
Snowflakeでのレイクハウス構築がより簡単に!Snowflake Horizon Catalogで定義されたSnowflake-managedなApache IcebergテーブルをGoogle ColabのPySparkからクエリしてみた
さがらです。
先日、「External query engine support for Apache Iceberg™ tables with Snowflake Horizon Catalog」という機能がプレビューでリリースされました。
この機能を用いてSnowflake上で定義したSnowflake-managedなIcebergテーブルをGoogle ColabのPySparkからクエリしてみたので、その検証内容について本記事でまとめてみます。
Snowflake-managedなIcebergテーブルを作成
公式Docを参考に、Snowflake-managedなIcebergテーブルを作成します。(EXTERNAL_VOLUMEの定義は割愛します。)
-- データベースの作成(catalog_syncなし)
CREATE DATABASE sagara_iceberg_db_managed_snowflake;
-- スキーマ作成
USE DATABASE sagara_iceberg_db_managed_snowflake;
CREATE SCHEMA tpch_sf1_iceberg;
USE SCHEMA tpch_sf1_iceberg;
-- テーブルの作成(catalog_syncなし)
CREATE OR REPLACE ICEBERG TABLE customer_iceberg (
c_custkey INTEGER,
c_name STRING,
c_address STRING,
c_nationkey INTEGER,
c_phone STRING,
c_acctbal INTEGER,
c_mktsegment STRING,
c_comment STRING
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'sagara_iceberg_external_volume'
BASE_LOCATION = 'customer_iceberg_managed_snowflake'; -- S3上でのフォルダ名
-- テーブルへデータロード
INSERT INTO customer_iceberg
SELECT * FROM snowflake_sample_data.tpch_sf1.customer LIMIT 10000;
-- テーブルのクエリ
SELECT * FROM customer_iceberg;
このデータベース・スキーマ・テーブル・EXTERNAL VOLUMEに関する権限を使用するロールに付与します。
-- データベースに対する権限付与
GRANT USAGE ON DATABASE sagara_iceberg_db_managed_snowflake TO ROLE SAGARA_ADMIN_ROLE;
GRANT CREATE SCHEMA ON DATABASE sagara_iceberg_db_managed_snowflake TO ROLE SAGARA_ADMIN_ROLE;
-- スキーマに対する権限付与
GRANT USAGE ON SCHEMA sagara_iceberg_db_managed_snowflake.tpch_sf1_iceberg TO ROLE SAGARA_ADMIN_ROLE;
-- テーブルに対する権限付与
GRANT SELECT ON TABLE sagara_iceberg_db_managed_snowflake.tpch_sf1_iceberg.customer_iceberg TO ROLE SAGARA_ADMIN_ROLE;
-- EXTERNAL VOLUMEに対する権限付与
GRANT USAGE ON EXTERNAL VOLUME sagara_iceberg_external_volume TO ROLE SAGARA_ADMIN_ROLE;
認証用のSERVICEユーザー作成~PAT生成
次に、認証に使うSERVICEユーザーを作成します。
-- サービスユーザー作成
USE ROLE ACCOUNTADMIN;
CREATE USER sagara_icebergexternal
TYPE = SERVICE
DEFAULT_ROLE = SAGARA_ADMIN_ROLE;
GRANT ROLE SAGARA_ADMIN_ROLE TO USER sagara_icebergexternal;
ネットワークポリシーも作成して、付与します。
USE ROLE ACCOUNTADMIN;
-- ネットワークポリシーを作成(あまり良くないのですが、検証のためこのように定義しています)
CREATE OR REPLACE NETWORK POLICY sagara_icebergexternal_ip_policy
ALLOWED_IP_LIST = ('0.0.0.0/0');
-- ユーザーにネットワークポリシーを適用
ALTER USER sagara_icebergexternal SET NETWORK_POLICY = sagara_icebergexternal_ip_policy;
最後に、アクセス用のPATを生成します。表示されたトークンは一度しか表示されないため、忘れずに保持しておきましょう。
USE ROLE ACCOUNTADMIN;
ALTER USER IF EXISTS sagara_icebergexternal ADD PROGRAMMATIC ACCESS TOKEN iceberg_external_token
DAYS_TO_EXPIRY = 365
ROLE_RESTRICTION = 'SAGARA_ADMIN_ROLE';

Google ColabのPySparkからクエリ
まず、Google Colabを立ち上げたらPATとAccount IdentifierをSecretとして登録します。


この後、以下のコードを入力します。(生成AIに作ってもらったコードです。)
!pip install pyspark==3.5.1 -q
from google.colab import userdata
from pyspark.sql import SparkSession
# === ここを確認した値に置き換えてください ===
ACCOUNT_IDENTIFIER = userdata.get('MY_ACCOUNT_IDENTIFIER')
CATALOG_NAME = "SAGARA_ICEBERG_DB_FOR_DUCKDB"
ROLE_NAME = "SAGARA_ADMIN_ROLE"
REGION = "ap-northeast-1"
# =========================================
CATALOG_URI = f"https://{ACCOUNT_IDENTIFIER}.snowflakecomputing.com/polaris/api/catalog"
HORIZON_SESSION_ROLE = f"session:role:{ROLE_NAME}"
# PAT取得
ACCESS_TOKEN = userdata.get('SNOWFLAKE_PAT')
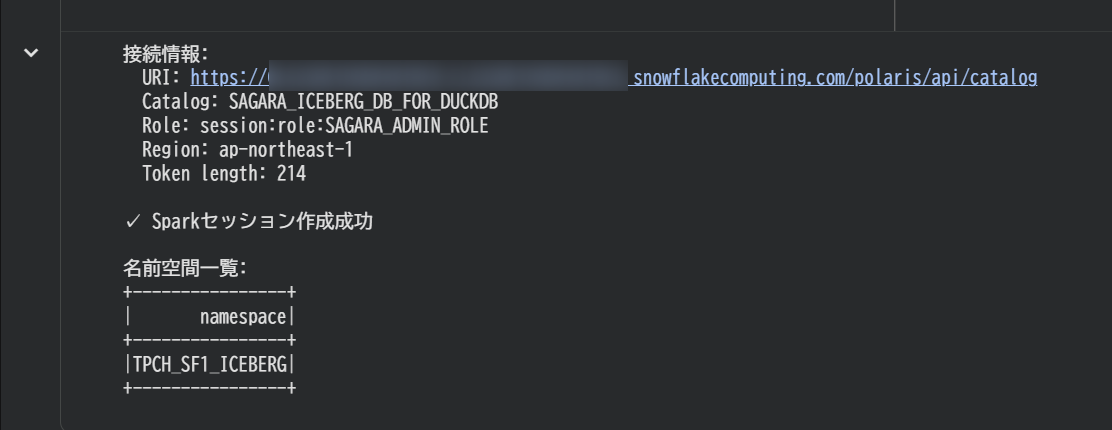
print(f"接続情報:")
print(f" URI: {CATALOG_URI}")
print(f" Catalog: {CATALOG_NAME}")
print(f" Role: {HORIZON_SESSION_ROLE}")
print(f" Region: {REGION}")
print(f" Token length: {len(ACCESS_TOKEN)}")
ICEBERG_VERSION = "1.9.1"
spark = (
SparkSession.builder
.appName("SnowflakeIcebergReader")
.master("local[*]")
.config(
"spark.jars.packages",
f"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:{ICEBERG_VERSION},"
f"org.apache.iceberg:iceberg-aws-bundle:{ICEBERG_VERSION}"
)
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.defaultCatalog", CATALOG_NAME)
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog")
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest")
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", CATALOG_URI)
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", CATALOG_NAME)
.config(f"spark.sql.catalog.{CATALOG_NAME}.credential", ACCESS_TOKEN)
.config(f"spark.sql.catalog.{CATALOG_NAME}.scope", HORIZON_SESSION_ROLE)
.config(f"spark.sql.catalog.{CATALOG_NAME}.client.region", REGION)
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials")
.config("spark.sql.iceberg.vectorization.enabled", "false")
.getOrCreate()
)
spark.sparkContext.setLogLevel("ERROR")
# テスト
try:
print("\n✓ Sparkセッション作成成功")
print("\n名前空間一覧:")
spark.sql("SHOW NAMESPACES").show()
except Exception as e:
print(f"\n✗ エラー: {e}")
問題なく実行できれば、下図のように表示されるはずです。
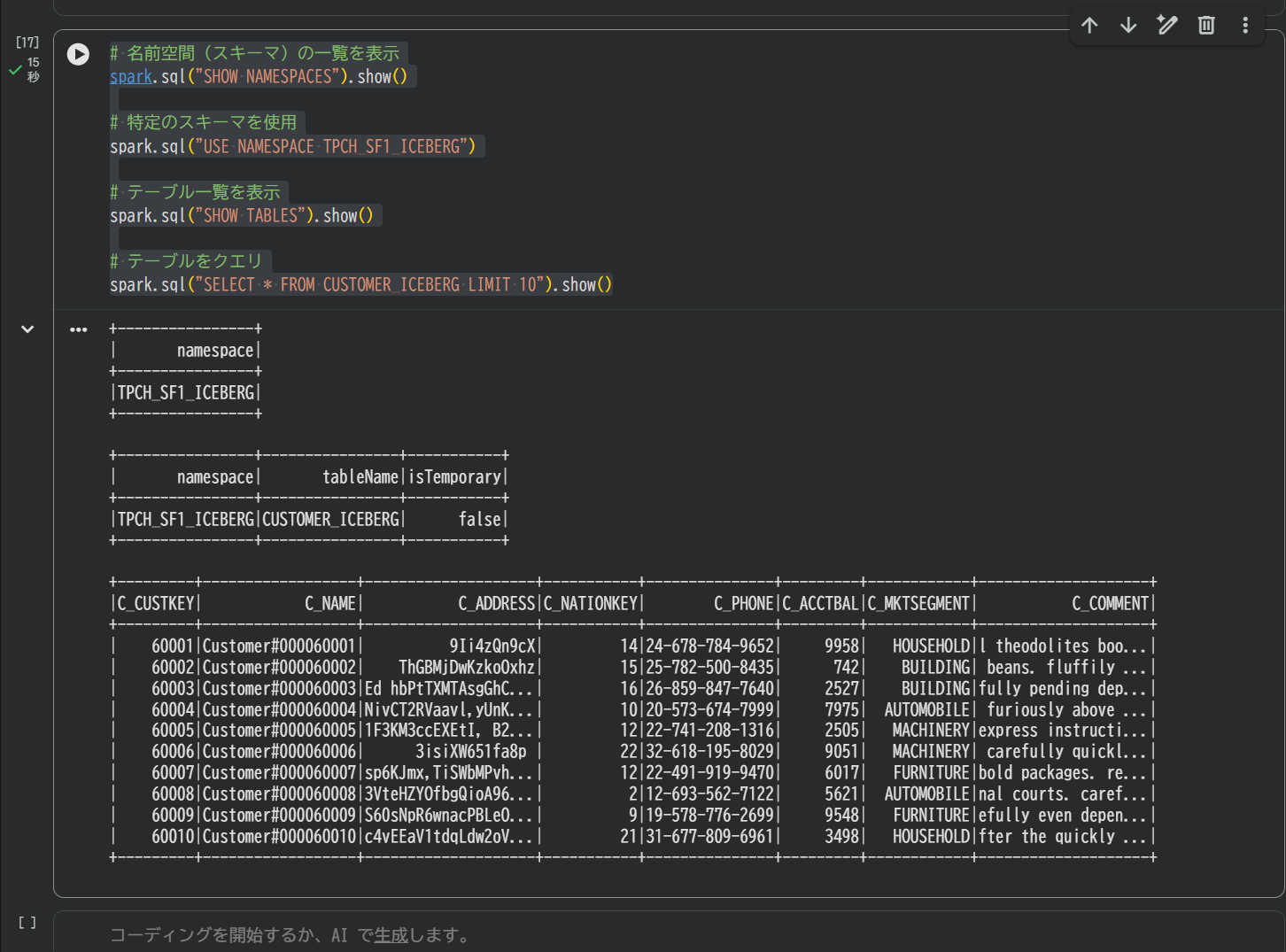
この後、以下のコードを入力して実行します。すると、テーブルをクエリすることが出来ました!(テーブル名などはすべて大文字じゃないとえらーとなりました。)
# 名前空間(スキーマ)の一覧を表示
spark.sql("SHOW NAMESPACES").show()
# 特定のスキーマを使用
spark.sql("USE NAMESPACE TPCH_SF1_ICEBERG")
# テーブル一覧を表示
spark.sql("SHOW TABLES").show()
# テーブルをクエリ
spark.sql("SELECT * FROM CUSTOMER_ICEBERG LIMIT 10").show()
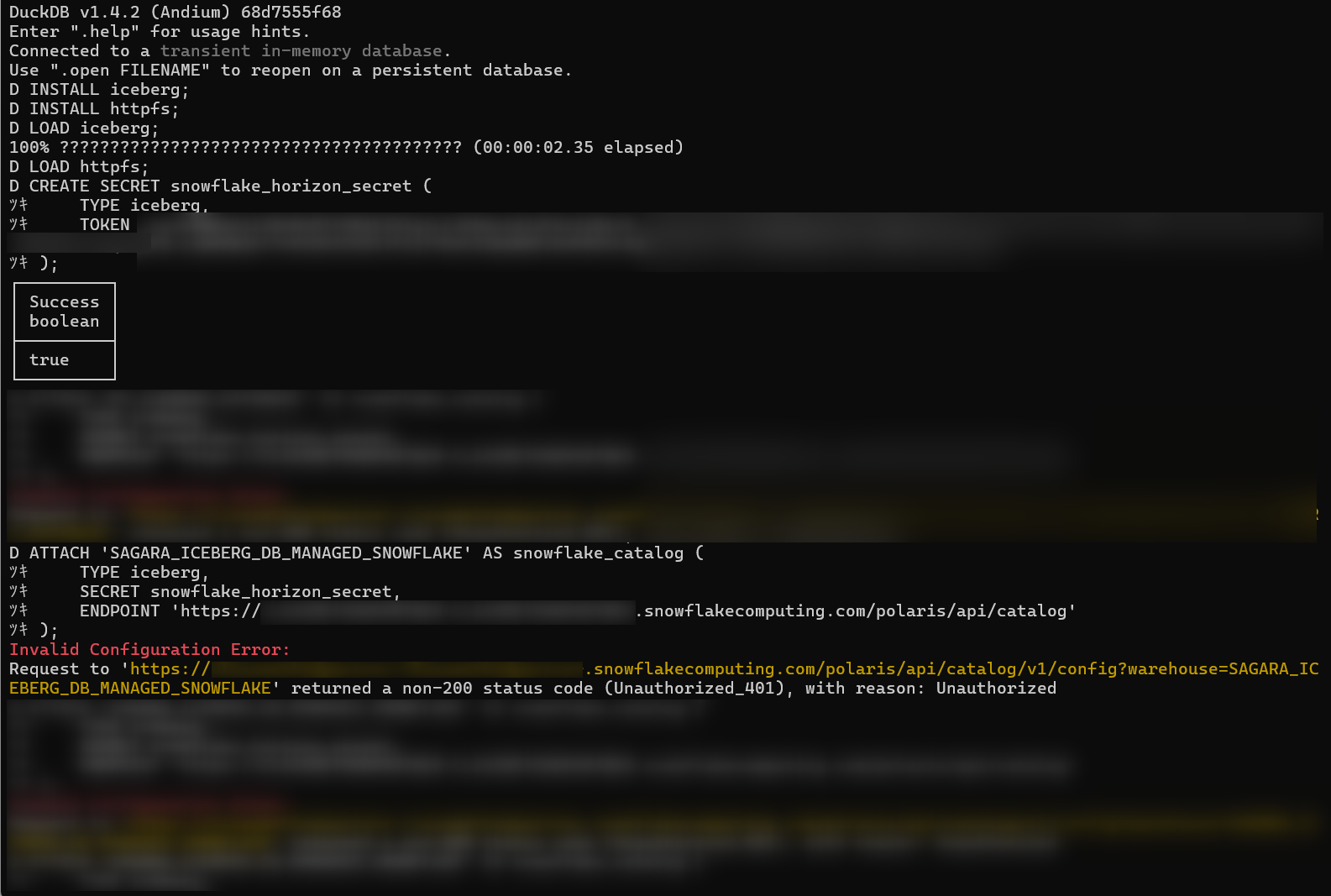
おまけ:DuckDBからの接続はうまくいかず…
本当はDuckDBから接続させたかったのですが、通常のApache Polarisとの接続とは異なる認証方法のため、生成AIの力も借りて色々試してみたのですがうまくいかずでした…
最後に
リリースされた「External query engine support for Apache Iceberg™ tables with Snowflake Horizon Catalog」機能を用いて、Snowflake Horizon Catalogで定義されたSnowflake-managedなApache IcebergテーブルをGoogle ColabのPySparkからクエリしてみました。
DuckDBからクエリできなかったことは残念なのですが、PySparkからはPATを発行するだけでとても簡単に接続ができました!まだプレビュー機能のため、他のクエリエンジンからの接続方法も今後確立されていくはずですので、期待したいです!!










