Prismaのシャドウデータベースの動作を確認してみる
はじめに
Prismaを使用してデータベースをマイグレーションする際、シャドウデータベースという一時的なデータベースが作成されます。通常、特に指定しなくてもPrismaが自動的に処理しますが、手動でシャドウデータベースの接続文字列を指定することもできます。この記事ではシャドウデータベースを明示的に作成し、どのような動きをするのか確認してみました。
Prismaのシャドウデータベースとは?
シャドウデータベースは、マイグレーションの際に一時的に作成される、メインのデータベースとは別のデータベースです。シャドウデータベースで現在のマイグレーション状態を再現し、作成したいスキーマとの差分を計算することでマイグレーションファイルを作成します。
この仕組みにより、マイグレーション履歴に不整合がないか、データロスが発生しないかどうか等の問題を、メインのデータベースに適用する前に検知できます。
シャドウデータベースは開発環境へのマイグレーション(prisma migrate dev)を行うときに一時的に作成されるもので、本番環境には必要ありません。
詳しくは、公式サイトに解説がありますので、そちらをご覧ください。
データベースの作成
dockerを使って簡単に構築します。メインのデータベース用とシャドウデータベース用のコンテナを用意します。
version: '3'
volumes:
prisma-main-db-volume:
prisma-shadow-db-volume:
services:
prisma-main-db:
image: postgres:17.0-alpine
ports:
- 5440:5432
environment:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
TZ: 'Asia/Tokyo'
volumes:
- prisma-main-db-volume:/var/lib/postgresql/data
prisma-shadow-db:
image: postgres:17.0-alpine
ports:
- 5441:5432
environment:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
TZ: 'Asia/Tokyo'
volumes:
- prisma-shadow-db-volume:/var/lib/postgresql/data
SQLクライアントから接続します。
Prismaのインストールと設定
Prismaをインストールします。今回はマイグレーションの確認のみなので、Prismaクライアントはインストールしていません。
npm install prisma --save-dev
以下のコマンドを実行し、初期セットアップをします。
npx prisma init --datasource-provider postgresql --output ../generated/prisma
prisma/schema.prismaファイルが作成されるので、以下のようにshadowDatabaseUrlを追加します。
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
shadowDatabaseUrl = env("SHADOW_DATABASE_URL")
}
.envファイルに接続文字列の設定をします。
DATABASE_URL="postgresql://test:test@127.0.0.1:5440/postgres?schema=public"
SHADOW_DATABASE_URL="postgresql://test:test@127.0.0.1:5441/postgres?schema=public"
マイグレーション実行
新規テーブル作成
まずはテーブルを作成します。
prisma/schema.prismaファイルに以下のモデルを記述します。
model users {
id Int @id @default(autoincrement())
name String @db.VarChar(100)
email String @unique @db.VarChar(255)
age Int
created_at DateTime? @default(now()) @db.Timestamp(6)
}
以下のコマンドを実行し、マイグレーションをします。マイグレーションの名前を聞かれるので、任意の名前を入力します。
npx prisma migrate dev
prisma/migrationsフォルダに新しいフォルダが作成されます。フォルダ内のmigrations.sqlは以下のようになっています。
-- CreateTable
CREATE TABLE "public"."users" (
"id" SERIAL NOT NULL,
"name" VARCHAR(100) NOT NULL,
"email" VARCHAR(255) NOT NULL,
"age" INTEGER NOT NULL,
"created_at" TIMESTAMP(6) DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT "users_pkey" PRIMARY KEY ("id")
);
-- CreateIndex
CREATE UNIQUE INDEX "users_email_key" ON "public"."users"("email");
SQLクライアントで見ると、メインのデータベースには作成したusersテーブルと、マイグレーション履歴を管理する_prisma_migrationsテーブルが作成されています。
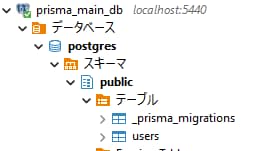
シャドウデータベースにはテーブルは作成されていません。
列を追加
新しい列を追加してみます。
prisma/schema.prismaファイルで、usersテーブルにis_validated列を追加します。
model users {
id Int @id @default(autoincrement())
name String @db.VarChar(100)
email String @unique @db.VarChar(255)
age Int
is_validated Boolean
created_at DateTime? @default(now()) @db.Timestamp(6)
}
以下のマイグレーションファイルが作成されます。
/*
Warnings:
- Added the required column `is_validated` to the `users` table without a default value. This is not possible if the table is not empty.
*/
-- AlterTable
ALTER TABLE "public"."users" ADD COLUMN "is_validated" BOOLEAN NOT NULL;
メインデータベースのusersテーブルにis_validated列が追加されているのが確認できます。

メインデータベースの_prisma_migrationsテーブルにも履歴が登録されています。

シャドウデータベースにはusersテーブルが作られていますが、is_validated列はありません。

他の開発メンバーが作成したマイグレーションがある状態でマイグレーションする
自分の開発用データベースにはis_validated列の追加までの履歴が適用済みです。その状態でmainブランチを取り込み、他の開発メンバーが作成したaddress列追加のマイグレーションファイルがプロジェクトフォルダに追加されたという状況を考えます。
まず、mainブランチから取り込んだことにするために、schema.prisma にaddress列を追加します。
model users {
id Int @id @default(autoincrement())
name String @db.VarChar(100)
email String @unique @db.VarChar(255)
age Int
is_validated Boolean @default(false)
address String?
created_at DateTime? @default(now()) @db.Timestamp(6)
}
mainブランチから取り込んだだけなので、マイグレーションファイルは存在しているものの、自分の開発用データベースには適用されていないはずです。そのため、以下のコマンドを実行し、マイグレーションファイルの作成のみを行います。(データベースへの適用はされません)
npx prisma migrate dev --create-only
これで「mainブランチを取り込んだ結果、他の開発メンバーが作ったマイグレーションファイルがプロジェクトフォルダに存在する状態」を再現できました。
この状態でusersテーブルに更にheight列を追加します。(usersが一体何を管理しているテーブルなのかよく分からなくなってきました)
model users {
id Int @id @default(autoincrement())
name String @db.VarChar(100)
email String @unique @db.VarChar(255)
age Int
is_validated Boolean @default(false)
address String?
height Int?
created_at DateTime? @default(now()) @db.Timestamp(6)
}
今度はcreate-onlyオプションはつけず、マイグレーションをデータベースに適用させます。
npx prisma migrate dev
メインデータベースのusersテーブルには他の開発メンバーが追加したaddress列と、自分がその後に追加したheight列が存在しています。

シャドウデータベースには、他の開発メンバーが追加したaddress列は存在していますが、height列は存在しません。

シャドウデータベースを手動で変更してみる
シャドウデータベースを手動で変更するとどうなるのでしょうか。
SQLクライアントを利用して、シャドウデータベースのaddress列をaddress_hoge列に変更します。

マイグレーションコマンドを実行すると、手動で変更を加えた列名は元に戻り、先ほど適用したheight列も追加されていました。(スキーマに変更を加えていないため、マイグレーションは作成されません)

マイグレーション履歴を改ざんしてみる
プロジェクトフォルダにある、height列を追加したときのマイグレーションファイルを以下のように書き換えます。
元
-- AlterTable
ALTER TABLE "public"."users" ADD COLUMN "height" INTEGER;
改ざん後
-- AlterTable
ALTER TABLE "public"."users" ADD COLUMN "height_hoge" INTEGER;
マイグレーションを実行すると、ドリフトエラーが検出されます。
- The migration `20250830005127_add_height` was modified after it was applied.
- Drift detected: Your database schema is not in sync with your migration history.
The following is a summary of the differences between the expected database schema given your migrations files, and the actual schema of the database.
It should be understood as the set of changes to get from the expected schema to the actual schema.
[*] Changed the `users` table
[-] Removed column `height_hoge`
[+] Added column `height`
シャドウデータベースのusersテーブルを見ると、height_hoge列が存在しています。シャドウデータベースは、既存のマイグレーションファイルを適用した上で、実際のデータベーススキーマと比較していることが確認できます。

以上のことから、シャドウデータベースはマイグレーション実行前にリセットされ、既存のマイグレーション状態を再現していることがわかります。
補足
Prismaの公式実装
Prismaの実装内には以下の記述があります。
prisma/packages/cli/src/mcp/MCP.ts at main · prisma/prisma
The migrate dev command performs these steps:
- Reruns the existing migration history in the shadow database in order to detect schema drift (edited or deleted migration file, or a manual changes to the database schema)
- Applies pending migrations to the shadow database (for example, new migrations created by colleagues)
- Generates a new migration from any changes you made to the Prisma schema before running migrate dev
- Applies all unapplied migrations to the development database and updates the _prisma_migrations table
- Triggers the generation of artifacts (for example, Prisma Client)`,
AIによる翻訳
migrate dev コマンドは以下の手順を実行します:
1. スキーマドリフトの検出: シャドウデータベースで既存のマイグレーション履歴を再実行し、スキーマドリフト(マイグレーションファイルの編集・削除、またはデータベーススキーマへの手動変更)を検出します
2. 保留中のマイグレーションの適用: シャドウデータベースに保留中のマイグレーション(例:同僚が作成した新しいマイグレーション)を適用します
3. 新しいマイグレーションの生成: migrate dev 実行前にPrismaスキーマに加えた変更から新しいマイグレーションを生成します
4. 開発データベースへの適用: 未適用のすべてのマイグレーションを開発データベースに適用し、_prisma_migrations テーブルを更新します
5. アーティファクトの生成: アーティファクト(例:Prisma Client)の生成をトリガーします
この説明から、シャドウデータベースには
- 前回までに実行済みのマイグレーション(マイグレーションファイルが存在し、
_prisma_migrationsテーブルに履歴が残っている) - 未実行のマイグレーション(マイグレーションファイルは存在しているが、
_prisma_migrationsテーブルに履歴がない)
が適用されることが読み取れ、前セクションで確認した動作とも一致しています。
実行ログの確認
また、マイグレーションコマンドの実行時に以下のように指定することで、デバッグログを出力できます。
DEBUG=prisma:* npx prisma migrate dev
前セクション「他の開発メンバーが作成したマイグレーションがある状態でマイグレーションする」実施時には以下のようなログが出力されます。(抜粋、加工済み)
注意:コメントはPrismaのソースコードを参考に記述しましたが、正確性は保証できません。
ログ
// 各ファイルから必要な情報を読み取り
prisma:getSchema Checking existence of C:\_work\999_test\prisma_shadow_db\schema.prisma +0ms
prisma:getSchema Reading schema from single file C:\_work\999_test\prisma_shadow_db\schema.prisma +1ms
prisma:loadEnv project root found at C:\_work\999_test\prisma_shadow_db\package.json +56ms
prisma:tryLoadEnv Environment variables loaded from C:\_work\999_test\prisma_shadow_db\.env +1ms
// schema.prismaのロード
Prisma schema loaded from prisma\schema.prisma
// シャドウデータベースに接続し、マイグレーション履歴の再現
prisma:schemaEngine:stderr {"fields":{"message":"Connected to an external shadow database."}}
prisma:schemaEngine:stderr {"fields":{"message":"Resetting schema(s)","schemas_to_reset":"[\"public\"]"}}
// メインデータベースに未適用のマイグレーションファイル適用
prisma:schemaEngine:rpc SENDING RPC CALL
{
"method": "applyMigrations",
"params": {
"migrationsList": {
"baseDir": "C:\\_work\\999_test\\prisma_shadow_db\\prisma\\migrations"
},
"migrationDirectories": [
{
"path": "20250830002358_add_users",
"migrationFile": {
"path": "migration.sql"
}
},
{
"path": "20250830003234_add_is_validated",
"migrationFile": {
"path": "migration.sql"
}
},
{
"path": "20250830004731_add_address",
"migrationFile": {
"path": "migration.sql"
}
}
]
}
}
prisma:schemaEngine:stderr {"fields":{"message":"Applying `20250830004731_add_address`"}}
Applying migration `20250830004731_add_address`
The following migration(s) have been applied:
migrations/
└─ 20250830004731_add_address/
└─ migration.sql
// データロスのチェック
prisma:schemaEngine:rpc SENDING RPC CALL {"method":"evaluateDataLoss"}
// チェック結果
prisma:migrate:dev {
"evaluateDataLossResult": {
"migrationSteps": 1,
"unexecutableSteps": [],
"warnings": []
}
} +98ms
// ユーザによるマイグレーション名の入力
√ Enter a name for the new migration: ... add_height
// 今回追加したheight列のマイグレーションファイルを作成
prisma:schemaEngine:rpc SENDING RPC CALL {"method":"createMigration"}
prisma:migrate:dev {
"createMigrationResult": {
"generatedMigrationName": "20250830005127_add_height"
}
} +5ms
// マイグレーションファイルの適用
prisma:schemaEngine:rpc SENDING RPC CALL {"method":"applyMigrations"}
Applying migration `20250830005127_add_height`
ログを確認することで、Prismaが内部でどのような処理を実行しているか詳しく追うことができます。
おわりに
あまりシャドウデータベースを意識することはありませんが、どのような動きをするのかふと気になったため確認してみました。Prismaのマイグレーション機能をより効果的に活用するために、シャドウデータベースの動作を理解しておくことは有用です。
もしも気になる方は、dockerを使って簡単にテスト環境を構築できますので、ご自身で確認してみてください。
この記事がどなたかの参考になれば幸いです。








