
RAGの埋め込みモデルを変更するなら、既存データの洗い替えが必須
ベクトル検索を利用するシステムでは、テキストなどの非構造化データを「埋め込みモデル」を使って、ベクトル(数字の配列)に変換します。RAG(Retrieval-Augmented Generation)システムの場合、検索キーワードと検索対象のドキュメントのベクトルを比較します。
さて、過去にPoC導入された数多のRAGシステムも、そろそろアップデートの機運が高まっているのではないでしょうか?
そのような場合、埋め込みモデルもアップデートするチャンスです。
ベクトル検索の埋込みモデルを変更するときには、どういう作業が求められるか、考えてみましょう。
RAGシステムと
埋め込みモデルは、RAGシステムにおいて主に以下の2つの場面で使われます。
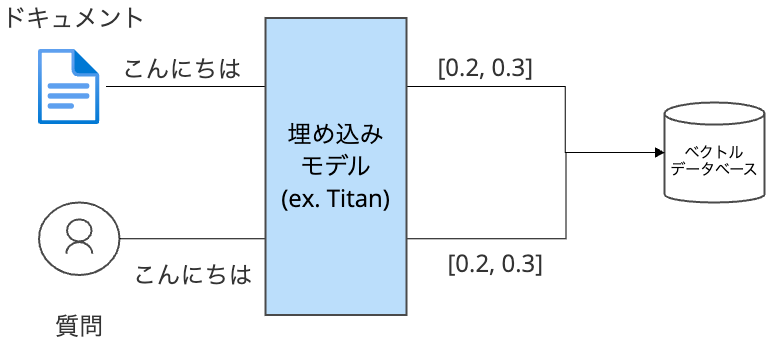
- インデクシング時: ドキュメントを埋め込みモデルでベクトル化してデータベースに格納
- 検索時: ユーザーの質問を埋め込みモデルでベクトル化し、データベースを検索
RAGが正しく機能するには、この両方のフェーズで同じモデルを使用し、意味空間を統一する必要があります。
そのため、埋め込みモデル変更時には、以下の2つの作業が必要です
- 埋め込み操作時の埋め込みモデルの変更
- ベクトルデータベースの埋め込みデータの洗い替え
1. 埋め込み操作時の埋め込みモデルの変更
検索時、インデクシング時といった埋め込み操作時の埋め込みモデルの変更はイメージしやすいと思います。
埋め込みモデルごとに意味空間は異なるため、「こんにちは」という入力が旧モデルでは [0.1, 0.5]だったのが、新モデルでは [0.3, 0.8] というように、異なる出力が得られます。
2. ベクトルデータベースの埋め込みデータの洗い替え
見落としがちなのが、既存データの洗い替えです。
新旧でモデルの次元が異なるような場合、より直接的に互換性がないと気づきやすいですが、1024のような同じ次元であっても、埋め込みモデルごとに意味空間が異なるため、互換性がなく、データの洗い替えが必要です。
洗い替えを忘れると、一体どのような問題が起きるのでしょうか。
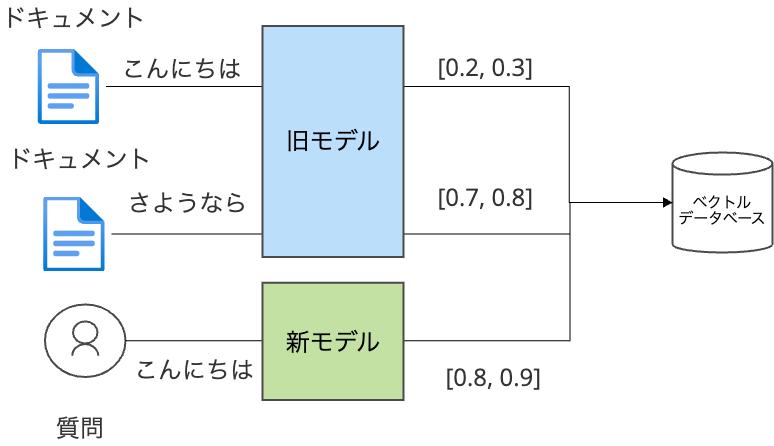
例えば、モデルの新旧で以下のようにベクトル表現が異なるとします。
旧モデルの世界(データベース内のデータ)
- 「こんにちは」 → [0.2, 0.3]
- 「さようなら」 → [0.7, 0.8]
新モデルの世界(検索時の質問)
- 「こんにちは」 → [0.8, 0.9]
この状態でデータベース内のデータを洗い替えずに、ユーザーが新モデルで「こんにちは」と検索したとします。
検索ワードのベクトル [0.8, 0.9] は、データベース内にある旧モデルのベクトルでは、「こんにちは」よりも「さようなら」のほうが近くなってしまいます。
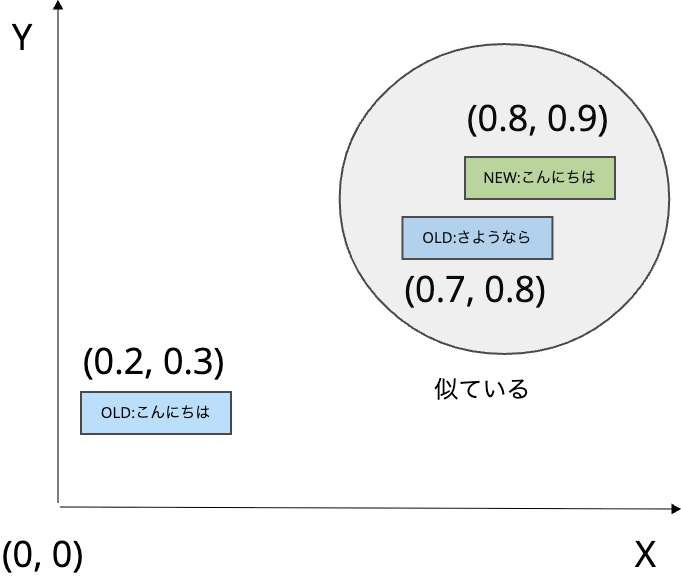
このように、過去のデータを洗い替えないと、意味的には遠いのに、ベクトル空間上では偶然近くに位置するために誤ってマッチングしてしまう、という問題が起きます。
まとめ
RAGシステムで埋め込みモデルを変更する際、検索時とインデクシング時のモデルを変更するだけでなく、意味空間の違いから、既存の埋め込みデータを新モデルで洗い替えも必要です。
特に、データの洗い替えは、データ移行作業のため、移行計画をしっかり立てましょう。
また、モデルの変更に伴う品質評価も忘れずに実施しましょう。










