
Nemotron 9B × Megatron-Bridge で Mamba-2 含む全層 LoRA を NVIDIA Brev H100 で学習させてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
前回の記事で、Nemotron 9B-v2-Japanese を国税庁 FAQ で RAFT ファインチューニングし、RAG の回答精度を改善しました。ただ、Mamba-2 層に LoRA が通らず全パラメータの 53% しか学習できていなかったことがずっと気になっていました。F1 が +8.9 ポイント改善、回答拒否が 47 件から 3 件に激減と、結果自体は悪くなかったのですが。。。
Nemotron 9B-v2-Japanese は 56 層のうち 27 層が Mamba-2(SSM)です。これらの in_proj と out_proj は、執筆時点の HuggingFace PEFT 実装では LoRA の適用手段が用意されていません。残りの Attention 層と FFN 層だけで成果は出ましたが、「残り 47% も学習したら結果は変わるのか?」という疑問が頭から離れませんでした。
この記事では、NGC NeMo コンテナに含まれる Megatron-Bridge v0.2.0 を使って Mamba-2 込みの 100% LoRA カバーを実現し、NVIDIA Brev のクラウド H100 で学習を回してみました。学習済みアダプターを DGX Spark に持ち帰って GGUF 変換し、Ollama で推論するところまで一気通貫です。結論から言うと、思った通りの結果にはなりませんでした。
Megatron-Bridge とは
執筆時点の HuggingFace PEFT では Mamba-2 の in_proj と out_proj に LoRA を適用する手段がない、という制約がありました。これは HuggingFace 側の実装に起因する問題で、Megatron の学習パイプラインならこれらの層もネイティブにサポートしています。つまり、モデルを一度 Megatron 形式に変換して学習し、終わったら HuggingFace 形式に戻せばいい。その橋渡しをするのが Megatron-Bridge です。
Megatron-Bridge は NeMo 25.11 系コンテナに含まれていて、import_ckpt → finetune → export_ckpt の 3 ステップで HuggingFace エコシステムのモデルを Megatron のネイティブなパイプラインで学習し、結果を HuggingFace 形式に持ち帰れます。
NeMo コンテナには専用のレシピ(nemotron_nano_9b_v2_finetune_config)が用意されていて、LoRA のターゲットモジュールやハイパーパラメータが事前にチューニングされています。レシピに含まれる LoRA ターゲットは以下の 6 種です。
| ターゲット | レイヤー種別 | HF PEFT | Megatron-Bridge |
|---|---|---|---|
| linear_qkv / q_proj,k_proj,v_proj | Self-Attention | 可 | 可 |
| linear_proj / o_proj | Self-Attention | 可 | 可 |
| linear_fc1 / gate_proj,up_proj | FFN | 可 | 可 |
| linear_fc2 / down_proj | FFN | 可 | 可 |
| in_proj | Mamba-2 | 不可 | 可 |
| out_proj | Mamba-2 | 不可 | 可 |
HF PEFT では上 4 種のみで 53% カバー。Megatron-Bridge では 6 種すべてで 100% カバーです。
DGX Spark の壁と Brev
SM 12.1 の壁
前回は NGC NeMo コンテナで DGX Spark の SM 12.1 問題を突破しましたが、Megatron-Bridge の import_ckpt では multiprocessing.Manager().Queue() が Docker コンテナ内で EOFError を起こす別の壁にぶつかりました。そこで今回はローカルで粘るよりクラウドの H100 を借りたほうが早いかもと判断しました。
NVIDIA Brev
NVIDIA Brev は、NVIDIA が提供するクラウド GPU インスタンスサービスです。H100 や A100 を時間単位で利用できます。
H100 80GB PCIe の 1 台構成で、執筆時点では $2.26/hr 前後(Hyperstack プロバイダー)と、個人の検証用途としては手が届く価格帯です。今回は TP=1(テンソル並列なし)で LoRA 学習するので、1 台で十分でした。
VM Mode を選ぶ
Brev には GPU 環境の構成方法がいくつかあります。
最初は Custom Container モードで NeMo コンテナを直接指定しようとしましたが、コンテナ内の Python 環境が外部管理扱いで pip install が通りません。VM Mode で起動して自分で docker run する方式に切り替えたところ、結果的にこのほうが柔軟で、ローカルと同じ感覚で作業できました。
Brev 環境構築
全体のパイプラインはシェルスクリプト(n6-brev-run.sh)にまとめました。
VM Mode のインスタンスに SSH 接続して、NeMo コンテナを起動します。
# NeMo コンテナを pull して起動
docker pull nvcr.io/nvidia/nemo:25.11.01
docker run --gpus all --ipc=host --ulimit memlock=-1 \
--ulimit stack=67108864 -v /ephemeral:/workspace \
nvcr.io/nvidia/nemo:25.11.01 bash /workspace/n6-brev-run.sh
/ephemeral は Brev インスタンスの一時ストレージで、ここに学習データとスクリプトを事前に scp で転送しておきます。--ipc=host と --ulimit memlock=-1 は Megatron の分散学習に必要なフラグです。
H100 の nvidia-smi は以下のとおりです。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.195.03 Driver Version: 570.195.03 CUDA Version: 13.0 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| 0 NVIDIA H100 PCIe On | 00000000:00:07.0 Off | 0 |
| N/A 28C P0 67W / 350W | 0MiB / 81559MiB | 0% Default |
+-----------------------------------------+------------------------+----------------------+
HF から Megatron 形式への変換
AutoBridge.import_ckpt() を使って HuggingFace 形式のモデルを Megatron 形式に変換します。
from megatron.bridge import AutoBridge
AutoBridge.import_ckpt(
"nvidia/NVIDIA-Nemotron-Nano-9B-v2-Japanese",
"/workspace/megatron-ckpt",
trust_remote_code=True,
dtype=torch.bfloat16,
device_map="cpu",
)
trust_remote_code=True が必須です。Nemotron 9B-v2-Japanese はカスタムモデルなので、これがないと can_handle() で弾かれます。事前のドライランで気づいた地味なハマりポイントでした。
mp.Queue() パッチ
変換の保存ステップで multiprocessing.Manager().Queue() が EOFError を起こす問題に遭遇しました。Docker コンテナ内の /dev/shm サイズ制限あたりが絡んでいそうですが、根本原因の追究より回避策を優先しました。
import multiprocessing as mp
import megatron.core.dist_checkpointing.strategies.filesystem_async as fs_async
# Manager().Queue() の代わりに plain mp.Queue() を使う
fs_async._get_write_results_queue = lambda: mp.Queue()
シングルノード構成では mp.Queue() で機能的に等価です。H100 上でこのパッチを当てた結果、変換は 71 秒で完了しました。チェックポイントサイズは 16.6GB です。
100% LoRA 学習
レシピ設定
Megatron-Bridge にはモデルごとの学習レシピが用意されています。Nemotron 9B-v2-Japanese には nemotron_nano_9b_v2_finetune_config が使えます。
from megatron.bridge.recipes.nemotronh import nemotron_nano_9b_v2_finetune_config
from megatron.bridge.peft.lora import LoRA
lora_config = LoRA(
target_modules=[
"linear_qkv", "linear_proj", # Attention
"linear_fc1", "linear_fc2", # FFN
"in_proj", "out_proj", # Mamba-2 ← HF PEFT では不可
],
dim=32,
alpha=32,
)
config = nemotron_nano_9b_v2_finetune_config(
peft=lora_config,
pretrained_checkpoint="/workspace/megatron-ckpt",
train_iters=500,
micro_batch_size=1,
global_batch_size=8,
seq_length=2048,
finetune_lr=1e-4,
)
前回(HF PEFT)との設定差分をまとめます。
| 項目 | 前回(HF PEFT) | 今回(Megatron-Bridge) |
|---|---|---|
| 学習フレームワーク | trl SFTTrainer | Megatron finetune() |
| LoRA カバー率 | 53% | 100% |
| LoRA rank | 16 | 32(レシピ既定値) |
| LoRA alpha | 32 | 32 |
| 学習率 | 2e-4 | 1e-4(レシピ既定値) |
| イテレーション | 138 step(1 epoch) | 500 iter |
| バッチサイズ | 8(bs=1 × grad_accum=8) | 8(mbs=1 × gbs=8) |
| 精度 | BF16 | BF16 |
| 学習環境 | DGX Spark(GB10) | Brev H100 80GB |
eval バッチサイズ問題
Megatron-Bridge の eval は、データ件数が global_batch_size 未満だとバッチ分割でクラッシュします。今回は eval 100 件に対して global_batch_size=8 なので本来問題ないはずですが、端数処理の不具合で引っかかりました。最終評価は Ollama 上で行うので、eval 自体を no-op にして回避しています。
import megatron.bridge.training.train as _train_module
_train_module.evaluate_and_print_results = lambda *a, **kw: None
Loss の推移
500 イテレーションの lm loss 推移です。
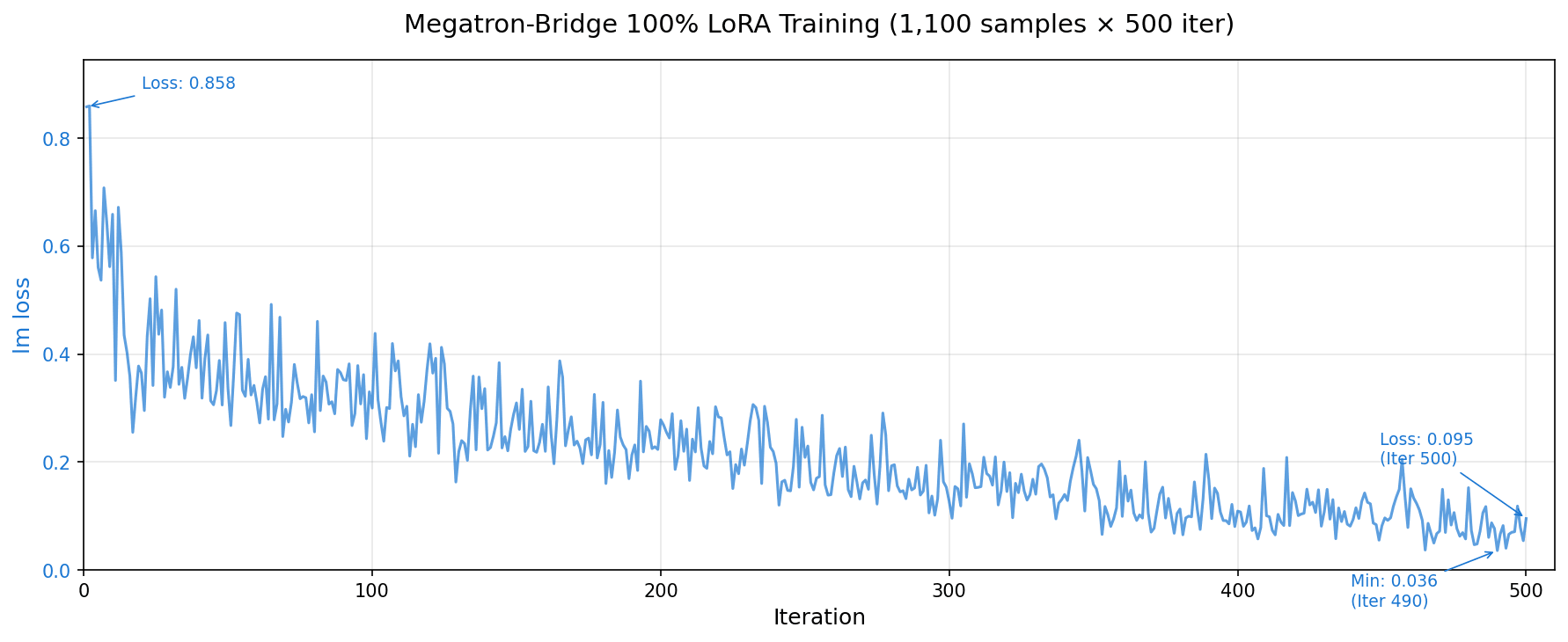
Loss は初期の 0.858 から 0.095 まで低下しました。前回(HF PEFT)の最終 Loss が 6.64 だったのに対し、桁が違います。これは学習フレームワーク間で Loss の計算方法が異なるためで、単純な比較はできませんが、学習自体は順調に収束していることがわかります。
学習にかかった時間は約 17 分でした。H100 の速さを実感しますね。DGX Spark では 55 分(138 step)かかっていた同じデータセットの学習が、500 iter でもこの速度です。GPU メモリは 23.3GB / 80GB で、TP=1 でも余裕がありました。
アダプターを持ち帰る
export_ckpt の source_path
学習が終わったら HuggingFace 形式にエクスポートします。学習チェックポイント(iter_0000500/)には LoRA のデルタ重み(.distcp)しか入っていないので、export_ckpt の source_path にこれを渡しつつ、ベースチェックポイントとマージします。
bridge = AutoBridge.from_hf_pretrained(
"nvidia/NVIDIA-Nemotron-Nano-9B-v2-Japanese",
trust_remote_code=True,
)
bridge.export_ckpt(
"/workspace/megatron-ckpt", # ベースの Megatron チェックポイント
"/workspace/hf-export", # エクスポート先(HF 形式)
source_path="/workspace/output/n6-megatron-lora/checkpoints/iter_0000500",
)
注意点として、bridge のインスタンスは from_hf_pretrained で初期化します。from_hf_config だと save_artifacts が未実装でエラーになります。ここはドライランで事前に気づけたので助かりました。
エクスポートは 50 秒で完了。ここまでの Brev 上の作業時間は合計で約 20 分、コストは $2.26/hr × 1 時間 ≈ $2.26 程度です。
GGUF 変換と Ollama 登録
エクスポートした HF モデルを DGX Spark に scp で転送し、GGUF に変換します。
前回は LoRA アダプター単体を GGUF に変換して Ollama の ADAPTER ディレクティブで合成していました。今回はそれが使えません。llama.cpp の LoRA adapter GGUF は Mamba-2 の in_proj と out_proj に非対応で、変換時にこれらのテンソルが無視されてしまうんですね。
なので今回はフルマージ済みの HF モデルを直接 GGUF に変換しています。
# フルマージ済み HF モデルを GGUF Q4_K_M に変換
python3 llama.cpp/convert_hf_to_gguf.py ./hf-export/ \
--outtype q4_k_m \
--outfile nemotron-9b-n6-Q4_K_M.gguf
| 方式 | 前回(HF PEFT) | 今回(Megatron-Bridge) |
|---|---|---|
| GGUF 形式 | LoRA adapter GGUF(36MB) | フルモデル GGUF(6.1GB) |
| Ollama 登録 | ADAPTER ディレクティブ |
FROM ディレクティブ |
| 理由 | llama.cpp が Attention + FFN の LoRA に対応 | Mamba-2 の LoRA adapter に非対応 |
Ollama の Modelfile は以下のとおりです。
FROM ./nemotron-9b-n6-Q4_K_M.gguf
TEMPLATE """{{- range $i, $_ := .Messages }}
{{- if eq .Role "system" }}<extra_id_0>System
{{ .Content }}
{{ end }}
{{- if eq .Role "user" }}<extra_id_1>User
{{ .Content }}
{{ end }}
{{- if eq .Role "assistant" }}<extra_id_1>Assistant
{{ .Content }}
{{ end }}
{{- end }}<extra_id_1>Assistant
"""
PARAMETER stop "<extra_id_1>"
PARAMETER num_ctx 8192
PARAMETER temperature 0.6
PARAMETER top_p 0.95
ollama create nemotron-9b-n6 -f Modelfile
これで ollama run nemotron-9b-n6 で推論できるようになりました。
評価結果
評価スクリプトとテストデータは前回記事とまったく同一のものを使い、条件を揃えて比較します。
JCQ 退行チェック
JCommonsenseQA(1,119 問)で汎用能力の退行を確認しました。
| モデル | JCQ 正答率 | 差分 |
|---|---|---|
| Baseline(FT なし) | 91.96%(1029/1119) | - |
| RAFT FT(HF PEFT / 53% LoRA) | 91.51%(1024/1119) | -0.45pp |
| RAFT FT(Megatron-Bridge / 100% LoRA) | 92.14%(1031/1119) | +0.18pp |
RAFT ドメイン F1 評価
国税庁 FAQ テストセット 200 件でトークンレベル F1 を計測しました。
| モデル | F1 | 回答不可 FP | 回答不可 TN |
|---|---|---|---|
| Baseline(FT なし) | 0.5646 | 47 | 153 |
| RAFT FT(HF PEFT / 53% LoRA) | 0.6536 | 3 | 197 |
| RAFT FT(Megatron-Bridge / 100% LoRA) | 0.4884 | 69 | 131 |
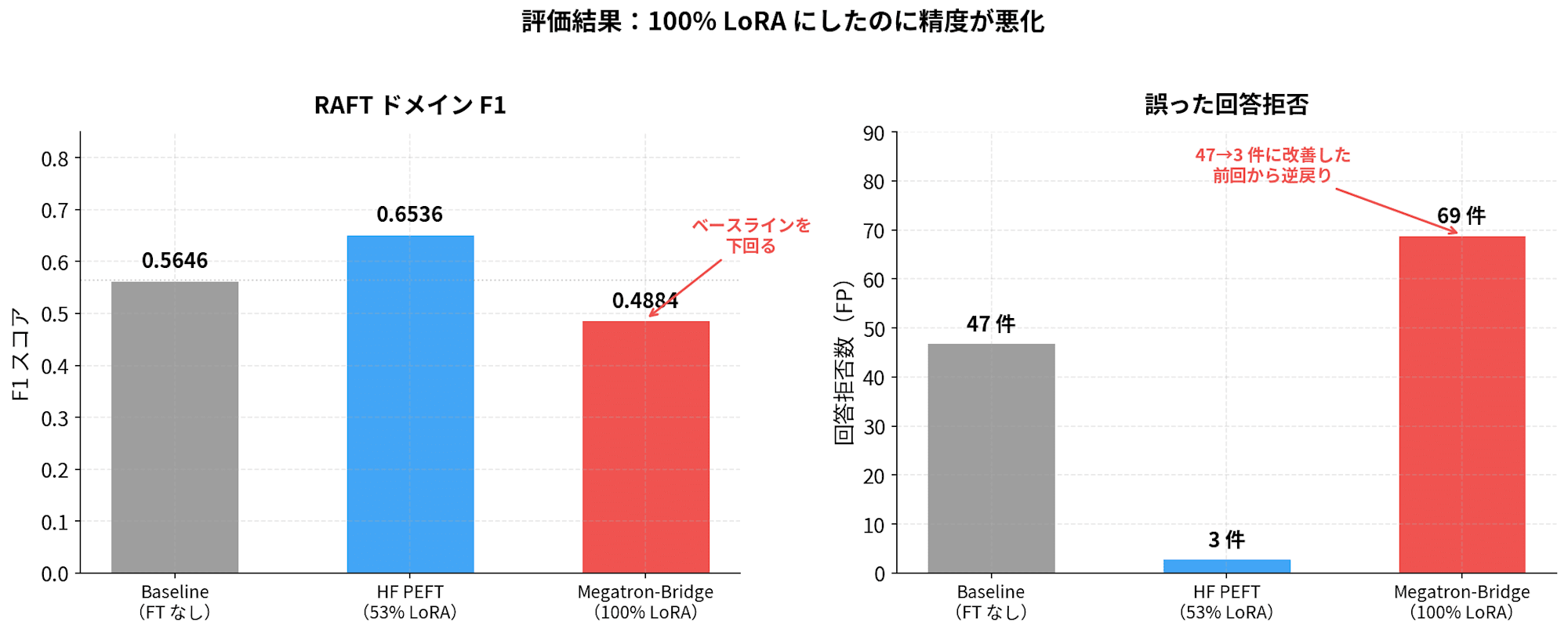
正直、この結果は予想外でした。100% LoRA にしたのに F1 はベースラインを下回っています。回答拒否(FP)も 69 件と、前回が 47 件から 3 件に激減させたのとは真逆の動きです。
定性サンプル
いくつかのサンプルを掘り下げてみました。まず気になるのが「今回のモデルが回答したサンプルに限定した F1」です。
| モデル | 回答数 | 回答サンプルの平均 F1 |
|---|---|---|
| RAFT FT(HF PEFT / 53% LoRA) | 197 | 0.6636 |
| RAFT FT(Megatron-Bridge / 100% LoRA) | 131 | 0.7457 |
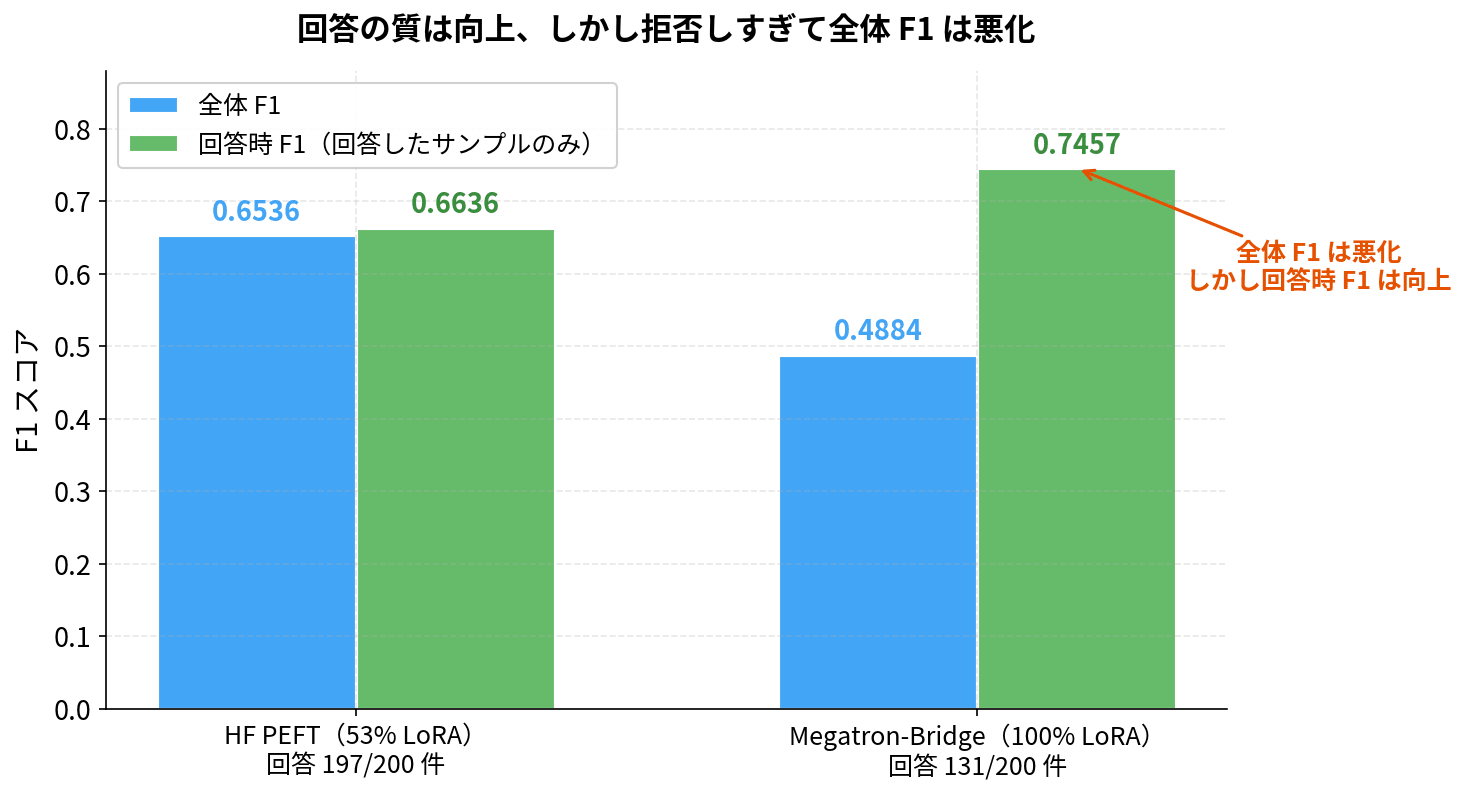
回答したときの精度自体は Megatron-Bridge のほうが高いんですね。問題は「回答するかどうかの判断」で、今回のモデルが過度に保守的になっている点です。
今回のモデルが拒否して前回のモデルが回答した例(3 件)
69 件の誤った回答拒否のうち、前回のモデルも同時に拒否したのは 3 件だけ。残り 66 件は前回のモデルが正しく回答できていたケースです。典型的なパターンを 3 件紹介します。
まず、養老保険の転換に関する質問。参考文書 5 に「転換した日の属する年分の必要経費に算入して差し支えありません」と明記されているにもかかわらず、今回のモデルは「提供された情報からは回答できません」と返しました。前回のモデルは該当箇所を引用して回答しています(F1: 0.418)。
次に、マイナンバーの猶予期間終了後の対応について。これも参考文書 5 に詳細な回答があり、前回のモデルは F1=0.808 で回答できています。今回のモデルは同じく拒否。参考文書の長さや専門用語の密度が関係しているのかもしれませんが、回答に必要な情報はちゃんと提供されています。
3 件目は SPC を経由したインド法人への利子に対する租税条約の適用。参考文書 1 に免税になる旨が明記されており、前回のモデルは F1=0.744 で回答。今回のモデルはやはり拒否です。
共通しているのは、いずれも参考文書に明確な回答が含まれている点です。今回のモデルは文書の内容を理解はしているものの、「回答できるかどうか」の判断で過度に慎重になっている印象です。
考察
100% LoRA なのに精度が下がった理由
定性サンプルで見たように、回答したときの F1 は今回のほうが高い(0.7457 vs 0.6636)。つまり回答の質自体は上がっています。全体の F1 が悪化した原因は「答えられるのに回答を拒否してしまう」ケースが 69 件も発生したことです。RAFT の学習データには「参考文書に答えがない場合は回答できませんと答える」サンプルが含まれていて、この拒否パターンを過学習してしまったと考えられます。
では、なぜ前回は同じデータで起きなかったのか。もっとも大きいのはエポック数の違いだと思っています。前回は 138 step(1 epoch)で学習を止めていましたが、今回は Megatron-Bridge のレシピ既定値をそのまま使って 500 iter 回しました。1,100 件のデータに対して約 3.6 epoch に相当します。拒否パターンを 3.6 周も繰り返し学習すれば、閾値が過度に下がるのは自然かもしれません。
ほかにも要因は考えられます。GGUF の変換方式が異なる点(前回は LoRA adapter GGUF をベースに重ねる方式、今回はフルマージ後に Q4_K_M 量子化)で、学習した微細な重み変化が量子化で丸められた可能性。あるいは、Mamba-2 の SSM 層に LoRA を通したことで、RAG の「参考文書から答えを探す」挙動よりも学習データのパターン記憶が優先された可能性。後者を検証するには Mamba-2 層だけ凍結した比較実験が必要ですが、今回はそこまで踏み込めていません。
前回と公平に比較するなら、rank=16、1 epoch、同じ GGUF 変換方式で揃えた実験が必要ですね。
Brev の費用対効果
今回の Brev 利用コストを整理します。
| 費目 | 時間 | コスト |
|---|---|---|
| ドライラン | ~1h | ~$2.26 |
| 本番実行 | ~1h | ~$2.26 |
| CoT 生成(Claude Haiku、前回実施済み) | - | ~$2.00 |
| 合計 | ~$6.52 |
DGX Spark でもっと時間をかけて解決できた可能性はありますが、$2.26 で H100 を 1 時間借りて問題を一気に突破できたのは悪くない判断だったかなと思っています。学習自体は 17 分で終わっていて、大半の時間は環境確認などの試行錯誤でした。
「クラウドで学習、エッジで推論」というパターンは DGX Spark との相性がいいと感じました。学習は H100 の速度が活きる場面、推論は DGX Spark の 128GB 統合メモリが活きる場面。Brev でスポット的に H100 を借りて学習し、結果をローカルに持ち帰るワークフローは今後も使えそうですし、まさにそのワークフローを想定していると思われる coming soon の DGX Spark と NVIDIA Brev との統合も楽しみです。
Megatron-Bridge の所感
Megatron-Bridge は正直なところ、ドキュメントが少ないです。API の使い方はソースコードを読んで試行錯誤する場面がほとんどでした。import_ckpt → finetune → export_ckpt の 3 ステップ自体はシンプルで、そこは好感触です。
ただ、各ステップにそれぞれ落とし穴がありました。import_ckpt では Manager().Queue() の EOFError、finetune では eval データのバッチサイズ不整合、export_ckpt では source_path を渡さないとモデルが壊れる問題。いずれも回避策はワンライナーで済むので、この記事が同じところで詰まった方の参考になれば幸いです。NeMo 25.11.01 時点の体験なので、将来のバージョンでは改善されているかもしれません。(私の使い方にも問題がありそうな気もしています。。。)
まとめ
Megatron-Bridge v0.2.0 を使って、Nemotron 9B-v2-Japanese の Mamba-2 層を含む 100% LoRA 学習を Brev H100 で実施しました。
| 項目 | 前回(HF PEFT) | 今回(Megatron-Bridge) |
|---|---|---|
| 学習フレームワーク | HF PEFT + trl | Megatron-Bridge v0.2.0 |
| LoRA カバー率 | 53% | 100% |
| 学習環境 | DGX Spark(GB10) | Brev H100 80GB |
| 学習時間 | 55 分 | 17 分 |
| GGUF 方式 | LoRA adapter(36MB) | フルモデル(6.1GB) |
| 追加コスト | ~$2(CoT 生成のみ) | ~$6.52(Brev + CoT) |
| JCQ 退行 | -0.45pp | +0.18pp(退行なし) |
| RAFT F1 | 0.6536 | 0.4884(悪化) |
技術的には、Brev のクラウド H100 で Megatron-Bridge を使い、Mamba-2 込みの 100% LoRA 学習を実現できました。「クラウドで学習してエッジに持ち帰る」ワークフローも問題なく動いています。
ただ、肝心の RAFT 精度は前回(53% LoRA)より悪化しました。LoRA カバー率を上げれば精度が上がるわけではない、という教訓です。回答したときの F1 自体は向上していたので、エポック数を揃えた再実験で拒否パターンの過学習を抑えられれば、結果は変わってくるかもしれません。
Megatron-Bridge 自体はハマりポイントこそ多いものの、HuggingFace エコシステムと Megatron の学習パイプラインをつなぐ橋渡しとして面白い位置づけだと感じました。ドキュメントの充実に期待しつつ、同じことを試そうとしている方の参考になれば幸いです。
スクリプト全体は以下のリポジトリで公開しています。








