
n8nのAIエージェントノードでのツールの使い方が悪くて無駄なトークンを使っていた件
自然言語からSQLを生成、実行、結果の表示をn8nで実験していて、Too many tokensエラーで動かなくなりました。
大きかった原因ですが、RAGの検索結果がそのままLLMのコンテキストに入っていたことでした。
以下のような感じ。
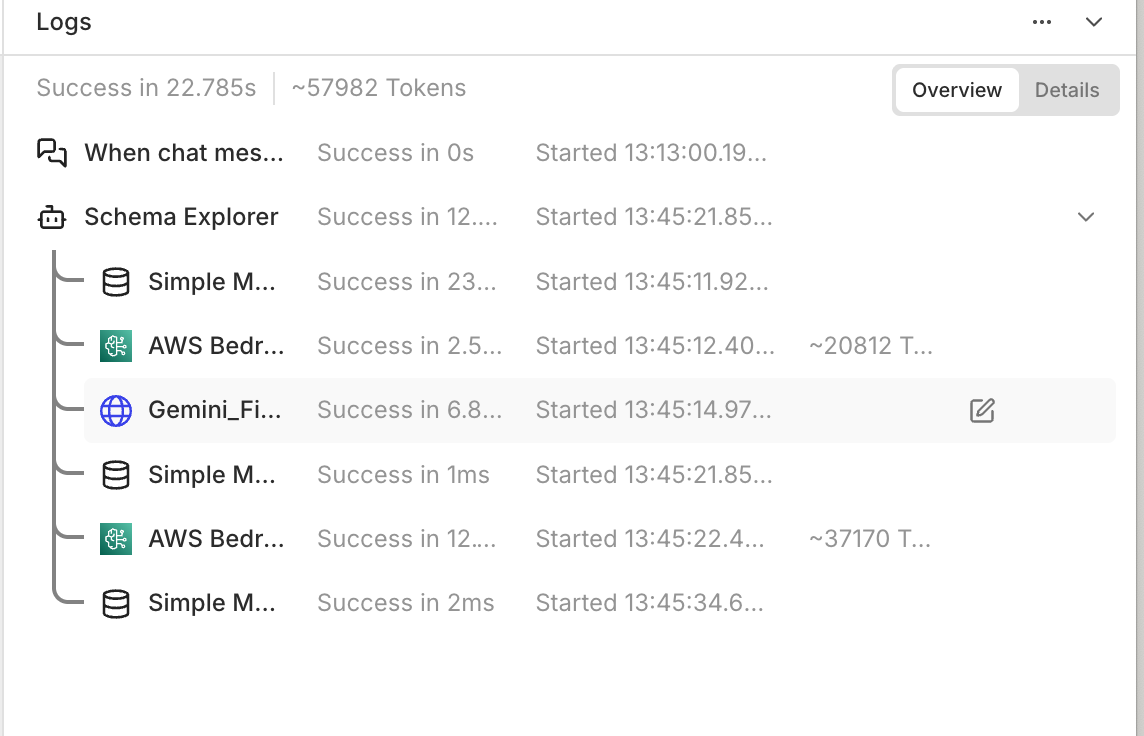
試していたこと
n8nのAIエージェントノードとGemini File Search APIを組み合わせ、スキーマ情報をRAGで取得してSQLを生成する仕組みに取り組んでいました。
Gemini File Search APIでRAG構築を試した時の記事
スキーマ情報(テーブル定義やカラム情報)、ナレッジ情報はGemini File Searchのストアーに保存し、API経由でRAG検索するようにしました。
曖昧な言葉があるとユーザーに聞き返すようにしていたため、会話履歴もメモリーに保存されるようになっています。
当初の設計:
[ユーザー質問] → [AIエージェント] → Tool: Gemini File Search / Memory: Simple Memory(会話履歴)
↓
スキーマ情報を取得
↓
SQLを生成
n8n(およびLangChainなどのフレームワーク)では、Toolの実行結果はAIエージェントのコンテキストに追加されます。
例)
| コンテキスト内訳 | トークン数 |
|---|---|
| システムプロンプト | 2000 |
| 会話履歴など | 3000 |
| Tool結果(RAG) | 20000 |
| ユーザー質問 | 100 |
繰り返しやりとりしていると、Toolの結果をまたLLMのインプットに利用しているのでさらにトークン量が膨れ上がる といったことがよく起こっていました。
Toolの結果について
Gemini File Search APIのレスポンスには、必要な情報以外にも大量のメタデータが含まれます。
{
"candidates": [
{
"content": { "parts": [{ "text": "..." }] },
"groundingMetadata": {
"groundingChunks": [
{ "retrievedContext": { "text": "大量のドキュメント..." } },
{ "retrievedContext": { "text": "大量のドキュメント..." } },
// さらに続く...
],
"groundingSupports": [...]
}
}
],
"usageMetadata": {...}
}
このレスポンス全体がToolの結果としてAIに渡されていたのです。
改善後の設計:
[ユーザー質問] → [Gemini File Search] → [圧縮] → [AIエージェント]
RAGをToolから外し、ワークフローで事前に実行 → 圧縮するように変更しました。
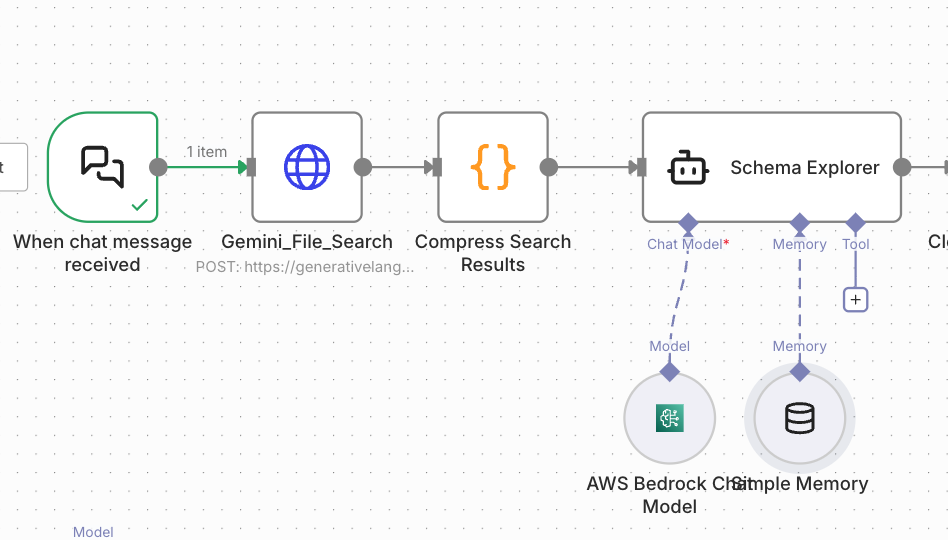
ToolではなくHTTP Requestノードで直接APIを呼び出します。
返ってきた結果から必要な情報だけを抽出しました(コードノードを使用)。
const items = $input.all();
// 全アイテムからテキストを抽出
let allContent = [];
for (const item of items) {
const response = item.json;
const candidates = response.candidates || [];
for (const candidate of candidates) {
const parts = candidate.content?.parts || [];
for (const part of parts) {
if (part.text) {
allContent.push(part.text);
}
}
}
// groundingChunksからも抽出(ある場合)
const groundingMeta = response.candidates?.[0]?.groundingMetadata;
if (groundingMeta?.groundingChunks) {
for (const chunk of groundingMeta.groundingChunks) {
const text = chunk.retrievedContext?.text;
if (text) {
allContent.push(text);
}
}
}
}
// 重複を除去
const uniqueContent = [...new Set(allContent)];
// 結合して圧縮
let combined = uniqueContent.join('\n\n---\n\n');
// 長すぎる場合は切り詰め
const MAX_CHARS = 4000;
if (combined.length > MAX_CHARS) {
combined = combined.substring(0, MAX_CHARS) + '\n\n...(以下省略)';
}
return {
json: {
schemaContext: combined.trim(),
sourceCount: items.length,
extractedChunks: uniqueContent.length,
estimatedTokens: Math.ceil(combined.length * 1.5)
}
};
AIエージェントのプロンプトで圧縮済みのコンテキストを参照します。
## 入力情報
- 質問: {{ $('When chat message received').item.json.chatInput }}
- スキーマ情報: {{ $json.schemaContext }}
同じ質問をした結果、大幅に消費トークンを削減できるようになりました。
例)
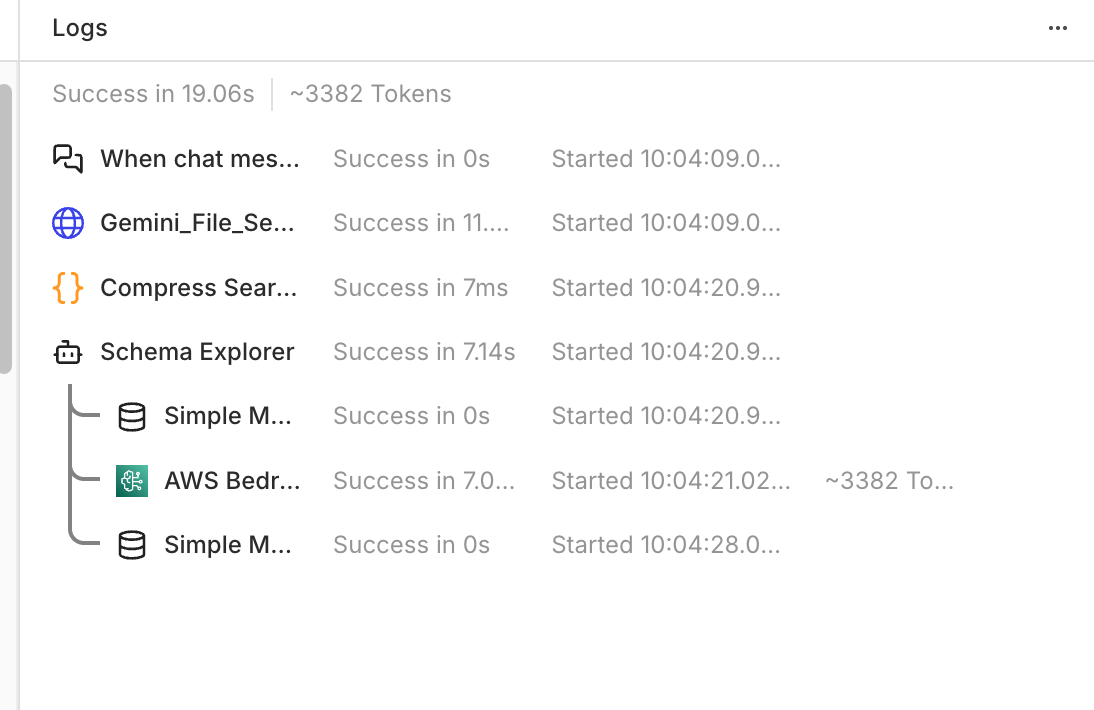
Toolにすべきかどうかの判断
Toolに向いているのは以下のようなもの。
- 結果が小さい(数百トークン以下)
- 呼ぶかどうかAIに判断させたい
- 結果をそのまま使える(加工不要)
- 複数のToolから選択させたい
逆にToolに向いていないのは、
- 結果が大きい(1,000トークン超)
- 毎回必ず実行する
- 結果を圧縮・加工したい
- エラー時の複雑なハンドリングが必要
今回のRAG検索では、
結果が大きい、毎回実行、圧縮必要 ということになったので、AIエージェントの外に出す判断にしました。
まとめ
今回n8nでAIエージェントを作って学べたことは、
全部Toolでやらせようとすると、トークンが爆発し、動作が不安定になってしまう ということでした。
-
Toolの結果はコンテキストに入る
- Toolが返した内容はそのままLLMのコンテキストに追加される
- 大きな結果を返すToolはトークンを圧迫する
-
RAGは事前処理で圧縮すべき
- 検索結果をそのまま渡さない
- 必要な情報だけ抽出・圧縮してから渡す
-
Toolは万能ではない
- 「AIが判断して呼ぶ」ケースに限定する
- 毎回実行する処理はワークフローで
ユーザー入力 -> 前処理 (検索・加工) -> AI Agent (判断・選択) -> 後処理 (実行) というワークフローにして無駄なトークンを使わず、動作が高速になりました。
今後の改善点
- スキーマ情報のキャッシュ(同じテーブルは再検索しない)
- クエリパターンごとのテンプレート化
- システムプロンプトを軽量にする









