
AWS Glue DataBrewでDatasetをJobで加工してS3 Bucketに出力してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
AWS Glue DataBrewは、ユーザーがコードを記述することなくVisualなコンソールからデータのクリーンアップや正規化を定義して実施できるツールです。
DataBrewの利用では、主に次の要素を操作することになります。
- Dataset:ファイルとしてアップロードされたり、AWSなどのどこかしらに保管され、DataBrewが読み取り専用で接続して処理対象とするデータです。
- Recipe:Datasetに対する処理内容を定義します。
- Job:Datasetに対してRecipeを適用して指定の場所に加工済みデータを出力します。
- Project:Datasetを読み込んでPreviewし、Recipeを作成したりJobを実行するためのコンソールが提供される、DataBrewの利用の中心となる概念です。
今回は、AWS Glue DataBrewの基本的な使い方を学ぶために、DatasetをJobで加工してS3 Bucketに出力する操作を行ってみました。
やってみた
Project作成
Glue DataBrewのコンソールにアクセスします。まずProjectを作成してみます。[Create Project]をクリック。
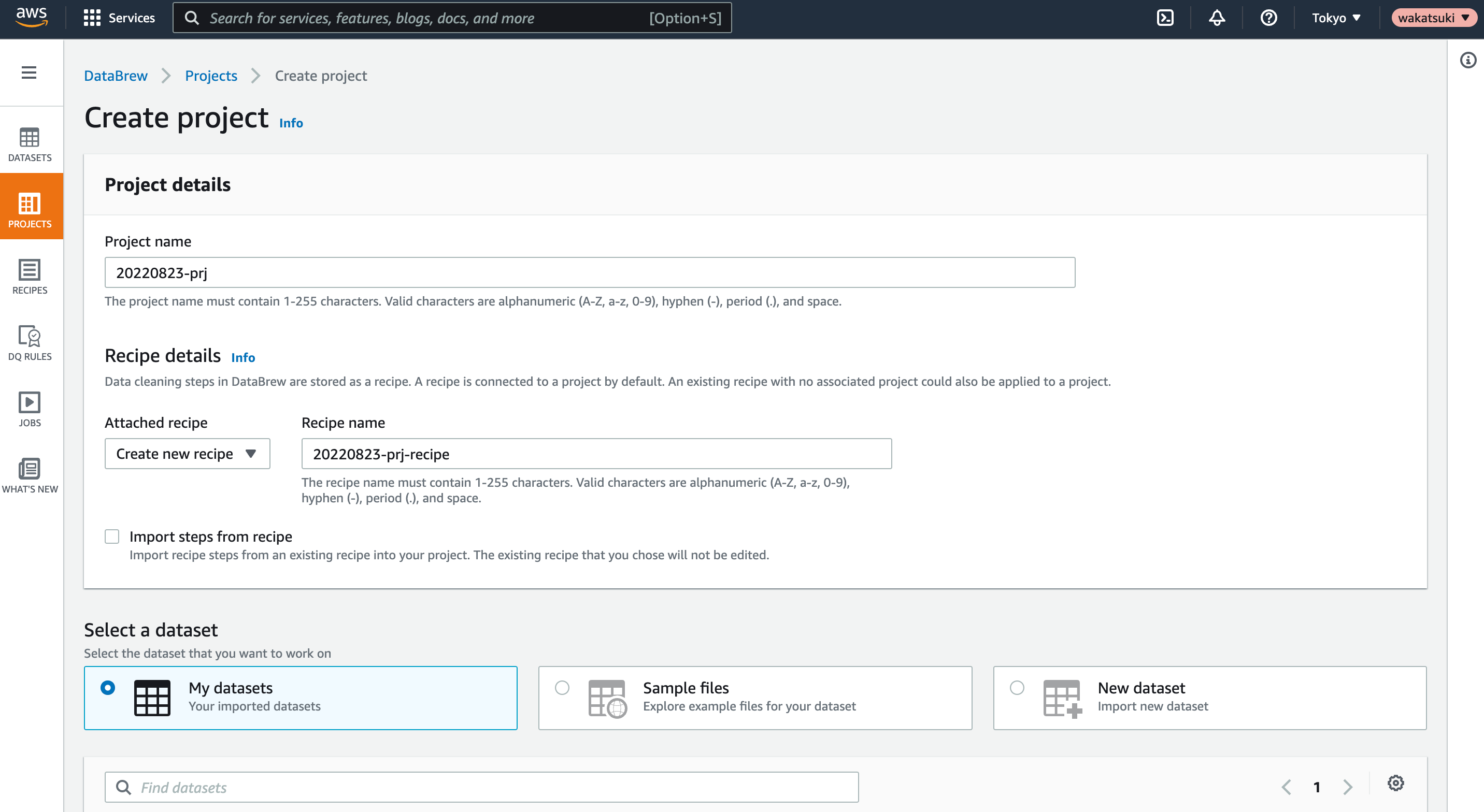
Project名を指定します。Recipeは新規作成されるようにします。
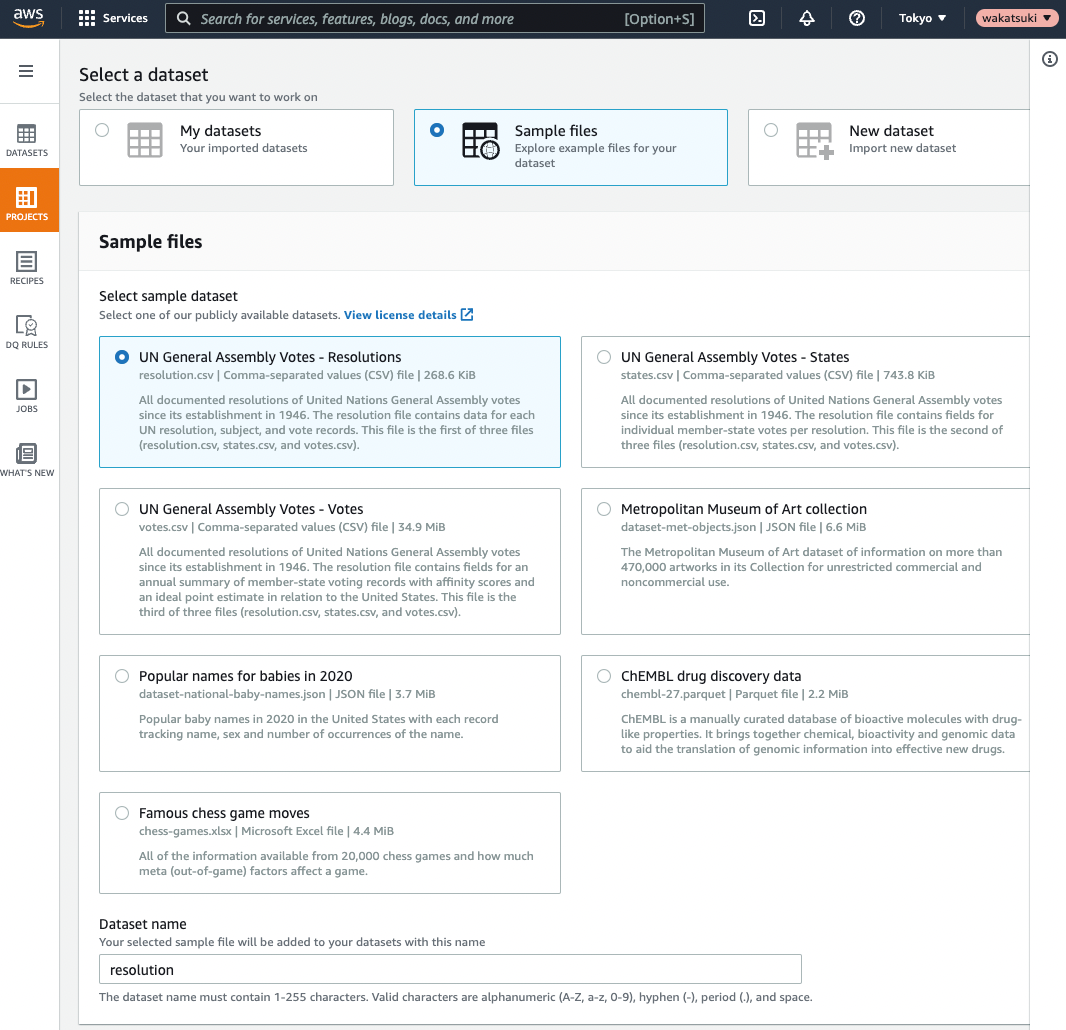
Datasetは検証に便利なサンプルが用意されているので適当なものを使用します。
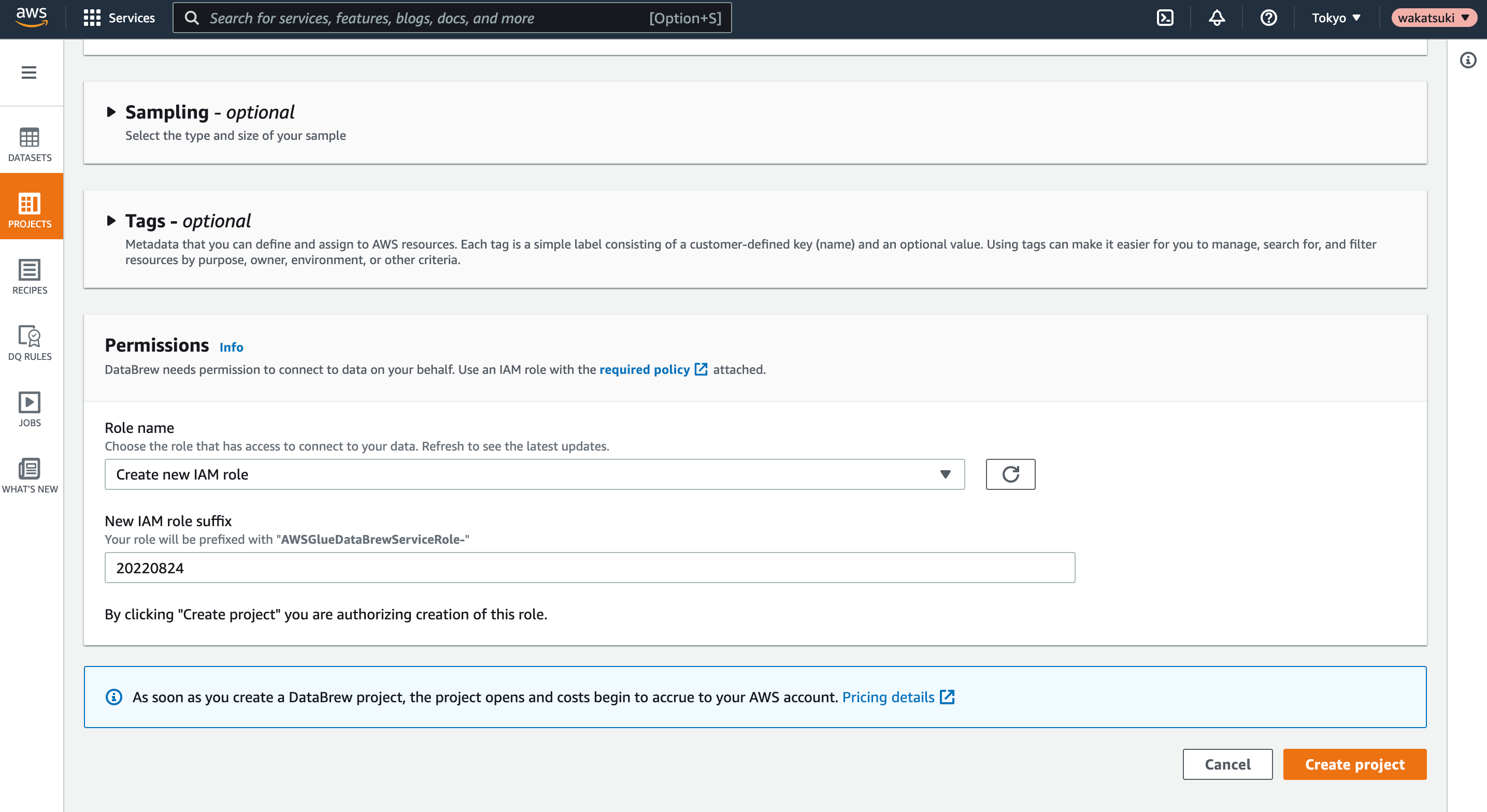
Permissionで、使用するIAMの情報を指定したら[Create project]でProjectを作成します。
作成したProjectのコンソールに遷移します。コンピュートリソースのプロビジョニングなどで数分ほど掛かります。
プロビジョニングが完了し、Project上で500行のDatasetが操作できるようになりました。
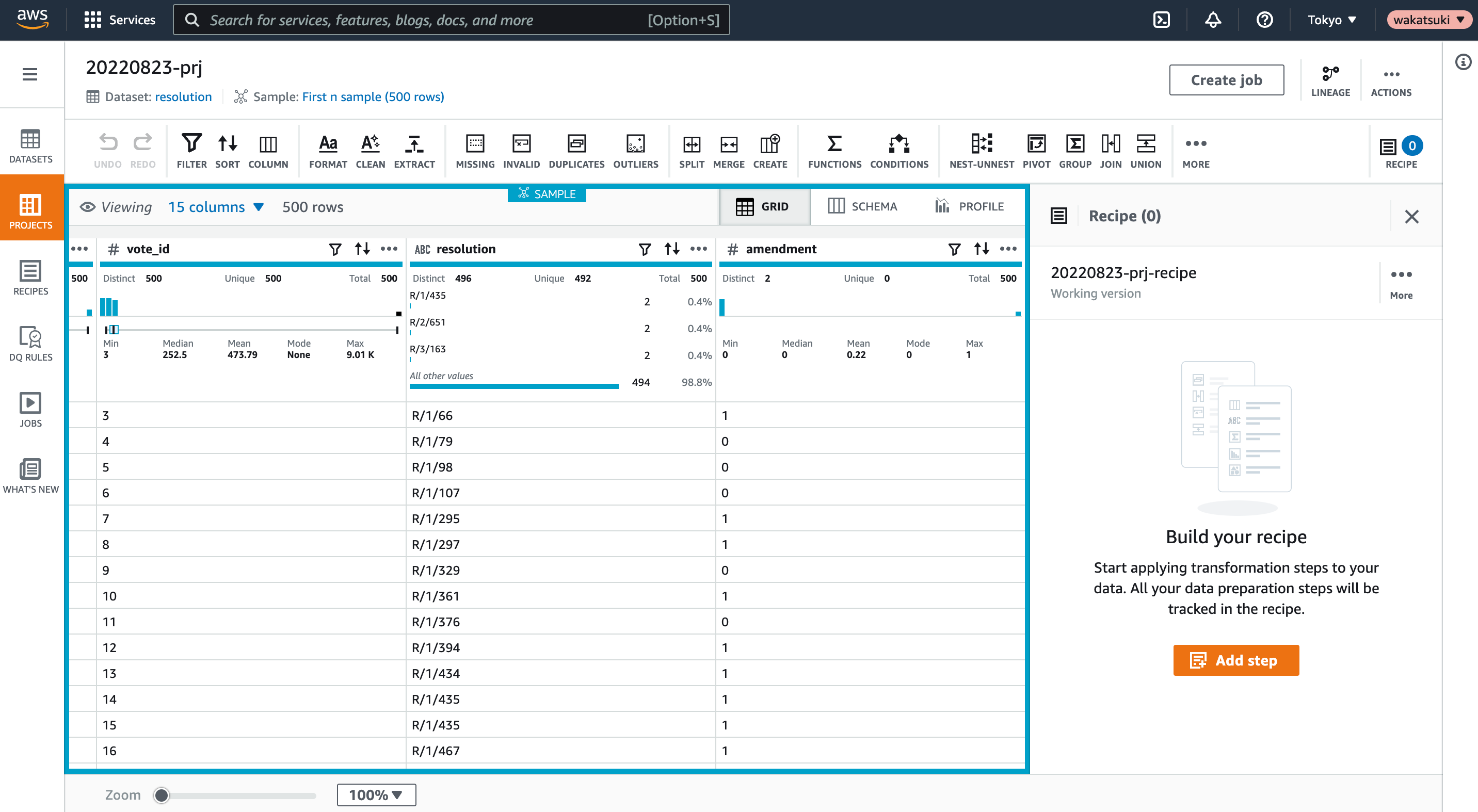
Recipe、Job作成
Project上ではRecipeとそれに紐づくJobを作成できます。
ここでは指定のカラムがnullのレコードを除外するようにしてみます。
[MISSING > Remove missing rows]をクリック。
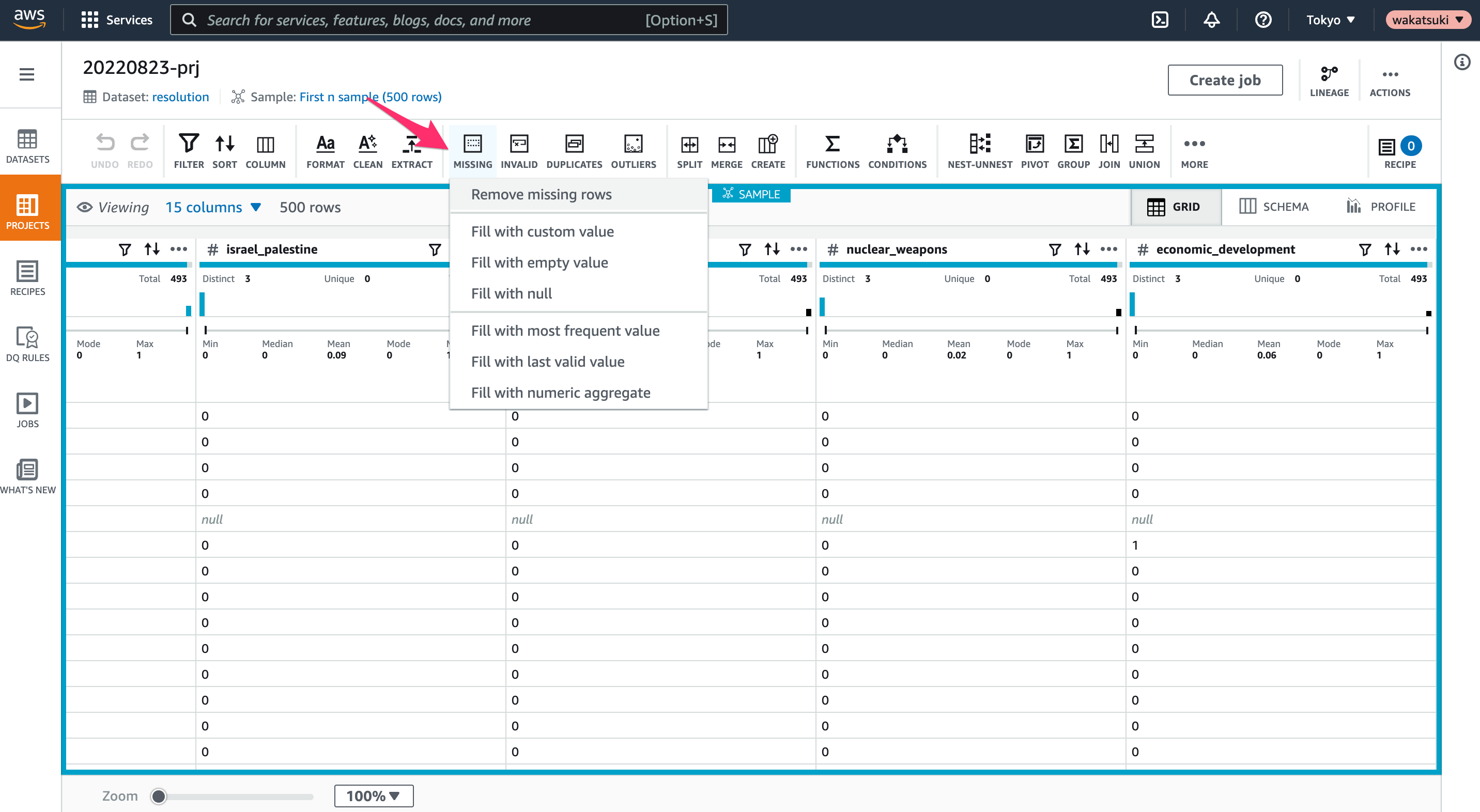
対象の列とActionを指定して[Preview shown]をクリックすると、削除対象のレコードが明示されます。[Apply]をクリック。
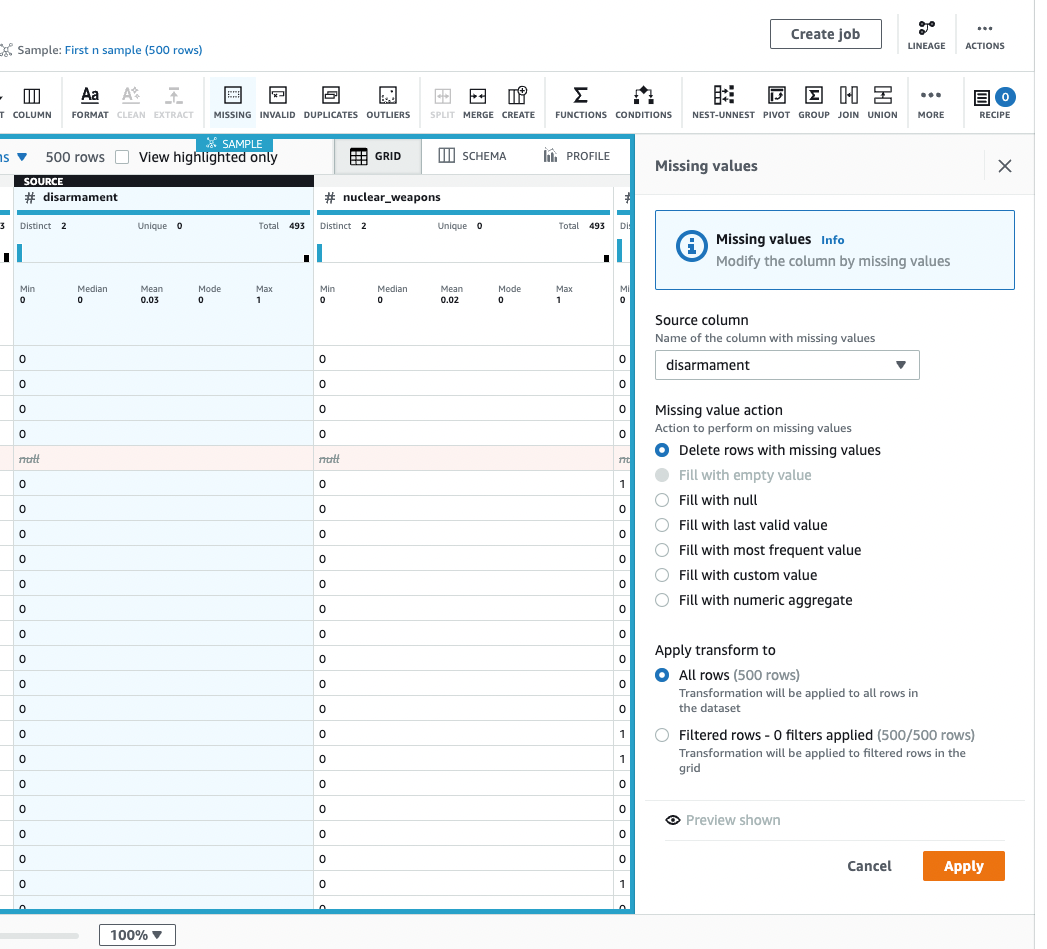
削除が適用されてレコード数が493となりました。
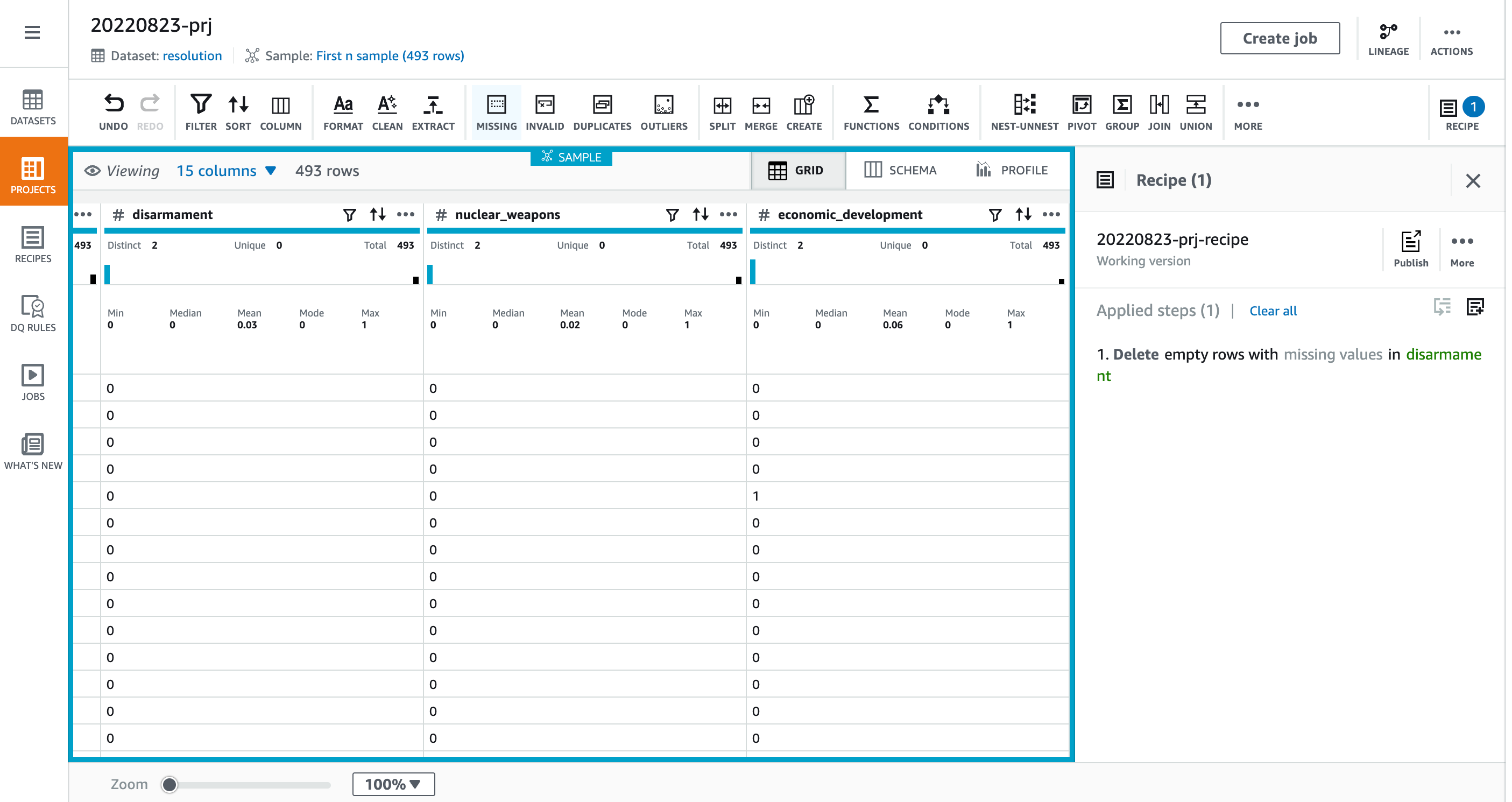
このRecipeを使用してJobを作ってみます。
[Create job]をクリック。
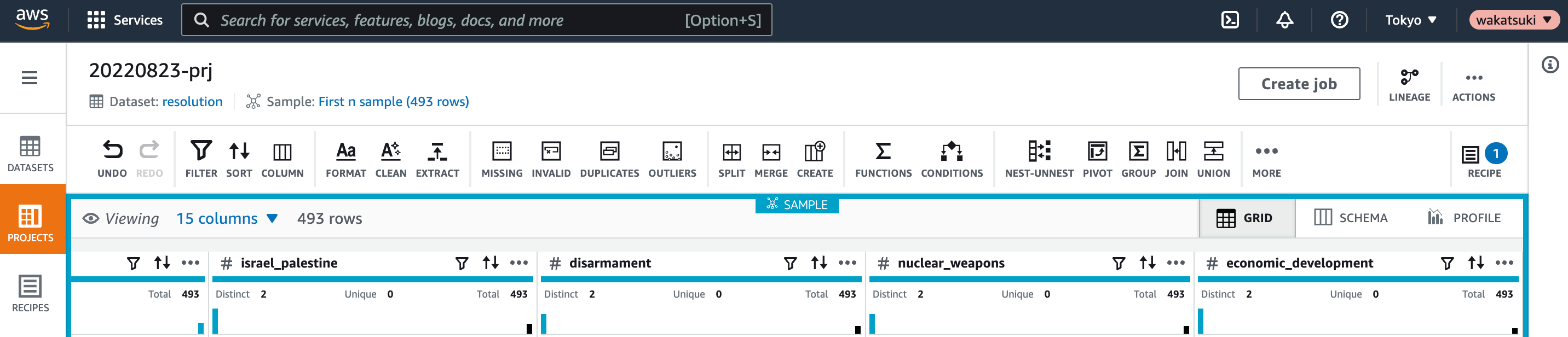
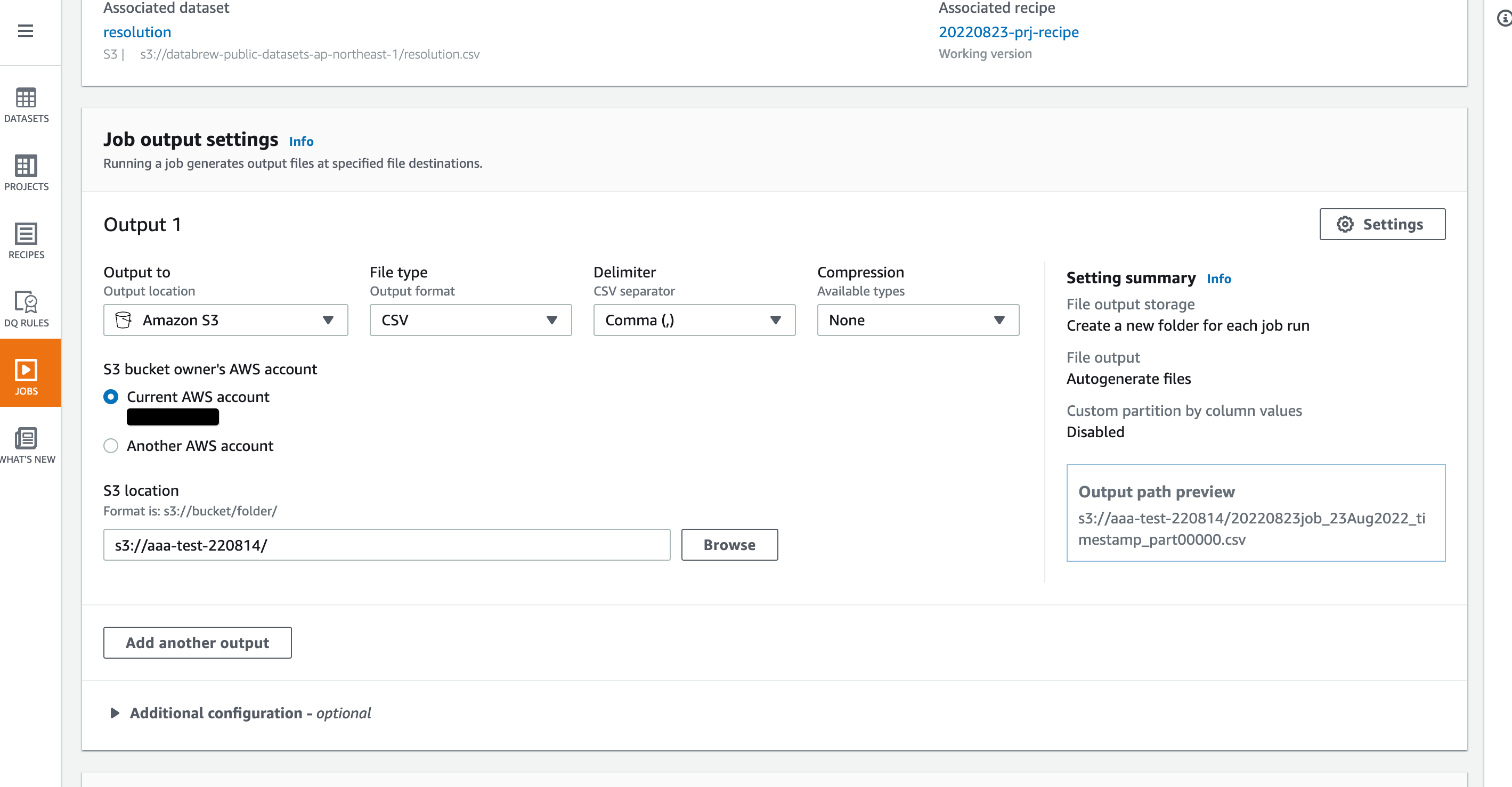
Jobの名前とOutputの設定を指定します。locationはS3 Bucketの他にRedshiftやGlue Data Catalogなどが選べます。
今回はS3 BucketにCSV形式で出力するようにします。予め作成されていたBucketを指定します。
Premissionで、使用するIAMを指定して[Create and run job]をクリック。
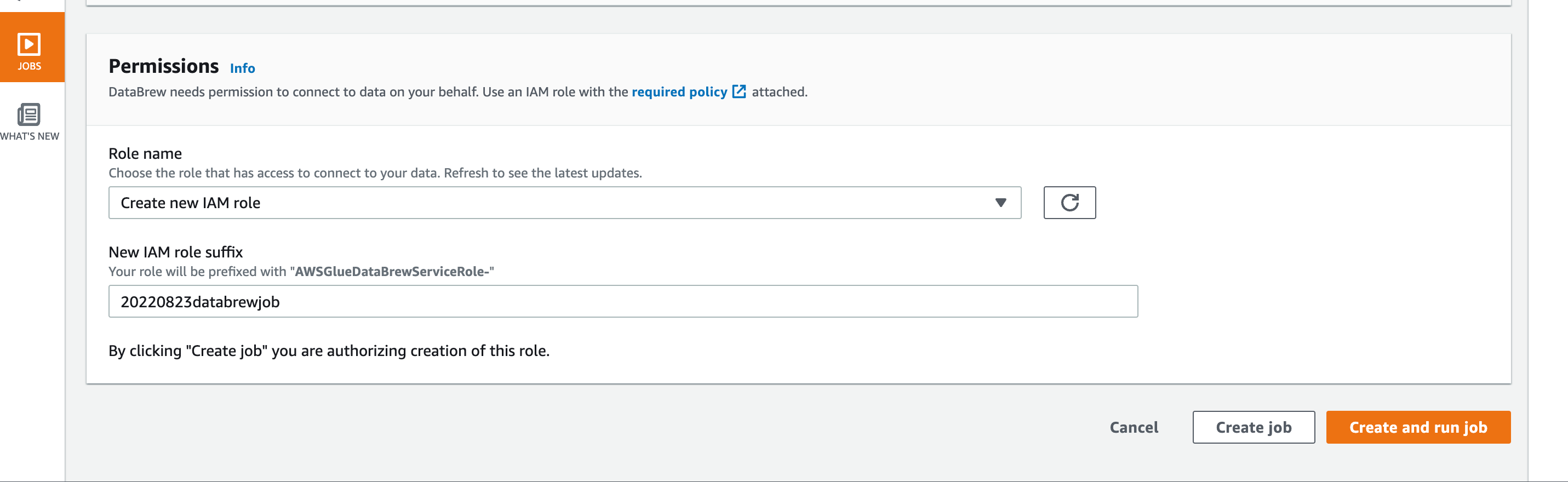
RecipeのJob実行が開始されました。
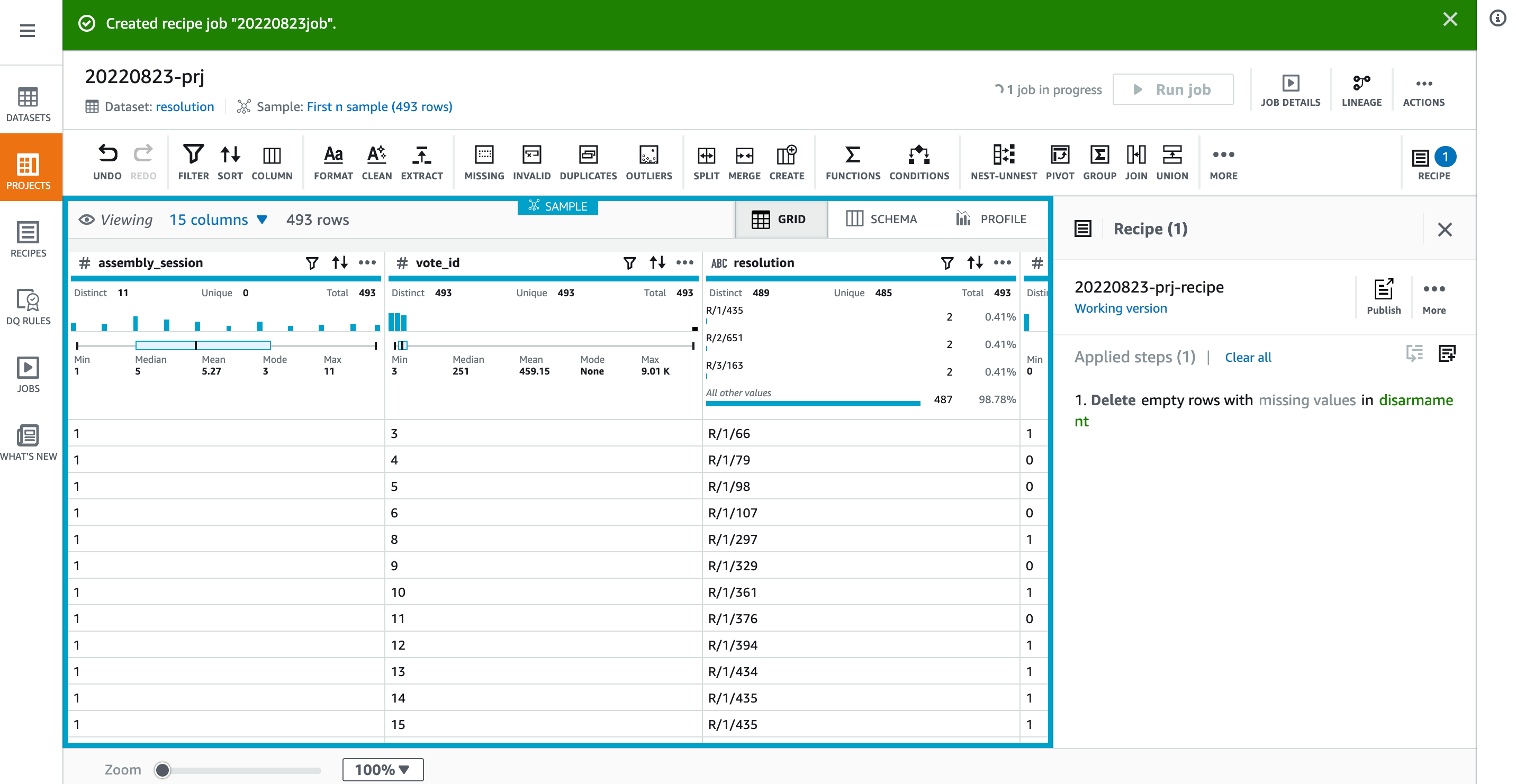
数分後に[JOBS]を開くとJobが完了していますね。Outputを開いてみます。
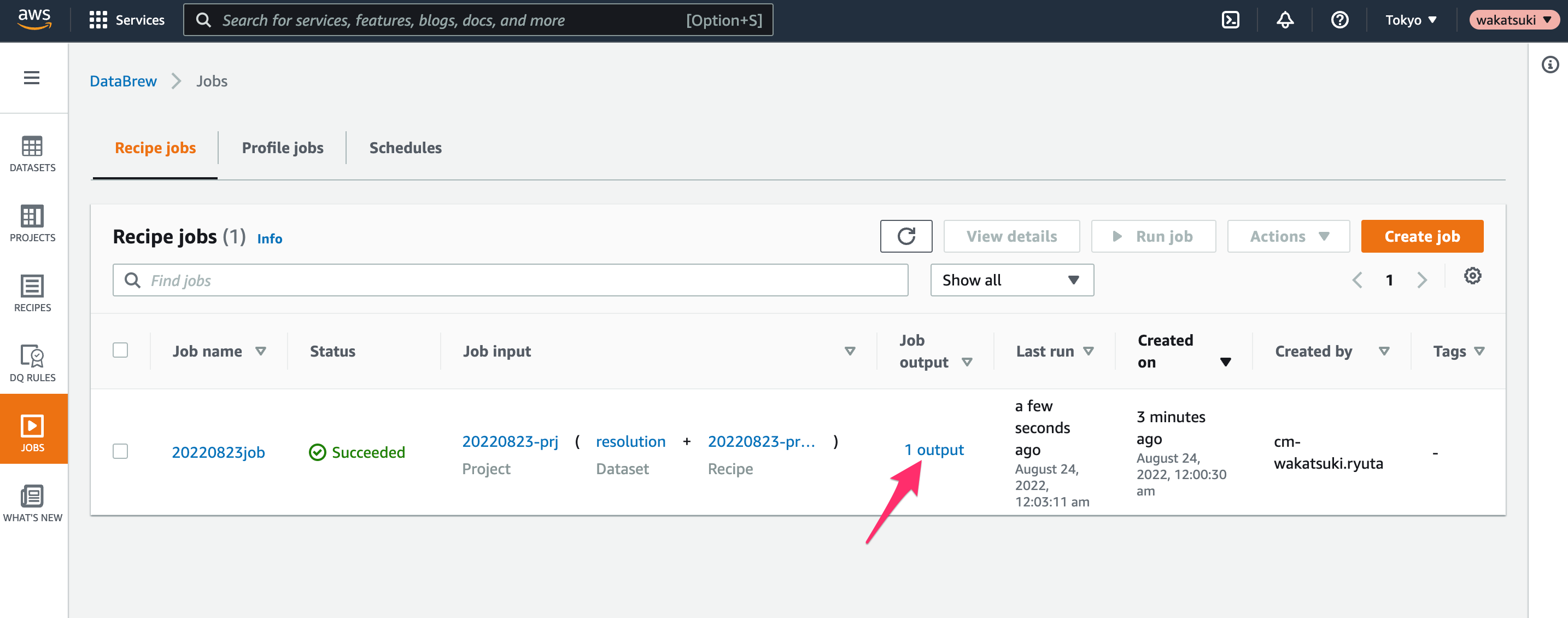
DestinationとなるBucketを開きます。
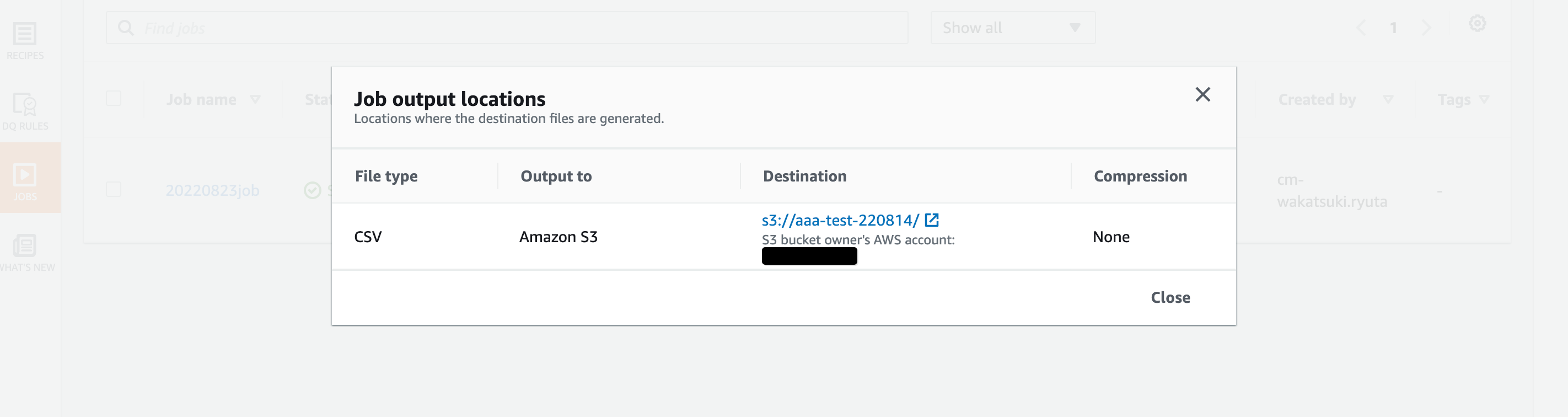
Bucket内にCSVファイルが出力されていますね!
S3 Selectでクエリしてみると、加工後のDatasetを確認することができました!
おわりに
AWS Glue DataBrewの基本的な使い方を学ぶために、DatasetをJobで加工してS3 Bucketに出力してみました。
DataBrewには今回ためして他にも既定で様々な加工メニューが用意されており、今回はごく簡単な処理を行いましたが、AthenaやGlue Jobで出来るデータ加工処理はほとんどDataBrewで置き換えできそうです。クエリやコードを書かずに大量データの加工ができるのは良いですね。コンソールも分かりやすくとっつきやすかったです。
また電話番号のフォーマットなど、データクレンジングでやりたいこととしてよくありそうだがAthenaなどで実現しようとするとちょっと大変そうな処理も既定のメニューで用意されているのは注目に値すると思います。こういったDataBrew独自の処理メニューが増えてくれば採用の機会も増えてきそうだなと思いました。
以上








