
RedPen でわかりやすい技術文書を書こう
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
RedPen でわかりやすい技術文書を書こう
最近はブログを始めマニュアルや仕様書など技術文書を書く機会が多くなってきました。 技術文書はわかりやすさが重要だと思うのですが実際は書けていません。 どうしたらわかりやすい文書が書けるのだろうか?と調べていたら RedPen というツールを見つけたので早速試してみました。
RedPen とは?
RedPen とはプログラマや記者が規約に従って文書を記述するのをサポートしてくれるオープンソースのソフトウェアツールです。
プログラミングが規約に従ってコーディングされているかチェックするように、RedPen は自然言語で記述された入力文書の検査を自動化してくれます。
RedPen の特徴
- 設定が柔軟に行えます。(カスタマイズも柔軟)
- どのような言語で書かれた文書でも処理できます。(もちろん日本語も OK です)
- Markdown や Textile フォーマットで記述された文書をそのまま検査できます。
最近は GitBook を使って Markdown で技術文書を書いているので、そのまま検査できるのは助かります。
RedPen のインストール
RedPen はコマンドラインベースのツールとして提供されています。 Homebrew 経由でインストールできるので、導入はとても簡単です。(for Mac)
brew install redpen
とりあえず使ってみる
インストールが完了したら以下のサンプル文章をファイルに保存して検査してみましょう。 以下の文章は、過去に私が公開したブログの一部です。
サンプル文章
## Index で分けるか? Type で分けるか? 例えば、商品情報を保存するインデックスの設計を考えてみましょう。 いわゆるRDBの設計で言うところのテーブル設計ですね。おそらくRDBではアプリケーション要件のみが、その設計の中心になるはずです。 例えば、商品名や説明、価格情報などの基本情報、カテゴリマスターがあって、1つの商品は SKU の組み合わせを複数持っているとか。あとはそれらの情報をどの単位でテーブルに落とし込むか?といった感じでしょうか? これを Elasticsearch で設計する場合、考慮するのはアプリケーション要件だけではないのです。説明する前に簡単に RDB との論理的な構成を比較してみると以下のような構成です。
ターミナルを開いて以下のように検査を実行します。
redpen sample.md
実行結果には、以下のような規約に沿っていない行とその理由が出力されます。 以下はその結果で出力されたエラーです。たくさんエラーが出力されています。わかりづらい文章ということですね。
sample.md:3: ValidationError[DoubledWord], 一文に二回以上利用されている単語 "設計" がみつかりました。 at line: いわゆるRDBの設計で言うところのテーブル設計ですね。 sample.md:3: ValidationError[SpaceBetweenAlphabeticalWord], アルファベット単語の前にスペースが存在しません。 at line: いわゆるRDBの設計で言うところのテーブル設計ですね。 sample.md:3: ValidationError[SpaceBetweenAlphabeticalWord], アルファベット単語の後にスペースが存在しません。 at line: いわゆるRDBの設計で言うところのテーブル設計ですね。 sample.md:3: ValidationError[SpaceBetweenAlphabeticalWord], アルファベット単語の前にスペースが存在しません。 at line: おそらくRDBではアプリケーション要件のみが、その設計の中心になるはずです。 sample.md:3: ValidationError[SpaceBetweenAlphabeticalWord], アルファベット単語の後にスペースが存在しません。 at line: おそらくRDBではアプリケーション要件のみが、その設計の中心になるはずです。 sample.md:5: ValidationError[KatakanaEndHyphen], カタカナ単語 "カテゴリマスター" に不正なハイフンが見つかりました。 at line: 例えば、商品名や説明、価格情報などの基本情報、カテゴリマスターがあって、1つの商品は SKU の組み合わせを複数持っているとか。 sample.md:5: ValidationError[DoubledWord], 一文に二回以上利用されている単語 "情報" がみつかりました。 at line: 例えば、商品名や説明、価格情報などの基本情報、カテゴリマスターがあって、1つの商品は SKU の組み合わせを複数持っているとか。 sample.md:5: ValidationError[DoubledWord], 一文に二回以上利用されている単語 "商品" がみつかりました。 at line: 例えば、商品名や説明、価格情報などの基本情報、カテゴリマスターがあって、1つの商品は SKU の組み合わせを複数持っているとか。 sample.md:5: ValidationError[CommaNumber], カンマの数 (5) が最大の "3" を超えています。 at line: 例えば、商品名や説明、価格情報などの基本情報、カテゴリマスターがあって、1つの商品は SKU の組み合わせを複数持っているとか。 sample.md:7: ValidationError[DoubledWord], 一文に二回以上利用されている単語 "構成" がみつかりました。 at line: 説明する前に簡単に RDB との論理的な構成を比較してみると以下のような構成です。
校正した文章がこちら。微妙な違いですが、心なしか文章がクドくなくなったような気がします。
## Index で分けるか? Type で分けるか? 例えば、商品情報を保存するインデックスの設計を考えてみましょう。 いわゆる RDB で言うところのテーブル設計ですね。おそらく RDB ではアプリケーション要件のみが、その設計の中心になるはずです。 例えばある商品は名称や説明、価格などの基本情報を持ちます。その商品情報は1つ以上のカテゴリマスタに紐付いていて、SKU の組み合わせを複数持っているとか。あとはそれらの情報をどの単位でテーブルに落とし込むか?といった感じでしょうか? これを Elasticsearch で設計する場合、考慮するのはアプリケーション要件だけではないのです。説明する前に簡単に RDB との論理的な構成を比較します。
設定ファイルのカスタマイズ
以下はデフォルトで使用されていた設定ファイルです。
<redpen-conf lang="ja"> <validators> <validator name="SentenceLength"> // センテンス長の規約 <property name="max_len" value="100"/> </validator> <validator name="InvalidSymbol"/> // 記号の規約 <validator name="KatakanaEndHyphen"/> // カタカナの規約 <validator name="KatakanaSpellCheck"/> // カタカナのスペルチェック <validator name="SectionLength"> // セクションの規約 <property name="max_num" value="1500"/> </validator> <validator name="ParagraphNumber"/> // パラグラフ数の規約 <validator name="DoubledWord" /> // 一文内の同一単語の規約 <validator name="SpaceBetweenAlphabeticalWord" /> // 日本語文書内のアルファベットの規約 <validator name="CommaNumber" /> // コンマの数の規約 <validator name="SuccessiveWord" /> // 単語の繰り返し規約 <validator name="JavaScript" /> </validators> </redpen-conf>
デフォルトでは、センテンス長や記号、カタカナなどの日本語の文章をわかりやすく統一するための規約が設定されています。なるほど、センテンスの文字数やパラグラフ数を極力短く、一文内では同じ単語を使用しないように気をつけるだけでもわかりやすくなりそうですね。
上記の設定以外にも、ですますとである調の混在や二重否定チェックなど日本語特有の規約も用意されています。
設定のカスタマイズは、デフォルトの内容をもとに自分好みに修正していけばよいでしょう。
※ 各種設定の詳細についてはマニュアルを参照してください。
カスタマイズした設定の指定は以下の例のように -c オプションを使用します。
redpen -c redpen-conf.xml sample.md
各種エディタのプラグイン
各種エディタ用にプラグインも用意されています。
- Atom Editor package by griffin-stewie
- Emacs redpen-paragraph by karronoli
- WordPress plugin
- IntelliJ IDEA plugin
- SublimeLinter module for RedPen
RedPen と Github と Travis CI でレビュを効率化
一人で技術文書を書いている場合は、コマンドラインで RedPen を実行して規約に沿っているか確認すれば良いのですが、複数人で作業している場合は Travis CI との連携が便利そうです。 規約(redpen-conf)を文書と一緒に Github で共有して、Travis CI と連携することで、基本的な規約のレビュが自動化できますね。
- Github で文書管理
- フォークしてもらう
- プルリクもらう
- Travis CI で規約自動チェック
- 規約沿った文書になっていればマージ
という流れです。
プルリクエストをもらって、規約に従っていなければ、以下のようにエラーが表示されます。
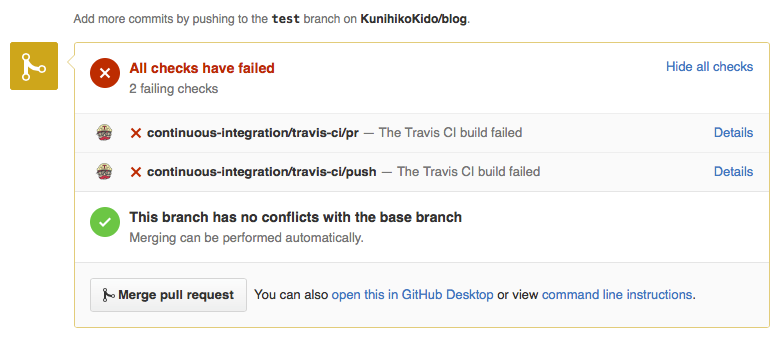
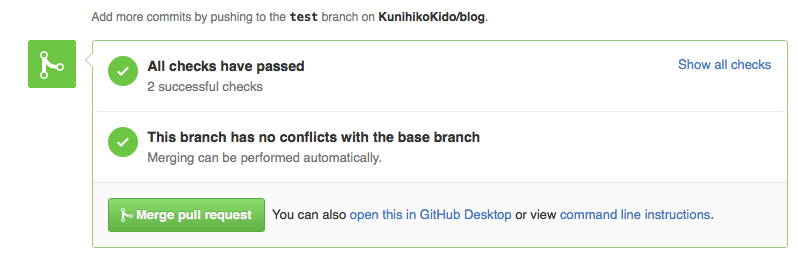
規約に従った文書であれば、 All checks have passed となって安全にマージすることができます。
Github のファイル構成例
以下のファイル構成では、src ディレクトリ配下に Markdown 形式の文章を管理する構成です。
myblog ├── .gitignore ├── .travis.yml # Travis CI ファイル ├── README.md ├── redpen-conf-ja.xml # RedPen 規約ファイル └── src # コンテンツファイル └── redpen-getting-started.md
Travis の設定ファイル例
Travis CI 用の設定ファイルです。
language: text jdk: - oraclejdk8 env: - URL=https://github.com/redpen-cc/redpen/releases/download/redpen-1.5.2 install: - wget $URL/redpen-1.5.2.tar.gz - tar xvf redpen-1.5.2.tar.gz - export PATH=$PWD/redpen-distribution-1.5.2/bin:$PATH script: - redpen -c redpen-conf-ja.xml -f markdown -l 0 src/*.md
RedPen 設定ファイル例
今回使用した RedPen の設定ファイルです。
<redpen-conf lang="ja"> <validators> <validator name="SentenceLength"> <property name="max_len" value="120"/> </validator> <validator name="InvalidSymbol"/> <validator name="KatakanaEndHyphen"/> <validator name="KatakanaSpellCheck"/> <validator name="SectionLength"> <property name="max_num" value="1500"/> </validator> <validator name="ParagraphNumber"/> <validator name="SpaceBetweenAlphabeticalWord" /> <validator name="CommaNumber" /> <validator name="SuccessiveWord" /> <validator name="JavaScript" /> <validator name="JapaneseStyle" /> <validator name="DoubleNegative" /> </validators> </redpen-conf>
まとめ
この記事も RedPen で校正しています。さすがに一文内の同一単語の規約(DoubledWord)は素人には厳しかったので外しました。 RedPen はセットアップも簡単なため、まずは個人的にブログから使っていこうかと思っています。(そのうち社内の仕様書や製品マニュアルでも使っていきたい。)








