
S3にCSVを置くだけでDynamoDBにマスターデータを投入する仕組みをAWS CDKで構築してみた
リテールアプリ共創部のるおんです。
アプリを開発していると、「店舗マスタ」「キャンペーン設定」といった マスターデータをどうやって投入・更新するか という問題に必ずぶつかります。RDBを採用している場合はマイグレーションファイルやシードスクリプトで対応できますが、DynamoDBのようなNoSQLではそのような仕組みがありません。
よくある選択肢としては、以下が挙げられます。
- 管理画面を作る:非エンジニアでも操作できて便利だが、UIとAPIの実装工数がそれなりにかかる
- CLIスクリプトを用意する:エンジニアがローカルから実行するシンプルな方法だが、本番実行が属人的になりやすい
- AWSコンソールからDynamoDBを直接操作する:手軽だが、ヒューマンエラーが起きやすく事故のもと
そんなときにちょうどいいのが、「S3にCSVファイルを置くだけで、自動でDynamoDBに取り込まれる」 という仕組みです。管理画面ほどの実装工数をかけず、CLIでの作業よりも優しいインターフェースでマスターデータを管理できます。
今回は、この仕組みを AWS CDK(TypeScript) でシンプルに作ってみたので紹介します。
先に結論
S3バケットの特定のフォルダにCSVをアップロードすると、S3イベントをトリガーにLambdaが起動し、CSVをパースしてDynamoDBに書き込む、という構成です。
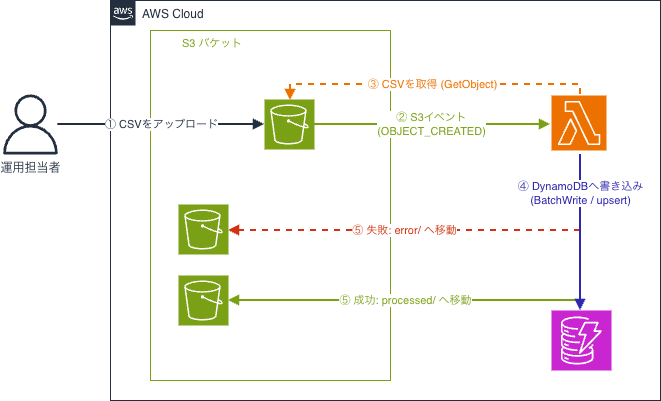
ポイントは以下の通りです。
- S3に置くだけ なので、専用の管理画面やAPIを作らなくてよい
- DynamoDBのパーティションキーで上書き されるので、「新規追加」も「既存更新」も同じCSV投入フローで完結する
- 取り込み後に
processed/・error/へファイルを移動 することで、「いつ・何が成功/失敗したか」がS3を見るだけで分かる - CDKで S3・DynamoDB・Lambda・イベント通知 をまとめて構築できる
手順の流れ
1. テストデータのCSVファイルを手元に用意
1行目はヘッダー、2行目以降がデータです。
facilityCode,facilityName,prefecture,isActive
TES01,テスト練習場01,東京都,true
TES02,テスト練習場02,神奈川県,true
TES03,テスト練習場03,大阪府,false
2. S3バケット内にuploadsフォルダに、マスターデータのCSVファイルをアップロード
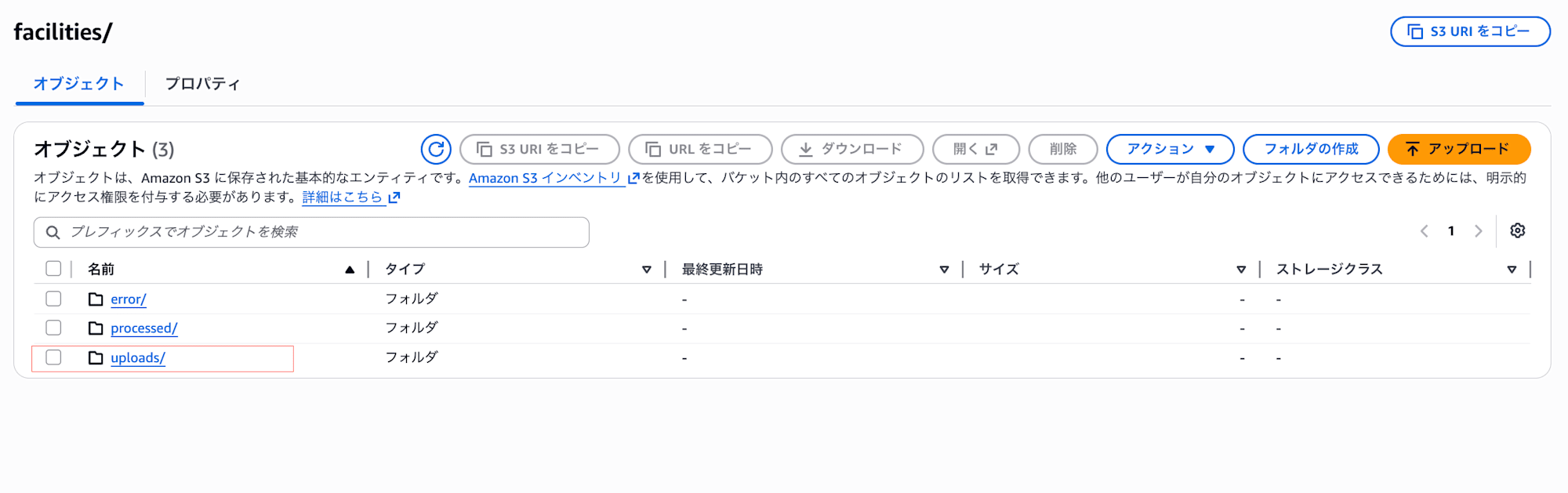
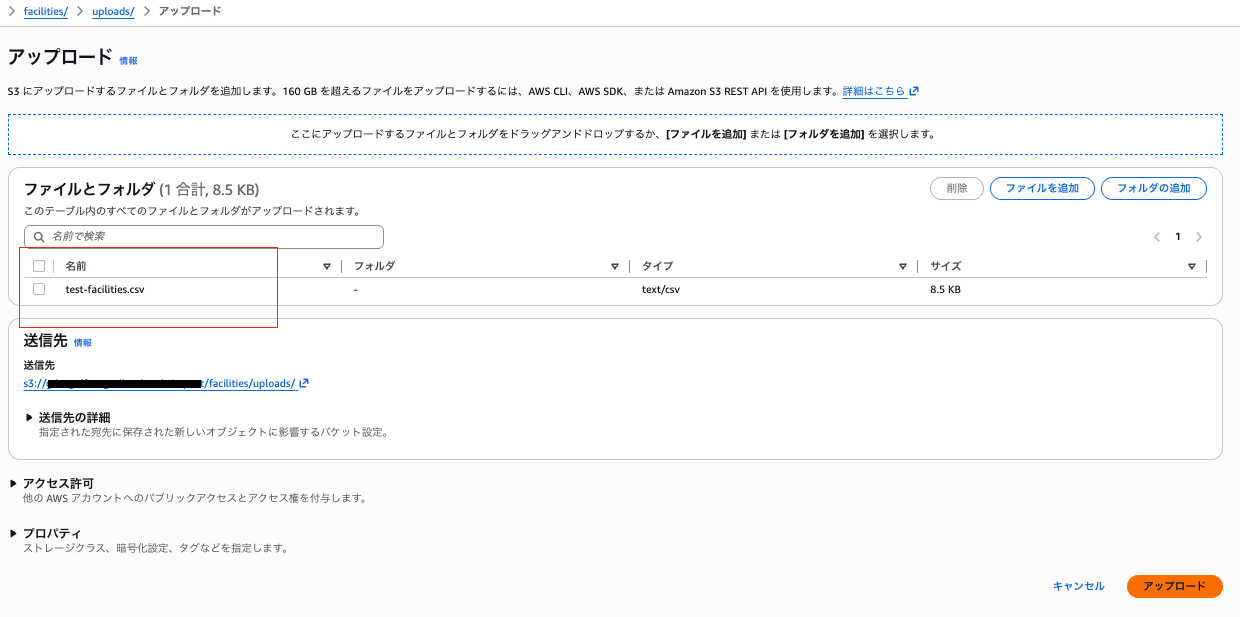
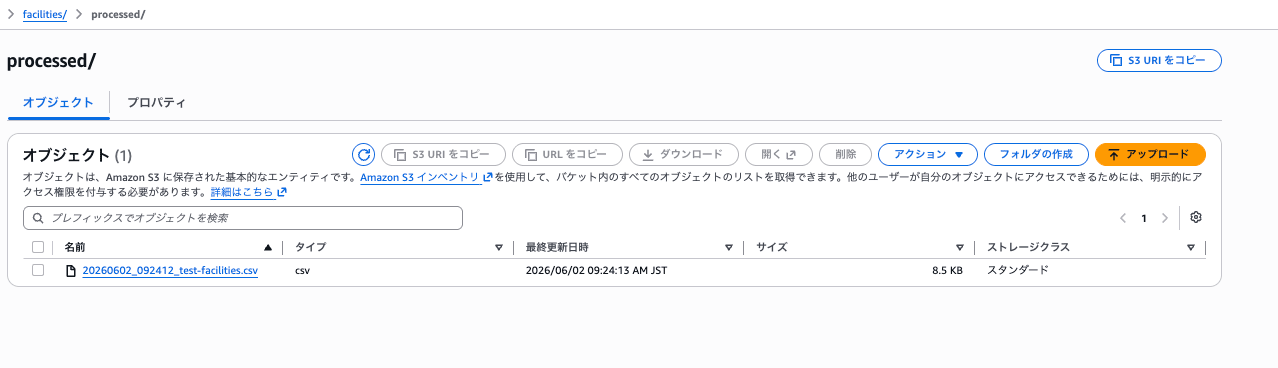
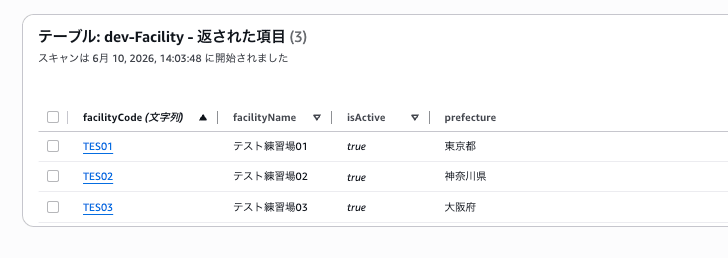
3-a. 成功すると、processed/に移動され、DynamoDBにデータが投入される
processed/フォルダに、時刻のプレフィックス付きで移動していることを確認。
DynamoDBにもCSVの内容が反映されていることを確認
3-b. 失敗するとerror/に移動される
error/フォルダに、時刻のプレフィックス付きで移動していることを確認。

構成
今回作るリソースは以下の3つだけです。
| リソース | 役割 |
|---|---|
| S3バケット | CSVのアップロード先。uploads/ に置かれた .csv をトリガーにする |
| Lambda | CSVを取得・パースしてDynamoDBへ書き込む |
| DynamoDBテーブル | マスターデータの格納先(facilityCode をパーティションキーにする) |
これらをCDKで一気に作っていきます。
やってみた
プロジェクト構成
以下のような構成で進めます。
csv-import-cdk/
├── lib/
│ └── csv-import-stack.ts # CDKスタック
├── lambda/
│ └── import-handler.ts # 取り込み用Lambda
├── bin/
│ └── csv-import.ts # エントリーポイント
└── package.json
CSVのパースには PapaParse を使うので、先に入れておきます。
npm install papaparse
npm install -D @types/papaparse @types/aws-lambda
1. CDKでS3・DynamoDB・Lambdaを作る
まずはCDKスタックです。各種リソースと権限を設定していきます。
import * as cdk from "aws-cdk-lib";
import {
aws_dynamodb as dynamodb,
aws_s3 as s3,
aws_s3_notifications as s3n,
} from "aws-cdk-lib";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
export class CsvImportStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// 1. マスターデータを格納する DynamoDB テーブル
const facilityTable = new dynamodb.Table(this, "FacilityTable", {
tableName: "facility",
partitionKey: {
name: "facilityCode",
type: dynamodb.AttributeType.STRING,
},
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
removalPolicy: cdk.RemovalPolicy.DESTROY, // 検証用
});
// 2. CSV をアップロードする S3 バケット
const bucket = new s3.Bucket(this, "CsvImportBucket", {
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
encryption: s3.BucketEncryption.S3_MANAGED,
removalPolicy: cdk.RemovalPolicy.DESTROY, // 検証用
autoDeleteObjects: true, // 検証用
});
// 3. 取り込み用 Lambda
const importFn = new NodejsFunction(this, "CsvImportFunction", {
runtime: Runtime.NODEJS_22_X,
entry: "lambda/import-handler.ts",
handler: "handler",
timeout: cdk.Duration.seconds(60),
environment: {
FACILITY_TABLE_NAME: facilityTable.tableName,
},
});
// 4. 権限付与(Lambda → S3 / DynamoDB)
bucket.grantReadWrite(importFn);
facilityTable.grantWriteData(importFn);
// 5. S3 イベント通知
// uploads/ 配下に .csv が作成されたら Lambda を起動する
bucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(importFn),
{ prefix: "uploads/", suffix: ".csv" },
);
}
}
ポイントは 最後のイベント通知の設定 です。
{ prefix: "uploads/", suffix: ".csv" }
このように prefix と suffix を指定することで、「uploads/ フォルダに .csv ファイルが作られたときだけ」 Lambdaが起動するようになります。あとで取り込み済みのファイルを processed/ に移動しますが、processed/ は uploads/ プレフィックスに一致しないので、移動したファイルで再びLambdaが起動してしまう(無限ループ)こともありません 。地味ですが大事なポイントです。
2. 取り込み用Lambdaを実装する
次にLambda本体です。やることはシンプルで、「S3からCSVを取る → パースする → DynamoDBに書く → ファイルを移動する」 だけです。
import {
CopyObjectCommand,
DeleteObjectCommand,
GetObjectCommand,
S3Client,
} from "@aws-sdk/client-s3";
import { DynamoDBClient } from "@aws-sdk/client-dynamodb";
import {
BatchWriteCommand,
DynamoDBDocumentClient,
} from "@aws-sdk/lib-dynamodb";
import type { S3Handler } from "aws-lambda";
import Papa from "papaparse";
const s3 = new S3Client({});
const ddb = DynamoDBDocumentClient.from(new DynamoDBClient({}));
const TABLE_NAME = process.env.FACILITY_TABLE_NAME!;
// CSV の1行(CSV から読むとすべて文字列で入ってくる)
type FacilityCsvRow = {
facilityCode: string;
facilityName: string;
prefecture: string;
isActive: string;
};
export const handler: S3Handler = async (event) => {
const record = event.Records[0];
const bucket = record.s3.bucket.name;
const objectKey = decodeURIComponent(
record.s3.object.key.replace(/\+/g, " "),
);
const timestamp = new Date().toISOString().replace(/[-:T]/g, "").slice(0, 14);
const fileName = objectKey.split("/").pop() ?? "facilities.csv";
try {
// 1. S3 から CSV を取得
const obj = await s3.send(
new GetObjectCommand({ Bucket: bucket, Key: objectKey }),
);
const csv = await obj.Body!.transformToString("utf-8");
// 2. CSV をパース
const { data } = Papa.parse<FacilityCsvRow>(csv, {
header: true,
skipEmptyLines: true,
});
// 3. DynamoDB の Item に変換
// CSV は文字列なので、isActive はここで boolean に直す
const now = new Date().toISOString();
const items = data.map((row) => ({
facilityCode: row.facilityCode,
facilityName: row.facilityName,
prefecture: row.prefecture,
isActive: row.isActive.toLowerCase() === "true",
updatedAt: now,
}));
// 4. DynamoDB へ書き込み(BatchWrite は 25 件ずつ)
for (let i = 0; i < items.length; i += 25) {
const chunk = items.slice(i, i + 25);
await ddb.send(
new BatchWriteCommand({
RequestItems: {
[TABLE_NAME]: chunk.map((item) => ({
PutRequest: { Item: item },
})),
},
}),
);
}
// 5. 成功したら processed/ に移動
await moveFile(bucket, objectKey, `processed/${timestamp}_${fileName}`);
console.log(`取り込み完了: ${items.length} 件`);
} catch (error) {
// 失敗したら error/ に移動して、エラーは投げ直す
await moveFile(bucket, objectKey, `error/${timestamp}_${fileName}`);
throw error;
}
};
// S3 には rename がないので、コピー+削除でファイルを移動する
const moveFile = async (bucket: string, from: string, to: string) => {
// CopySource はURLエンコードが必要(スラッシュは保持する)
const encodedSource = from.split("/").map(encodeURIComponent).join("/");
await s3.send(
new CopyObjectCommand({
Bucket: bucket,
CopySource: `${bucket}/${encodedSource}`,
Key: to,
}),
);
await s3.send(new DeleteObjectCommand({ Bucket: bucket, Key: from }));
};
書き込みには BatchWriteCommand を使っています。DynamoDBのBatchWriteは 一度に最大25件 という制限があるので、25件ずつに区切って送っています。
そして PutRequest は パーティションキー(facilityCode)が同じItemがあれば上書き してくれます。つまり、同じ facilityCode のCSVをもう一度アップロードすれば、既存データがまるごと更新されます。「追加」も「更新」も同じ仕組みで扱える のがDynamoDBのupsert(Put)のうれしいところです。
3. デプロイ
あとはデプロイするだけです。
npx cdk deploy
デプロイが完了すると、S3バケット・DynamoDBテーブル・Lambdaが一式作成されます。
4. 動作確認
テスト用のCSVを用意します。1行目はヘッダー、2行目以降がデータです。
facilityCode,facilityName,prefecture,isActive
TES01,テスト練習場01,東京都,true
TES02,テスト練習場02,神奈川県,true
TES03,テスト練習場03,大阪府,false
これを、作成されたバケットの uploads/ フォルダ にアップロードします。
aws s3 cp facilities.csv s3://<作成されたバケット名>/uploads/facilities.csv
アップロードすると、S3イベントをトリガーにLambdaが起動します。CloudWatch Logsを見ると、
取り込み完了: 3 件
というログが出力されていました。
DynamoDB側を確認してみると、CSVの中身がしっかり取り込まれています。isActive も文字列の "true" ではなく、ちゃんと boolean になっていますね。
aws dynamodb scan --table-name facility
そして、アップロードしたCSVは uploads/ から消え、processed/20260609_facilities.csv のようにタイムスタンプ付きで processed/ に移動 されていました。これで「いつ取り込んだか」がS3を見るだけで分かります。
試しに、わざと壊れたCSV(カラムが足りない、など)を入れると error/ 配下に移動されるので、失敗したファイルもひと目で分かります。
もう少し作り込むなら
今回は仕組みが分かるように、かなりシンプルに書きました。実運用に乗せるなら、以下のあたりを足してあげると安心です。
- バリデーション:今回は文字列をそのまま入れていますが、zod などで「必須項目が空でないか」「
isActiveがtrue/falseか」などをチェックすると、不正なマスターデータの混入を防げます - エラー通知:
error/に移動するだけでなく、CloudWatch AlarmやSNS経由でSlackなどに通知すると、取り込み失敗にすぐ気づけます - 種別ごとのルーティング:
uploads/facilities/uploads/campaigns/のようにプレフィックスを分け、Lambda側でプレフィックスを見て処理を振り分ければ、1つのバケット・1つのLambdaで複数のマスターデータ を扱えます
このあたりは要件に応じて、必要になったタイミングで足していくのがよいと思います。
おわりに
今回は、S3にCSVを置くだけでDynamoDBにマスターデータを投入する仕組み を、CDK + Lambdaでシンプルに作ってみました。
- 専用の管理画面を作らなくても、S3にアップロードするだけ でマスターデータを投入できる
- DynamoDBのPut(upsert)で、「追加」も「更新」も同じフロー で扱える
- 取り込み後に
processed/・error/へ移動 することで、結果がS3を見るだけで分かる
「マスターデータの投入、どうしようかな」と悩んでいる方にとって、管理画面を作るほどではないけど手作業はしたくない という、ちょうど中間のニーズにハマる仕組みだと思います。
以上、どなたかの参考になれば幸いです。
参考









