![[セッションレポート] PayPalの大規模自律SRE agent実装事例とGemini Enterprise Agent Platformによるagent運用基盤 #GoogleCloudNext](https://images.ctfassets.net/ct0aopd36mqt/4VZteia2tZFWoXPzZmZcuT/32265bac33524fc15a9254504b80ef85/260401_eyechatch_googlecloudnext26_w1200h630.png?w=3840&fm=webp)
[セッションレポート] PayPalの大規模自律SRE agent実装事例とGemini Enterprise Agent Platformによるagent運用基盤 #GoogleCloudNext
お疲れさまです。とーちです。
Google Cloud Next 2026に参加してきました。本記事は "Scaling autonomous SRE with Agent Runtime on Gemini Enterprise Agent Platform" という、PayPalが自律型SRE agentをどう構築し本番運用しているか、またそれを支えるGemini Enterprise Agent Platform上でのagent運用基盤について話されたセッションのレポートです。
セッション概要
タイトル
Scaling autonomous SRE with Agent Runtime on Gemini Enterprise Agent Platform
概要
How does a global payments leader handle incidents at the speed of code? Join this session to discover how PayPal built and scaled an autonomous site reliability engineering (SRE) agent platform with Agent Runtime on Gemini Enterprise Agent Platform. PayPal's architecture integrates directly with production observability stacks to detect, analyze, and resolve incidents. Learn how this system helped them significantly cut down both the mean time to repair (MTTR) and the total hours spent on manual effort. We'll dive into the production journey, from the architecture of multi-agent loops to the governance required for autonomous remediation at scale.
※日本語訳:
世界的な決済事業者が、コードが流れるスピードでインシデントにどう対処しているのか? 本セッションでは、PayPalがGemini Enterprise Agent Platform上のAgent Runtimeを使って、自律型SRE (サイトリライアビリティエンジニアリング) agentのプラットフォームをどう構築し、スケールさせたのかを紹介します。PayPalのアーキテクチャは、本番の可観測性スタックと直接統合してインシデントを検出・分析・解決します。このシステムによってMTTR (平均修復時間) と手作業工数がどれだけ削減されたかをお話しします。本番投入までの道のりとして、マルチagentループのアーキテクチャから、大規模な自律修復に必要なガバナンスまで踏み込んで解説します。
スピーカー
- Mir Islam 氏 (PayPal, Director of AI Ops & SRE)
- Afrina M 氏 (Google Cloud, Senior Product Manager)
- Cedric Yao 氏 (Google Cloud, Head of Application Innovation Programs, GTM)
agentを構成する3つの要素
最初のパートはGoogle CloudのCedric氏が話されていました。
まず会場に「皆さんにとってAI agentとは何ですか?」という問いかけがあり、会場からは「小さなロボット」「ある条件を満たすまでwhile trueで動くもの」「自分自身の分身 (Claude CodeやGemini CLIのようなもの)」といった回答が挙がっていました。
これに対してCedric氏は「業界としてagentの定義はまだ固まっていない」と前置きした上で、agentを大きく2種類に分けて捉えていると仰っていました。
- 自分の代わりに動くagent
- ADK・Crew AI・LangGraphなどのライブラリを使って構築し、成果物としてデプロイするagent
今回のセッションで扱うのは後者で、これを構築する上で必要な要素は Models / Context / Tooling の3つだと整理されていました。

Models: 100人のインターンと面接するイメージ
モデル選びについては「100人の大学院生をインターンとして受け入れるとき、一人ひとり面接して "うちの仕事に合うか" を見極めるのと同じ」とインターンにたとえていました。インターンに得意不得意があるように、モデルによって得意不得意があるので、タスクに最も適したモデルをその都度選べる環境を用意するのが大事というお話です。
Context: "戻ってきてくれるインターン"に育てる
組織の文脈を知らないインターンに「このアプリケーションを作って」と丸投げしても動けないのと同じで、agentにも組織固有の文脈(Context)を渡す必要があります。
ビルドの慣習はどうなっているか、動いていないサーバーは止めていいのか、といった組織固有の文脈をどう教え込むか、ここが鍵になるとのことでした。
Tooling: オーケストレーションやハーネスも含む広い概念
Toolingという言葉はかなり広い意味で使われていて、Cedric氏は「100人のインターンが戻ってきたとして、どう管理しますか?」という問いと同じだと表現されていました。具体的には以下のようなものが含まれるとのことでした。
- agent群を束ねるオーケストレーション
- agentを実際にデプロイするときのハーネス (実行基盤)
- agentが正しい行動をとっているかを観察するプラットフォーム
- tool呼び出しの軌跡 (trajectory) が正しい方向に向かっているかを把握する仕組み
agentそのものを作る話だけでなく、それを運用・観察する基盤までまとめてToolingと呼んでいる、という捉え方でした。
この3要素の話を踏まえて、次はPayPalのMir氏のパートに移りました。
PayPalでの自律SRE agent実装事例
PayPalの規模とSREが抱える課題
Mir氏はまずPayPalの規模感を紹介されていました。
- 毎分500万ドル超の売上がシステムを通過
- 3,000のmicroservices
- 1日あたり25億回のAPIインタラクション
- 年間1,050万回の本番変更
決済事業者として失敗が許されない状況の中、SRE・プロダクションエンジニアは地道な手作業に埋もれているというお話でした。Mir氏が「ここ2週間で夜中にインシデント対応で起こされた方?」と会場に問いかける場面もあり、私も休日にインシデント対応の電話がかかってきた経験を思い出しました。
PayPalで実際に起きていた具体的な課題として、以下が挙げられていました。
- 繰り返しのトリアージでエンジニアの集中力が消耗している
- オンコールシフトやインシデント間でコンテキストが失われる
- RCA (Root Cause Analysis) ドキュメントや更新が遅れる
- 深夜呼び出しでエンジニアが疲弊する
- PayPal社内で計測したところ、インシデント対応工数の70%がデータ収集と手作業での相関付けに使われていた

Mir氏は「問題はツールが足りないことではなく、各ツール・データをまたいでインシデント対応を指揮する仕組みが足りないこと」と強調されていました。
ボトムアップアプローチでデータから棚卸しする
PayPalではAIやモデル、フレームワークの話から始めるのではなく、「まずデータがどこにあるか」「なぜそこに保存されているか」「人はどうアクセスしているか」「データソース同士はどう繋がっているか」を棚卸しするところから始めた、とのことでした。
棚卸しされた主要なデータソースはこちらです。
- BigQuery (Google Cloud): SREデータレイクとして大部分のSRE情報を保持
- CAL: PayPal内製のロギングシステム (ログ・リアルタイム可観測性・分散トレーシング)
- ServiceNow: ITSMの変更リクエスト
- Splunk / Datadog: ログ・メトリクス・ダッシュボード・アラート

さらにこれらの上に SRE MCP tools を構築したというのが特徴的でした。バラバラに散らばったデータソースに対して統一的なAPI層を用意し、agent側から一箇所で叩けるようにしたとのことです。「MCPレイヤーに投資したことでagentを実用的にできた」と仰っていました。SRE MCPを使ったagentが具体的にどう動くかは、後述のデモ(カオスエンジニアリングツールで異常を注入)がわかりやすかったです。
夜中2時のインシデント対応問題
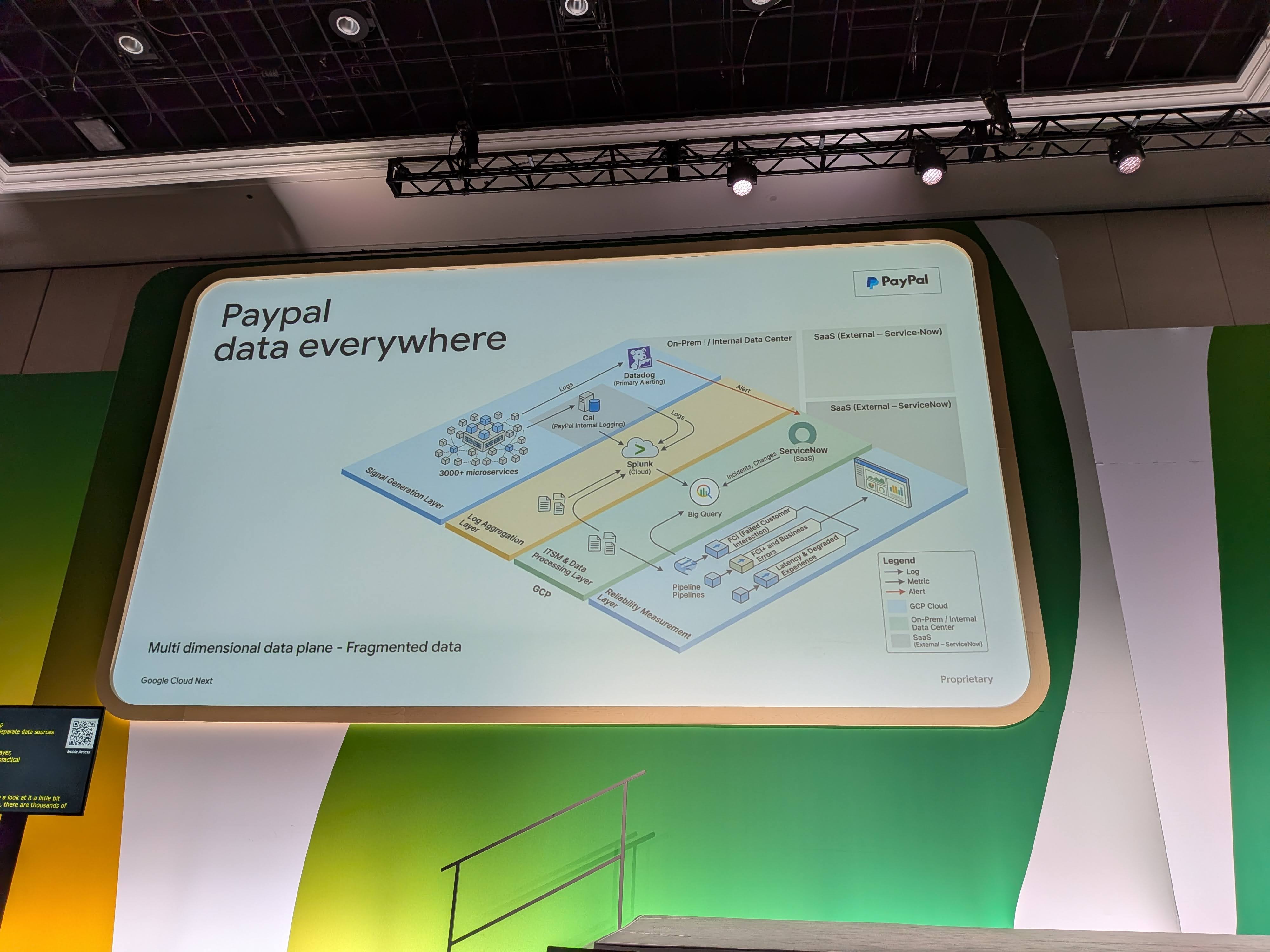
図を見ながらの説明では、数千のmicroservices、様々なアラート生成ツール (SaaS・内製・オンプレ)、顧客インタラクション情報が入り乱れた状態が示されていました。
Mir氏は「あなたはSREで、夜中2時に呼び出しを受けて起きる。そこからこの大量のデータソースを辿らないといけない。頭がクラクラしますよね」と表現されていて、私も確かにこれは大変そうと思いました。
この状況を「ダッシュボードやアラートやツールをさらに増やす」で解決するのは間違いだとMir氏は明言されていました。企業がAIや運用ツールへ投資を増やしているにもかかわらず、現場の繰り返しの運用作業はむしろ増えているという趣旨の話がされていて、見るべきダッシュボードが増えるだけでなく、「AIが何をしているか」を監視する作業まで上乗せされてしまうとのことでした。
自律SRE: 単なるチャットボットではない
では解決策は何か。Mir氏は「自律SRE (Autonomous SRE)」と呼ぶアプローチを紹介されました。これはRAGとナレッジベースの上に乗っただけのAIチャットボットではなく、検出・トリアージ・緩和・レポートというインシデントライフサイクル全体を回すagentによるワークフロー だと強調されていました。

このプラットフォームの主な特徴はこちらです。
- 並列実行: 従来は人間が検出 → トリアージ → 連絡を順番にこなすため直列処理にならざるを得なかったが、データ収集・影響範囲分析・変更履歴調査をagentに同時並行で走らせることでライフサイクル全体を短縮
- 永続メモリ: オンコールシフト交代時に失われがちなコンテキストを、セッションを跨いで記憶を呼び戻す仕組みとして保持。過去のインシデントや直前のシフトで得たユーザーコンテキストを覚えたまま動く
- インテリジェントなトリアージ: トリアージagentが過去インシデント履歴に対して意味的な類似度でマッチングを行い、新しいインシデントにスコアを付けてエンジニアが起きる前に最有力の根本原因候補を提示
- MCP統合: 全agentがMCP経由で各種ツール (BigQuery / CAL / ServiceNow / Splunk / Datadog 等) へアクセス
- Vertex AI上で動作: サーバーレス、自動スケール、マネージドなインフラ、可観測性を最初から備える
「永続メモリの部分はとても大きい。どれだけきちんとドキュメント化していても、シフトを離れるエンジニアと一緒に得たコンテキストが持ち去られてしまう。agentがセッションを跨いで過去インシデントや直前シフトのユーザーコンテキストを覚えていてくれる」という補足がありました。セッションを跨いだ記憶を具体的にどう実装しているのかはセッション内では明確な説明がなく気になるところでした。Gemini Enterprise Agent PlatformのMemory Bank機能を使っているのかもしれませんが、Memory Bankだと長期メモリを使うことになるので、定期的に掃除しないと古いインシデントの文脈が新しい対応に混ざってしまいそうな懸念があります。独自の仕組みを別途構築している可能性もありそうです。
モデル選択はユースケース次第

「どのモデル使ってるの?」とよく聞かれるそうですが、Mir氏は「使用するモデルはユースケースが決める」という立場でした。新しいモデルが出るたびに試すが、モデルを差し替えられる柔軟な仕組みが前提になる、というお話です。
- Google CloudのModel Gardenで200以上のモデルを試せる
- PayPalの現在の本番モデルは Gemini 1.5 Pro (推論力とインシデント分析の精度で選定)
- コード変更なしでモデルを差し替え可能
- Vertex AIの評価フレームワークで、精度・ハルシネーション・レイテンシー・コストプロファイリングを、インシデントのトリアージや根本原因分析といったSRE業務で実際に扱うタスクに対して比較
ADKによる開発速度の向上

複数のagentフレームワークを評価し、一部は自前でも作ってみた結果、Google CloudのADK (Agent Development Kit) を採用したとのことでした。PayPalにおける自律SRE agent開発での実測値として以下が紹介されていました。
- 開発時間が60〜70%短縮
- コード量は40〜50%削減
- POCから本番投入まで2〜3週間
この速さの背景として、セッション管理やメモリ管理、永続コンテキスト、親agentから子agentへのタスク振り分け、並列agent実行といったインフラ相当の機能が最初から入っていることが挙げられていました。「自前で各agentを束ねる仕組みを作っていたときはこれらを全部考える必要があったが、もう考えなくていい」と仰っていました。私もADKを使ってagent処理を書いたことがありますが、たしかにシンプルに書ける印象があります。
PayPalのエコシステムとsupervisor agent
PayPalの全体構成としては、以下の通りです。supervisor agentが、検出・コミュニケーション・トリアージ・緩和などの各agentを束ねています。
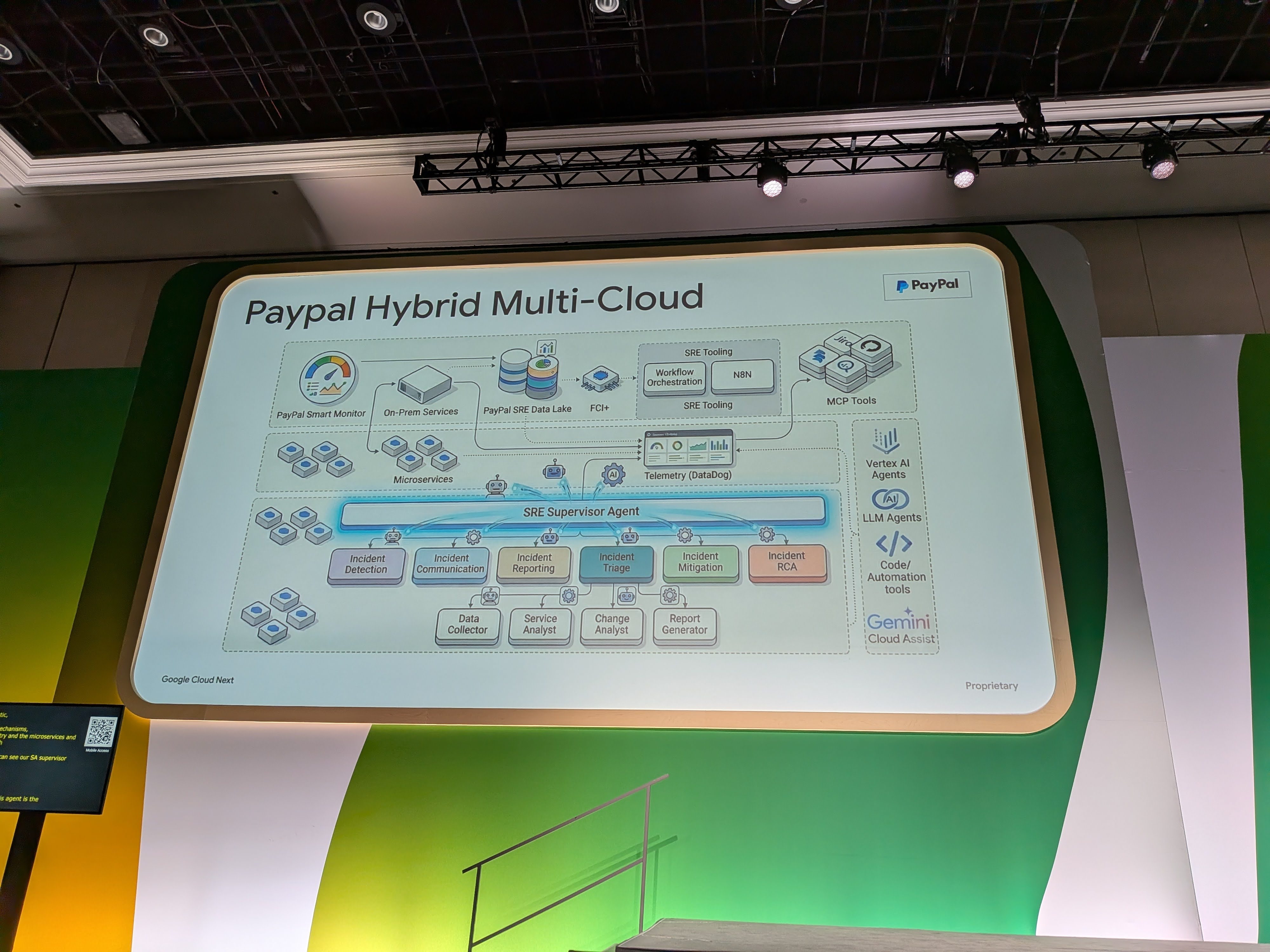
Mir氏は「カンファレンスで見るデモはゼロから作るシナリオ (greenfield) なので見栄えが良いが、PayPalの現実は3,000 microservicesや既存のデータ・アラート基盤がすでに動いている既存環境 (brownfield) で、そこに乗せる必要があった」と、既存システムの上に作る難しさを強調されていました。
Day 2 Operationsの標準機能

agentを作ること自体は、フレームワークが揃ってきたので比較的容易だが、本番に持っていくのが難しい、というお話でした。Google Cloudはagent運用に必要なDay 2 Operations向けの機能を以下のように標準で備えているとのこと。
- agentの動作ログ・メトリクス・トレースを取る可観測性・モニタリングの仕組みが最初から組み込まれている
- agent出力の品質を継続的に評価する仕組みと、トラフィック変動に応じた自動スケール、ワークロードの信頼性確保までが一つの基盤に統合されている
デモ: カオスエンジニアリングツールで異常を注入
デモでは、左側にカオスエンジニアリングツール (game day tool) で異常を注入する画面、右側にSlackチャンネルが表示されていました。流れは以下のとおりです。
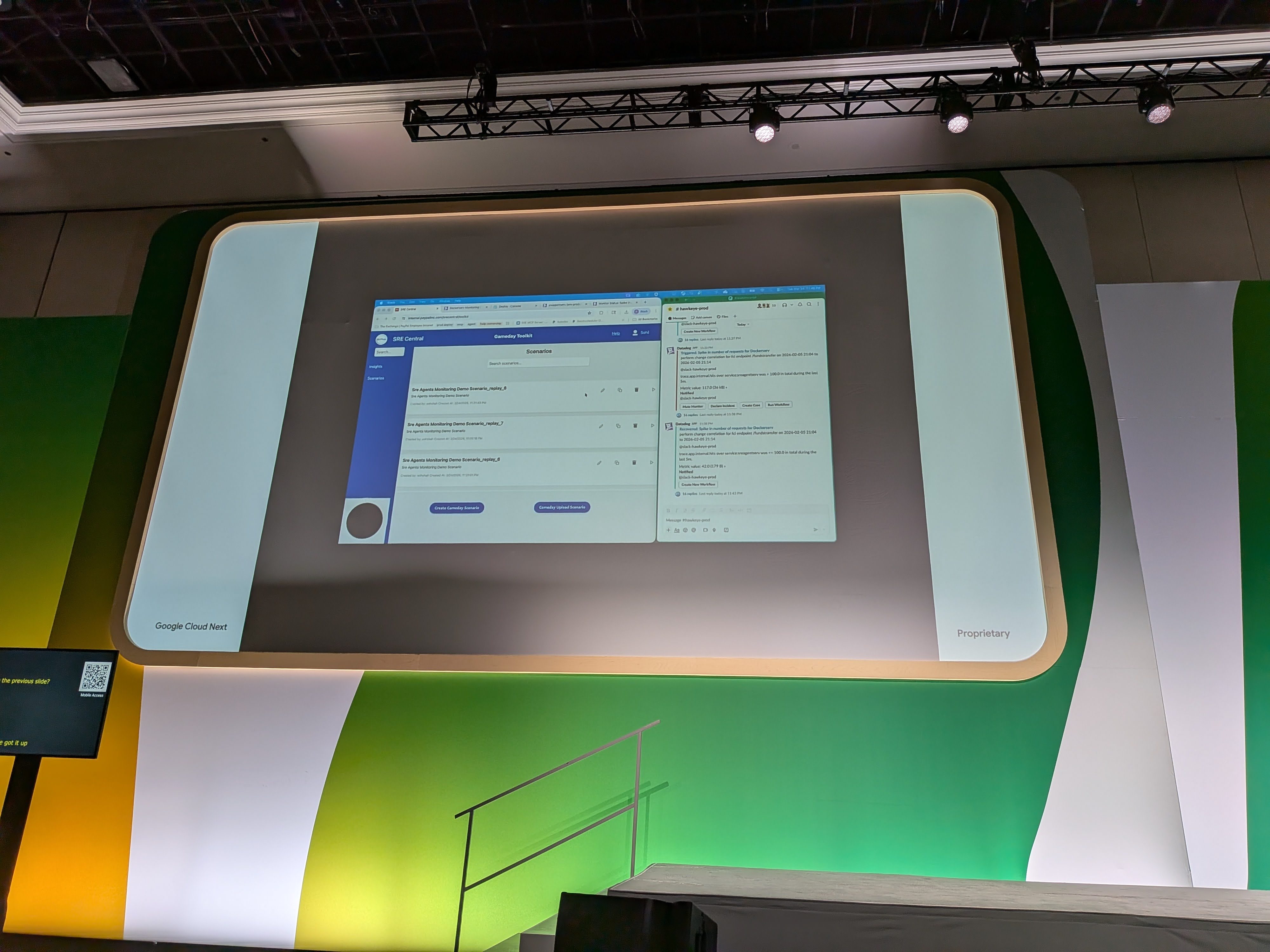
- 異常を注入するとDatadogが検知し、閾値を超えるとSlackにアラートが届く
- supervisor agentがメッセージを拾い、investigator agentとdata collector agentを起動
- data collector agentがPayPal内の各データソースから情報を集め、service analyst agentへ渡す
- service analyst agentが上流・下流サービスを洗い出し、障害の影響範囲を特定
- change analyst agentがその時間帯に入った本番変更の中から原因候補を特定
- mitigator agentが該当サービスに登録された運用手順 (SOP / ITR) の中から今回の異常と合致するものを実行 (デモではテストサービスの再起動が実行)
- reporting agentがレポートを生成し、communications agentが関係者 (役員・顧客など) へ連絡してインシデントをクローズ
「SREの未来は自律的になっていくが、それは仕事を奪うことを意味しない。繰り返し作業を肩代わりしてくれるので、夜中2時に起きて『これは誤報なのか本物なのか』を切り分けるために眠れなくなる必要はなくなる」という締めくくりでした。デモを通してどのくらいの粒度でagentを作っているのかが具体的に理解できましたし、ここまで障害対応を自律的にやれているのは素直にすごいなと思いました。
1,000 agent時代のガバナンスとgolden path
続いて、Google CloudのAfrina氏から、agentを責任を持って本番運用するための話に移りました。
"戻ってくるインターン"を1,000人マネジメントすると考える
Afrina氏は、1,000 agent (あるいは10,000、20,000) が動く世界を想像してほしい、と切り出されました。新入社員が組織に受け入れられる (オンボードされる) ときと同じことをagentにも考えないといけない、というお話です。
- オンボーディングプロセス: 新入社員にいきなり社内のすべての鍵を渡して「どこでも好きに動いていいよ」とはしないのと同じで、agentにも段階を踏んだ受け入れが必要
- ビルディングセキュリティ (バッジ・キーカードアクセス): 入退館記録の概念、立入制限区域の存在
- 組織図: なぜそのagentが起動されたか、目的は何か、誰と会話しているか、の可視性
- タイムシートと人事評価: agentが良い判断をしているか、ハルシネーションを起こしていないかをチェックする
Agent Governanceの4つの柱
これらを実現する概念として Agent Governance があり、4つの柱で構成されるとのことでした。単なる比喩ではなく、それぞれが具体的な制御ポイントを持っています。
- Agent Security: バッジに相当する部分。agent自身のIDとクレデンシャル管理、呼び出し元の認証・認可を担う
- Agent Gateway: オンボーディングプロセスに相当。agentが外部サービスやtool、他agentへアクセスする際の経路を一本化し、どこへ出ていいか・何を呼んでいいかを制御する
- Identity and Registry: 組織図に相当。どのagentが誰によって・何の目的で登録されたかを一元管理し、誰と誰が会話できるかを明示する
- Observability: 人事評価に相当。各agentの入出力、tool呼び出しの軌跡、ハルシネーション発生の検知、判断の良し悪しをログ・メトリクスとして可視化する
「数万台のagentにスケールさせるなら、この4つを整えるのがコア」とのことでした。
非標準の道と可観測性後回し問題

各チームがIDE・フレームワーク・評価ツールなどを個別に選んで組み合わせると、社内でガバナンスが効かなくなるという課題が指摘されていました。実際、多くの組織が 非標準化された道 を選んでしまう、とのことです。
- Click-Ops: 自動化された再現可能なプロセスではなく、GUIで手動設定してしまう。4つのガバナンスもポチポチ設定で組み上げてしまうイメージ
- Lack of visibility: 可観測性を後回しにしがち。agent呼び出しのトレース取得、実行状況のトラッキング、ランタイム攻撃からの保護、有害コンテンツ (プロンプトインジェクションや不適切出力) のブロックといった要素を事前に考えない
- Agent sprawl: agentが無秩序に増えて制御もポリシー設定もできなくなる。「うちには3,000 agentあるけどどう見る? どう管理する?」という相談が、カンファレンス中にも多数寄せられていたとのこと
Golden Path: シンプルで"退屈"な標準経路
解決策として提唱されていたのが Golden Path です。Afrina氏曰く「golden pathはシンプルで退屈な道で、それゆえにagentのデプロイが標準化され、ワンクリックで完了するようになる」とのことでした。
golden pathを作る上でのポイントは、「agentを構築する人がやるべきこと」と「そうでないこと」を切り分けることです。ガバナンスの4つの柱は、自律型agentでもマーケティング用agentでも業務処理用agentでも共通して必要になるので、agent builder(開発者)が毎回設定する必要はなく、プラットフォーム側に寄せるべき、という考え方でした。
構築ステップは以下の3ステップです。

- ランタイムの選択: ランタイムの選択肢は複数ある。エンタープライズとビジネスに合うものを選ぶ
- インフラデプロイメントテンプレートの作成とガバナンスの埋め込み: ここがgolden path作成の肝で、一度だけやる作業
- テンプレートをagent builder(開発者)に配布: 同じテンプレートを使い回して何台でもデプロイできるようにする
これをやると、デプロイと同時に可視性、何をしているかの制御、ランタイム攻撃への対応といったものが標準で手に入ります。SecOpsチーム・ガバナンスチーム・コンプライアンスチームが対処すべき情報もそのまま取得できる、とのことでした。
Application Design Center (ADC)
golden pathを実現するGoogle CloudネイティブのツールとしてAfrina氏が紹介されたのが Application Design Center (ADC) です。
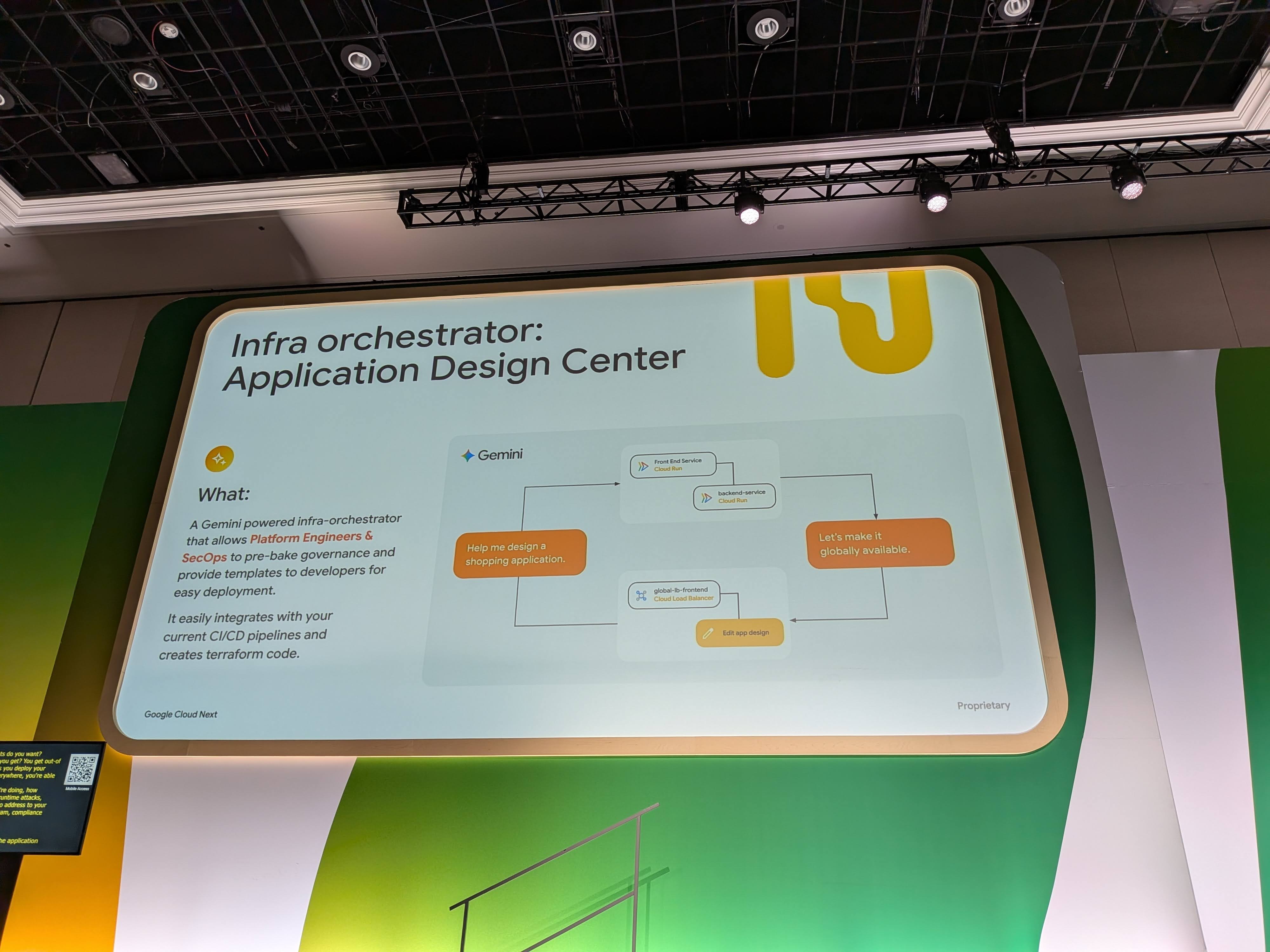
役割分担としては、
- SecOpsやプラットフォームエンジニア・SREが先にADCに入り、自社のインフラに合ったデプロイメントテンプレートを作成する
- その後、agent builderがそのテンプレートを使ってagentロジックを流し込むだけで本番デプロイまで到達する
となります。「これで開発者は本番投入の妨げではなくなり、誰もが本番に押し出せるgolden pathが整う」というのがメッセージでした。
ADCの主な機能はこちらです。

- 複数のデプロイメントアーキテクチャ: マーケティング用agent、SRE用agentなど用途別に異なるアーキテクチャテンプレート (ランタイム構成・ネットワーク・IAM設定を含む) を複数保持し、agentの種類に応じて選択できる
- ポリシー管理: 各agentにどのGoogle Cloudサービスへのアクセス権を持たせるか、どのagent・toolと会話させるか / させないかを、Agent Gateway側とテンプレート側で宣言的に制御できる。agent builderは機密データ保護やセキュリティポリシーなどの非機能要件を個別に実装する必要がない
- セルフサービスポータル: プラットフォームチームが承認のボトルネックにならないよう、開発者が自分でテンプレートを選び、agentロジックを流し込んで本番デプロイまで到達できる
想定利用者はアーキテクト・プラットフォームエンジニア・SecOps・開発者、つまりagentを構築しデプロイしたい人全員が対象、とのお話でした。
まとめ
- PayPalはSRE現場の繰り返し作業とコンテキストロスを解消するために、自律SRE agentをVertex AIとADKで構築し、POCから2〜3週間で本番投入した
- agent構築の鍵は Models / Context / Tooling の3要素。とりわけ既存のデータソースをMCPで束ねて "一箇所で叩ける" 状態にすることが実用性を大きく押し上げた
- supervisor agentを中心に、data collector / service analyst / change analyst / mitigator / reporting / communicationsの各agentが並列・直列を組み合わせて、インシデントの検出から緩和・報告まで完結させる
- agentを1,000台単位で運用するには Agent Security / Agent Gateway / Identity and Registry / Observability の4つのガバナンスが不可欠
- Application Design Centerで、ガバナンスを埋め込んだデプロイメントテンプレートを一度作っておけば、agent builderはロジックだけ乗せて本番まで到達できる (golden path)
所感
- Agent Governanceの4つの柱 (Security / Gateway / Identity and Registry / Observability) は、そのままチェックリストとしても使えそうだなと感じました。もしAI agentを作る案件があれば、まずこの4観点を考え方のベースに置いてみたいです
- Application Design Centerについては、初めて知りました。エージェントデプロイをテンプレート化できるのは良さそうなので自分でも触ってみたいです。
以上、とーちでした。








