
コード進行からジャズの楽曲を検索するシステムを作ってみた
はじめに
ちょうど1年くらい前に趣味で作った個人用のシステムについて紹介します。個人用と書いてある通り、サービスとして公開しているわけではないです。
システムの全てについて細かく書いていくととんでもないボリュームになるので、伝えたい要素だけ抜粋してお届けします。
このシステムはベクトル検索を用いたシステムなのですが、私自身この分野は全然門外漢で、色々調べながら動くものを作ったという感じです。なので、詳しい人から見たらツッコミどころが多いかもしれませんが、その際は優しく教えていただけますと嬉しいです。
さて、作ったシステムがどんなシステムかというと、コード進行を入力すると、その進行に一致すると思われるジャズの曲を提示してくれる検索システムです。
音源が手元にある場合は既存の音楽認識サービスで曲名を調べられますし、浮かんでいる音がメロディーであれば鼻歌でも検索はできるかもしれません。ただ浮かんでいる音がコードのみの場合はそうはいきません。
私自身、頭の中でコードだけが流れて、「この曲なんだっけ...」と気持ち悪くなることが多く、そうした状況を解決するために作ったのが今回のシステムです。
ジャズは基本的にある曲のコード進行上で即興演奏を行いますが、コードそのものを変えることも多々あります。そのため、「この曲のコード進行は絶対にこれ」と決まっていないケースも多いです。自分の頭の中で鳴っているコードも、自分が勝手にアレンジしたものであることも多いです。
こうした状況では、単純に楽曲のコード進行を保持したDBを作って完全一致で検索するようなアプローチは有効ではありません。
今回はこの問題に対して、ベクトル検索というアプローチで対応することにしました。
今回は楽曲のコード進行や、特殊な音楽理論に基づくコード進行の変換といった要素が色々あり、既存サービスではベクトル化等が難しそうだったのでオリジナルで作りました。
仕組みはシンプルです。個々のコードを128次元のベクトルに変換し、進行を4つの時間ブロックに分けて各ブロックの平均ベクトルを連結した512次元のベクトルで表現します。PostgreSQLのpgvector拡張でコサイン類似度による近傍探索を行います。
技術スタックは TypeScript + Hono + PostgreSQL(pgvector)+ Next.js を使いました。
システムの全体像
システムのデータフローは以下の通りです。
【データ登録】
曲のコード進行データを用意
↓
パーサー(テキスト → 構造化データ)
↓
各拍にコードを割り当て
↓
一定の小節数ごとにブロックに分割
↓
各ブロックを512次元ベクトルに変換
↓
PostgreSQL + pgvector に格納・HNSWインデックス作成
【検索時】
ユーザーがコードを入力
↓
パーサー → 各拍にコードを割り当て
↓
データ登録時と同じルールでブロックに分割
↓
各ブロックを12キーに移調 & ネガティブハーモニー変換でクエリ作成
(例: 1ブロック → 12移調 × 2(原形+ネガティブハーモニー) = 24クエリ)
↓
pgvector でコサイン類似度検索(24クエリ並列実行)
↓
類似度順にソートして結果を返す
フロントエンドは小節×拍の入力欄にコードを入力して検索ボタンを押す作りになっています。
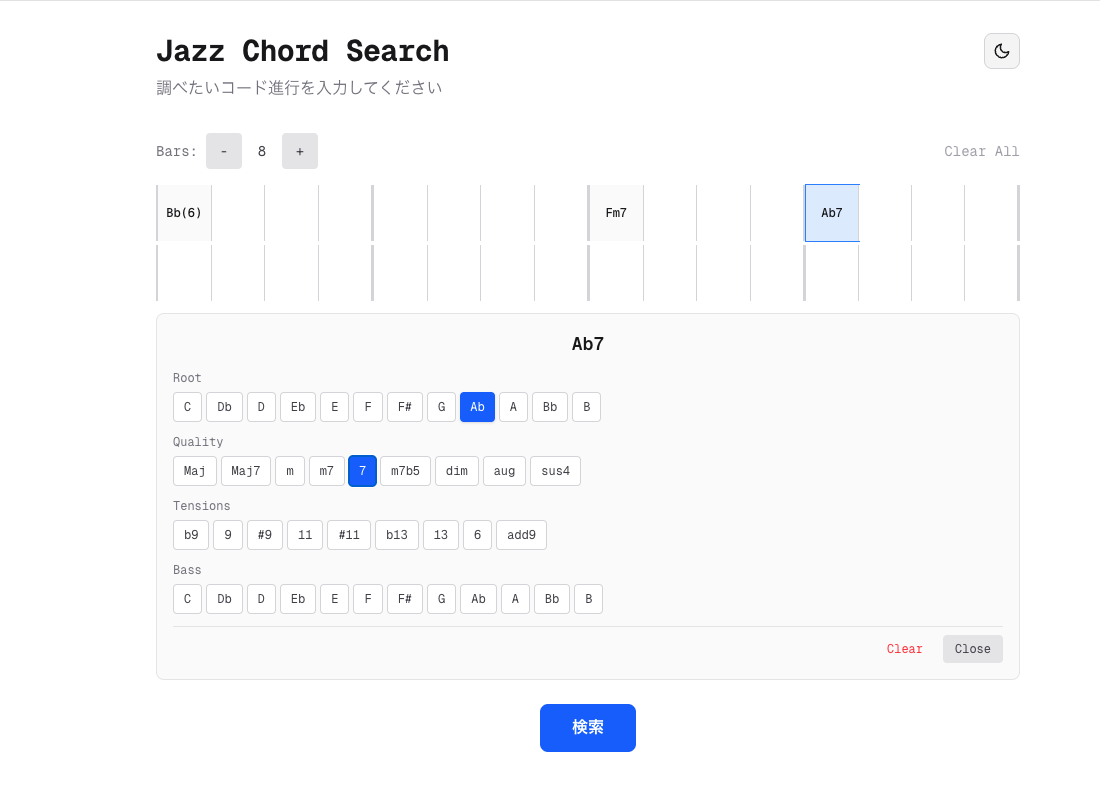
以降のセクションでは、このシステムのポイントを掘り下げます。
コードのベクトル化
コードのベクトル化の中身
1つのコードを以下の構造でベクトル化します。
| 次元 | 特徴 | 何を捉えるか |
|---|---|---|
| 0–11 (12dim) | ルート | 絶対的な音名(C, Db, D, ...) |
| 12–23 (12dim) | 五度圏上での関係 | 調性的な近さ |
| 24–35 (12dim) | ベース音 | 分数コード(例: C/G)のベース音を区別 |
| 36–44 (9dim) | 種類 | maj, min, dom7, m7b5 などコードの種類 |
| 45–56 (12dim) | 構成音(絶対音) | コード構成音を絶対音(C, E, G等)のフラグで表現。テンションは0.7倍の重み |
| 57–68 (12dim) | 構成音(ルートからの相対音) | キーに依存しない構造的類似性を表現するため |
| 69–81 (13dim) | テンション・omit・テンションスコア | テンション(b9, #11等)とomitの有無のフラグ(12dim)+テンション量の数値スコア |
| 82–90 (9dim) | 和声機能 | トニック(T)・サブドミナント(SD)・ドミナント(D)の分類と五度圏上の位置 |
| 91–114 (24dim) | コードの種類の詳細+組み合わせ | メジャーか、7thを含むか等の細分類フラグと、ルート×種類の掛け合わせ |
| 115–127 (13dim) | 拡張用の予備領域 | 後から新しい特徴を追加できるよう確保した余白。別のロジックでのリハモも組み込む予定でしたが、結局使いませんでした |
ポイントは、絶対音と相対音の両方を持たせていることです。
- 絶対音: 同じキーでの正確なマッチに寄与
- 相対音: キーが違っても構造が同じならマッチする
五度圏上での関係を数値化する
五度圏上での音と音の距離感をベクトルに反映するために、sin、cosで数値化しています。
function rootCircleOfFifths(root: number): number[] {
const pos = FIFTHS_POSITION[root]; // C=0, G=1, D=2, ...
const angle = (2 * Math.PI * pos) / 12;
const v: number[] = [];
for (let h = 1; h <= 6; h++) {
v.push(Math.sin(h * angle));
v.push(Math.cos(h * angle));
}
return v;
}
少ない小節数の入力に対応する
ユーザーは曲全体のコード進行をすべて打ち込むわけではなく、一部分を打ち込むことが多いです。曲の冒頭ではなく、途中の一部分を入力するかもしれません。なのでただ曲全体のコードと比較するだけではうまくいきません。
そこで、各楽曲をあらかじめ短いブロックに切り分けておきます。
- ブロックの長さ: 4小節・8小節・16小節の3種類
- 切り方: 2小節ずつずらしながら切り出す(1〜4小節目、3〜6小節目、5〜8小節目…)。曲のどの位置の進行を入力されてもマッチできる
- 各ブロックを個別にベクトル化 → pgvectorに格納
入力の小節数に応じて、対応する長さのブロックだけを検索対象にします。
function selectWindowSize(queryBars: number): number {
if (queryBars <= 6) return 4;
if (queryBars <= 12) return 8;
return 16;
}
bar_count(4/8/16小節)ごとにインデックスを分けて構築しているため、入力の小節数に応じて効率的に検索できます。
CREATE INDEX song_segments_bc4_idx ON song_segments
USING hnsw (embedding vector_cosine_ops)
WHERE bar_count = 4;
実装中に起きた問題
問題1: 短い入力だと完全一致でも正確にマッチしない問題
初期の実装では、ブロック内の全てのコードベクトルを平均して1本の128次元ベクトルにしていました。
[Dm7, G7, Cmaj7, A7]
→ (vec(Dm7) + vec(G7) + vec(Cmaj7) + vec(A7)) / 4
→ 128次元ベクトル
このアプローチでは、16小節くらいの長い入力でリハモが多少入っていても、平均化がノイズを吸収してくれるため、それなりに良いスコアが出ていました。
ところが、4小節などの短い入力で完全一致のコードを入力した際、マッチするはずの曲が1位にならず、同じコードを含む大量の曲が同スコアで並ぶという問題が起きました。
原因: 順番の情報が消えていた
原因は単純でした。ベクトルを足し合わせるとコードの順番の情報が消えてしまいます。
avg(Dm7, G7, Cmaj7, A7) = avg(G7, Dm7, A7, Cmaj7)
順序を区別できないと、たまたま同じコードを含む無数のブロックが全て同じスコアになってしまいます。
解決策
平均化する代わりに、ブロックを4つの時間グループに分割し、各グループの平均ベクトルを連結する方式に変更しました。
ブロック [Dm7 | G7 | Cmaj7 | A7] (4小節)
↓
Group 0: vec(Dm7) → 128次元
Group 1: vec(G7) → 128次元
Group 2: vec(Cmaj7) → 128次元
Group 3: vec(A7) → 128次元
↓
連結 → [Group0, Group1, Group2, Group3] = 512次元
↓
L2正規化
ブロックの長さに応じてグループの粒度が変わりますが、常に4グループ × 128次元 = 512次元です。
| ブロック | 各グループの粒度 | 順序保存の精度 |
|---|---|---|
| 4小節 | 1小節ごと | 完全(各小節が独立グループ) |
| 8小節 | 2小節ごと | 2小節ブロック単位 |
| 16小節 | 4小節ごと | 4小節ブロック単位 |
export function generateEmbedding(
events: BeatEvent[],
barCount?: number,
): number[] {
const expanded = expandBeats(events);
const bars = barCount ?? Math.max(...expanded.map((b) => b.bar)) + 1;
const barsPerGroup = bars / SEGMENT_GROUPS; // SEGMENT_GROUPS = 4
const groups = Array.from({ length: SEGMENT_GROUPS }, () =>
new Array(CHORD_DIM).fill(0),
);
const counts = new Array(SEGMENT_GROUPS).fill(0);
for (const beat of expanded) {
const g = Math.min(Math.floor(beat.bar / barsPerGroup), SEGMENT_GROUPS - 1);
const vec = chordToVector128(beat.chord);
for (let i = 0; i < CHORD_DIM; i++) groups[g][i] += vec[i];
counts[g]++;
}
const result: number[] = [];
for (let g = 0; g < SEGMENT_GROUPS; g++) {
if (counts[g] > 0) {
for (let i = 0; i < CHORD_DIM; i++) groups[g][i] /= counts[g];
}
result.push(...groups[g]);
}
return l2Normalize(result); // 512次元
}
この変更で問題が解消しました。
長い進行を入力した際の検索精度も維持されたままです。
問題2: 中途半端な小節数の入力だとマッチしない
ブロックの長さが4小節なのに、ユーザーが6小節を入力するとどうなるでしょうか。
前述のとおり、楽曲はあらかじめ4小節・8小節・16小節のブロックに切り分けてあります。6小節の入力に対しては、最も近い4小節のブロックと比較することになります。
ここで問題になるのが、ベクトル変換時の4グループへの分け方です。4小節を4グループに分ければ1グループ1小節ですが、6小節を4グループに分けると各グループに割り当てられる小節数が変わり、グループの境界がずれます。同じ進行を含んでいてもベクトルが大きく異なってしまい、マッチしなくなります。
実際に、Cherokeeの冒頭6小節を入力してもヒットしない問題が発生しました。具体的には
Group 0: bar 0, 1 ← 2小節
Group 1: bar 2 ← 1小節
Group 2: bar 3, 4 ← 2小節
Group 3: bar 5 ← 1小節
一方、DB側のCherokeeの4小節ブロック(1〜4小節目)は
Group 0: bar 0 ← 1小節
Group 1: bar 1 ← 1小節
Group 2: bar 2 ← 1小節
Group 3: bar 3 ← 1小節
Group 3の内容が全く異なるため、コサイン類似度が大きくずれてしまい、マッチしません。
解決策
入力側もDB登録時と同じやり方でブロックに切り分けるようにしました。6小節の入力なら、2小節ずつずらしながら4小節ずつ切り出して、それぞれで検索します。
6小節の入力 → 4小節ずつ、2小節ずらし
ブロック1: 1〜4小節目 → ベクトル化して検索
ブロック2: 3〜6小節目 → ベクトル化して検索
こうすると、DB側のブロック(1〜4小節目、3〜6小節目…)と同じグループ分けになるのでマッチするようになりました。
問題3: キーに対する依存
元データと違うキーで入力された場合のマッチ度が安定しない問題が起きていました。
128次元中48次元が絶対的な音名に依存しています。そのため、Cメジャーの ii-V-I(Dm7 → G7 → Cmaj7)と Dメジャーの ii-V-I(Em7 → A7 → Dmaj7)は、ベクトル空間上で同一にはなりません。
キー非依存の80次元(インターバル、和声機能等)のおかげで0.4〜0.6程度の類似度は出ますが、完全一致にはなりません。
検討したアプローチ
2つのアプローチを検討しました。
| ベクトルをキーに依存しない設計にする | 入力を全12キーに移調する | |
|---|---|---|
| DBの再構築 | 必要 | 不要 |
| 既存精度への影響 | 同キーの精密マッチの精度が劣化するリスク | 影響なし |
| 実装コスト | ベクトル設計のやり直し+DB再登録 | ほぼなし |
| リスク | 中〜高 | ほぼゼロ |
入力を12キーに移調する方式を採用しました。DB側のベクトルやスキーマに一切手を加えず、検索時に入力を12キー分コピーして並列に検索するだけです。
ネガティブハーモニーへの対応
上述のエニーキー対応に関連しますが、各移調に対してネガティブハーモニーの変換も適用します。
ネガティブハーモニーとは、ルートと完全5度の間の軸で音を反転させる手法です。
「これは写像で定義できるのでは?」と思い、その方針で実装してみることにしました。
実装では、コードの構成音を1音ずつ以下の式で反転します。
p' = (2K + 7 - p) mod 12
ここでKはキー(0=C, 1=Db, ...)、pは変換前の音です。
たとえばKey=CでCmaj7を変換すると:
Cmaj7の構成音 {C, E, G, B}
→ 各音を反転 → {G, Eb, C, Ab}
→ コード同定 → Abmaj7
反転後の音の集合からコードを定めるには、集合内の各音をルート候補として試し、そのルートから見てコードの種類(maj7, min7, dom7 など)の構成音がすべて含まれているかを確認します。含まれている場合、残りの音がテンション(b9, #11等)として説明できるかも検証します。複数の解釈が成立する場合は、構成音数が多いコードの種類を優先することで、テンションを含むコードでも正確に変換できます。
検索フロー
以上を組み合わせると、検索の流れはこうなります。
// 入力をDB登録時と同じルールで切り分ける
const step = windowSize / 2;
const windows: BeatEvent[][] = [];
for (let start = 0; start + windowSize <= queryBars; start += step) {
const winEvents = events
.filter((e) => e.bar >= start && e.bar < start + windowSize)
.map((e) => ({ ...e, bar: e.bar - start }));
if (winEvents.length > 0) windows.push(winEvents);
}
if (windows.length === 0) windows.push(events);
// 各ブロック × 12キー × 2(原形+ネガティブハーモニー版)をすべてベクトル化
const embeddings: number[][] = [];
for (const winEvents of windows) {
for (let semitones = 0; semitones < 12; semitones++) {
const transposed =
semitones === 0 ? winEvents : transposeEvents(winEvents, semitones);
embeddings.push(generateEmbedding(transposed, windowSize));
const key = detectKey(transposed);
const nh = negativeHarmonyEvents(transposed, key);
embeddings.push(generateEmbedding(nh, windowSize));
}
}
const allResults = await searchSegmentsMulti(embeddings, windowSize, limit);
ブロック数 × 12キー × 2(原形+ネガティブハーモニー版)のベクトルをすべてDBに投げ、同じ曲が複数ヒットした場合は最も類似度が高いものだけを残します。4小節の入力なら24個、6小節なら48個のクエリになります。
const bestPerSong = new Map<string, SegmentSearchResult>();
for (const results of allResults) {
for (const r of results) {
const existing = bestPerSong.get(r.songId);
if (!existing || r.score > existing.score) {
bestPerSong.set(r.songId, r);
}
}
}
まとめ
なんとなくの思いつきから作りましたが、結構精度の高いものができて満足です。
作るのはめちゃくちゃ大変だったのですが、先日Agent Teamsに同じものを仕様だけ投げて作ってもらったら、一瞬で完成度の高いものを出してきて、嬉しさ半分悲しさ半分という気持ちでした。
今度そのAgent Teamsを使ってみた感想もブログに書こうと思います。









