
S3 インベントリ + Athenaで、DataSyncのマニフェストファイルを作ってみた
こんにちは!クラウド事業本部の吉田です。
DataSyncを利用したS3のファイル移行を行う際、特定ファイルの転送方法としては主に2通りあります。
- フィルターパターン
- 特定のパターンに一致するファイルを移行対象にする方式
- 特定のフォルダ配下のファイルだけデータ転送したいケースに有効
- フィルターを使用して特定のファイル、オブジェクト、フォルダーを転送する - AWS DataSync
- 特定のパターンに一致するファイルを移行対象にする方式
- マニフェストファイル
- 移行対象の全ファイルのパスを記載したマニフェストファイルを元に移行する方式
- 移行対象の正確に指定できる
- マニフェストを使用した特定のファイルまたはオブジェクトの転送 - AWS DataSync
- 移行対象の全ファイルのパスを記載したマニフェストファイルを元に移行する方式
2、3の特定のフォルダ配下の全てのファイルを送るなどといったパターンの場合は、フィルターパターンを利用する方が楽に移行できます。
しかし、複雑なパターンの場合では、フィルターパターンの作成工数が増加したり、移行対象ファイルのみ転送するということが難しくなることがあります。
そのようなケースでは、マニフェストファイルを利用する方が適している可能性があります。
ただ、移行対象ファイルが多いとマニフェストファイルを作るのも大変です。
今回は、S3インベントリとAthenaを活用してDataSyncのマニフェストファイルを作成し、効率的にデータ移行を行う方法をまとめてみました。
前提
今回の記事は、マニフェストファイルの作成方法を中心とした内容です。
DataSyncの詳細な構築方法については、下記のブログを参考にしてください。
AWS DataSync でクロスアカウントの Amazon S3 ロケーションとの間でデータを転送してみた | DevelopersIO
フィルターパターンの制約
マニフェストファイルの作成方法の解説の前に、まずフィルターパターンの制約について解説します。
フィルターパターンには、include(包含)/exclude(除外)フィルターの2種類あります。
特殊文字としてワイルドカードが利用できますが、includeフィルターでは前方一致でしか利用できないという制約があります。
包含フィルターは、ワイルドカード () 文字をパターン内の右端の文字としてのみサポートします。たとえば、/documents|/code* はサポートされていますが、*.txt はサポートされていません。
フィルターを使用して特定のファイル、オブジェクト、フォルダーを転送する - AWS DataSync#包含フィルターの作成
つまり、パスの途中でワイルドカードを利用することができません。
例えば「年月フォルダ配下の特定のフォルダ内の特定のファイルを転送したい」というケースでは、設定するフィルターパターンの数が多くなります。
このままではわかりづらいので、次のセクションで具体例を出します。
移行対象ファイルとフィルターパターン例
具体的な例で、フィルターパターンの課題を確認してみましょう。
移行元S3バケットの内容
移行元のS3バケットの格納されているファイルの内容は、下記の通りとします。
ecommerce/[YYYYMM]/orders/order-foo-[ランダムID].txt
ecommerce/[YYYYMM]/orders/order-foo-[ランダムID].bak
ecommerce/[YYYYMM]/orders/order-bar-[ランダムID].txt
ecommerce/[YYYYMM]/orders/order-bar-[ランダムID].bak
ecommerce/[YYYYMM]/orders/order-baz-[ランダムID].txt
ecommerce/[YYYYMM]/orders/order-baz-[ランダムID].bak
ecommerce/[YYYYMM]/csv_data/report-hoge-[ランダムID].csv
ecommerce/[YYYYMM]/csv_data/report-hoge-[ランダムID].bak
ecommerce/[YYYYMM]/csv_data/report-fuga-[ランダムID].csv
ecommerce/[YYYYMM]/csv_data/report-fuga-[ランダムID].bak
ecommerce/[YYYYMM]/products/product-qux-[ランダムID].json
ecommerce/[YYYYMM]/products/product-quux-[ランダムID].json
ecommerce/[YYYYMM]/settings/settings-piyo-[ランダムID].json
ecommerce/[YYYYMM]/settings/settings-hogehoge-[ランダムID].json
- 各パターンごとに10個ファイルがある
- 期間は2025年7月~9月とする
移行対象ファイル
そして、下記のパターンのファイルを移行対象とします。
ecommerce/[YYYYMM]/orders/order-foo-[ランダムID].txt
ecommerce/[YYYYMM]/orders/order-bar-[ランダムID].txt
ecommerce/[YYYYMM]/csv_data/report-hoge-[ランダムID].csv
必要なフィルターパターン(include)
フィルターパターンで対応する場合、includeフィルターは下記のようになります
ecommerce/202507/orders/order-foo-*
ecommerce/202507/orders/order-bar-*
ecommerce/202507/csv_data/report-hoge-*
ecommerce/202508/orders/order-foo-*
ecommerce/202508/orders/order-bar-*
ecommerce/202508/csv_data/report-hoge-*
ecommerce/202509/orders/order-foo-*
ecommerce/202509/orders/order-bar-*
ecommerce/202509/csv_data/report-hoge-*
課題点
課題点は以下の通りです。
- 年月ごとのフィルターを用意しなければならない
- 今回のケースでは9つのフィルターとなりますが、これが何十ヶ月のファイルの対象だった場合さらにフィルターの数が多くなります
- 拡張子の指定ができないため、移行対象外の拡張子のファイルが含まれる
- 今回のパターンだと下記の移行対象外のファイルが含まれます
- ecommerce/[YYYYMM]/orders/order-foo-[ランダムID].bak
- ecommerce/[YYYYMM]/orders/order-bar-[ランダムID].bak
- ecommerce/[YYYYMM]/csv_data/report-hoge-[ランダムID].bak
- 今回のパターンだと下記の移行対象外のファイルが含まれます
2つ目の課題に関しては、excludeフィルターを作成すれば解決します。
excludeフィルターは後方一致に対応しているため、「*.bak」というexcludeフィルターを作成すればbakファイルを移行対象外にすることができます。
ただ、「ecommerce/[YYYYMM]/orders/」配下のbakファイルは送りたいといった要望が来ると、対応することが難しくなります。
ちなみに、includeフィルターとexcludeフィルターを併用した場合に留意すべきことが、下記のブログでまとめられているためぜひ読んでみてください。
AWS DataSyncのinclude/excludeパターンを混ぜるとどうなる? | DevelopersIO
このように、フィルターパターンで対応することが難しく、移行対象を明確に指定することができるマニフェストファイルを利用する方がいいケースがあります。
マニフェストファイル作成方法
ではここから、マニフェストファイルの作成方法を解説していきます。
移行元のS3バケットの内容と移行対象データに関しては、「移行対象ファイルとフィルターパターン例」セクションと同様の内容とします。
移行元のS3バケット名はsource-ecommerce-kwpus3hとしています。
バケットの内容をわかりやすくするために、キャプチャも貼ります。

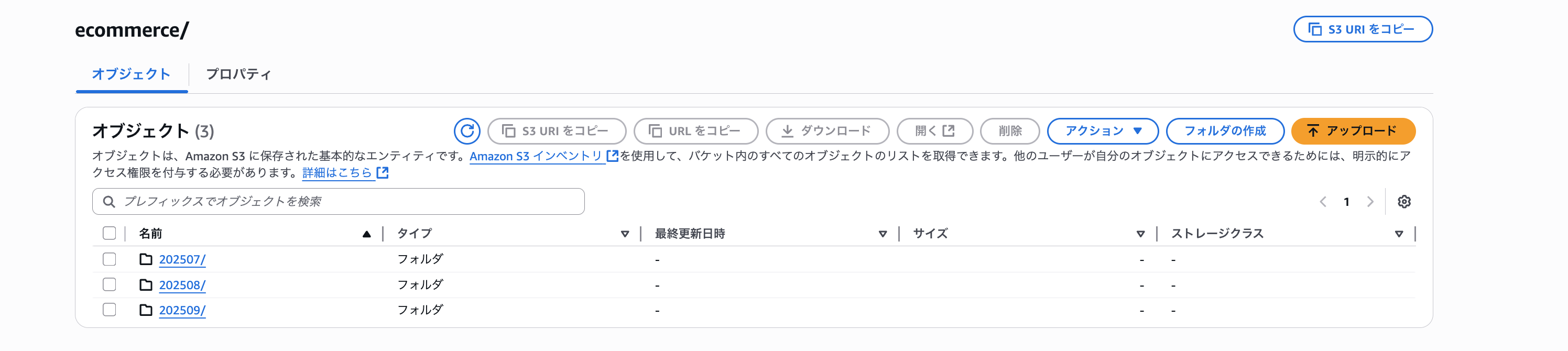
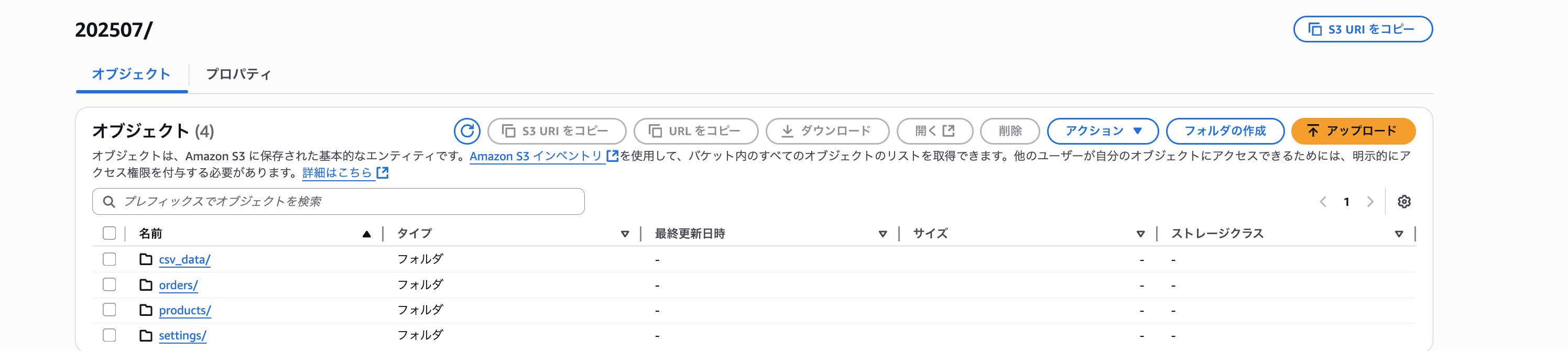
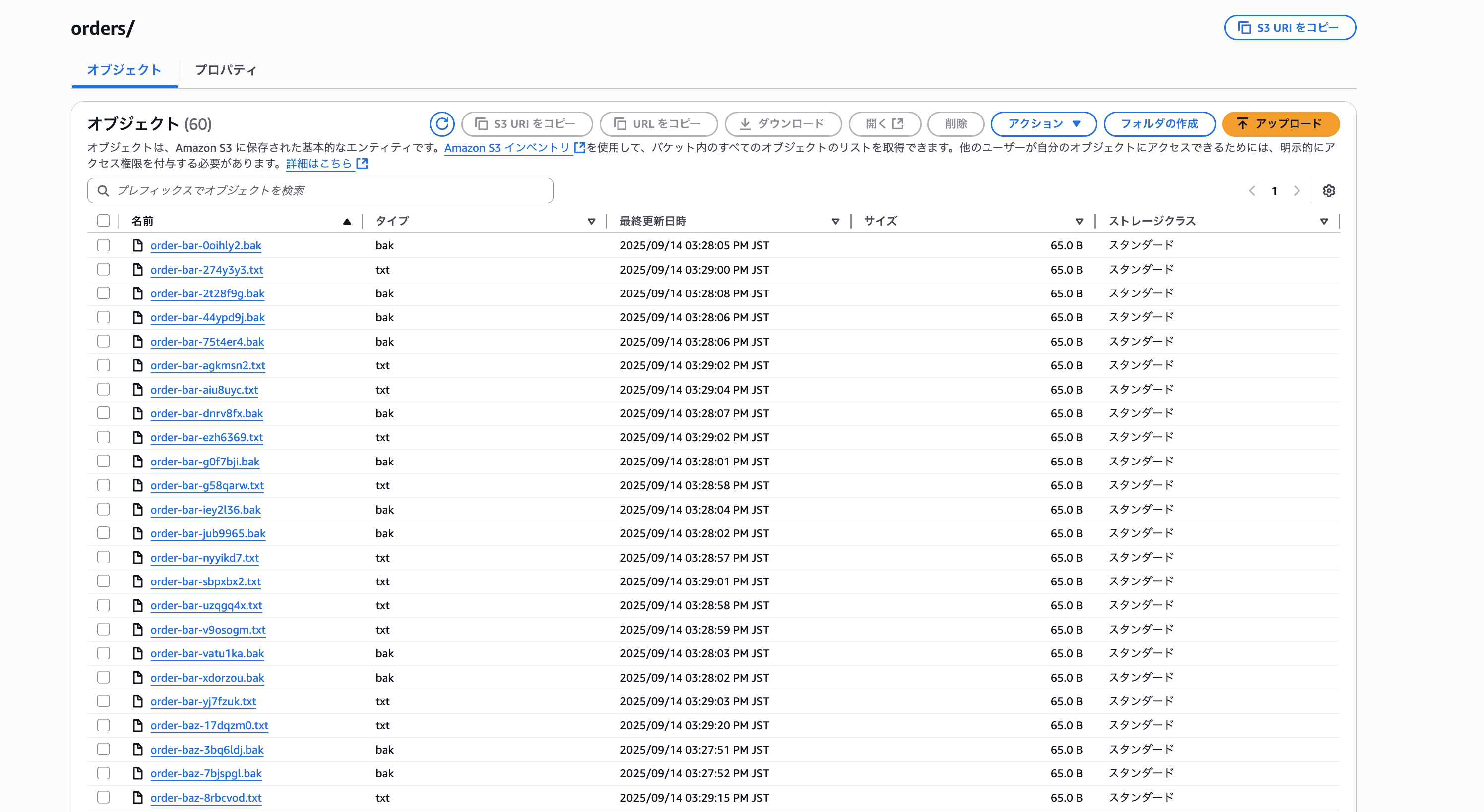
テストファイル作成用のシェルスクリプトはClaude Codeで作りました。
#!/bin/bash
# バケット名を設定してください
BUCKET_NAME="source-ecommerce-kwpus3h"
# ランダム文字列生成関数
generate_random_id() {
echo $(cat /dev/urandom | tr -dc 'a-z0-9' | fold -w 7 | head -n 1)
}
# 年月のリスト
months=("202507" "202508" "202509")
# ファイルパターンの定義
declare -A patterns=(
["orders/order-foo"]="txt"
["orders/order-foo-bak"]="bak"
["orders/order-bar"]="txt"
["orders/order-bar-bak"]="bak"
["orders/order-baz"]="txt"
["orders/order-baz-bak"]="bak"
["csv_data/report-hoge"]="csv"
["csv_data/report-hoge-bak"]="bak"
["csv_data/report-fuga"]="csv"
["csv_data/report-fuga-bak"]="bak"
["products/product-qux"]="json"
["products/product-quux"]="json"
["settings/settings-piyo"]="json"
["settings/settings-hogehoge"]="json"
)
echo "サンプルファイルの作成を開始します..."
echo "バケット名: $BUCKET_NAME"
# 各月に対してファイルを作成
for month in "${months[@]}"; do
echo "処理中: $month"
# 各パターンに対してファイルを作成
for pattern in "${!patterns[@]}"; do
extension="${patterns[$pattern]}"
# bakファイルの場合、パターン名を調整
if [[ $pattern == *"-bak" ]]; then
clean_pattern=${pattern%-bak}
for i in {1..10}; do
random_id=$(generate_random_id)
file_path="ecommerce/$month/$clean_pattern-$random_id.bak"
echo "Sample content for $file_path" | aws s3 cp - "s3://$BUCKET_NAME/$file_path"
done
else
for i in {1..10}; do
random_id=$(generate_random_id)
file_path="ecommerce/$month/$pattern-$random_id.$extension"
echo "Sample content for $file_path" | aws s3 cp - "s3://$BUCKET_NAME/$file_path"
done
fi
done
done
echo "ファイル作成完了!"
echo "作成されたファイル数を確認:"
aws s3 ls "s3://$BUCKET_NAME/ecommerce/" --recursive | wc -l
全体の流れ
S3インベントリとAthenaを活用したマニフェストファイル作成の流れは以下の通りです。
- S3インベントリですべてのファイルのパス情報を取得
- Athenaで移行対象のファイルを抽出するクエリを実行
- クエリ結果からマニフェストファイルを作成
S3インベントリですべてのファイルのパス情報を取得
移行元S3バケットでS3インベントリを設定します。
詳細な手順は以下のブログを参照してください。
S3バケットのオブジェクト数やサイズを確認する前に知っておきたいこと(LISTリクエストとS3インベントリ) | DevelopersIO
- S3インベントリの出力先となるS3バケットを作成
- 移行元S3バケットと違うアカウントで作成することも可能です。
- 今回は、移行元S3バケットと同じアカウント上で、
inventory-source-ecommerce-kwpus3hという名前で作成しております。
- 移行元バケットのインベントリ設定を作成
- 全てデフォルトで設定しております。(出力形式はCSV)
1日~2日待ちますと、S3インベントリ用バケットにファイル一覧ファイルが出力されております。
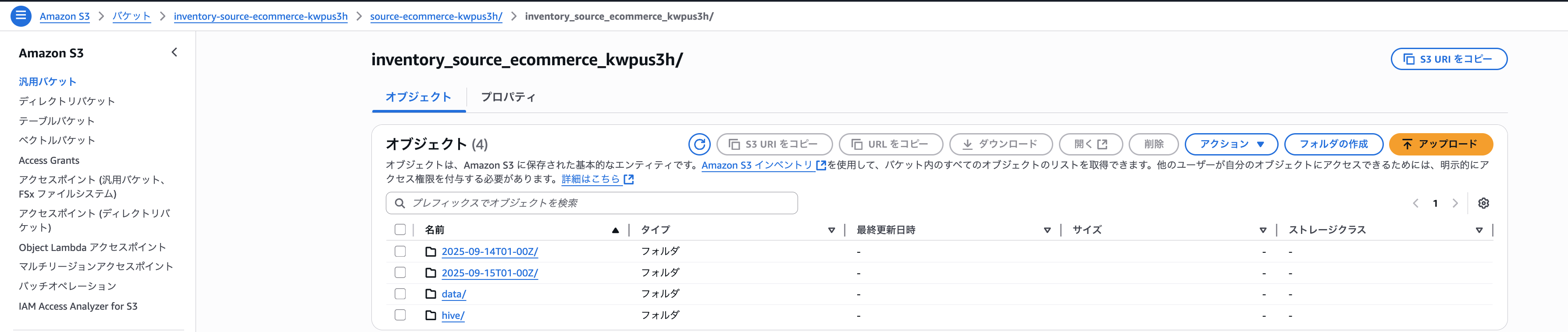
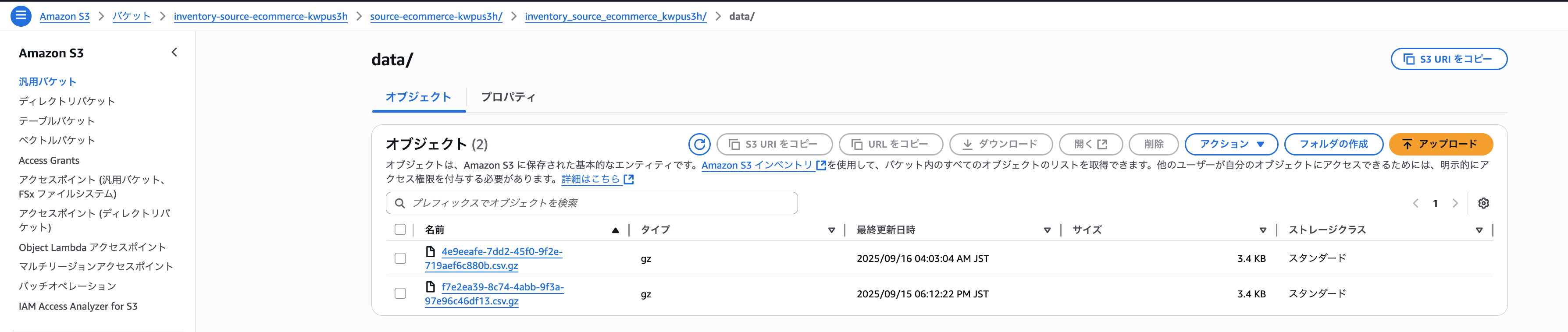
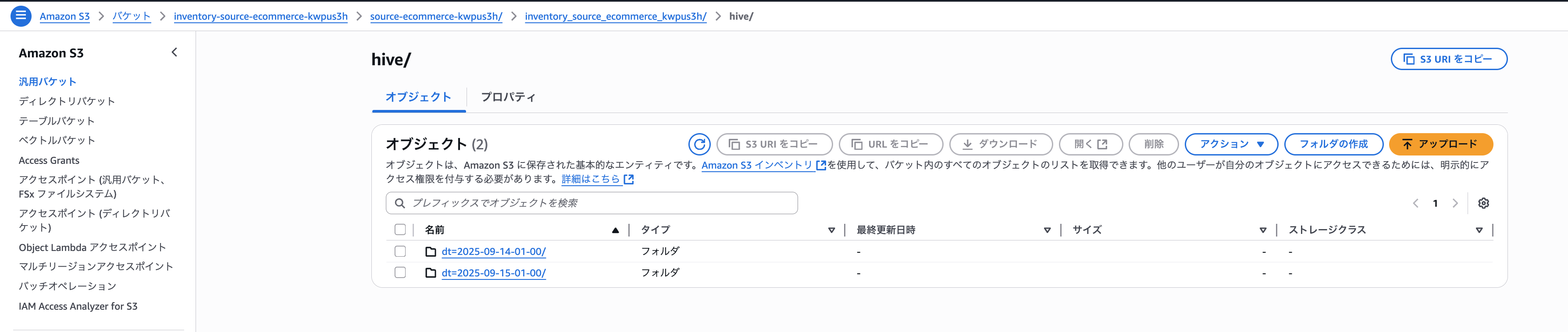
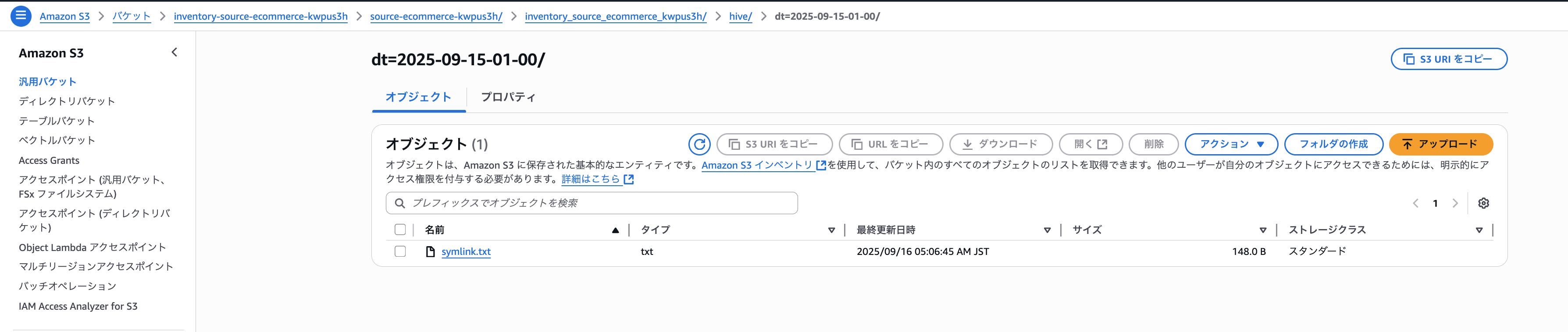
「data」フォルダにファイル一覧が記載されたファイルが格納され、「hive/dt=YYYY-MM-DDThh-mm/symlink.txt」に「data」フォルダ配下のファイルがいつの時点のファイル一覧ファイルなのかが記載されています。
例えば、「hive/dt=2025-09-15-01-00/symlink.txt」の内容は、下記の通りとなります。
s3://inventory-source-ecommerce-kwpus3h/source-ecommerce-kwpus3h/inventory_source_ecommerce_kwpus3h/data/4e9eeafe-7dd2-45f0-9f2e-719aef6c880b.csv.gz
「4e9eeafe-7dd2-45f0-9f2e-719aef6c880b.csv.gz」は、「2025/9/15 1:00」時点のファイル一覧が記載されているということですね。
Athenaで移行対象のファイルを抽出するクエリを実行
- S3インベントリ用テーブルの作成
以下のクエリでAthenaにテーブルを作成します。
CREATE EXTERNAL TABLE テーブル名(
bucket string,
key string
) PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 'S3インベントリ用S3バケットのhiveフォルダまでのURI'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.dt.type" = "date",
"projection.dt.format" = "yyyy-MM-dd-HH-mm",
"projection.dt.range" = "2022-01-01-00-00,NOW",
"projection.dt.interval" = "1",
"projection.dt.interval.unit" = "HOURS"
);
一点、重要な点としては、LOCATIONではファイル一覧ファイルがあるdataフォルダではなくhiveフォルダを指定する点です。
このように指定することでパーティション分割ができます。
先ほどのS3インベントリのファイル一覧の構成と合わせて、下記のブログが参考になります。
S3バケット内のファイル一覧(S3 Inventory)をAthenaを利用して分析する | DevelopersIO
今回は、下記のクエリを実行しました。
CREATE EXTERNAL TABLE s3_inventory_table(
bucket string,
key string
) PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 's3://inventory-source-ecommerce-kwpus3h/source-ecommerce-kwpus3h/inventory_source_ecommerce_kwpus3h/hive/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.dt.type" = "date",
"projection.dt.format" = "yyyy-MM-dd-HH-mm",
"projection.dt.range" = "2022-01-01-00-00,NOW",
"projection.dt.interval" = "1",
"projection.dt.interval.unit" = "HOURS"
);
- 移行対象ファイルの抽出クエリ実行
テーブルが作成できましたら、次は移行対象ファイルの抽出するクエリを実行します。
抽出対象は、下記のパターンのファイルです。
ecommerce/[YYYYMM]/orders/order-foo-[ランダムID].txt
ecommerce/[YYYYMM]/orders/order-bar-[ランダムID].txt
ecommerce/[YYYYMM]/csv_data/report-hoge-[ランダムID].csv
以下のクエリで、移行対象ファイルを抽出します。
SELECT key
FROM テーブル名
WHERE (
条件文
)
AND dt = 'YYYY-MM-DD-hh-mm'
ORDER BY key;
SELECT key
FROM s3_inventory_table
WHERE (
(key LIKE 'ecommerce/%/orders/order-foo-%' AND key LIKE '%.txt')
OR
(key LIKE 'ecommerce/%/orders/order-bar-%' AND key LIKE '%.txt')
OR
(key LIKE 'ecommerce/%/csv_data/report-hoge-%' AND key LIKE '%.csv')
)
AND dt = '2025-09-15-01-00'
ORDER BY key;
クエリ結果からマニフェストファイルを作成
- 結果のダウンロードと加工
Athenaのクエリ結果をCSVファイルとしてダウンロードします。
そのままこのCSVファイルをマニフェストファイルとして利用したいところですが、少し加工する必要があります。
- 1行目のヘッダを削除
- 各行のダブルクォートを削除
- ダブルクォートがあるとDataSyncが正しくキーを認識しないため
以下のコマンドでヘッダ行とダブルクォートを削除します。
sed '1d; s/^"//; s/"$//' クエリ結果のCSVファイル名 > manifest.csv
sed '1d; s/^"//; s/"$//' ac6d5a4e-077e-4c5d-86cb-4bef70f8ca6f.csv > manifest.csv
CSVファイルの加工前と加工後は、下記の通りです。
"key"
"ecommerce/202507/csv_data/report-hoge-0i0fa87.csv"
"ecommerce/202507/csv_data/report-hoge-440nukd.csv"
"ecommerce/202507/csv_data/report-hoge-6mdvijt.csv"
(省略)
ecommerce/202507/csv_data/report-hoge-0i0fa87.csv
ecommerce/202507/csv_data/report-hoge-440nukd.csv
ecommerce/202507/csv_data/report-hoge-6mdvijt.csv
(省略)
- マニフェストファイルのアップロード
作成したマニフェストファイルをS3バケットにアップロードします。
マニフェストファイルを配置するS3バケットは新規に作成する形でもいいですが、移行先のバケットに配置する形でも問題ないです。
移行先のバケットに配置すると、マニフェストファイルにアクセスするためのIAMロールを新規に作成する必要がなくなります。
後ほどのタスク作成手順で詳しく解説します。
DataSyncタスクの作成
こちらのDataSyncのタスク作成手順は、マニフェストファイルを指定するところを中心に解説します。
前提でも記載しましたが、DataSyncの詳細な構築手順は下記のブログを参照してください。
AWS DataSync でクロスアカウントの Amazon S3 ロケーションとの間でデータを転送してみた | DevelopersIO
タスク作成手順(マニフェストファイル指定部分)
- 「送信元データオプション」の「スキャンするコンテンツ」から「特定のファイル、オブジェクト、フォルダ」を選択
- 「マニフェストの使用」を選択
- S3 URIでアップロードしたマニフェストファイルを指定
- マニフェストアクセスロールに、マニフェストファイルへのアクセス権限があるIAMロールを指定
- ここでマニフェストファイルを移行先のS3バケットに配置すると、送信先ロケーションで設定したIAMロールを流用することができます
- マニフェストファイル用の新規S3バケットを作成した場合は、以下の公式ドキュメントを参照してマニフェストファイルのアクセス権限があるIAMロールを作成してください
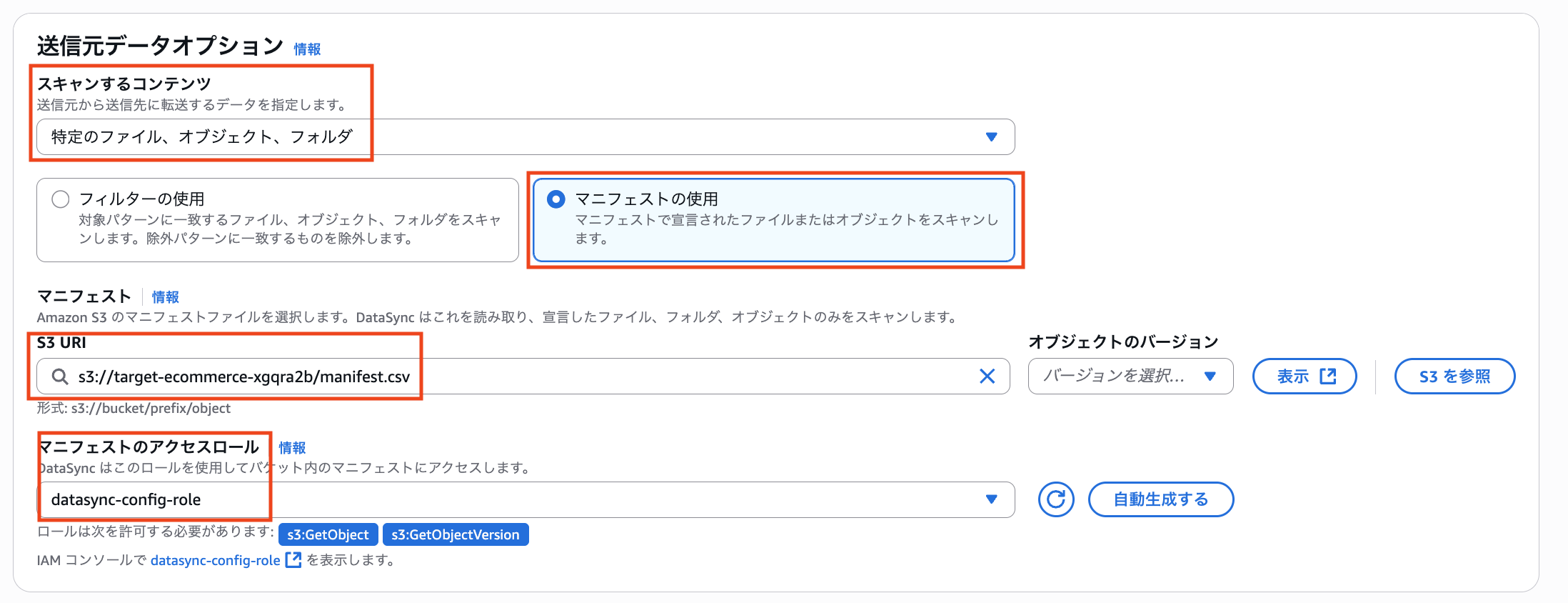
タスクの実行が成功しましたら、移行先のS3バケットを確認してみましょう




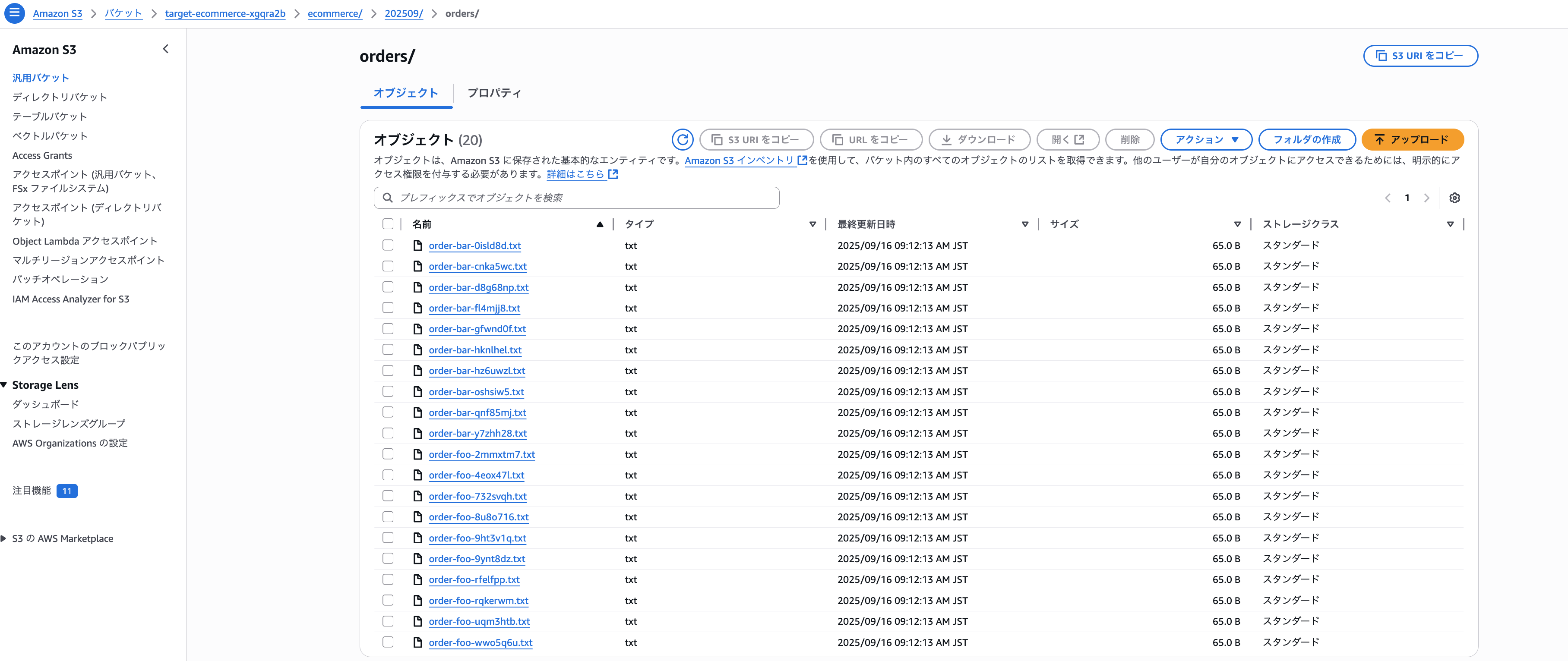
無事、移行対象のファイルが移行できていますね。
最後に
S3インベントリとAthenaを活用することで、複雑な条件でのファイル移行もマニフェストファイル方式で効率的に実行できることを確認できました。
フィルターパターンでは対応が困難な要件でも、SQLクエリを使って柔軟に移行対象を抽出できるため、大規模なデータ移行プロジェクトでも活用できそうです!
以上、クラウド事業本部の吉田でした!
参考資料
- フィルターを使用して特定のファイル、オブジェクト、フォルダーを転送する - AWS DataSync
- マニフェストを使用した特定のファイルまたはオブジェクトの転送 - AWS DataSync
- AWS DataSync でクロスアカウントの Amazon S3 ロケーションとの間でデータを転送してみた | DevelopersIO
- AWS DataSyncのinclude/excludeパターンを混ぜるとどうなる? | DevelopersIO
- S3バケットのオブジェクト数やサイズを確認する前に知っておきたいこと(LISTリクエストとS3インベントリ) | DevelopersIO
- S3バケット内のファイル一覧(S3 Inventory)をAthenaを利用して分析する | DevelopersIO








