![[新機能]Snowflake から Google Cloud の Lakehouse ランタイム カタログに Apache Iceberg REST カタログ統合を使用して接続できるようになりました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-37f4322e7cca0bb66380be0a31ceace4/0886455fd66594d3e7d8947c9c7c844d/eyecatch_snowflake?w=3840&fm=webp)
[新機能]Snowflake から Google Cloud の Lakehouse ランタイム カタログに Apache Iceberg REST カタログ統合を使用して接続できるようになりました
はじめに
2026年6月のアップデートで、Snowflake から Google Cloud の BigLake Metastore(現 Lakehouse ランタイム カタログ)への Apache Iceberg REST カタログ統合を使用して接続する機能が一般提供となりました。
こちらを試してみた内容を本記事でまとめてみます。
アップデートの概要
本機能については以下に記載があります。
Snowflake の Iceberg REST カタログ統合(CATALOG_SOURCE = ICEBERG_REST)から、Google Cloud の Lakehouse ランタイム カタログ(REST エンドポイント https://biglake.googleapis.com/iceberg/v1/restcatalog)に接続し、Catalog-linked database を作成することで、Google Cloud 側の Iceberg テーブルを Snowflake から読み書きできるようになる機能です。
特徴として、認証には WIF(Workload identity federation) を使用するため、サービスアカウントの長期鍵なしに Snowflake から Google Cloud へ認証できます。
なお、本機能で Snowflake が読み書きする対象は、Lakehouse ランタイム カタログが管理する Iceberg テーブルです。Lakehouse ランタイム カタログのテーブルは BigQuery からも参照できるため、結果として Snowflake が作成・書き込みしたテーブルを BigQuery から参照することも可能になります。
これまで Snowflake と BigQuery の間で Iceberg テーブルを共有するには、メタデータファイル(metadata.json)のパスを直接指定する手動連携が基本でした。具体的には以下のような運用が必要でした。
- 一方で作成・更新した Iceberg テーブルをもう一方で参照するには、最新の metadata.json のパスを指定してテーブルを定義する
- 元データが更新されると、Iceberg のアーキテクチャ上「新しい metadata.json」が生成されるが、自動追随しないため、最新のメタデータパスを特定してテーブル定義を再設定する処理(ストアドプロシージャ等)が必要
これまでの方式については、以下の記事が参考になります。
今回の REST カタログ統合では、カタログを介してテーブルを自動的に検知でき、このような手動のメタデータパス管理なしに連携できる点がポイントと思います。
Lakehouse ランタイム カタログ
はじめに Google Cloud 側の用語を簡単に整理しておきます。
- Google Cloud Lakehouse(旧 BigLake):Google Cloud 上でオープンなレイクハウスを実現するためのプラットフォーム全体を指します
- Lakehouse ランタイム カタログ(旧 BigLake metastore)
- メタデータサービスに相当し、Apache Iceberg REST カタログ エンドポイントを提供します。今回 Snowflake が接続するのは、この REST カタログ エンドポイントです
なお、2026年4月20日より BigLake は「Lakehouse for Apache Iceberg」、BigLake metastore は「Lakehouse ランタイム カタログ」に名称変更されています。
試してみる
本記事では、以下の内容を検証しました。
- Lakehouse ランタイム カタログ管理のテーブル(
gs://)を Snowflake から参照・書き込み - 上記のテーブルを BigQuery から参照
前提条件
以下の環境を使用しています。
- Snowflake トライアルアカウント(AWS 東京リージョン)
- Google Cloud プロジェクト
Snowflake が AWS 東京のため、Google Cloud 側のリソース(GCS バケット・Lakehouse カタログ・BigQuery)は地理的に近い東京リージョン(asia-northeast1)に揃えました。
事前準備
以下の通り、Cloud Shell で変数を設定し必要な API を有効化しておきました。
export PROJECT_ID="<プロジェクトID>"
export LOCATION="asia-northeast1"
export GCS_BUCKET="<バケット名>"
export PROJECT_NUMBER="$(gcloud projects describe "$PROJECT_ID" --format='value(projectNumber)')"
gcloud config set project "$PROJECT_ID"
# 必要な API を有効化
gcloud services enable \
biglake.googleapis.com bigquery.googleapis.com storage.googleapis.com \
iamcredentials.googleapis.com sts.googleapis.com
GCS バケットも作成しておきます。
gcloud storage buckets create "gs://$GCS_BUCKET" \
--location="$LOCATION" --uniform-bucket-level-access
Workload Identity Federation の設定
まず Snowflake 側で、WIF の Issuer URL を取得します。
SELECT SYSTEM$GET_WORKLOAD_IDENTITY_ISSUER_URL();
+------------------------------------------------------------------------+
| SYSTEM$GET_WORKLOAD_IDENTITY_ISSUER_URL() |
|------------------------------------------------------------------------|
| https://identity.snowflake.com/oauth2/xxxxxxxx/xxxxxxxx/xxxxxxxxxxxxxx |
+------------------------------------------------------------------------+
この Issuer URL を使って、Google Cloud 側に Workload Identity プールと OIDC プロバイダを作成します。
export WIF_POOL_ID="snowflake-pool"
export WIF_PROVIDER_ID="snowflake-provider"
export SF_ISSUER_URL="<上記で取得した Issuer URL>"
gcloud iam workload-identity-pools create "$WIF_POOL_ID" \
--location=global --display-name="Snowflake BigLake Pool"
gcloud iam workload-identity-pools providers create-oidc "$WIF_PROVIDER_ID" \
--location=global \
--workload-identity-pool="$WIF_POOL_ID" \
--issuer-uri="$SF_ISSUER_URL" \
--attribute-mapping="google.subject=assertion.sub"
Catalog 統合で使う OAuth Audience(プロバイダのリソース名)を組み立てておきます。
export OAUTH_AUDIENCE="//iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${WIF_POOL_ID}/providers/${WIF_PROVIDER_ID}"
echo "$OAUTH_AUDIENCE"
Lakehouse ランタイム カタログ管理テーブルを Snowflake から参照・書き込み
Lakehouse カタログの作成
gcs-bucketタイプのカタログを作成します。このタイプではカタログ ID がそのままバケット ID として扱われるため、カタログ名は作成済みのバケット名と一致させる必要がありました。
export MY_CATALOG="$GCS_BUCKET"
gcloud biglake iceberg catalogs create "$MY_CATALOG" \
--catalog-type=gcs-bucket \
--credential-mode=vended-credentials \
--primary-location="$LOCATION"
--credential-mode=vended-credentialsとすることで、カタログ側が GCS の資格情報を払い出すため、後述の Snowflake 側で外部ボリュームが不要になります。
出力:
Created catalog [projects/<プロジェクト>/catalogs/<カタログ名>].
BigLake service account: xxx@xxxxx
BigLake service account ID: xxxxxxxxxx
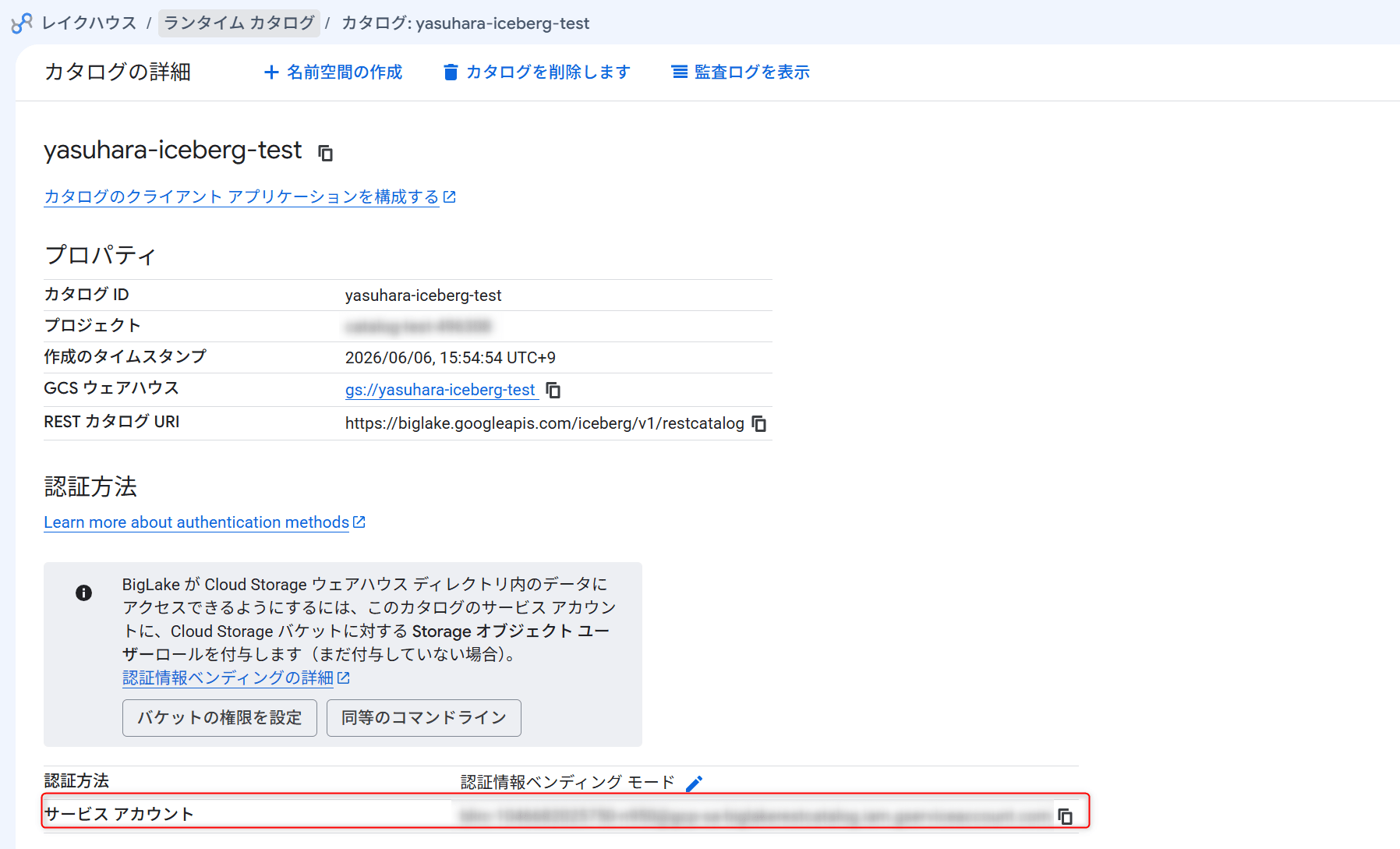
カタログのサービスアカウントにバケット権限を付与
vended-credentials モードでは、カタログ作成時に自動生成される Lakehouse ランタイムカタログのサービスアカウントに対して、バケットへの roles/storage.objectUser を明示的に付与しておく必要がありました。
CATALOG_SA="blirc-${PROJECT_NUMBER}-xxxx@gcp-sa-biglakerestcatalog.iam.gserviceaccount.com"
gcloud storage buckets add-iam-policy-binding "gs://$GCS_BUCKET" \
--member="serviceAccount:$CATALOG_SA" \
--role="roles/storage.objectUser"
サービスアカウントの値は Google Cloud コンソール(IAM)などでも確認できます。
PyIceberg でテーブルを作成
Lakehouse ランタイムカタログで管理するテーブルは、Iceberg REST クライアントから作成します。ここでは Cloud Shell から PyIceberg を使いました。
pip install "pyiceberg[gcsfs]" pyarrow
gcloud auth application-default login
gcloud auth application-default loginでログインしておくことで、ローカル環境に ADC(Application Default Credentials:アプリケーションデフォルト認証情報)が生成されます。これにより、Python スクリプト(PyIceberg)が GCS などの Google Cloud サービスにアクセスする際、自動的にユーザーの権限でアクセスできるようになります。
ログイン後、以下のスクリプトを実行し、namespace(demo_ns)と Iceberg テーブル(customers)を作成してサンプルデータを追加しました。
サンプルデータの作成
import os
from datetime import date
import google.auth
import google.auth.transport.requests
import pyarrow as pa
from pyiceberg.catalog.rest import RestCatalog
# cloud-platform スコープを明示した OAuth2 トークンを取得(auth.type=google 単独だと 401 になったため)
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(google.auth.transport.requests.Request())
catalog = RestCatalog(
name="lakehouse",
**{
"uri": "https://biglake.googleapis.com/iceberg/v1/restcatalog",
"warehouse": f"gs://{os.environ['GCS_BUCKET']}",
"token": creds.token,
"header.x-goog-user-project": os.environ["PROJECT_ID"],
"header.X-Iceberg-Access-Delegation": "vended-credentials",
},
)
catalog.create_namespace_if_not_exists("demo_ns")
data = pa.table({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Carol"],
"signup_date": [date(2026, 1, 10), date(2026, 2, 20), date(2026, 3, 5)],
})
table = catalog.create_table_if_not_exists("demo_ns.customers", schema=data.schema)
table.append(data)
print(table.scan().to_arrow())
出力:
pyarrow.Table
id: int64
name: string
signup_date: date32[day]
----
id: [[1,2,3]]
name: [["Alice","Bob","Carol"]]
signup_date: [[2026-01-10,2026-02-20,2026-03-05]]
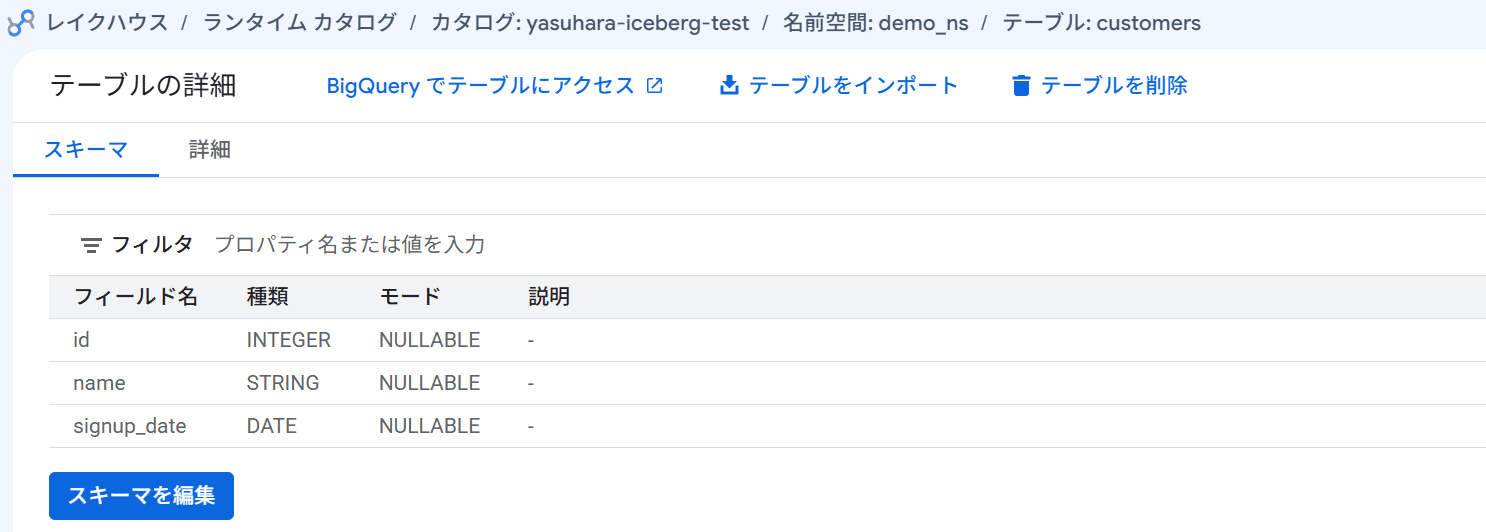
テーブル作成後、レイクハウスランタイムカタログの詳細にも表示されていました。
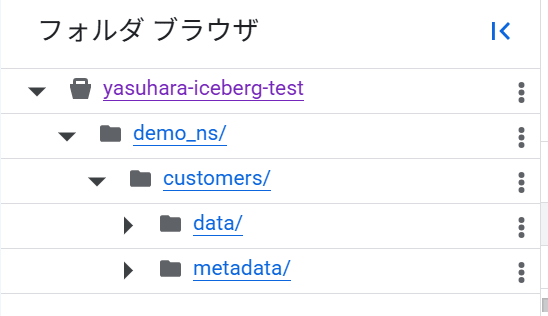
バケット側には、データファイル・メタデータファイルも追加されています。
Snowflake で Catalog 統合を作成
ここから Snowflake 側の設定を行います。
Google Cloud 側にカタログとテーブルを用意できたので、Snowflake から Lakehouse ランタイムカタログの REST エンドポイントに接続するための Catalog 統合オブジェクトを作成します。
CREATE OR REPLACE CATALOG INTEGRATION lakehouse_int
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
REST_CONFIG = (
CATALOG_URI = 'https://biglake.googleapis.com/iceberg/v1/restcatalog'
CATALOG_NAME = 'gs://<バケット名>'
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS
ADDITIONAL_HEADERS = ( "x-goog-user-project" = '<プロジェクトID>' )
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_GRANT_TYPE = TOKEN_EXCHANGE
OAUTH_TOKEN_URI = 'https://sts.googleapis.com/v1/token'
OAUTH_AUDIENCE = '<OAUTH_AUDIENCE>'
OAUTH_ALLOWED_SCOPES = ('https://www.googleapis.com/auth/bigquery')
)
ENABLED = TRUE;
カタログ統合作成後、以下を実行し出力のWORKLOAD_IDENTITY_FEDERATION_SUBJECT(identity_ から始まる文字列)を控えておきます。
DESC CATALOG INTEGRATION lakehouse_int;
Google Cloud 側で IAM 権限を付与
先ほどの手順で取得したWORKLOAD_IDENTITY_FEDERATION_SUBJECTに、必要なロールを付与します。
export WIF_SUBJECT="<WORKLOAD_IDENTITY_FEDERATION_SUBJECT>"
P1="principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${WIF_POOL_ID}/subject/${WIF_SUBJECT}"
gcloud projects add-iam-policy-binding "$PROJECT_ID" --role="roles/biglake.admin" --member="$P1"
gcloud storage buckets add-iam-policy-binding "gs://$GCS_BUCKET" --role="roles/storage.objectAdmin" --member="$P1"
gcloud projects add-iam-policy-binding "$PROJECT_ID" --role="roles/serviceusage.serviceUsageConsumer" --member="$P1"
後続の Snowflake 側の処理でSYSTEM$VERIFY_CATALOG_INTEGRATIONを実行時にserviceusage.services.useを要求したため、roles/serviceusage.serviceUsageConsumerの付与が必要でした。
なお、ここでは検証用途のため管理者ロールを付与しています。本番では最小権限の観点から用途に応じて絞ることを推奨します。
Snowflake からの参照・書き込み
接続の準備は以上で、実際に Snowflake から Lakehouse ランタイムカタログのテーブルを操作します。
まず SYSTEM$VERIFY_CATALOG_INTEGRATIONで接続を検証し、Catalog-linked database を作成します。これにより、カタログ側の namespace が schema として同期され、その配下の Iceberg テーブルが Snowflake から参照できるようになります。
SELECT SYSTEM$VERIFY_CATALOG_INTEGRATION('lakehouse_int');
問題なければ以下の表示となります。
+----------------------------------------------------+
| SYSTEM$VERIFY_CATALOG_INTEGRATION('LAKEHOUSE_INT') |
|----------------------------------------------------|
| { |
| "success" : true, |
| "errorCode" : "", |
| "errorMessage" : "" |
| } |
+----------------------------------------------------+
Catalog-linked database を作成します。
>CREATE OR REPLACE DATABASE lakehouse_db
LINKED_CATALOG = ( CATALOG = 'lakehouse_int' );
+---------------------------------------------+
| status |
|---------------------------------------------|
| Database LAKEHOUSE_DB successfully created. |
+---------------------------------------------+
しばらくするとスキーマやテーブルが同期され、Snowflake からも参照できるようになります。
>SHOW ICEBERG TABLES IN SCHEMA lakehouse_db.demo_ns;
+-------------------------------+-----------+---------------+-------------+--------------+----------------------+--------------+--------------------+--------------------+-------------------+---------------+--------------------+---------+-----------------+--------------+-------------------+---------------------+------------------+---------------------------+------------------------------+
| created_on | name | database_name | schema_name | owner | external_volume_name | catalog_name | iceberg_table_type | catalog_table_name | catalog_namespace | base_location | can_write_metadata | comment | owner_role_type | name_mapping | catalog_sync_name | auto_refresh_status | partition_specs | current_partition_spec_id | iceberg_table_format_version |
|-------------------------------+-----------+---------------+-------------+--------------+----------------------+--------------+--------------------+--------------------+-------------------+---------------+--------------------+---------+-----------------+--------------+-------------------+---------------------+------------------+---------------------------+------------------------------|
| 2026-06-06 16:57:45.908 +0900 | customers | LAKEHOUSE_DB | demo_ns | ACCOUNTADMIN | <invalid> | NULL | UNMANAGED | NULL | NULL | NULL | Y | | ROLE | NULL | | | [ { | 0 | 2 |
| | | | | | | | | | | | | | | | | | "spec-id" : 0, | | |
| | | | | | | | | | | | | | | | | | "fields" : [ ] | | |
| | | | | | | | | | | | | | | | | | } ] | | |
+-------------------------------+-----------+---------------+-------------+--------------+----------------------+--------------+--------------------+--------------------+-------------------+---------------+--------------------+---------+-----------------+--------------+-------------------+---------------------+------------------+---------------------------+------------------------------+
実際にテーブルを参照してみます。
SELECT * FROM lakehouse_db.demo_ns.customers ORDER BY id;
+----+-------+-------------+
| id | name | signup_date |
|----+-------+-------------|
| 1 | Alice | 2026-01-10 |
| 2 | Bob | 2026-02-20 |
| 3 | Carol | 2026-03-05 |
+----+-------+-------------+
問題なく参照できました。
続けて、Snowflake からの書き込み操作を試してみます。
-- 書き込み
> INSERT INTO lakehouse_db.demo_ns.customers VALUES (4, 'Dave', '2026-04-15'::DATE);
+-------------------------+
| number of rows inserted |
|-------------------------|
| 1 |
+-------------------------+
-- 書き込み(Snowflake から新規作成)
> CREATE SCHEMA IF NOT EXISTS lakehouse_db.sf_ns;
+------------------------------------+
| status |
|------------------------------------|
| Schema sf_ns successfully created. |
+------------------------------------+
> CREATE ICEBERG TABLE lakehouse_db.sf_ns.orders (order_id INT, amount NUMBER(10,2));
+------------------------------------+
| status |
|------------------------------------|
| Table orders successfully created. |
+------------------------------------+
INSERT INTO lakehouse_db.sf_ns.orders VALUES (100, 1980.00);
SELECT * FROM lakehouse_db.sf_ns.orders;
+----------+---------+
| order_id | amount |
|----------+---------|
| 100 | 1980.00 |
+----------+---------+
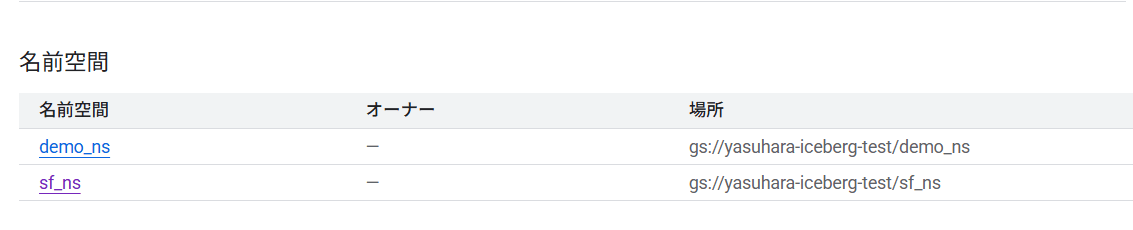
書き込み後、Lakehouse ランタイム カタログ側でも名前空間が追加されています。
書き込んだ内容は PyIceberg からも確認できました。
PyIcebergから確認
cat > read_iceberg.py <<'EOF'
import os
import sys
import time
import google.auth
import google.auth.transport.requests
from pyiceberg.catalog.rest import RestCatalog
PROJECT_ID = os.environ["PROJECT_ID"]
GCS_BUCKET = os.environ["GCS_BUCKET"]
target = sys.argv[1] if len(sys.argv) > 1 else "demo_ns.customers"
namespace = target.split(".")[0]
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(google.auth.transport.requests.Request())
catalog = RestCatalog(
name="lakehouse",
**{
"uri": "https://biglake.googleapis.com/iceberg/v1/restcatalog",
"warehouse": f"gs://{GCS_BUCKET}",
"token": creds.token,
"header.x-goog-user-project": PROJECT_ID,
"header.X-Iceberg-Access-Delegation": "vended-credentials",
},
)
print("namespaces:", catalog.list_namespaces())
print(f"tables in {namespace}:", catalog.list_tables(namespace))
t0 = time.perf_counter()
table = catalog.load_table(target)
arrow = table.scan().to_arrow()
elapsed = time.perf_counter() - t0
print(arrow)
print(f"table={target}, rows={arrow.num_rows}, elapsed={elapsed:.2f}s")
EOF
# Snowflake から追加したレコードを確認
$ python3 read_iceberg.py demo_ns.customers
namespaces: [('demo_ns',), ('sf_ns',)]
tables in demo_ns: [('demo_ns', 'customers')]
pyarrow.Table
id: int64
name: string
signup_date: date32[day]
----
id: [[4],[1,2,3]]
name: [["Dave"],["Alice","Bob","Carol"]]
signup_date: [[2026-04-15],[2026-01-10,2026-02-20,2026-03-05]]
table=demo_ns.customers, rows=4, elapsed=2.23ss
# Snowflake が作成したテーブルを Lakehouse ランタイム側から確認
$ python3 read_iceberg.py sf_ns.orders
namespaces: [('demo_ns',), ('sf_ns',)]
tables in sf_ns: [('sf_ns', 'orders')]
pyarrow.Table
order_id: int32
amount: decimal128(10, 2)
----
order_id: [[100]]
amount: [[1980.00]]
table=sf_ns.orders, rows=1, elapsed=1.84s
BigQuery から参照
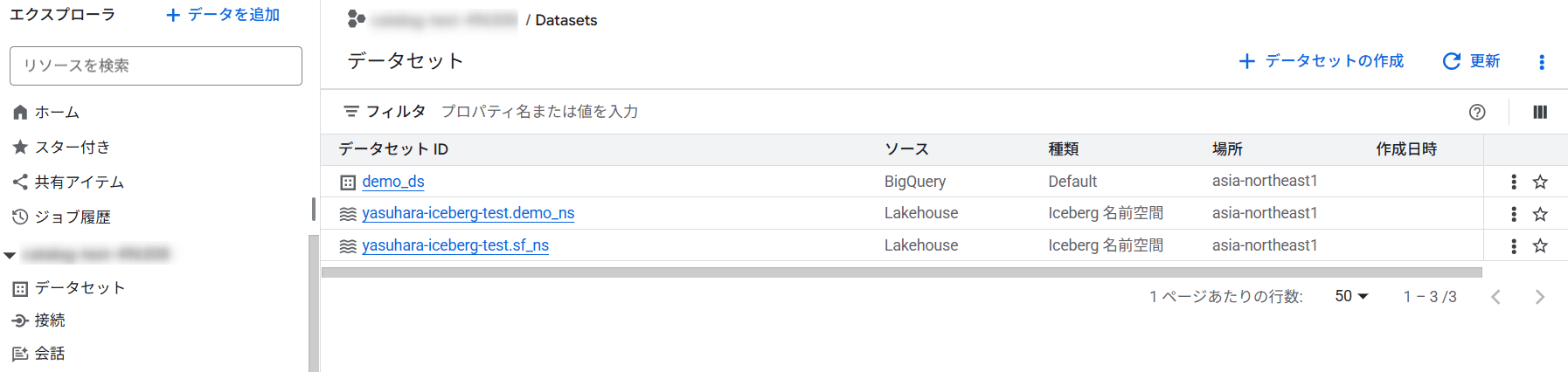
Lakehouse ランタイム カタログで管理されるテーブルは BigQuery からも参照できます。
BigQuery では、Project.Catalog.Namespace.Tableの階層でクエリします。
$ bq query --use_legacy_sql=false \
"SELECT * FROM \`<プロジェクトID>.<カタログ名>.demo_ns.customers\` ORDER BY id;"
+----+-------+-------------+
| id | name | signup_date |
+----+-------+-------------+
| 1 | Alice | 2026-01-10 |
| 2 | Bob | 2026-02-20 |
| 3 | Carol | 2026-03-05 |
| 4 | Dave | 2026-04-15 |
+----+-------+-------------+
$ bq query --use_legacy_sql=false "SELECT * FROM \`<プロジェクトID>.<カタログ名>.sf_ns.orders\`;"
+----------+--------+
| order_id | amount |
+----------+--------+
| 100 | 1980 |
+----------+--------+
参照できました。
一方で書き込み操作はできません。
$ bq query --use_legacy_sql=false --location=asia-northeast1 \
"INSERT INTO \`<プロジェクトID>.<カタログ名>.demo_ns.customers\` (id, name, signup_date) VALUES (1, '山田 太郎', DATE '2026-06-06');"
BigQuery error in query operation: Error processing job '<プロジェクトID>:bqjob_rc3238af8f9b4ab8_0000019e9c494b0e_1': DML statements are only supported over tables that have data
stored in BigQuery. Unsupported table: <プロジェクトID>.<カタログ名>.demo_ns.customers
この点は以下にも記載があります。
Open source engines have read and write access to these tables, while BigQuery has read-only access.
さいごに
Snowflake から Google Cloud の Lakehouse ランタイム カタログへの Iceberg REST カタログ統合を試してみました。
Workload Identity Federation による接続で、Snowflake から参照・書き込みしつつ、BigQuery からも同じテーブルを参照できます。
こちらの内容がどなたかの参考になれば幸いです。








