![[レポート]インシデント解決の加速:AI駆動の原因究明(根本原因の分析)に参加しました。#AWSreInvent #COP320](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート]インシデント解決の加速:AI駆動の原因究明(根本原因の分析)に参加しました。#AWSreInvent #COP320
はじめに
こんにちは。AWS re:Invent2025 に参加しているオペレーション部のshiinaです。
現地よりビルダーズセッション「インシデント解決の加速:AI駆動の原因究明(根本原因の分析)#COP320」のレポートをお伝えします。
セッション概要
タイトル
インシデント解決の加速:AI駆動の原因究明(根本原因の分析) #COP320
詳細
クリティカルなインシデントが発生したとき、1分1秒が勝負です。本セッションでは、AIを活用してインシデント対応と根本原因分析のプロセスを大幅に高速化する方法を紹介します。Amazon CloudWatch のインベスティゲーション機能を使い、実際の現場を想定したシナリオを通じて、AIによるインサイトを体験します。自然言語でのクエリやアラームトリガーからガイド付きインベスティゲーションを起動する練習を行い、生成AIを使ってメトリクス、ログ、デプロイイベントなどのテレメトリデータを横断的に関連付けながら、システムの状況を素早く分析する方法を学びます。さらに、AIが提案する分析結果を評価し、根本原因をより効率的に特定して MTTR(平均復旧時間)を大幅に短縮するための実践的なスキルを身につけます。
スピーカー
- Natassa Eleftheriou,Sr Technical Account Manager, aws
- Jose Augusto Ferronato,Solutions Architect, AWS
- Siddhesh Kumbhare,Sr. Technical Account Manager, Amazon Web Services
- Dan Malloy,Technical Account Manager, AWS
- Ravikumar Sola,Enterprise Support Lead, AWS
レベル
300

運用におけるボトルネック
大規模システム運用では、技術よりも人や組織、データの扱いがボトルネックになりがちです。
ログやメトリクスが不足していたり、逆に散らばりすぎて活用できないと、障害時の原因特定と復旧が大きく遅れます。
さらに、担当者の属人化、教育不足などのでインシデントの初動対応を難しくします。

インシデントのライフサイクル
インシデントは次のライフサイクルで進みます。
- 検知(アラーム・テレメトリ・問い合わせ)
- 調査(影響把握・一次対応)
- 復旧
- 振り返り・根本原因分析
AWS が重視する根本原因分析のポイント
AWS では障害が起きるたびに詳細な根本原因分析を実施しています。
根本原因分析は"インシデントの犯人探し"ではなく、"なぜこの設計・運用だと再発しうるのか"を突き止め、二度と同じ失敗をしない構造に変えることが目的となります。
実務でできる5つのアクション
現場で今すぐ取り組めるアクションは次の通りです。
-
インストルメンテーションとオブザーバビリティの改善
各アプリケーションで必要なログ・メトリクス・トレースを明確化し、取りすぎ・取りなさすぎを避け、トラブルシュートに使える粒度で整備します。 -
直近インシデントの根本原因分析とナレッジ化
障害報告書(ポストモーテム)を作成し、技術的要因・組織的要因の両方を整理し、得られた教訓をドキュメントや勉強会を通じてチームに共有する。 -
インシデント対応プロセスの見直し
検知から復旧までのフローを可視化し、インシデント対応時の役割(司令塔など)を明確にします。 -
アラームの一元管理とチューニング
アラームがバラバラのツールに散らばっていないか確認し、本当に重要なものが埋もれないよう、しきい値や通知ルールを見直します。 -
重要システム向けの監視・予防策強化計画の策定
ビジネスへの影響が大きいシステムから優先的に、監視項目・テスト・冗長構成などの予防策ロードマップを作る。
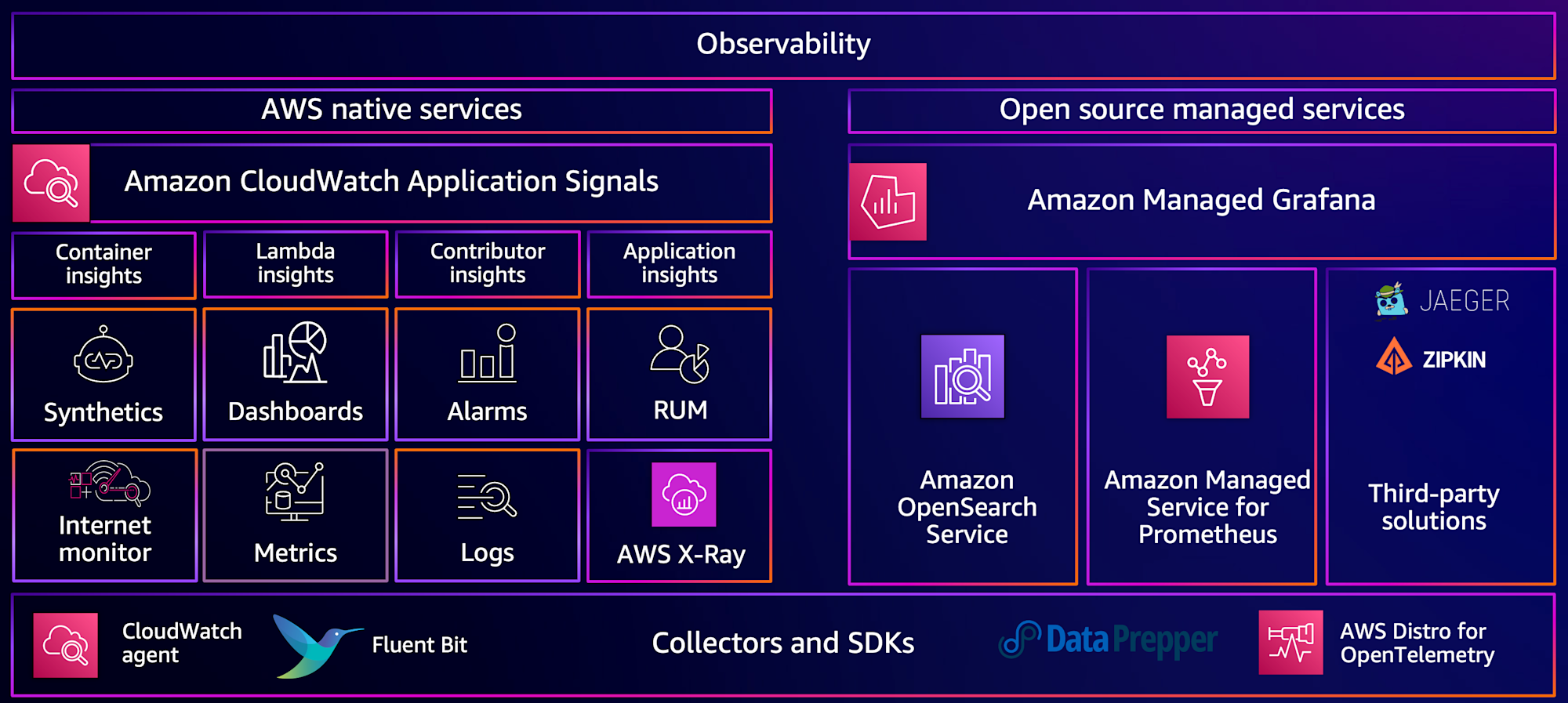
オブザーバビリティのベストプラクティス
ベストプラクティス集は下記 URL より確認できます。
- AWS Observability Best Practices
https://aws-observability.github.io/observability-best-practices/
ワークショップをやってみた
ワークショップでは、CloudWatch Application Signals、Cloudwatch Investigations、AI オペレーションを利用してマイクロサービスベースのアプリケーションのインサイトを発見する方法を実践しました。
具体的なシナリオは次の通りです。
- MongoDBの障害
- DynamoDBのスロットリング
- RDSの書き込みレイテンシ上昇
- Kubernetes リソース制限抵触
- インタラクティブなインシデントレポート
SLO 作成と AI オペレーション調査
はじめに対象サービスのサービスレベル目標(SLO)を定義を行いました。
SLO 違反が発生した際に、AI オペレーションで自動的に調査を開始し、インシデント検知〜原因推定までを行いました。

アラームからの調査とランブック実行
CloudWatch アラームをトリガーとして調査を行います。
AI オペレーションが提示する仮説をもとに、対応ランブック(手順書)を実行し、問題を修正する一連の手順を体験しました。

Kubernetes リソース制限の問題対応(EKS)
Kubernetes リソース制限が原因でサービスが不安定になるシナリオを扱いました。
SLO 違反を検出した際に AI オペレーション経由で調査を実施し、問題特定を行いました。

インシデントレポート生成
AI オペレーションによるインシデントレポート機能では以下の情報が整理されて出力されます。
- イベントのタイムライン:テレメトリから自動抽出された時系列
- 根本原因分析:受け入れられた仮説に基づく根本原因
- 影響評価:調査テレメトリから導出される影響範囲
- 是正措置:推奨される修復・改善手順
- 学んだ教訓:AWS ベストプラクティスに沿った学びのまとめ
なお、エクスポートも可能なのでポストモーテムや社内共有に活用できます。
最後に
今回のセッションを通して、AI は運用チームが本質的な判断や改善に集中できるようにサポートしてくれる存在だと感じました。
SLO 違反をきっかけにした AI オペレーションによる自動調査やインシデントレポートの自動生成などは運用効率化につながりそうです。
一方で、オブザーバビリティの整備やインシデント対応プロセスの見直しといったことも重要と感じました。
#AWSreInvent
#COP320








