
S3 Tables のカタログ統合による Snowflake Iceberg テーブルを作成し、既存テーブルのデータを挿入してみた
データ事業本部のsutoです。
今回はSnowflakeのカタログ統合を構成して、S3 TablesのテーブルをSnowflakeのIcebergテーブルとして連携してみました。
Snowflakeのテーブルデータを Amazon S3 Tablesのテーブルとして保存することで、Amazon SageMaker Lakehouse の分析・AI/MLサービスとの連携がしやすくなるだろうという思いから、従来のようなSnowflakeの通常テーブル(Permanent Table)のデータをSELECTしIcebergテーブルへ挿入できるのかも試してみました。
やってみた
前提として、今回作業するAWSのリージョンは「 us-east-1 」です。
LakeFormationで権限付与
- AWS 分析サービスとの統合が有効になっていることを確認
- (なっていない場合:Administrative roles and tasksで、使用しているIAMロール(またはIAMユーザー)にLakeformation管理権限を付与しておいてください)
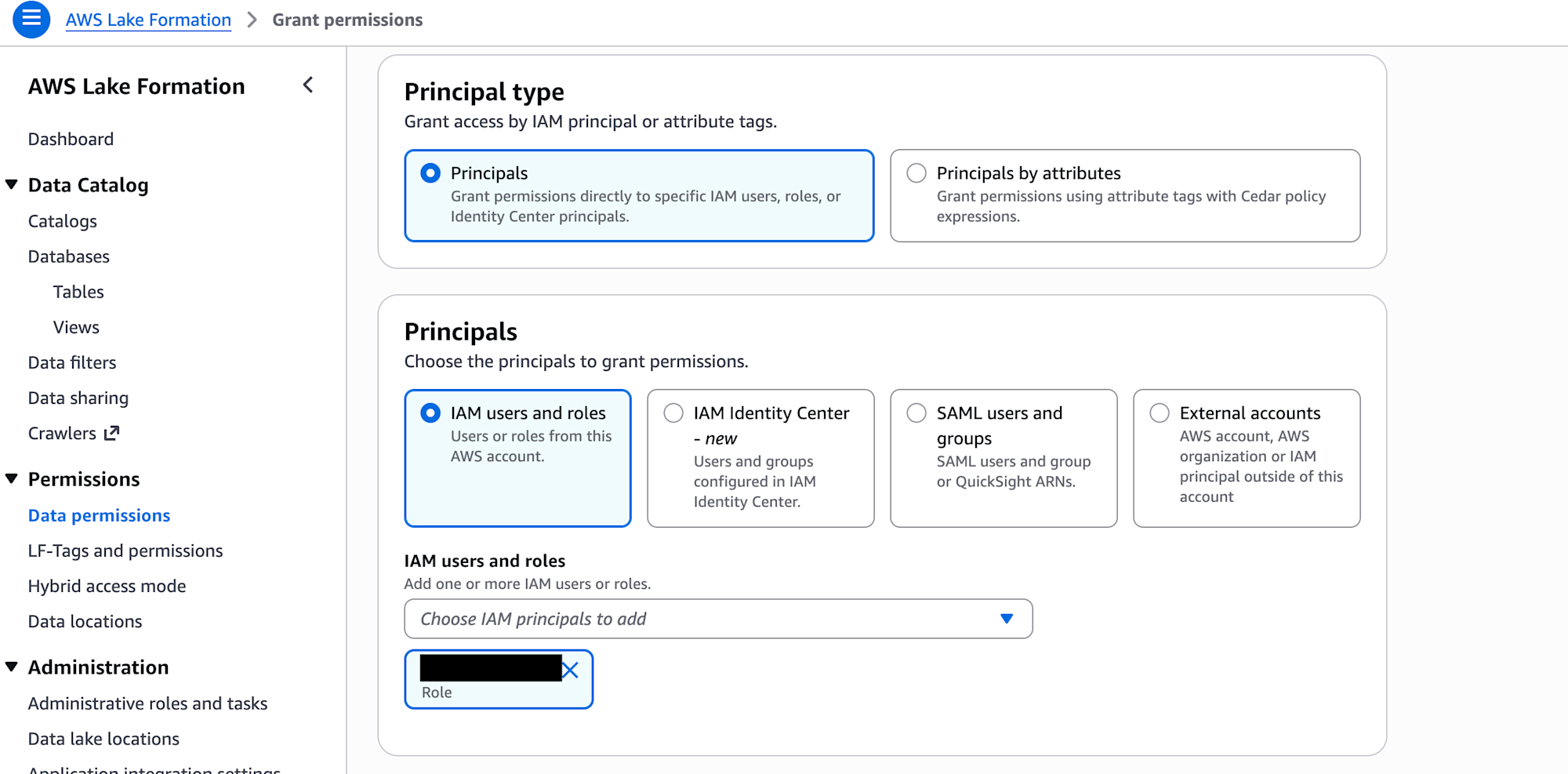
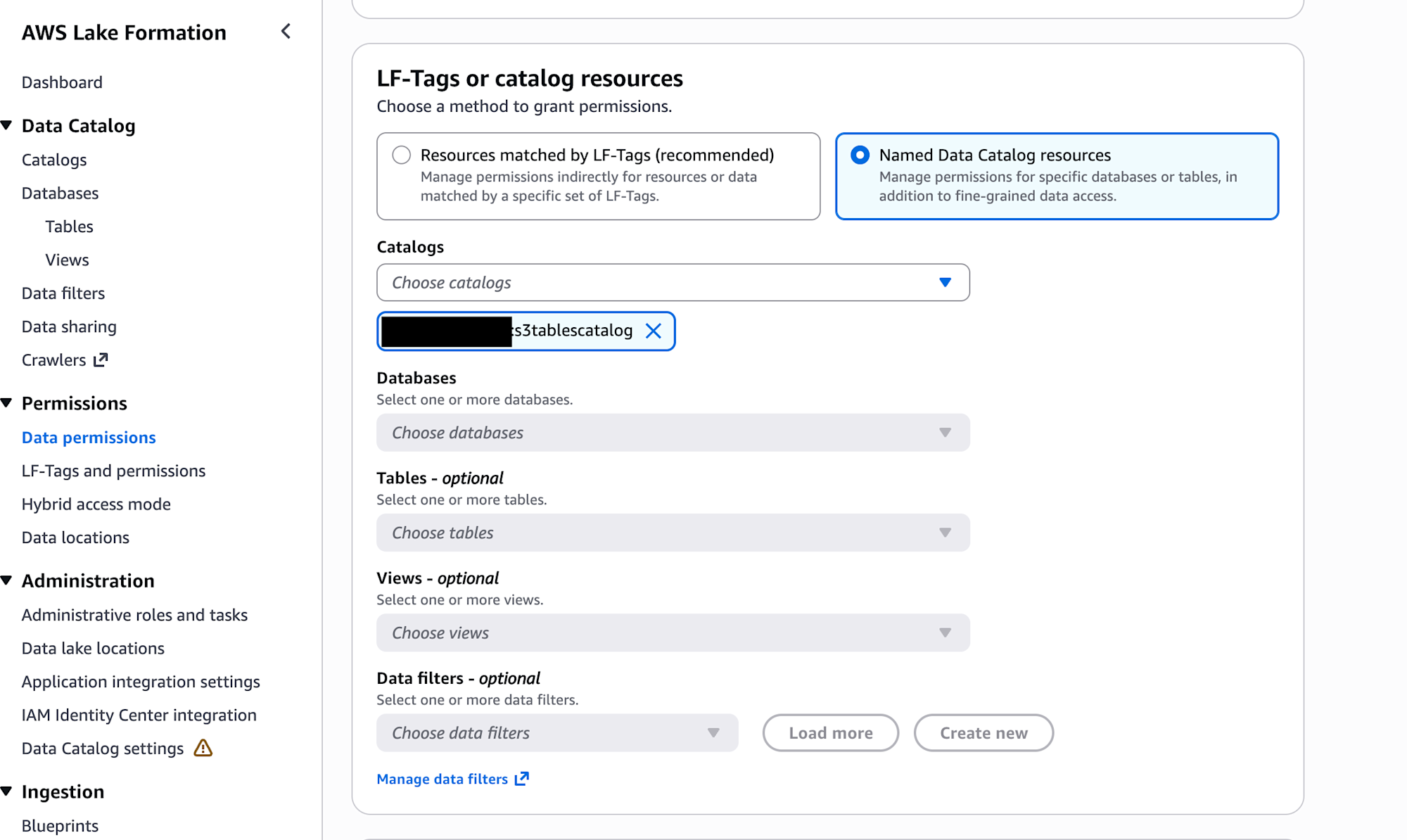
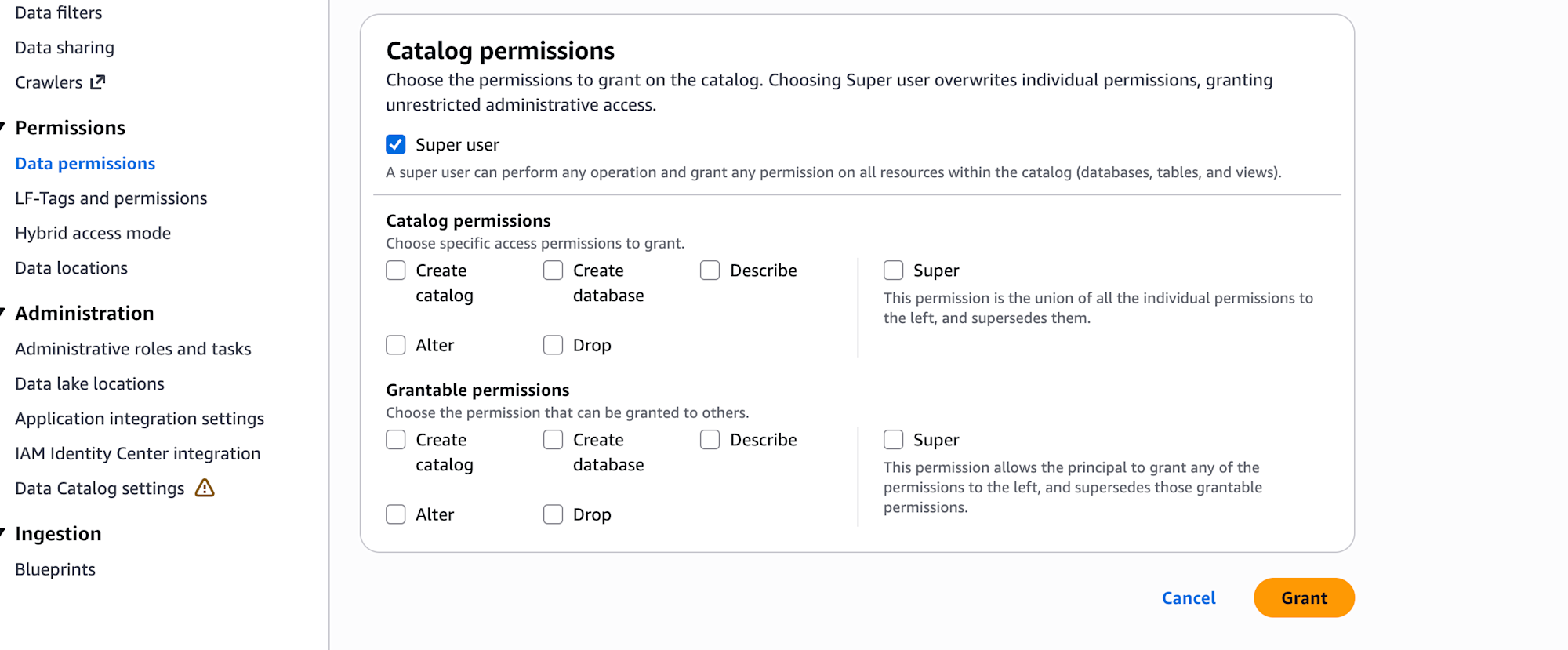
- Data permissionsで、本作業で使用しているIAMロール(またはIAMユーザー)に、”s3tablescatalog”の権限を付与する
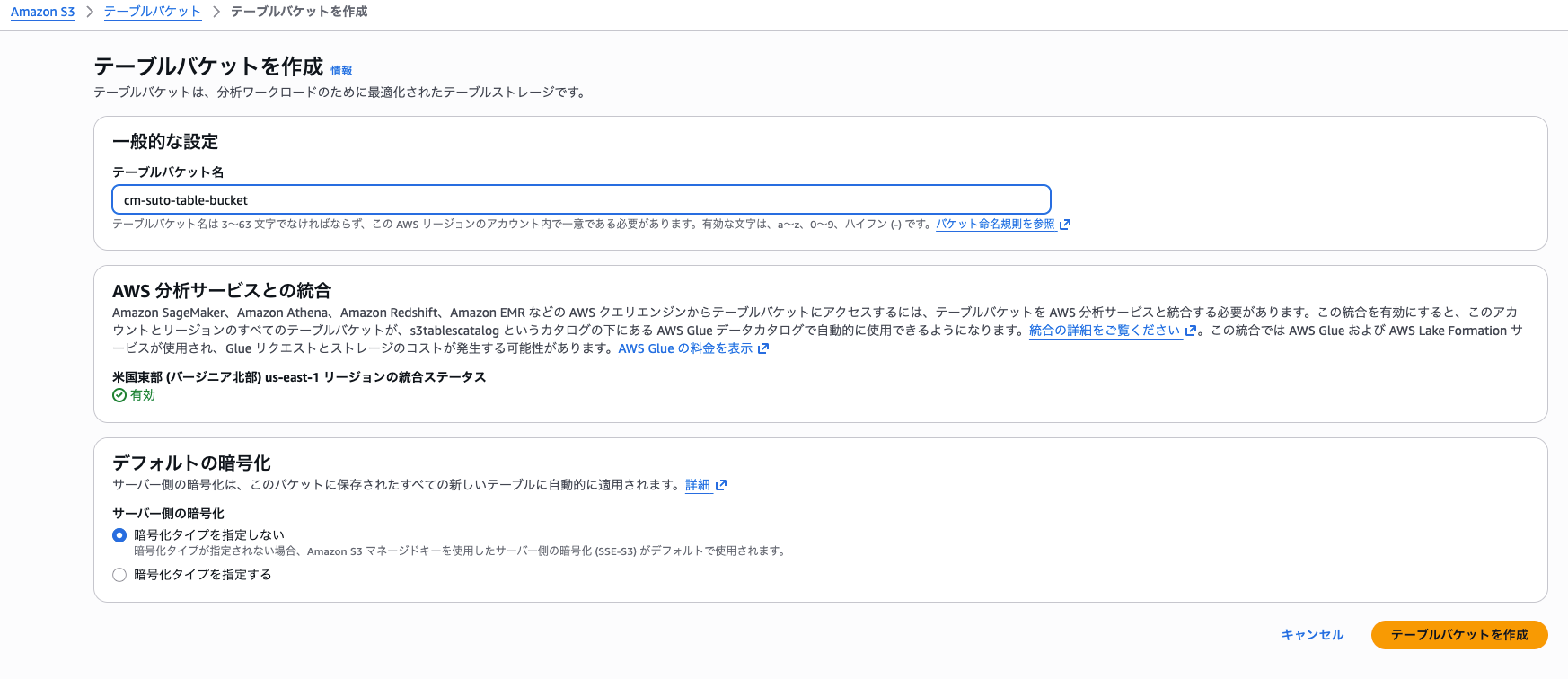
S3 Tablesのバケット・名前空間の作成
今回はAWSコンソールから以下のパラメータでS3 Tablesのバケットを作成します。
- バケット名:cm-suto-table-bucket
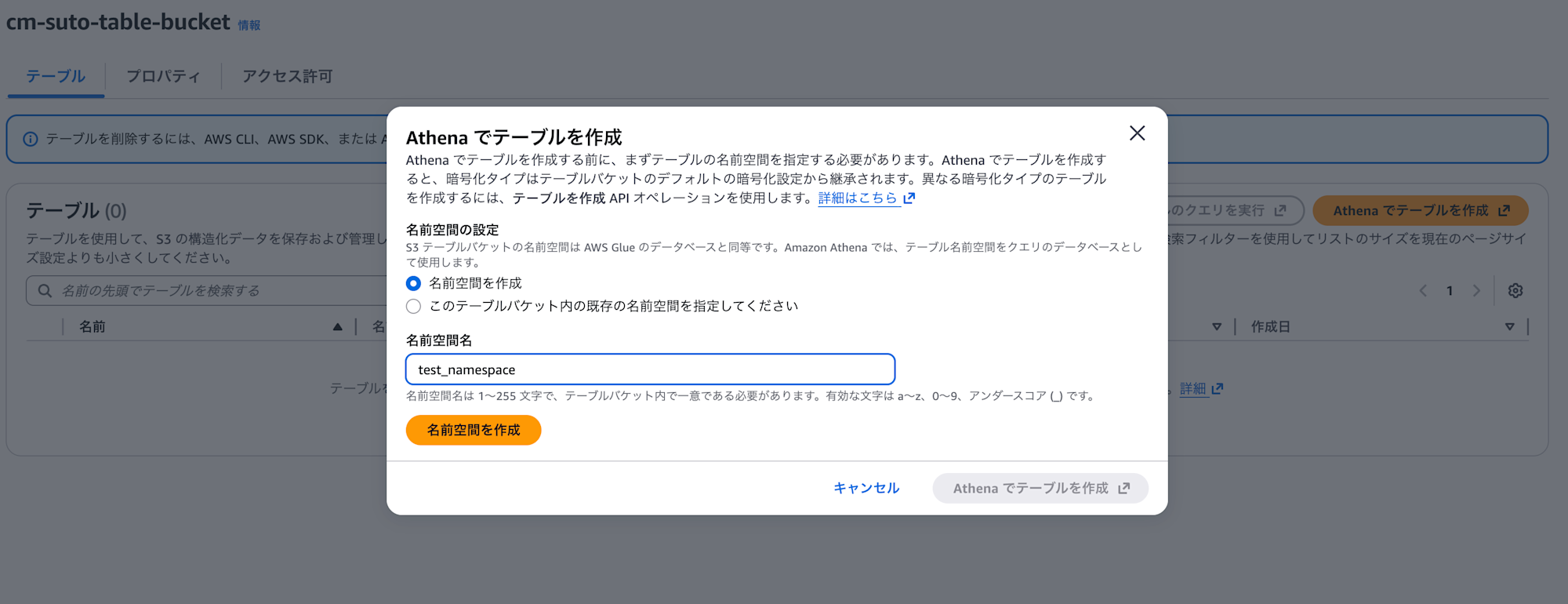
S3 Tablesのテーブル作成
- 「Athenaでテーブルを作成」を選択し、名前空間の新規作成を行いつつAthenaの画面に遷移します。
- 名前空間名:test_namespace
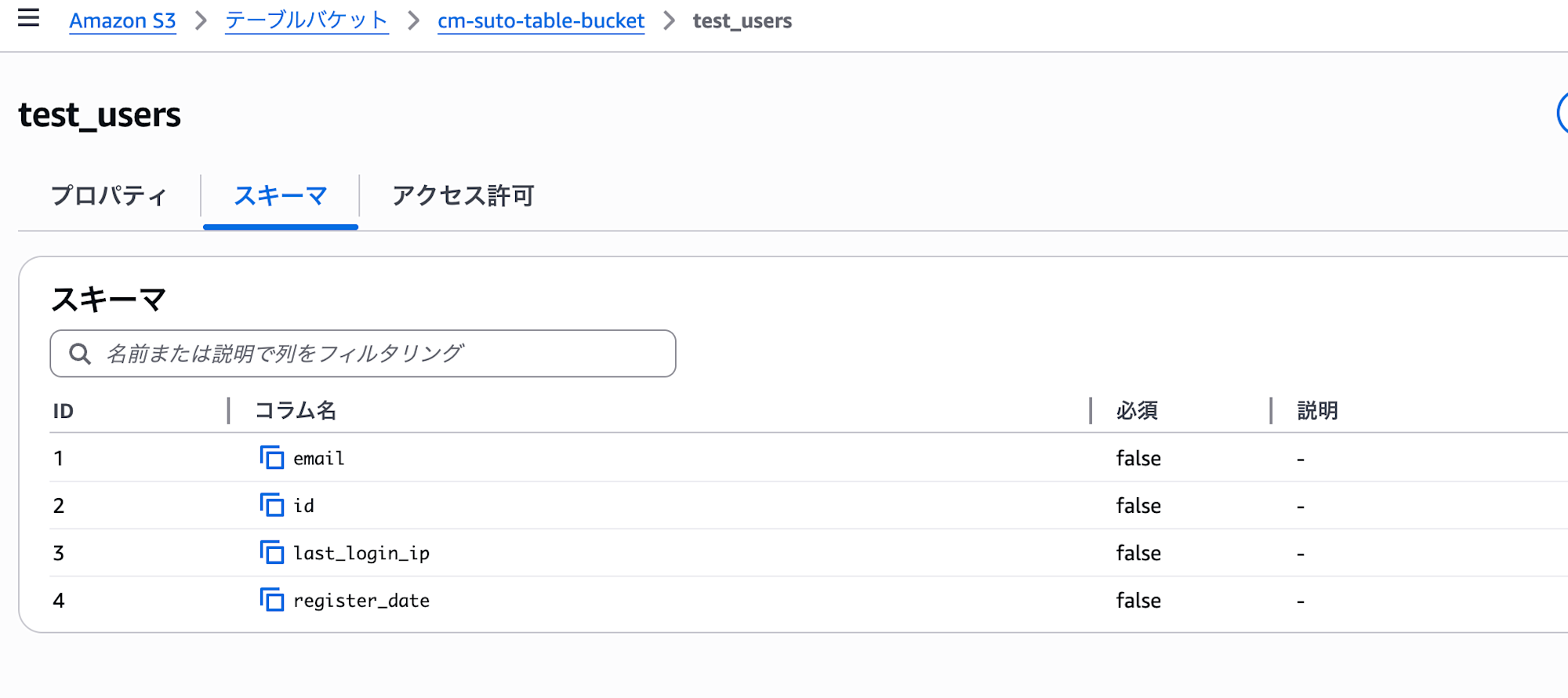
- Athenaのクエリエディタに遷移したら以下のクエリでテーブル(test_users)を作成します。
CREATE TABLE `test_namespace`.test_users (
email string,
id string,
last_login_ip string,
register_date date)
PARTITIONED BY (month(register_date))
TBLPROPERTIES ('table_type' = 'iceberg')
;
Snowflakeとのカタログ統合設定
Snowflakeが引き受けてGlue s3tablescatalogを参照するためのロールを作成します。
- 以下の許可ポリシーのIAMポリシーを持つIAMロールを作成します
- 信頼されたエンティティでは、「別のアカウント」を選択(別のアカウントのIDは後ほどSnowflakeの設定値を設定するため、このタイミングでは適当でOK)
- 許可ポリシー内のAWSアカウントは作業している自身のAWSアカウントIDに置き換えてください
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::[AWSアカウントID]:bucket/cm-suto-table-bucket/*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::[AWSアカウントID]:bucket/cm-suto-table-bucket",
"Condition": {
"StringLike": {
"s3:prefix": [
"*"
]
}
}
},
{
"Effect": "Allow",
"Action": "lakeformation:GetDataAccess",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"glue:GetCatalog",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables",
"glue:CreateTable",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:*:[AWSアカウントID]:catalog/*",
"arn:aws:glue:*:[AWSアカウントID]:catalog/s3tablescatalog",
"arn:aws:glue:*:[AWSアカウントID]:catalog/s3tablescatalog/*",
"arn:aws:glue:*:[AWSアカウントID]:database/*",
"arn:aws:glue:*:[AWSアカウントID]:table/*"
]
},
{
"Effect": "Allow",
"Action": [
"lakeformation:GetDataAccess"
],
"Resource": "*"
}
]
}
- Snowflakeにログインし、CATALOG INTEGRATIONを作成
CREATE OR REPLACE CATALOG INTEGRATION suto_s3tables_catalog_integration
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = 'default'
REST_CONFIG = (
CATALOG_URI = 'https://glue.us-east-1.amazonaws.com/iceberg'
CATALOG_API_TYPE = AWS_GLUE
WAREHOUSE = '[アカウントID]:s3tablescatalog/cm-suto-table-bucket'
ACCESS_DELEGATION_MODE = vended_credentials
)
REST_AUTHENTICATION = (
TYPE = SIGV4
SIGV4_IAM_ROLE = 'arn:aws:iam::[アカウントID]:role/[作成したIAMロール名]'
SIGV4_SIGNING_REGION = 'us-east-1'
)
ENABLED = TRUE
-
次に
DESC CATALOG INTEGRATION suto_s3tables_catalog_integration;を実行- 結果に表示された
API_AWS_IAM_USER_ARNとAPI_AWS_EXTERNAL_IDを取得
- 結果に表示された
-
AWSコンソールに戻り、作成したIAMロールの「信頼されたエンティティ」を編集する
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "[API_AWS_IAM_USER_ARNのarn]"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId":"[API_AWS_EXTERNAL_IDの値]"
}
}
}
]
}
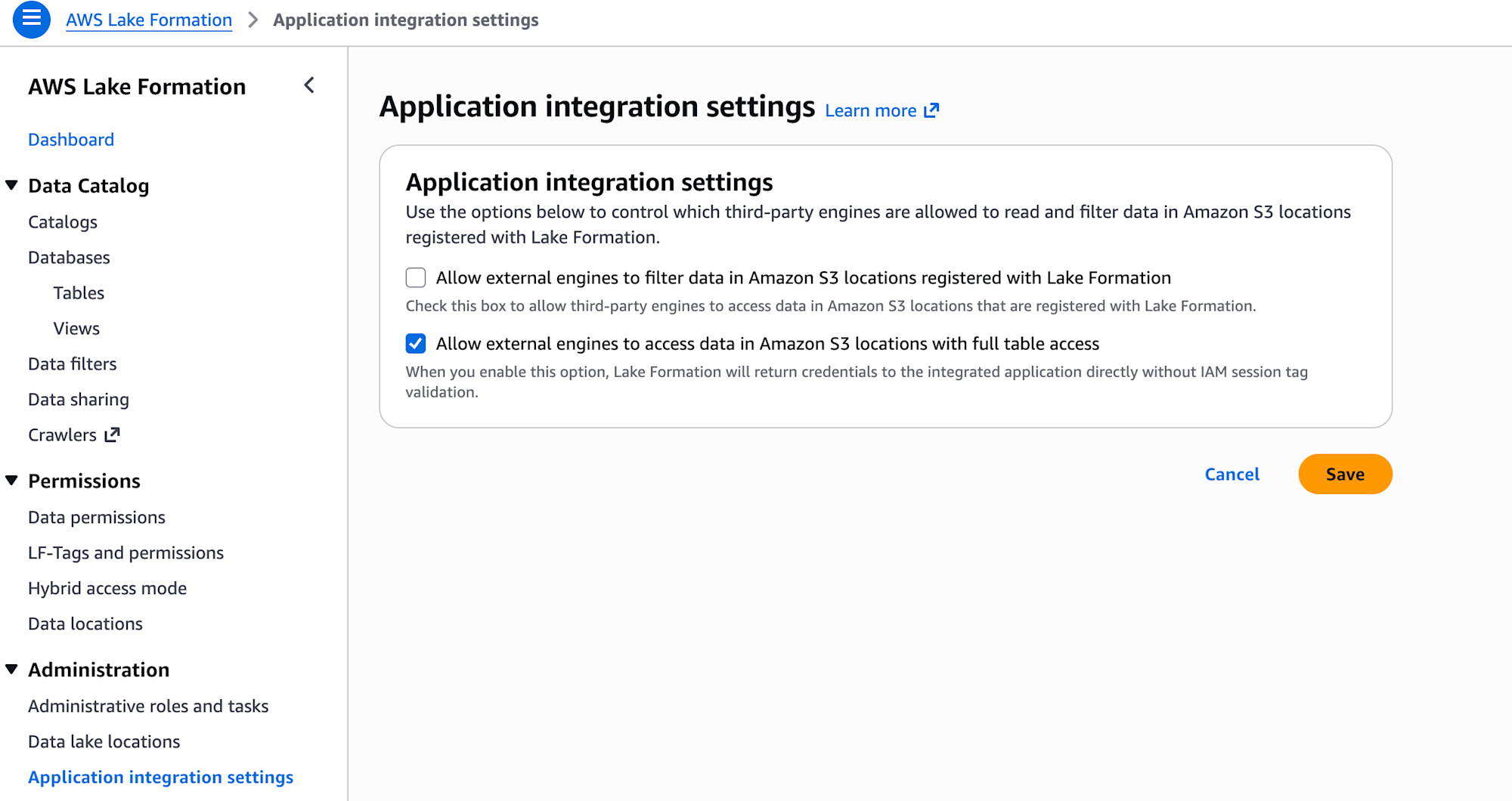
- AWS Lake Formationで、作成したIAMロールに権限を付与
| Resource Type | Resources | Permissions |
|---|---|---|
| Catalog | [アカウントID]:s3tablescatalog/cm-suto-table-bucket | Describe |
| Database | [アカウントID]:s3tablescatalog/cm-suto-table-bucket/test_namespace | Describe |
| Table | アカウントID]:s3tablescatalog/cm-suto-table-bucket/test_namespace/* ←(ALL TABLE) | * |

- 「Allow external engines to access data in Amazon S3 locations with full table access」にチェックを入れて保存
- Snowflakeがs3tablescatalogを参照できるようにすることで、Snowflake CATALOG INTEGRATIONでカタログ統合が実現できます
Icebergテーブルの作成
- Snowflakeコンソールの方に戻り、Icebergテーブルを作成
CREATE OR REPLACE ICEBERG TABLE SUTO_DB.TEST_S3_TABLES.s3_test_users
CATALOG = 'suto_s3tables_catalog_integration' --カタログ統合
CATALOG_NAMESPACE = 'test_namespace' --名前空間
CATALOG_TABLE_NAME = 'test_users' --テーブル名
AUTO_REFRESH = FALSE
;
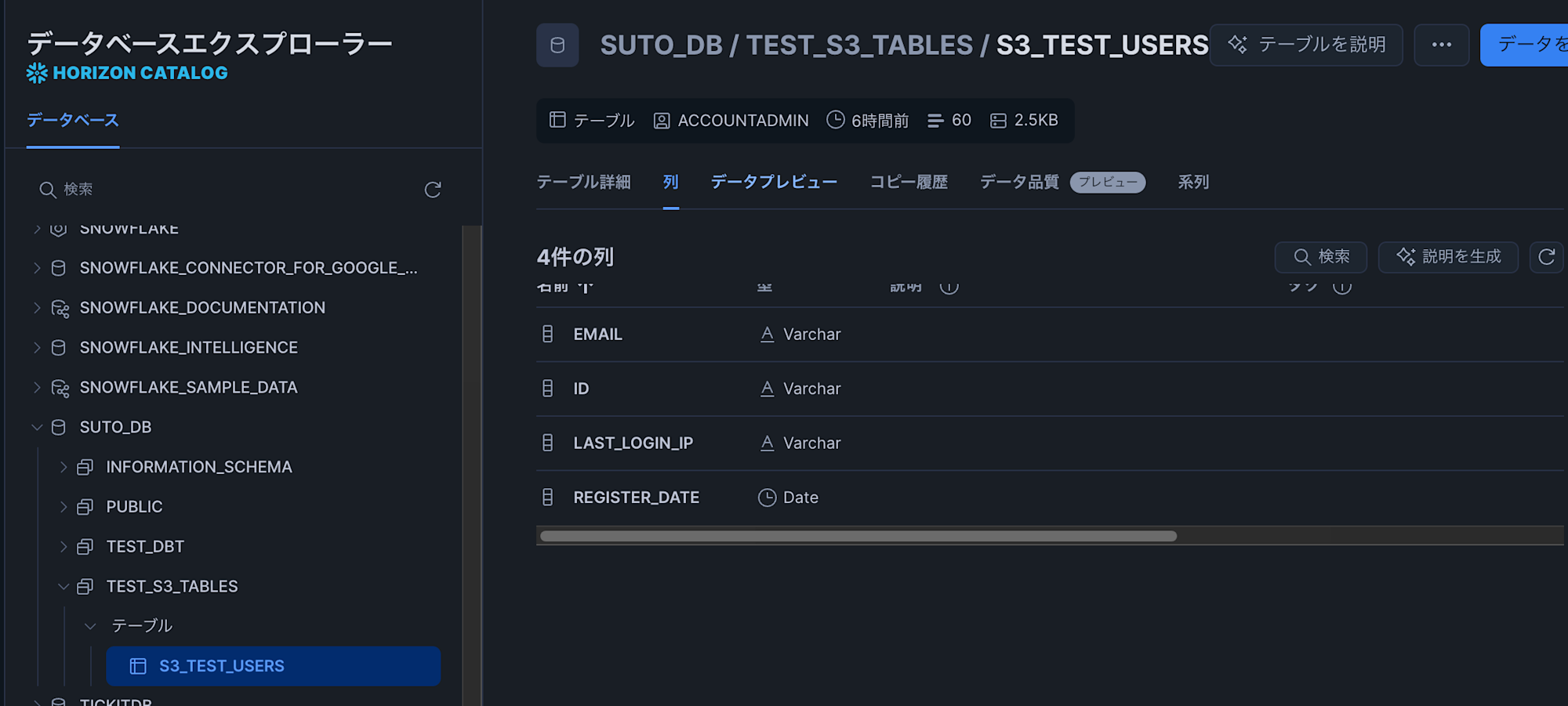
これでS3 Tablesのテーブル(test_namespace.test_users)を参照するテーブル(s3_test_users)が作成できました。
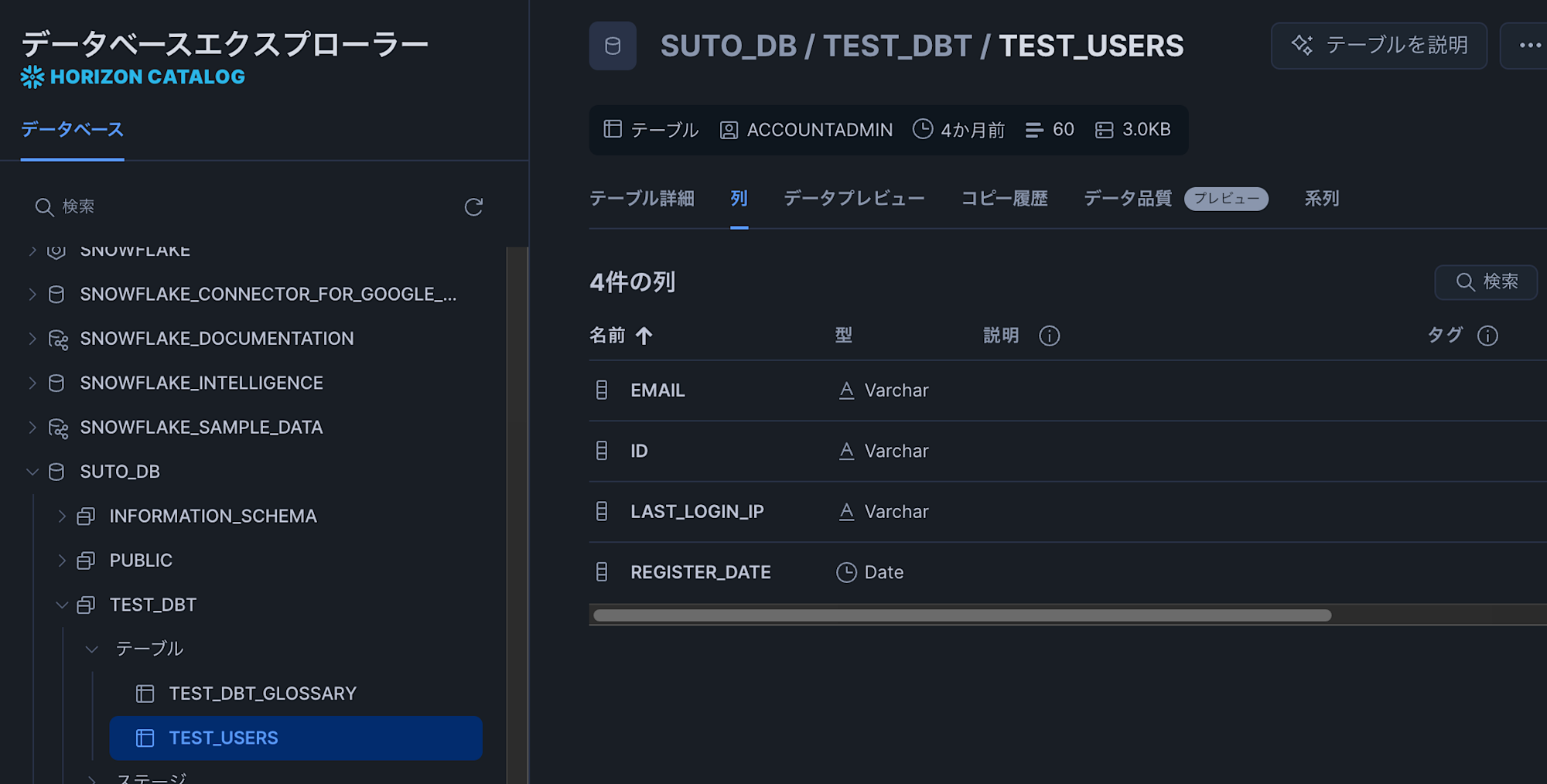
既存の通常テーブルを元にデータを挿入してみる
s3_test_usersに対してsnowflakeに事前に作成してある通常テーブルのデータをロードしてみます。
今回はカラム構成が同じテーブルである「TEST_DBT.test_users」というテーブルを準備しています。
- 以下のクエリを実行します
INSERT INTO SUTO_DB.TEST_S3_TABLES.s3_test_users
SELECT *
FROM SUTO_DB.TEST_DBT.test_users;
- クエリが成功し、Icebergテーブルにデータが問題なくロードされました(テーブル内のデータはダミーデータです)
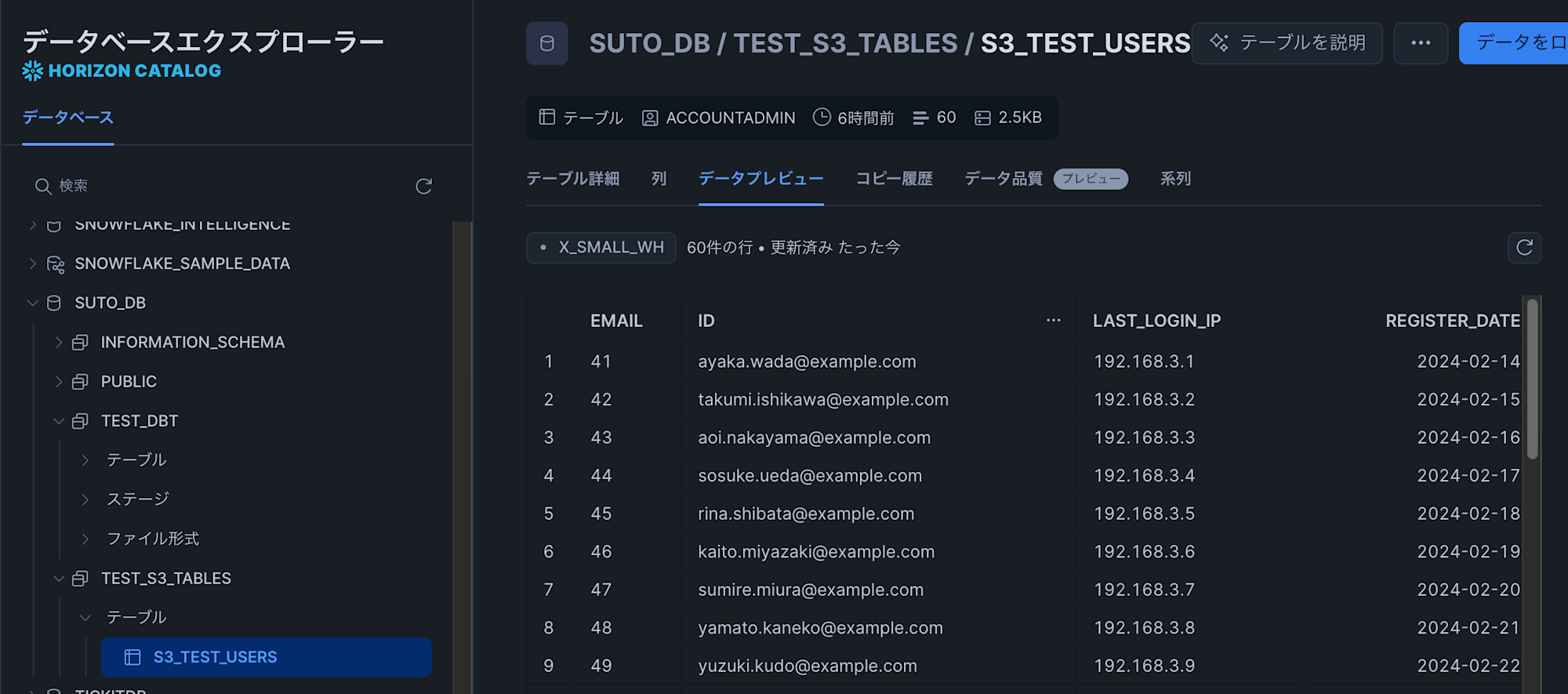
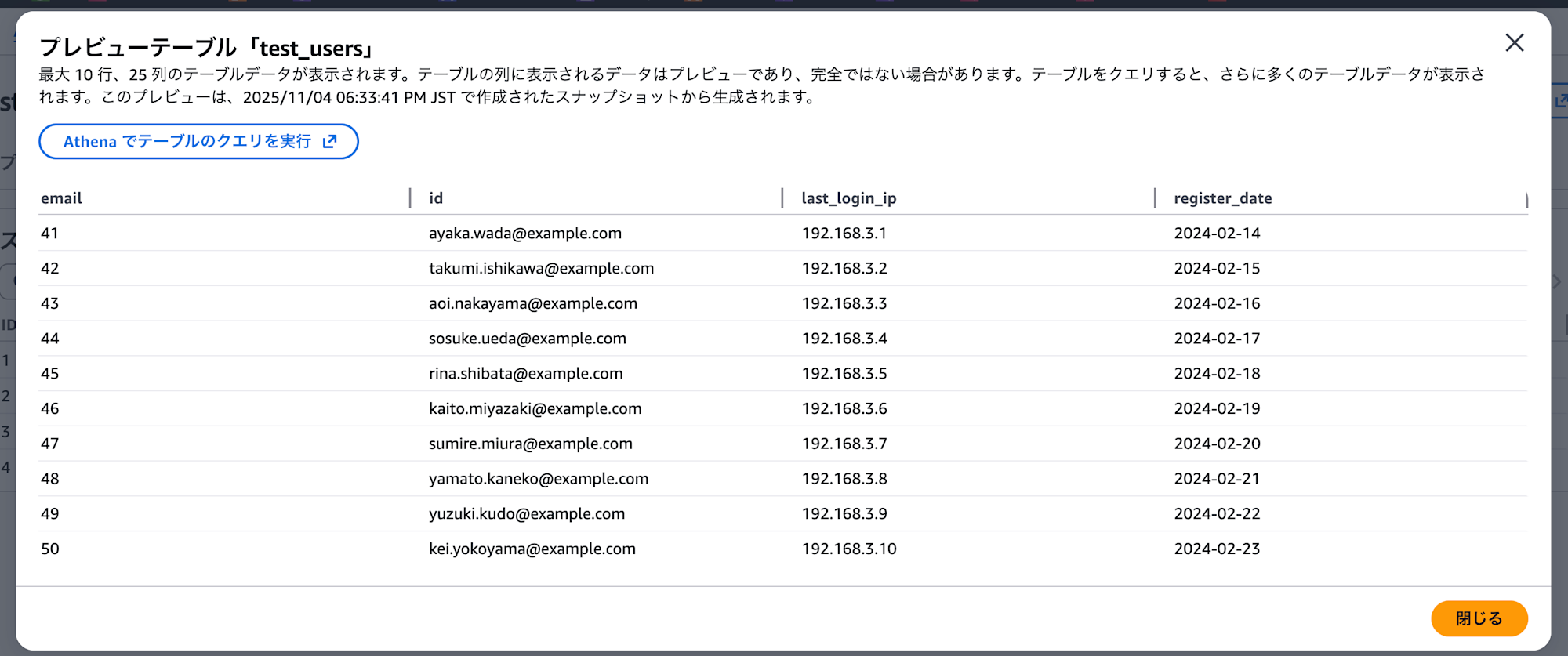
- また、AWSコンソールの方でS3 Tablesのテーブルプレビューで確認しても、データが問題なく表示されたので、S3側にデータが格納されていることがわかります。
所感
Snowflakeのカタログ統合を構成して、S3 TablesのテーブルをSnowflakeのIcebergテーブルを作成し、既存テーブルのデータを挿入してみました。
INSERT文を使っているので、TB以下の規模の大きくないデータであれば、「COPY INTOでS3外部ステージ経由でアンロード→GlueジョブによるS3 Tablesテーブル作成+データロード」という手間がなくともS3 Tablesへデータを持っていけそうです。
(CTASを使えるとよかったのですが、「外部Icebergカタログ」の扱いなので利用できませんでした。)
参考








