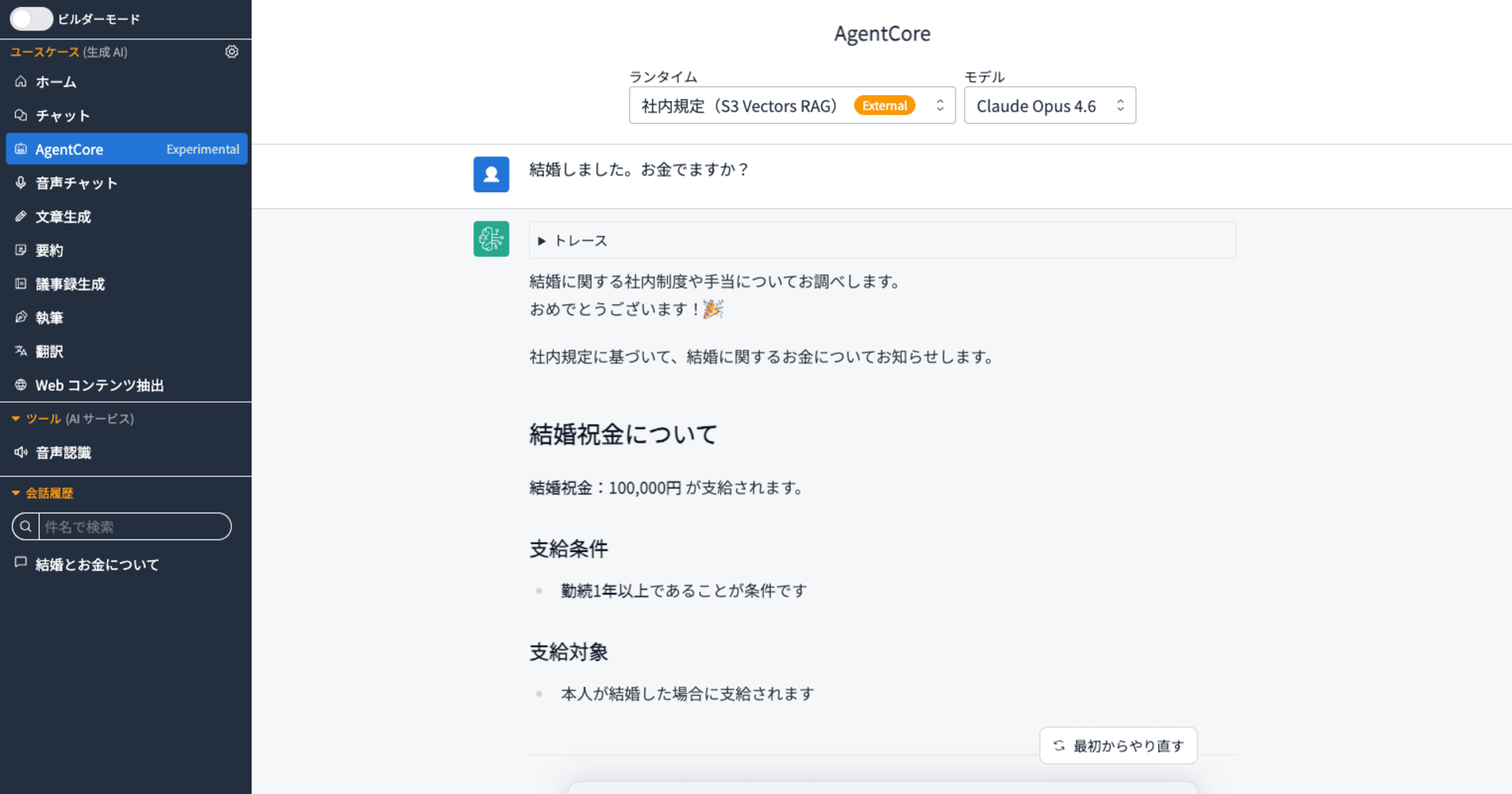
S3 Vectors と Bedrock で、サーバーレスなお手軽セマンティック検索基盤を構築してみた
Amazon S3 Vectors は、ベクトルデータの格納と類似検索に特化したサービスです。Amazon Bedrock の Embedding モデルと組み合わせることで、テキストのセマンティック検索(意味的な類似検索)をサーバーレスで構築できます。
今回、DevelopersIOの約6万件の記事データを題材に、この構成でどれほど手軽に検索基盤を構築できるのかを検証しました。その具体的な手順を紹介します。
- ベクトル化 — 記事要約を Bedrock Batch Inference で一括ベクトル化
- S3 Vectors 登録 — ベクトル + メタデータ(タイトル・著者)をインデックスに登録
- 検索 — AWS CLI で検索ワードをベクトル化 → S3 Vectors で類似検索 → 結果出力
アーキテクチャ
前提
入力データ: articles.jsonl
記事ID、タイトル、著者、slug、公開日、言語、要約を1行1記事のJSONLで用意しました。
{"id": "abc123def456ghi789jk01", "title": "dbt platform の Advanced CI で event_time による最適化機能を試してみた", "author": "yasuhara-tomoki", "slug": "dbt-platform-advanced-ci-event-time", "published_at": 1736920200, "language": "ja", "summary": "dbt platform Advanced CI機能は、Enterprise以上のプランで利用可能なCI最適化機能です。..."}
{"id": "xyz987wvu654tsr321qp02", "title": "CloudWatch Application Signals で複数の異なるルックバックウィンドウを持つバーンレートアラームを組み合わせつつ CDK で実装してみる", "author": "masukawa-kentaro", "slug": "cloudwatch-application-signals-burn-rate-alarm-cdk", "published_at": 1733797500, "language": "ja", "summary": "CloudWatch Application Signals でバーンレートアラームを複数のルックバックウィンドウで設..."}
| フィールド | 用途 |
|---|---|
id |
S3 Vectors のキー |
title |
ベクトル化入力 + メタデータ(non-filterable) |
author |
メタデータ(filterable) |
slug |
メタデータ(filterable・記事URL構築用) |
published_at |
メタデータ(filterable・epoch秒。範囲クエリ対応) |
language |
メタデータ(filterable) |
summary |
ベクトル化入力(title + summary を結合してベクトル化) |
※ published_at を epoch 秒(整数)で格納しているのは、S3 Vectors のフィルタ比較演算子($gte / $lt 等)が数値型のみ対応のためです。
モデル選定:Amazon Nova Embed v1
今回は amazon.nova-2-multimodal-embeddings-v1:0 を採用しました。2025年11月発表の新モデルで、現時点では us-east-1 のみの提供のためクロスリージョン利用となりますが、性能を優先して採用しました。1,000トークンあたり $0.00002(Batch Inference は更に50%割引)と非常に低コストで、数万件規模の一括ベクトル化にも適しています。Bedrock のマネージドサービス内で完結するため、外部モデルのホスティングや管理が不要な点もメリットです。
AWSリソース
| リソース | 値 |
|---|---|
| Embeddingモデル | amazon.nova-2-multimodal-embeddings-v1:0 |
| ベクトル次元 | 1024 |
| S3 Vectorsバケット | my-vectors-bucket |
| S3 Vectorsインデックス | my-blog-index |
| バッチ用S3 | my-batch-bucket |
| IAMロール | BedrockBatchInferenceRole |
Step 1: ベクトル化
今回は精度検証をクイックに行うため、手動の Python スクリプトで進めました。
1-1. Batch Inference 用 JSONL 生成
articles.jsonl から Bedrock Batch Inference の入力形式に変換しました。
import json
with open('articles.jsonl') as f_in, open('embed_input.jsonl', 'w') as f_out:
for line in f_in:
article = json.loads(line)
text = f"{article['title']}\n{article['summary']}"
record = {
'recordId': article['id'],
'modelInput': {
'schemaVersion': 'nova-multimodal-embed-v1',
'taskType': 'SINGLE_EMBEDDING',
'singleEmbeddingParams': {
'embeddingPurpose': 'GENERIC_INDEX',
'embeddingDimension': 1024,
'text': {'truncationMode': 'END', 'value': text}
}
}
}
f_out.write(json.dumps(record, ensure_ascii=False) + '\n')
1-2. S3 にアップロード
aws s3 cp embed_input.jsonl s3://my-batch-bucket/input-rag/embed_input.jsonl
1-3. Batch Inference ジョブ投入
import boto3
bedrock = boto3.client('bedrock', region_name='us-east-1')
resp = bedrock.create_model_invocation_job(
modelId='amazon.nova-2-multimodal-embeddings-v1:0',
jobName='rag-vectorize-demo',
roleArn='arn:aws:iam::<ACCOUNT_ID>:role/BedrockBatchInferenceRole',
inputDataConfig={
's3InputDataConfig': {
's3Uri': 's3://my-batch-bucket/input-rag/embed_input.jsonl'
}
},
outputDataConfig={
's3OutputDataConfig': {
's3Uri': 's3://my-batch-bucket/output-rag/'
}
}
)
job_arn = resp['jobArn']
print(f'ジョブARN: {job_arn}')
1-4. ジョブ完了待ち
import time
while True:
status = bedrock.get_model_invocation_job(jobIdentifier=job_arn)['status']
print(f'status: {status}')
if status in ('Completed', 'Failed', 'Stopped'):
break
time.sleep(60)
1,000件で約15分、入力116,945トークンで完了しました。Batch Inference の基本的な手順は、次の記事を踏襲しています。
Step 2: S3 Vectors 登録
2-1. インデックス作成(初回のみ)
metadataConfiguration で title を non-filterable(表示専用)に指定し、他の4項目を filterable にしました。
s3vectors = boto3.client('s3vectors', region_name='<YOUR_REGION>')
s3vectors.create_index(
vectorBucketName='my-vectors-bucket',
indexName='my-blog-index',
dataType='float32',
dimension=1024,
distanceMetric='cosine',
metadataConfiguration={
'nonFilterableMetadataKeys': ['title']
}
)
2-2. ベクトル + メタデータ結合 → 登録
バッチ出力のベクトルと、articles.jsonl のメタデータ(タイトル・著者・slug・公開日・言語)を結合して登録しました。
import json
import boto3
s3 = boto3.client('s3', region_name='us-east-1')
s3vectors = boto3.client('s3vectors', region_name='<YOUR_REGION>')
# articles.jsonl からメタデータをロード
article_meta = {}
with open('articles.jsonl') as f:
for line in f:
a = json.loads(line)
article_meta[a['id']] = {
'title': a['title'],
'author': a['author'],
'slug': a['slug'],
'published_at': a['published_at'],
'language': a['language']
}
# バッチ出力を読み込み、メタデータと結合して登録
resp = s3.get_object(
Bucket='my-batch-bucket',
Key='output-rag/<JOB_ID>/embed_input.jsonl.out'
)
vectors = []
total = 0
for line in resp['Body'].iter_lines():
result = json.loads(line)
article_id = result['recordId']
meta = article_meta.get(article_id, {})
vectors.append({
'key': article_id,
'data': {'float32': result['modelOutput']['embeddings'][0]['embedding']},
'metadata': {
'title': meta.get('title', ''),
'author': meta.get('author', ''),
'slug': meta.get('slug', ''),
'published_at': meta.get('published_at', 0), # epoch秒(int)で格納
'language': meta.get('language', '')
}
})
if len(vectors) >= 100:
s3vectors.put_vectors(
vectorBucketName='my-vectors-bucket',
indexName='my-blog-index',
vectors=vectors
)
total += len(vectors)
vectors = []
if vectors:
s3vectors.put_vectors(
vectorBucketName='my-vectors-bucket',
indexName='my-blog-index',
vectors=vectors
)
total += len(vectors)
print(f'登録完了: {total}件')
ポイント:
metadataにtitle、author、slug、published_at、languageを格納しました。検索時にDBへの問い合わせなしで記事のメタ情報を取得できますput_vectorsは upsert 動作。同じキーで再登録するとベクトル・メタデータが上書きになりますput_vectorsは1回あたり最大100件のため、100件単位でバッチ登録しています
S3 Vectors メタデータの制約
S3 Vectors のメタデータには以下の制約があります。
| 項目 | 制限 |
|---|---|
| メタデータ合計サイズ | 40 KB / ベクトル(filterable + non-filterable) |
| フィルタ可能メタデータ | 2 KB / ベクトル |
| メタデータキー数 | 50 キー / ベクトル |
| non-filterable キー数 | 10 キー / インデックス |
| 対応する型 | string, number, boolean, list |
フィルタ可能メタデータは 2KB 制限があります。表示用途のみであれば non-filterable メタデータとして登録すると 40KB まで利用できます。
non-filterable メタデータとして、title を設定しています。
メタデータフィルタリング
S3 Vectors は query_vectors の filter パラメータでメタデータによる絞り込みに対応しています。filter には dict を直接渡します。
# 特定の著者の記事のみ検索
result = s3vectors.query_vectors(
vectorBucketName=BUCKET_NAME,
indexName=INDEX_NAME,
queryVector={'float32': query_vector},
topK=10,
returnDistance=True,
returnMetadata=True,
filter={"author": {"$eq": "wakatsuki-ryuta"}}
)
日付で範囲指定する場合、$gte / $lt などの比較演算子は Number 型のみ対応しています。今回、範囲クエリの利用を想定し、published_at を epoch 秒(整数)で格納したことで、期間指定が可能になりました。
from datetime import datetime, timezone
# 2026年以降の記事のみ
epoch_2026 = int(datetime(2026, 1, 1, tzinfo=timezone.utc).timestamp())
result = s3vectors.query_vectors(
vectorBucketName=BUCKET_NAME,
indexName=INDEX_NAME,
queryVector={'float32': query_vector},
topK=10,
returnDistance=True,
returnMetadata=True,
filter={"published_at": {"$gte": epoch_2026}}
)
# 2025年の記事のみ(範囲指定)
epoch_2025 = int(datetime(2025, 1, 1, tzinfo=timezone.utc).timestamp())
result = s3vectors.query_vectors(
...,
filter={"published_at": {"$gte": epoch_2025, "$lt": epoch_2026}}
)
主な演算子:
| 演算子 | 対応型 | 説明 |
|---|---|---|
$eq |
string, number, boolean | 完全一致 |
$ne |
string, number, boolean | 不一致 |
$gt / $gte |
number | より大きい / 以上 |
$lt / $lte |
number | より小さい / 以下 |
$in / $nin |
array | いずれかに一致 / いずれにも不一致 |
$exists |
boolean | フィールドの存在確認 |
$and / $or |
array of filters | 論理 AND / OR |
詳細は Metadata filtering を参照してください。
Step 3: 検索
AWS CLI で検索する
Python を使わず、AWS CLI だけでも検索できました。
検索ワードをベクトル化
# リクエストボディを作成
cat > /tmp/embed_request.json << 'EOF'
{
"schemaVersion": "nova-multimodal-embed-v1",
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": 1024,
"text": {
"truncationMode": "END",
"value": "Lambda コールドスタート 対策"
}
}
}
EOF
# Bedrock でベクトル化(日本語はファイル経由で渡す)
aws bedrock-runtime invoke-model \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--region us-east-1 \
--content-type application/json \
--body fileb:///tmp/embed_request.json \
/tmp/query_vector.json
クエリベクトルを抽出して S3 Vectors で検索
# ベクトル配列を抽出
python3 -c "
import json
d = json.load(open('/tmp/query_vector.json'))
print(json.dumps(d['embeddings'][0]['embedding']))
" > /tmp/query_vec_array.json
# S3 Vectors で類似検索
aws s3vectors query-vectors \
--vector-bucket-name my-vectors-bucket \
--index-name my-blog-index \
--query-vector "float32=$(cat /tmp/query_vec_array.json)" \
--top-k 5 \
--return-distance \
--return-metadata \
--region <YOUR_REGION>
実行結果
{
"vectors": [
{
"distance": 0.1290004849433899,
"key": "article-001",
"metadata": {
"title": "Lambdaのコールドスタート問題と対策について整理する",
"published_at": 1732491853,
"language": "ja",
"author": "manabe-kenji",
"slug": "lambda-coldstart-measures"
}
},
{
"distance": 0.1369316577911377,
"key": "article-002",
"metadata": {
"language": "ja",
"slug": "lambda-cold-start-avoid-hack",
"published_at": 1559084450,
"title": "VPC Lambdaのコールドスタートにお悩みの方へ捧ぐコールドスタート予防のハック Lambdaを定期実行するならメモリの割り当ては1600Mがオススメ?!",
"author": "iwata-tomoya"
}
},
{
"distance": 0.14367318153381348,
"key": "article-003",
"metadata": {
"title": "LambdaのProvisioned Concurrencyを使って、コールドスタート対策をしてみた #reinvent",
"language": "ja",
"published_at": 1576128882,
"author": "sato-naoya",
"slug": "lambda-provisioned-concurrency-coldstart"
}
},
{
"distance": 0.15859538316726685,
"key": "article-004",
"metadata": {
"language": "ja",
"title": "[速報]コールドスタート対策のLambda定期実行とサヨナラ!! LambdaにProvisioned Concurrencyの設定が追加されました #reinvent",
"author": "iwata-tomoya",
"slug": "lambda-support-provisioned-concurrency",
"published_at": 1575418456
}
},
{
"distance": 0.16454929113388062,
"key": "article-005",
"metadata": {
"language": "ja",
"published_at": 1669858986,
"slug": "session-lamba-snapstart",
"author": "hamada-koji",
"title": "Lambdaのコールドスタートを解決するLambda SnapStartのセッションに参加してきた(SVS320) #reinvent"
}
}
],
"distanceMetric": "cosine"
}
--return-distance と --return-metadata を指定することで、距離スコアとメタデータ(タイトル・著者・slug・公開日・言語)が返りました。
cosine distance で値が小さいほど類似度が高くなります。「Lambda コールドスタート」に関連する記事が上位にヒットしました。
全量への拡張
パイロットの1,000件で動作確認ができたので、全量(約57,000件)も同じ手順で処理しました。Batch Inference の1ジョブあたり最大50,000件の制限があるため、入力を分割して投入しています。
| 項目 | 1,000件パイロット | 57,000件全量 |
|---|---|---|
| Batch Inference | ~15分 | ~30分(分割投入) |
| S3 Vectors 登録 | ~10秒 | ~10分 |
| Embedding コスト | ~$0.002 | ~$0.12 |
補足: 他の Embedding モデルへの対応
Titan Text Embeddings v2 の場合
Nova とは modelInput の形式が異なります。Titan は inputText / dimensions のシンプルな形式です。
record = {
'recordId': article['id'],
'modelInput': {
'inputText': f"{article['title']}\n{article['summary']}",
'dimensions': 1024,
'normalize': True
}
}
出力のベクトル取得パスも異なります。
| モデル | ベクトル取得パス |
|---|---|
| Nova Embed v1 | modelOutput['embeddings'][0]['embedding'] |
| Titan Embeddings v2 | modelOutput['embedding'] |
Cohere Embed v4 の場合
Cohere Embed v4 は Batch Inference に非対応ですが、リアルタイム API(invoke_model)で 最大96件のバッチ処理 に対応しており、数万件規模でも実用的な速度で処理できます。
import boto3, json
bedrock = boto3.client('bedrock-runtime', region_name='us-west-2')
resp = bedrock.invoke_model(
modelId='us.cohere.embed-v4:0',
body=json.dumps({
"texts": ["テキスト1", "テキスト2", ...], # 最大96件
"input_type": "search_document",
"embedding_types": ["float"],
"output_dimension": 1024
})
)
vectors = json.loads(resp['body'].read())['embeddings']['float']
注意点:
- 推論プロファイル経由が必須: モデルID
cohere.embed-v4:0を直接指定するとValidationExceptionになります。us.cohere.embed-v4:0(クロスリージョン推論プロファイル)を使用してください - 検索クエリ時は
input_typeを変更: 登録時は"search_document"、検索時は"search_query"を指定します - スロットリング対策: 大量処理時は指数バックオフのリトライを実装してください
| 項目 | Nova Embed v1 | Titan Embeddings v2 | Cohere Embed v4 |
|---|---|---|---|
| Batch Inference | 対応 | 対応 | 非対応 |
| リアルタイムバッチ | 1件ずつ | 1件ずつ | 最大96件/回 |
| モデルID | amazon.nova-2-multimodal-embeddings-v1:0 |
amazon.titan-embed-text-v2:0 |
us.cohere.embed-v4:0 |
| ベクトル取得パス | embeddings[0]['embedding'] |
embedding |
embeddings['float'] |
| 登録/検索の区別 | なし | なし | input_type で指定 |
ジョブ名の制約に注意
create_model_invocation_job の jobName は正規表現 [a-zA-Z0-9](-*[a-zA-Z0-9+\-.])* に制限されています。アンダースコア(_)は使用できません。
# エラー
bedrock.create_model_invocation_job(jobName='titan-embed-summary_en', ...)
# OK
bedrock.create_model_invocation_job(jobName='titan-embed-summary-en', ...)
要約タイプ名などにアンダースコアを含む場合は、ハイフンに変換してからジョブ名に使用してください。
まとめ
Bedrock Batch Inference で記事要約を一括ベクトル化し、S3 Vectors にメタデータとともに登録することで、セマンティック検索を構築しました。メタデータにタイトル・著者・slug・公開日・言語を持たせたことで、検索時にDBへの問い合わせなしで記事情報を取得でき、フィルタによる絞り込みも可能です。
Amazon S3 Vectors × Bedrock(amazon.nova-2-multimodal-embeddings-v1:0)なら、サーバーレスかつフルマネージドに、手軽に検索基盤を構築できます。
ただし、クエリあたりの取得件数は最大100件のため、大規模データでの複雑な重み付けやハイブリッド検索が必要な場合は別のアプローチも検討が必要です。全文検索や複雑なランキング調整が必要なら OpenSearch が適していますが、まずは低コストかつ管理不要でセマンティック検索を試したい場合には S3 Vectors をお試しください。