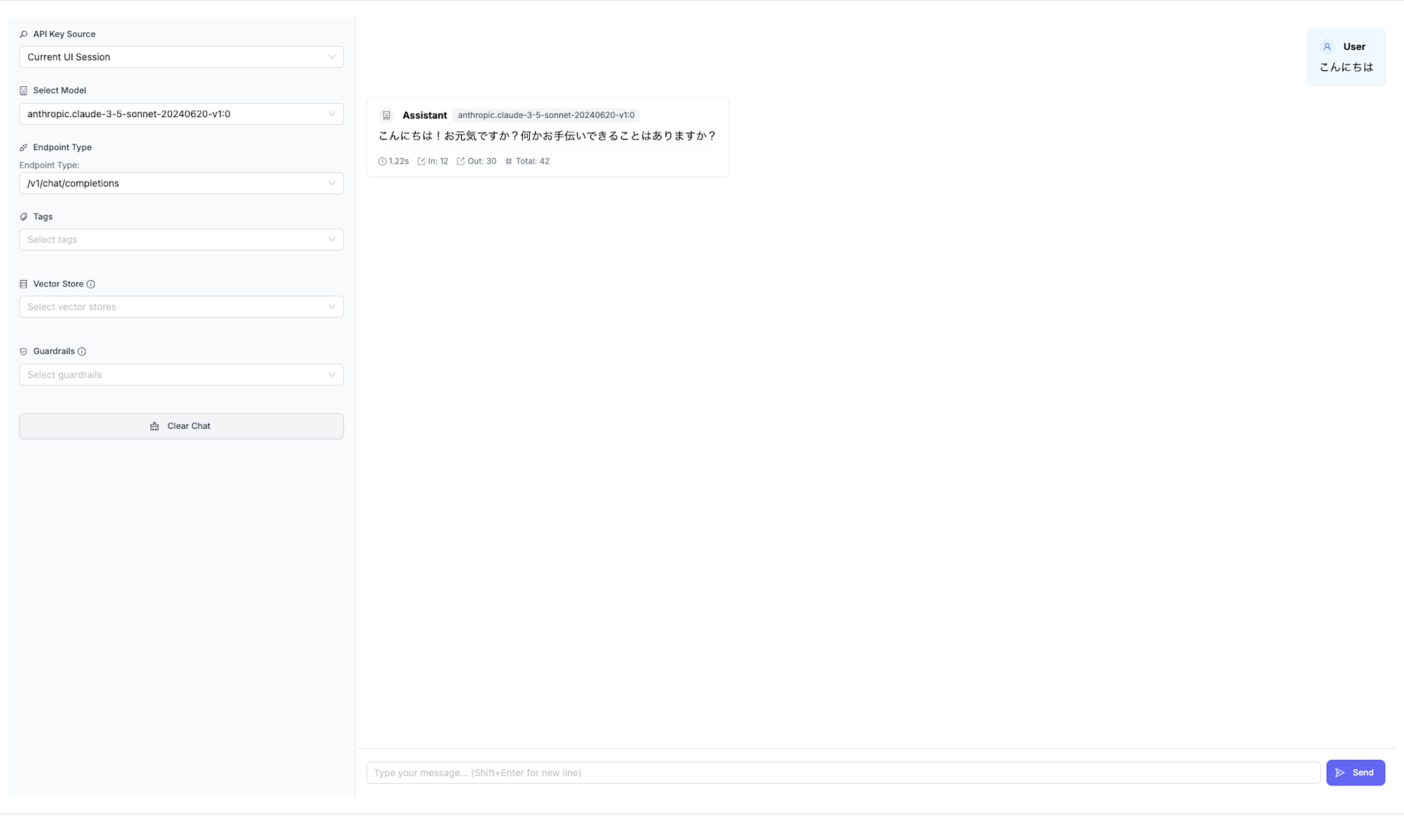
Test Key画面でBedrockに接続できることを確認してみます。リージョンに合わせて、デフォルトでいくつかのモデルが登録されています。今回はその中の一つのClaude 3.5 Sonnetを利用して確認します。反応が返ってきているので、接続できていそうです。
ローカルのClineからも次のような設定で接続できました。
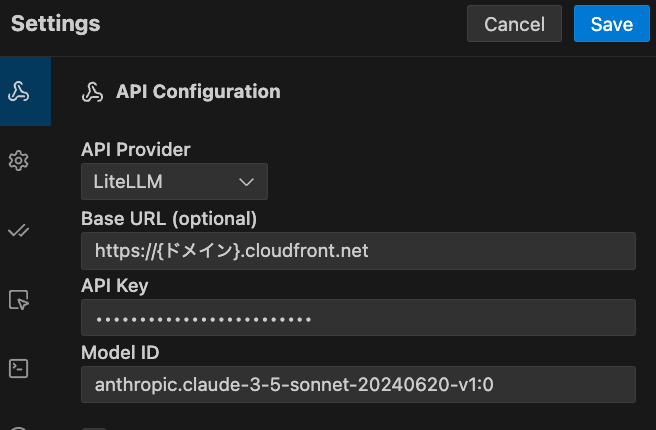
リソース設定の変更
デプロイ後に.envを変更した場合は、再度deploy.shを実行することでAWSリソースに反映できます。
AWS_PROFILE={プロファイル名} AWS_DEFAULT_REGION=ap-northeast-1 ./deploy.sh
LiteLLM設定ファイルの変更
LiteLLM設定ファイルのconfig/config.yamlを変更した場合は、update-litellm-config.shを実行することで反映できます。設定ファイルをS3にアップロードし、ECSタスクを再起動します。
AWS_PROFILE={プロファイル名} AWS_DEFAULT_REGION=ap-northeast-1 ./update-litellm-config.sh
片付け
Uninstall the Guidance を参考に、以下のコマンドで作成したAWSリソースを削除します。
AWS_PROFILE={プロファイル名} AWS_DEFAULT_REGION=ap-northeast-1 ./undeploy.sh
さいごに
Multi-Provider Generative AI Gateway on AWSを用いて、LiteLLM Proxy ServerをAWS上にデプロイする流れを紹介しました。LiteLLMとミドルウェアをホスティングするECSに加えて、RDSでのデータの永続化やElastiCacheでのキャッシュ、CloudFrontやWAFなど、運用を見越した構成になっているのは良いですね。また、各リソースがTerraformで定義されてるだけでなく、個別で管理が必要なECRやtfstate用S3バケットの作成なども考慮したデプロイ用スクリプトが用意されているため、デプロイも簡単にできました。デプロイ用スクリプトが冪等性を考慮したものになっているため、更新時にも利用できるのは便利です。とはいえ、実際に運用する場合は、各スクリプトやリソース設定を確認し、更新時のダウンタイムなど運用上の問題がないか確認したり、運用に合わせるために変更したほうが良さそうです。LiteLLM、Multi-Provider Generative AI Gateway on AWSそれぞれに様々な機能があるため、色々試しながら活用することでLLM利用時の課題解消に役立てていきたいですね。
参考
- LiteLLM - Getting Started | liteLLM
- aws-solutions-library-samples/guidance-for-multi-provider-generative-ai-gateway-on-aws: This Guidance demonstrates how to streamline access to numerous large language models (LLMs) through a unified, industry-standard API gateway based on OpenAI API standards
- Guidance for Multi-Provider Generative AI Gateway on AWS
- ClineからLiteLLM Proxyを通してAmazon Bedrockを利用する | DevelopersIO











