Snowflake Quickstartの「Snowflake CortexとStreamlitを使った顧客レビュー分析ダッシュボードの構築」を試してみた
かわばたです。
本ブログはClassmethod SaaSで加速するゲーム開発 Advent Calendar 2025の18日目のブログとなります!
他のブログも合わせてご覧ください。
今回は表題のとおり、Snowflake Quickstartの「Snowflake CortexとStreamlitを使った顧客レビュー分析ダッシュボードの構築」を試していきたいと思います。
また、ゲーム業界でどのような形で利用できそうかユースケースも考えていきます。
【公式ドキュメント】
対象読者
- Snowflake CortexとStreamlitについて興味のある方
行う内容
下記ドキュメントからの引用となります。
- Snowflakeに保存されているDOCXファイルからコンテンツを抽出して解析する方法
- Snowflake Cortexによるドキュメント解析を通じて非構造化データを構造化形式に再構成する方法
- Snowflake Cortexをテキスト翻訳、要約、感情分析に適用する方法
- StreamlitとAltairを使ってインタラクティブな視覚化を作成する方法
- ビジネスインサイトのための感情分析結果を解釈する方法
検証環境と事前準備
検証環境
- Snowflake トライアルアカウント Enterprise版
事前準備
【setup.sql格納先】
データベース、スキーマ、ステージを作成していきます。
今回は検証目的なのでACCOUNTADMINの権限で試していきます。
-- データベース&スキーマの作成
CREATE DATABASE IF NOT EXISTS avalanche_db;
CREATE SCHEMA IF NOT EXISTS avalanche_schema;
-- ステージの作成
CREATE STAGE IF NOT EXISTS avalanche_db.avalanche_schema.customer_reviews
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE')
DIRECTORY = (ENABLE = true);
サンプルデータのアップロード
架空のウィンタースポーツ用品会社に関する顧客レビューで構成されるAvalancheの顧客レビューデータをダウンロードし、作成したステージにアップロードします。
【サンプルデータ格納先】
下記のような形で、.docxファイルが100件格納されました。
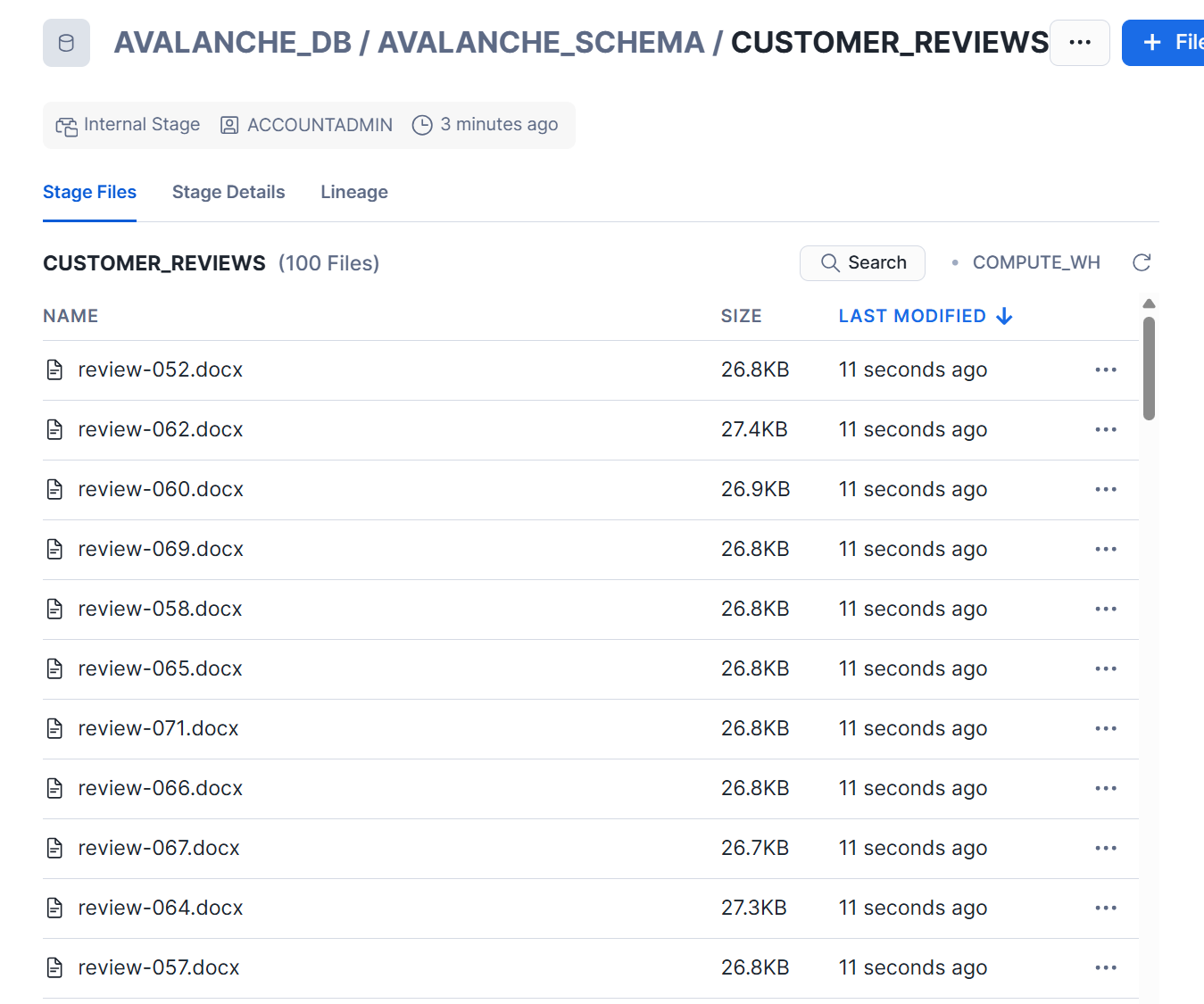
SQLコマンドでステージ配下を確認してみます。
ls @avalanche_db.avalanche_schema.customer_reviews;
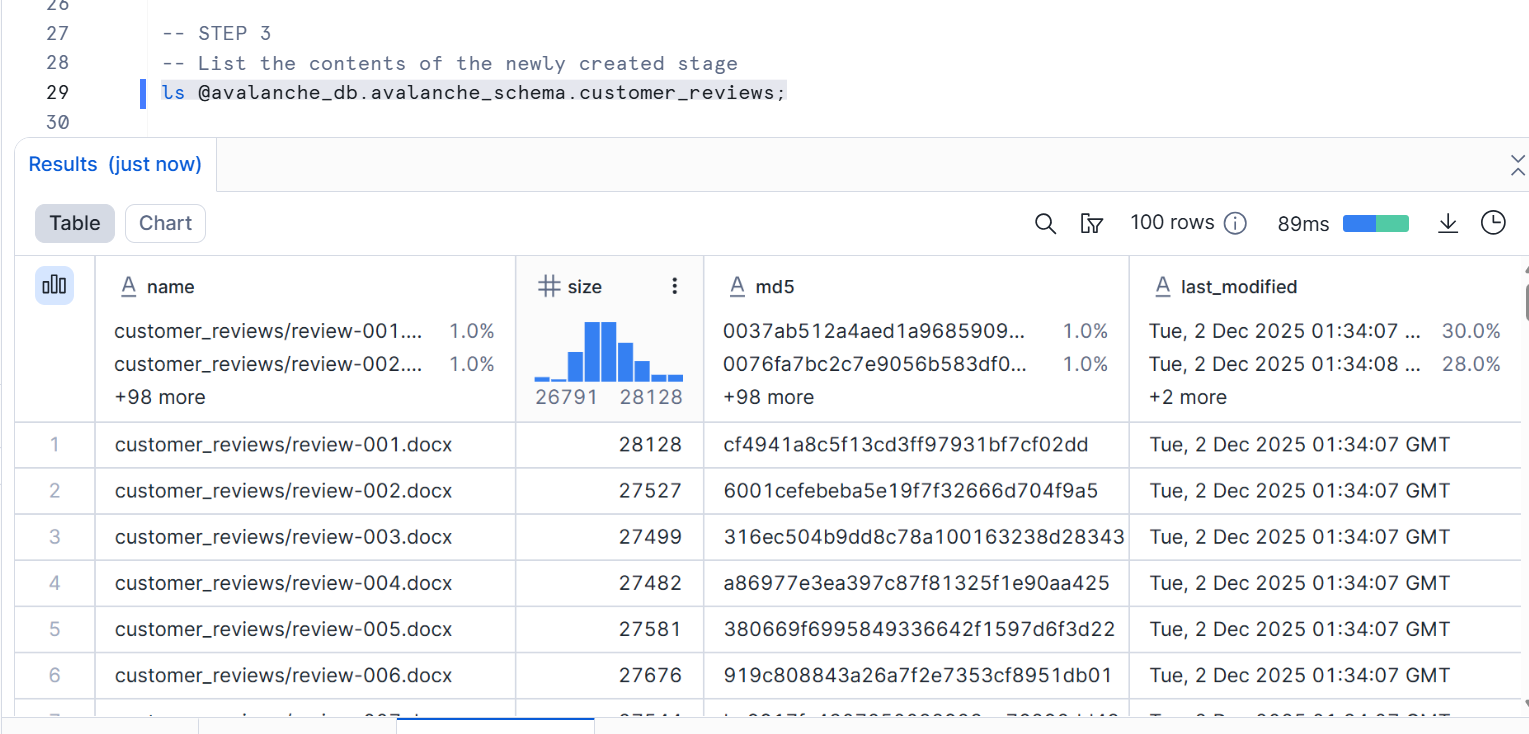
問題なく格納できていますね。
ちなみに、.docxファイルは下記のような形で顧客レビューデータとなります。

Notebookのダウンロード
GitHubからNotebookをダウンロードします。
【格納先】
下記設定でNotebookを作成しました。
顧客レビューデータの取得
DOCXファイルからデータを抽出
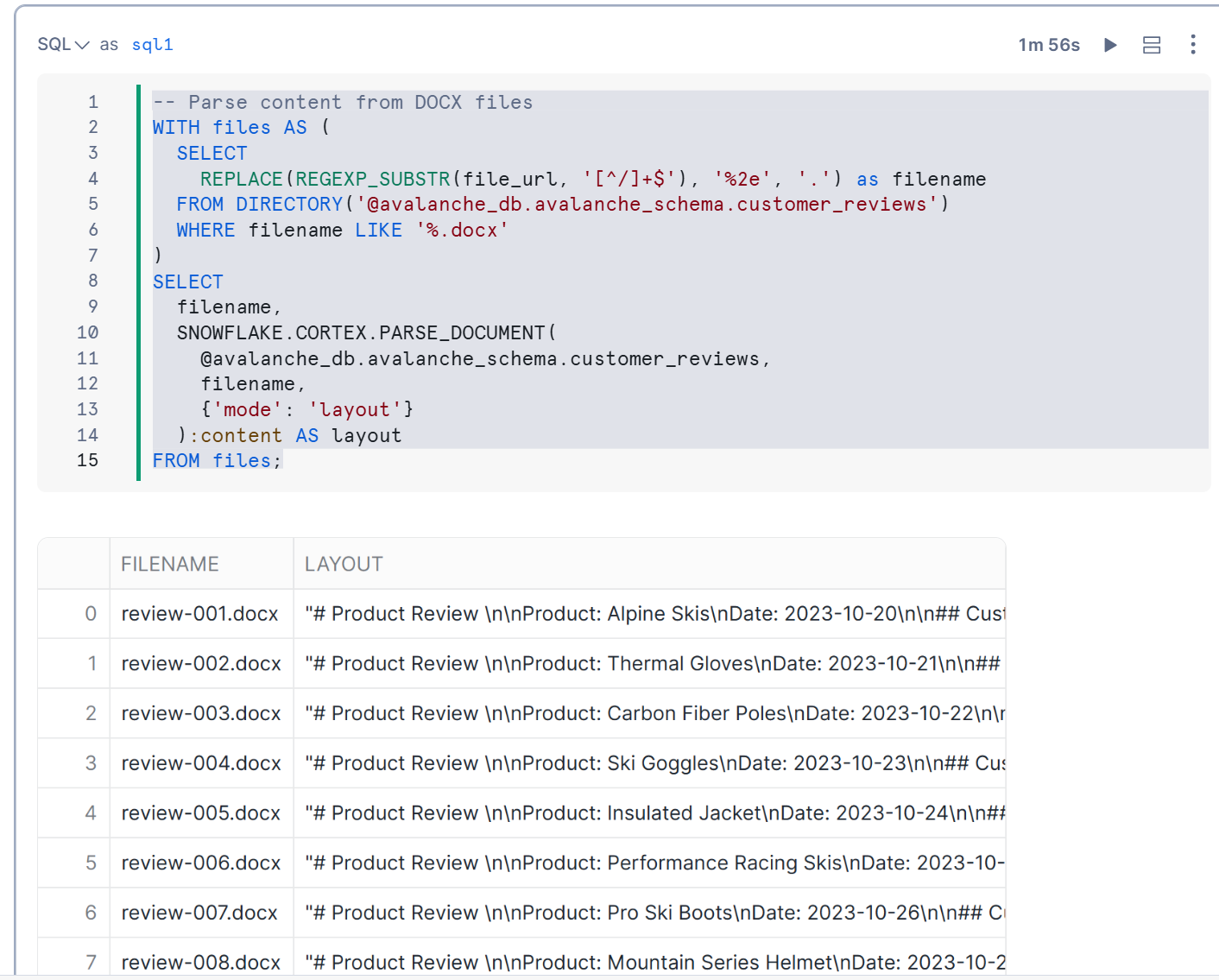
SNOWFLAKE.CORTEX.PARSE_DOCUMENTを使用してファイルからデータを抽出していきます。
DOCX、PDFなど、様々な形式のドキュメントからテキストを抽出するのに特に便利です。「レイアウト」モードではドキュメントの構造が維持されるため、特定のセクションのみを簡単に抽出できます。
【公式ドキュメント】
-- Parse content from DOCX files
WITH files AS (
SELECT
REPLACE(REGEXP_SUBSTR(file_url, '[^/]+$'), '%2e', '.') as filename
FROM DIRECTORY('@avalanche_db.avalanche_schema.customer_reviews')
WHERE filename LIKE '%.docx'
)
SELECT
filename,
SNOWFLAKE.CORTEX.PARSE_DOCUMENT(
@avalanche_db.avalanche_schema.customer_reviews,
filename,
{'mode': 'layout'}
):content AS layout
FROM files;
すると下記のような形でデータを抽出することができました。
データの再構築
抽出されたコンテンツの構造化
データを抽出することができましたが、これではまだデータを活用できない状態です。
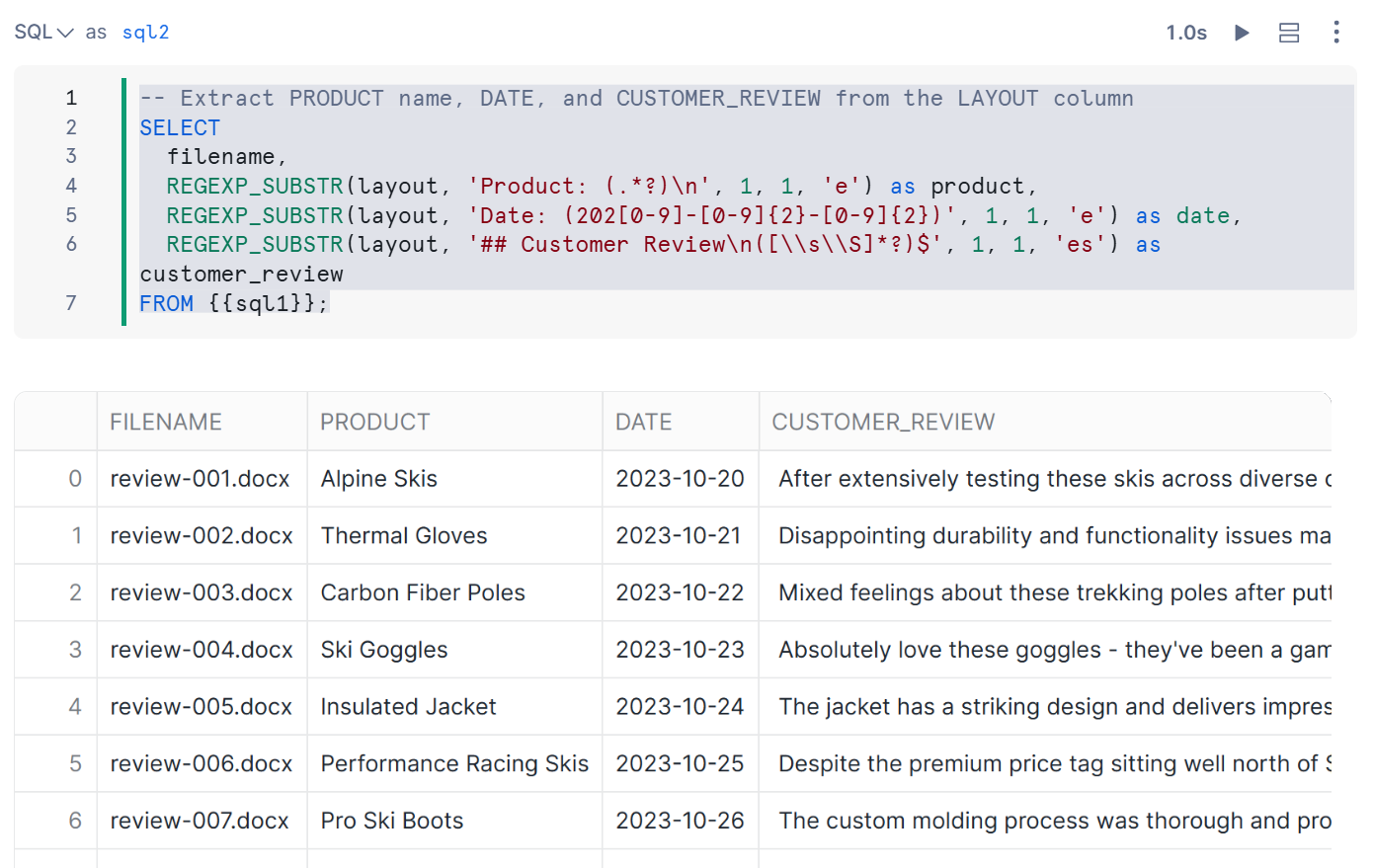
正規表現を使用して、商品名、日付、顧客レビューのテキストなどの特定の情報を抽出していきます。
-- Extract PRODUCT name, DATE, and CUSTOMER_REVIEW from the LAYOUT column
SELECT
filename,
REGEXP_SUBSTR(layout, 'Product: (.*?)\n', 1, 1, 'e') as product,
REGEXP_SUBSTR(layout, 'Date: (202[0-9]-[0-9]{2}-[0-9]{2})', 1, 1, 'e') as date,
REGEXP_SUBSTR(layout, '## Customer Review\n([\\s\\S]*?)$', 1, 1, 'es') as customer_review
FROM {{sql1}};
下記のように出力され、構造化することができました。
CortexでデータにAIを適用する
構造化されたデータに対して、SnowflakeのCortex LLM関数を適用して高度なテキスト分析を実行していきます。
- TRANSLATE (SNOWFLAKE.CORTEX):レビューの文章を指定の言語に変換する
- SUMMARIZE (SNOWFLAKE.CORTEX):レビューの簡潔な要約を作成する
- SENTIMENT (SNOWFLAKE.CORTEX):各レビューの感情を分析する
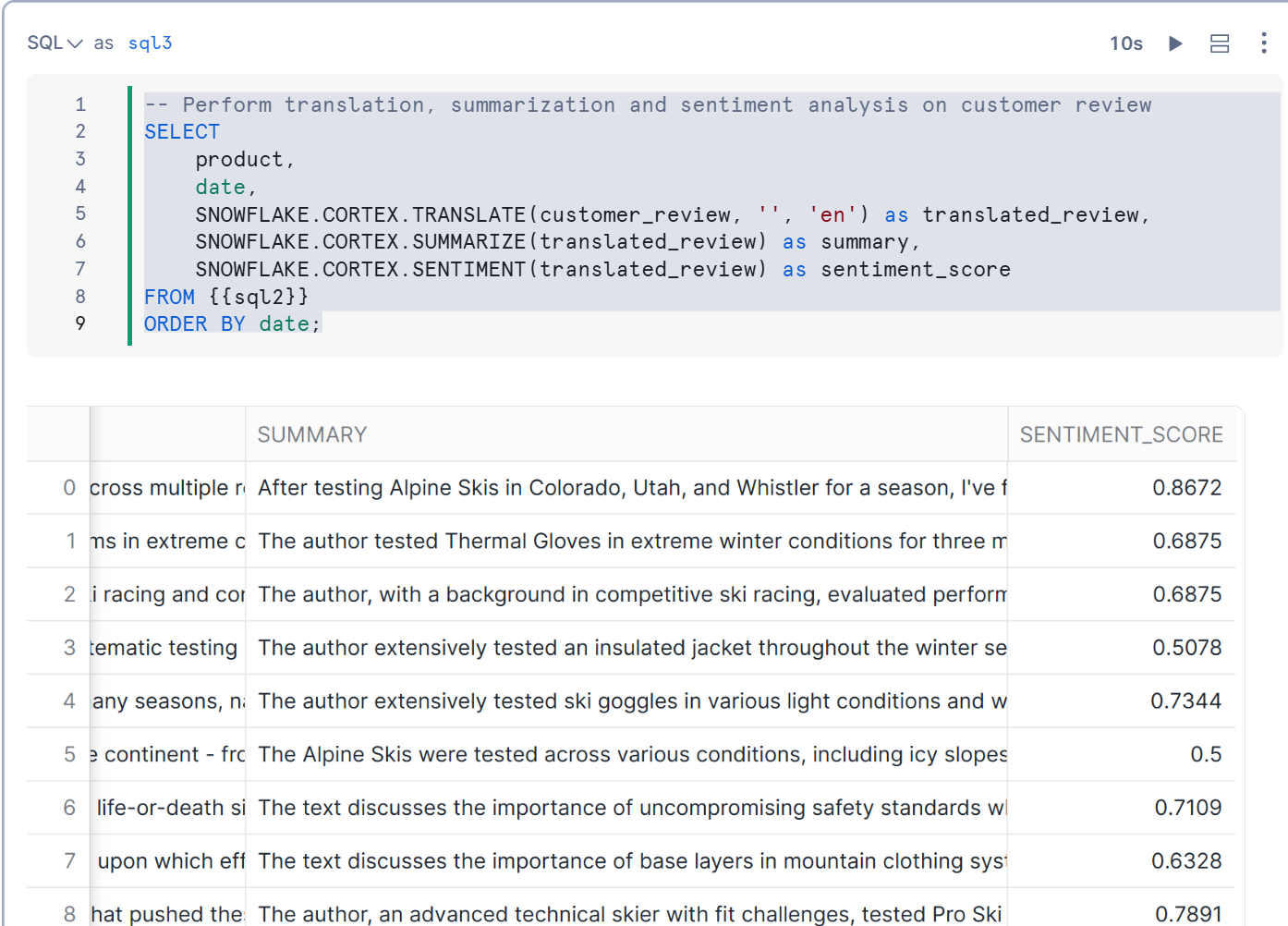
-- Perform translation, summarization and sentiment analysis on customer review
SELECT
product,
date,
SNOWFLAKE.CORTEX.TRANSLATE(customer_review, '', 'en') as translated_review,
SNOWFLAKE.CORTEX.SUMMARIZE(translated_review) as summary,
SNOWFLAKE.CORTEX.SENTIMENT(translated_review) as sentiment_score
FROM {{sql2}}
ORDER BY date;
下記のとおり変換することができました。
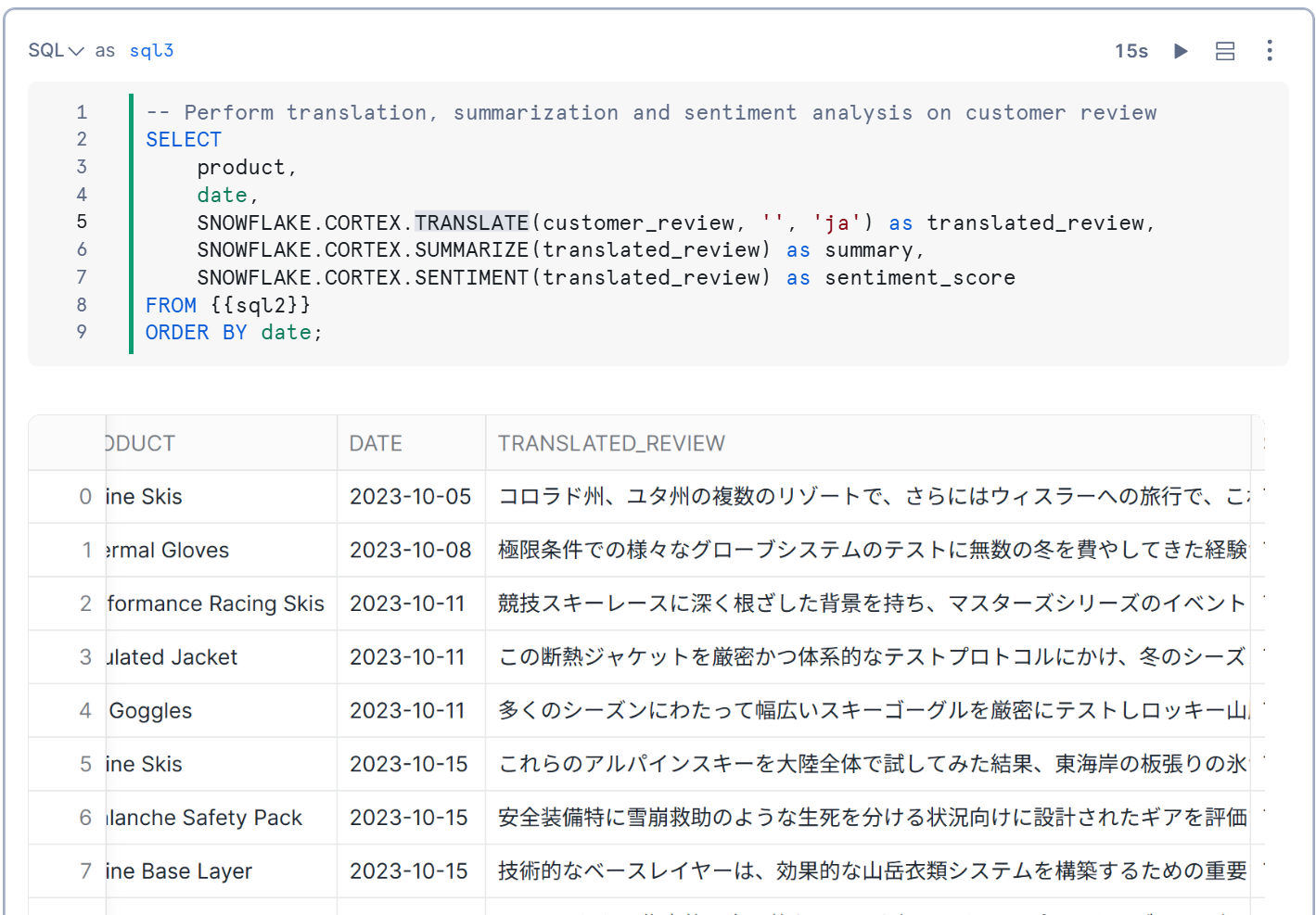
TRANSLATEの引数をjaとすることで日本語にもできます。
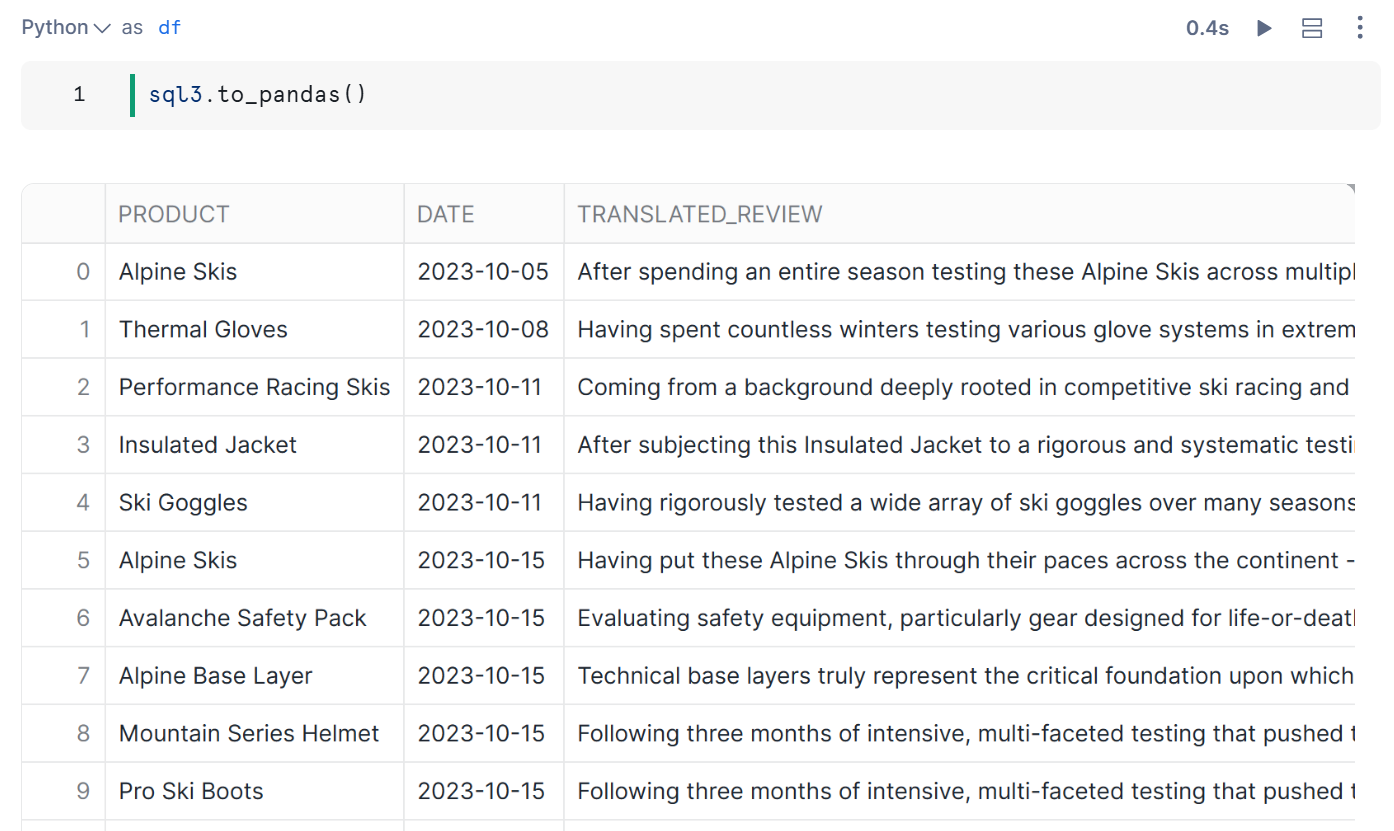
SQLの結果をPandas DataFrameに変換
可視化を行うために、SQLの結果をPandas DataFrameに変換します。
.to_pandas()
Streamlitで可視化
StreamlitとAltairでインタラクティブなチャートを作成する
先ほど作成したPandas DataFrameを用いて、顧客レビューの感情に関する洞察を得るために可視化をしていきます。
センチメントスコアを可視化
import streamlit as st
import altair as alt
import pandas as pd
# SENTIMENT_SCOREを数値型に変換する(確実に数値として扱うため)
df['SENTIMENT_SCORE'] = pd.to_numeric(df['SENTIMENT_SCORE'])
# 棒グラフのベースを作成する
chart = alt.Chart(df).mark_bar(size=15).encode(
x=alt.X('DATE:T',
axis=alt.Axis(
format='%Y-%m-%d', # YYYY-MM-DD形式(例: 2023-01-01)
labelAngle=90) # ラベルを90度回転させる
),
y=alt.Y('SENTIMENT_SCORE:Q'),
color=alt.condition(
alt.datum.SENTIMENT_SCORE >= 0,
alt.value('#2ecc71'), # 正の値(ポジティブ)は緑色
alt.value('#e74c3c') # 負の値(ネガティブ)は赤色
),
tooltip=['PRODUCT:N', 'DATE:T'] # ツールチップ(ホバー時の情報)を追加
).properties(
height=500
)
# チャートを表示する
st.altair_chart(chart, use_container_width=True)
出力結果は下記のとおりです。
ポジティブな感情には緑、ネガティブな感情には赤を使用して表現しています。
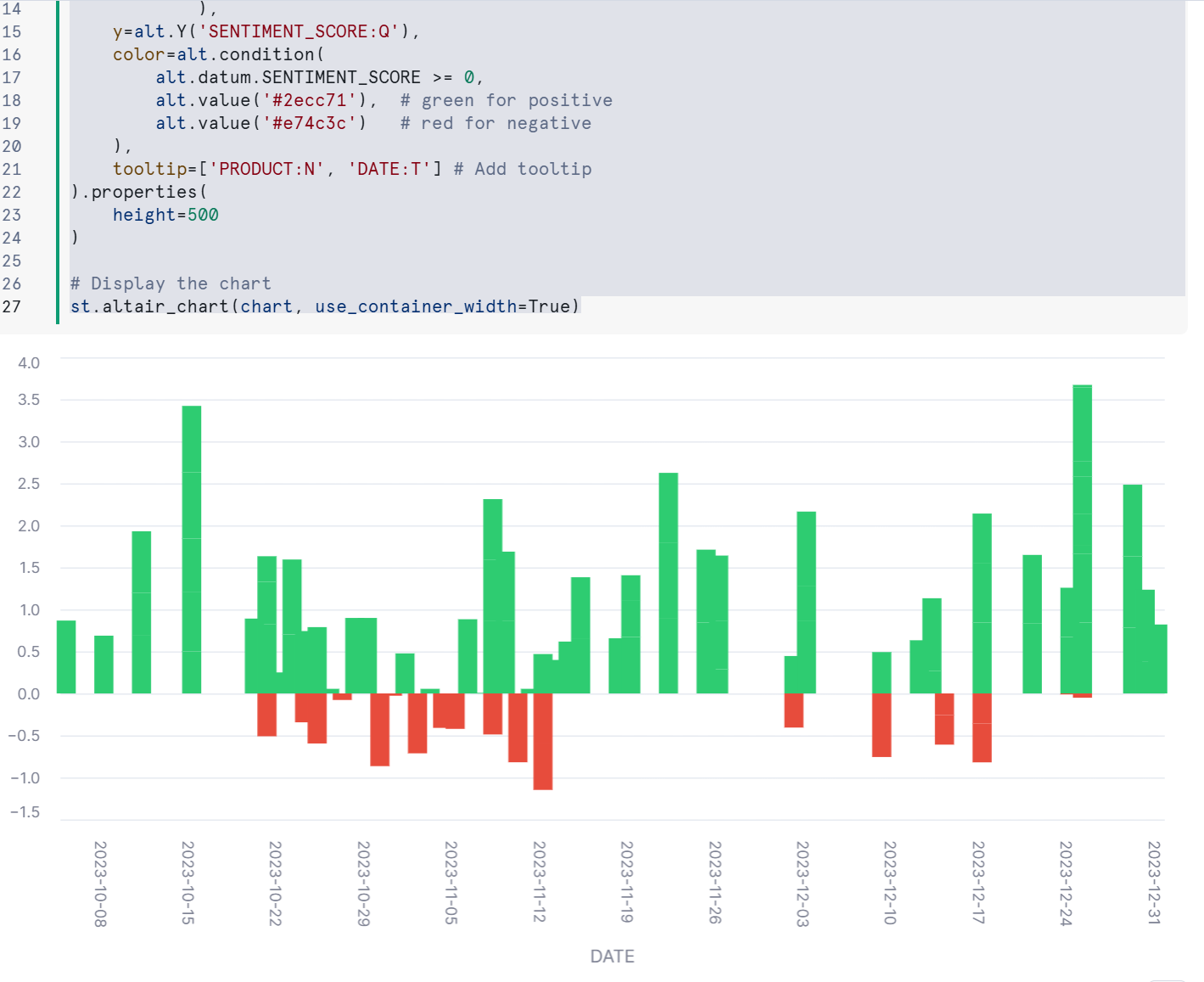
製品センチメントスコアを可視化
import streamlit as st
import altair as alt
import pandas as pd
# PRODUCT(製品)別に集計してベースのチャートを作成する
bars = alt.Chart(df).mark_bar(size=15).encode(
y=alt.Y('PRODUCT:N',
axis=alt.Axis(
labelAngle=0, # ラベルを水平にする
labelOverlap=False, # ラベルの重なりを防ぐ
labelPadding=10 # パディング(余白)を追加する
)
),
x=alt.X('mean(SENTIMENT_SCORE):Q', # SENTIMENT_SCOREの平均値を集計する
title='MEAN SENTIMENT_SCORE'),
color=alt.condition(
alt.datum.mean_SENTIMENT_SCORE >= 0,
alt.value('#2ecc71'), # 正の値(ポジティブ)は緑色
alt.value('#e74c3c') # 負の値(ネガティブ)は赤色
),
tooltip=['PRODUCT:N', 'mean(SENTIMENT_SCORE):Q']
).properties(
height=400
)
# チャートを表示する
st.altair_chart(bars, use_container_width=True)
出力結果は下記のとおりです。
各商品の平均感情スコアを表示しています。
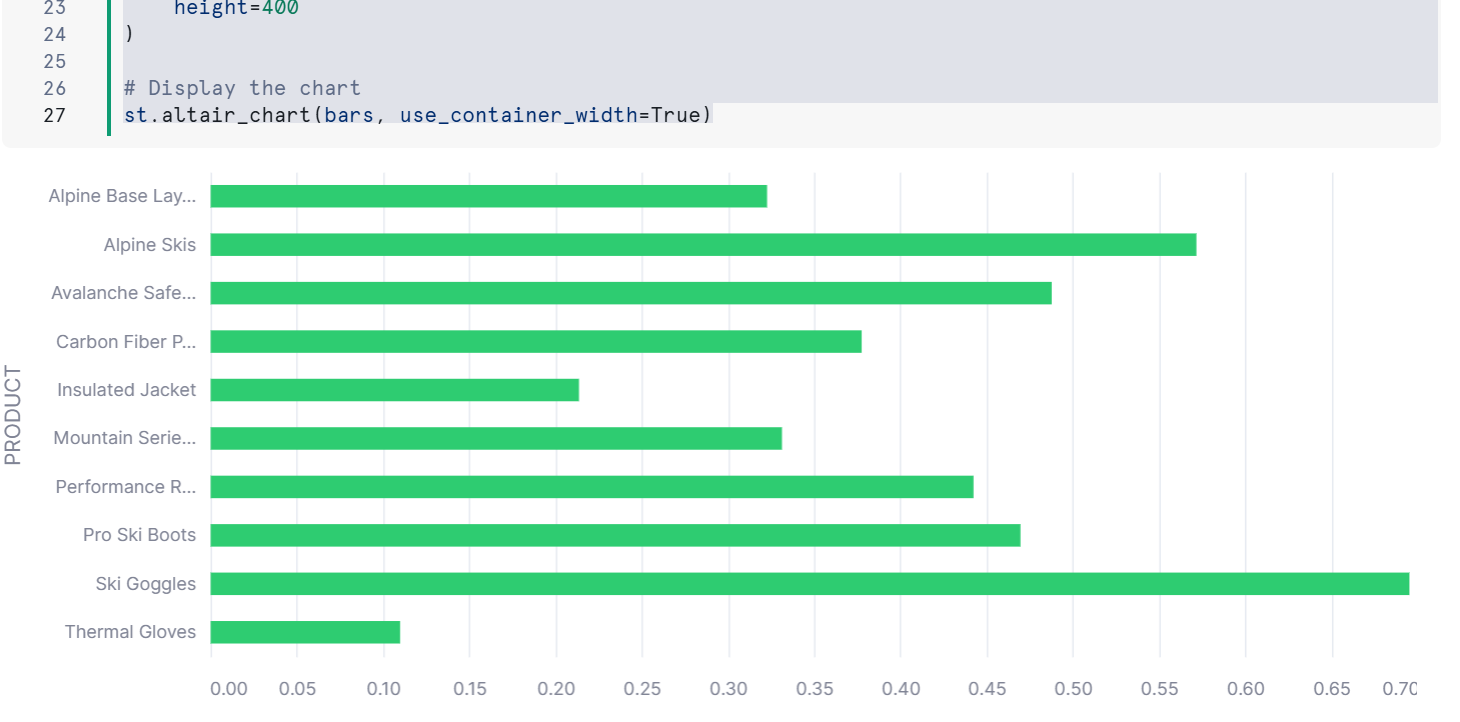
ダウンロードボタン
ユーザーが処理済みのデータをエクスポートするためのダウンロードボタンを追加します。
# Download button for the CSV file
st.subheader('Processed Customer Reviews Data')
st.download_button(
label="Download CSV",
data=df[['PRODUCT', 'DATE', 'SUMMARY', 'SENTIMENT_SCORE']].to_csv(index=False).encode('utf-8'),
mime="text/csv"
)
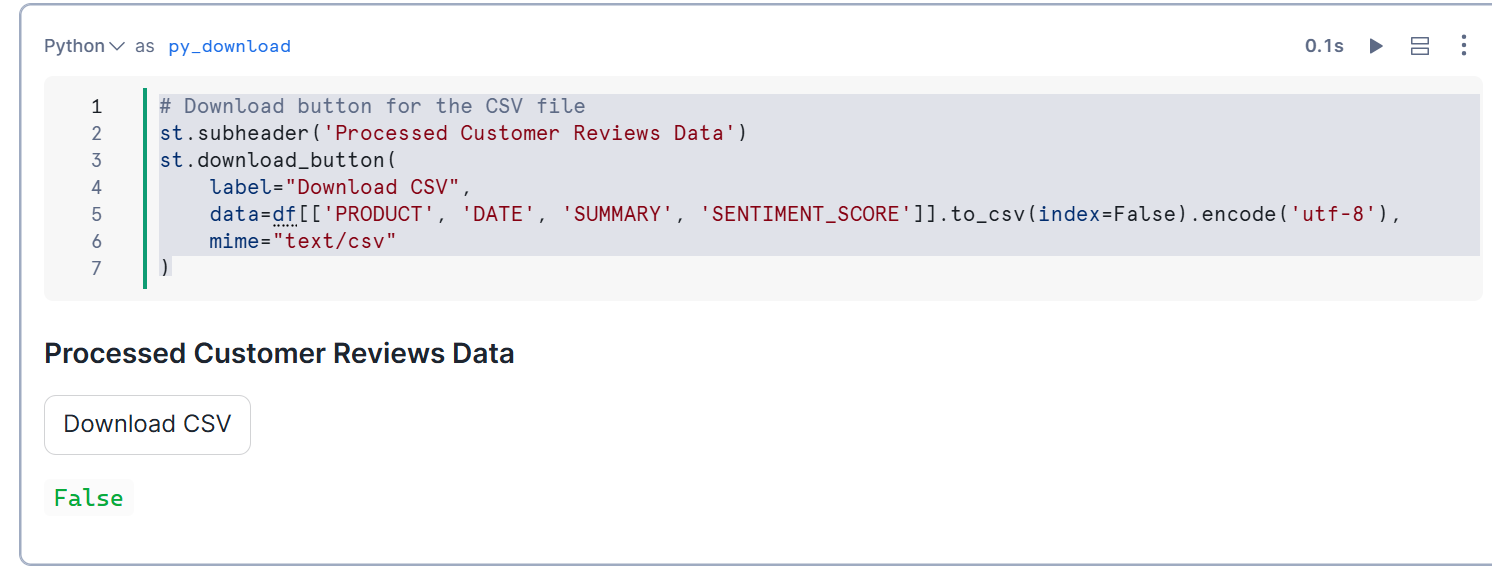
ダウンロードしたCSVは下記のような形で出力されます。
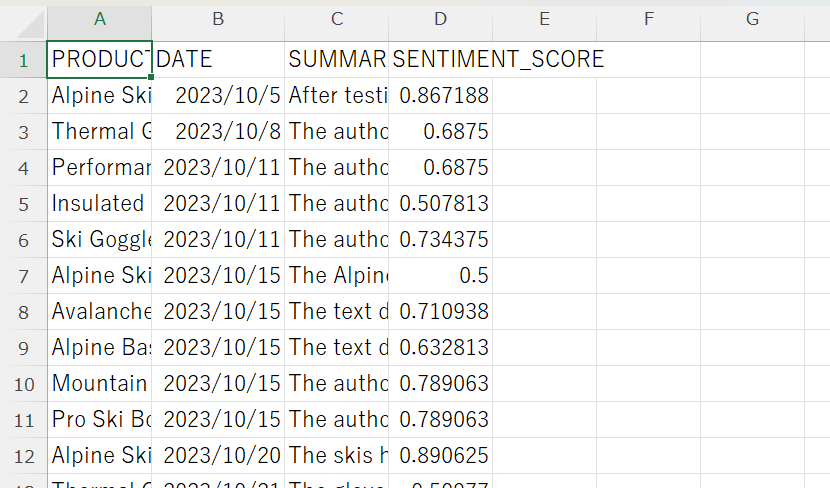
ゲームのレビューについて感情分析してみる
使用するデータ
KaggleのSteam Games, Reviews, and Rankings.のデータを使用していきます。
データ容量が大きかったため、分割処理をローカル環境で行っています。
import pandas as pd
# 正しいファイルパスを指定します
input_file = '指定のファイルパス'
# 分割する行数
chunk_size = 100000
# ファイルを分割して保存
for i, chunk in enumerate(pd.read_csv(input_file, chunksize=chunk_size)):
chunk.to_csv(f'output_{i+1}.csv', index=False)
print("ファイルの分割が完了しました。")
分割したファイルをステージに格納しました。
レビューデータをバルクロード
スキーマおよびテーブルを作成しデータをバルクロードしていきます。
-- スキーマの作成
CREATE SCHEMA IF NOT EXISTS steam_schema;
-- テーブルの作成
CREATE OR REPLACE TABLE steam_reviews (
review TEXT,
hours_played VARCHAR(16777216),
helpful VARCHAR(16777216),
funny VARCHAR(16777216),
recommendation VARCHAR(16777216),
review_date VARCHAR(16777216),
game_name VARCHAR(16777216),
username VARCHAR(16777216)
);
-- バルクロード
COPY INTO steam_reviews
FROM (
SELECT
$1, -- review
$2, -- hours_played
$3, -- helpful
$4, -- funny
$5, -- recommendation
$6, -- review_date
$7, -- game_name
$8 -- username
FROM @avalanche_db.avalanche_schema.steam_reviews -- ご自身のステージ名に置き換えてください
)
FILE_FORMAT = (
TYPE = 'CSV',
SKIP_HEADER = 1,
FIELD_DELIMITER = ',',
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
);
CortexでデータにAIを適用する
reviewカラムに対して、センチメントスコアをSNOWFLAKE.CORTEX.SENTIMENT関数を使用して出力します。
-- Perform translation, summarization and sentiment analysis on customer review
SELECT
game_name,
review_date,
SNOWFLAKE.CORTEX.SUMMARIZE(review) as summary,
SNOWFLAKE.CORTEX.SENTIMENT(review) as sentiment_score
FROM AVALANCHE_DB.STEAM_SCHEMA.STEAM_REVIEWS
ORDER BY review_date
LIMIT 1000; -- 100万レコードすべて回すと時間がかかりすぎるため1000行
Pandas DataFrameに変換
sql4.to_pandas()
Streamlitで可視化してみた
import streamlit as st
import pandas as pd
import plotly.express as px
# game_nameごとにSENTIMENT_SCOREの平均値を計算
# SENTIMENT_SCOREが数値でない場合を考慮し、エラーはNaNに変換
df2['SENTIMENT_SCORE'] = pd.to_numeric(df2['SENTIMENT_SCORE'], errors='coerce')
# NaN値を除外して平均を計算
sentiment_by_game = df2.groupby('GAME_NAME')['SENTIMENT_SCORE'].mean().sort_values(ascending=False)
# --- Streamlit アプリケーション ---
st.title('ゲームのセンチメントスコア分析ダッシュボード')
st.write("アップロードされたデータセットを用いて、ゲームごとのセンチメントスコアを多角的に可視化します。")
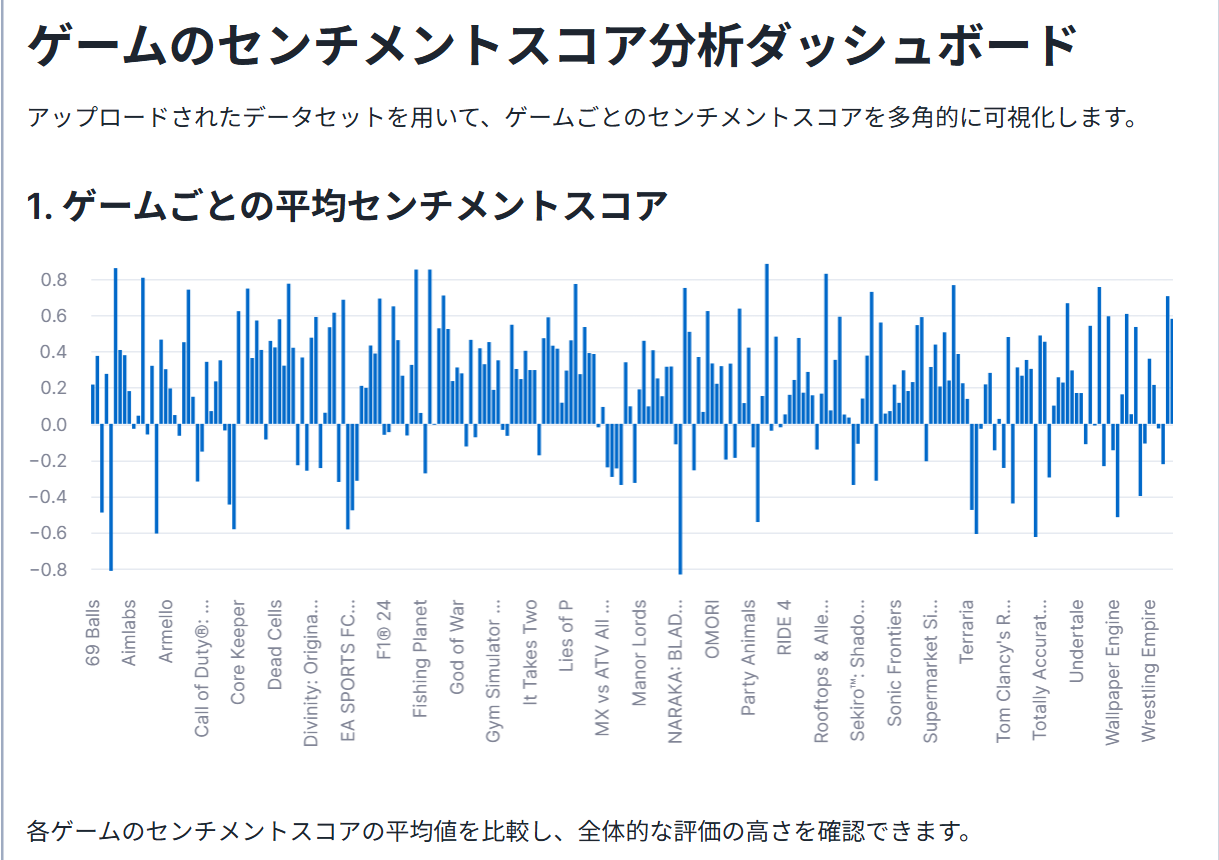
# --- 1. ゲームごとの平均センチメントスコア(棒グラフ)---
st.header('1. ゲームごとの平均センチメントスコア')
sentiment_by_game_mean = df2.groupby('GAME_NAME')['SENTIMENT_SCORE'].mean().sort_values(ascending=False)
st.bar_chart(sentiment_by_game_mean)
st.write("各ゲームのセンチメントスコアの平均値を比較し、全体的な評価の高さを確認できます。")
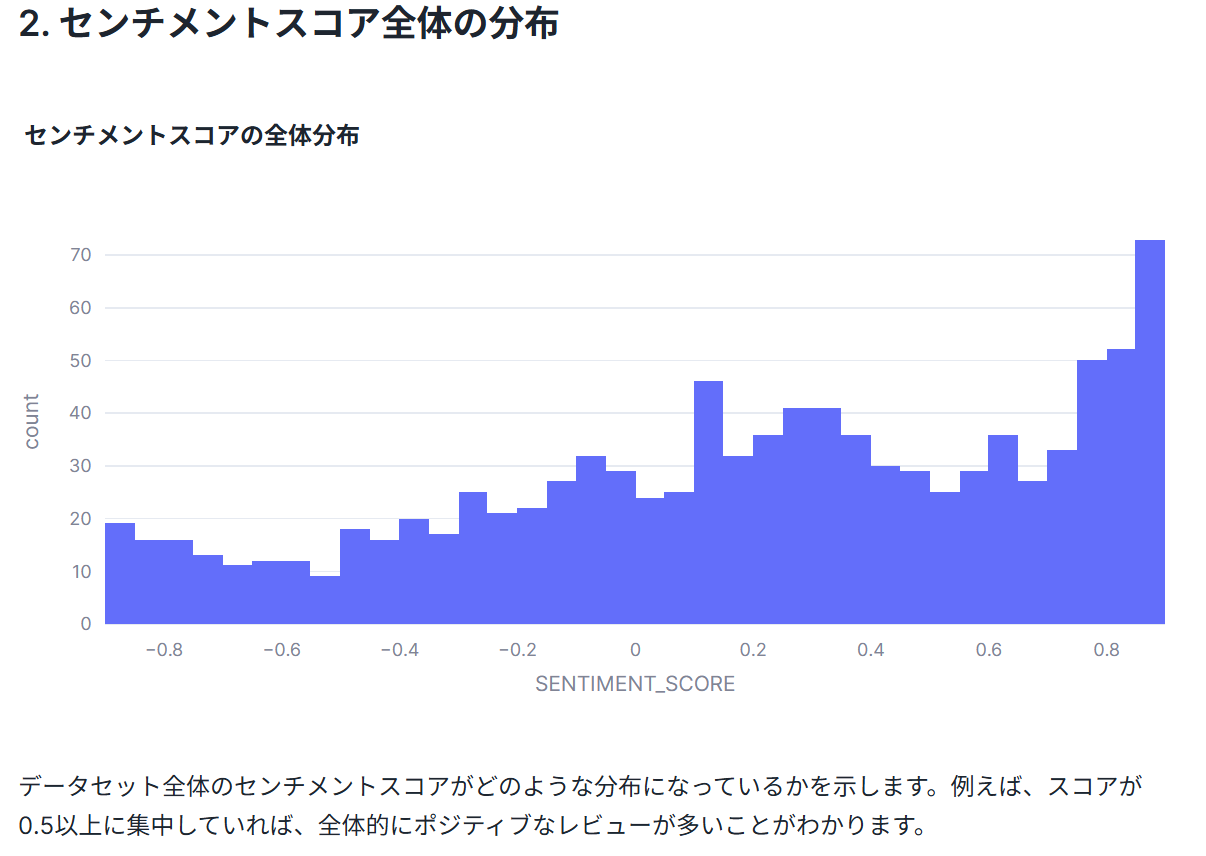
# --- 2. センチメントスコア全体の分布(ヒストグラム)---
st.header('2. センチメントスコア全体の分布')
fig_hist = px.histogram(df2, x='SENTIMENT_SCORE', nbins=50, title='センチメントスコアの全体分布')
st.plotly_chart(fig_hist)
st.write("データセット全体のセンチメントスコアがどのような分布になっているかを示します。例えば、スコアが0.5以上に集中していれば、全体的にポジティブなレビューが多いことがわかります。")
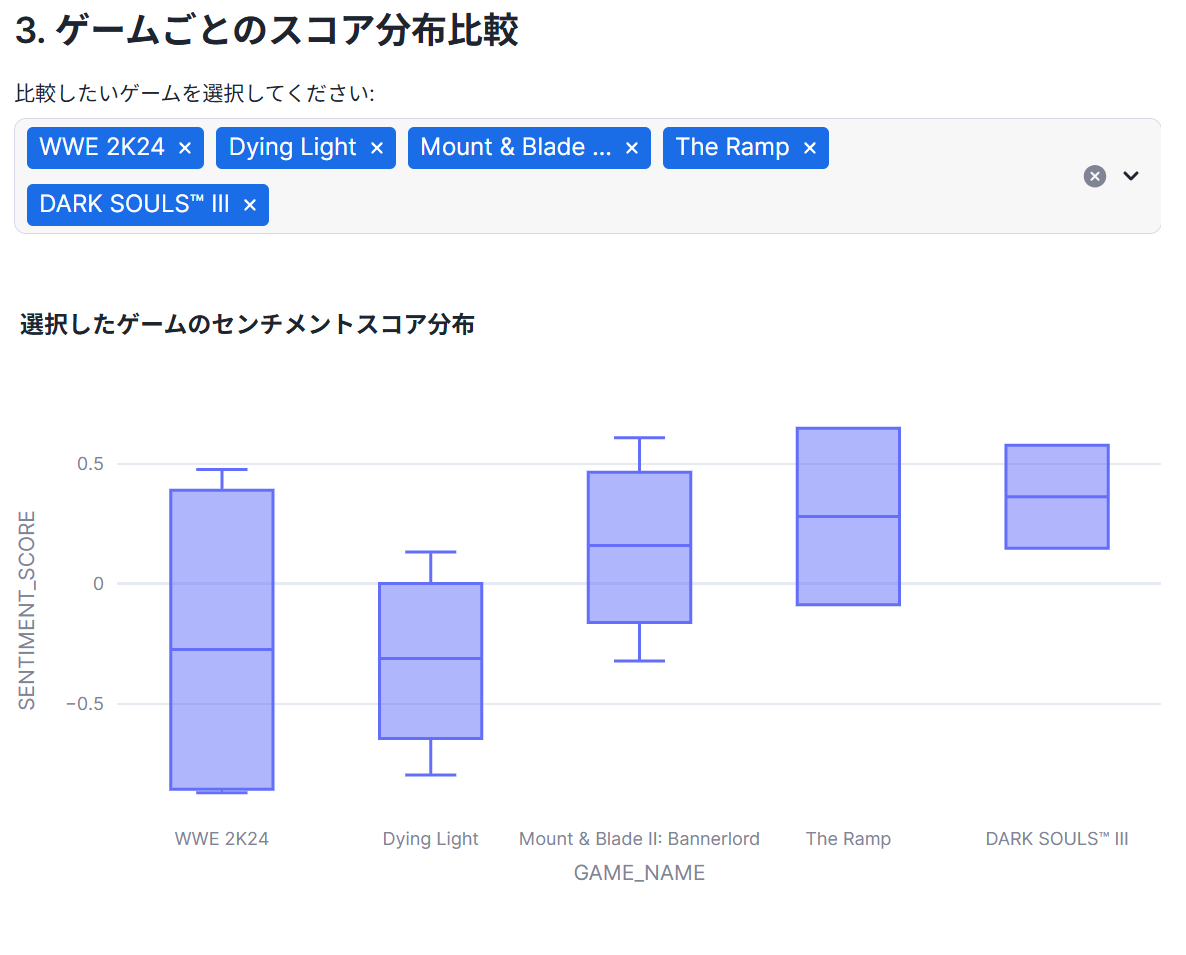
# --- 3. ゲームごとのスコア分布比較(箱ひげ図)---
st.header('3. ゲームごとのスコア分布比較')
# 表示するゲームをユーザーが選択できるようにする
all_games = df2['GAME_NAME'].unique()
selected_games = st.multiselect('比較したいゲームを選択してください:', options=all_games, default=list(all_games[:5]))
if selected_games:
filtered_df2 = df2[df2['GAME_NAME'].isin(selected_games)]
fig_box = px.box(filtered_df2, x='GAME_NAME', y='SENTIMENT_SCORE', title='選択したゲームのセンチメントスコア分布')
st.plotly_chart(fig_box)
st.write("""
箱ひげ図は、スコアのばらつきを視覚的に理解するのに役立ちます。
- **箱の高さ**: スコアの集中度合い(箱が低いほど評価が安定)。
- **箱の中の線**: 中央値。
- **ひげの長さ**: スコアの範囲。
- **点(外れ値)**: 他の多くの評価から大きく外れたスコア。
これにより、「平均は高いが賛否両論あるゲーム」や「平均はそこそこだが安定して高評価のゲーム」といった特徴が見えてきます。
""")
else:
st.warning('比較するゲームを1つ以上選択してください。')
st.write("---")
st.write("### 元データ")
st.dataframe(df2)
まとめ
レビューなどの結果に対して、AIが自動でポジティブかネガティブかを判断しスコア化してくれるのは良いですね。
AIを使用しないでやろうとするとかなり大変ですが、これならクエリを数行書けばスコア化してくれて非常に楽です。
レビューやコールセンターの録音データ文字起こしなど幅広く活用できそうです。
コストと実行時間が多少かかるので、すべてのデータというよりはアドホック的分析するケースに役立つと思います!
最後に
最新の内容をいち早く支援しています
弊社クラスメソッドでは、Snowflake Intelligenceはもちろんdbt Projects on Snowflakeなどの最新機能に関する情報発信を定期的に行っており、これらの最新機能に関する技術支援も可能です。
この記事が何かの参考になれば幸いです!







