
AWS再入門ブログリレー AWS Glue編
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
当エントリは弊社コンサルティング部による『AWS 再入門ブログリレー 2019』の14日目のエントリです。
このブログリレーの企画は、普段AWSサービスについて最新のネタ・深い/細かいテーマを主に書き連ねてきたメンバーの手によって、今一度初心に返って、基本的な部分を見つめ直してみよう、解説してみようというコンセプトが含まれています。
AWSをこれから学ぼう!という方にとっては文字通りの入門記事として、またすでにAWSを活用されている方にとってもAWSサービスの再発見や2019年のサービスアップデートのキャッチアップの場となればと考えておりますので、ぜひ最後までお付合い頂ければ幸いです。
では、さっそくいってみましょう。14日目のテーマは『AWS Glue』です。
目次
AWS Glueとは
AWS GlueはフルマネージドなETL(抽出、変換、ロード)サービスです。
S3やRDS、Redshift等の各種AWSサービスとの連携を管理してくれるので、利用者は本来取り組むべき作業である、ETLジョブの作成や監視といった部分に注力出来るようになります。
各種AWSサービスの間を繋ぐ「糊(Glue)」として処理を構成・実行する形となります。
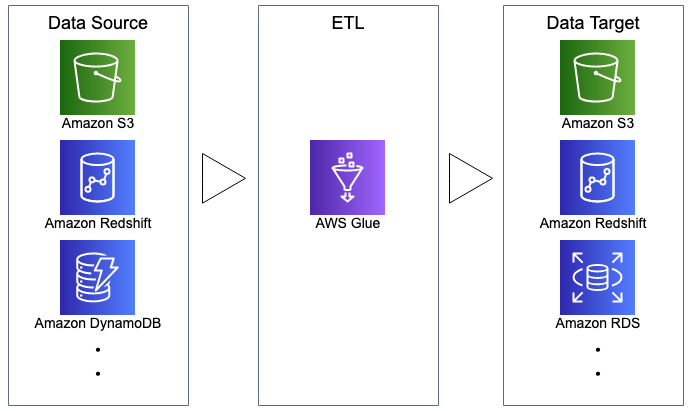
AWS Glueの概念・構成要素
AWS Glue実行環境(構成要素)のイメージです。
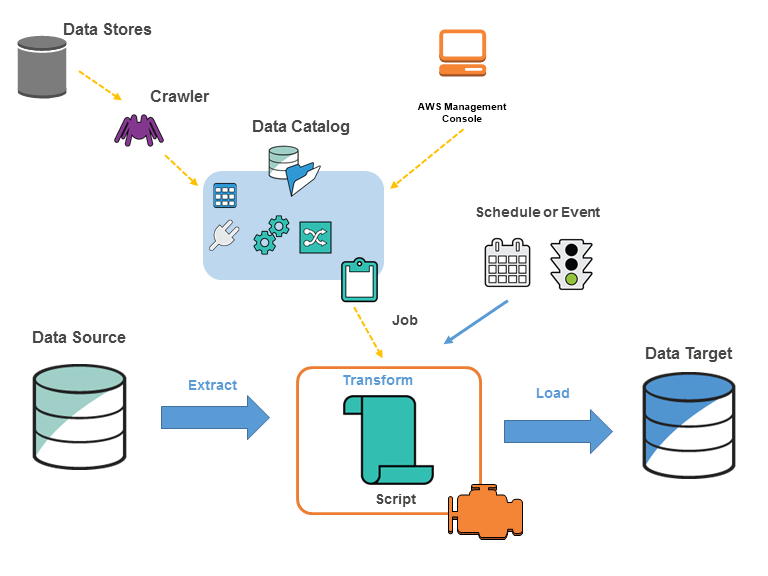
AWS Glueでは通常、以下のアクションでETLを実施します。
- データソースをクロールし、データカタログにメタデータテーブルを作成
- データカタログの情報を元にジョブを定義
- ジョブ定義に基づいてETLの雛形コードが自動生成
- ジョブ実行で、データソースからデータを抽出し、変換してデータターゲットにロード
以下、構成要素の説明になります。
データストア、データソース、データターゲット
データストアは、データを永続的に保存するリポジトリです。Amazon S3、リレーショナルデータベース等がそれにあたります。データソースは、AWS Glueで行うETLの入力としてとして使用されるデータストアです。データターゲットは、書込み先(ロード)のデータストアです。
データカタログ
永続的なメタデータストアです。各AWSアカウントで1つのデータカタログを持ち、ETLに必要なテーブル定義、ジョブ定義、およびその他の制御情報を保持します。
クローラ
データカタログにメタデータテーブルを作成するプログラムです。データストア(ソースまたはターゲット)に接続し、クロールしたデータは分類され、スキーマ情報を抽出します。
クロール可能なデータストアは、ファイルベース、テーブルベースのデータストアに対応しており、S3、DynamoDB、RDS、Redshift等をクロールすることができます。
ジョブ
ETL作業を実行するために必要なビジネスロジックです。データカタログのデータを使用して、データを変換するジョブを定義できます。 変換スクリプト、データソース、およびデータターゲットで構成され、サーバレスなApache Spark環境で実行されます。ジョブはオンデマンドや、スケジュール、イベントトリガーで実行することが可能です。
ジョブにはSparkと、Python Shell2つのタイプがあります。
Sparkタイプは、Sparkのクラスタを制御して大規模分散処理します。ジョブを起動すると1つのDriverと複数のExecutorが起動され、スクリプトはDriverで実行されます。
Python Shellタイプは、単にPythonスクリプトを実行する目的のジョブです。Python 2.7またはPython 3.6と互換性のあるスクリプトが実行可能です。
料金体系
データカタログ、クローラ、ジョブに対し料金が設定されていて、それらの合計となります。
クローラとジョブの料金計算はやや特殊で、DPU (Data Processing Unit) という数に基づいて時間(1秒)ごとに課金が発生します。
データカタログ
データカタログは、オブジェクト数とアクセスリクエスト数に応じて月額料金がかかります。
- 100万オブジェクトの格納まで無料、以降10万オブジェクト毎に1ドル/月
- 毎月100万リクエストまで無料、以降100万リクエスト毎に1ドル/月
クローラ
各クローラーには2DPUが割り当てられ、クローラーの実行で使用されたDPU時間が課金されます。
1DPU 0.44ドル/時で、10分未満の処理は10分として計算されます。
ジョブ
ジョブの実行に費やしたDPU時間が課金されます。
1DPU 0.44ドル/時で、10分未満の処理は10分として計算されます。 使用されるDPUの数はジョブの設定により異なります。
詳細については以下をご確認ください。
チュートリアルをやって理解を深めよう
AWS Glueでは、コンソールのメニューに「チュートリアル」が存在します。
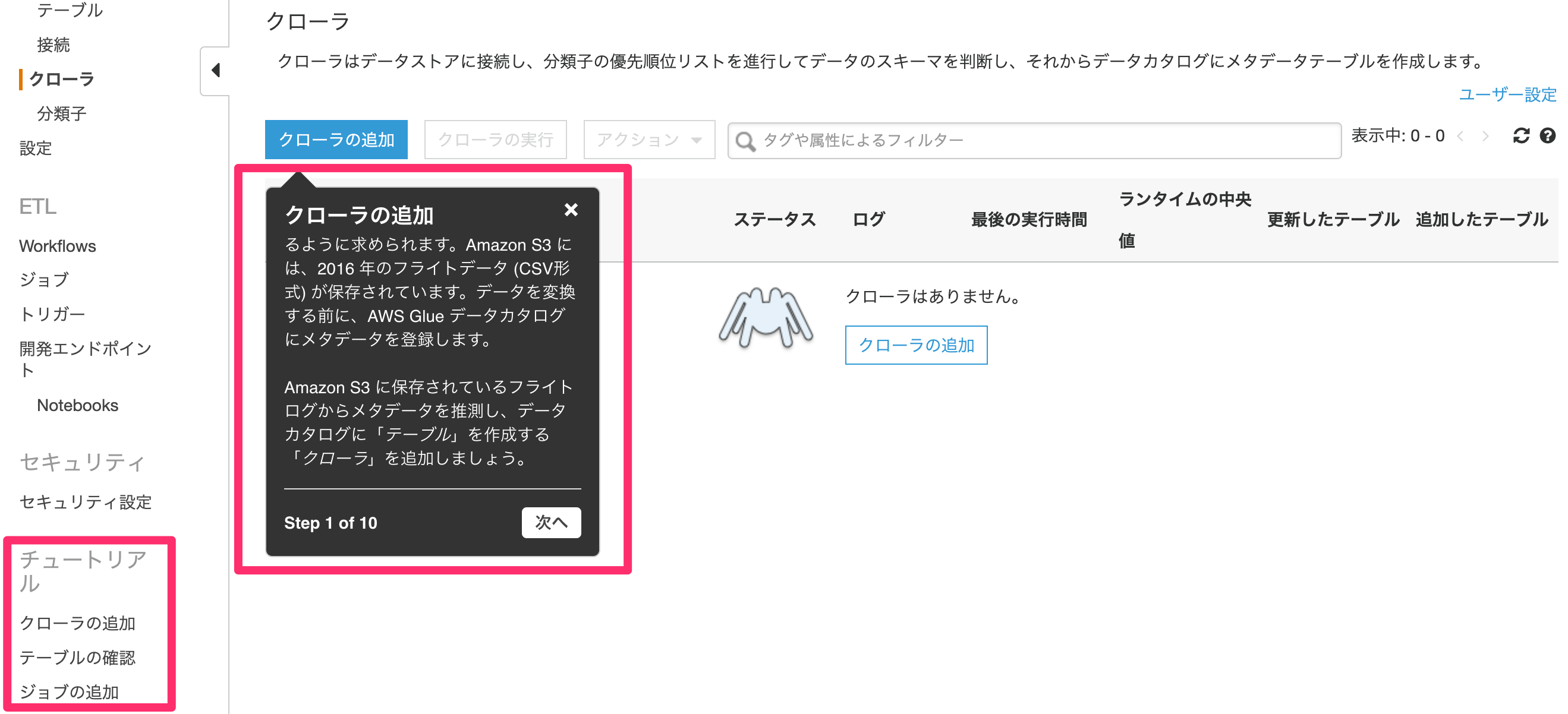
チュートリアルは「S3上にアップロードされているCSVファイルをParquet形式に変換」するというユースケースとなります。 現在、日本語でガイドがあり、とても分かり易い内容となっています。
以下のエントリで、チュートリアルを解説していますので、こちらを参考に実施してみてはいかがでしょうか。
Redshiftにデータをロードしてみた
ここではチュートリアルで用意されているS3上のデータを利用し、VPC上のRedshiftにデータをロードしてみたいと思います。
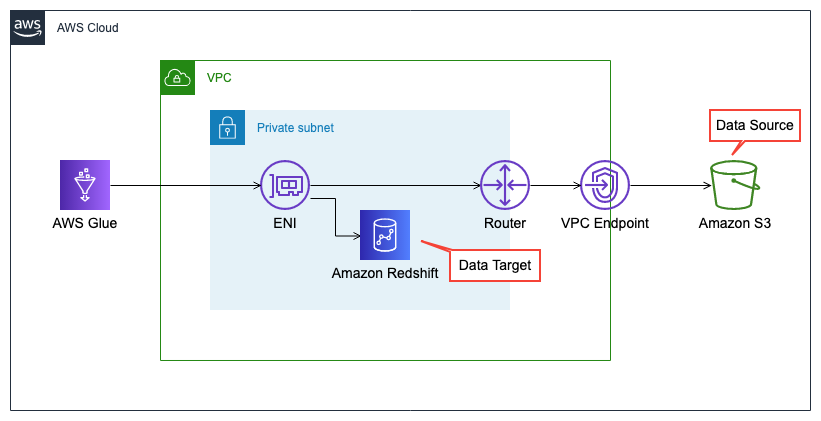
デフォルトでは、AWS GlueからVPC内のリソースにアクセスすることはできません。VPC内のリソースにアクセスできるようにするには、ルーティング設定やセキュリティグループ等、追加の設定が必要になります。
AWS Glueが、VPC内のリソースにアクセスする場合は、ENI経由でのアクセスとなり、すべての TCP ポートに対して自己参照のインバウンドルールを持つセキュリティグループが必要です。
また、ここではデータソースをS3にしているので、プライベートサブネット(のENI経由)からアクセスするために、S3へのVPCエンドポイントが必要となります。
今回の検証で必要になる、VPCやRedshiftについては、CFnテンプレートを用意しましたので、AWS Glue以外の構築手順については割愛しています。
AWS Glueを除くリソースが既に構築済み(上記CFnテンプレート実行後の状態)の前提で進めていきたいと思います。
データターゲット(Redshift)の事前確認
データターゲットはRedshiftになります。ETL実施前にロード先のスキーマを確認してみたいと思います。 ここではQuery editorを利用して、データベースにアクセスします。
Redshiftのコンソールより「Query editor」をクリックします。
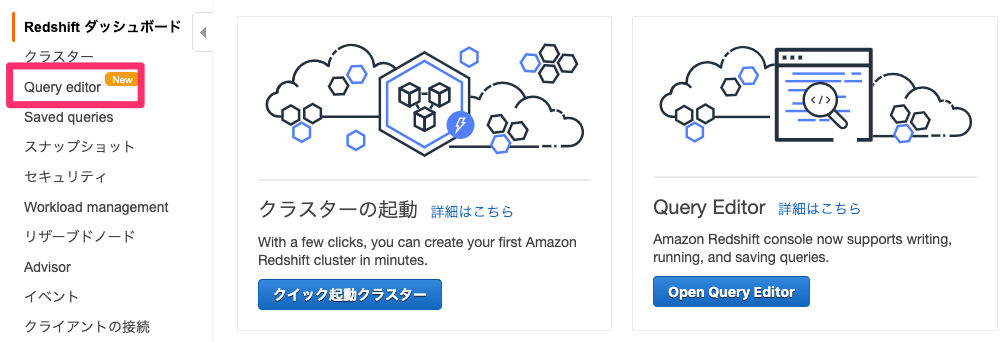
RedShiftに作成したデータベースの認証情報を入力し「接続」をクリックします。
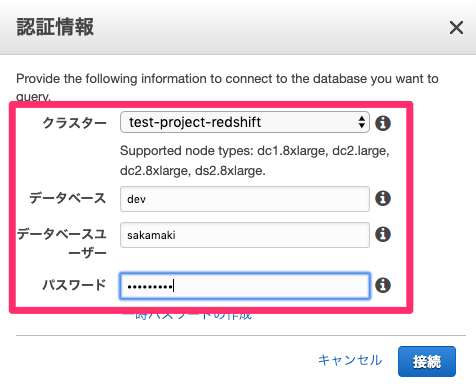
この時点ではスキーマ内にテーブルはありません。
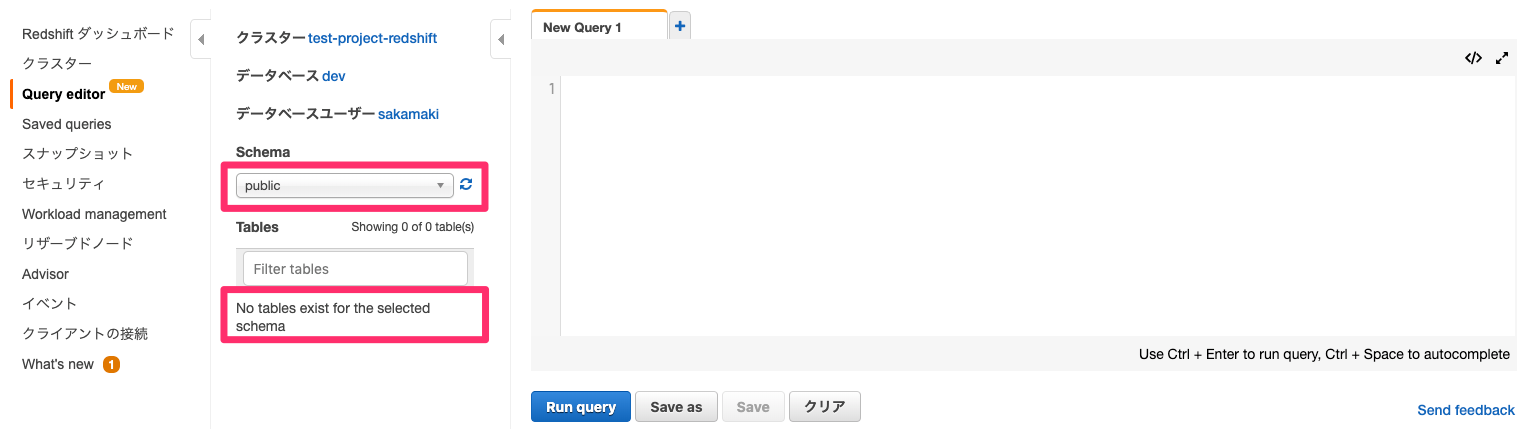
クローラの作成
AWS Glueにてデータカタログにメタデータテーブルを作成します。クローラの作成はチュートリアル「クローラの追加」と同様のため、手順は割愛します。チュートリアル実施後は、データカタログに「flightscsv」テーブルが作成されます。

ジョブの追加と実行
ETLを実施するジョブを作成していきます。「ジョブ」をクリックします。
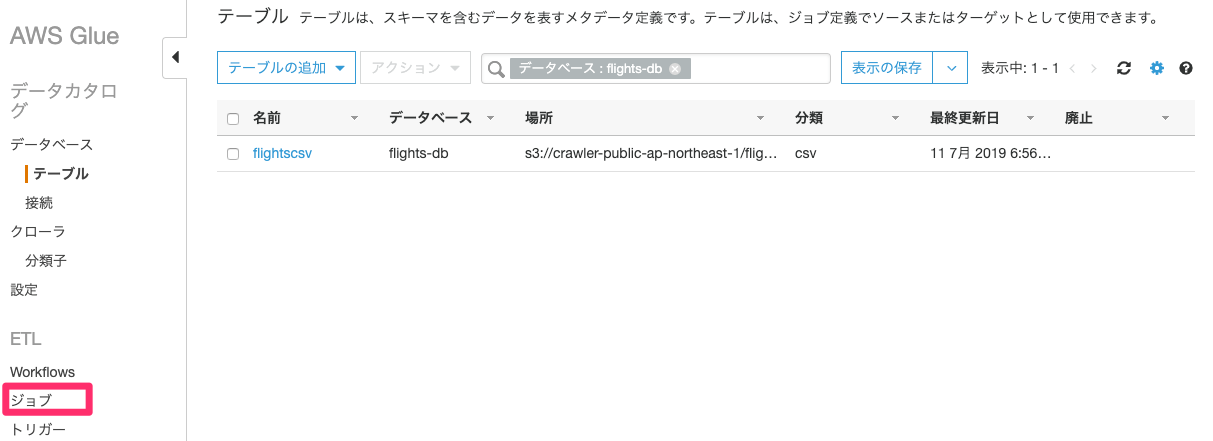
「ジョブの追加」をクリックします。
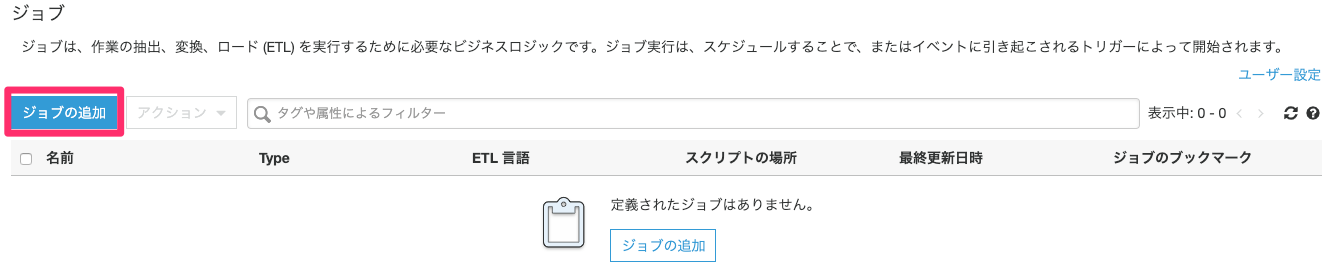
任意のジョブ名を入力し、クローラ作成時に使用したIAMロールを選択し「次へ」をクリックします。
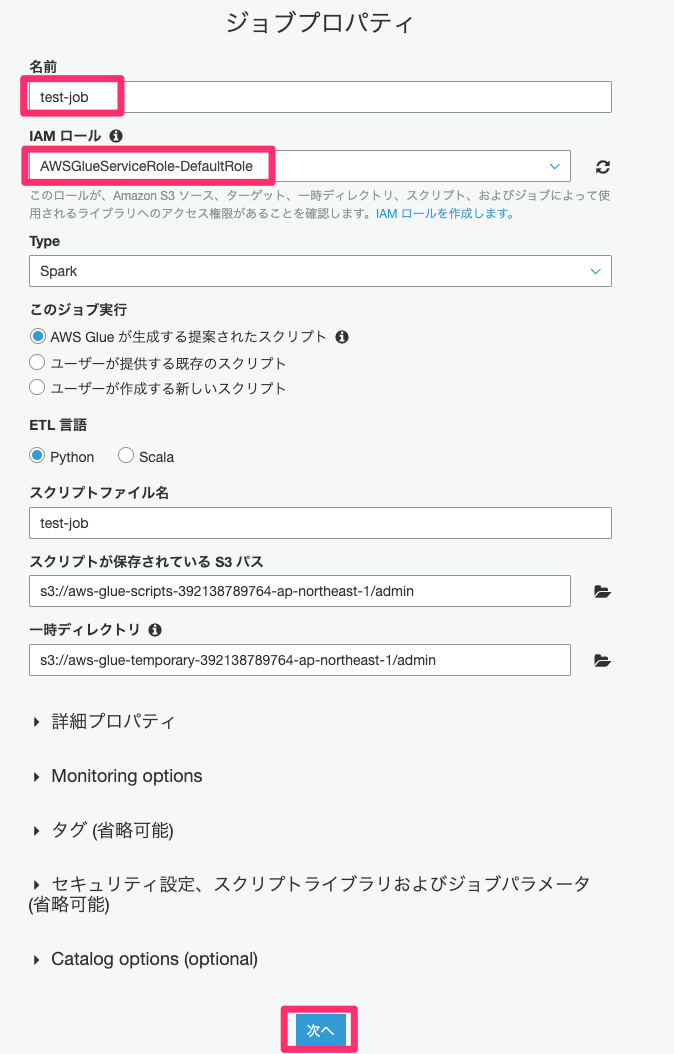
データソースにS3上の「flightscsv」を選択して、「次へ」をクリックします。
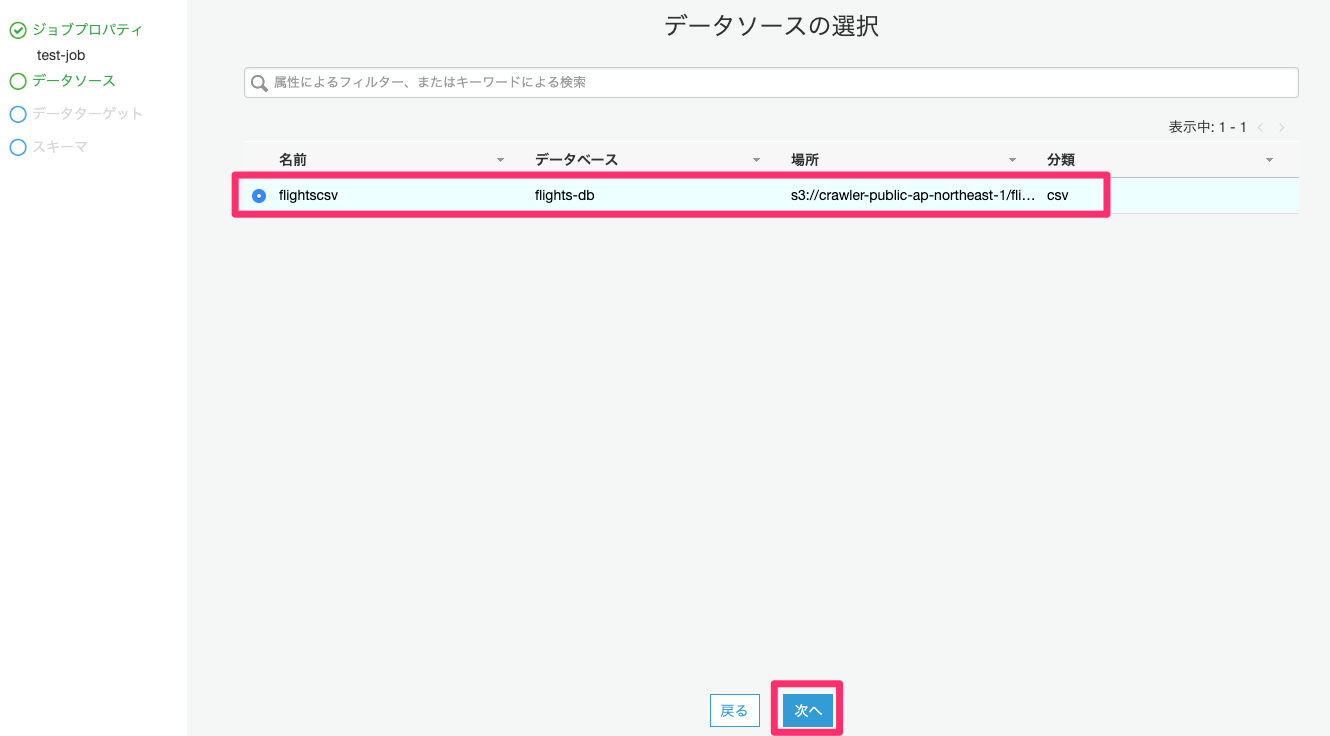
「データターゲットでテーブルを作成する」を選択します。
「接続の追加」をクリックします。
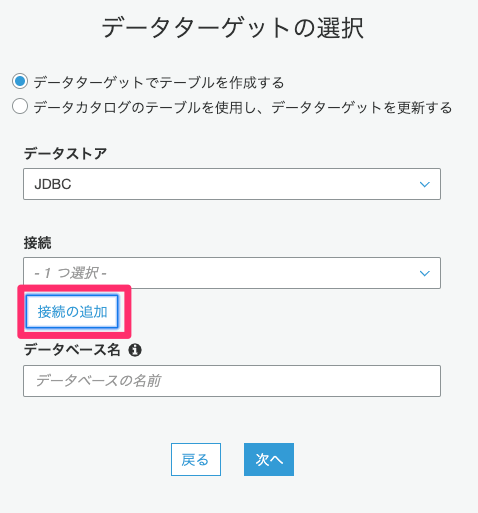
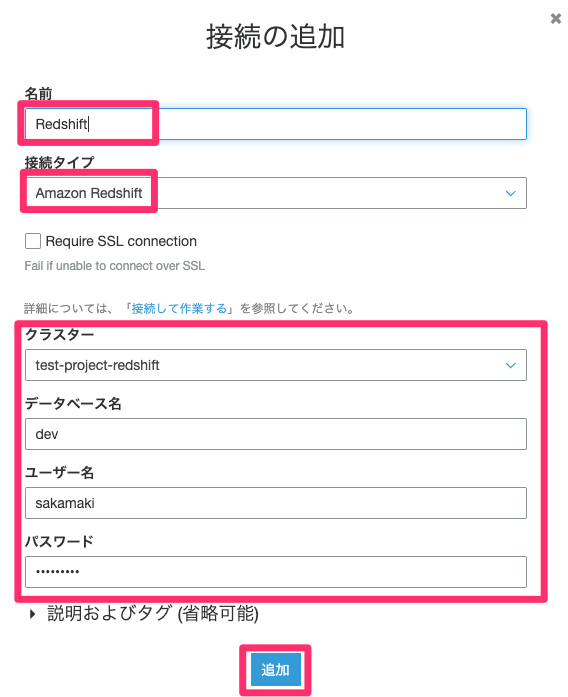
任意の接続名(ここではRedshift)を入力し、接続タイプは「Amazon Redshift」を選択します。事前に作成しているRedshiftの認証情報を入力し「追加」をクリックします。
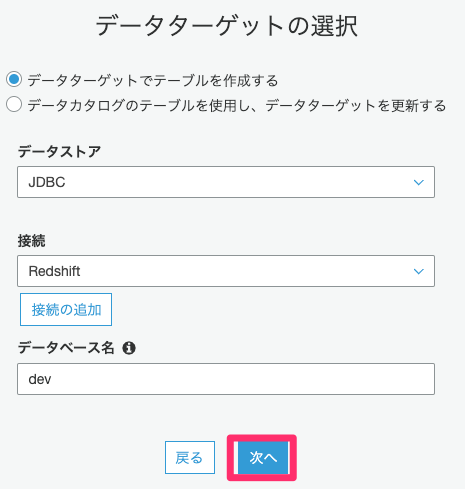
「次へ」をクリックします。
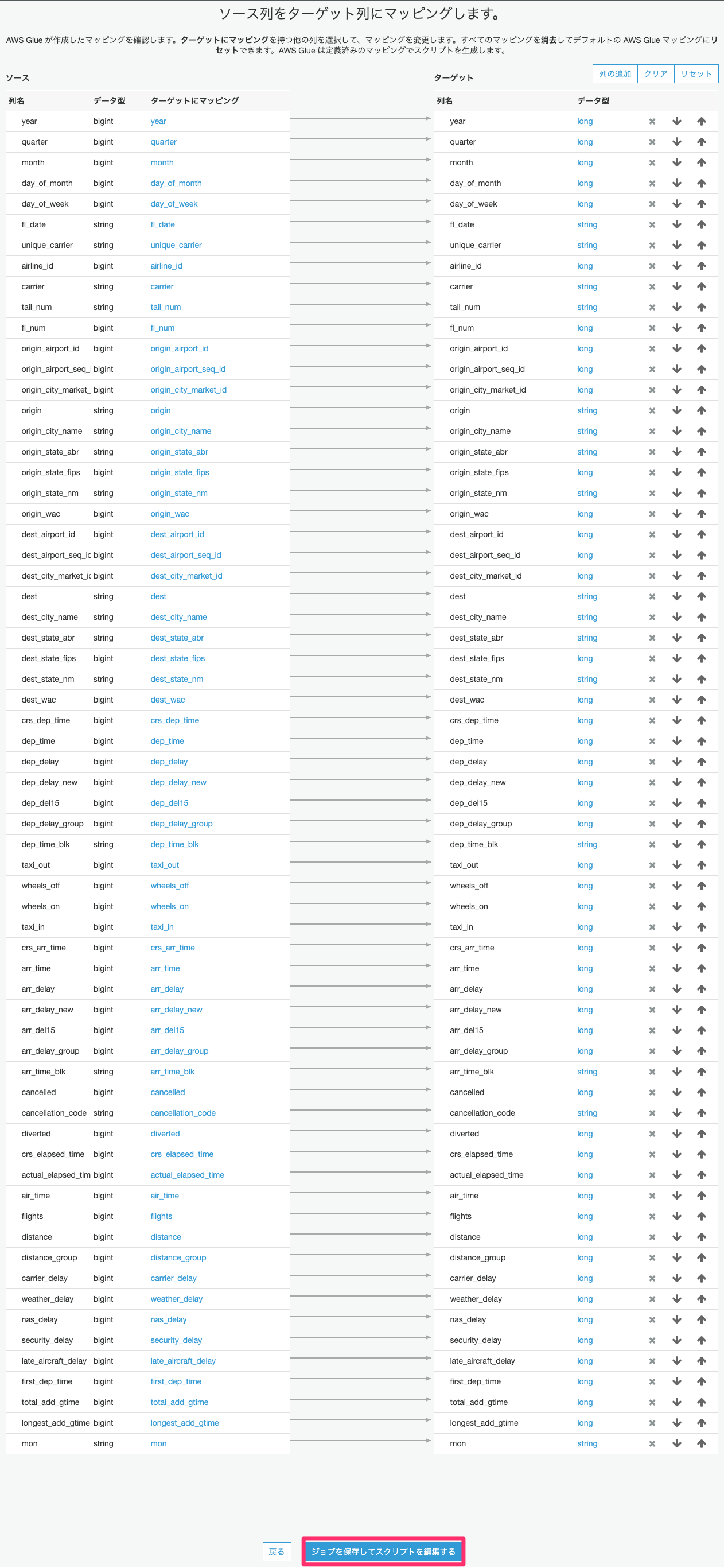
ソースデータのカラムの選択や型変換等はこちらで可能ですが、ここでは変更せず「ジョブを保存してスクリプトを編集する」をクリックします。
指定したジョブ定義に基づいて、ETLのコードが自動生成されます。こちらでコードを編集することが可能ですが、ここでは変更せず「ジョブの実行」をクリックします。
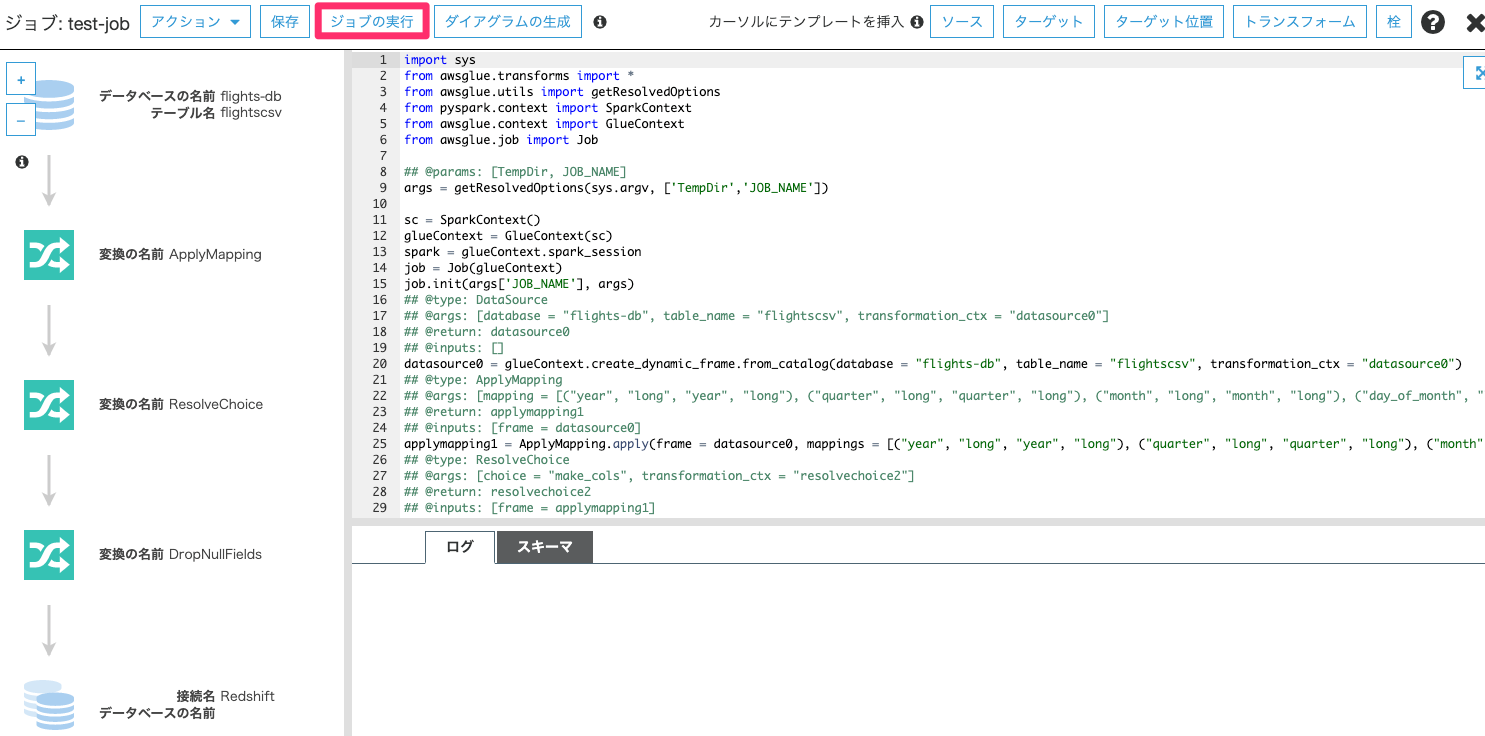
「ジョブの実行」をクリックします。

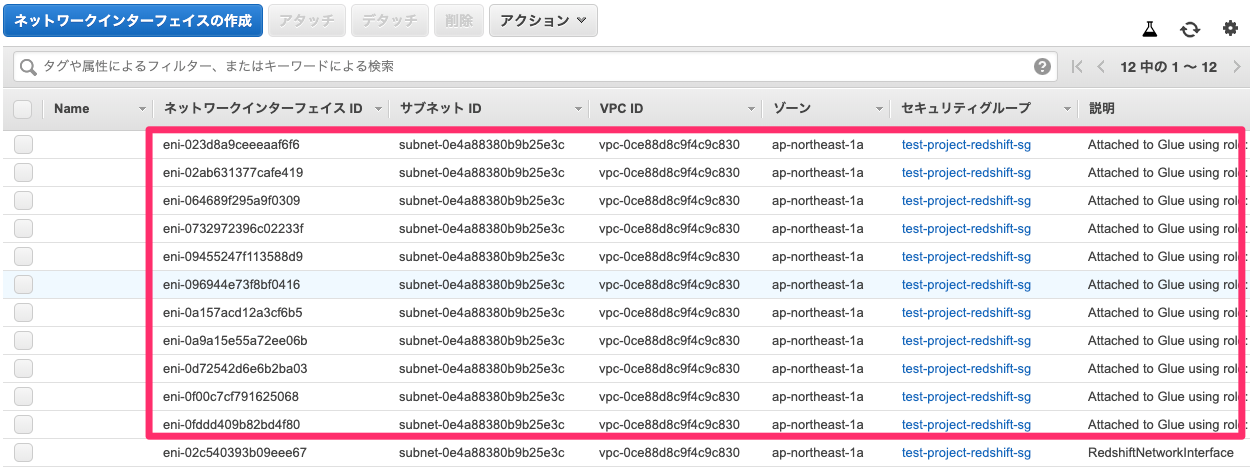
ジョブ実行すると、AWS Glueが指定したプライベートサブネット上にENIを作成します。ENIに割り当てられたプライベートIPで、VPC内のリソースにアクセスします。(S3へのアクセスはENI、VPCエンドポイント経由)
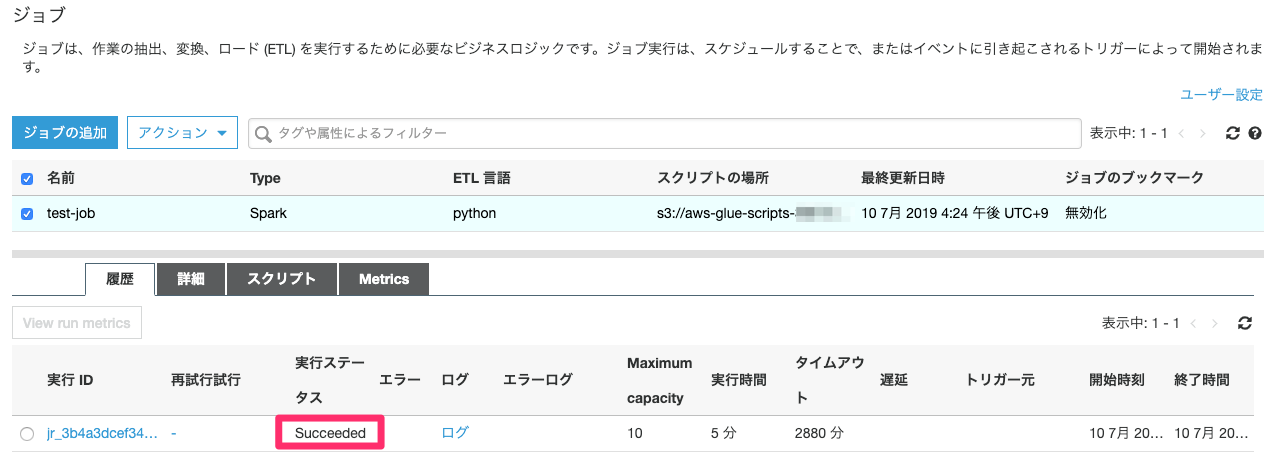
ジョブの実行ステータスが「Running」から「Succeeded」に変わればジョブは完了です。
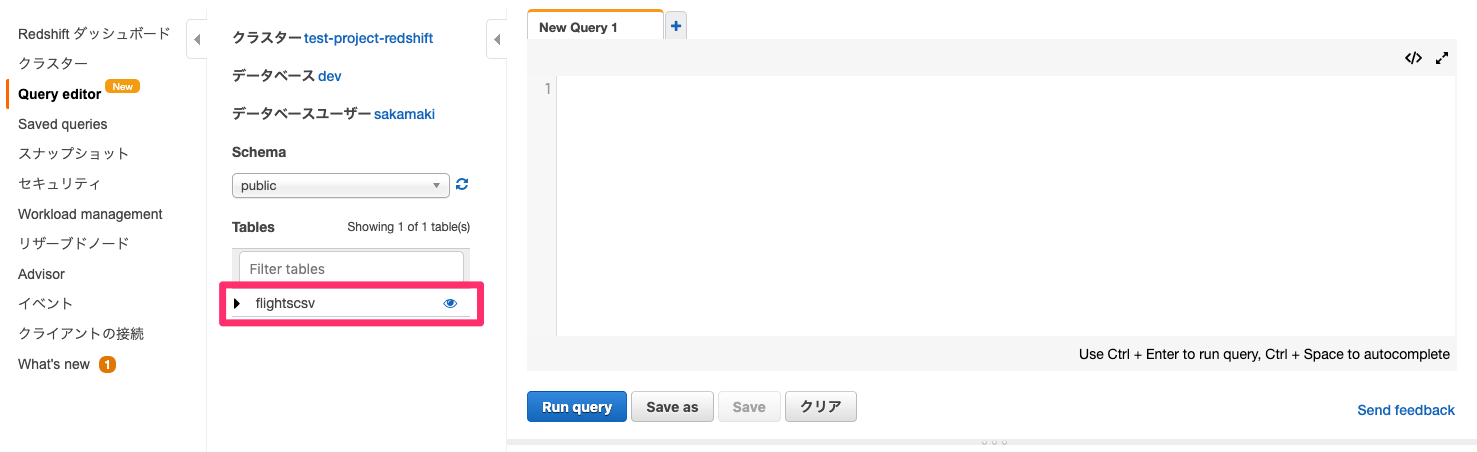
データターゲット(Redshift)の確認
ETLジョブ完了後にRedshiftのスキーマを確認してみると、スキーマ内に「flightscsv」テーブルが作成されています。
クエリを発行するとテーブル内のデータが確認できます。
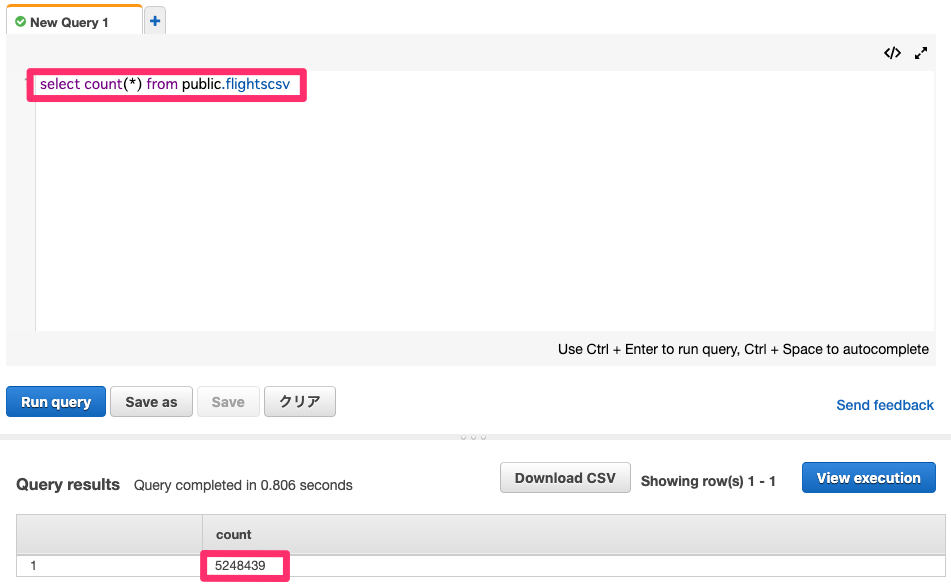
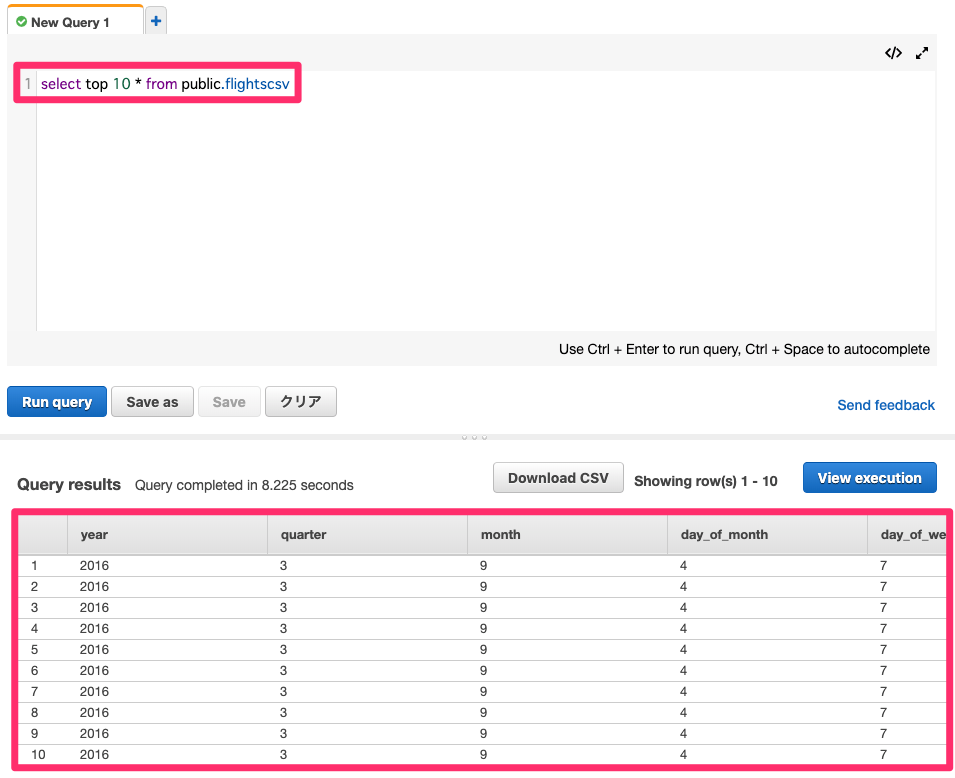
AWS Glueを利用しETLが実施できました!!
さいごに
以上、『AWS サービス別 再入門ブログリレー 2019』の6日目のエントリ『AWS Glue』でした。実際に動かしてみると構成や処理のイメージ等について理解が深まる思います。本エントリが、AWS Glueの利用を検討している方の第1歩になれば幸いです。
次回(7/22)はまさをの「Amazon WorkSpaces」の予定です。お楽しみに!








