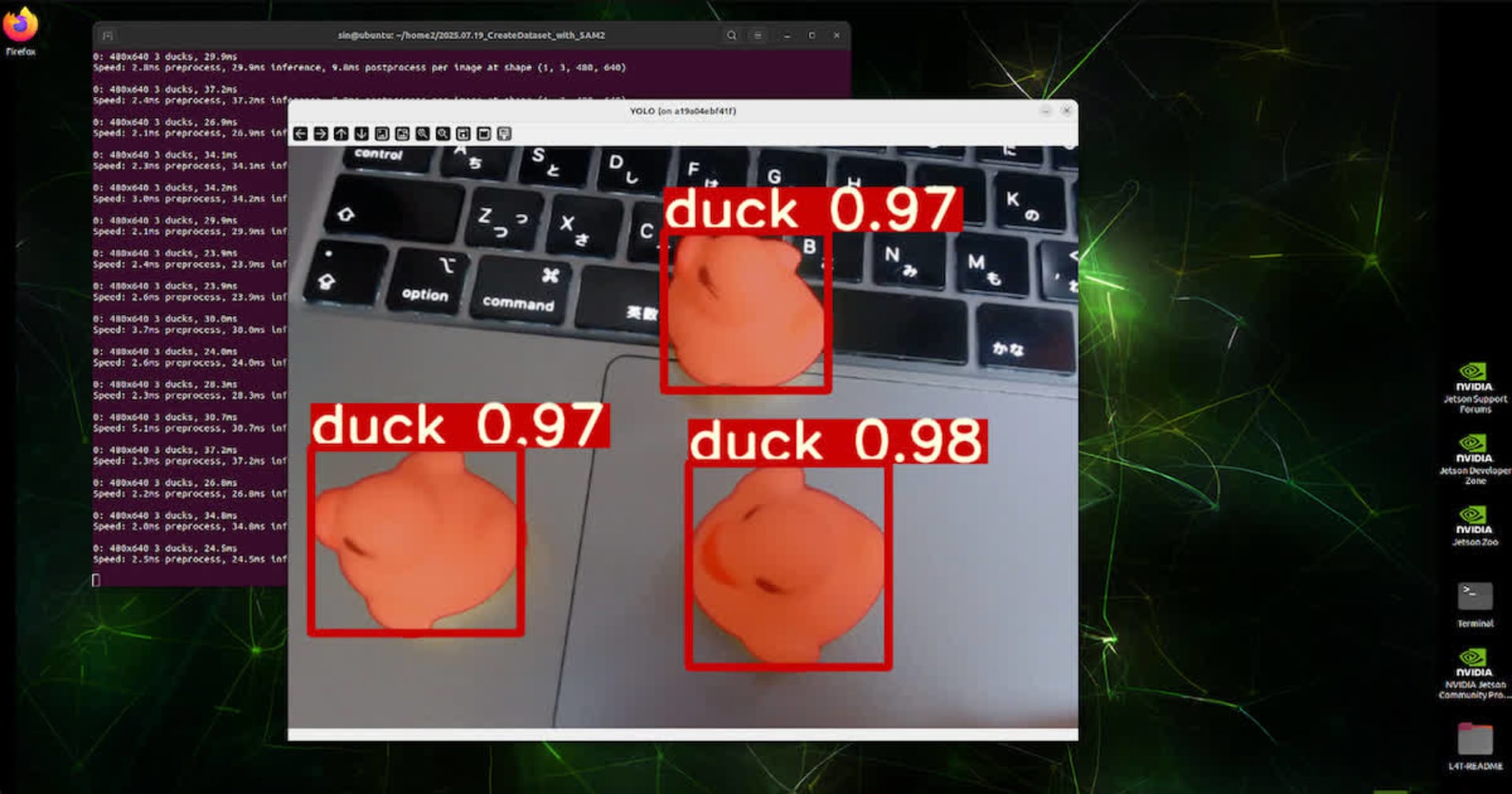
ぬいぐるみを検出するモデルをYOLOv5で作成し、ONNX形式に変換してRaspberryPIで使用してみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
1 はじめに
CX 事業本部 delivery部の平内(SIN)です。
「ぬいぐるみ」の物体検出は、結構、むつかしくて、色々試していたのですが、なかなか精度の高いものを作れていませんでした。 しかし、Segment Anythingを使用して、手返し良くたデータセットを作成することで、いい感じのモデルになったので、今回はこちらを、紹介させてください。
また、AWS IoT Greengrassは、ONNXRuntimeにも対応しているとのことで、こちらでも試してみたいので、今回は、ONNXへ変換して、RaspberryPIで使用してみました。
https://github.com/aws-samples/aws-iot-gg-onnx-runtime
2 YOLOv5
Segment Anythingでデータセットを作成するには、検出したい物体を撮影し、その動画からバウンディングボックで切り取られた透過画像を生成します。


そして、適当な背景を合成することでデータセットを作成しています。

「データセットを手返し良く」という意味で、モデルは逐次作成して確認しながら進めています。精度が納得できない場合、その場面の動画を撮影して、データを追加し、再度モデルを作成するという作業の繰り返しです。
今回、最終的に利用されたデータセットは、以下のようになりました。
- 30秒程度の動画
- TOMATO × 12本、 AHIRU × 12本
- SegmentAnythingで作成した、透過PNG
- TOMATO 1,222枚、 AHIRU × 1,228枚
- データセット
- 画像 3,000枚
- アノテーション(バウンディングボックス) 約32,000
YOLOv5のファインチューニングについては、下記をご参照ください。
3 ONNX
YOKOv5で提供されている export.py で、ONNX形式のモデルを簡単に作成できます。
$ python3 export.py --weights best.pt --include onnx $ ls -al -rw-r--r-- 1 root root 28509774 May 28 04:34 best.onnx -rw-r--r-- 1 root root 14391485 May 28 04:33 best.pt
参考:https://docs.ultralytics.com/yolov5/tutorials/model_export/
入出力の形式は、以下のようになっていました。
confirm.py
import onnxruntime
sess = onnxruntime.InferenceSession("./best.onnx")
print(sess.get_inputs()[0])
print(sess.get_outputs()[0])
best.onnx
$ python3 confirm.py NodeArg(name='images', type='tensor(float)', shape=[1, 3, 640, 640]) NodeArg(name='output0', type='tensor(float)', shape=[1, 25200, 7])
4 RaspberryPi
使用したのは、RaspberryPi 4B(4G) で、OSは、今年5月の最新版(2023-05-03) Raspberry Pi OS (64-bit) A port Debian Bullseye with the Respbeyy Pi Desktop (Compatible with Raspberry Pi 3/4/400)です。

$ cat /proc/cpuinfo | grep Revision Revision : c03112 $ lsb_release -a No LSB modules are available. Distributor ID: Debian Description: Debian GNU/Linux 11 (bullseye) Release: 11 Codename: bullseye $ uname -a Linux raspberrypi 6.1.21-v8+ #1642 SMP PREEMPT Mon Apr 3 17:24:16 BST 2023 aarch64 GNU/Linux $ getconf LONG_BIT 64
最新の機械学習関連のライブラリは、64bit版OSでは、pipで簡単にインストールできます。
$ pip install opencv-python Successfully installed opencv-python-4.7.0.72 $ pip install onnxruntime Successfully installed coloredlogs-15.0.1 flatbuffers-20181003210633 humanfriendly-10.0 mpmath-1.3.0 numpy-1.24.3 onnxruntime-1.15.0 packaging-23.1 protobuf-4.23.2 sympy-1.12 $ pip install torch Successfully installed filelock-3.12.0 networkx-3.1 torch-2.0.1 $ pip install torchvision Successfully installed torchvision-0.15.2 $ pip install onnx Successfully installed onnx-1.14.0
RaspberryPIのインストーラで、デフォルトとなっている32bitOSを使用すると、上記の最新ライブラリは、pip installだけではインストールできませんでした。例えば、下記のように、少し前のバージョンのwheelsを使用したり、コンパイルすることになってしまうので、ちょっと面倒かもしれません。
$ wget https://github.com/nknytk/built-onnxruntime-for-raspberrypi-linux/raw/master/wheels/bullseye/onnxruntime-1.14.0-cp39-cp39-linux_armv7l.whl $ sudo pip install onnxruntime-1.14.0-cp39-cp39-linux_armv7l.whl
5 動作確認
動作確認した様子です。
RaspberryPI上で、写真を推論しています。


コードです。https://github.com/ultralytics/yolov5/blob/master/detect.pyを参考にさせて頂きました。
detect.py
import numpy as np
import cv2
import math
import torch
import time
import torchvision
import onnxruntime
def box_label(
img, box, line_width, label="", color=(128, 128, 128), txt_color=(255, 255, 255)
):
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
cv2.rectangle(img, p1, p2, color, thickness=line_width, lineType=cv2.LINE_AA)
if label:
tf = max(3 - 1, 1)
w, h = cv2.getTextSize(label, 0, fontScale=3 / 3, thickness=tf)[0]
outside = p1[1] - h >= 3
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
cv2.rectangle(img, p1, p2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
0,
3 / 3,
txt_color,
thickness=tf,
lineType=cv2.LINE_AA,
)
return img
def xywh2xyxy(x):
y = x.clone()
y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x
y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y
y[..., 2] = x[..., 0] + x[..., 2] / 2 # bottom right x
y[..., 3] = x[..., 1] + x[..., 3] / 2 # bottom right y
return y
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
agnostic=False,
labels=(),
max_det=300,
nm=0,
):
bs = prediction.shape[0] # batch size
nc = prediction.shape[2] - nm - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
max_wh = 7680 # (pixels) maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 0.5 + 0.05 * bs # seconds to quit after
t = time.time()
mi = 5 + nc
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
x = x[xc[xi]] # confidence
if labels and len(labels[xi]):
lb = labels[xi]
v = torch.zeros((len(lb), nc + nm + 5), device=x.device)
v[:, :4] = lb[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
if not x.shape[0]:
continue
x[:, 5:] *= x[:, 4:5]
box = xywh2xyxy(x[:, :4])
mask = x[:, mi:]
conf, j = x[:, 5:mi].max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
n = x.shape[0]
if not n:
continue
x = x[x[:, 4].argsort(descending=True)[:max_nms]]
c = x[:, 5:6] * (0 if agnostic else max_wh)
boxes, scores = x[:, :4] + c, x[:, 4]
i = torchvision.ops.nms(boxes, scores, iou_thres)
i = i[:max_det]
output[xi] = x[i]
if (time.time() - t) > time_limit:
break
return output
def letterbox(
im,
new_shape=(640, 640),
color=(114, 114, 114),
scaleup=True,
stride=32,
):
shape = im.shape[:2] # current shape [height, width]
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(
im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color
)
return im, ratio, (dw, dh)
def clip_boxes(boxes, shape):
# Clip boxes (xyxy) to image shape (height, width)
boxes[..., 0].clamp_(0, shape[1]) # x1
boxes[..., 1].clamp_(0, shape[0]) # y1
boxes[..., 2].clamp_(0, shape[1]) # x2
boxes[..., 3].clamp_(0, shape[0]) # y2
def scale_boxes(img1_shape, boxes, img0_shape):
gain = min(
img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]
) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (
img1_shape[0] - img0_shape[0] * gain
) / 2 # wh padding
boxes[..., [0, 2]] -= pad[0] # x padding
boxes[..., [1, 3]] -= pad[1] # y padding
boxes[..., :4] /= gain
clip_boxes(boxes, img0_shape)
return boxes
colors = [(0, 0, 200), (200, 200, 0)]
line_width = 6
def main():
# weights = "./yolov5s.onnx"
weights = "./best.onnx"
input_path = "test-images"
output_path = "output"
files = [
"001.jpg",
"002.jpg",
"003.jpg",
"004.jpg",
"005.jpg",
"006.jpg",
"007.jpg",
"008.jpg",
"009.jpg",
"010.jpg"
]
session = onnxruntime.InferenceSession(weights, providers=["CPUExecutionProvider"])
for file in files:
input_file = "{}/{}".format(input_path, file)
output_file = "{}/{}".format(output_path, file)
run(session, input_file, output_file)
def run(session, input_file, output_file):
print("input_file:{} output_file:{}".format(input_file, output_file))
max_det = 1000 # maximum detections per image
# conf_thres = 0.25 # confidence threshold
# iou_thres = 0.45 # NMS IOU threshold
conf_thres = 0.5 # confidence threshold
iou_thres = 0.45 # NMS IOU threshold
imgsz = (640, 640)
agnostic_nms = False
hide_conf = False
stride = 32
meta = session.get_modelmeta().custom_metadata_map
if "stride" in meta:
stride, names = int(meta["stride"]), eval(meta["names"])
fp16 = False
imgsz = list(imgsz)
imgsz = [max(math.ceil(x / int(stride)) * int(stride), 0) for x in imgsz]
output_names = [x.name for x in session.get_outputs()]
im0s = cv2.imread(input_file) # BGR
im = letterbox(im0s, [640, 640], stride=32)[0] # padded resize
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im) # contiguous
im = torch.from_numpy(im)
im = im.half() if fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
im = im[None] # [3, 640, 480] => [1, 3, 640, 480]
# inference
im = im.cpu().numpy() # torch to numpy
y = session.run(output_names, {session.get_inputs()[0].name: im})
pred = torch.from_numpy(y[0])
pred = non_max_suppression(
pred, conf_thres, iou_thres, agnostic_nms, max_det=max_det
)
for det in pred:
im0 = im0s.copy()
if len(det):
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
for *xyxy, conf, cls in reversed(det):
c = int(cls)
label = names if hide_conf else f"{names} {conf:.2f}" #
im0 = box_label(
im0, xyxy, line_width, label, color=colors
)
cv2.imwrite(output_file, im0)
if __name__ == "__main__":
main()
6 最後に
改めて実感してますが、Segment Anythingを使用したデータセット作成は、強力です。
透過PNGの切り出しもGPU環境であれば、フレーム単位の処理時間は1秒程度なので、そこまで時間もかかりませんでした。
もう少し工夫すれば、「手返し」も更にに良くなるのではと、妄想しております。