
カオスだったprismatixのインフラをTerraformで構成管理できるようにした話
prismatix SREチームの中山です。
この記事は、クラスメソッドのグループ企業であるプリズマティクス株式会社が提供するサービス prismatix の構成管理を改善した記録です。
一言で言えばTerraformで各種クラウドサービスのリソースを管理できるようにしただけなのですが、大変ではあったのでここに書き残そうと思います。
3行まとめ
- マイクロサービスアーキテクチャのサービスにおける構成管理で雑多なツールが利用されておりカオスだった
- Terraformに一本化した
- オペレーションを簡素化でき、認知負荷もある程度下がったことで各種作業のリードタイムが改善
前提
prismatixとは
記事を読んでいただくにあたり、prismatixというサービスがどのような形でサービスを提供しているのか、前提となる情報を共有します。
prismatixは、「会員サービス」、「認証サービス」、「商品管理」、「ポイント管理」など、CRM基盤やECサイトを構成するために必要な機能をAPIとして提供しているサービスです。
顧客が利用したい機能を取捨選択します。
- 認証
- 会員管理
- 商品管理
- 注文
- 決済
- 検索
- ・・・等、全 16 機能
そういったコンセプトのサービスであることも踏まえて、アーキテクチャスタイルとして マイクロサービスアーキテクチャ を採用しています。
詳細は以下のリンク先をご覧ください。
また、顧客別に個別の環境を提供する シングルテナント方式 を採用しています。
そのため、1顧客に対して2つ以上の環境を提供することとなります(本番 + ステージング + α)。
現在は、全体で100近い環境を管理しています。
環境にもよりますが、以下の様な規模感で利用されています。
- ID基盤
- 1顧客で最大 50,000 リクエスト / 分
- EC
- 1顧客で最大 700購入 / 分 のトランザクション
このサービスは、2016年11月から開発をスタートしており(プリズマティクス株式会社の設立)、何度かインフラとして採用するAWSサービスの変更を経て今に至っています。
- Elastic Beanstalk + RDS for MySQL
- ECS on EC2 + Aurora for MySQL
- ECS on Fargate + Aurora for MySQL ← 今ここ
検索サービスに関してはElasticsearchを利用しており、ここも構成が変わっています。
- Amazon Elasticsearch Service
- Elasticsearch on EC2
- Opensearch on EC2 ← 今ここ
アプリケーションには、一貫して Java + Spring が採用されています。
異動したときの状況
私自身は2021年の後半から prismatix に関わるようになり、2022年3月に以前の所属(AWSのコンサル)から正式に異動しました。
異動先のチームは Kiban チームでした。
このチームは、顧客からのリクエストを受けての構成変更やバージョンアップ作業・障害対応や監視業務などを行っています。
異動後、オンボーディングとして環境構築や比較的簡単な構成変更から業務を行うようになりましたが、以下の様な点に課題を感じました。
- 構築手順が長い・細かい
- 構築手順に分岐が多い(例:特定のバージョン以降をデプロイする場合には、この手順を実施する必要あり、等)
- 利用するツールが多い(詳細は後述しますが、Terraform / CloudFormation / Gradle / python / Shell Script / Ruby / Go製の独自ツール など)
- 各手順間の依存関係がわかりにくい
また、ある程度業務に慣れてくるとより高度な作業も実施するようになりました。
これらの業務を通して以下の様な課題を感じました。
- 作業手順の作成が難しい
- ある目的に対して、どの設定を変える必要があるのかがわかりにくく、その設定をどうやって変えたらいいかがわかりにくい
- ある目的に対して、複数の手順を実行する際にどのような順番で実行する必要があるのかもわかりにくい
- 過去の作業手順を参考にすることはできるが、環境によっては踏襲できない場合もある(都度判断が必要 / 実施した実績の無い作業だと準備が大変)
そんな状況もありつつ、一部はAtlantisをGitHubと連携させてTerraformのGitOpsをやっていたりで、すごい不思議な状態でした。
Atlantisに関しては以前にイベントに登壇して紹介しているのでそちらをご覧ください。
異動したタイミングでの私の能力・経験の問題もあったとは思いますが、一言で言うと認知負荷が非常に大きかったです。
様々な課題
これらの状況によって、以下の様な悪影響があったように思います。
- 新たに参加するメンバーのオンボーディングが大変もしくは失敗する
- 入る側ももちろん、受け入れる側の負担も大きい
- 顧客環境に対する作業の実施時には必ず作業手順書を作成するが、その作成者およびレビュアーの負担が大きい
- メンバーの定着や業務の難易度の課題によりお客様からの各種作業依頼にタイムリーに対応できないことがある
改善
こういった背景もあり、2022年7月にSREチームが再発足と併せて抜本的な改善を実施する事になりました。
方針
既存の構成要素のうち、Terraform(Atlantis + GitHub)で管理している部分が最も効率的に扱えていました。
そのため、各種クラウドリソースの構成管理を可能な限りTerraformに一本化することを基本方針としました。
現状把握
まずは現状を把握・整理しました。
冒頭で述べたとおり、シングルテナントなのでお客様からの要望に応じて都度環境を作成します。
その際、環境構築手順書に基づいて作業を実施します。
この環境構築手順書を頼りに現状の構成(理想的な状態・ベースライン)の把握を行いました。
しかし、何の作業をどのような順番で実行する必要があるかは書いてあるものの、手順間の依存関係や実行するように指定されているスクリプトの内容に対する解説はあまりなく、読み解くのに苦労しました。
既存の構築手順を紐解いて図にすると以下の様になっていました (ECS on Fargate + Aurora for MySQL + Elasticsearch on EC2) 。
文字が小さくてスミマセン・・・
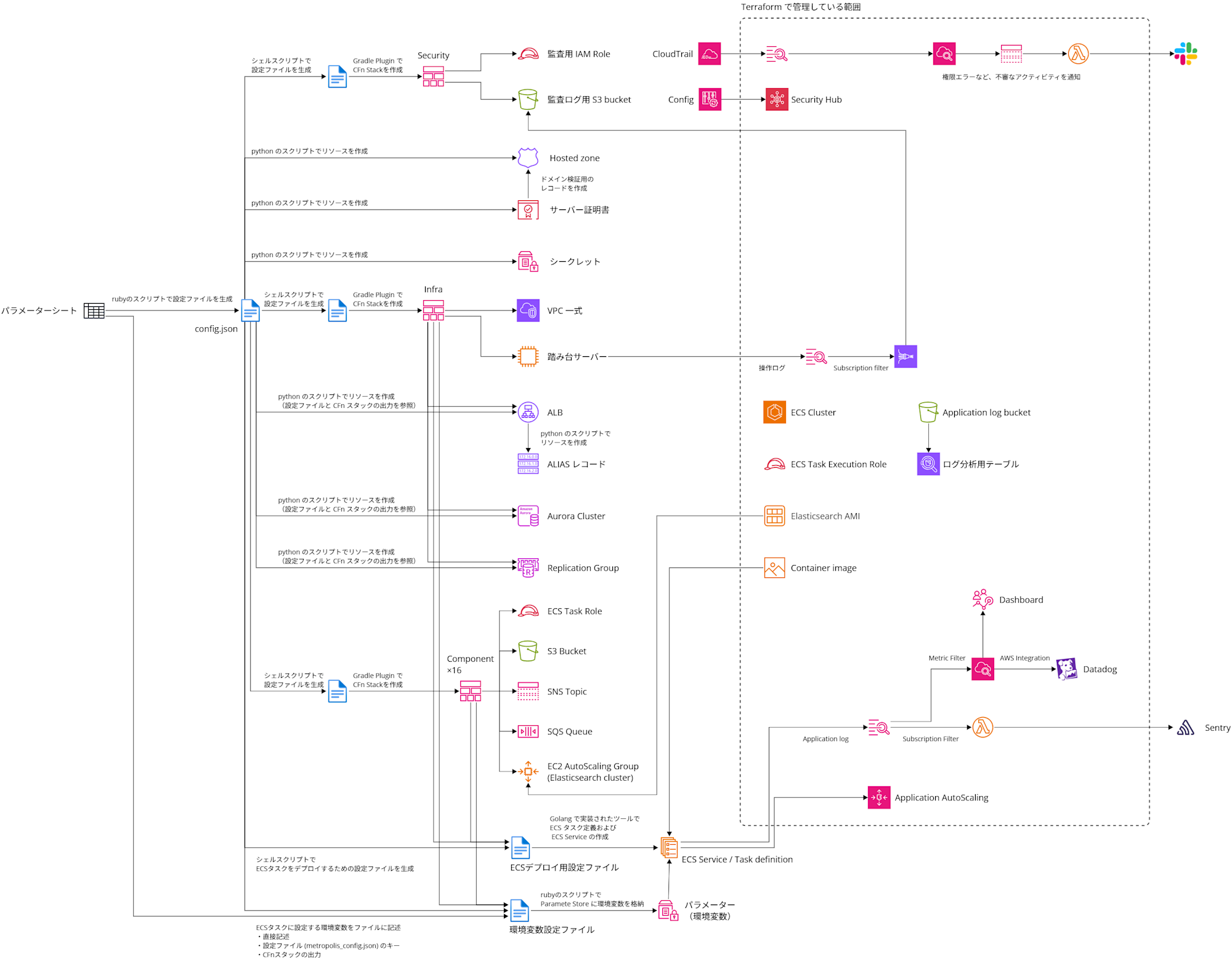
大まかな手順をテキストにまとめると以下の様になります。
大まかな手順
- 顧客要件等を整理したパラメーターシートに基づいてconfig.jsonファイルを生成
- rubyのスクリプトを利用
- 共通で利用するAMIやECR等へのアクセス権を付与
- Terraformを利用
- セキュリティ設定を作成
- 独自のGradle Pluginを利用したCloudFormationによるデプロイ
- 事前にGradle用の設定ファイルを生成
config.jsonを参照して生成
- Hosted zoneやACMのサーバー証明書を作成
- pythonのスクリプトを利用
- スクリプトが
config.jsonを参照
- スクリプトが
- pythonのスクリプトを利用
- 各種シークレットを生成
- pythonのスクリプトを利用
- スクリプトが
config.jsonを参照
- スクリプトが
- pythonのスクリプトを利用
- VPCなどネットワーク系リソース一式を作成
- 独自のGradle Pluginを利用したCloudFormationによるデプロイ
- 事前にGradle用の設定ファイルを生成
config.jsonを参照して生成
- 以降、Infraスタックと呼称
- ALB等のリソースを作成
- pythonのスクリプトを利用
- スクリプトが
config.jsonを参照 - InfraスタックのOutputも参照
- スクリプトが
- pythonのスクリプトを利用
- Aurora Cluster一式を作成
- pythonのスクリプトを利用
- スクリプトが
config.jsonを参照 - InfraスタックのOutputも参照
- スクリプトが
- pythonのスクリプトを利用
- Replication Group(Elasticache)一式を作成
- pythonのスクリプトを利用
- スクリプトが
config.jsonを参照 - InfraスタックのOutputも参照
- スクリプトが
- pythonのスクリプトを利用
- 各マイクロサービスコンポーネントを構成するリソースを作成(ECSのリソースは除く)
- 独自のGradle Pluginを利用したCloudFormationによるデプロイ
- 事前にGradle用の設定ファイルを生成
config.jsonを参照して生成
- 全16種類のコンポーネントのうち、必要なものを選択してデプロイ
- 以降、Componentスタックと呼称
- 環境変数をSSM Parameter Storeに格納
- 顧客要件等を整理したパラメーターシートに基づいて設定ファイルを作成
- 値は「設定ファイルに直接記述」、「CloudFormationスタックの出力」、「
config.jsonのキー」として記述できる
- 値は「設定ファイルに直接記述」、「CloudFormationスタックの出力」、「
- rubyのスクリプトを利用してリソースを作成
- 設定ファイルに基づいて、CloudFormationスタックの出力や
config.jsonから値を取得し、リソース(パラメーターストア)を作成
- 設定ファイルに基づいて、CloudFormationスタックの出力や
- 顧客要件等を整理したパラメーターシートに基づいて設定ファイルを作成
- ECS Clusterを作成
- Terraformを利用して作成
- ECSタスクのデプロイ
- Golangで実装された独自デプロイツールを利用
- デプロイの前に設定ファイルを生成
- シェルスクリプトで生成
config.jsonやInfra・Componentスタックの出力も参照する
- 作成した設定ファイルとSSM Parameter Storeの値を利用してECSタスク定義およびECS Serviceを作成
- そのほかのリソースをTerraformを利用して作成
- 以下の様なリソースを作成
- Athenaによるログ検索設定
- ECSのAutoScaling設定
- ログ監視のための設定
- 不審なアクティビティを検知するためのリソース一式
- Security Hub
- その他・・・
- 目的ごとにTerraform moduleを実装している
- 以下の様なリソースを作成
長いので折りたたんでいますが、これでも細かいところは割愛しています。
とりあえず、なんかやばそうってことが伝われば幸いです。
手順(実行するスクリプト)が細切れで複雑になっていますし、利用するツールが多岐にわたっています。
利用されていたツール / 言語は以下の通りでした。
- ruby
- python
- shell script
- Gradle Plugin / CloudFormation
- golang
- Terraform (Atlantis + GitHub)
- Ansible
- 踏み台サーバー等の構成管理で利用
整理してみると、主要なリソースがTerraform以外で作成され、そのほかの周辺設定でTerraformが利用されていることがわかります。
推測ですが、
- 必要に迫られて一旦仕組みを作った(そのときの担当者の裁量で)
- 後で全体を改善したくても時間が無くて対応できなかった
- さらに変更が発生
- 後で改善するには複雑すぎ
みたいな感じでこうなったのでしょうか・・・あくまでも推測ですが・・・
仕組みが複雑なのも問題なのですが、一部のスクリプトやツール(特にruby/golang/Gradle Plugin)は作成者が異動・退職しており、実質メンテナンスが困難な状態になっていました。
一応安定して動いてはいたものの、何か致命的な問題が発生したら迅速に対応できない可能性が非常に高い状態でした。
Terraform moduleの実装
どのようなAWSリソースがどのような順番で作成されているかは一応把握できました。
その結果を踏まえ、すでにTerraformで管理されているAWSリソースも含めて、Terraformで一元管理できるようにします。
そのためにTerraform moduleを実装しました。
リソースの役割やライフサイクルなどを考慮し、以下の様な感じでモジュールを分けることとしました。
(厳密にはもう少し細かいですが、主要なものは以下の通り)
- セキュリティモジュール
- 全環境でほぼ共通(AWSアカウントのセキュリティ)
- 変更頻度は非常に少ない
- インフラモジュール
- 利用する機能から横断的に利用するリソース全般(ネットワークやマネジメントサービスのリソース)
- 変更頻度は少ないが、アプリケーションの機能追加などに併せてリソースの追加・変更・削除の可能性がある
- データストアモジュール
- 各マイクロサービスから横断的に利用されるデータストア(Aurora)
- 変更頻度は少ないが、アプリケーションの機能追加などに併せてリソースの追加・変更・削除の可能性がある
- AuroraのエンジンバージョンのEOLに伴う変更もある
- マイクロサービスコンポーネントモジュール
- 各マイクロサービスで利用するAWSリソース(1つのマイクロサービスで専有)
- 全16種類のマイクロサービス毎に定義
- 顧客要件に応じた環境変数の変更やイベントに合わせたスケーリングなど、変更頻度は高め
- その他モジュール群
- 検索機能のためにElasticsearchのクラスターを構成している。検索機能の一部としてモジュールに組み込むことも考えたが、クラスターのB/Gデプロイのために独立したモジュールとして実装
図にすると以下の通りです(細かいモジュール群は割愛しています)。
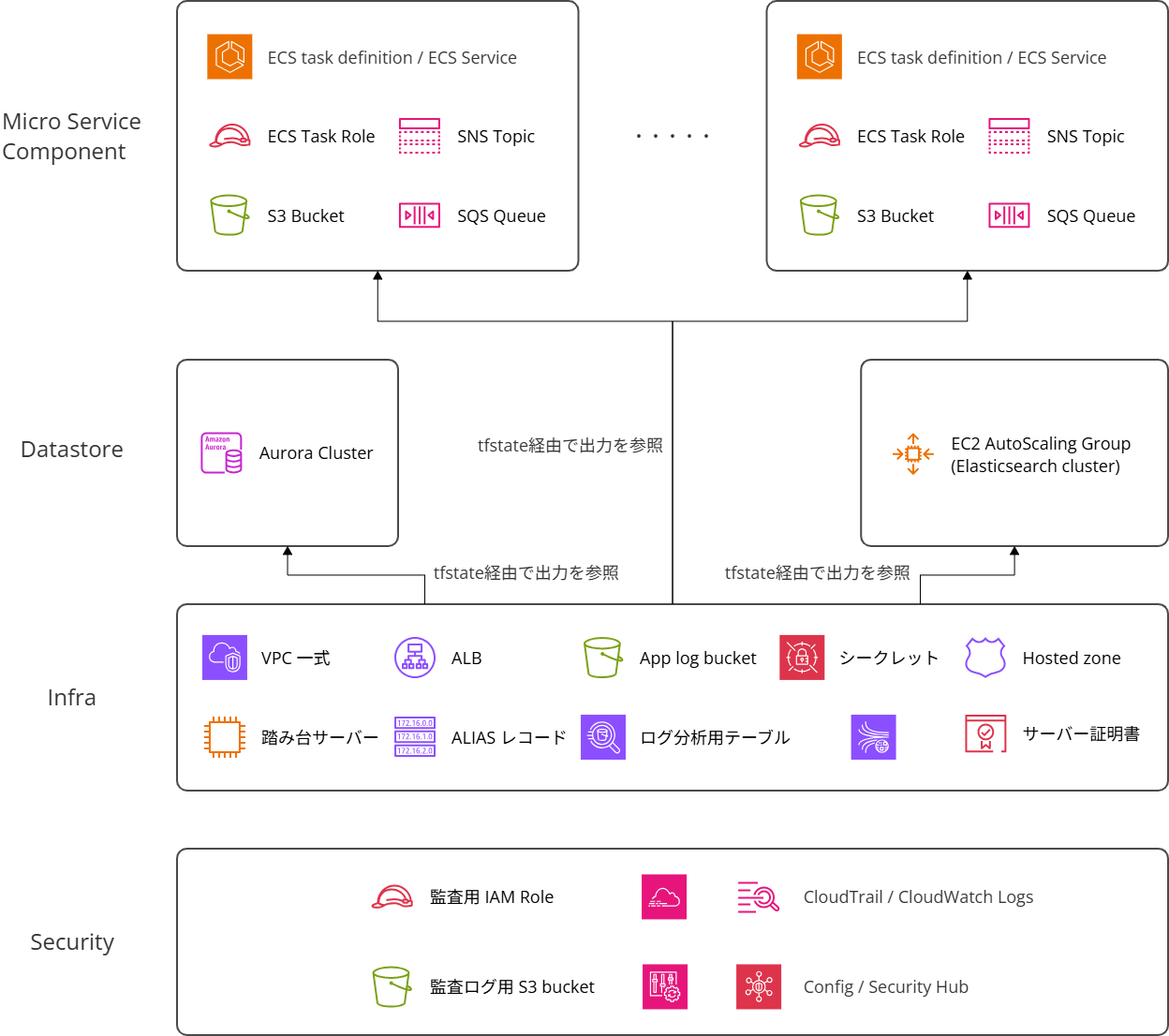
このような感じで、これまでTerraformで管理されていなかったリソースを中心にTerraformで管理されていたリソースも含めて各Terraform moduleに整理・統合していきました。
CloudFormationテンプレートやスクリプトで構築していたので、基本的にはそのまま移植するだけなのでコーディング作業自体は容易でした。
基本的には単純移行なのですが、少し工夫したポイントがあるので紹介します。
ECSタスクのデプロイ
ECS関連の設定は独自のツールでデプロイしていたため、実環境の設定内容を確認してTerraform化しました。
環境変数に関しては、サービスとして設定が必須のものと任意のものがあり、前者はECSタスク定義内に直接設定 / 後者はS3ファイル上に記述するようにしました。
顧客の要件に応じて設定するものは後者で設定することになります。
S3オブジェクト自体もTerraformで管理しています。
ちなみに、同じ環境変数をタスク定義とS3の両方で設定した場合、タスク定義側の設定が優先される仕様なので留意する必要があります。
If there are individual environment variables specified in the container definition, they take precedence over the variables contained within an environment file.
Amazon ECS task definition parameters for the Fargate launch type
Secrets Manager
各種シークレットはこれまでSSM Parameter Storeで管理していましたが、このタイミングでSecrets Managerでの管理に移行しました。
具体的にどのような構成にしているかの言及は避けますが、秘匿すべき情報のTerraformでの管理については、以下の資料が非常に参考になります。
控えめに言ってこの資料は最高です。
リソースのインポートを前提とした実装
当然ながら、既存のリソースを(原則)リプレースさせることなくインポートする必要があります。
そのため、リソース名などはモジュール変数で指定できるようにする必要があります。
かといって、新規構築時に全部指定されるのも手間です。
そのため、変数には適切なデフォルト値を設定しました。
新規環境構築手順の作成・検証
Terraform moduleの利用を前提とした新規環境の構築手順を作成しました。
従来の手順で複数の手順に横断して作成していたリソースを整理したTerraform moduleで作成できるようになったため、全体の手順はそれなりにシンプルになりました。
具体的には、従来は最大32のステップで構築手順が構成されていましたが、これが22になりました。
もう少し減らしたいのですが、既存の1スクリプト(1ステップ)において複数のことをやっていたり(Gradleで特定のマイクロサービス向けのCFnスタックを作成 + DBのマイグレーションを実行、等)見通しが悪い手順を分割・整理したのでこうなりました。
.tf ファイルの生成には envsubst コマンドを利用して容易に生成できるようテンプレートも用意しました。
以下の様なイメージで要件に合わせて環境変数を設定の上でコマンドを実行し、.tfファイルを生成できるようにしています(実際のものをかなり簡略化しています)。
module "${ENV_NAME}-infra" {
providers = {
aws = aws.${ENV_NAME}
}
source = "git::https://github.com/${ORG_NAME}/${REPO_NAME}//prismatix/infra?ref=${TAG}"
env_name = "${ENV_NAME}"
log_bucket_name = data.terraform_remote_state.security_settings.outputs.${ENV_NAME}-log_bucket_name
alb_public_hosted_zone_id = data.terraform_remote_state.route53.outputs.${ENV_NAME}-zone_id
alb_domain_name = "${DOMAIN_NAME}"
}
data "terraform_remote_state" "route53" {
backend = "s3"
config = {
bucket = "${TFSTATE_BUCKET}"
key = "route53/${ENV_TYPE}.tfstate"
region = "ap-northeast-1"
}
}
data "terraform_remote_state" "security_settings" {
backend = "s3"
config = {
bucket = "${TFSTATE_BUCKET}"
key = "security_settings/${ENV_TYPE}.tfstate"
region = "ap-northeast-1"
}
}
export ENV_NAME="environment"
export ENV_TYPE="development"
export ORG_NAME="organization"
export REPO_NAME="terraform-module"
export TAG="0.1"
export DOMAIN_NAME="prismatix.example.com"
export TFSTATE_BUCKET="tfstate-bucket"
envsubst < template.tf > main.tf
前のステップで作成したリソースのID等をモジュールの変数に渡したい場合には、terraform_remote_state を利用します。
社内開発環境の移行
当然ながら、いきなり顧客環境への適応はできないので、まずは社内開発環境を新しい環境に置き換えました。
この作業を通して、Terraform moduleや手順書の改善を行いました。
既存の社内開発環境は利用開始からかなり時間が経過しており、用途がよくわからないリソースや検証時に削除されなかったリソースなどが多数存在しました。
こういった環境においてはterraform importを利用して既存のリソースをインポートすることは難しいので、まずは新規環境を構築し、既存環境のリソースを削除する形で移行しました。
既存環境移行手順の作成・検証
新規環境構築の手順と同じ流れで移行手順を作成しました。
なお、移行に際しては顧客環境を特定のバージョンまでバージョンアップしておくことを前提としました。
これにより、terraform import時のPlan結果をある程度想定しやすくしました。
こちらも細かい手順は割愛しますが、基本的には新規環境構築手順と同じ要領で.tfファイルを生成します。
その際、モジュールには変数を通して既存のリソース名などを設定します。
リソース名は、固定のものもあればCloudFormationでランダムに設定されたものなど様々なパターンがありましたが、いずれもスクリプトを実装して機械的に取得するようにしました。
加えて、既存のリソースをインポートするためのインポートブロックを含む.tfファイルを作成しました。
以下の様なイメージでファイルを作成します。
環境(利用する機能)によりますが、最大で1000近いリソースを管理する必要があり、実際の記述量はもっと膨大です。
# Python等のスクリプトで作成したリソースのIDやARNを取得
export ALB_NAME=$(aws elbv2 describe-load-balancers \
--query "LoadBalancers[?contains(LoadBalancerName,\`prismatix-alb\`)].LoadBalancerName" \
--output text); echo "ALB_NAME: ${ALB_NAME}"
export ALB_ARN=$(aws elbv2 describe-load-balancers \
--query "LoadBalancers[?contains(LoadBalancerName,\`prismatix-alb\`)].LoadBalancerArn" \
--output text); echo "ALB_ARN: ${ALB_ARN}"
# 独自のGradle Pluginを利用して作成したリソースはCloudFormationスタックを参照してリソースのIDやARNを取得
export CFN_ALB_LOG_BUCKET=$(aws cloudformation describe-stack-resource \
--stack-name infra \
--logical-resource-id LogBucket \
--query StackResourceDetail.PhysicalResourceId \
--output text); echo "CFN_ALB_LOG_BUCKET: ${CFN_ALB_LOG_BUCKET}"
module "${ENV_NAME}-infra" {
providers = {
aws = aws.${ENV_NAME}
}
source = "git::https://github.com/${ORG_NAME}/${REPO_NAME}//prismatix/infra?ref=${TAG}"
env_name = "${ENV_NAME}"
log_bucket_name = data.terraform_remote_state.security_settings.outputs.${ENV_NAME}-log_bucket_name
alb_public_hosted_zone_id = data.terraform_remote_state.route53.outputs.${ENV_NAME}-zone_id
alb_domain_name = "${DOMAIN_NAME}"
alb_log_bucket_name = "${CFN_ALB_LOG_BUCKET}"
alb_name = "${ALB_NAME}"
}
data "terraform_remote_state" "route53" {
backend = "s3"
config = {
bucket = "${TFSTATE_BUCKET}"
key = "route53/${ENV_TYPE}.tfstate"
region = "ap-northeast-1"
}
}
data "terraform_remote_state" "security_settings" {
backend = "s3"
config = {
bucket = "${TFSTATE_BUCKET}"
key = "security_settings/${ENV_TYPE}.tfstate"
region = "ap-northeast-1"
}
}
import {
to = module.${ENV_NAME}-infra.aws_lb.prismatix
id = "${ALB_ARN}"
}
import {
to = module.${ENV_NAME}-infra.aws_s3_bucket.alb_log
id = "${CFN_ALB_LOG_BUCKET}"
}
既存環境の移行
手順に従って既存環境をTerraformの管理下に移行していきます。
まずは手順書の作成および社内環境を利用した手順の検証を行いました。
検証の過程で見つかった考慮不足に関しては、随時Terraform moduleや手順を修正しました。
特に環境変数の設定を正しく移行しないと重大なインシデントになるのでかなり丁寧に確認を行いました。
その後、顧客環境に対しても適用を進めていきました。
ここで見つかった課題に関しても、適宜Terraform moduleや手順を修正していきました。
なお、ECSタスク定義に関してはどうしてもリプレースが伴い、それによってECSタスクの入れ替えが発生します。
そのため、適宜お客様へのアナウンスや必要に応じて作業スケジュールの調整なども行います。
協力いただいたお客様およびメンバーに感謝いたします。
移行手順が確立したこのあたりから、移行作業を加速していくためにチームで作業を進めていくことになりました。
対象環境は100近くあり、一人では対応が難しいためです。
協力してもらえるメンバーに対して随時レクチャーを行い、移行作業を進めていきました。
協力していただきありがとうございました!
ちなみに、既存環境はこの2-3年以内に構築されたものもあれば、6-7年ものあります。
そのため、実際には想定していなかった構成になっている事も多かったです(想像よりは少なかったですが)。
- ElastiCacheでReplication Groupを使っているはずが、Cahche Clusterのままの環境が残っていた。
- 使用しなくなった環境変数が設定されたままになっていた。
- 削除の可否を確認するのがかなり手間でした
- アプリケーションのバージョンアップに伴って廃止された変数かどうかは、application.propertiesや環境変数一覧の履歴等で確認
- 顧客要件の変化に伴うものかどうかは、作業管理チケット等で確認
- 削除の可否を確認するのがかなり手間でした
- 想定外の命名になっているリソースがあった。
- その他・・・
これらの問題について、都度対応方針(現状を維持するのか / あるべき状態に修正するのか)を検討し、Terraform moduleを修正したり移行用のスクリプトを修正したり対象環境の設定を修正するなどしました。
この移行作業は2025年6月頃に一部の例外を残して完了する見込みとなっています。
通常業務も兼務しつつ途中で通常の運用業務が忙しくなって中断するなどしながらも、3年でなんとか完遂できそうです。
ただ・・・達成感が無いわけではないのですが、やはり「なぜここまで時間がかかってしまったのか」という思いも強いです。
移行の効果
今回の移行で以下の様な効果を得ることができました。
- 作業依頼から完了までのリードタイムの短縮
- 環境構築であれば、2~3週間から1週間程度に短縮
- バージョンアップ作業はケースバイケースだが、AWSリソースの操作はほぼTerraformに寄せることができた
- それにより、従来は手順書を書き起こす必要があった作業がGitHubでPull Requestを作成するだけでよいケースが増えた(Terraformによる構成変更は、GitHub + AtlantisでGitOpsを実現済)
- 認知負荷の低減
- Terraform moduleの種類をできるだけ抑え、全体像を把握しやすくした
- Terraform管理外のリソースや設定も明確になった(MySQLやElasticsearchの「中」の設定、等)
- より厳格な構成管理の実現(ドリフトの発生を予防・発見しやすい)
- 構成変更の横展開がしやすい
- 以前は、全環境に対する構成変更を1環境ずつ手作業で実施していたが、1つのPull Requestでまとめて適用する事が可能になった
今回の移行によって、以下の様な新たな課題も発生しました。
- 環境変数をタスク定義とS3オブジェクトの両方で管理するため、仕組みを正しく理解した上でオペレーションを行う必要がある(これまでには無かった「クセ」ができた)
- より多くのオペレーションがTerraform / Atlantisに依存することになり、GitHubやAtlantisサーバーの障害が業務に与える影響が大きくなった
- 1つ1つのTerraform moduleがこれまでより大きくなったので、これらを把握・理解するのは相対的に難しくなった。
しかし、トータルでは圧倒的にプラスの効果が大きいように思います。
これにより、従来はAWS環境に対して何らかの改善しようと思っても変更による影響範囲が読みにくかったり作業工数が大きくなったりして躊躇することが多かったのですが、今後は積極的に改善できそうです(やっとスタートラインに立てた感覚)。
まとめ
まとめます。
- prismatixの構成管理が非常に複雑化しており、運用に支障が出ていた。
- 仕組みを作った当事者がいないケースが多く、「なぜこうなったのか」、「今もこの仕組みが必要なのか」の確認が難しかった。
- 仕組み自体は複雑だったが、手順書やコードはあったのでなんとか現状を把握できた。
- ツールの整理で一定程度の効率化はできた。
- なぜここまで多様なツールを利用・開発するに至ってしまったのか・こんなに複雑化するまで抜本的な課題解決がなされなかった理由は何なのか、振り返り・予防が必要
今回の取り組みを通して、「シンプルにすること」の重要性を痛感しました。
サービスの要求・要件を満たせるのであれば、構成はシンプルにするべきです。
シンプルにすることで認知負荷を下げることができ、積極的な改善もしやすく、新たなメンバーのオンボーディングもスムーズになるでしょう。
また、ドキュメンテーションの重要性も改めて認識しました。
今回は構築手順書がよりどころになりましたが、もっと情報が少なければ今回の件は諦めていたかもしれません。
どんなにシンプルな構成のシステムであっても、どのような要件に基づいて構成を決めたのか、書き残しておくことが重要だと痛感しました。
最後に、この取り組みを通じて「なぜこうなってしまったのか・なぜ(一時的なつもりでも)この方法を選択したのか・なぜここまで課題が積み残されたのか・なぜ・・・」という思いがありました。
体制・予算・緊急度の高いタスクなど、いろんな事情はあったんだと思いますが、さすがに課題を溜めすぎだと思いました。
また、技術選定に関する統制も無かったのではないかと推測しています。
自律性も大事だとは思いますが、もう少しチームのスキルセットも踏まえた選択をしてくれても良かったのではないか、と思わずにはいられません。
技術組織を管理・統制する皆様におかれましては(それ以外の方も)、まずはこういうケースが起こりうるということを知っていただきつつ、定期的に課題の把握と解消を実施してほしいと思う次第です。
現場からは以上です。










