![[小ネタ] Athena の UNION を使用して複数 S3 バケットの情報を同時にクエリしてみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-764c44f07bcd41184fe62a432ae120ab/512a4cdcd05a0ed3ddea950fdf619fa0/amazon-athena?w=3840&fm=webp)
[小ネタ] Athena の UNION を使用して複数 S3 バケットの情報を同時にクエリしてみた
現時点(2025/04/24)では、Athena でテーブルを作成する際に複数の S3 バケットを指定することはできません。
以下ドキュメントにあるように CREATE TABLE 文の LOCATION 句では、必ず 1 つの S3 バケットのみ指定する必要があります。
そのため、テーブル定義を行う際に、LOCATION 句に複数の S3 バケットを指定することやバケットを指定せずに全てのバケットを対象とするような設定はできません。
Athena から複数 S3 バケットを同時にクエリするためには、テーブルを S3 バケット毎に作成し、クエリ時に UNION を利用して結合する方法があります。
以下、その手順の紹介です。
S3 バケットにサンプルデータをアップロード
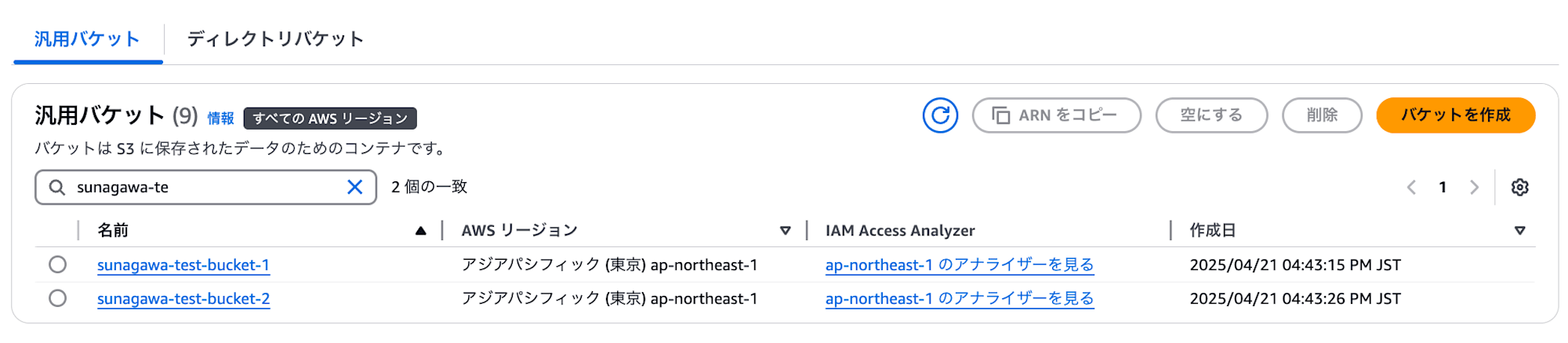
デフォルト設定で S3 バケットを2つ作成します。
S3 バケットにアップロードするための CSV データを作成します。
UserName,Place
Takahashi,Tokyo
Kimura,Fukuoka
Nakamura,Tokyo
Satou,Osaka
UserName,Place
Tanaka,Kyoto
Matumoto,Nagasaki
UserName,Place
Kojima,Nara
Murata,Fukui
S3 バケットに CSV をアップロードします。
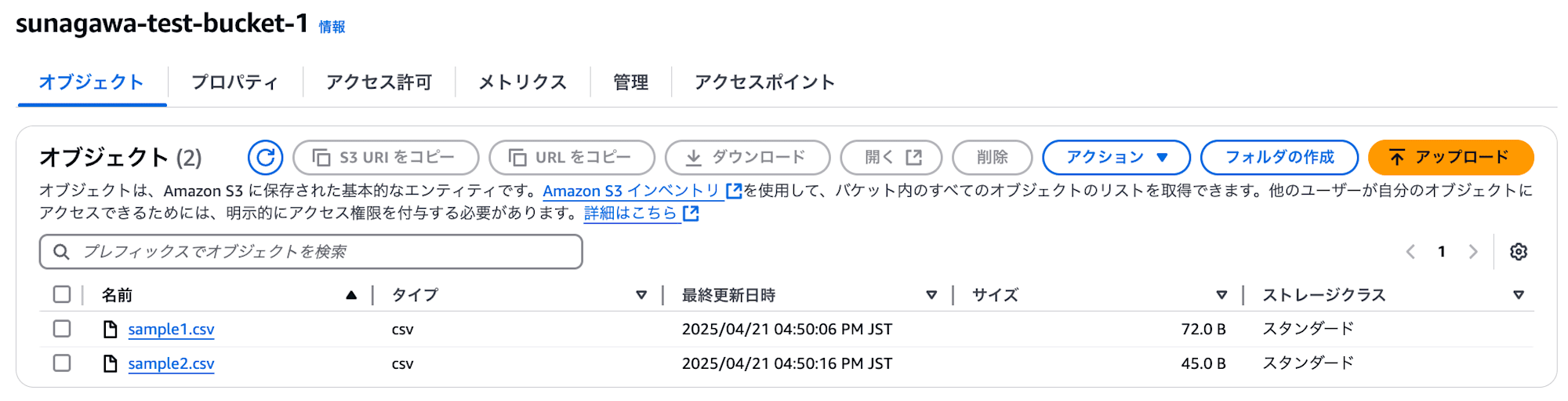
以下画像のように S3 バケット sunagawa-test-bucket-1 に sample1.csv, sample2.csv を配置し、
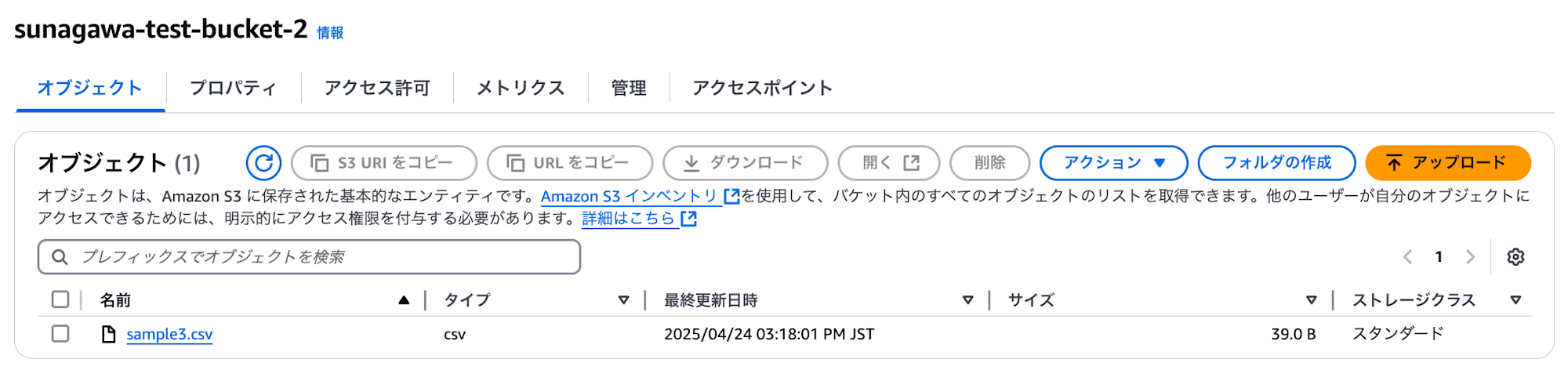
sunagawa-test-bucket-2 に sample3.csv をアップロードした状態です。
-
sunagawa-test-bucket-1
-
sunagawa-test-bucket-2
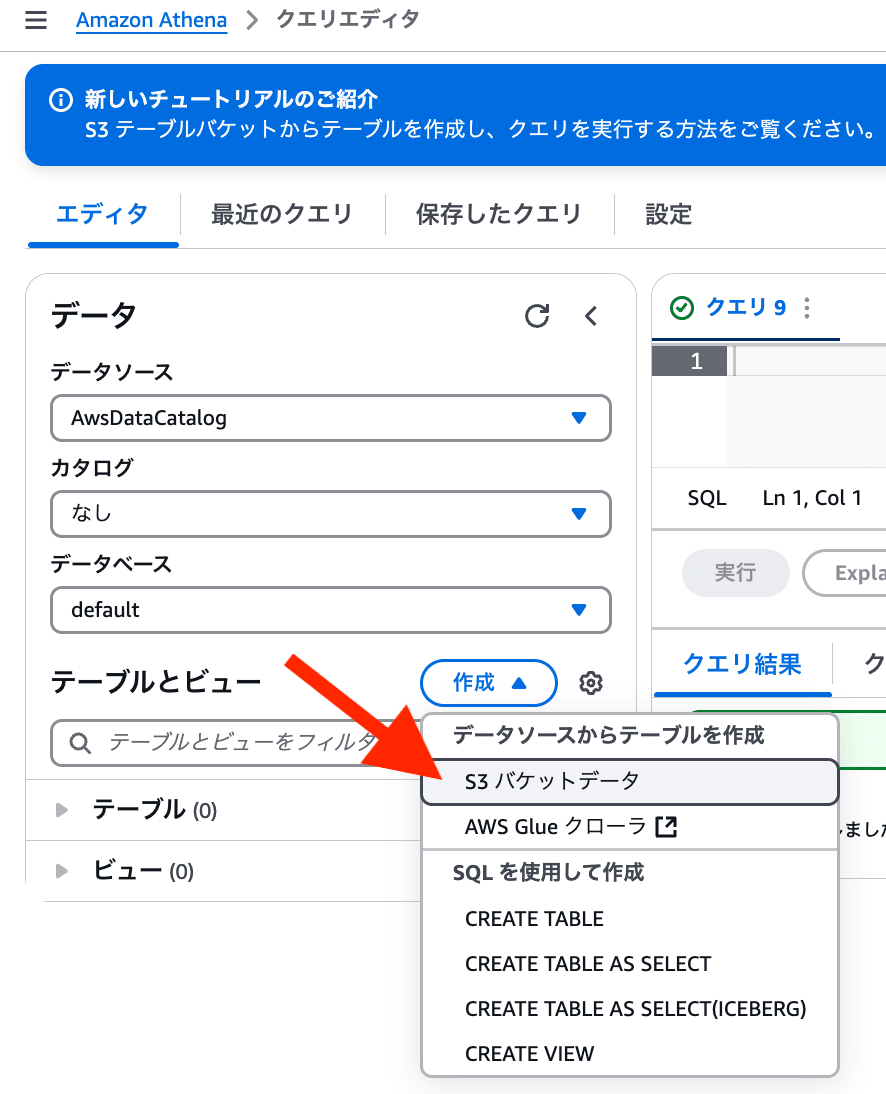
Athena テーブル作成
Athena のクエリエディタの「作成」ボタンを選び、「S3 バケットデータ」を選択します。
任意のテーブル名を指定します。

データセットの場所として、先の項目で作成した1つ目の S3 バケットを指定します。

ファイル形式を CSV とします。

列の詳細にて、CSV ファイルのカラムをそれぞれ設定します。
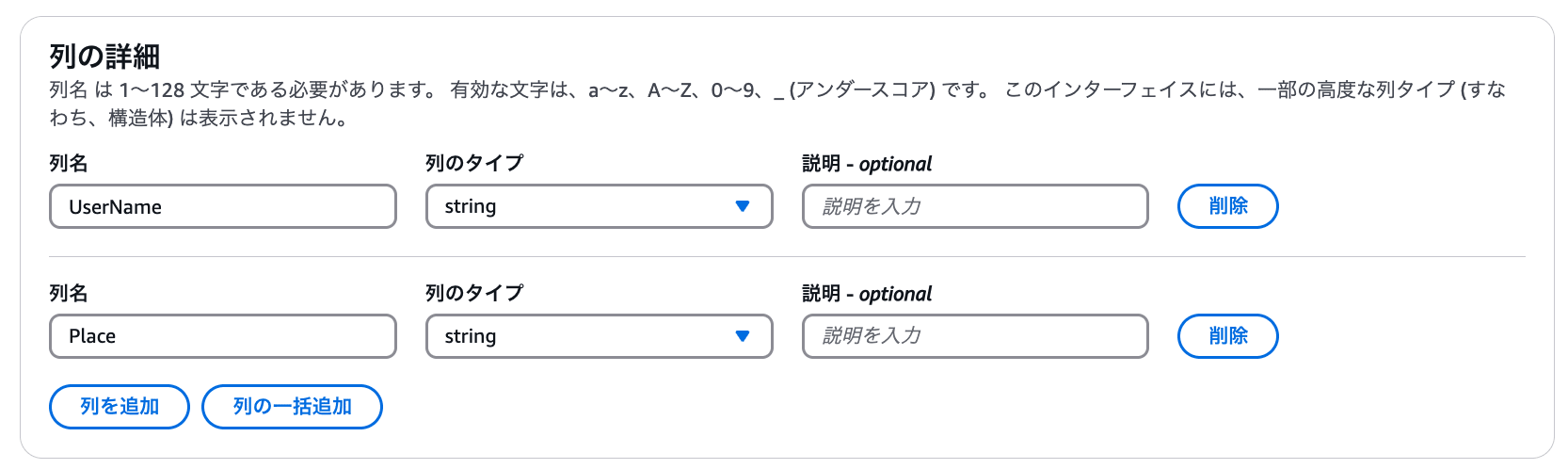
テーブルのプロパティにて skip.header.line.count を 1 に設定します。(これは CSV ファイルのヘッダー行を Athena テーブルに含めないようにする設定です。)
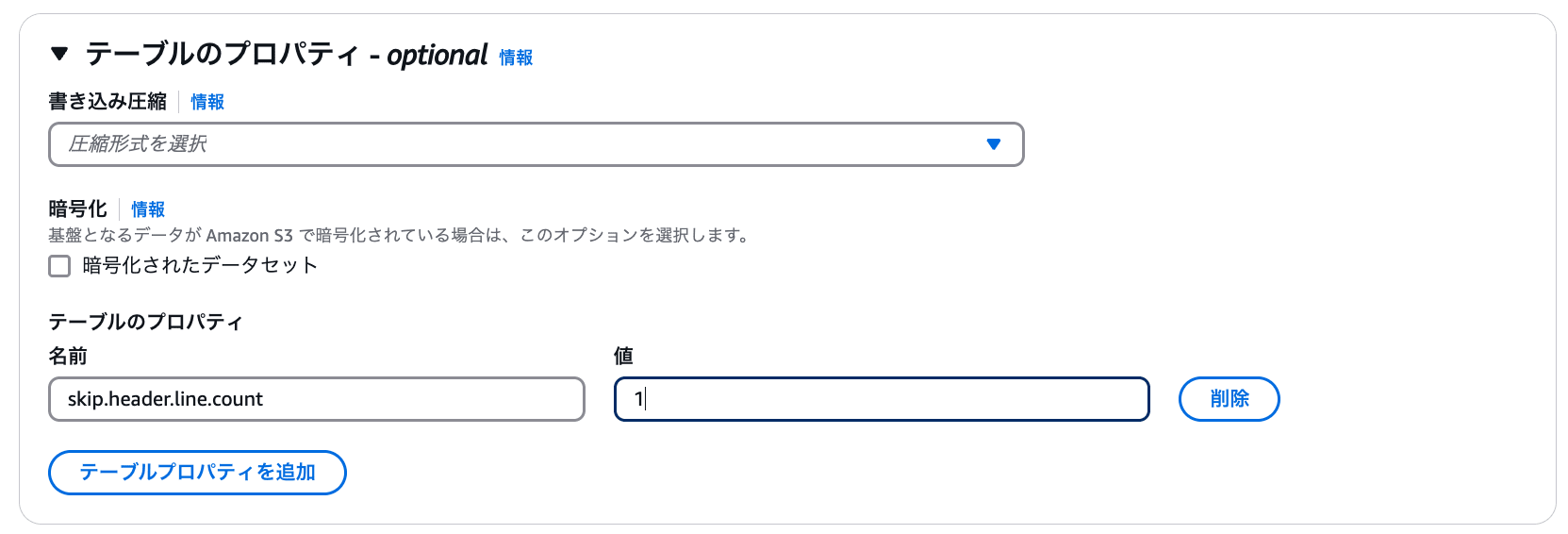
上記設定ができたら、「テーブルを作成」を押下し、 Athena テーブルを作成します。
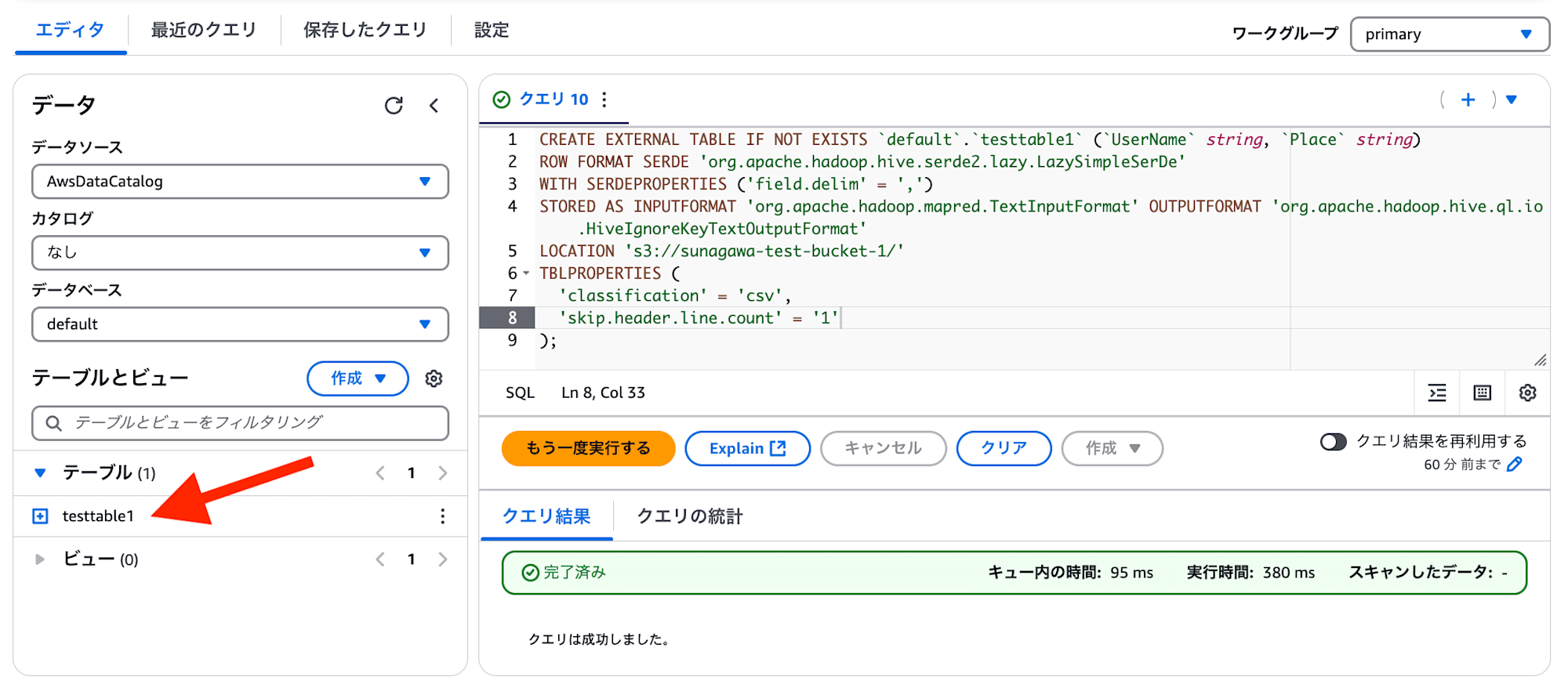
実際には、上記設定に応じて、以下のような CREATE TABLE 文が自動作成、実行され、Athena テーブルが作られます。
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`testtable1` (`UserName` string, `Place` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://sunagawa-test-bucket-1/'
TBLPROPERTIES (
'classification' = 'csv',
'skip.header.line.count' = '1'
);
コンソールを見ると、以下のように testtable1 が作成されていることがわかります。
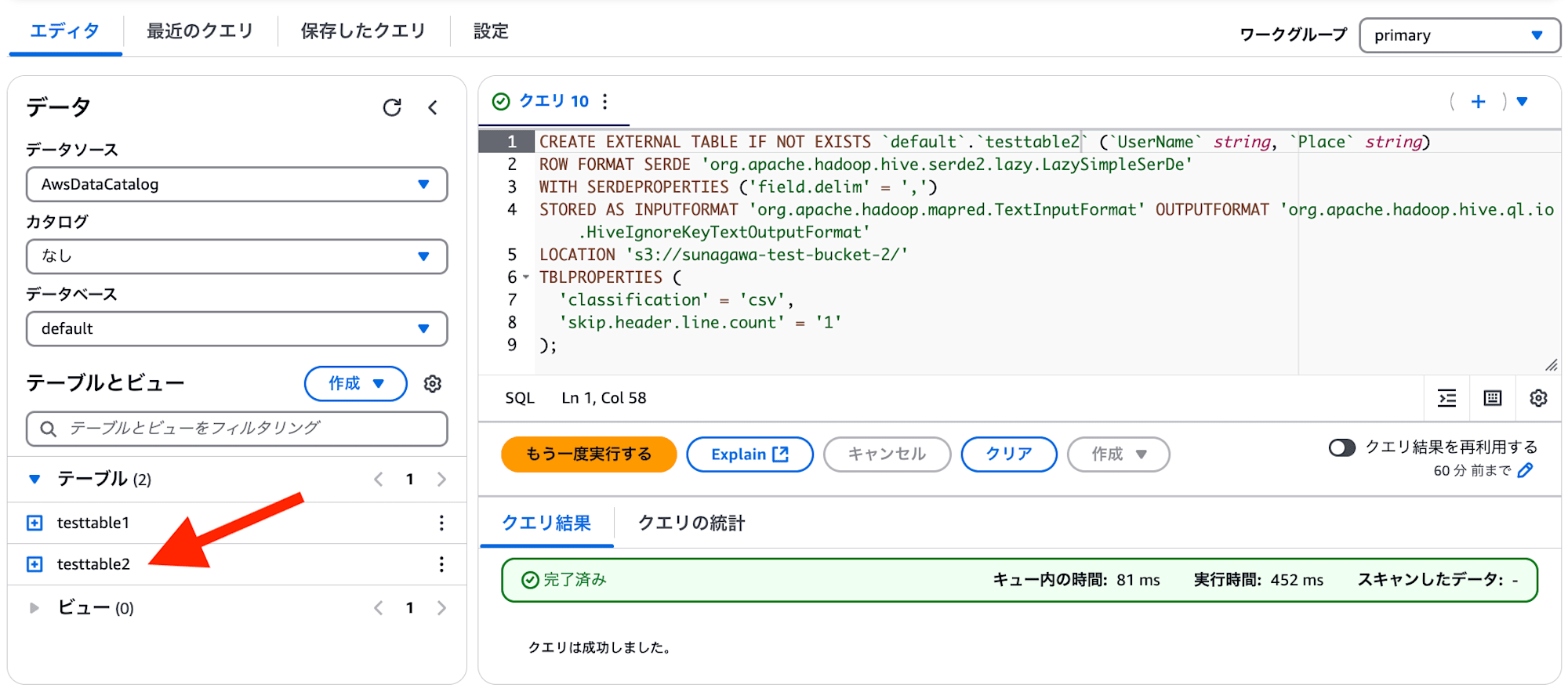
続いて、2つ目の S3 バケットをクエリするための Athena テーブル testtable2 を作成します。
先ほど作成された CREARTE TABLE 文を流用し、テーブル名の部分を testtable2 に変更、LOCATION 句 に指定する S3 バケットを sunagawa-test-bucket-2 に変更しています。それ以外は変わりません。
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`testtable2` (`UserName` string, `Place` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://sunagawa-test-bucket-2/'
TBLPROPERTIES (
'classification' = 'csv',
'skip.header.line.count' = '1'
);
上記をクエリエディタで実行すると、以下のように testtable2 が作成されました。これで準備 OK です。
動作確認
動作確認をしていきます。
Athena では UNION 句を使用することで、複数テーブルをクエリすることが可能です。
具体的には以下のような形でクエリします。
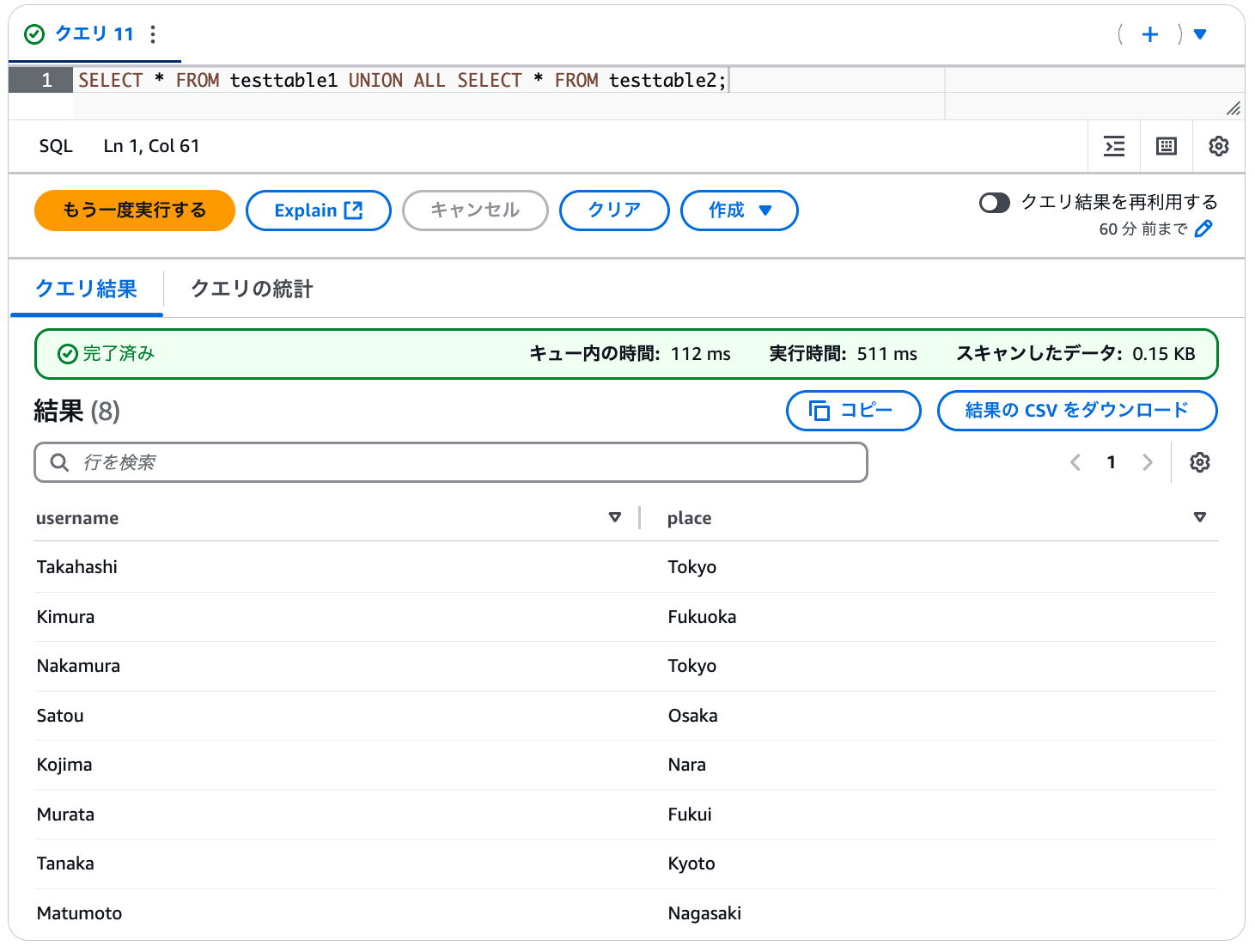
SELECT * FROM testtable1 UNION ALL SELECT * FROM testtable2;
実行結果を見ると以下のように、S3 にアップロードされた sample1 から sample3 までの CSV ファイルの結果が取得できていることがわかります。これで複数バケットを同時にクエリすることができました。
終わりに
今回は、Athena で複数 S3 バケットに対して同時にクエリできるか試してみました。
最初は CREATE TABLE 文のテーブル定義で、複数バケットを指定できるかとか色々試しましたが、ドキュメントにある通り、その使い方はサポートされていないことがわかりました。
複数バケットをクエリする際は、複数テーブルを作成して UNION を使用することが現実的な解決法になります。
今後、Athena テーブル作成時に複数のバケットが設定できるようになったら嬉しいですね。
本ブログがどなたかお役に立ちますと幸いです。
参考情報







