
Obsidian Web ClipperでOllamaを使ってローカルLLMで記事を要約する方法
どうも!オペ部の西村祐二です!
Obsidian Web ClipperのInterpreter機能では、AIモデルを使ってWebページの要約やタグ抽出ができます。クラウドAPIだけでなく、Ollamaを使ったローカルLLMにも対応しているので、コストを気にせずに利用できます。
この記事では、OllamaをObsidian Web Clipperに設定してローカルLLMで記事要約する手順と、実際に運用する中で分かったチューニングのポイントをまとめます。モデルには最近リリースされたGemma 4を使用しました。
結論
Ollama + gemma4でローカル完結のWeb記事要約環境を構築できます。デフォルト設定のままだとコンテキスト長不足やCORSエラーで正常に動作しないため、環境変数でのチューニングが重要です。
この記事で分かること:
- Obsidian Web ClipperにOllamaを設定する手順
- CORS(403エラー)の回避方法
- テンプレートへのプロンプト変数の設定
- インタープリターコンテキストの最適化
- 環境変数によるコンテキスト長の拡張と高速化
- リクエスト内容のデバッグ方法
前提条件
- Ollamaがインストール済み
- Ollamaでモデルがダウンロード済み(例:
ollama pull gemma4) - ブラウザにObsidian Web Clipperが導入済み
- Obsidianがインストール済み
手順
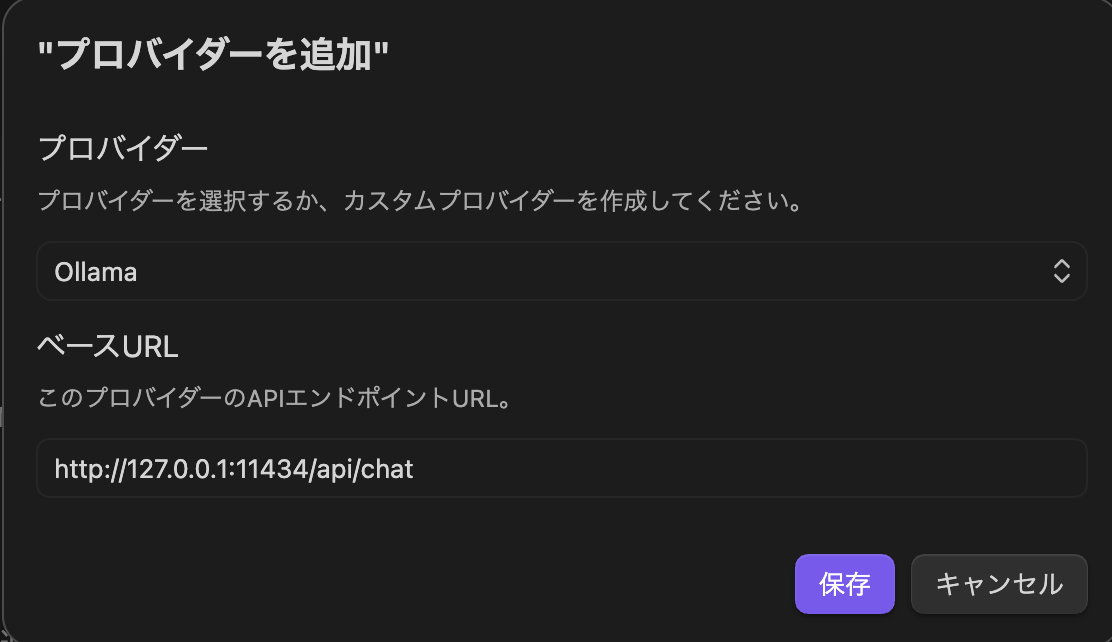
1. Ollamaプロバイダーの追加
Web Clipperの設定から Interpreter セクションを開き、プロバイダーを追加 で以下のように設定しました。
- プロバイダー: Ollama
- ベースURL:
http://127.0.0.1:11434/api/chat(プリセット選択時に自動入力される値)
OllamaはWeb Clipperのプリセットプロバイダーとして登録されているため、ベースURLはデフォルトのままで問題ありません。APIキーも不要です。
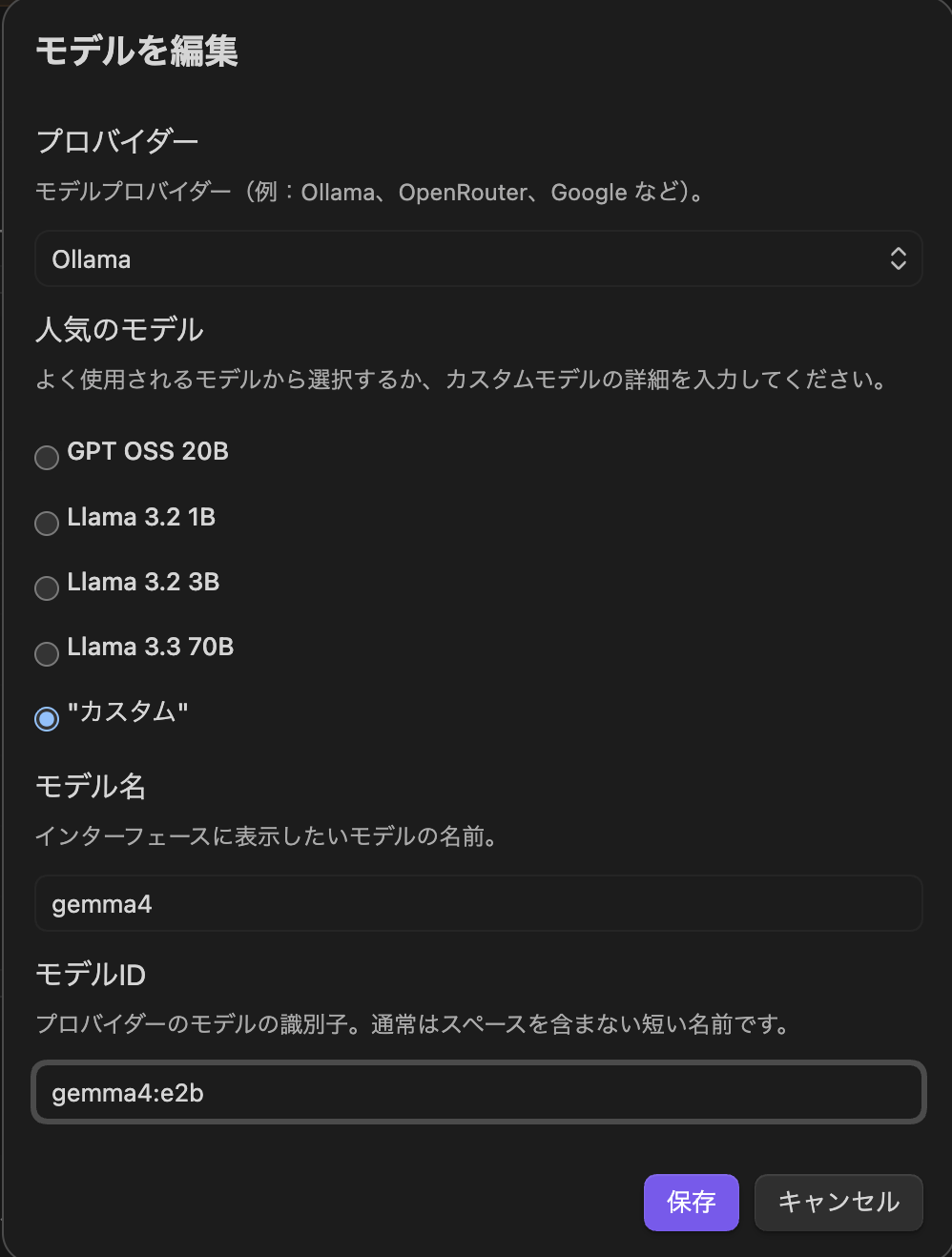
2. モデルの追加
モデルを追加 でモデルを登録しました。
- プロバイダー: Ollama
- 表示名: Gemma 4(任意の表示名)
- モデルID:
gemma4
モデルIDはOllamaで管理しているモデル名と正確に一致させる必要があります。gemma4 のようにタグを省略すると gemma4:latest として扱われます。別のバリアント(例: gemma4:e2b)を使う場合はタグまで含めて指定します。ollama listコマンドでインストール済みモデルの名前を確認できます。
ollama list
3. OLLAMA_ORIGINS付きでサーバー起動
ブラウザ拡張からOllamaにアクセスするには、CORS(Cross-Origin Resource Sharing)の許可設定が必要です。通常のOllamaアプリ起動では403エラーになります。
まずOllamaアプリを停止しました。メニューバーのOllamaアイコンから「Quit Ollama」を選択するか、ターミナルで以下を実行しました。
pkill ollama
次に、OLLAMA_ORIGINS環境変数を付けてサーバーを起動しました。
OLLAMA_ORIGINS=moz-extension://*,chrome-extension://*,safari-web-extension://* ollama serve
これで各ブラウザの拡張機能からのアクセスが許可されます。
4. テンプレートにプロンプト変数を追加
Interpreterを動作させるには、Web Clipperのテンプレートにプロンプト変数を埋め込む必要があります。{{"プロンプト"}} の形式で記述すると、クリップ時にInterpreterがLLMに問い合わせて結果を埋めてくれます。
例えば、テンプレートのプロパティに以下のように設定しました。
| プロパティ | 値 |
|---|---|
| description | {{"記事の要点"}} |
| tags | clippings, {{"検索に利用できそうなタグ情報を3-5ワード抽出,小文字,スペース禁止"}} |
description には記事の要点を、tags には固定タグ clippings に加えてLLMが抽出したタグを追加する設定です。プロンプトの内容は自由に変更できるので、用途に合わせて調整できます。
テンプレートにプロンプト変数が含まれている場合、クリップ時にInterpreterセクションが表示され、interpret ボタンで処理を実行する流れになります。
5. インタープリターコンテキストの最適化
Web Clipperの設定 > Interpreter > 詳細設定 > デフォルトインタープリターコンテキスト でコンテキストを設定できます。
いろいろ試行錯誤した結果、一周回って以下のように設定するのがおすすめかなと思いました。
{{content}}
content 変数はページの本文をMarkdown形式で返します。HTMLフィルターを組み合わせるより、この変数を使うのが最もシンプルで効果的でした。
| 変数 | 形式 | 特徴 |
|---|---|---|
{{content}} |
Markdown | 本文抽出済み。見出し・リスト・コードブロック等の構造が保持される。トークン効率が良い |
{{contentHtml}} |
HTML | 本文のHTML。フィルターで加工が必要 |
{{fullHtml}} |
HTML | ページ全体のHTML。nav・sidebar等のノイズを含む |
{{content}} はMarkdown形式のため、LLMが文書構造を理解しやすく、HTMLタグ分のトークンも節約できます。技術記事のコードブロックも保持されるため、情報の欠落が少ないのもメリットです。
基本的な設定は以上です。このままでも動作しますが、Ollamaのサーバー側のデフォルト設定では長文ページでコンテキスト長が不足するケースがありました。以下のチューニングで改善できます。なお、環境変数を変更する場合はサーバーの再起動が必要です。
チューニング
コンテキスト長の拡張
Ollamaのデフォルトコンテキスト長はVRAMに応じて自動設定されます(24GiB未満のVRAMでは4096トークン)。長文のWebページを処理する場合は不足することがあるため、OLLAMA_CONTEXT_LENGTH環境変数でサーバー起動時に指定できます。
OLLAMA_CONTEXT_LENGTH=16384 OLLAMA_ORIGINS=moz-extension://*,chrome-extension://*,safari-web-extension://* ollama serve
KVキャッシュ量子化による高速化
OLLAMA_KV_CACHE_TYPE環境変数でKVキャッシュ(推論時の中間データ)の量子化タイプを指定できます。Flash Attentionが有効な場合、メモリ使用量を削減しつつ処理を高速化できる可能性があります。
OLLAMA_FLASH_ATTENTION=1 も合わせて設定する必要があります。
OLLAMA_CONTEXT_LENGTH=16384 OLLAMA_FLASH_ATTENTION=1 OLLAMA_KV_CACHE_TYPE=q8_0 OLLAMA_ORIGINS=moz-extension://*,chrome-extension://*,safari-web-extension://* ollama serve
モデルバリアントの選択
gemma4にはサイズの異なるバリアントがあります。処理速度と品質のバランスに応じて選択できます。
| モデル | サイズ | 処理時間(参考値) | 特徴 |
|---|---|---|---|
gemma4:e2b |
7.2GB | 約37秒 | 軽量。速度重視の場合の選択肢 |
gemma4:latest(= e4b) |
9.6GB | 約64秒 | 標準。品質と速度のバランス |
gemma4:26b |
18GB | - | 高品質だが低速。VRAMに余裕がある場合 |
処理時間はApple M2 Max / 32GBでの参考値です(Flash Attention + KVキャッシュ量子化有効、プロンプト約2600トークン)。gemma4:e2b は gemma4:latest と比較して約半分の処理時間で、Web Clipperの要約タスク(要約、タグ抽出など)でも十分な品質が得られました。
チューニング後の起動コマンド
上記のチューニングをすべて含めた起動コマンドは以下のとおりです。
OLLAMA_CONTEXT_LENGTH=16384 OLLAMA_FLASH_ATTENTION=1 OLLAMA_KV_CACHE_TYPE=q8_0 OLLAMA_ORIGINS=moz-extension://*,chrome-extension://*,safari-web-extension://* ollama serve
チューニングしても期待どおりの結果が得られない場合は、デバッグログで原因を調査できます。
デバッグ方法
OllamaのデバッグログでWeb Clipperからどのようなリクエストが送信されているか確認できます。
サーバーログの確認
OLLAMA_DEBUG=trueを付けてサーバーを起動すると、プロンプトのトークン数やリクエスト形式が確認できます。
OLLAMA_DEBUG=true OLLAMA_CONTEXT_LENGTH=16384 OLLAMA_FLASH_ATTENTION=1 OLLAMA_KV_CACHE_TYPE=q8_0 OLLAMA_ORIGINS=moz-extension://*,chrome-extension://*,safari-web-extension://* ollama serve
ログには以下のような情報が出力されます。
msg="completion request" images=0 prompt=2631 format=""
msg="completion request" images=0 prompt=2652 format="\"json\""
prompt=2631 がプロンプトのトークン数です。コンテキスト長に対してこの値が大きすぎると、レスポンスに使えるトークンが不足します。
リクエスト本文の確認
OLLAMA_DEBUG_LOG_REQUESTS=trueを追加すると、リクエスト本文がJSONファイルとして保存されます。
OLLAMA_DEBUG=true OLLAMA_DEBUG_LOG_REQUESTS=true OLLAMA_CONTEXT_LENGTH=16384 OLLAMA_FLASH_ATTENTION=1 OLLAMA_KV_CACHE_TYPE=q8_0 OLLAMA_ORIGINS=moz-extension://*,chrome-extension://*,safari-web-extension://* ollama serve
ログに保存先のパスが出力されます。
msg="logged to /var/folders/.../ollama-request-logs-.../...body.json"
このJSONファイルを確認すると、Web Clipperが送信したシステムプロンプト、コンテキスト(ページ本文)、ユーザープロンプトの内容をすべて確認できます。コンテキスト設定が正しく反映されているか、不要なノイズが含まれていないかの検証に役立ちます。
まとめ
Obsidian Web ClipperでOllamaを使ったローカルLLMによる記事要約の設定手順とチューニングのポイントをまとめました。
ポイントは以下のとおりです。
OLLAMA_ORIGINS環境変数でCORSを許可する(必須)- インタープリターコンテキストは
{{content}}がシンプルで効果的 OLLAMA_CONTEXT_LENGTHで長文ページに対応するOLLAMA_FLASH_ATTENTION=1とOLLAMA_KV_CACHE_TYPE=q8_0でメモリ効率を改善する- デバッグログでリクエスト内容を確認できる
クラウドAPIを使わずにローカルで完結するため、プライバシーやコストを気にせず利用できるのがメリットだと感じました。
一方で、チューニングを施しても軽量モデルの gemma4:e2b で約37秒かかるのが現状です。Webページをクリップするたびにこの待ち時間が発生するのは、体験としてはやや重いと感じました。より高速なローカルモデルの登場に期待したいところです。
別のアプローチとして、クリップ時にはプレーンな状態で保存しておき、Claude CodeなどのAIツールでバッチ的にタグ付けや要約を実行する方法も考えられます。ユーザーが待つ必要がなく、より高性能なモデルで処理できるため、結果的に体験が良くなる可能性がありそうです。
誰かの参考になれば幸いです。
参考リンク:









