
AWS ParallelCluster 3.14.0 にコンピュートノードの起動サブネットを優先度をつけられる配分戦略が追加されました
はじめに
AWS ParallelCluster v3.14.0 がリリースされました。6 ヶ月ぶりの大きなアップデートです。
今回のアップデートでは、P6e-GB200 と P6-B200 インスタンスのサポートに加えて、2つの新しい配分戦略が追加されました。
- オンデマンドインスタンス用:
prioritized - スポットインスタンス用:
capacity-optimized-prioritized
本記事では、新しい配分戦略を中心にアップデート内容を紹介し、スポットインスタンス用の capacity-optimized-prioritized の動作を検証します。
アップデート内容早見
AWS ParallelCluster v3.14.0 の主なアップデート内容は以下の通りです。
- P6e-GB200 および P6-B200 インスタンスタイプのサポート
- 最新ハイスペック GPU が ParallelCluster でも利用可能に!
- 優先度付き配分戦略が追加
- Amazon Linux 2023 で Amazon DCV サポート
- ParallelCluster で Ubuntu 20.04 LTS のサポート終了
- Slurm のバージョン 24.11.6 へのアップグレード
詳細は GitHub のリリースノートをご確認ください。
P6e-GB200, P6-B200 を新規サポート
P6e-GB200 と P6-B200 の制限事項
新しくサポートされた GPU インスタンスは、利用可能な OS に制限があるためご確認ください。
P6e-GB200 インスタンス
- サポート OS: Amazon Linux 2023、Ubuntu 22.04、Ubuntu 24.04 のみ
- IMEX 使用時は追加セットアップが必要
P6e-GB200 インスタンスの詳細については、以下の記事もご参照ください。
P6-B200 インスタンス
- サポート OS: Amazon Linux 2023、RHEL 8/9、Rocky 8/9、Ubuntu 22.04、Ubuntu 24.04
P6-B200 インスタンスの詳細については、以下の記事もご参照ください。
GPU ヘルスチェックの注意事項
ヘルスチェックの実行時間が 10 分を超える可能性があります。これによりジョブの失敗やスループットの大幅な低下を引き起こす恐れがあります。
Scheduling:
SlurmQueues:
- Name: string
# -- 省略 ---
HealthChecks:
Gpu:
Enabled: false # ヘルスチェック無効化が推奨
参考: Scheduling section - AWS ParallelCluster
新しい配分戦略が登場
今回追加された 2 つの配分戦略により、複数サブネット構成でのコンピュートノード起動時にサブネット優先度を指定できるようになりました。
以前、疎結合なワークロードにおける複数 AZ 活用方法を紹介しましたが、新しい配分戦略によってこの手法がより効果的に利用できます。
prioritized (オンデマンド用)
prioritized は、オンデマンドインスタンス用の新しい配分戦略です。複数のサブネットを指定している場合に起動するサブネットの優先順位を指定できます。
設定例
SlurmQueues/Networking/SubnetIds で指定されたサブネットの順序に従ってEC2 起動の優先順位が決まります。
- Name: p1
ComputeResources:
- Name: ondemand
Instances:
- InstanceType: c7i.large
MinCount: 0
MaxCount: 10
DisableSimultaneousMultithreading: true
+ CapacityType: ONDEMAND
+ AllocationStrategy: prioritized
Networking:
SubnetIds:
+ - subnet-xxxxxxxx1 # 優先度: 高
+ - subnet-xxxxxxxx2 # 優先度: 中
+ - subnet-xxxxxxxx3 # 優先度: 低
ユースケース
FSx for Lustre や、FSx for OpenZFS のシングル AZ またはシングル AZ 冗長構成などの特定 AZ に配置されるストレージサービスを利用する場合、同一 AZ で EC2 インスタンスを起動することでレイテンシを最小化できます。
prioritized を使用すると以下の動作が可能になります。
- 通常時: 優先度が高いサブネット(同一 AZ)でインスタンスを起動
- キャパシティ不足時: 優先度が低いサブネット(別 AZ)で起動
これにより目的の AZ を優先しながら、キャパシティ不足時は別 AZ で EC2 インスタンスを起動できます。レイテンシ最適化と可用性確保を両立できます。これはかゆいところに手が届く良いアップデートです。
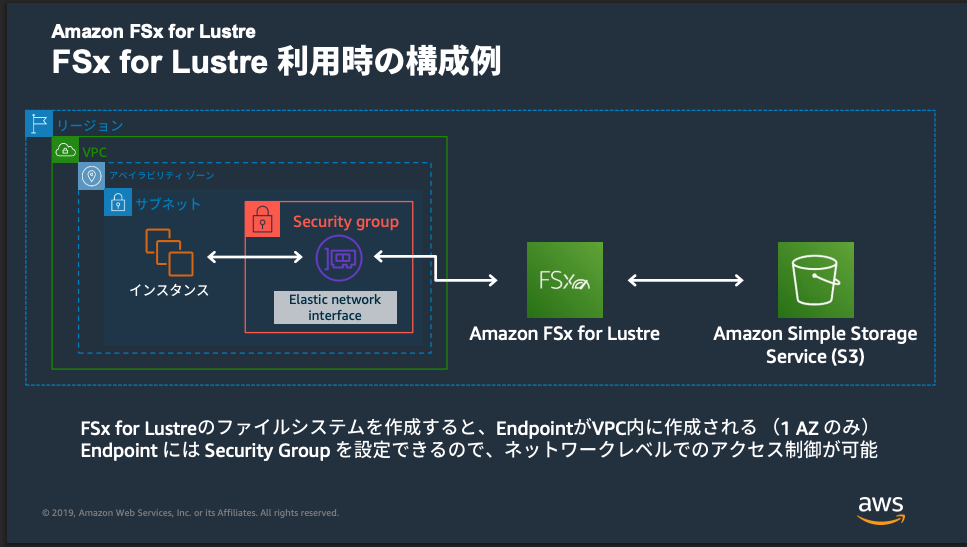
画像引用: Amazon FSx for Lustre - [AWS Black Belt Online Seminar]
capacity-optimized-prioritized (スポット用)
capacity-optimized-prioritized は、スポットインスタンス用の新しい配分戦略です。
キャパシティ最適化を最優先しつつ、ベストエフォートでサブネット優先順位を適用します。
スポットインスタンスでは、中断リスクの最小化が最優先となります。その上で、EC2 が起動するサブネットも考慮したい場合にcapacity-optimized-prioritized が有効です。ユースケースもオンデマンド用のprioritizedと同じです。
prioritized と capacity-optimized-prioritized の違い早見
| 項目 | prioritized (オンデマンド) | capacity-optimized-prioritized (スポット) |
|---|---|---|
| 優先順位の適用 | 指定した通りに守る | ベストエフォート |
| 第一優先 | 指定したサブネットの順序 | キャパシティの最適化 |
| 用途 | EC2 の起動するサブネットの制御 | 中断リスク低減 + 起動サブネットの考慮 |
検証環境の構築
さっそくスポットインスタンス用の capacity-optimized-prioritized 戦略を使用したクラスタを構築して動作を確認します。
検証環境
以下の環境を用意しました。
| 項目 | 値 |
|---|---|
| AWS ParallelCluster | 3.14.0 |
| OS | Ubuntu 24.04 |
| ヘッドノード | t3a.micro |
| リージョン | ap-northeast-1 |
クラスターコンフィグ
検証に使用したクラスターのコンフィグファイルです。
クラスター設定ファイル全文
Region: ap-northeast-1
Image:
Os: ubuntu2404
Tags:
- Key: Name
Value: cluster-v3.14.0
# ----------------------------------------------------------------
# Head Node Settings
# ----------------------------------------------------------------
HeadNode:
InstanceType: t3a.small
Networking:
ElasticIp: false
SubnetId: subnet-029f0fb0acc64043d
LocalStorage:
RootVolume:
Size: 45
Encrypted: true
VolumeType: gp3
Iops: 3000
Throughput: 125
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
# ----------------------------------------------------------------
# Compute Node Settings
# ----------------------------------------------------------------
Scheduling:
Scheduler: slurm
SlurmSettings:
ScaledownIdletime: 5
# ------ Slurm Accounting ------
# Database:
# Uri: slumdb2.cja2kmww8voi.ap-northeast-1.rds.amazonaws.com:3306
# UserName: admin
# PasswordSecretArn: arn:aws:secretsmanager:ap-northeast-1:060238338506:secret:slurmdb2-0VTEb7
SlurmQueues:
# ------ Compute ------
- Name: test
ComputeResources:
- Name: test
Instances:
- InstanceType: t3a.micro
MinCount: 0
MaxCount: 10
DisableSimultaneousMultithreading: true
ComputeSettings:
LocalStorage:
RootVolume:
Size: 45
Encrypted: true
VolumeType: gp3
Iops: 3000
Throughput: 125
CapacityType: SPOT
AllocationStrategy: price-capacity-optimized
Networking:
SubnetIds:
- subnet-029f0fb0acc64043d
- subnet-0b9c598622ad54e61
- subnet-01559948e762bd434
PlacementGroup:
Enabled: false
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
# ------ Compute ------
- Name: p1
ComputeResources:
- Name: c7i-normal
Instances:
- InstanceType: c7i.large
MinCount: 0
MaxCount: 10
DisableSimultaneousMultithreading: true
ComputeSettings:
LocalStorage:
RootVolume:
Size: 45
Encrypted: true
VolumeType: gp3
Iops: 3000
Throughput: 125
CapacityType: SPOT
AllocationStrategy: price-capacity-optimized
Networking:
SubnetIds:
- subnet-0b9c598622ad54e61
- subnet-01559948e762bd434
- subnet-029f0fb0acc64043d
PlacementGroup:
Enabled: false
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
# ------ Compute ------
- Name: p2
ComputeResources:
- Name: c7i-prioritized
Instances:
- InstanceType: c7i.large
MinCount: 0
MaxCount: 10
DisableSimultaneousMultithreading: true
ComputeSettings:
LocalStorage:
RootVolume:
Size: 45
Encrypted: true
VolumeType: gp3
Iops: 3000
Throughput: 125
CapacityType: SPOT
AllocationStrategy: capacity-optimized-prioritized
Networking:
SubnetIds:
- subnet-0b9c598622ad54e61
- subnet-01559948e762bd434
- subnet-029f0fb0acc64043d
PlacementGroup:
Enabled: false
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
# ----------------------------------------------------------------
# Shared Storage Settings
# ----------------------------------------------------------------
SharedStorage:
- MountDir: /home
Name: efs1
StorageType: Efs
EfsSettings:
FileSystemId: fs-0f66550e47cbc924b
# ----------------------------------------------------------------
# Other Settings
# ----------------------------------------------------------------
Monitoring:
Logs:
CloudWatch:
Enabled: true
RetentionInDays: 180
DeletionPolicy: "Delete"
Dashboards:
CloudWatch:
Enabled: false
動作検証
意図的にスポット料金が高い AZ を優先順位の上位へ指定し、それでもキャパシティ最適化が優先されるかを検証します。
検証環境の構成
2 つのパーティションを用意しました。起動可能なインスタンスタイプは c7i.large のみで意図的にスポット料金が高い順にサブネットを指定しています。
| パーティション | 配分戦略 | サブネット優先順位 |
|---|---|---|
| p1 (c7i-normal) | price-capacity-optimized |
1c → 1d → 1a |
| p2 (c7i-prioritized) | capacity-optimized-prioritized |
1c → 1d → 1a |
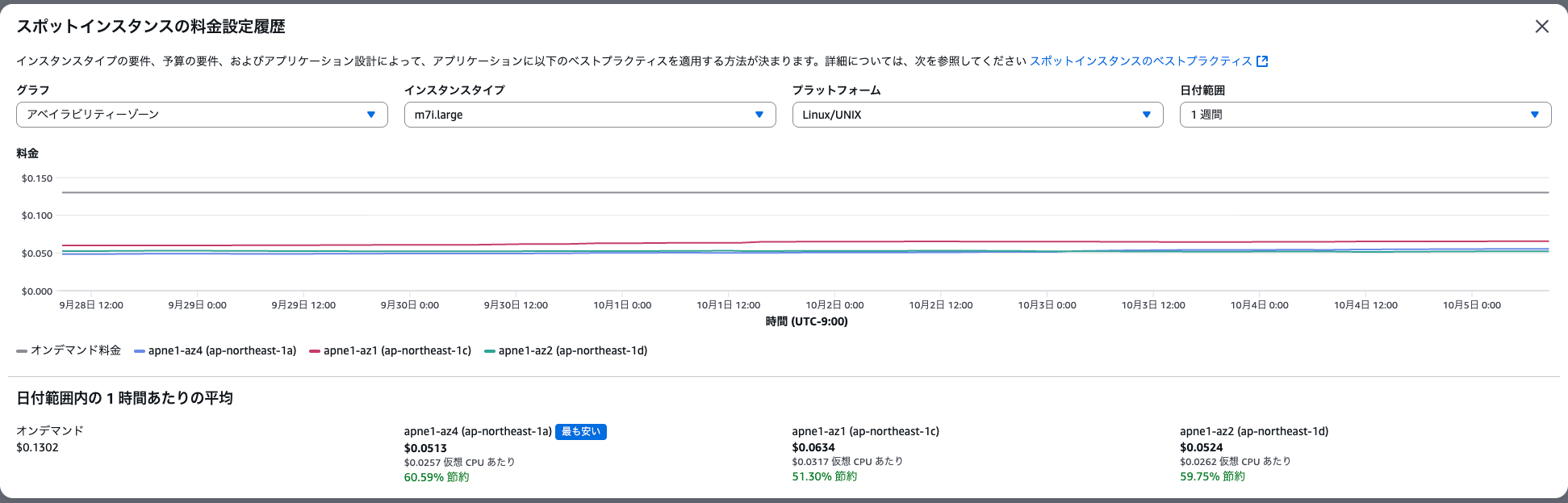
スポット料金の確認
検証時点での c7i.large のスポット料金は以下の通りでした。
| AZ | スポット料金 | 順位 |
|---|---|---|
| ap-northeast-1a | $0.0513 | 最安 |
| ap-northeast-1d | $0.0524 | 2位 |
| ap-northeast-1c | $0.0634 | 3位 |
検証 1: p1 パーティションでの起動確認
従来の price-capacity-optimized 戦略を使用する p1 パーティションに 10 ノードのジョブを投入しました。
#!/bin/bash
#SBATCH --job-name=test_p1
#SBATCH --partition=p1
#SBATCH --nodes=10
#SBATCH --ntasks=10
#SBATCH --output=job_p1_%j.out
#SBATCH --error=job_p1_%j.err
srun hostname
sbatch job-p1.sh
結果
10 台すべてが ap-northeast-1d で起動しました。
$ aws ec2 describe-instances \
--filters "Name=tag:parallelcluster:compute-resource-name,Values=c7i-normal" \
"Name=instance-state-name,Values=running,pending" \
--query 'Reservations[*].Instances[*].[Placement.AvailabilityZone,SubnetId]' \
--output table
--------------------------------------------------------------------
| DescribeInstances |
+------------------+----------------------------+
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
+------------------+----------------------------+
検証 2: p2 パーティションでの起動確認(10 ノード一括)
新しい capacity-optimized-prioritized 戦略を使用する p2 パーティションに 10 ノードのジョブを投入しました。
#!/bin/bash
#SBATCH --job-name=test_p2
#SBATCH --partition=p2
#SBATCH --nodes=10
#SBATCH --ntasks=10
#SBATCH --output=job_p2_%j.out
#SBATCH --error=job_p2_%j.err
srun hostname
sbatch job-p2.sh
結果
サブネット優先順位では 1c が最優先でしたが、10 台すべてが ap-northeast-1d で起動しました。念のため同じジョブを再度投入しましたが、結果は同じでした。
$ aws ec2 describe-instances \
--filters "Name=tag:parallelcluster:compute-resource-name,Values=c7i-prioritized" \
"Name=instance-state-name,Values=running,pending" \
--query 'Reservations[*].Instances[*].[Placement.AvailabilityZone,SubnetId]' \
--output table
--------------------------------------------------------------------
| DescribeInstances |
+------------------+----------------------------+
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
+------------------+----------------------------+
検証 3: p2 パーティションでの起動確認(1 ノード × 10 回)
さらに確認するため、起動するノード数を 1 に変更したジョブを 30 秒間隔で 10 回サブミットしました。
#!/bin/bash
#SBATCH --job-name=test_p2_single
#SBATCH --partition=p2
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --output=job_p2_single_%j.out
#SBATCH --error=job_p2_single_%j.err
srun hostname
for i in {1..10}; do
sbatch job-p2-single.sh
sleep 30
done
結果
10 回の投入すべてで ap-northeast-1d にインスタンスが起動しました。どうやら現時点ではスポット起動するなら 1d がオススメの様です。
$ aws ec2 describe-instances \
--filters "Name=tag:parallelcluster:compute-resource-name,Values=c7i-prioritized" \
"Name=instance-state-name,Values=running,pending" \
--query 'Reservations[*].Instances[*].[Placement.AvailabilityZone,SubnetId]' \
--output table
--------------------------------------------------------------------
| DescribeInstances |
+------------------+----------------------------+
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
| ap-northeast-1d | subnet-01559948e762bd434 |
+------------------+----------------------------+
検証結果の考察
すべての検証で ap-northeast-1d にインスタンスが起動した理由は、キャパシティ最適化が優先されたためと考えられます。
capacity-optimized-prioritized 戦略では、以下の優先順位で動作します。
- 第一優先: スポット中断リスクがもっとも低いキャパシティプールを選択
- 第二優先: 可能な範囲でサブネット優先順位を考慮(ベストエフォート)
今回の検証では、ap-northeast-1d がもっとも中断リスクが低いと判断され、サブネット優先順位よりもキャパシティ最適化が優先されました。
スポットインスタンスの中断リスクを最小化しながら、推測ですがキャパシティに余裕がある場合は指定したサブネットの優先順位も考慮されるという特性を垣間見れたのではないでしょうか。本当は指定したサブネットが優先されるとおもしろかったのですが残念です。スポット料金に差がないインスタンスタイプを選べば結果も違ったかもしれません。
まとめ
AWS ParallelCluster v3.14.0 で追加された 2 つの新しい配分戦略について解説しました。
- prioritized (オンデマンド用): サブネットの優先順位を守る
- capacity-optimized-prioritized (スポット用): キャパシティを最優先し、ベストエフォートでサブネット優先度を適用
本記事では、スポット用の capacity-optimized-prioritized 戦略の動作を検証しました。
おわりに
今回追加された配分戦略はかゆいところに手が届く良いアップデートでした。特定サブネットを優先したいときは積極的に検討してみます。








