
CloudWatch Logs でログ種別の自動検出・分類を活用して、Logs Insights でスキャンする量を簡単に削減してみる #AWSreInvent
re:Invent 2025 のキーノートで Cloud Watch ログの統合管理機能が発表されました。
アップデート内容が幅広くて明確に定義し辛いですし、呼び方が「統合管理機能」で良いのかもわかりませんが、要は他 SaaS のログなども集めて CloudWatch でログ基盤を作りやすくなったというアップデートです。
具体的には下記のような内容です。
- AWS マネージドな形での 3rd パーティーアプリケーションログの取り込み
- ログ種別の自動検出・分類
- CloudWatch マネージドでログスキーマ変換などのデータ処理を実現可能なパイプライン機能
- ファセットを利用した Logs Insights のクエリレスな分析
- AWS マネージドな S3 テーブル統合
- 組み込みのログ管理用ダッシュボード
また、ログ種別の自動検出・分類ができるようになったため、インデックスを利用したログスキャン量の削減も非常に行いやすくなりました。
特に下記種類のログが検知された場合はデフォルトでフィールドインデックスを利用できるようになります。
- VPC フローログ
- Route53 クエリログ
- WAF アクセスログ
- CloudTrail ログ
また、他のログについてもロググループレベルでは無く、データソースごとにインデックス設定を行えるようになりました。
今回はどう便利になったかを検証していこうと思います。
VPC フローログでデフォルトで利用できるインデックスを活用してスキャン量を削減してみる
VPC フローログを下記形式で出力します。
${version} ${account-id} ${interface-id} ${srcaddr} ${dstaddr} ${srcport} ${dstport} ${protocol} ${packets} ${bytes} ${start} ${end} ${action} ${log-status}
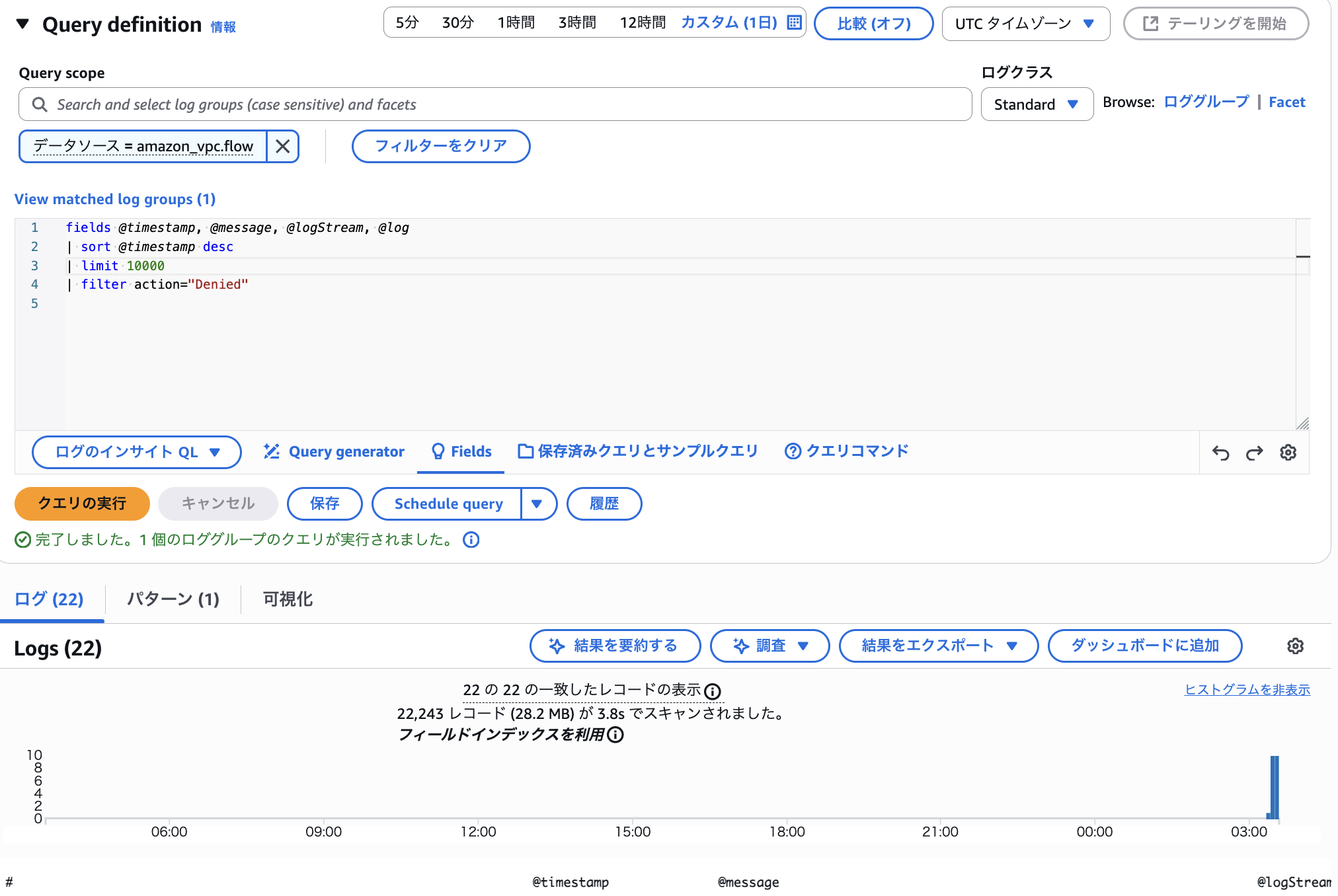
まず、インデックスを指定せずに過去 1 日分の拒否された通信を表示します。
fields @timestamp, @message, @logStream, @log
| sort @timestamp desc
| limit 10000
| filter action="Denied"
マッチしたのが 22 レコードでもスキャンサイズは 28.2 MB 程度になりました。
拒否されていない大半の通信もスキャン対象になってしまっていることがわかります。
続いて、インデックスを利用してクエリを実行します。
fields @timestamp, @message, @logStream, @log
| sort @timestamp desc
| limit 10000
| filter action="Denied"
| filterIndex action="Denied"
大半の拒否されていない通信をスキャン対象から省くことで 905 KB と大きくスキャンサイズを減らすことができました。
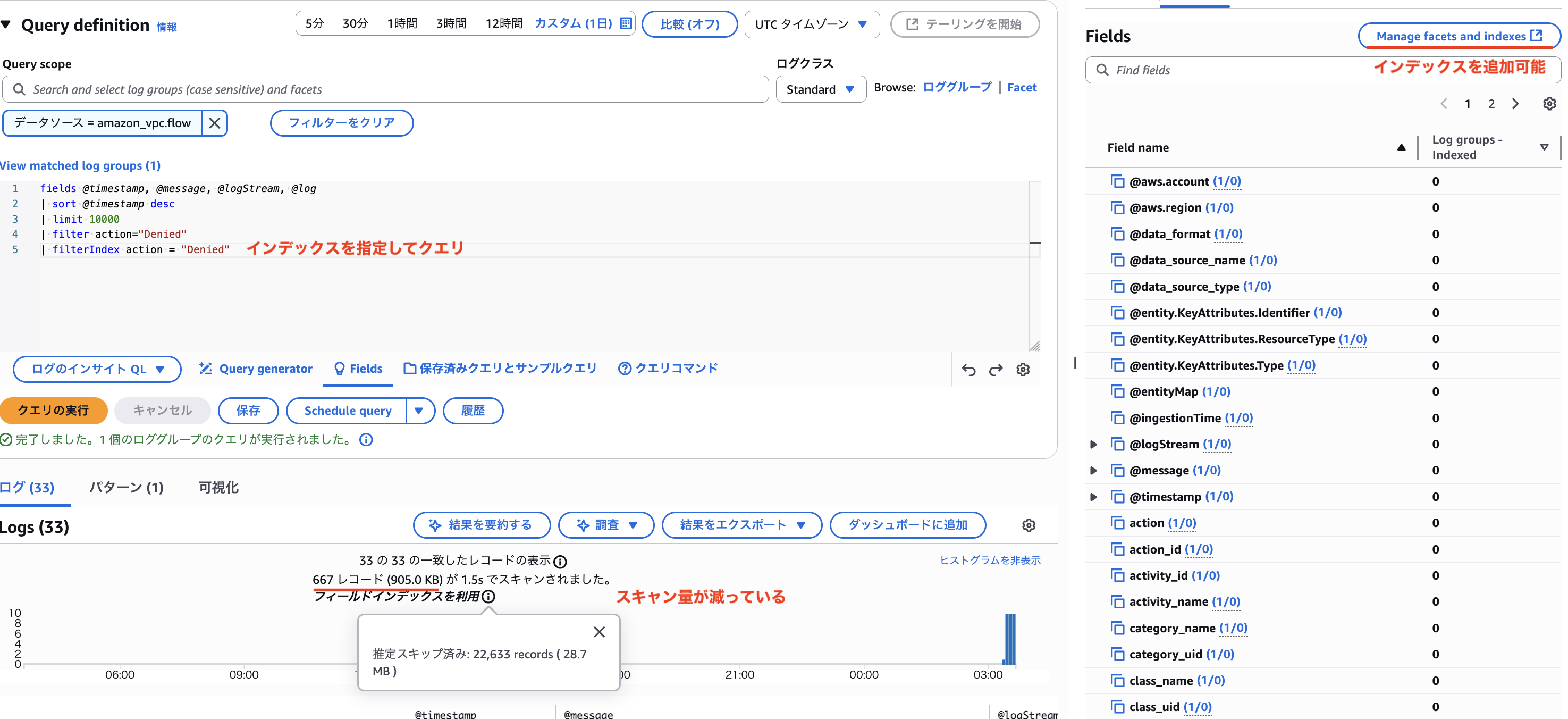
ここで驚くべきなのは、データソースごとにデフォルトでインデックスが作成されており、特に複雑なことは考えずに利用できることです。
ログ種別の自動検知・分類ができるようになり、自動でインデックスやファセットを作成してくれるようになったからですね。
データソースごとのインデックスポリシーを修正してみる
続いて、インデックスポリシーを修正してみます。
デフォルトでフィールドインデックスが設定されている AWS サービスログでも追加でインデックスを利用したい場合は修正が必要です。
また、API Gateway のアクセスログなど、自動検出はされるものの最初からフィールドインデックスが利用できるわけでは無いものも存在します。
これらのログについても個別にインデックスポリシーを設定する必要があります。
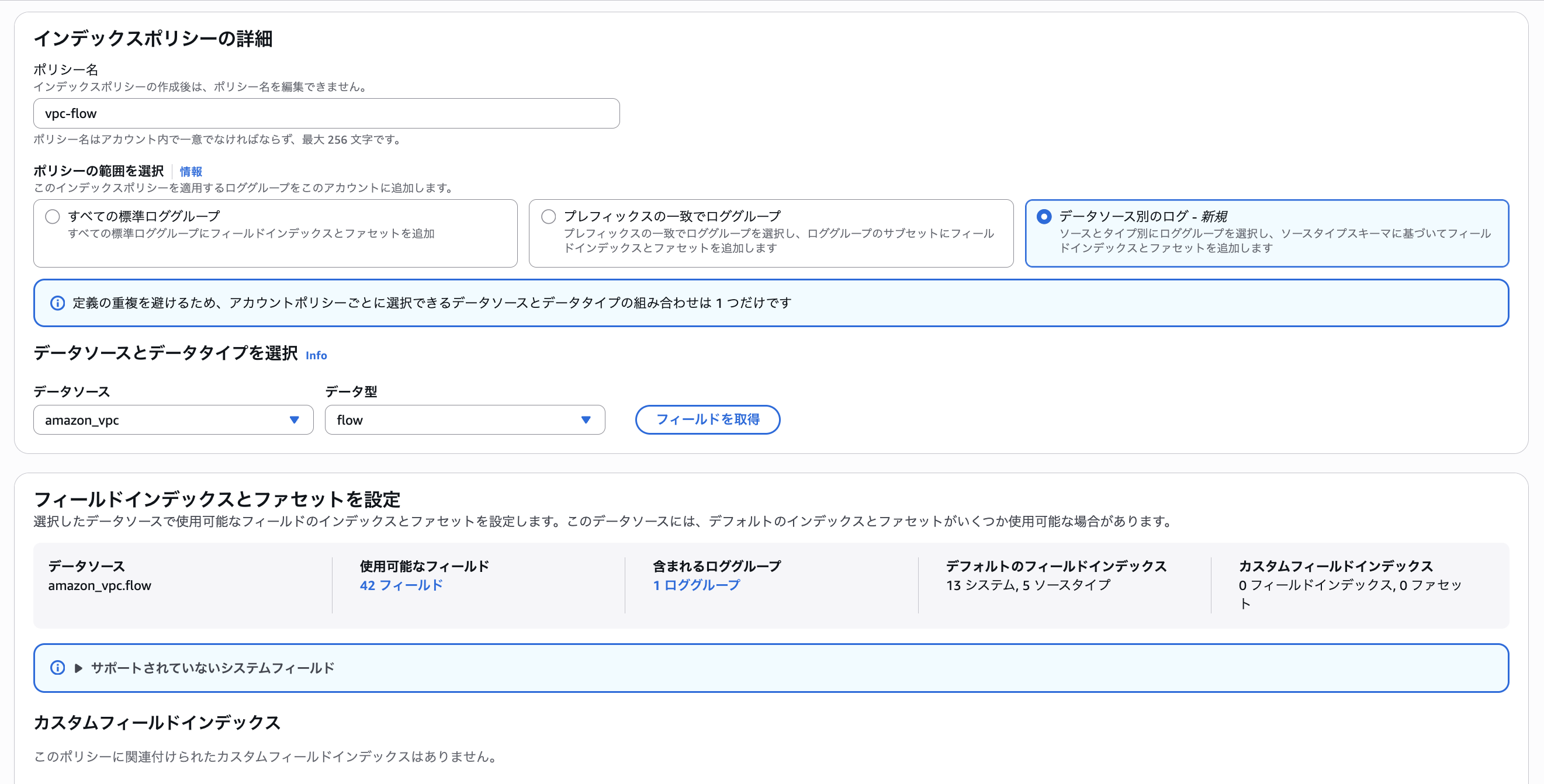
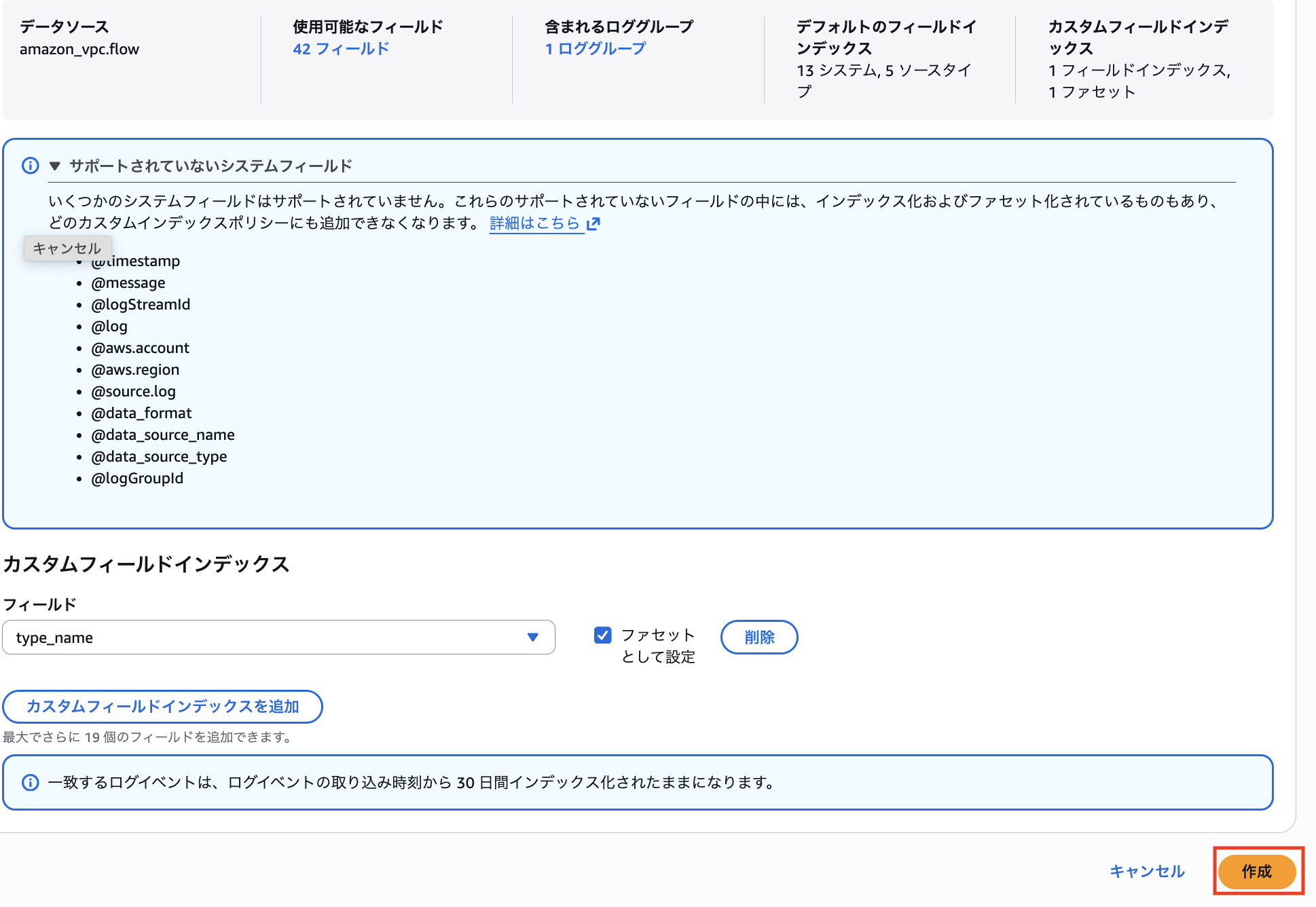
クエリ画面右上の「Manage facets and Indexes」をクリックした後、「インデックスポリシーを作成」をクリックします。

データソースごとのインデックスポリシーを作成します。
action や flowDirection などはデフォルトでインデックス化され、ファセットとしても設定されていることがわかります。
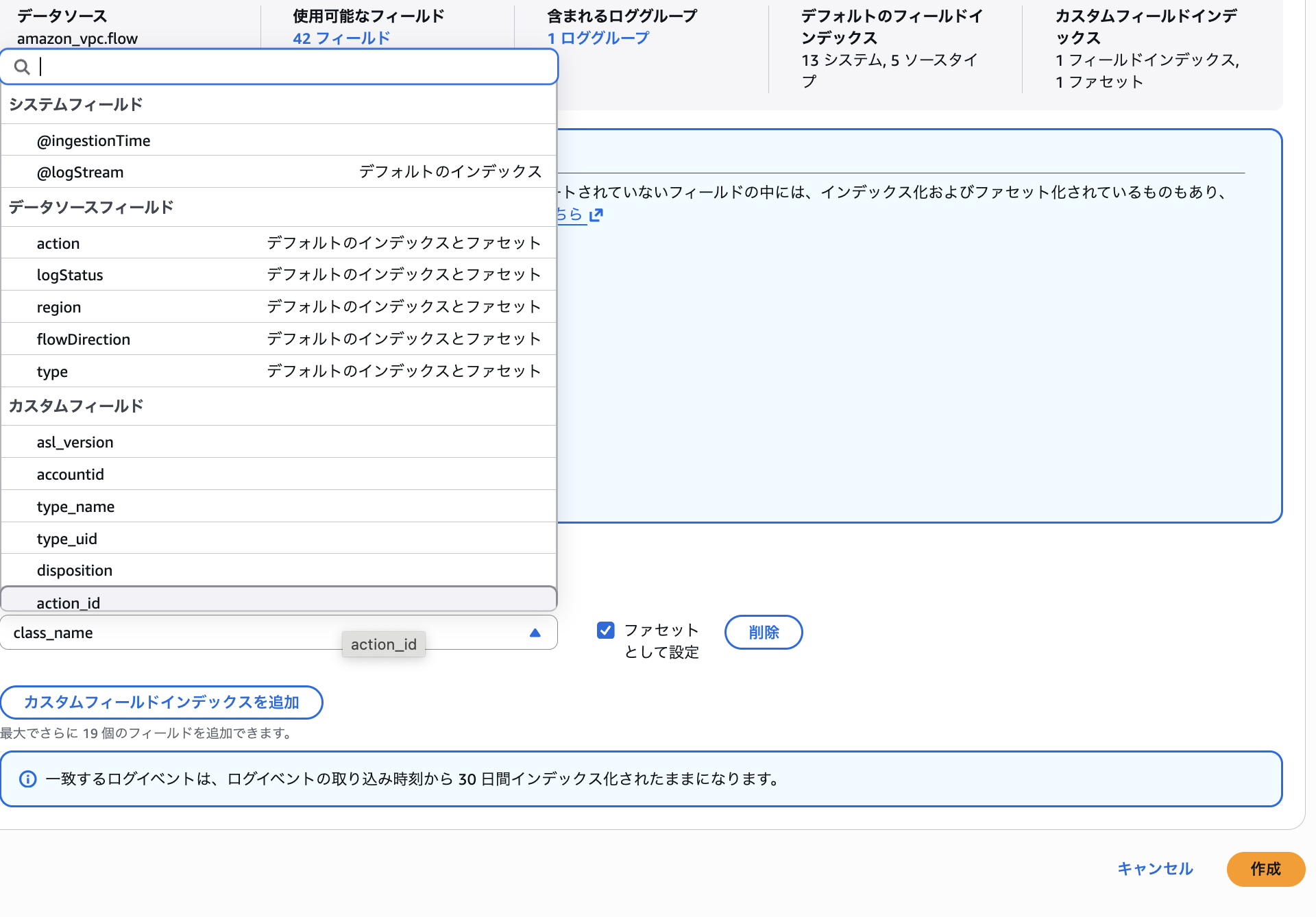
今回は type_name を選択して、インデックスおよびファセットの対象として追加します。
ログクエリ画面に戻ると、ファセット画面に type_name が増えていることがわかります。
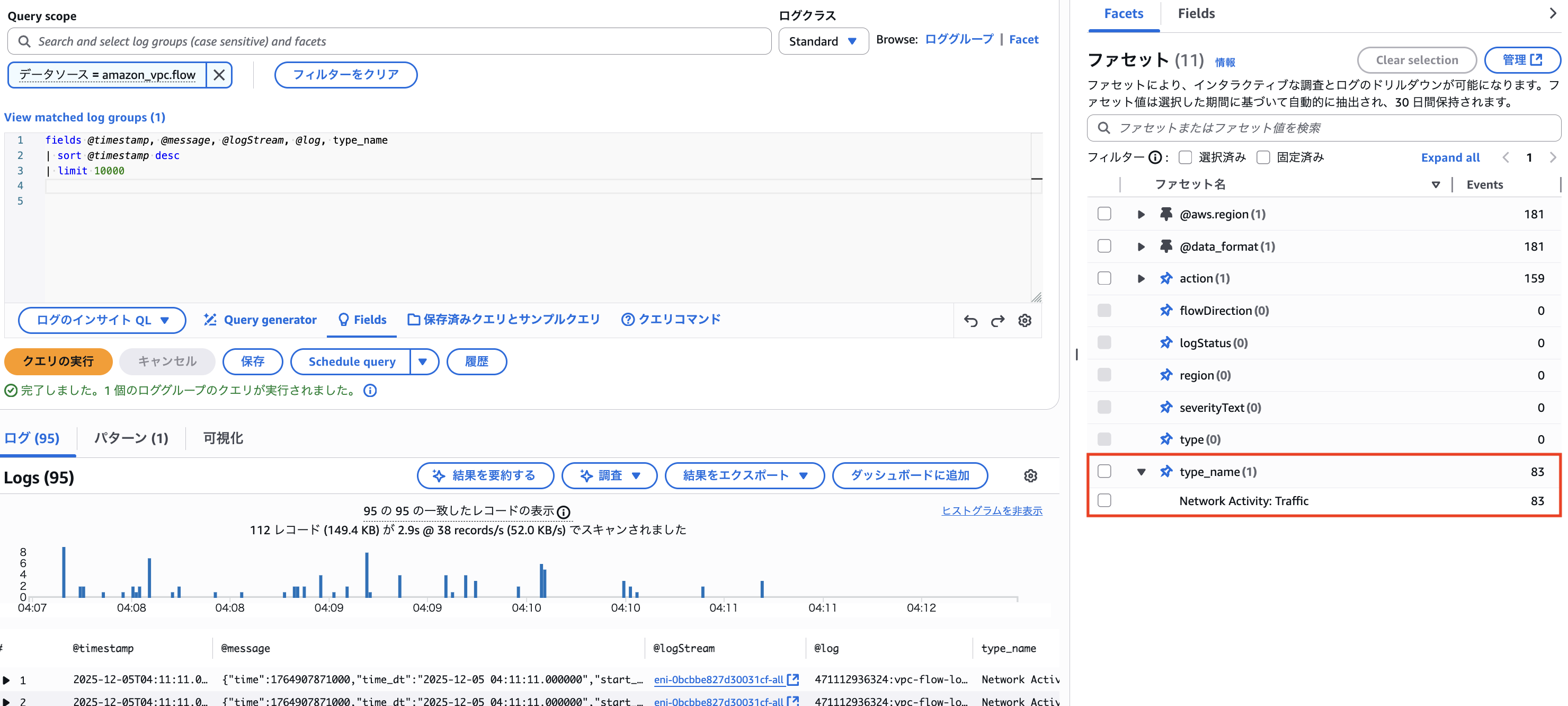
また、filterIndex としても指定することができました。
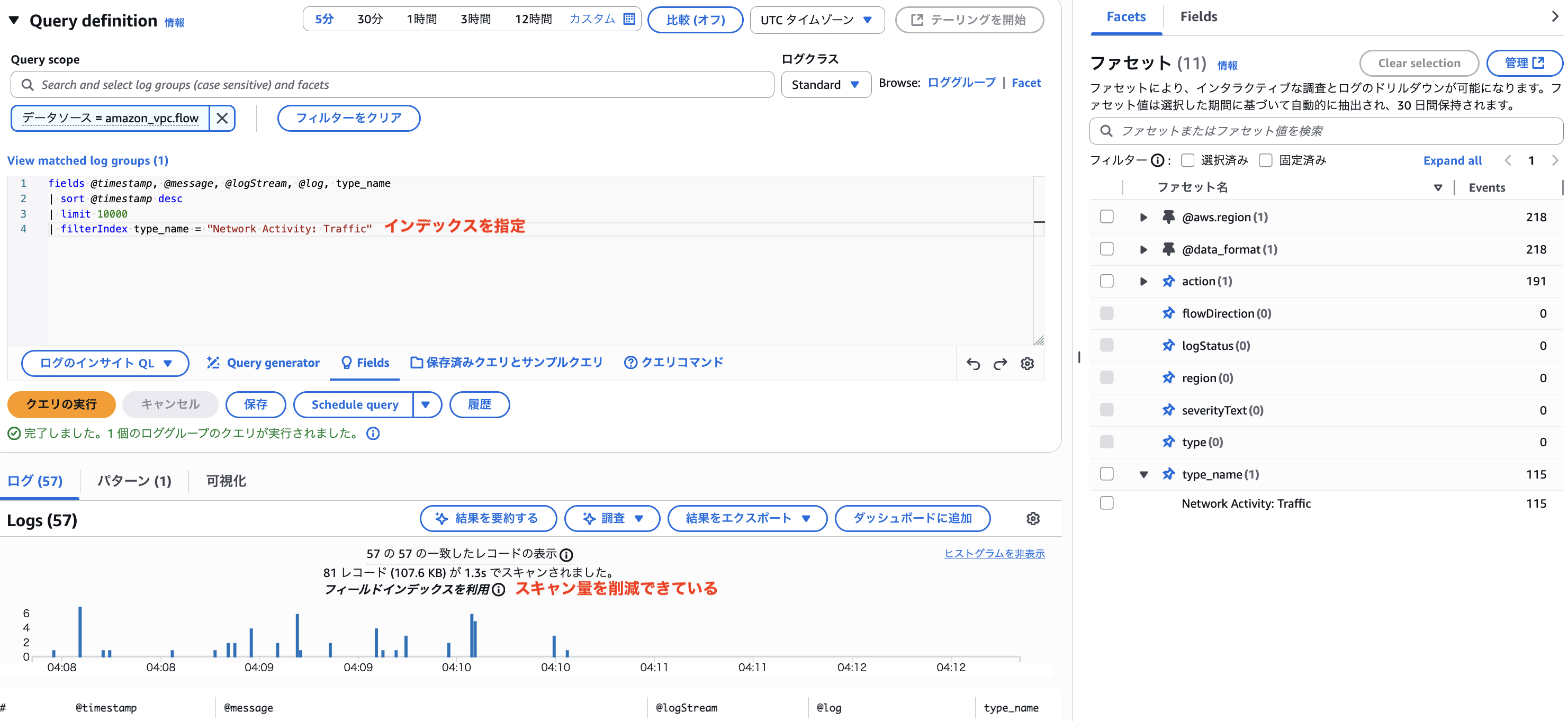
action と違ってほぼ全てのログに Network Activity Traffic が指定されているので、スキャン量削減効果は大したこと無いですが、インデックスとしては利用できてそうです。
最後に
カスタムログについてもタグベースでデータソースを検出させつつ、データソースごとにインデックスを作成することが可能です。
また、ファセット分析を行った場合は自動で filterIndex を明示的に指定した際と同等のスキャン量削減効果がありそうでした。
データソースの自動検出もインデックスを利用したスキャンも無料で利用できるので、ガンガン使っていきたいですね。










