
k6 で複数シナリオを同時実行し、Grafana OSS でダッシュボードを分けて可視化してみた
製造ビジネステクノロジー部の小林です。
前回の記事では、EC2 上で k6 を実行し、InfluxDB + Grafana OSS でリアルタイムに可視化する環境を構築しました。
実際の負荷テストでは、複数のシナリオを同時に実施したいケースもあります。そこで今回は、2 つのシナリオを並列実行し、それぞれのメトリクスを Grafana の異なるダッシュボードで個別に可視化する方法をご紹介します。
前提条件
- k6 実行環境: Graviton EC2
- OS: Amazon Linux 2023(ARM)
- Grafana OSS が EC2 上で起動済み
- InfluxDB が EC2 上で起動済み
- Grafana への接続: VSCode ターミナルから SSM ポートフォワーディング経由でアクセス(ポート 3000)
Grafana へのアクセスは以下のコマンドでポートフォワーディングを開始します。
aws ssm start-session \
--target <EC2 インスタンス ID> \
--document-name AWS-StartPortForwardingSession \
--parameters "portNumber=3000,localPortNumber=3000"
実行結果
Starting session with SessionId: XXXXXXXXX-XXXXXXXXnj7vivo2eak2j6u
Port 3000 opened for sessionId XXXXXXXXX-XXXXXXXX26bnj7vivo2eak2j6u.
Waiting for connections...
この状態で、ブラウザから http://localhost:3000 にアクセスすると Grafana の画面が表示されます。
複数シナリオを同時に走らせたい
負荷テストの実施時に、以下のような要件が生じることがあります。
- 通常処理とコールバック処理など、複数の API に同時に負荷をかけたい
- それぞれの結果を混ぜずに、個別のダッシュボードで確認したい
- テストは EC2 上でバックグラウンド実行して、SSH を切断しても継続させたい
k6 のデフォルト設定では、複数プロセスが同じデータベースに書き込むため、メトリクスが混在し、シナリオの区別が困難になります。
InfluxDB の データベースをシナリオごとに分ける
k6 実行時のコマンドに、--out influxdb=http://localhost:8086/<データベース名> の データベース名を変えるだけで、データを完全に分離できます。あとは Grafana のデータソースとダッシュボードをそれぞれ作成するだけです。
やってみた
nohup でバックグラウンド並列実行
InfluxDB では、書き込み時にデータベースが存在しない場合は自動的に作成されます。そのため、事前に CREATE DATABASE を実行する必要はありません。
また、通常、k6 run はフォアグラウンドで実行されるため、SSH 接続が切断されるとテストも終了してしまいます。nohup を使用することで、SSH 接続を切断した後もテストを継続して実行できます。
# 通常 API のランピングテスト
nohup k6 run --out influxdb=http://localhost:8086/k6_ramping_api dist/api-ramping.js > k6-logs_ramping_api_$(date +%Y%m%d-%H%M%S).log 2>&1 &
# コールバック処理 API のランピングテスト
nohup k6 run --out influxdb=http://localhost:8086/k6_ramping_api_callback dist/api-callback-ramping.js > k6-logs_ramping_api_callback_$(date +%Y%m%d-%H%M%S).log 2>&1 &
コマンドの各オプション解説
| コマンド/オプション | 説明 |
|---|---|
| nohup | SSH 切断後もプロセスを継続 |
| --out influxdb=http://localhost:8086/k6_ramping_api | 出力先の InfluxDB とデータベース名を指定。ここを変えるだけでデータが分離される |
| > k6-logs_...$(date +%Y%m%d-%H%M%S).log | 標準出力をタイムスタンプ付きのログファイルへ保存 |
| 2>&1 | 標準エラーも同じログファイルへ |
| & | バックグラウンド実行 |
確認
ps aux | grep k6
2 プロセスが起動していれば OK です。

Grafana にデータソースを 2 つ追加
前回の記事では k6 という データベース名でデータソースを 1 つ作成しました。今回はデータベースごとにデータソースを追加します。
左メニューから Connections → Data Sources → Add new data source で InfluxDB を選択し、それぞれ以下の設定で保存します。
通常 API 用
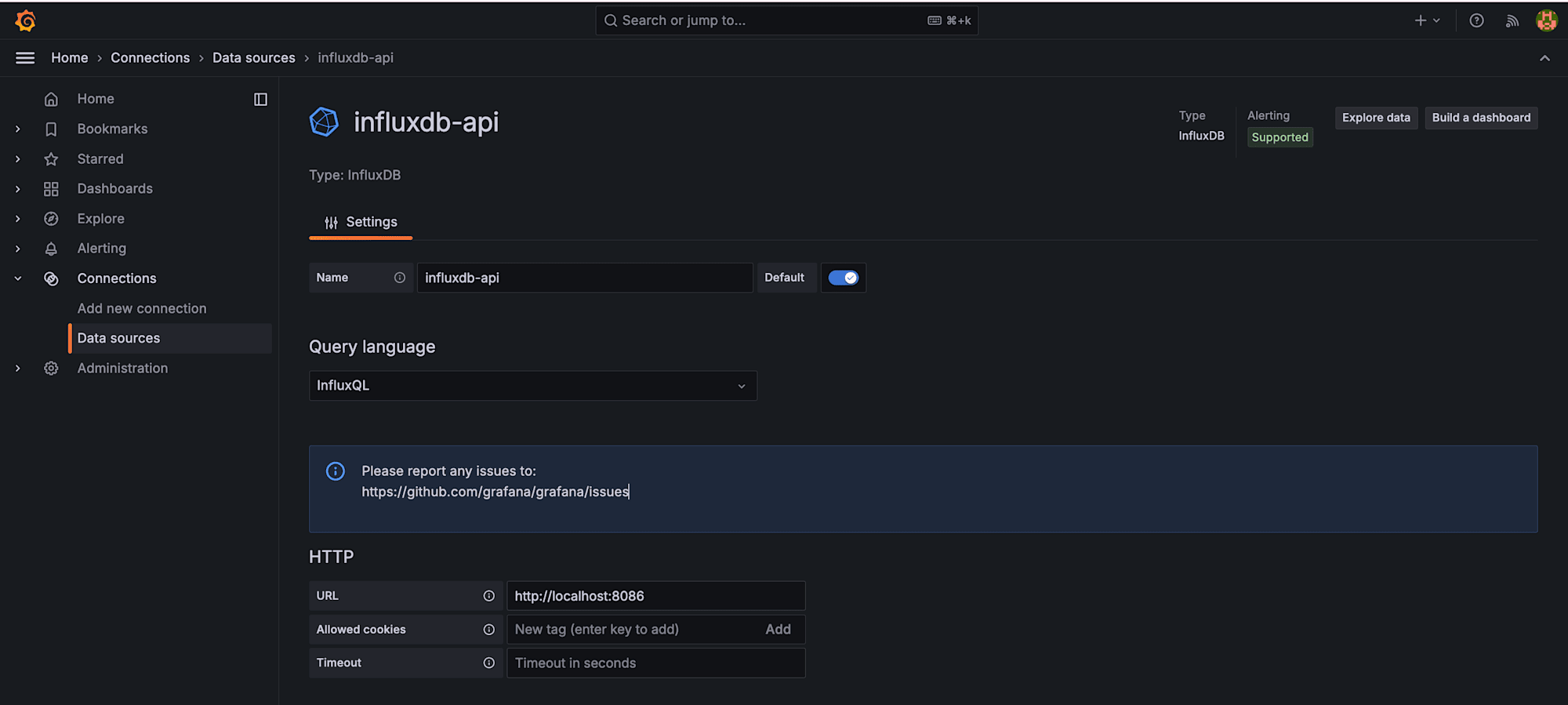
- Name: influxdb-api
- URL: http://localhost:8086
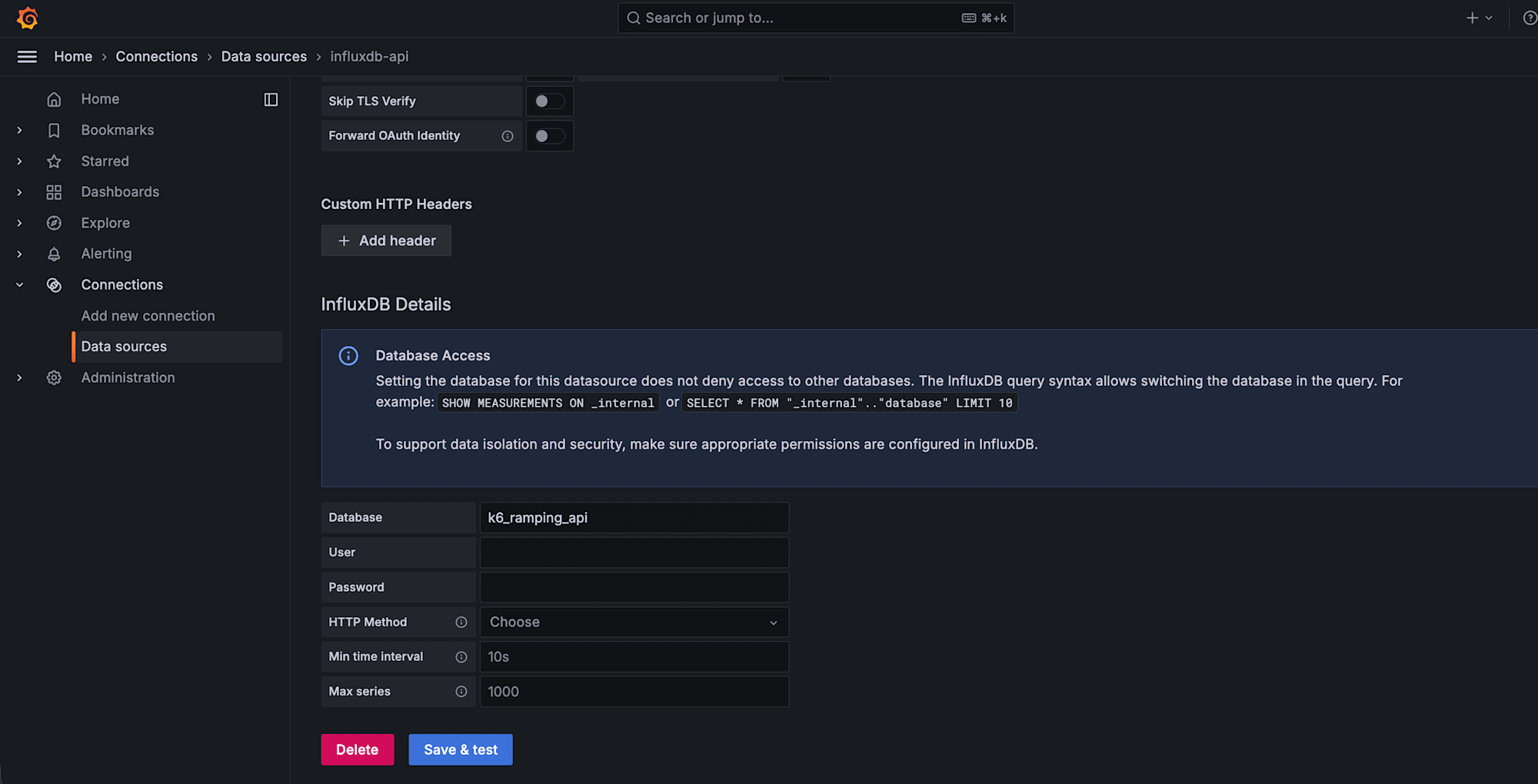
- Database: k6_ramping_api
コールバック処理用
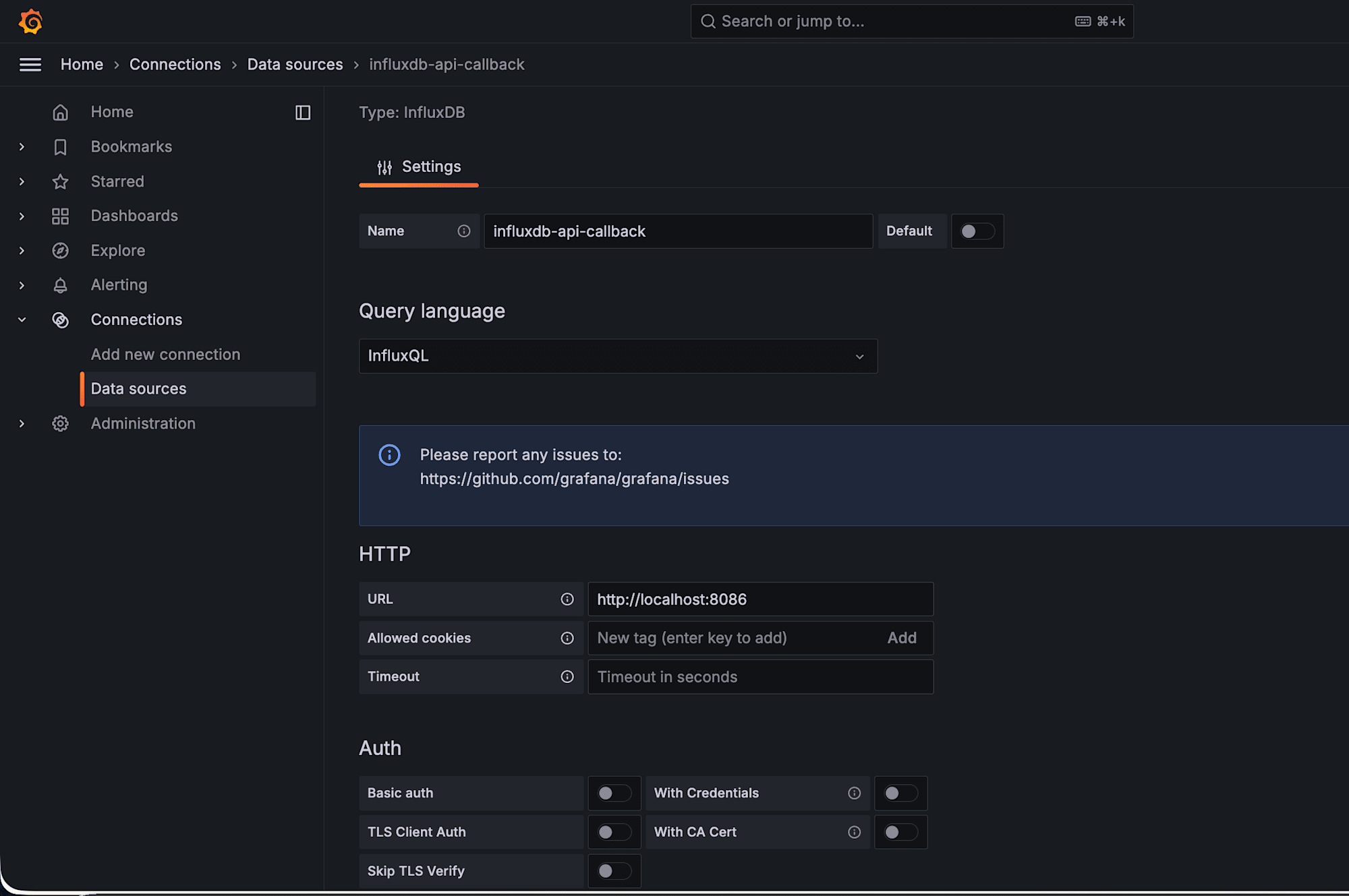
- Name: influxdb-api-callback
- URL: http://localhost:8086
- Database: k6_ramping_api_callback
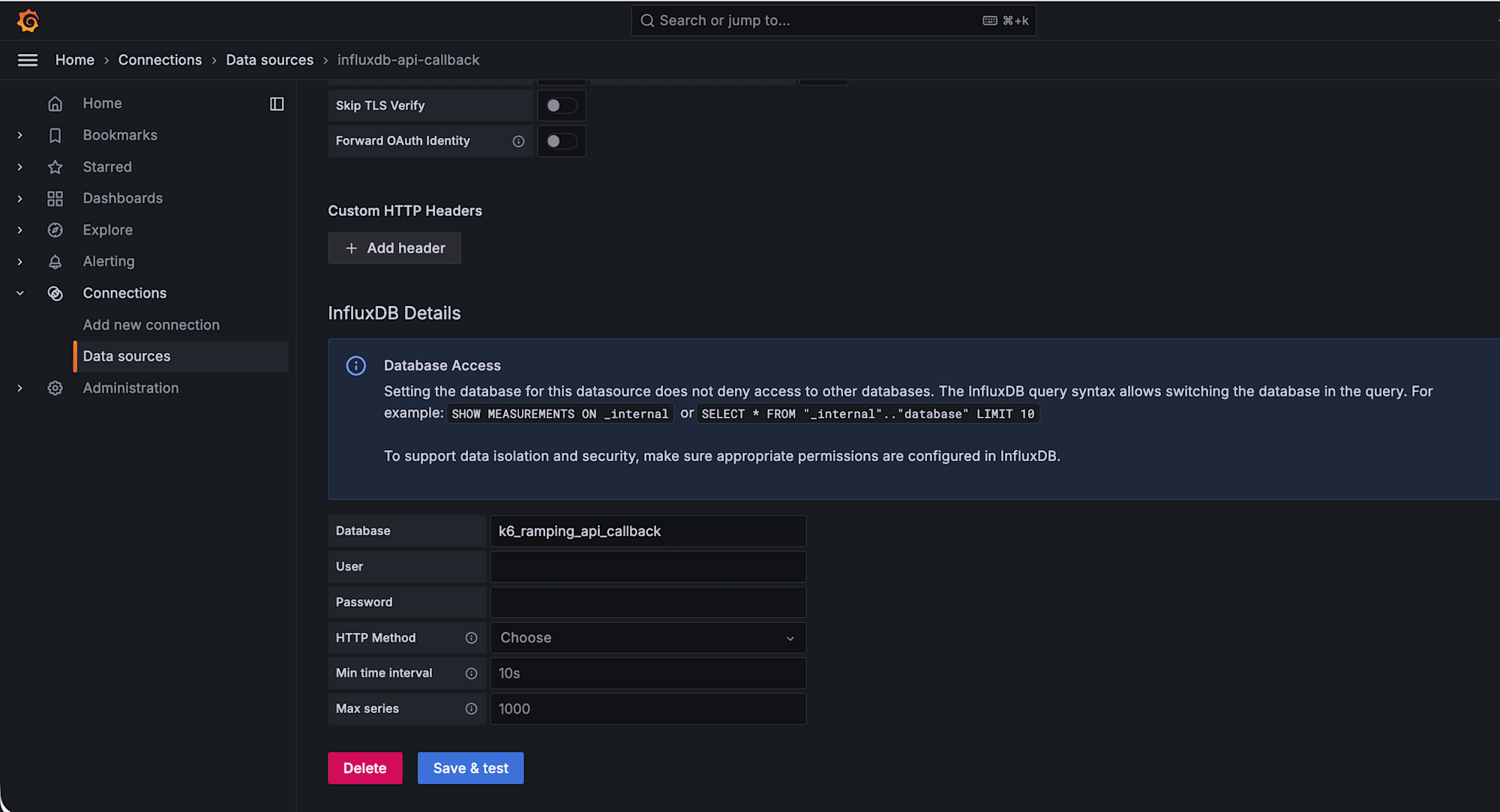
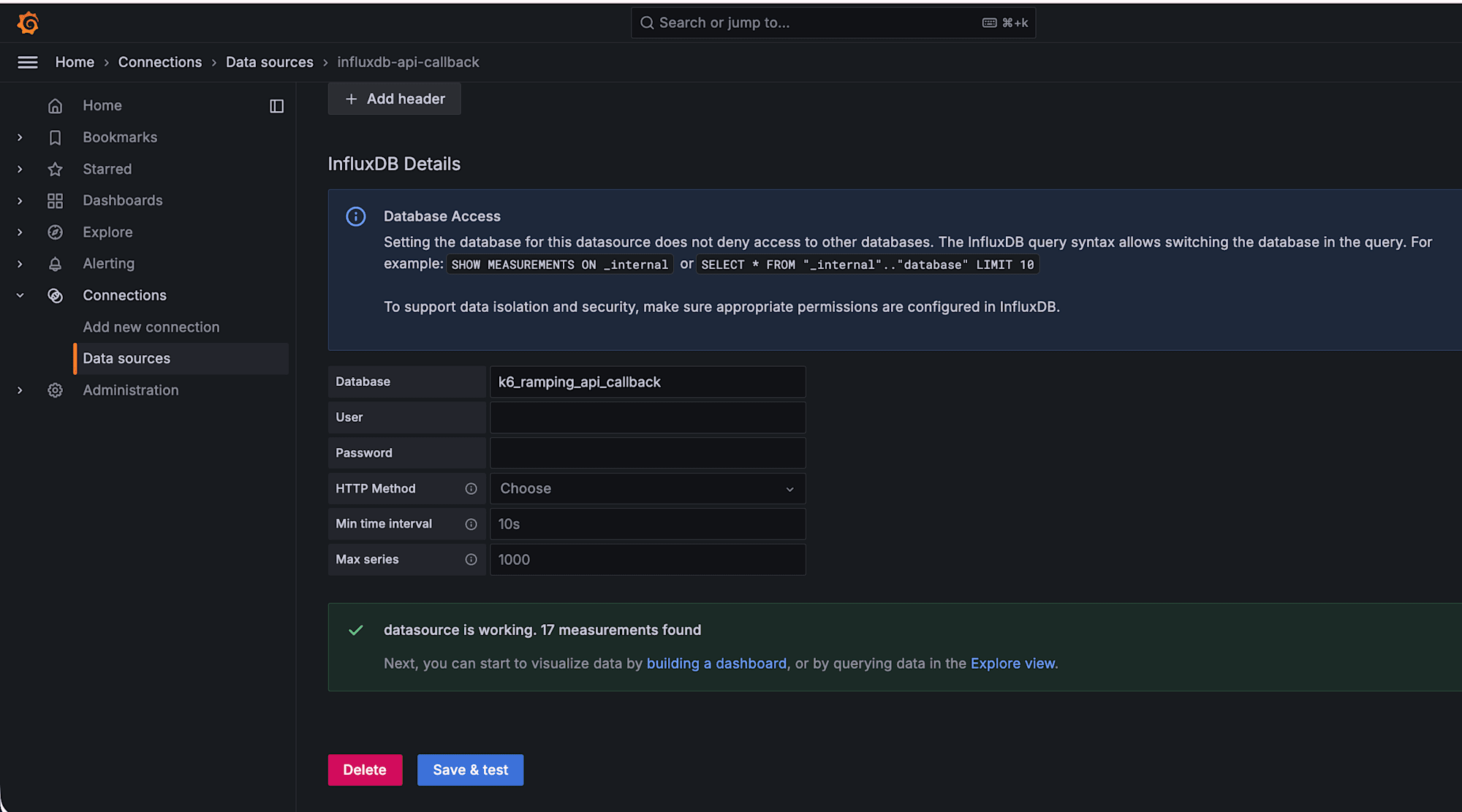
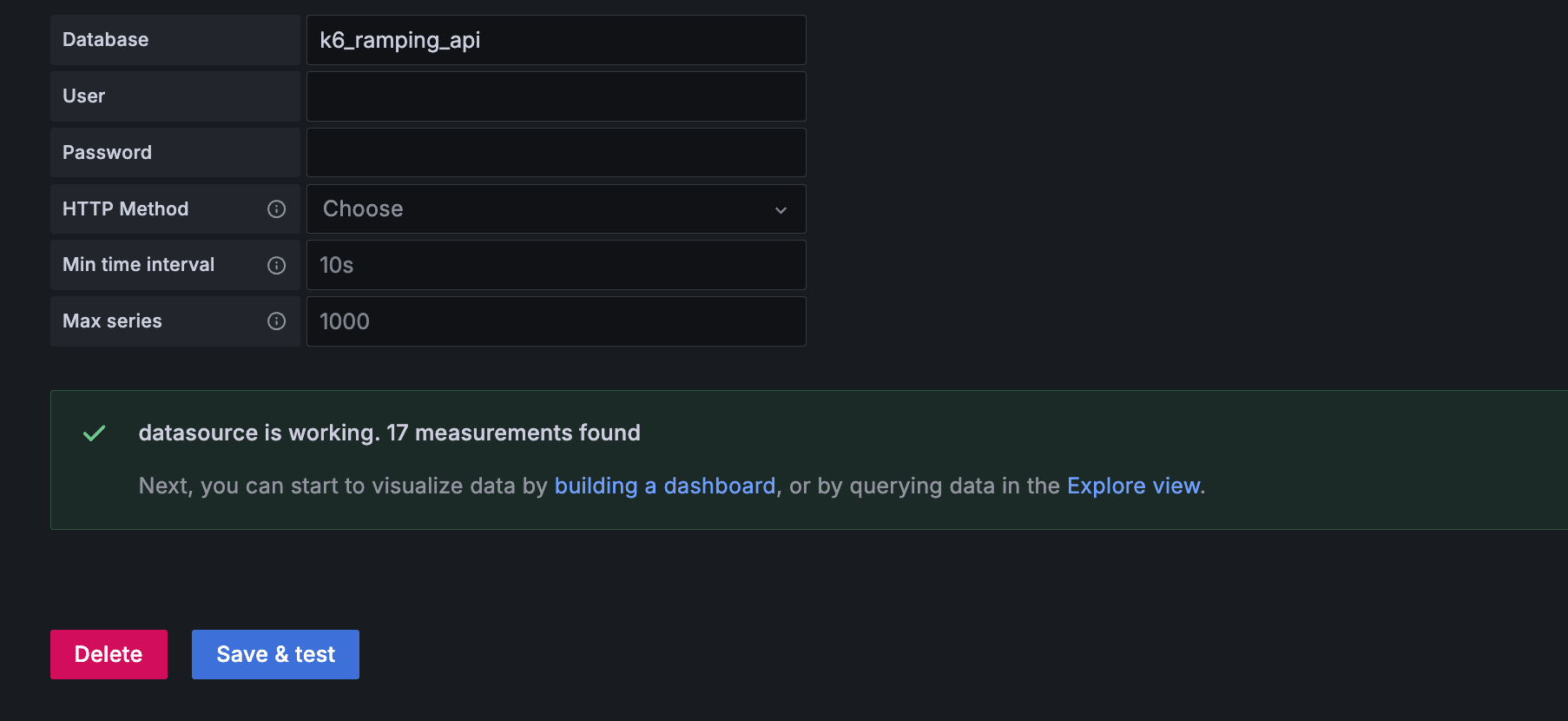
それぞれ Save & Test で Data source is working と表示されれば OK です。
ダッシュボードをシナリオごとにインポート
公式ダッシュボード(ID: 2587)を 2 回インポートします。インポート時のデータソース選択をそれぞれ変えるだけです。
1 回目: データソース =k6_ramping_api、ダッシュボード名 = influxdb-api
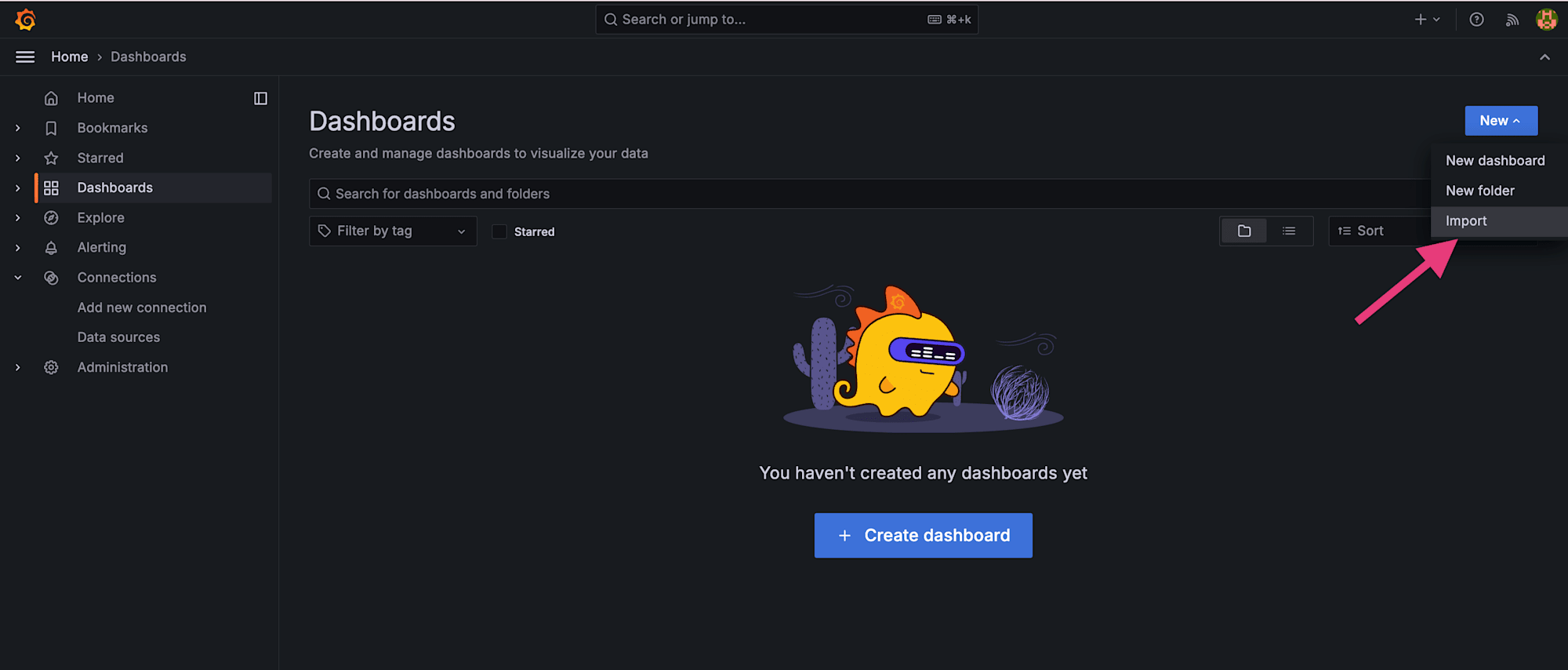
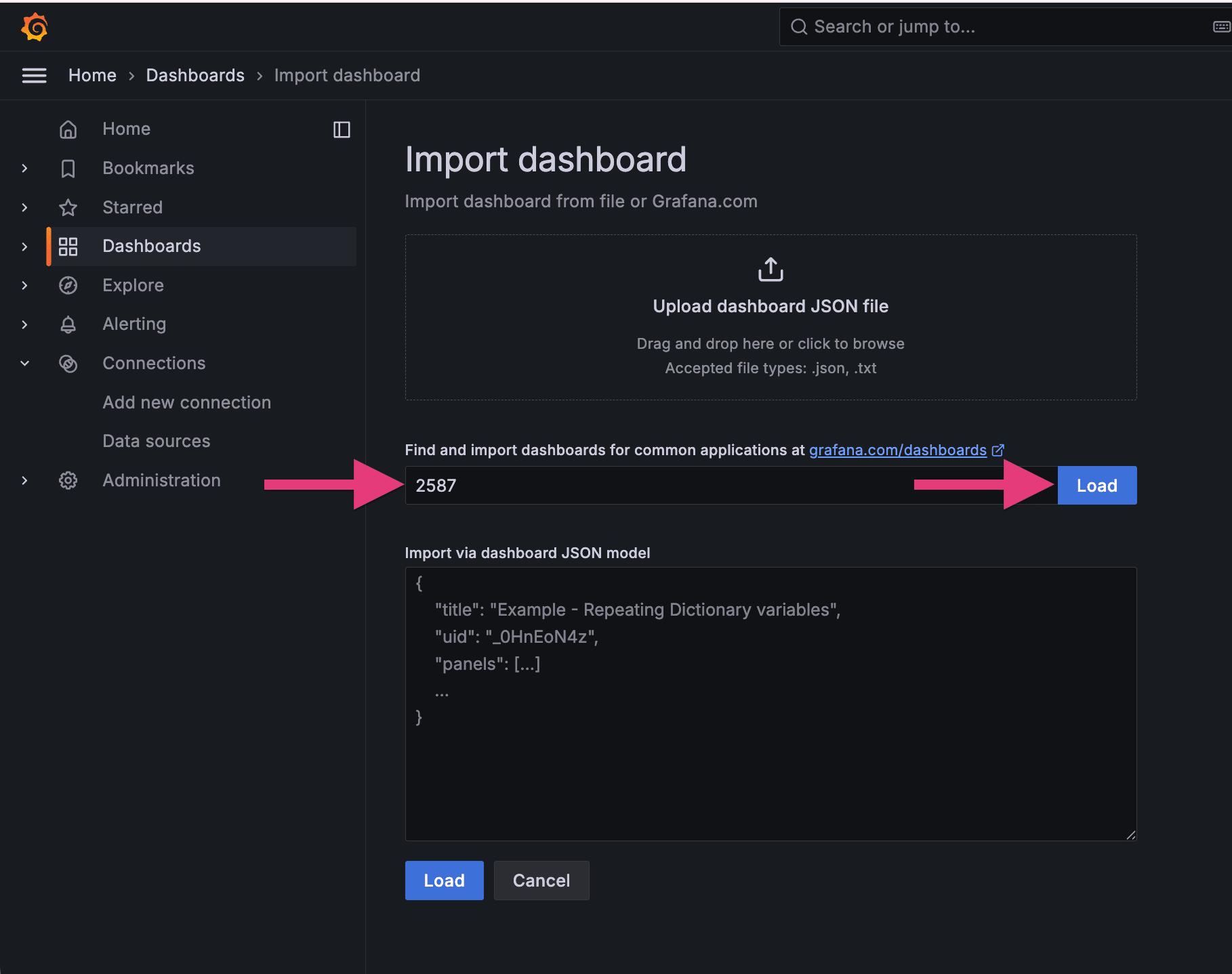
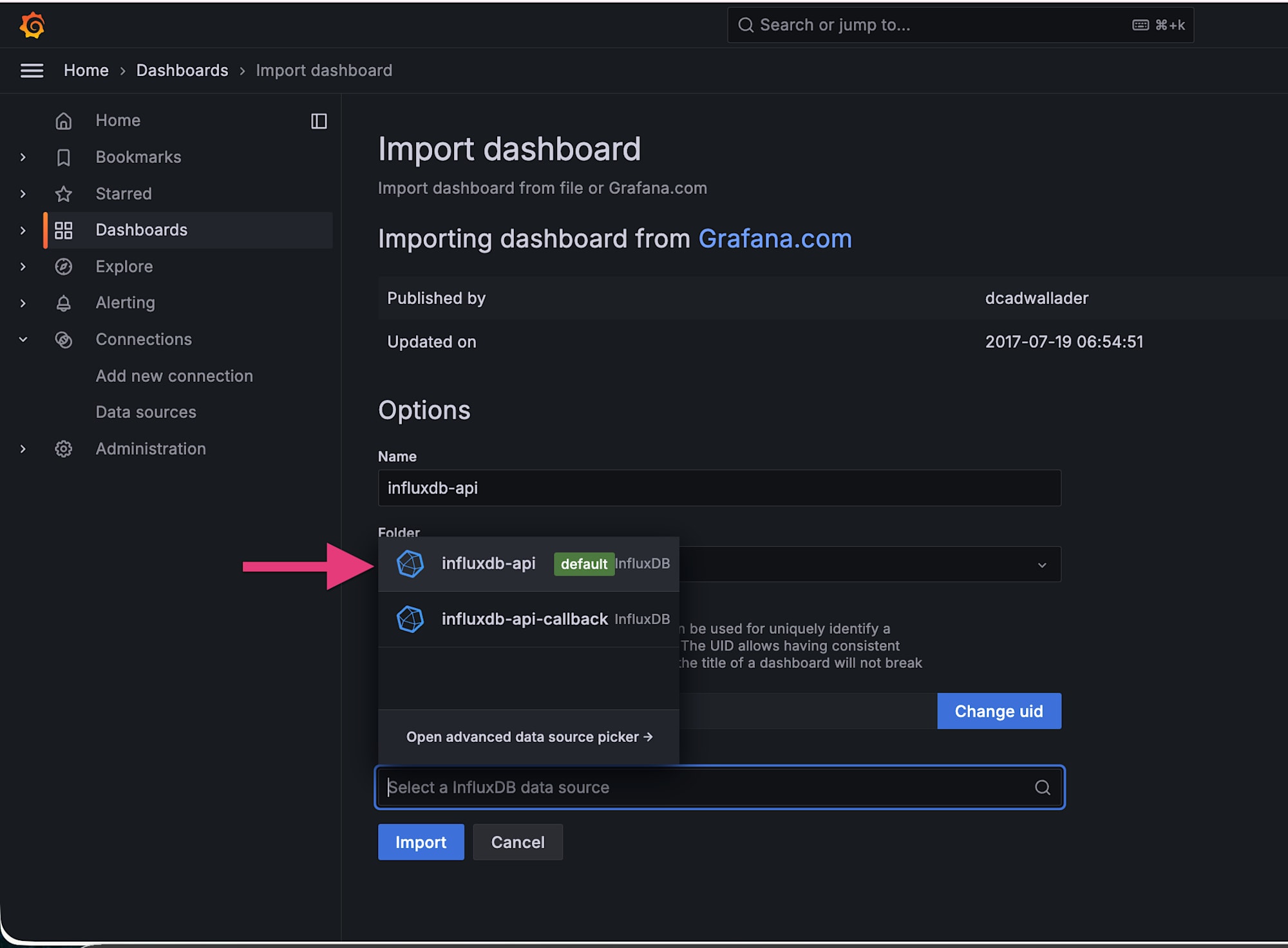
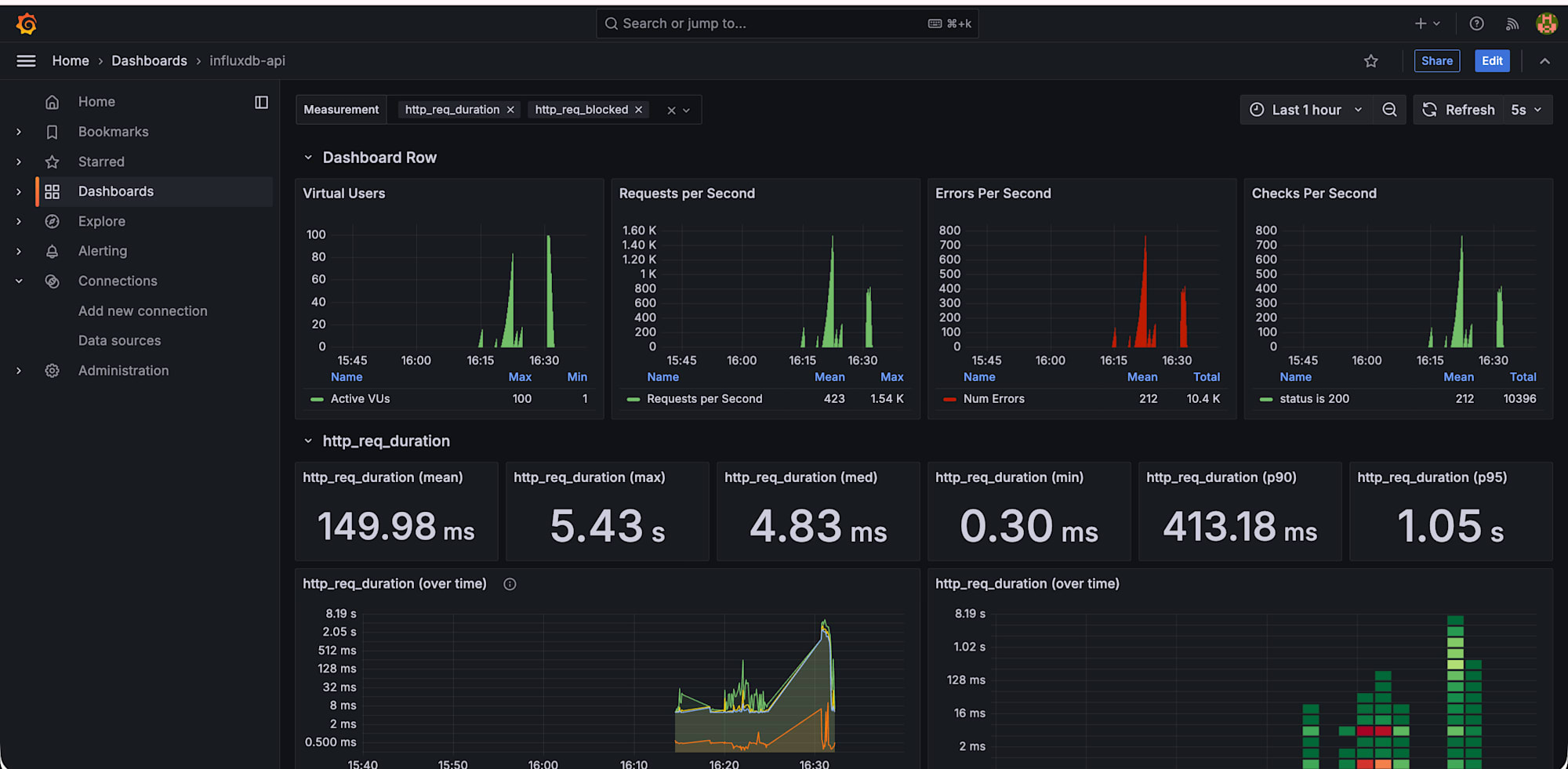
1 つ目のダッシュボードが作成できました。
2 回目: データソース = k6_ramping_api_callback、ダッシュボード名 = influxdb-api-callback
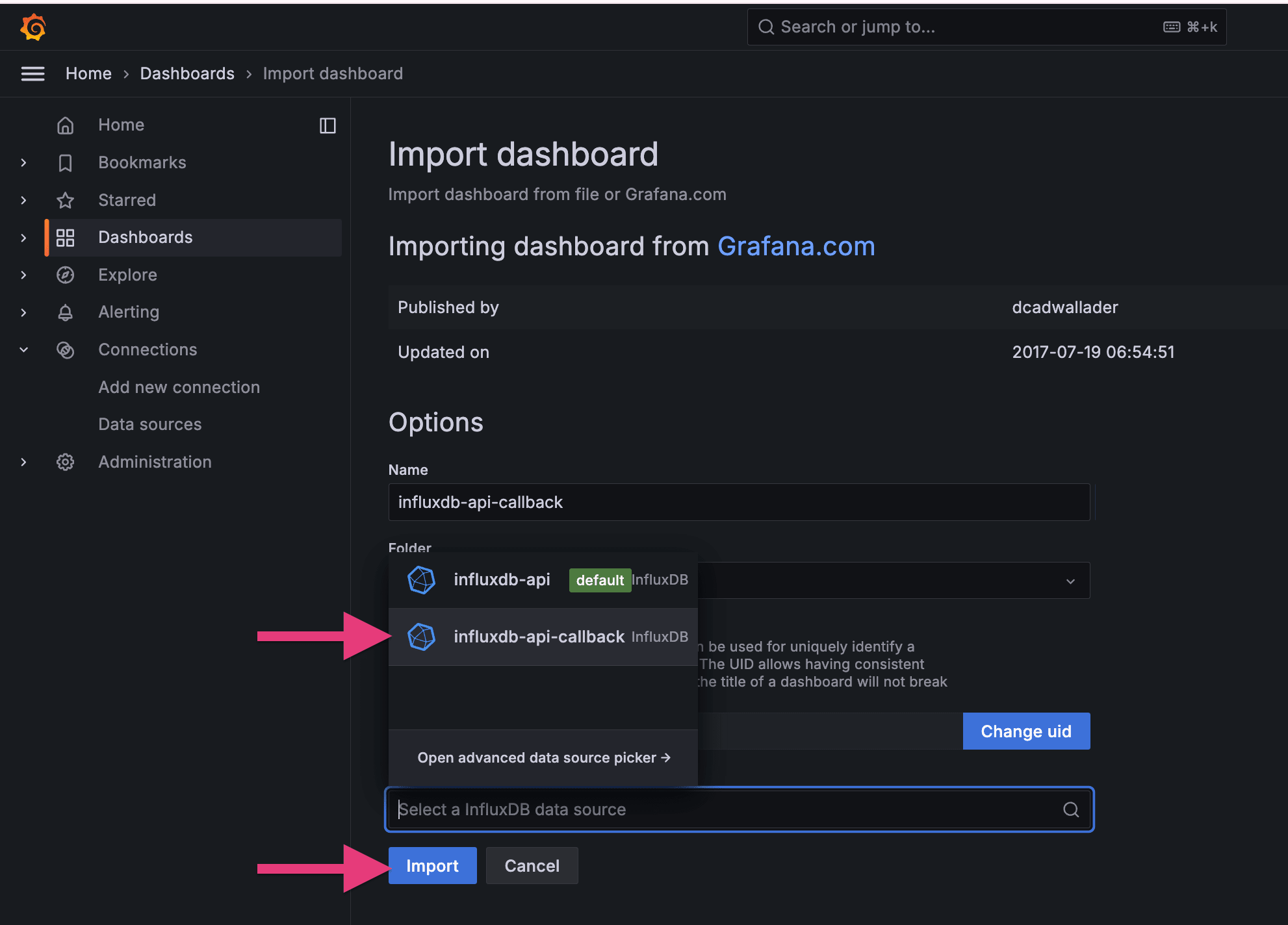
2 つ目のダッシュボードも作成できました。
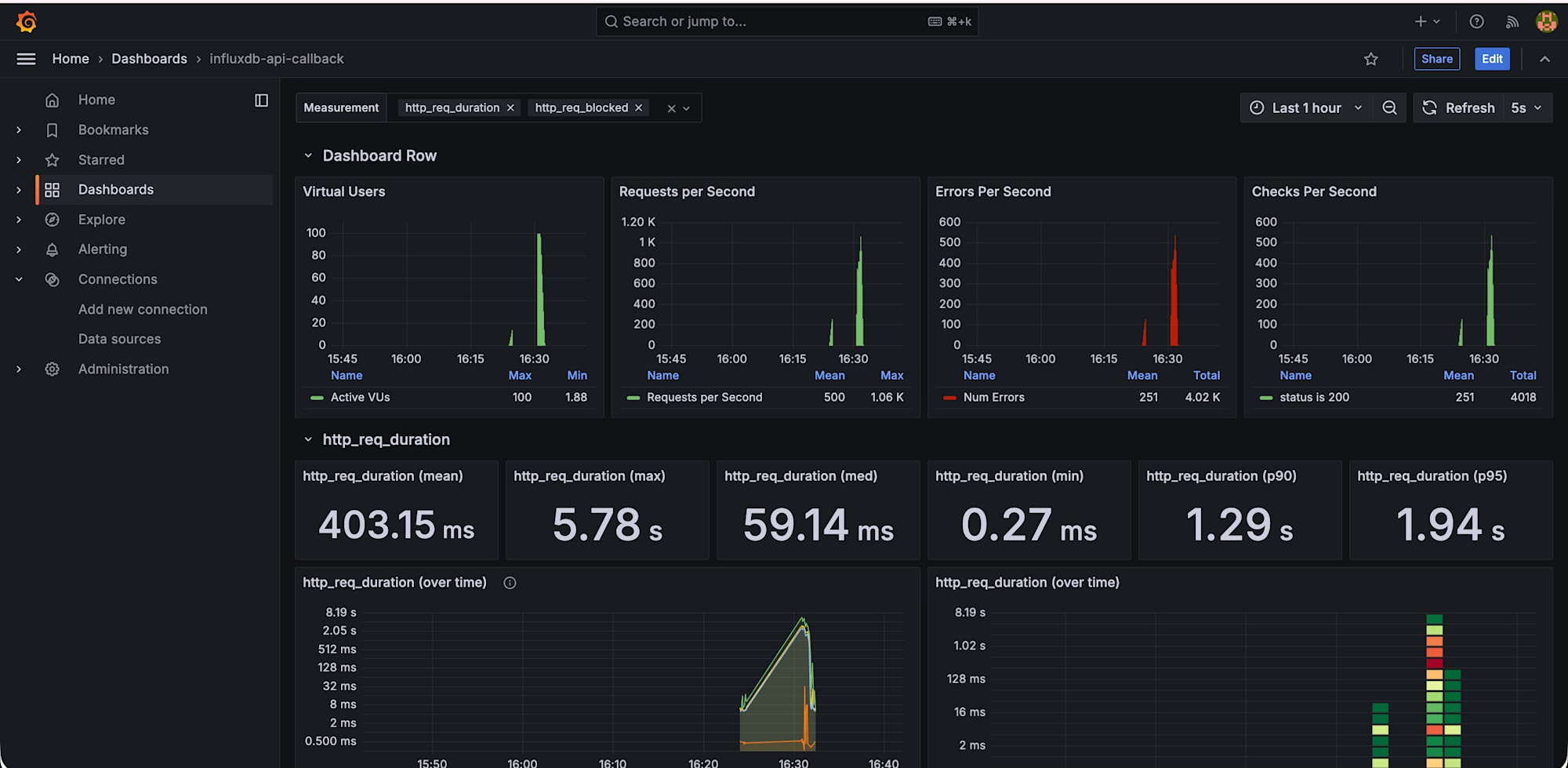
2 つのダッシュボードが作成できていますね!
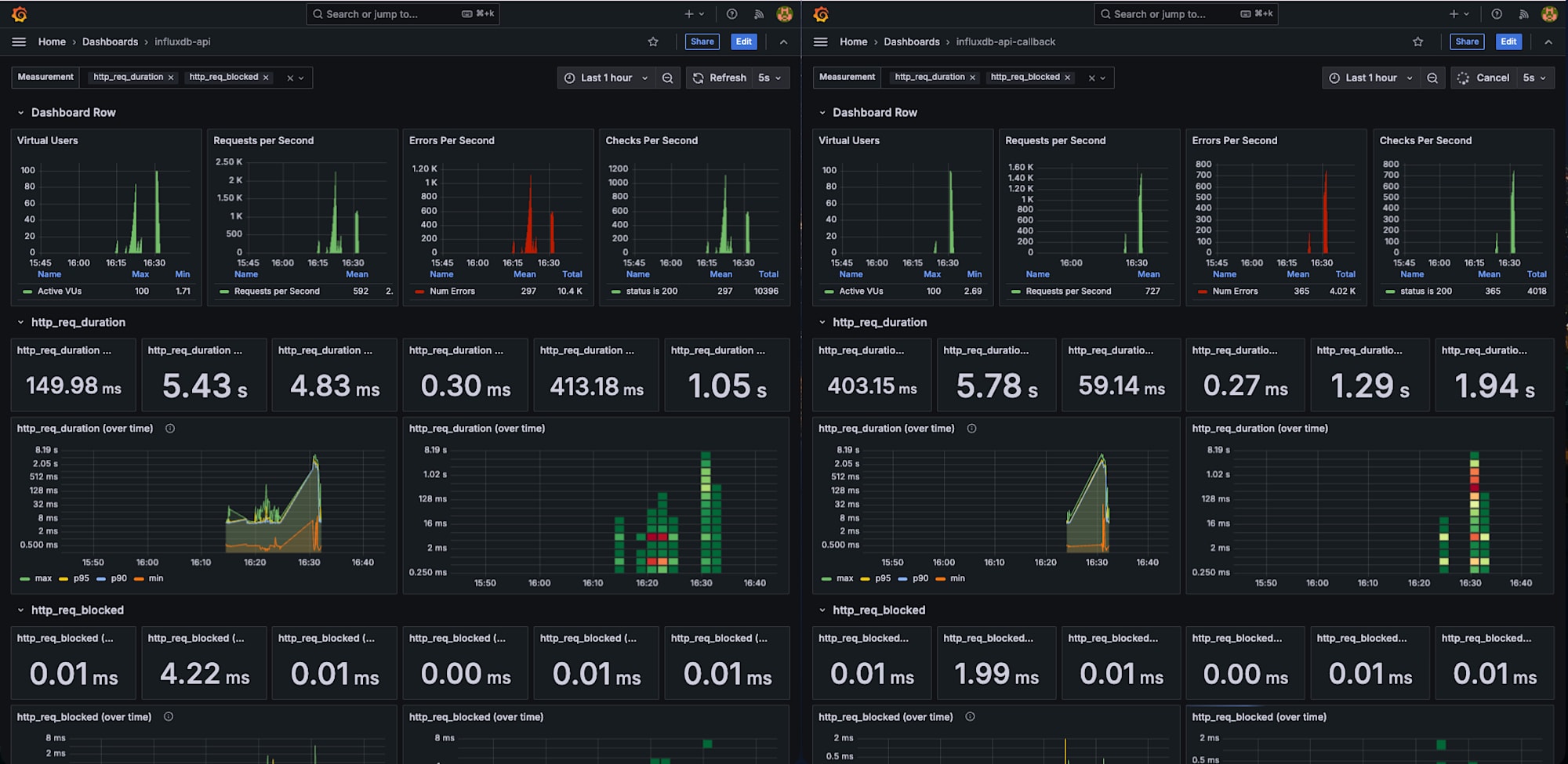
このようにタブで分けると監視しやすいかもしれません。
(左:influxdb-api 、右:influxdb-api-callback)
まとめ
InfluxDB のデータベースを分けるのは、コマンドの データベース名を変えるだけなのでとても簡単でした。シナリオが増えても同じ手順でスケールできます。この記事がどなたかの参考になれば幸いです!










