Snowflakeのレプリケーショングループで異なるクラウド間のデータベースレプリケーションを試してみた
かわばたです。
Snowflake には、同一組織内の複数アカウント間でデータベースやその他のオブジェクトをレプリケートする機能があります。DR(ディザスタリカバリ)や地理的冗長化、クラウド間でのデータ同期といったユースケースに対応できます。
本記事では、Standard / Enterprise エディションで利用可能なレプリケーショングループを使い、異なるクラウド間でのデータベースレプリケーションを検証します。
概要
背景
企業のデータ基盤では、以下のようなニーズが増えています。
- 障害時にデータを異なるリージョン・異なるクラウドから参照したい(DR対策)
- 地理的に分散したチームが低レイテンシーでデータにアクセスしたい
- マルチクラウド戦略の一環として、異なるクラウドプロバイダー間でデータを同期したい
Snowflake のレプリケーション機能を使えば、これらを Snowflake ネイティブの機能だけ で実現できます。
レプリケーションの基本概念
Snowflake のレプリケーションは、ソースアカウント(プライマリ)のオブジェクトをターゲットアカウント(セカンダリ)に複製する仕組みです。セカンダリに作成されたオブジェクトは読み取り専用のレプリカになります。
レプリケーションの単位として、以下の2つのグループが用意されています。
| グループ | 概要 | エディション |
|---|---|---|
| レプリケーショングループ | オブジェクトをまとめてレプリケート。セカンダリは読み取り専用 | 全エディション(データベース・シェア) |
| フェイルオーバーグループ | レプリケーショングループ + フェイルオーバー/フェイルバック機能。セカンダリをプライマリに昇格可能 | Business Critical 以上 |
エディション別の利用可能機能
| 機能 | Standard | Enterprise | Business Critical |
|---|---|---|---|
| データベース・シェアのレプリケーション | OK | OK | OK |
| レプリケーショングループ | OK | OK | OK |
| アカウントオブジェクト(ロール、ウェアハウス等)のレプリケーション | - | - | OK |
| フェイルオーバーグループ | - | - | OK |
| クライアントリダイレクト | - | - | OK |
本記事では Standard / Enterprise で利用可能なレプリケーショングループによるデータベースレプリケーションを検証します。
レプリケート可能なオブジェクト
データベースをレプリケートすると、主に以下のオブジェクトが含まれます。
※ 網羅的な最新一覧は公式ドキュメントを参照してください。
- パーマネントテーブル、トランジェントテーブル
- ビュー(通常、マテリアライズド、セキュア)
- スキーマ
- ストアドプロシージャ、UDF
- ストリーム、タスク(※ 後述の注意事項あり)
- マスキングポリシー、行アクセスポリシー
- ステージ、パイプ(※ レプリケーショングループ / フェイルオーバーグループで対応。データベースレプリケーション単体では非対応)
ストリーム・タスクに関する注意:
- ストリームのソースオブジェクトがレプリケーション非対応の場合、refresh が失敗する可能性があります。ストリームとそのベースオブジェクトは同一データベース内に含めるか、同一レプリケーショングループに含める必要があります。
- タスクグラフは、所有ロールの条件によりレプリケーションが正常に動作しない場合があります。
- 作成されたものの、一度も
RESUMEもEXECUTE TASKもされていないタスクはレプリケートされません(タスクのバージョンが作成されていないため)。
一方、以下のオブジェクトはレプリケーション非対応です。
- 一時テーブル(Temporary table)
- 外部テーブル
- ハイブリッドテーブル(レプリケーション時にスキップされる)
- イベントテーブル(レプリケーション時にスキップされる)
- シェアから作成されたデータベース
レプリケーションのスケジュール
自動レプリケーションは REPLICATION_SCHEDULE パラメータで制御します。分単位のインターバルまたは Cron 式で指定可能です。
-- インターバル指定(10分ごと)
REPLICATION_SCHEDULE = '10 MINUTE'
-- Cron式(毎時0分にUTCで実行)
REPLICATION_SCHEDULE = 'USING CRON 0 * * * * UTC'
注意: レプリケーションは非同期で行われます。次回の refresh は前回 refresh の開始時刻と設定間隔(または cron 式)に基づいてスケジュールされます。前回の refresh が継続中の場合、次回 refresh はその完了後に遅延して開始されるため、実際のレプリケーションラグは refresh の所要時間に応じて増加する可能性があります。
検証環境
| 項目 | ソースアカウント | ターゲットアカウント |
|---|---|---|
| クラウド | AWS | Azure |
| リージョン | AWS_AP_NORTHEAST_1 | Azure_japaneast |
| エディション | Enterprise | Enterprise |
| ロール | ACCOUNTADMIN | ACCOUNTADMIN |
| データベース | REPLICATION_TEST_DB | (レプリケーションで作成) |
レプリケーションの基本動作検証(SQL)
レプリケーションの有効化
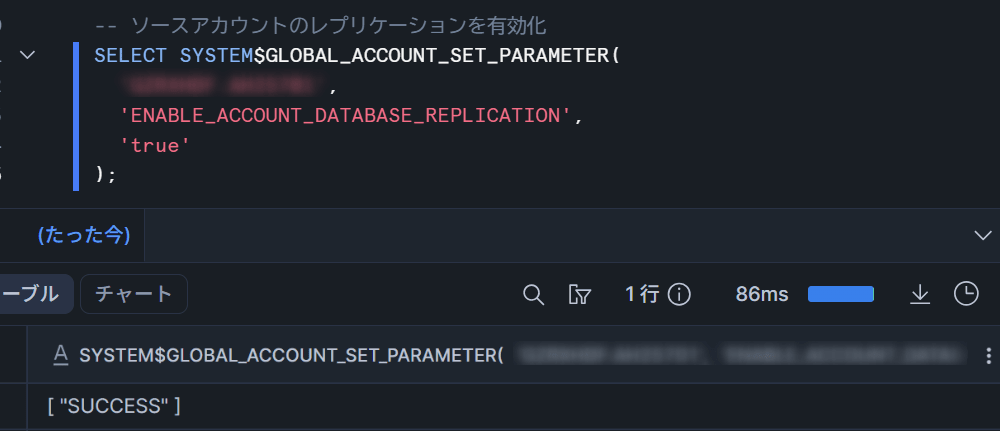
まず、組織管理者(ORGADMIN)がソースアカウントとターゲットアカウントの両方でレプリケーションを有効化します。
-- ORGADMIN ロールで実行
USE ROLE ORGADMIN;
-- ソースアカウントのレプリケーションを有効化
SELECT SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER(
'<org_name>.<source_account>',
'ENABLE_ACCOUNT_DATABASE_REPLICATION',
'true'
);
-- ターゲットアカウントのレプリケーションを有効化
SELECT SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER(
'<org_name>.<target_account>',
'ENABLE_ACCOUNT_DATABASE_REPLICATION',
'true'
);
補足: レプリケーションが有効化されているアカウント一覧は
SHOW REPLICATION ACCOUNTSで確認できます。組織内の全アカウントを確認したい場合はSHOW ACCOUNTSを使用します。SHOW REPLICATION ACCOUNTS;
ソースアカウントにテストデータを準備
レプリケーション対象となるデータベースとテストデータを作成します。
-- ソースアカウントで実行
USE ROLE ACCOUNTADMIN;
-- テスト用データベース作成
CREATE OR REPLACE DATABASE REPLICATION_TEST_DB;
-- テスト用テーブル作成
CREATE OR REPLACE TABLE REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS (
ORDER_ID INT,
CUSTOMER_NAME VARCHAR(100),
ORDER_DATE DATE,
AMOUNT DECIMAL(10, 2)
);
-- テストデータ挿入
INSERT INTO REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS VALUES
(1, 'Tanaka', '2026-04-01', 1500.00),
(2, 'Suzuki', '2026-04-02', 2300.00),
(3, 'Yamada', '2026-04-03', 800.00),
(4, 'Sato', '2026-04-04', 4200.00),
(5, 'Ito', '2026-04-05', 1100.00);
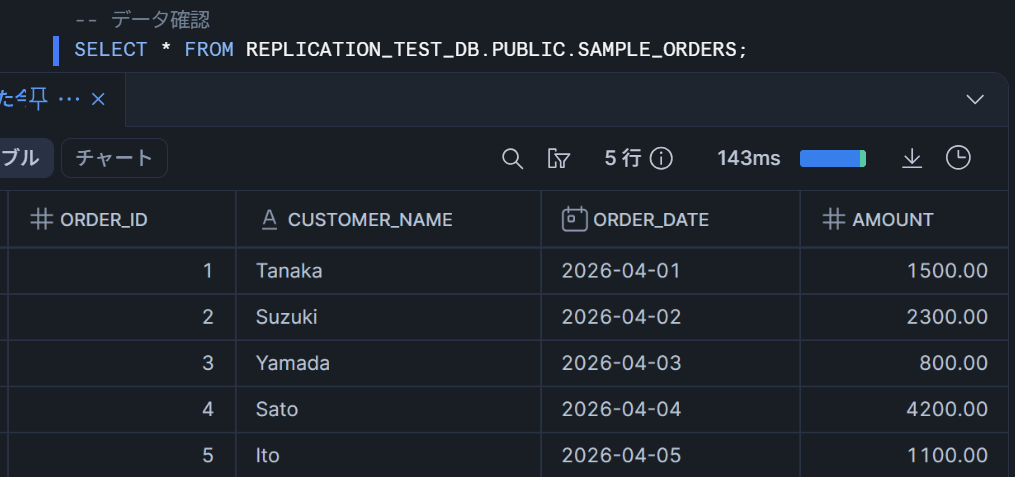
-- データ確認
SELECT * FROM REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS;
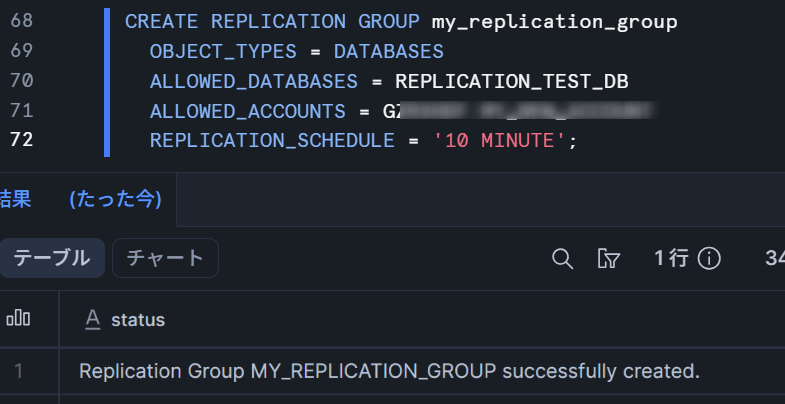
レプリケーショングループの作成(ソースアカウント)
ソースアカウントでレプリケーショングループを作成し、ターゲットアカウントへのレプリケーションを許可します。
-- ソースアカウントで実行
USE ROLE ACCOUNTADMIN;
CREATE REPLICATION GROUP my_replication_group
OBJECT_TYPES = DATABASES
ALLOWED_DATABASES = REPLICATION_TEST_DB
ALLOWED_ACCOUNTS = <org_name>.<target_account>
REPLICATION_SCHEDULE = '10 MINUTE';
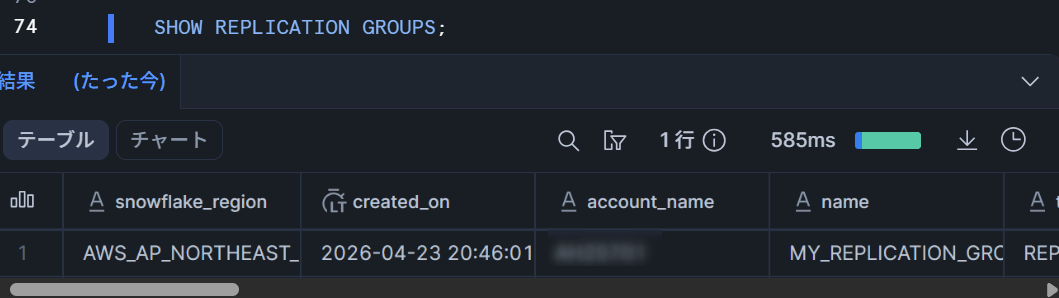
作成したレプリケーショングループの状態を確認します。
SHOW REPLICATION GROUPS;
セカンダリレプリカの作成(ターゲットアカウント)
ターゲットアカウントで、ソースアカウントのレプリケーショングループのレプリカを作成します。
-- ターゲットアカウントで実行
USE ROLE ACCOUNTADMIN;
CREATE REPLICATION GROUP my_replication_group
AS REPLICA OF <org_name>.<source_account>.my_replication_group;
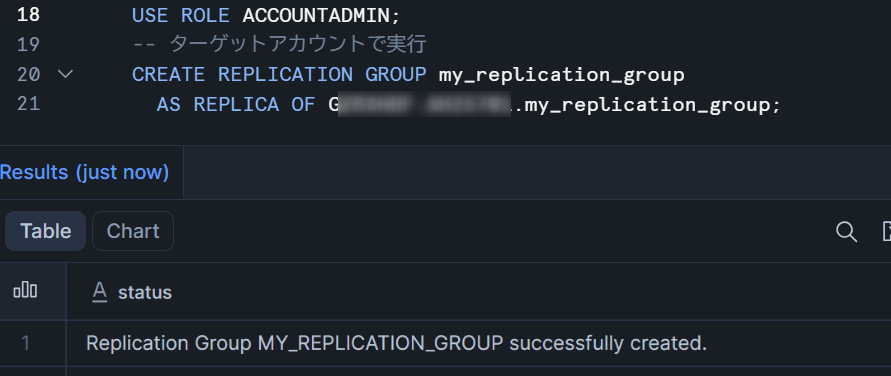
補足: セカンダリレプリケーショングループを作成すると、初回の refresh が自動的に実行されます。以下の検証5では、初回の自動 refresh を待たずに明示的に手動 refresh を実行して確認しています。
手動リフレッシュとデータ確認
自動スケジュールを待たずに、手動でリフレッシュを実行してデータが同期されるか確認します。
-- ターゲットアカウントで実行
-- 手動リフレッシュ
ALTER REPLICATION GROUP my_replication_group REFRESH;
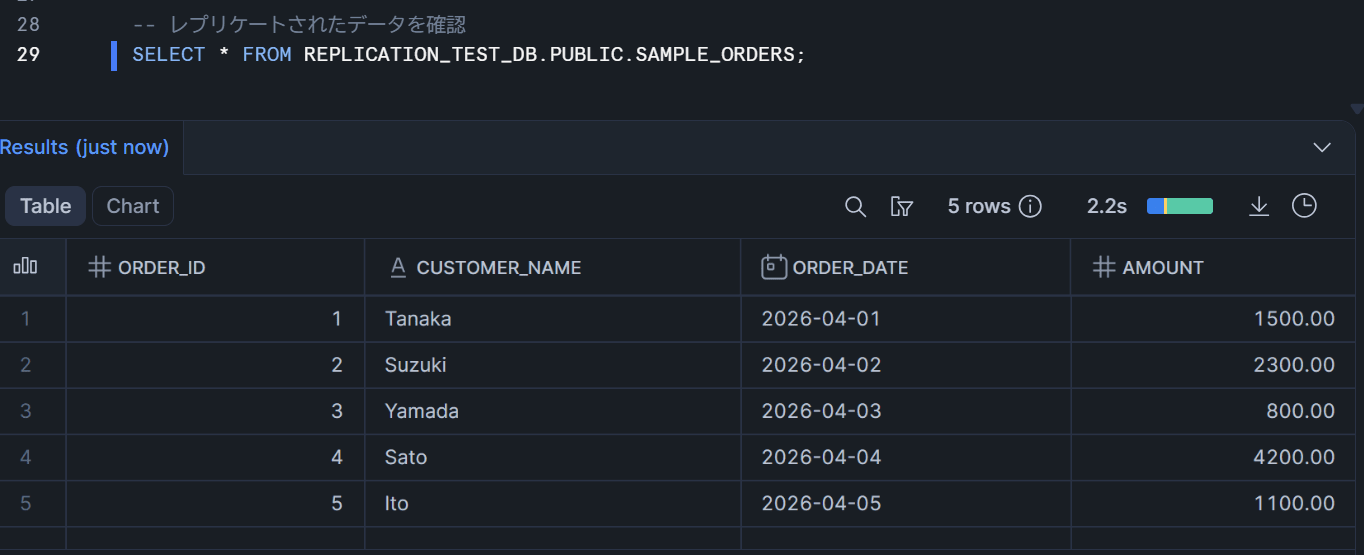
-- レプリケートされたデータを確認
SELECT * FROM REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS;
ソースへのデータ追加後の同期確認
ソースアカウントにデータを追加し、リフレッシュ後にターゲットに反映されるか確認します。
-- ===========================
-- ソースアカウントで実行
-- ===========================
-- 追加データを挿入
INSERT INTO REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS VALUES
(6, 'Watanabe', '2026-04-10', 3500.00),
(7, 'Takahashi', '2026-04-11', 900.00),
(8, 'Kobayashi', '2026-04-12', 6100.00);
-- ソース側の件数確認
SELECT COUNT(*) AS SOURCE_ROW_COUNT FROM REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS;
-- → 8件
-- ===========================
-- ターゲットアカウントで実行
-- ===========================
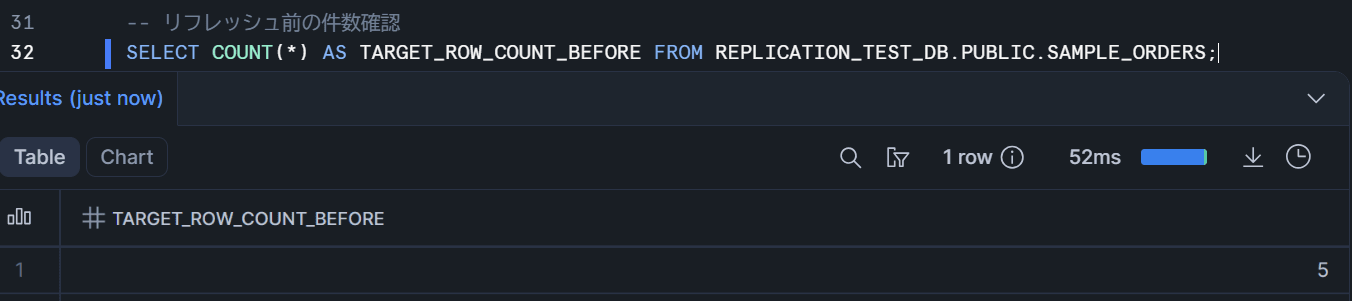
-- リフレッシュ前の件数確認
SELECT COUNT(*) AS TARGET_ROW_COUNT_BEFORE FROM REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS;
-- → 5件(まだ同期されていない)
-- 手動リフレッシュ実行
ALTER REPLICATION GROUP my_replication_group REFRESH;
-- リフレッシュ後の件数確認
SELECT COUNT(*) AS TARGET_ROW_COUNT_AFTER FROM REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS;
-- → 8件(+3件反映)
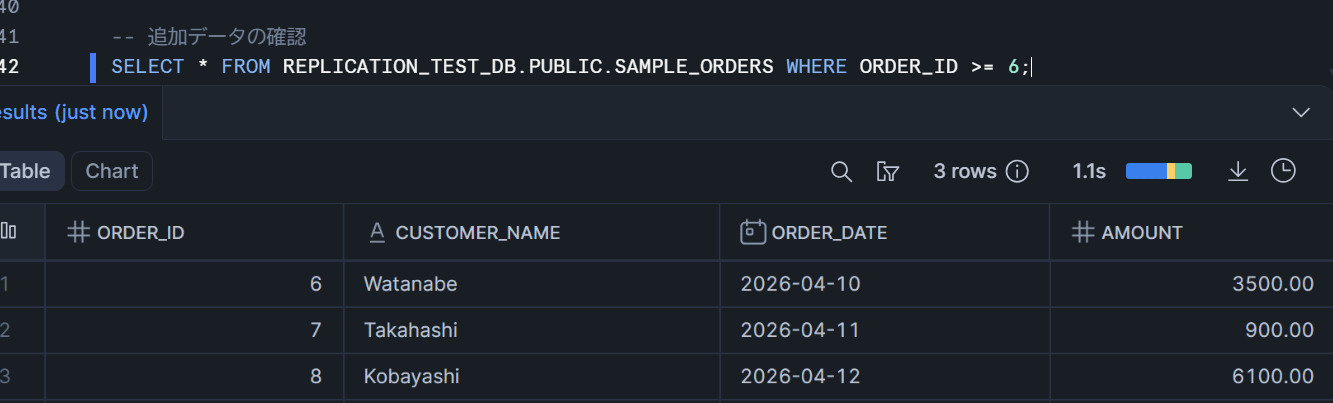
-- 追加データの確認
SELECT * FROM REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS WHERE ORDER_ID >= 6;
セカンダリオブジェクトの読み取り専用確認
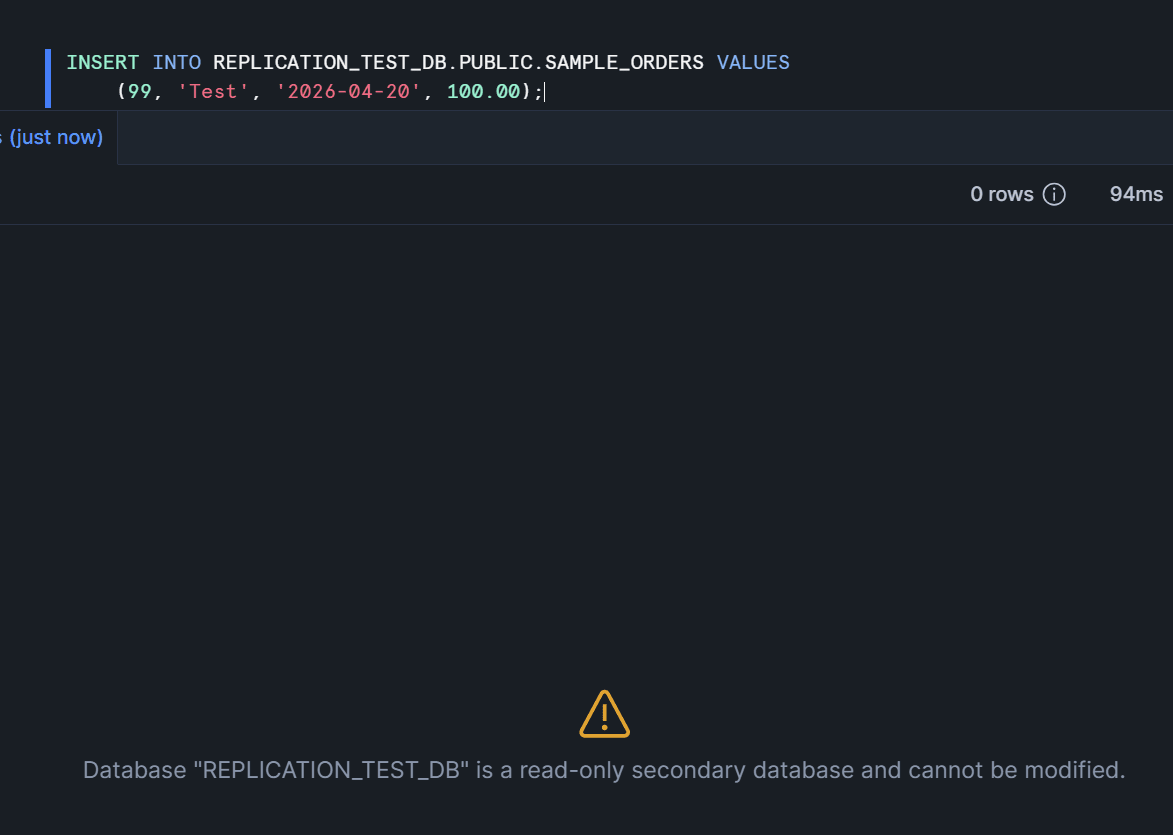
セカンダリ(ターゲット)側のデータベースは読み取り専用です。書き込みを試みてエラーになることを確認します。
-- ターゲットアカウントで実行
-- 書き込みを試みる → エラーになるはず
INSERT INTO REPLICATION_TEST_DB.PUBLIC.SAMPLE_ORDERS VALUES
(99, 'Test', '2026-04-20', 100.00);
レプリケーションの監視
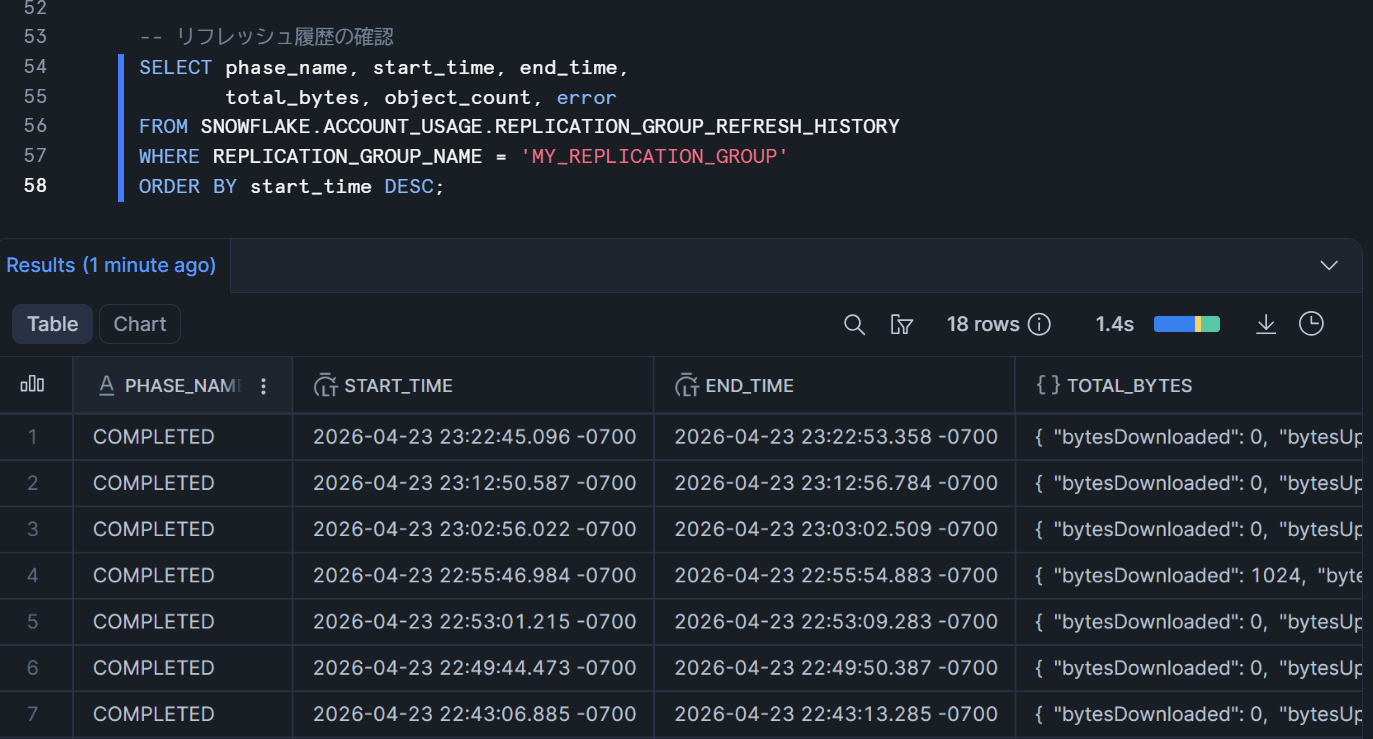
リフレッシュ履歴の確認
-- ターゲットアカウントで実行
SELECT phase_name, start_time, end_time,
total_bytes, object_count, error
FROM SNOWFLAKE.ACCOUNT_USAGE.REPLICATION_GROUP_REFRESH_HISTORY
WHERE REPLICATION_GROUP_NAME = 'MY_REPLICATION_GROUP'
ORDER BY start_time DESC;
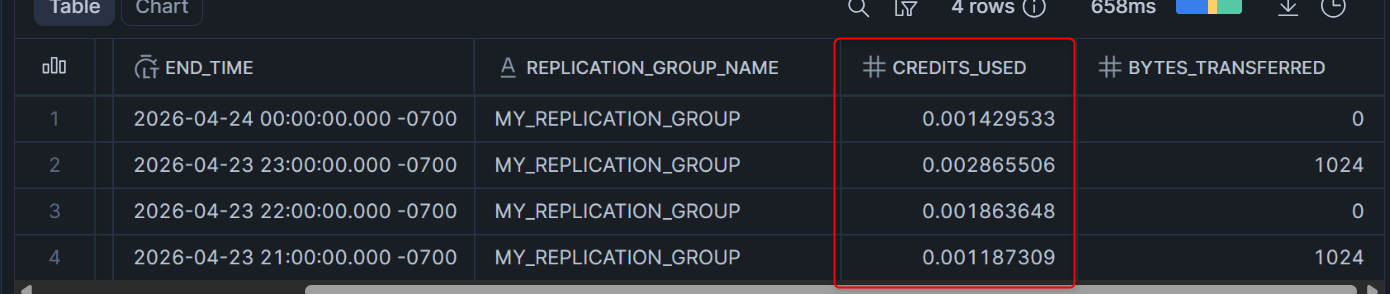
コスト(クレジット使用量)の確認
-- ターゲットアカウントで実行
SELECT START_TIME, END_TIME, REPLICATION_GROUP_NAME, CREDITS_USED, BYTES_TRANSFERRED
FROM TABLE(SNOWFLAKE.INFORMATION_SCHEMA.REPLICATION_GROUP_USAGE_HISTORY(
DATE_RANGE_START => DATEADD('day', -7, CURRENT_DATE())
))
ORDER BY START_TIME DESC;
Snowsightの管理画面Admin > Accounts > Replication > Groups
コストに関する補足
レプリケーションのコストはターゲットアカウントに課金され、以下の2カテゴリで構成されます。
| コスト区分 | 内容 |
|---|---|
| データ転送 | リージョン間・クラウド間のデータ転送料金。クラウドプロバイダーの料金体系に依存 |
| コンピュートリソース | メタデータ・データの差分特定やコピー処理に使用するSnowflake提供のリソース |
コスト管理のポイント:
- レプリケート対象のデータベースを必要最小限に絞る
REPLICATION_SCHEDULEの間隔を業務要件に合わせて最適化する(頻度が高いほどコスト増)- 不要になったレプリケーションは停止する
考慮事項・注意点
| 項目 | 内容 |
|---|---|
| セカンダリは読み取り専用 | レプリカ側ではデータの書き込み・変更はできない |
| 非同期レプリケーション | 前回 refresh が継続中の場合、次回 refresh は完了後に遅延開始されるため、実際のラグは refresh 所要時間に応じて増加する可能性がある |
| タイムトラベル・フェイルセーフ | セカンダリで独立して管理される(ソースからは複製されない) |
| グループメンバーシップ | データベース/シェアは1つのフェイルオーバーグループにのみ所属可能。レプリケーショングループには、各グループのターゲットアカウントが異なる限り複数所属できる。同一オブジェクトをレプリケーショングループとフェイルオーバーグループの両方に所属させることはできない |
| 非対応オブジェクト | 外部テーブル、ハイブリッドテーブル、イベントテーブル等はレプリケーション非対応 |
| フェイルオーバー | Business Critical 以上が必要。Standard / Enterprise ではレプリケーション(読み取り専用レプリカ)のみ |
まとめ
| 検証項目 | 結果 |
|---|---|
| レプリケーション有効化 | ORGADMIN で SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER を実行 |
| レプリケーショングループ作成 | CREATE REPLICATION GROUP でデータベースを指定して作成 |
| セカンダリレプリカ作成 | ターゲットアカウントで AS REPLICA OF で作成 |
| 手動リフレッシュ | ALTER REPLICATION GROUP ... REFRESH で即時同期 |
| データ追加の同期 | ソースへの追加データがリフレッシュ後にターゲットに反映 |
| セカンダリの読み取り専用 | 書き込み試行はエラーとなることを確認 |
| 自動レプリケーション | REPLICATION_SCHEDULE に従い自動同期が動作 |
| 監視 | SQL 関数および Snowsight から進捗・履歴・コストを確認可能 |
Standard / Enterprise エディションでもデータベースのレプリケーションは十分に実用的であり、異なるクラウド間でも問題なく動作することを確認できました。
フェイルオーバー(セカンダリをプライマリに昇格して読み書き可能にする機能)が必要な場合は Business Critical 以上のエディションが必要となるため、DR要件に応じたエディション選択が重要です。
参考
- Replication and failover across accounts
- Introduction to replication and failover across multiple accounts
- Replication configuration
- Replication considerations
- Monitoring replication
- Replication cost
この記事が何かの参考になれば幸いです!








