
S3バケット上のCSVファイルをバッファに読み出してpandasで編集する
2020.12.11
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
Pythonではpandasというデータ解析を支援するライブラリを使用することにより、CSVなどのテーブル形式のデータを効率的に扱うことができます。
今回は、S3バケット上のCSVファイルをバッファに読み出してpandasで編集してみました。
環境
- Python:
3.6.10 - Pandas:
0.24.2
スクリプト
入力元のS3バケットから取得したCSVファイルをpandasで編集して出力先のS3バケットにPutするスクリプトです。
import boto3
import io
import pandas as pd
SRC_BUCKET_NAME="<SRC_BUCKET_NAME>"
SRC_OBJECT_KEY_NAME="<SRC_OBJECT_KEY_NAME>"
SRC_FILE_ENCODING="utf-8"
DEST_BUCKET_NAME="<DEST_BUCKET_NAME>"
DEST_OBJECT_KEY_NAME="<DEST_OBJECT_KEY_NAME>"
s3 = boto3.resource('s3')
src_obj = s3.Object(
SRC_BUCKET_NAME,
SRC_OBJECT_KEY_NAME
)
body_in = src_obj.get()['Body'].read().decode(
SRC_FILE_ENCODING
)
buffer_in = io.StringIO(body_in)
df_in = pd.read_csv(
buffer_in,
lineterminator='\n'
)
df_out = df_in.rename(
columns={'name': 'last_name'}
)
buffer_out=io.StringIO()
df_out.to_csv(buffer_out, index=False)
body_out=buffer_out.getvalue()
dest_obj = s3.Object(
DEST_BUCKET_NAME,
DEST_OBJECT_KEY_NAME
)
dest_obj.put(Body = body_out)
スクリプトの解説
S3からファイルを取得し、ファイルのコンテンツ(CSVテキスト)を変数に格納します。
src_obj = s3.Object(
SRC_BUCKET_NAME,
SRC_OBJECT_KEY_NAME
)
body_in = src_obj.get()['Body'].read().decode(
SRC_FILE_ENCODING
)
io.StringIO()でCSVテキストをバッファに書き出します。これによりCSVテキストをファイル化せずに直接pandasで読み出せるようになります。
buffer_in = io.StringIO(body_in)
バッファをpandasのread_csv()で読み出してDataFrameとします。
df_in = pd.read_csv(
buffer_in,
lineterminator='\n'
)
DataFrameを編集します。今回はrename()でCSVテキストの列名を変更します。
df_out = df_in.rename(
columns={'name': 'last_name'}
)
編集後のDataFrameをto_csv()でCSVテキストとしてバッファに書き出して、変数に格納します。
buffer_out=io.StringIO()
df_out.to_csv(buffer_out, index=False)
body_out=buffer_out.getvalue()
変数に格納された編集後のCSVテキストをコンテンツとしたファイルをS3にPutします。
dest_obj = s3.Object(
DEST_BUCKET_NAME,
DEST_OBJECT_KEY_NAME
)
dest_obj.put(Body = body_out)
スクリプトの実行
下記のようなCSVファイルを入力元のS3バケットに配置します。
9th_rank,name,type
6,takamori,Pa
7,sakuma,Cu
8,nitta,Co
9,ogata,Cu
10,hayami,Co
前述のスクリプトを実行します。
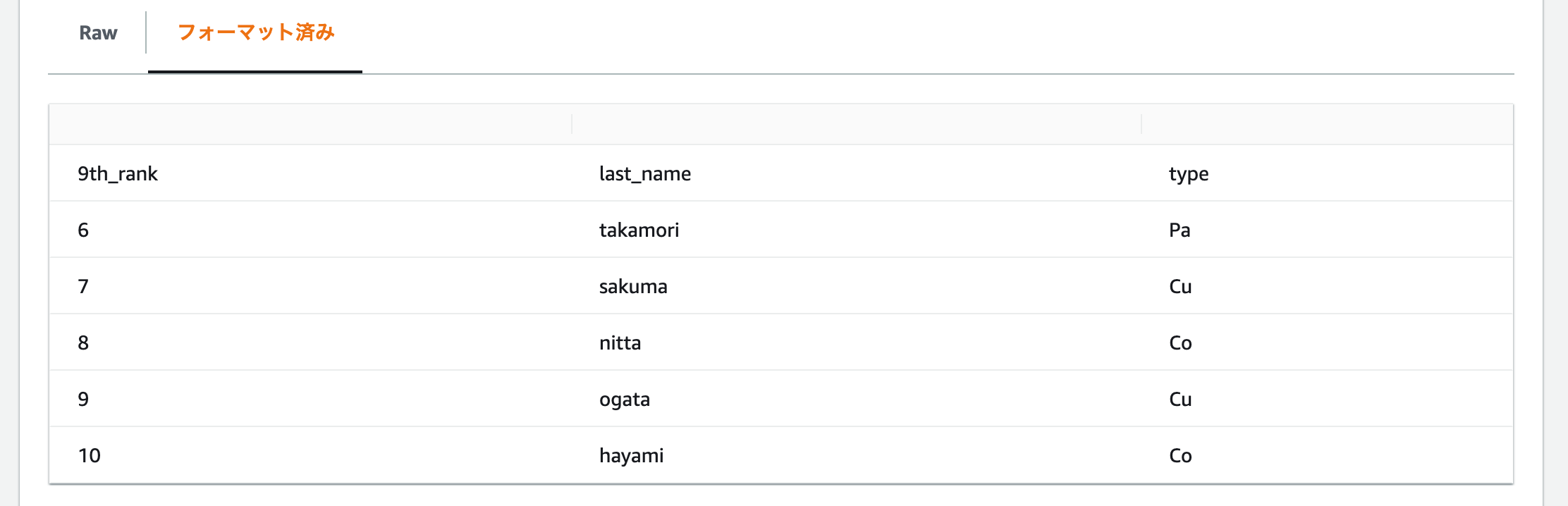
すると、出力先のS3バケットに以下のCSVファイルが作成されました。ちゃんと列名も変更されています。
9th_rank,last_name,type
6,takamori,Pa
7,sakuma,Cu
8,nitta,Co
9,ogata,Cu
10,hayami,Co
おわりに
S3バケット上のCSVファイルをバッファに読み出してpandasで編集してみました。
AWSでETL処理を構築する際によくある処理パターンだと思うので、確認ができて良かったです。
参考
以上










