
Amazon Bedrock Knowledge Bases × OpenSearch Serverless で貯めたドキュメントについてAI に質問できる環境をつくってみた
製造ビジネステクノロジー部の小林です。
今回は Knowledge Base を使って RAG を作ってみました。
「過去の設計メモや議事録、調査資料があちこちに散らばっていて、参照したいときに見つからない…」
そんなドキュメントが溜まっているのに活用できていない悩みを解決するのが RAG (Retrieval-Augmented Generation : 検索拡張生成) 。LLM を使って手元のドキュメントを検索し、その内容を踏まえた回答を生成させる仕組みです。
本記事では、Amazon Bedrock Knowledge Bases を使って「貯めたドキュメントに AI で質問できる」環境をつくってみます。
RAG とは
RAG は、LLM に外部のデータベースやドキュメントを検索させ、その検索結果を元に回答を生成させる技術です。これにより、
- LLM が学習していない自分だけのドキュメントの内容
- 学習データのカットオフ以降の最新情報
を踏まえた回答を引き出せます。素の LLM の弱点であるハルシネーションを抑えつつ、ソース (引用元) 付きで回答してくれるため、「どの資料に書いてあったか」をその場で確認できるのもうれしいポイントです。
そもそも Amazon Bedrock とは
本記事で使う Amazon Bedrock について、簡単におさらいしておきます。
Amazon Bedrock は、複数の AI 企業が提供する基盤モデル (Foundation Model) を、AWS の単一 API で利用できるフルマネージドサービスです。
Anthropic の Claude、Amazon の Nova / Titan、Meta の Llama、Mistral、Cohere、OpenAI の GPT などのモデルをサーバーレスな API で呼び出せます。
ポイントは「モデルそのもの」ではなく「モデルへのアクセス層」だという位置づけ。AWS が GPU の調達や運用、スケーリング、認証基盤をすべて管理してくれるため、利用者は API を叩くだけ。アクセス制御は IAM ロールで完結し、外部のサービスキーを管理する必要がありません。
外部 SaaS との比較
OpenAI API などの外部 SaaS と比べた強みはざっくり以下のとおり。
- データが AWS アカウント内に閉じる: 入出力は学習に利用されないし、VPC 内に閉じられる
- IAM ベースの権限管理: API キーを発行・ローテーションする運用が不要
- AWS エコシステムとの統合: CloudWatch でログ、S3 でデータソース、Lambda で呼び出しなど、既存サービスとシームレスに接続
- 複数モデルの使い分け: 同じ API で Claude も Llama も Nova も切り替えられる
- コンプライアンス: HIPAA、ISO、SOC、FedRAMP High などに対応
SageMaker との違い
Amazon SageMaker との使い分けについて、以下のとおり異なる役割を担っています。
- SageMaker: モデルを自分で訓練・運用するためのプラットフォーム
- Bedrock: 訓練済みモデルを即座に活用したいユースケース向け
Bedrock の位置づけ
Amazon Bedrock の機能一覧
Bedrock は単に「モデルを叩く API」ではなく、生成 AI アプリの本番運用に必要な機能をプラットフォームとしてまとめて提供しているのが大きな特徴です。2026 年時点で利用可能な主要機能を整理すると以下のとおり。
| カテゴリ | 機能 | 役割 |
|---|---|---|
| モデル呼び出し | InvokeModel / Converse API | 基本のモデル呼び出し。各モデル共通のメッセージ形式で叩ける |
| Cross-Region Inference | リージョン間で自動フェイルオーバー | |
| Batch Inference | 非同期バッチ処理 (通常の半額) | |
| Provisioned Throughput | 専用スループットを予約購入、安定した大量推論向け | |
| Priority / Flex Tiers | 用途別のサービスティア (Priority は低レイテンシ、Flex は安価) | |
| データ活用 (RAG 系) | Knowledge Bases | 後述する RAG パイプライン |
| Data Automation | 非構造データ (PDF / 動画 / 音声) を構造化 | |
| エージェント系 | Agents | 設定ベースの管理型エージェント (Action Groups、KB 連携、Memory、Guardrails) |
| AgentCore | フレームワーク非依存のプロダクション向けエージェント基盤 (Runtime / Gateway / Memory / Identity / Observability) | |
| Flows | ノードベースのビジュアルワークフロー | |
| 品質・安全性 | Guardrails | 入出力の有害コンテンツフィルタ。動推論によるハルシネーション検知 |
| Evaluations | モデル出力の品質評価 | |
| Prompt Management | プロンプトのバージョン管理 | |
| コスト最適化 | Prompt Caching | プロンプト前置部のキャッシュ (最大 1 時間)、コスト削減 |
| Intelligent Prompt Routing | 品質を保ったまま最安モデルへ自動振り分け (最大 30% コスト減) | |
| Model Distillation | 蒸留モデルの作成 (最大 500% 高速、75% コスト減) | |
| カスタマイズ | Custom Model Import | 独自モデルの持ち込み |
| Fine-tuning | 提供モデルに対する追加学習 | |
| その他 | Marketplace | サードパーティモデルの追加調達 |
このうち今回扱うのは Knowledge Bases。次の章で詳しく見ていきます。
Knowledge Bases とは
Knowledge Bases は、社内ドキュメントなどの独自データに基づいて回答を生成する RAG パイプラインを、フルマネージドで提供する機能です。
通常、RAG を自前で実装しようとすると以下の作業が必要になります。
- ドキュメントを読み込んでテキスト抽出 (PDF / Word のパース)
- テキストをチャンクに分割
- 埋め込みモデルでベクトル化
- ベクトルストアに格納
- クエリをベクトル化して類似検索
- 検索結果を生成モデルに渡してプロンプト構築
- 引用元情報の管理
Knowledge Bases を使うと、これらが全部マネージドになります。利用者は「S3 にファイルを置いて、ベクトルストアと埋め込みモデルを選んで、同期ボタンを押す」だけで RAG 環境が立ち上がります。
提供形態は 2 種類ある
Knowledge Bases には現在 2 つの提供形態があります。
| 形態 | 概要 | 適した用途 |
|---|---|---|
| Self-managed Knowledge Base | ベクトルストアやチャンク戦略、埋め込みモデルを自分で選べる従来型 | 細かいチューニングをしたい、構成を理解しておきたい |
| Managed Knowledge Base (2026 年 6 月 17 日 GA) | ベクトルストアの選定すら不要のフルマネージド版。SharePoint、Confluence、Google Drive 等のコネクタも追加 | とにかく早く立ち上げたい、データソースが SaaS にある |
本記事では、構成要素を理解しながら進める意味で Self-managed を使ってハンズオンします。
Self-managed Knowledge Base の主要コンポーネント
Self-managed Knowledge Base は以下の要素から構成されます。
- データソース: S3 バケットなど、ドキュメントの保管場所
- 埋め込みモデル: テキストをベクトルに変換するモデル (Titan Text Embeddings V2、Cohere Embed 等)
- ベクトルストア: ベクトル化された情報を格納する DB (OpenSearch Serverless、Aurora、Neptune Analytics 等)
- 生成モデル: 検索結果を元に回答を生成するモデル (Claude、Nova、Llama 等)
それぞれを自由に組み合わせられるので、ユースケースに合わせた最適な構成が組めます。本記事のサンプルでは 埋め込み = Titan Text Embeddings V2 / ベクトルストア = OpenSearch Serverless / 生成 = Claude (テスト UI で選択) の組み合わせを使います。
サポートされる入力フォーマット
Knowledge Bases は主要なファイル形式を直接読み込めます。
- プレーンテキスト (
.txt) - Markdown (
.md) ← 見出し構造を保持 - HTML (
.html) - PDF (
.pdf) ← スキャン PDF は別途 OCR が必要 - Word (
.doc/.docx) - CSV (
.csv) - Excel (
.xlsx)
前処理でフォーマット変換をする必要が基本的にないため、「とりあえず手元の資料を全部 S3 にアップロードする」という使い方が可能です。
引用元 (Citation) の自動付与
Knowledge Bases の強力な機能が、回答に引用元を自動で付けること。「どの資料のどこから取得したか」というメタデータが回答とともに返ってくるので、根拠を即座に確認できます。
想定するユースケース
今回は「手元に溜まったドキュメントを横断検索して、自然言語で質問できる」というシンプルなシナリオを想定します。
| 項目 | 内容 |
|---|---|
| データ種別 | 議事録、調査メモ、ブログ下書き、訪問ログなど (Markdown / CSV / PDF / Excel) |
| データ量 | 検証用に数ファイル程度 |
| 期待する回答 | 「過去に〇〇について書いたメモあったよね?」「△△ の調査結果まとめて」など、引用元付きで回答 |
検証用ドキュメント (sample-docs/)
今回は以下の架空サンプルを用意しました。
| ファイル | 形式 | 内容 |
|---|---|---|
book-club-meeting-001.md |
Markdown | 読書会ミーティングの議事録 |
survey-coffee-beans.md |
Markdown | コーヒー豆の主要品種に関する調査メモ |
blog-draft-cafe-tour.md |
Markdown | 東京カフェ巡りのブログ下書き |
survey-brewing-methods.pdf |
コーヒーの抽出方法に関する調査メモ | |
cafe-visit-log.csv |
CSV | 訪問カフェの記録 (エリア / 評価 / 価格などの構造化データ) |
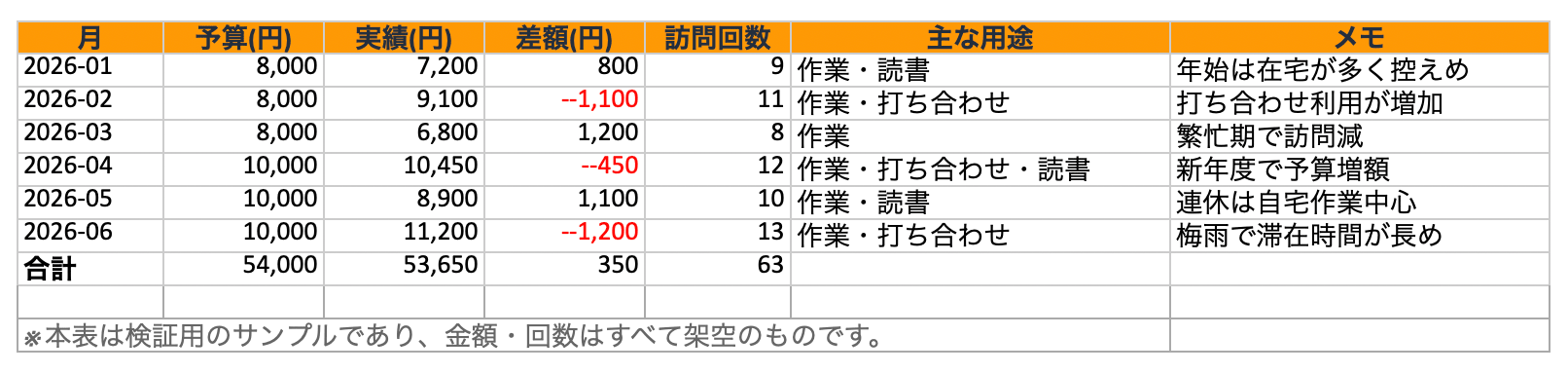
monthly-cafe-budget.xlsx |
Excel | 月別のカフェ支出管理表 (予算 / 実績 / 訪問回数) |
今回 S3 にアップロードした検証用サンプルは以下の 6 ファイルです。Markdown・PDF・CSV・Excel とフォーマットをあえて混在させ、Knowledge Bases がこれらを事前変換なしでそのまま検索できることを確認します。
sample-docs/book-club-meeting-001.md— 読書会の議事録 (Markdown)

sample-docs/survey-coffee-beans.md — コーヒー豆の主要品種に関する調査メモ (Markdown)

sample-docs/blog-draft-cafe-tour.md — 東京カフェ巡りのブログ下書き (Markdown)

sample-docs/survey-brewing-methods.pdf — コーヒーの抽出方法に関する調査メモ (PDF)

sample-docs/cafe-visit-log.csv — 訪問カフェの記録。エリア・評価・価格などの構造化データ (CSV)
sample-docs/monthly-cafe-budget.xlsx — 月別のカフェ支出管理表。予算・実績・訪問回数 (Excel)
アーキテクチャ
今回構築するアーキテクチャは以下のとおりです。
ポイントは「Quick create a new vector store」を選ぶことで、本来は構築が大変な OpenSearch Serverless のベクトル検索コレクションが自動でプロビジョニングされる点です。
やってみた
マネジメントコンソールで RAG 環境を構築していきます。
1: Amazon S3 にデータソース用バケットを作成
まずはデータソースとなる S3 バケットを作成し、sample-docs/ のサンプルドキュメントをアップロードします。
S3 コンソールから バケットを作成 を選び、リージョン (ap-northeast-1)、一意なバケット名を指定して作成します。作成できたら、アップロード画面にサンプルドキュメントをドラッグ&ドロップします。
CLI で済ませたい場合は以下でも OK です。
aws s3 mb s3://kb-docs-handson --region ap-northeast-1
aws s3 cp ./sample-docs/ s3://kb-docs-handson/ --recursive
2: Bedrock Knowledge Bases の作成
Amazon Bedrock コンソールの左メニューから Knowledge Bases を開き、Create Managed KB ボタン右の ▼ から Self-managed KB > Unstructured Vector Store KB を選択します。
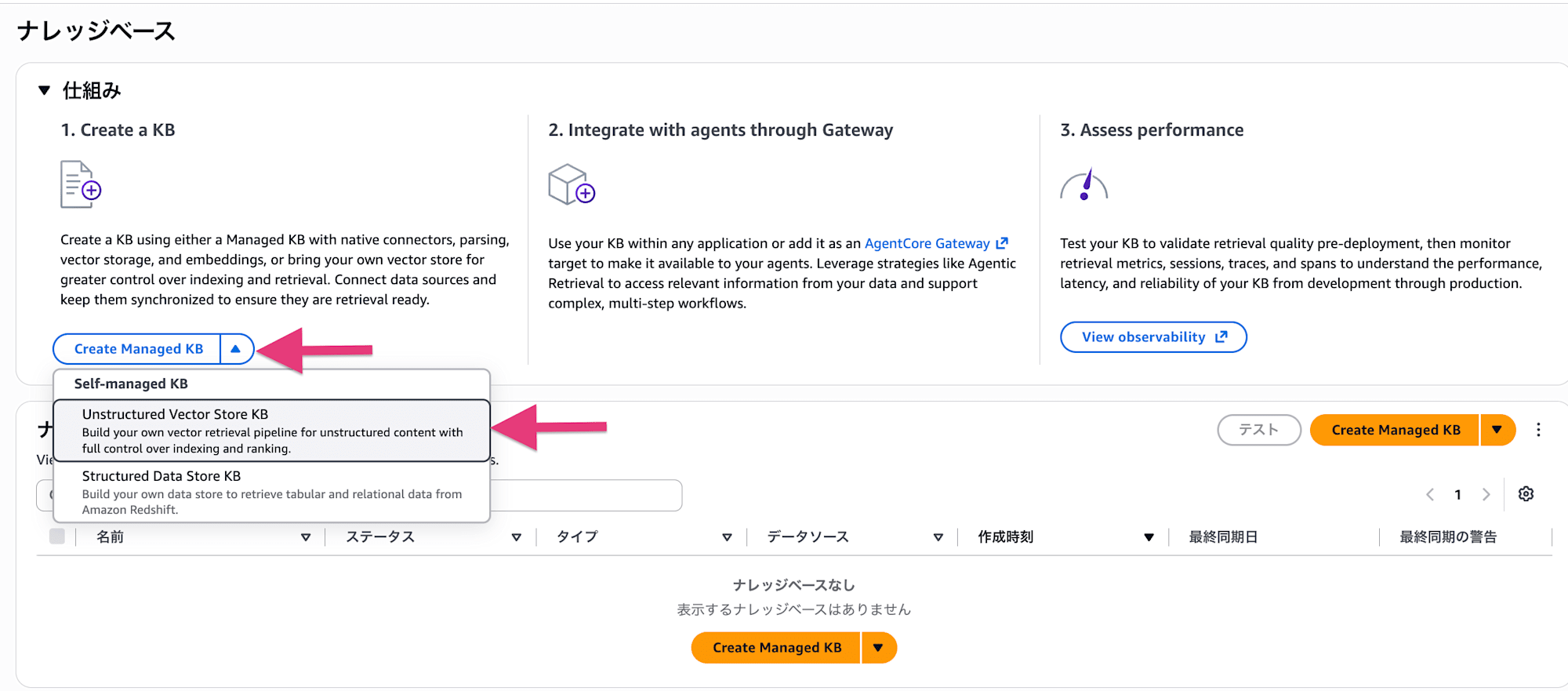
オレンジの Create Managed KB をそのまま押すと Managed KB の作成画面に進んでしまうので注意。今回は Self-managed 構成なので、ドロップダウンから Unstructured Vector Store KB を選びます。
設定する主な項目は以下のとおり。
| 項目 | 設定値 |
|---|---|
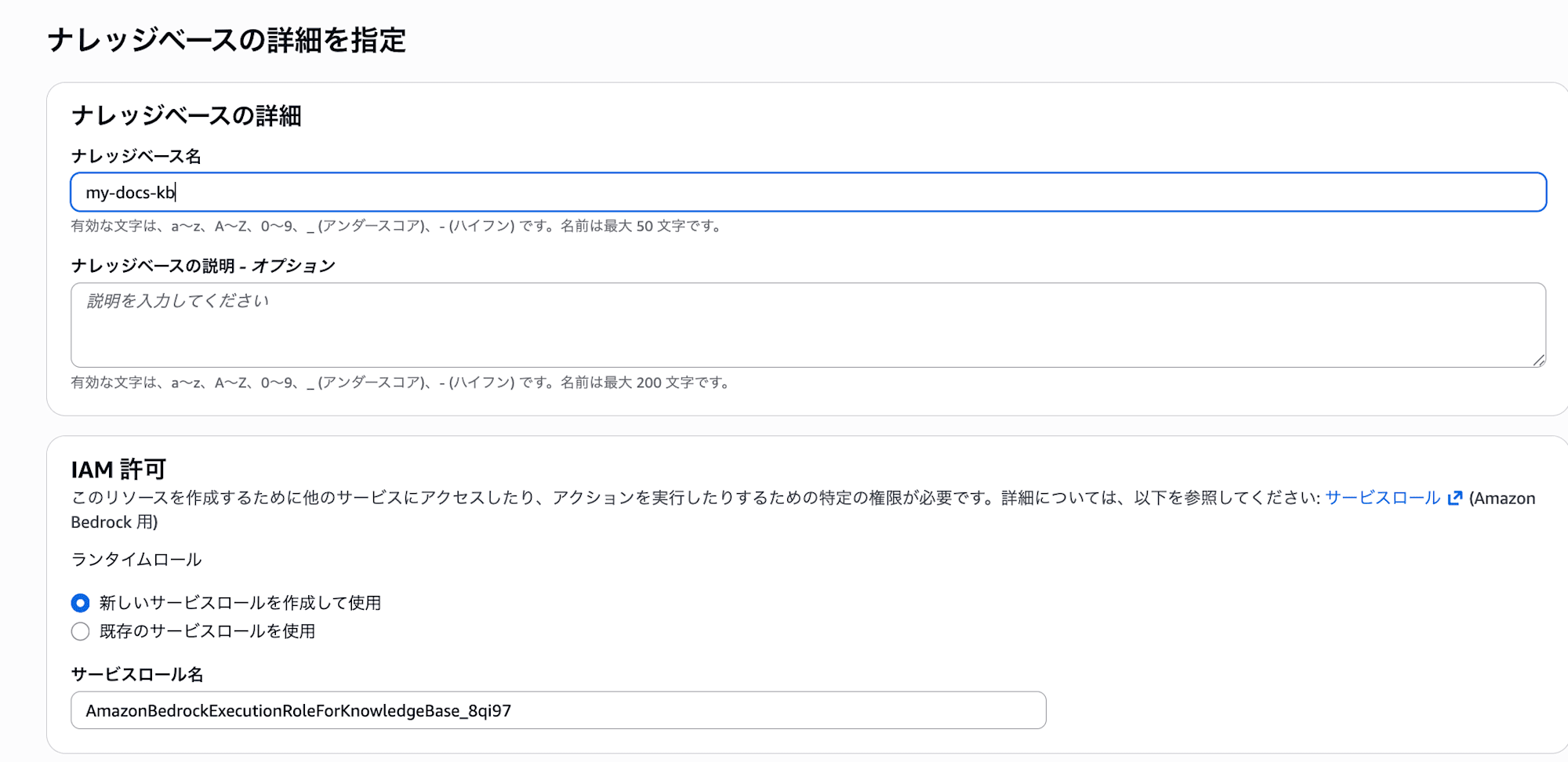
| Knowledge base name | my-docs-kb |
| IAM permissions | 新規作成 |
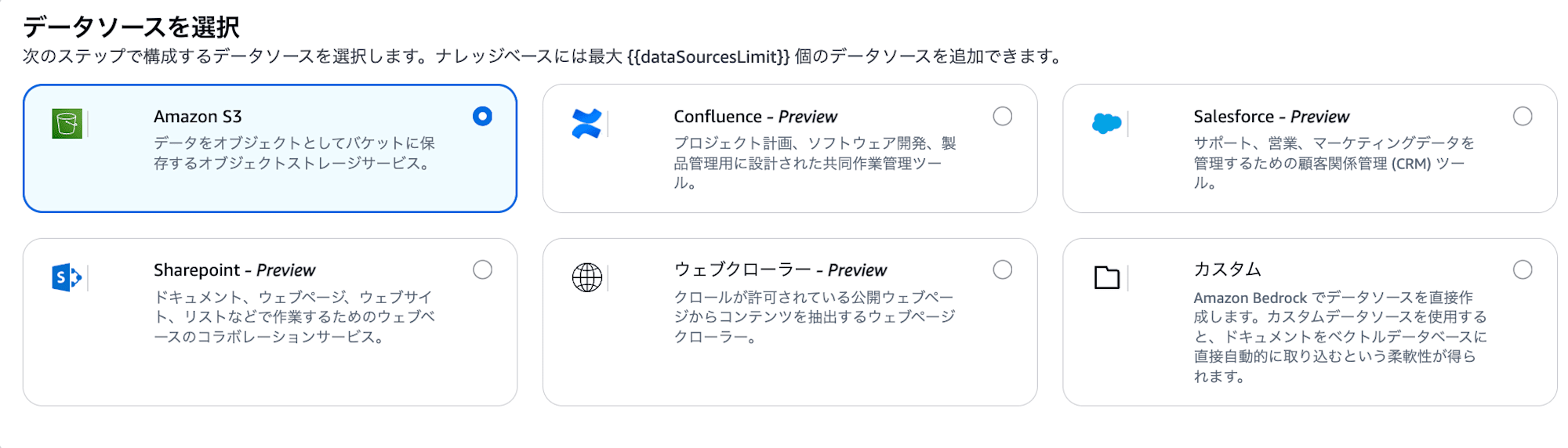
| Data source | Amazon S3 |
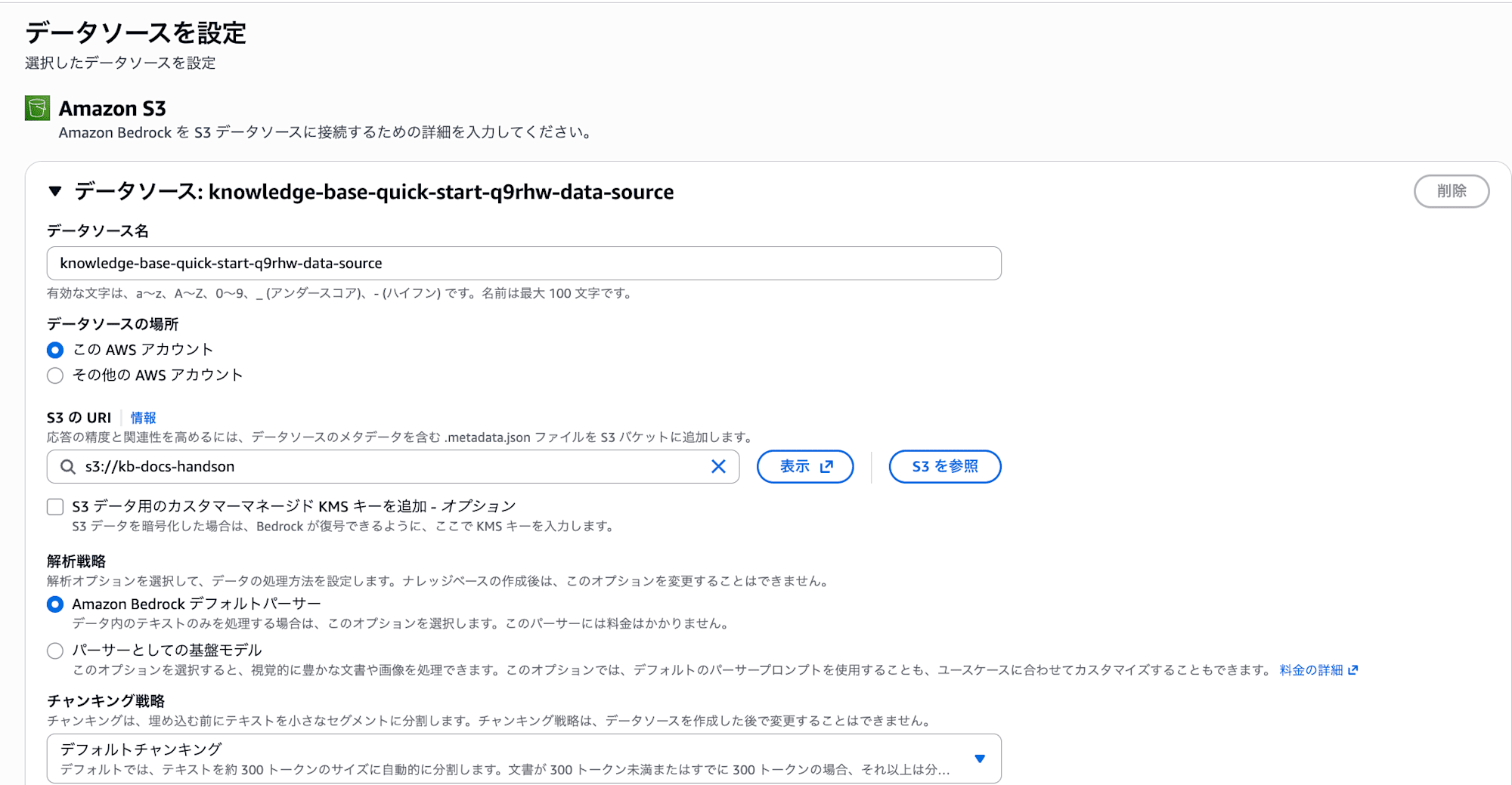
| S3 URI | Step 1 で作ったバケット |
| Embeddings model | Titan Text Embeddings V2 |
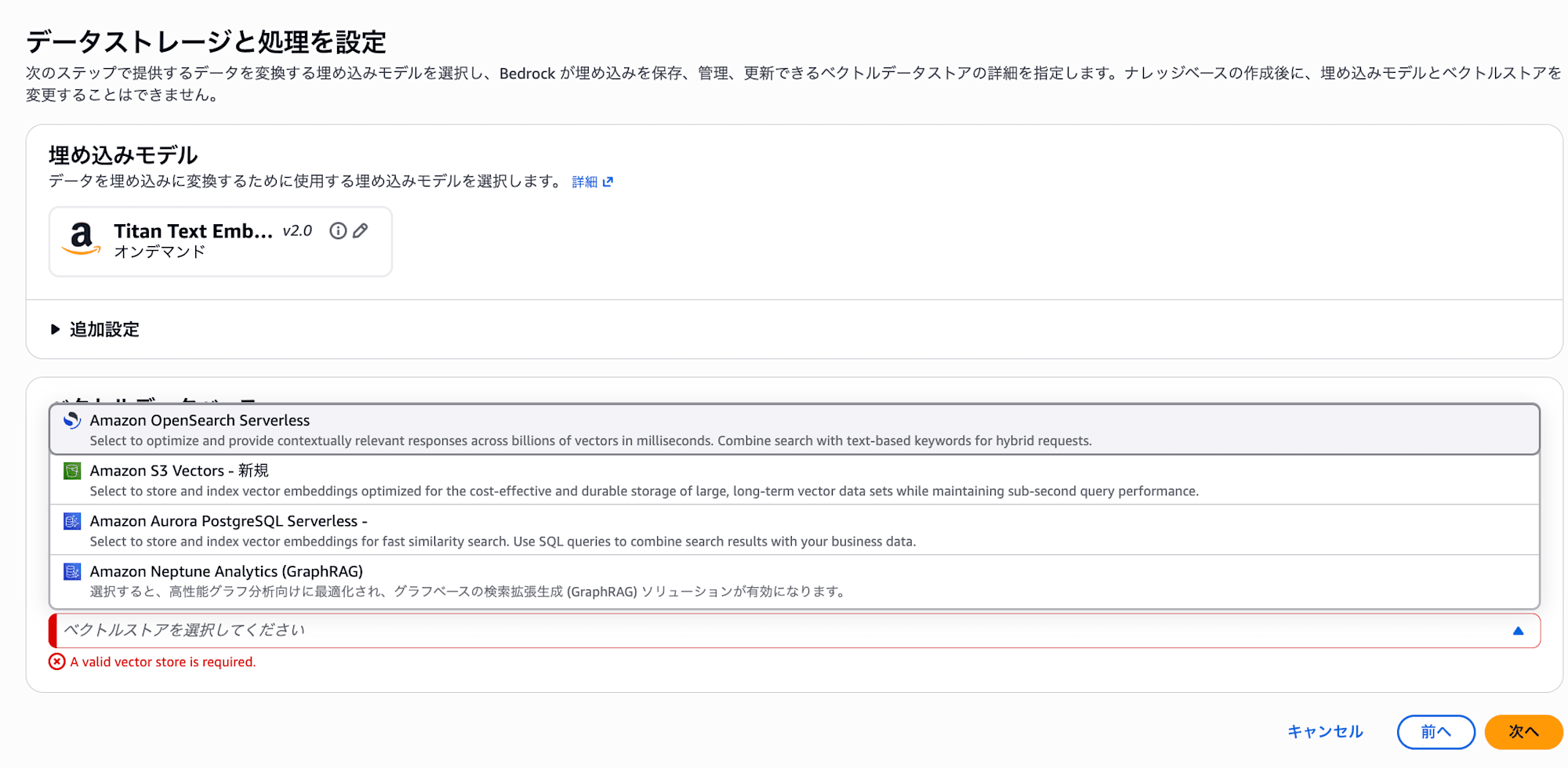
| Vector database | Quick create a new vector store - Amazon OpenSearch Serverless |
各設定値の解説
- Knowledge base name : Knowledge Bases の識別名。
- IAM permissions : Knowledge Base が S3 (データ読み込み)・埋め込みモデル・OpenSearch Serverless にアクセスするための実行ロールです。
- Data source : ドキュメントの保管場所。今回は Amazon S3 を選択します (SharePoint、Confluence なども選べます)。
- S3 URI : Step 1 で作ったバケット (例: s3://kb-docs-handson/) を指定します。バケット直下ではなく特定のプレフィックス配下だけを対象にしたい場合は、s3://バケット名/フォルダ/ のように絞り込めます。
- Embeddings model : テキストをベクトル (数値の並び) に変換するモデルです。Titan Text Embeddings V2 は Amazon 製で日本語を含む多言語に対応し、次元数やコストのバランスが良いため、RAG での利用例が多くあります。
- Vector database : ベクトル化した情報を格納・検索する DB です。Quick create a new vector store - Amazon OpenSearch Serverless を選ぶと、必要なリソース一式を Bedrock が自動でプロビジョニングしてくれます。
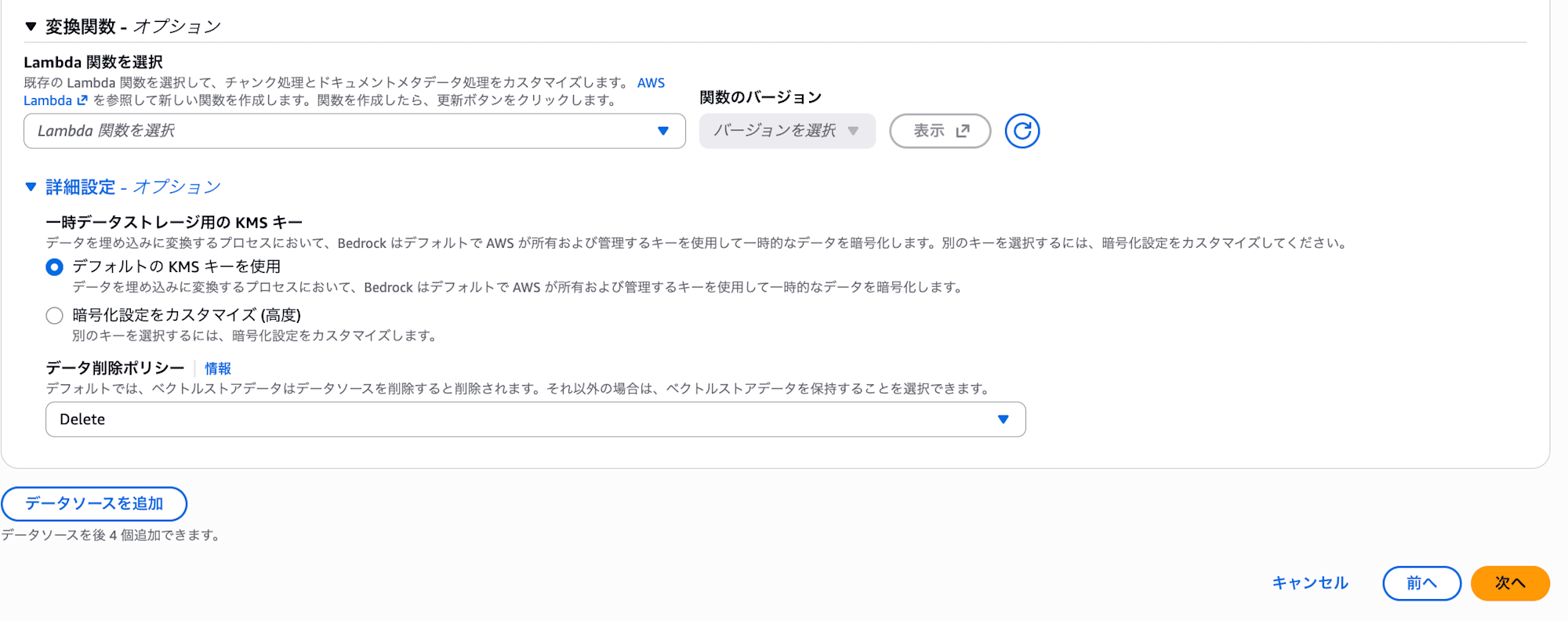
オプション設定
ベクトルストアのクイック作成では、追加設定として以下を選べます。いずれも今回の検証ではデフォルトのまま (オフ) で OK です。
- 冗長を有効にする (アクティブレプリカ) : デフォルトは無効で、これは開発・検証ワークロードに最適な設定です。有効にするとアクティブなレプリカが立ち上がって可用性が上がりますが、その分ストレージ (OCU) コストが増えます。今回は検証用途なのでオフのままで OK です。
- カスタマーマネージド KMS キーを追加 : ベクトルストアはデフォルトで AWS 管理のキーによって暗号化されます。キーの管理・ローテーションを自分でコントロールしたい (組織のコンプライアンス要件があるなど) 場合のみ、ここで自前の KMS キーを指定します。
Knowledge Bases が作成できました。

3: データソースの 同期
Knowledge Base が作成できたら、データソースを選択して 同期 ボタンを押下します。

同期が始まりました。
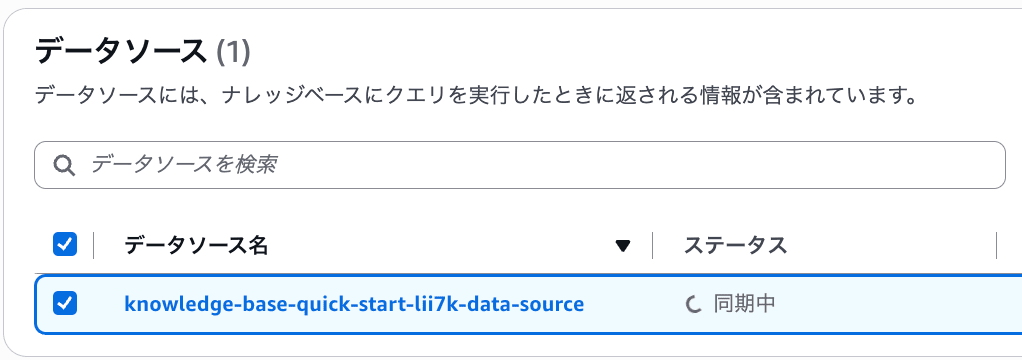
同期の中で行われる処理は以下のとおりです。
- S3 のオブジェクトを読み込み
- テキスト抽出
- チャンク分割 (デフォルトでは Default chunking 戦略)
- Titan Text Embeddings V2 でベクトル化
- OpenSearch Serverless に格納
検証用の数ファイル程度であれば数分で完了します。

4: コンソール上でのテスト
同期が完了したら、いよいよ実際に質問を投げてみます。Knowledge Base の詳細画面から「テスト」を開くと、左側が設定、右側が プレビューの 2 画面構成になっています。
まず左側の 「取得と応答生成」 で動作モードを選びます。
| モード | 内容 |
|---|---|
| Agentic retrieval with answer generation / Agentic retrieval only | 高度な取得モード。Managed Knowledge Bases 専用のため、今回の Self-managed KB ではグレーアウトして選べません |
| 取得のみ: データソース | 生成 AI を通さず、ベクトル検索でヒットしたチャンクだけを返す (検索精度のチューニング時に便利) |
| 取得と応答生成: データソースとモデル | ヒットした検索結果を生成モデルに渡し、回答文まで生成する。通常の RAG 体験はこれ |
今回は 「取得と応答生成: データソースとモデル」 を選択します。
次に 「モデルを選択」 ボタンから、回答を生成するモデルを指定します
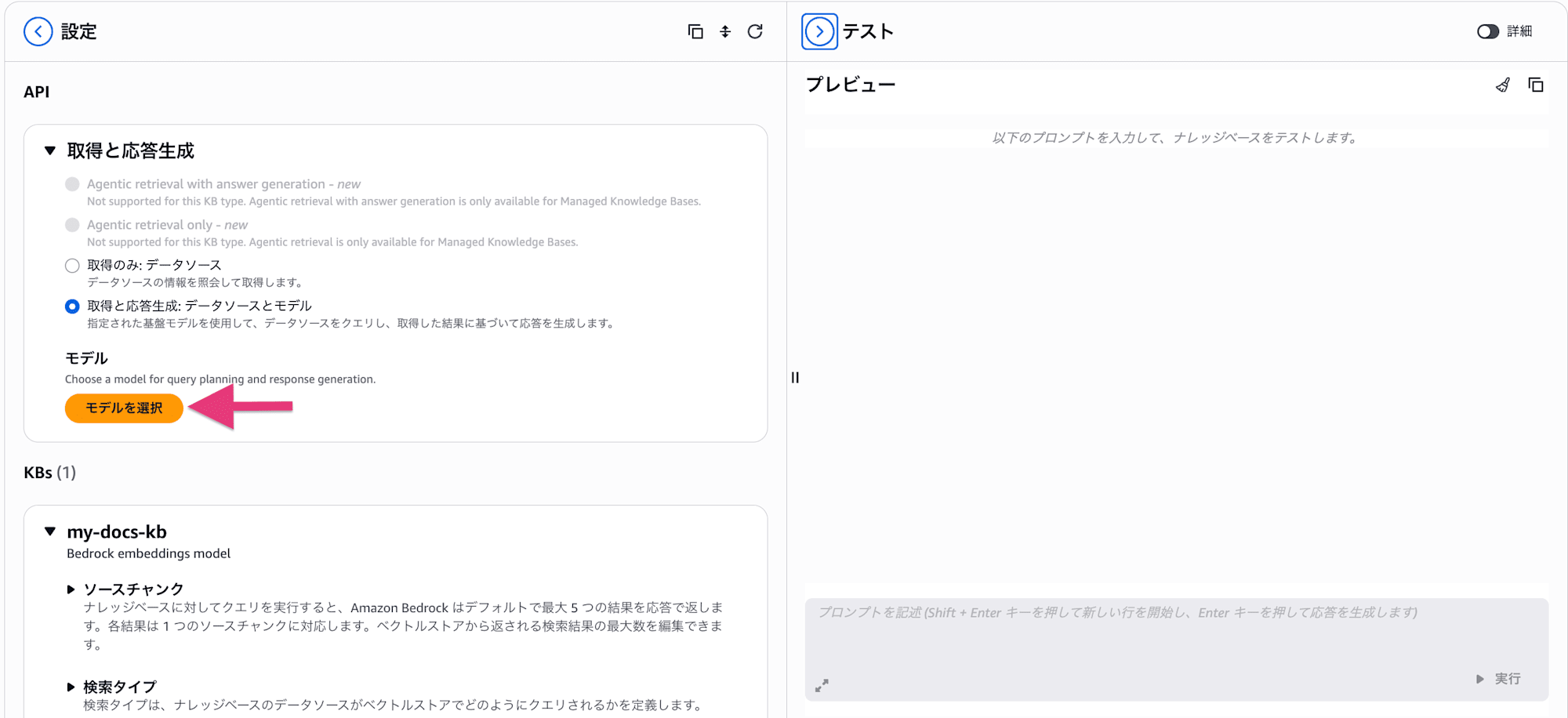
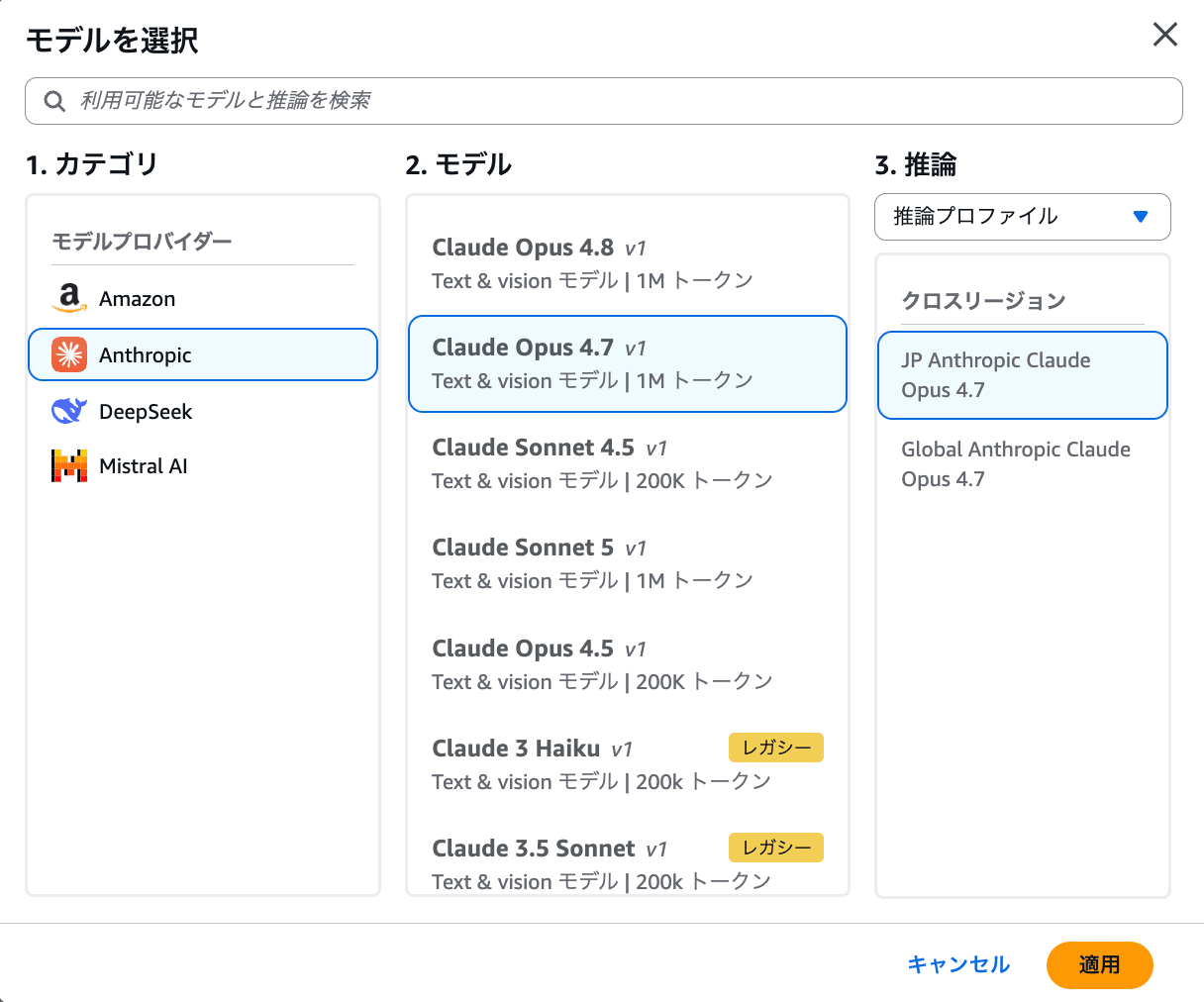
- カテゴリ : モデルプロバイダーを選ぶ (Amazon / Anthropic / DeepSeek / Mistral AI など)。今回は Anthropic を選択。
- モデル : Claude Sonnet / Opus といった具体的なモデルを選ぶ。コンテキスト長 (トークン数) も併記されています。用途に応じて、賢さ重視なら Opus、速度・コスト重視なら Sonnet / Haiku 系、といった選び分けができます。
- 推論 : 推論プロファイルを選ぶ。クロスリージョン推論のプロファイル (例: JP Anthropic Claude ...) を選ぶと、複数リージョンにまたがって推論リクエストが処理され、スループットや可用性が上がります。
選んだら 「適用」 で確定します。
質問してみる
準備ができたら、右側の入力欄に自然言語で質問を入力して送信します。裏側では「質問のベクトル化 → OpenSearch Serverless で類似検索 → ヒットしたチャンクを生成モデルに渡して回答」という RAG の流れが自動で走り、引用元付きで回答が返ってきます。
まずは Markdown の調査メモに書いた内容を聞いてみます。
Q: コーヒー豆の主要品種にはどんなものがある?
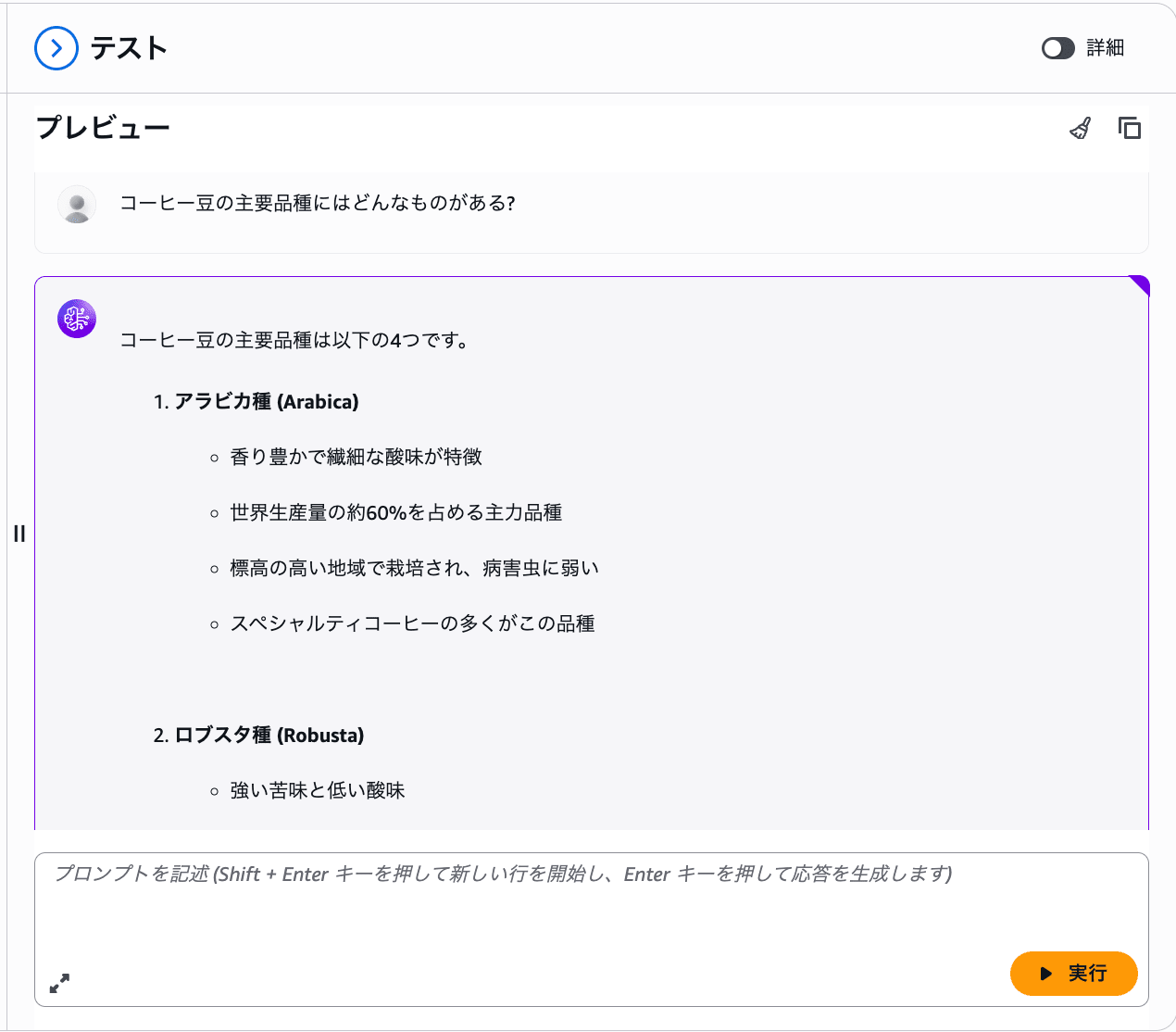

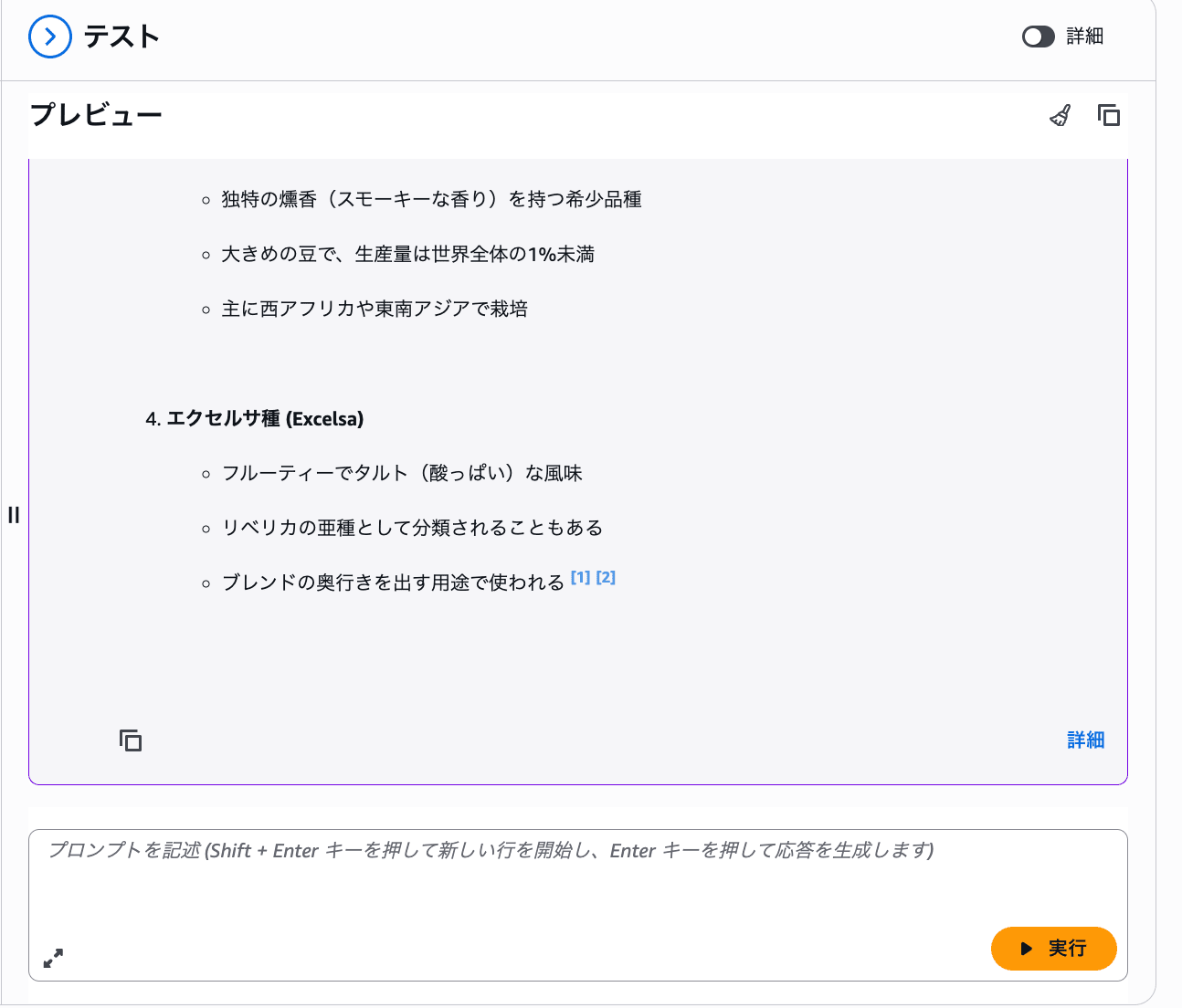
しっかりコーヒー豆の品種が返ってきました!注目したいのは、回答に引用元がひも付いていること。どの資料のどこを根拠にしたのかをその場でたどれるので、「AI が勝手に言っているだけでは?」という不安をすぐに解消できます。根拠の文書を必ず示してくれる。ここが RAG の強みかと思います。
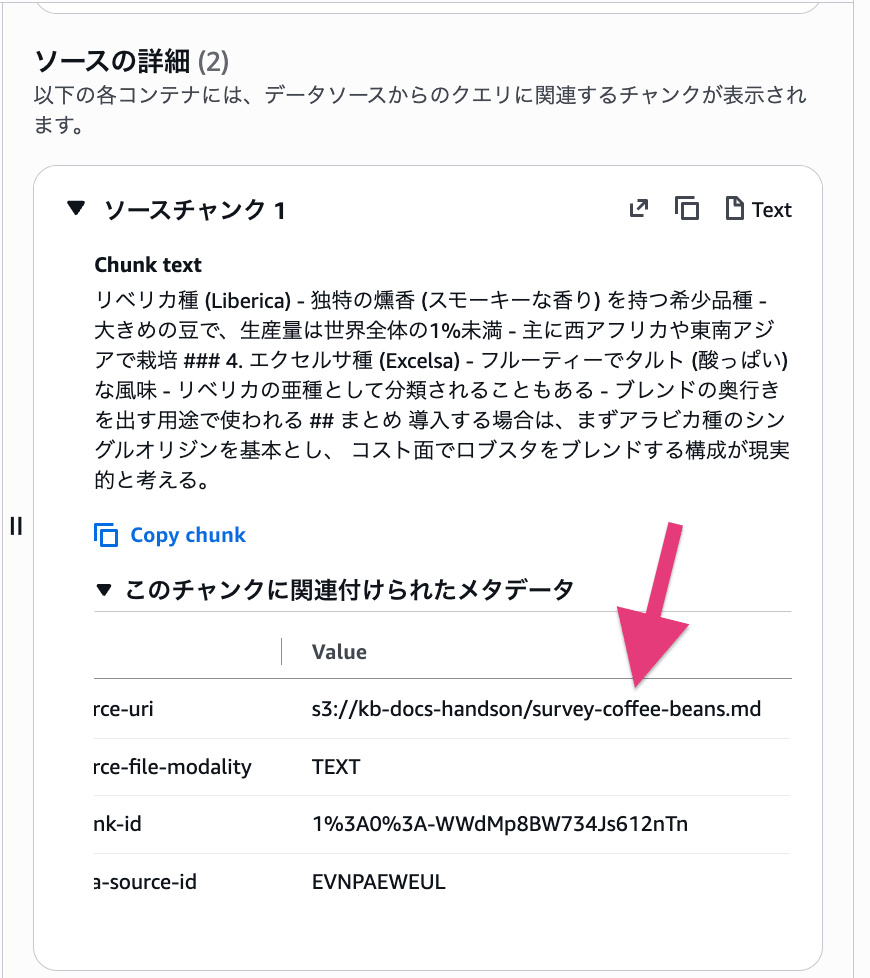
サンプルは Markdown・PDF・CSV・Excel が混在しています。以下のように、どの形式のファイルが根拠でも同じ感覚で質問できます。
Q: 清澄白河エリアで作業しやすいカフェは? # Markdown / CSV から
Q: 読書会で決まった次回の課題図書は? # Markdown から
Q: 水出しコーヒーの特徴を教えて # PDF から
Q: カフェ代の支出が一番多かった月は? # Excel から
なかでも「ちゃんと読めているか」が気になる Excel を試してみます。
Q: カフェ代の支出が一番多かった月は?
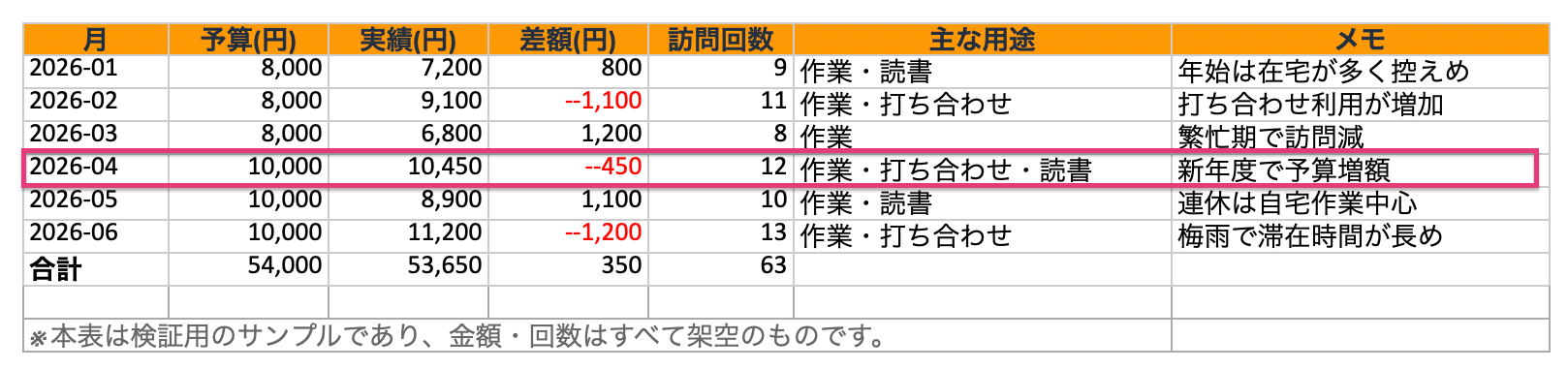
回答は「2026 年 4 月が最も支出が多かった」というもの。表形式のデータもきちんと読み取って答えてくれました。
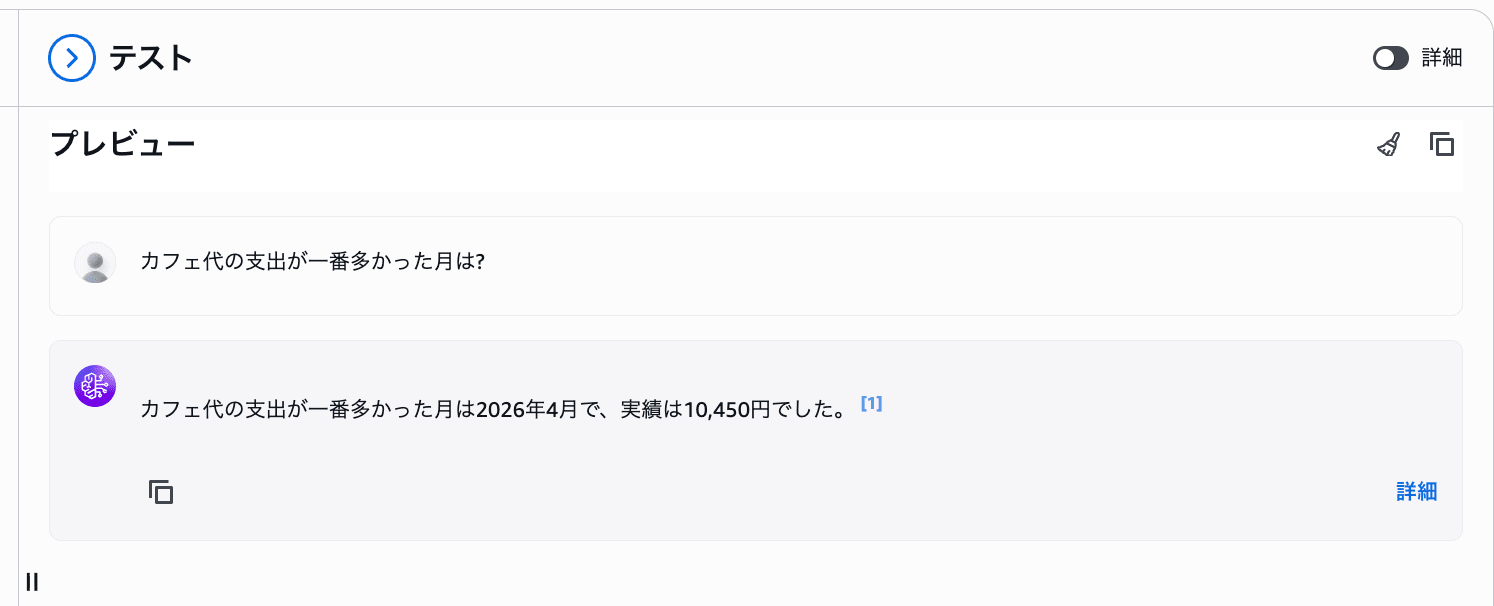
念のため元の Excel ファイルを確認すると、たしかに 2026 年 4 月の支出が最大。回答が正しいことを裏取りできました。
Tips
リソースの削除
検証を終えてリソースを片付けるとき、Knowledge Base を消しても OpenSearch Serverless のコレクションは自動削除されません。費用が掛かるので、明示的に削除しましょう。
aws opensearchserverless list-collections --region ap-northeast-1
aws opensearchserverless delete-collection --id <COLLECTION_ID>
モデル選びの注意
テスト UI でリリース直後の最新モデルを選ぶと、Custom prompt templates must be provided... や temperature is deprecated といったエラーが出ることがあります。これは最新世代モデルが従来のデフォルトプロンプトや推論パラメータと非互換なため。まずは Claude 4.6 Sonnet などの安定版モデルを選ぶと、デフォルト設定のままスムーズに動きます。


料金感
検証レベルであれば気になる金額ではないですが、継続的に使うなら以下を把握しておきましょう。
- Titan Text Embeddings V2: 入力トークンあたりの従量
- OpenSearch Serverless: OCU 時間課金 (最低 2 OCU)
- Claude (Sonnet / Haiku): 入出力トークンあたりの従量
特に OpenSearch Serverless は「使ってなくても OCU が立ち上がっていれば課金される」ため、検証が長期化する場合は要注意です。
まとめ
今回は Amazon Bedrock Knowledge Bases でシンプルな RAG を構築してみました。
やったことは「S3 に置く → 同期 → 質問する」の 3 ステップだけです。ベクトル DB の構築やチャンク分割といった面倒な部分を全部マネージドに任せられるので、コンソールから数クリックで RAG が立ち上がってしまう手軽さには驚きました。
また、事前のフォーマット変換なしで、Markdown も Excel もそのままきちんと読み取ってくれるのはとても嬉しいですね!
RAG を利用した Chatbot も簡単に作れそうです。
この記事がどなたかのお役に立てば幸いです。
参考リンク










