Azure SQL DatabaseからADF Data Flow Activityを使ってSnowflakeにロードしてみた
かわばたです。
本記事では、Mapping Data Flow の Snowflake Sink を使って Azure SQL Database から Snowflake にロードできること、および Snowflake internal data transfer が利用されることを確認します。
【以前のCopy Activity記事】
背景・課題
ADF で Azure SQL Database から Snowflake にデータをロードする場合、Copy Activity を使う方法が一般的です。Copy Activity でも列マッピングや一部の型変換は可能ですが、以下のような変換・制御を ADF 内で実装したい場合は、Mapping Data Flow Activity が選択肢になります。
- 型変換(日時型の変換など)
- Null 置換
- 条件分岐
- 複数 Source の Join
- Upsert 制御
- データ品質チェック
- 派生列追加
なお、本記事ではまず、Mapping Data Flow の Snowflake Sink を使って Azure SQL Database から Snowflake にロードできること、および Snowflake internal data transfer が利用されることを確認します。
技術的アプローチ
今回構築する構成は以下です。
Azure SQL Database
Table
↓
Azure Data Factory
Mapping Data Flow Activity
↓
Snowflake
Database / Schema / Table
Data Flow では、Azure SQL Database を Source、Snowflake を Sink として設定します。Snowflake コネクタの Mapping Data Flow は Azure Integration Runtime でサポートされており、Self-hosted Integration Runtime ではなく Azure IR 側で実行されます。
今回の重要ポイント
| 項目 | 方針 |
|---|---|
| ADF Activity | Mapping Data Flow Activity |
| Source | Azure SQL Database の Table |
| Sink | Snowflake Table |
| Snowflake 接続 | Snowflake V2 Connector |
| 認証方式 | Key Pair 認証推奨 |
| ステージング | Data Flow 側で Snowflake internal data transfer を利用 |
| IR | Azure Integration Runtime |
制限事項
- Mapping Data Flow は Spark クラスター上で実行されるため、起動コスト(ウォームアップ時間)があります
- Data Flow の Snowflake コネクタは Azure Integration Runtime でのみサポートされています。Self-hosted IR は使用できません
コスト
- Data Flow の実行には Azure Integration Runtime の Data Flow コンピュートコストが発生します
- Snowflake 側ではウェアハウスの実行コストが発生します
前提条件
以下が作成済みであることを前提とします。
Azure 側
- Azure Data Factory: 作成済み
- Azure SQL Database: 次の事前準備セクションで作成します
- ADF から Azure SQL Database に接続可能であること: 必要に応じて ADF Managed Virtual Network / Managed Private Endpoint を構成済み
Azure SQL Database コネクタは Mapping Data Flow の Source/Sink として利用できます。Source では Table 指定または Query 指定が可能です。
Snowflake 側
- Snowflake Account
- ADF 接続用 User / Role
- Key Pair 認証用の公開鍵・秘密鍵
- Load 先の Database / Schema / Warehouse / Table
事前準備
Azure SQL Database の作成
SQL Database の作成
- Azure Portal で
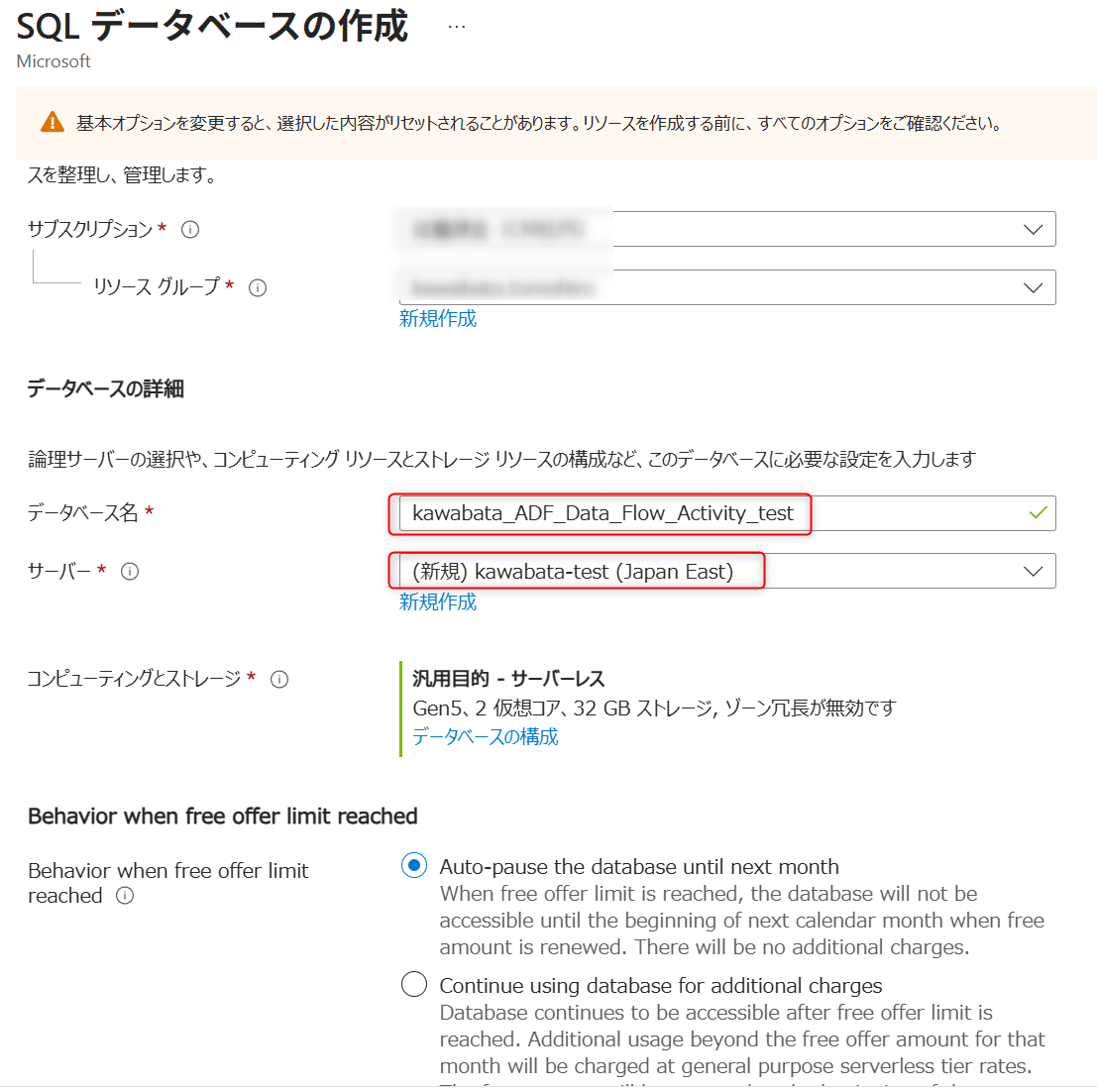
SQL databasesを検索し、Createを選択 - 以下の設定を行います
| 項目 | 設定値 |
|---|---|
| Resource group | 任意のResource group |
| Database name | ADF_Data_Flow_Activity_test |
| Server | 新規作成 |
ファイアウォール規則の設定
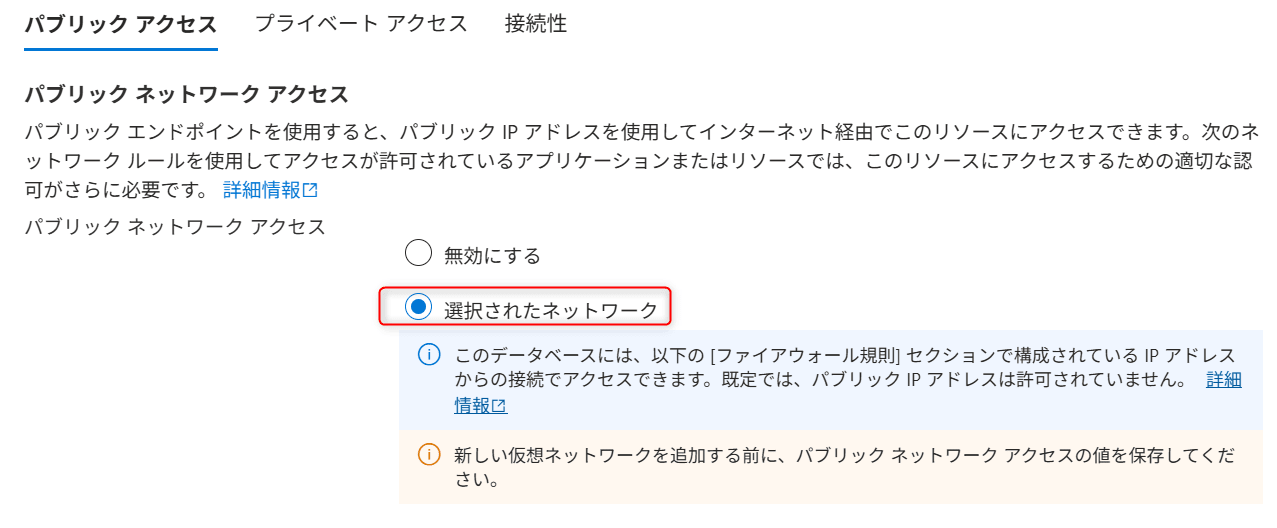
ADFからアクセスできるようにファイアウォールを設定します。
- 作成した SQL Server のリソースを開く
Networkingを選択- 以下を設定
| 項目 | 設定値 |
|---|---|
| パブリックアクセス | 選択されたネットワーク |
| クライアント IP の追加 | Add your client IPv4 address をクリック |

Azure SQL Database にテーブルを作成する
Azure SQL Databaseのクエリエディターより下記クエリを実行し、テーブルおよびサンプルデータを作成します。
/*
テーブル作成とサンプルデータ投入
Target table: dbo.test_snow
*/
BEGIN TRY
BEGIN TRANSACTION;
-- 既存テーブルがある場合は削除
DROP TABLE IF EXISTS dbo.test_snow;
-- テーブル作成
CREATE TABLE dbo.test_snow (
ID NVARCHAR(50) NOT NULL,
NAME NVARCHAR(100) NOT NULL,
CREATED_AT DATETIME2(0) NOT NULL,
UPDATED_AT DATETIME2(0) NOT NULL,
CONSTRAINT PK_test_snow PRIMARY KEY (ID)
);
-- サンプルデータ投入
INSERT INTO dbo.test_snow (
ID,
NAME,
CREATED_AT,
UPDATED_AT
)
VALUES
(
N'001',
N'Sample Item A',
CONVERT(DATETIME2(0), '2026-01-15T10:00:00', 126),
CONVERT(DATETIME2(0), '2026-05-01T09:00:00', 126)
),
(
N'002',
N'Sample Item B',
CONVERT(DATETIME2(0), '2026-02-20T14:30:00', 126),
CONVERT(DATETIME2(0), '2026-05-10T11:00:00', 126)
),
(
N'003',
N'Sample Item C',
CONVERT(DATETIME2(0), '2026-03-10T08:45:00', 126),
CONVERT(DATETIME2(0), '2026-05-20T16:30:00', 126)
);
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
THROW;
END CATCH;
テーブルが作成されたか確認します。
SELECT
TABLE_SCHEMA,
TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'test_snow';
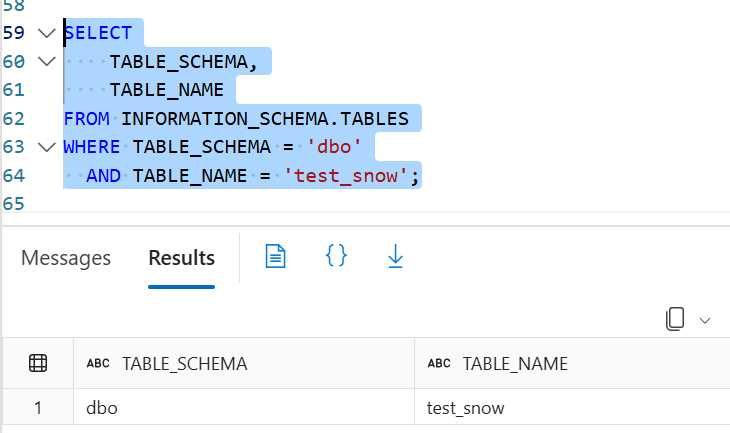
作成されていることが確認できました。
Snowflake 側のオブジェクト作成
Snowflake 側に、ADF からロードするための Database / Schema / Warehouse / Table を作成します。ここでは例として以下の名前を使います。
| 種別 | 名前 |
|---|---|
| Database | ADF_DEMO_DB |
| Schema | RAW |
| Warehouse | ADF_DEMO_WH |
| Role | ADF_ROLE |
| User | ADF_USER |
| Table | test_snow |
Database / Schema / Warehouse を作成します。
USE ROLE SYSADMIN;
CREATE DATABASE IF NOT EXISTS ADF_DEMO_DB;
CREATE SCHEMA IF NOT EXISTS ADF_DEMO_DB.RAW;
CREATE WAREHOUSE IF NOT EXISTS ADF_DEMO_WH
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
ロード先テーブルを作成します。実際には dbo.test_snow の列定義に合わせて作成してください。
CREATE TABLE IF NOT EXISTS ADF_DEMO_DB.RAW.test_snow (
ID VARCHAR,
NAME VARCHAR,
CREATED_AT TIMESTAMP_NTZ,
UPDATED_AT TIMESTAMP_NTZ
);
テーブルが作成されたことを確認します。
DESC TABLE ADF_DEMO_DB.RAW.test_snow;
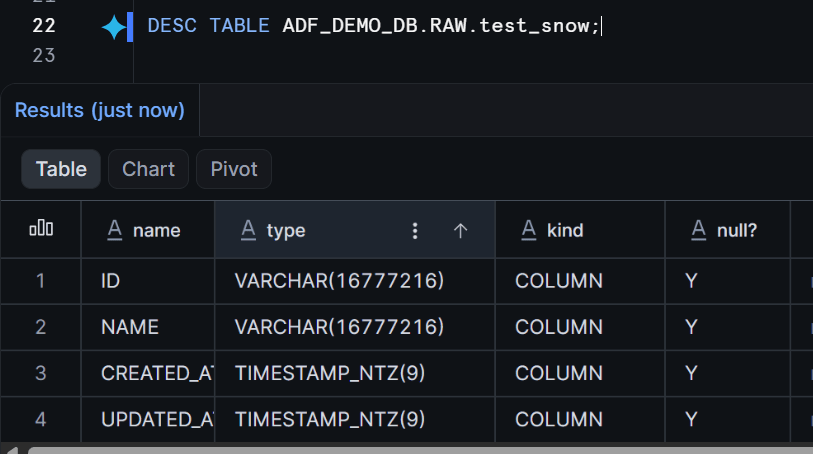
テーブルの定義が表示されれば問題ありません。
ADF 用 Role / User を作成する
Role を作成します。
USE ROLE SECURITYADMIN;
CREATE ROLE IF NOT EXISTS ADF_ROLE;
Key Pair 認証を使う前提で、User を作成します。
CREATE USER IF NOT EXISTS ADF_USER
DEFAULT_ROLE = ADF_ROLE
DEFAULT_WAREHOUSE = ADF_DEMO_WH
DEFAULT_NAMESPACE = ADF_DEMO_DB.RAW
MUST_CHANGE_PASSWORD = FALSE;
Role を User に付与します。
GRANT ROLE ADF_ROLE TO USER ADF_USER;
Snowflake 側の権限を付与する
ADF から Snowflake に書き込むため以下を付与します。
USE ROLE SYSADMIN;
GRANT USAGE ON WAREHOUSE ADF_DEMO_WH TO ROLE ADF_ROLE;
GRANT USAGE ON DATABASE ADF_DEMO_DB TO ROLE ADF_ROLE;
GRANT USAGE ON SCHEMA ADF_DEMO_DB.RAW TO ROLE ADF_ROLE;
GRANT CREATE TABLE ON SCHEMA ADF_DEMO_DB.RAW TO ROLE ADF_ROLE;
GRANT SELECT, INSERT, UPDATE, DELETE
ON TABLE ADF_DEMO_DB.RAW.test_snow
TO ROLE ADF_ROLE;
Data Flow で単純 Insert のみを行うなら INSERT が中心ですが、将来的に Upsert / Update / Delete を使う可能性がある場合は、上記のように UPDATE / DELETE も付与しておくと検証しやすいです。
Data Flow は internal data transfer を利用するため Storage Integration 指定とは異なりますが、ADF 用 Role には検証時の権限不足を避けるため、スキーマ上の CREATE STAGE も付与しておくことを推奨します。Microsoft の Snowflake コネクタ前提条件でも、Snowflake 側 User には Database の USAGE、Schema/Table への Read/Write、Schema 上の CREATE STAGE が必要とされています。
GRANT CREATE STAGE ON SCHEMA ADF_DEMO_DB.RAW TO ROLE ADF_ROLE;
Key Pair 認証用の鍵を作成する
ADF から Snowflake へは、パスワード認証よりも Key Pair 認証を推奨します。
下記記事の内容に沿って設定しました。
Azure SQL Database 側の権限を設定する
ADF が Azure SQL Database のテーブルを参照できるようにします。
SQL 認証を使う場合は、ADF Linked Service に指定する SQL User に対して SELECT 権限を付与します。
CREATE USER [adf_sql_user]
WITH PASSWORD = 'Your_Strong_Password_123!';
GRANT SELECT ON OBJECT::[dbo].[test_snow] TO [adf_sql_user];
試してみた
Azure SQL Database Linked Service を作成する
ADF Studio を開き、Linked Service を作成します。
- ADF Studio にアクセス
- 左メニューから
Manageを選択 Linked services→Newを選択Azure SQL Databaseを検索し、Azure SQL Database コネクタを選択
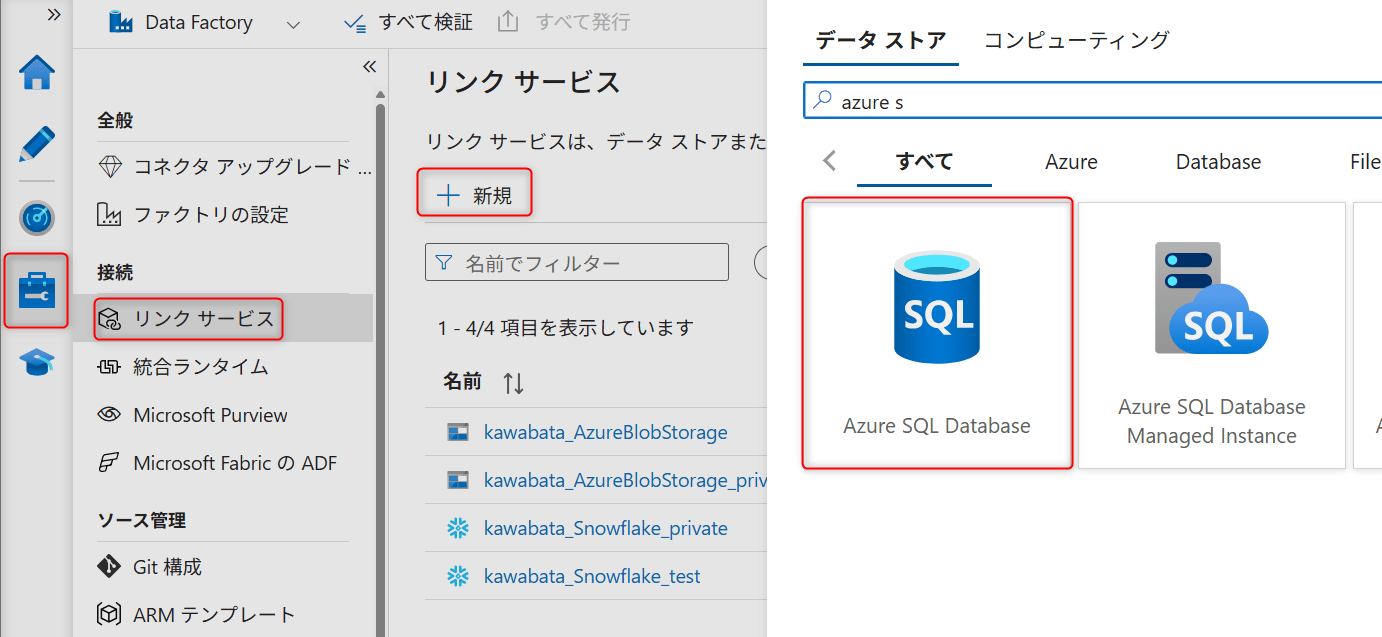
以下の設定を行います。
| 項目 | 設定値 |
|---|---|
| Name | 任意の名称 |
| Connect via integration runtime | AutoResolveIntegrationRuntime または Managed VNet 用 Azure IR |
| Authentication type | SQL authentication / Managed Identity など |
| Server name | Azure SQL Server 名 |
| Database name | 対象 Database |
| User name | SQL 認証の場合に指定 |
| Password | SQL 認証の場合に指定 |
Test connection をクリックし、成功することを確認します。
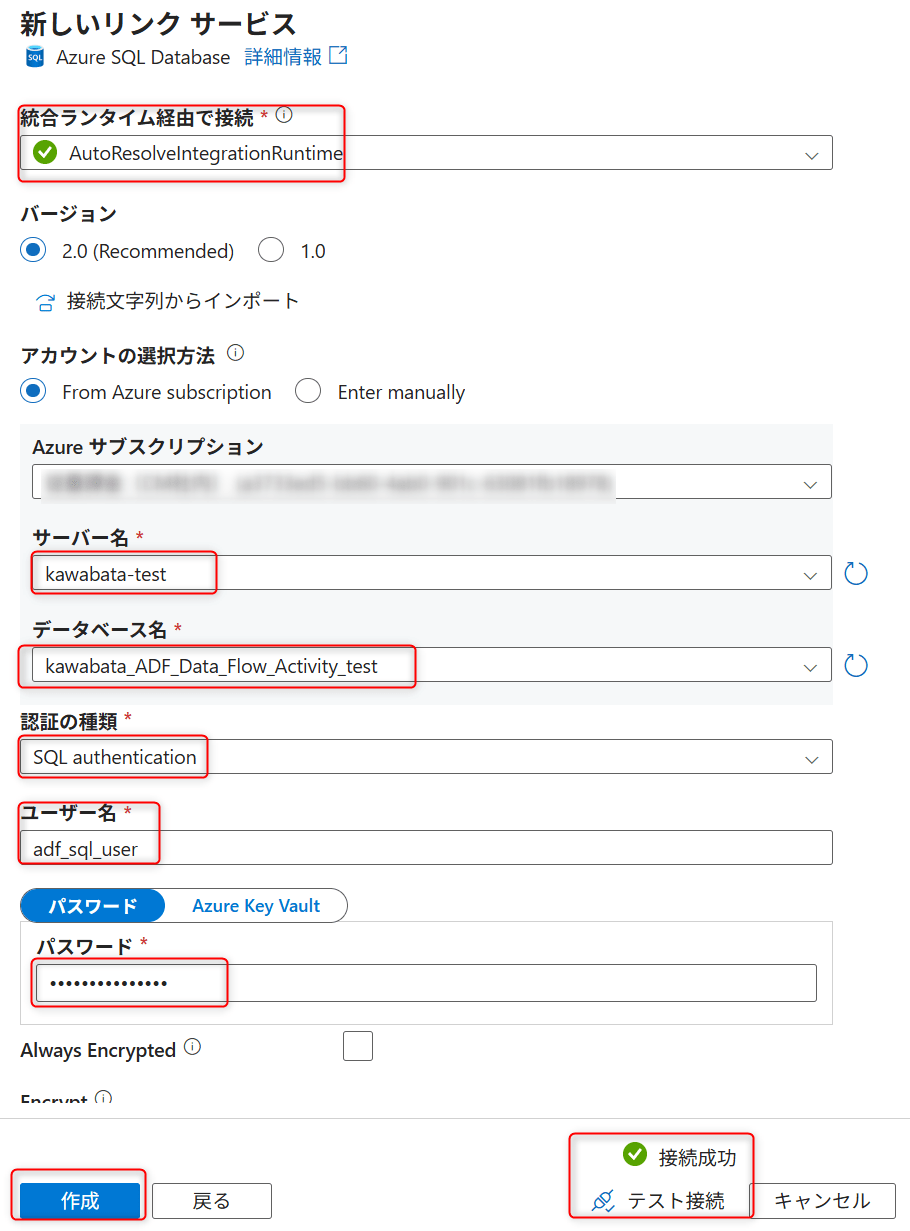
Succeeded と表示されれば問題ありません。
Snowflake V2 Linked Service を作成する
次に Snowflake への Linked Service を作成します。
- ADF Studio の
Manage→Linked services→New Snowflakeを検索し、Snowflake コネクタを選択
以下の設定を行います。
| 項目 | 設定値 |
|---|---|
| Name | 任意の名称 |
| Connect via integration runtime | AutoResolveIntegrationRuntime |
| Account identifier | Snowflake の Account Identifier |
| Database | ADF_DEMO_DB |
| Warehouse | ADF_DEMO_WH |
| Role | ADF_ROLE |
| Authentication type | KeyPair |
| User | ADF_USER |
| Private key | rsa_key.p8 の中身 |
| Private key passphrase | パスフレーズありの場合に指定 |
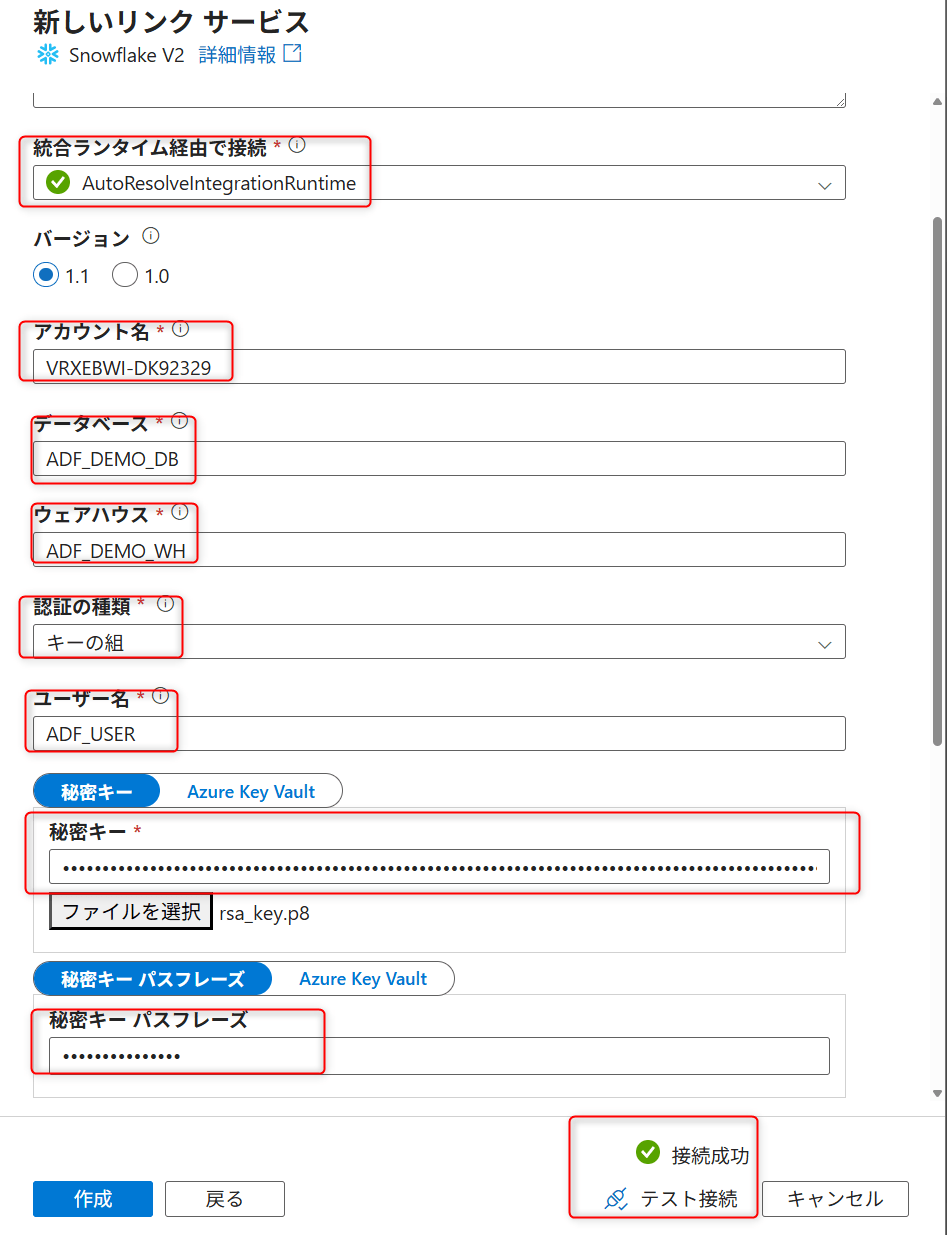
Test connection を実行し、Succeeded と表示されれば問題ありません。
Dataset を作成する
Data Flow の Source 用と Sink 用の Dataset を作成します。
Azure SQL Database Dataset(Source 用)
- ADF Studio の
Author→Datasets→New dataset Azure SQL Databaseを選択- Linked Service に、先ほど作成したものを指定
| 項目 | 設定値 |
|---|---|
| Name | AzureSqlTable_test_snow |
| Linked service | 先ほど作成したもの |
| Table name | dbo.test_snow |
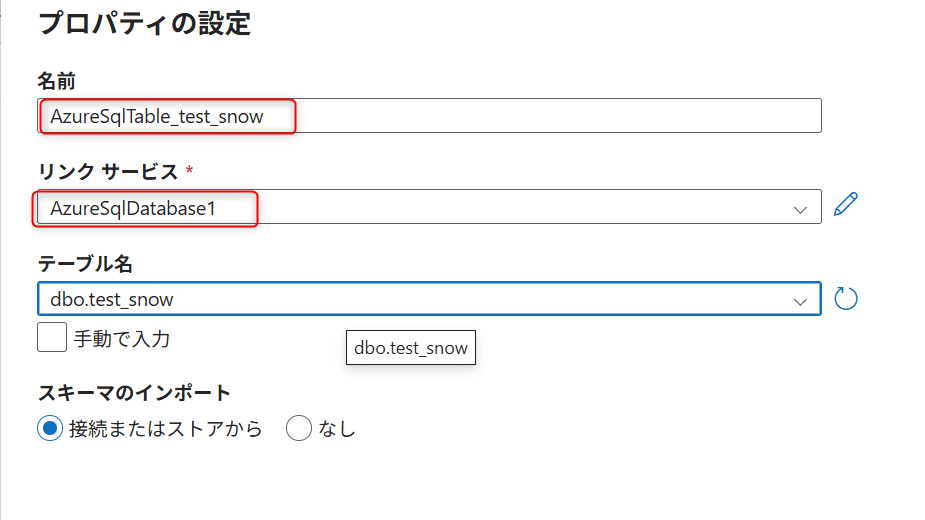
Snowflake Dataset(Sink 用)
- ADF Studio の
Author→Datasets→New dataset Snowflakeを選択- Linked Service に先ほど作成したものを指定
| 項目 | 設定値 |
|---|---|
| Name | Snowflake |
| Linked service | 先ほど作成したもの |
| Schema | RAW |
| Table | test_snow |

Mapping Data Flow を作成する
- ADF Studio の
Author→Data flows→New data flow Mapping Data Flowを選択
Source・Sinkを設定する
Source の設定
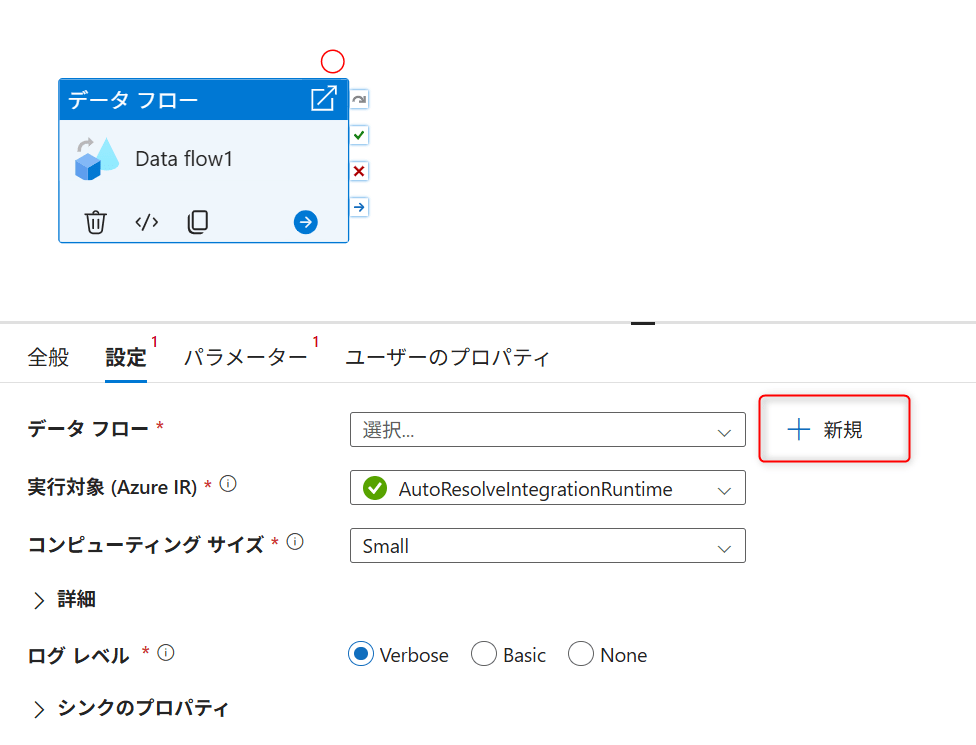
Data Flow キャンバスで Add Source を選択します。
| 項目 | 設定値 |
|---|---|
| Output stream name | testsnow |
| Source type | Dataset |
| Dataset | 先ほど作成した |
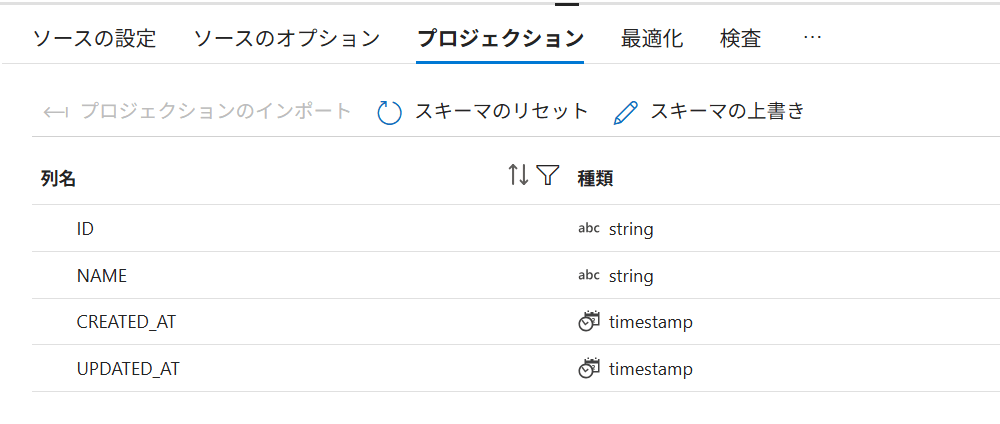
Source の Projection タブで、Azure SQL Database 側の列が正しく読み取れていることを確認します。必要に応じて Import schema を実行します。
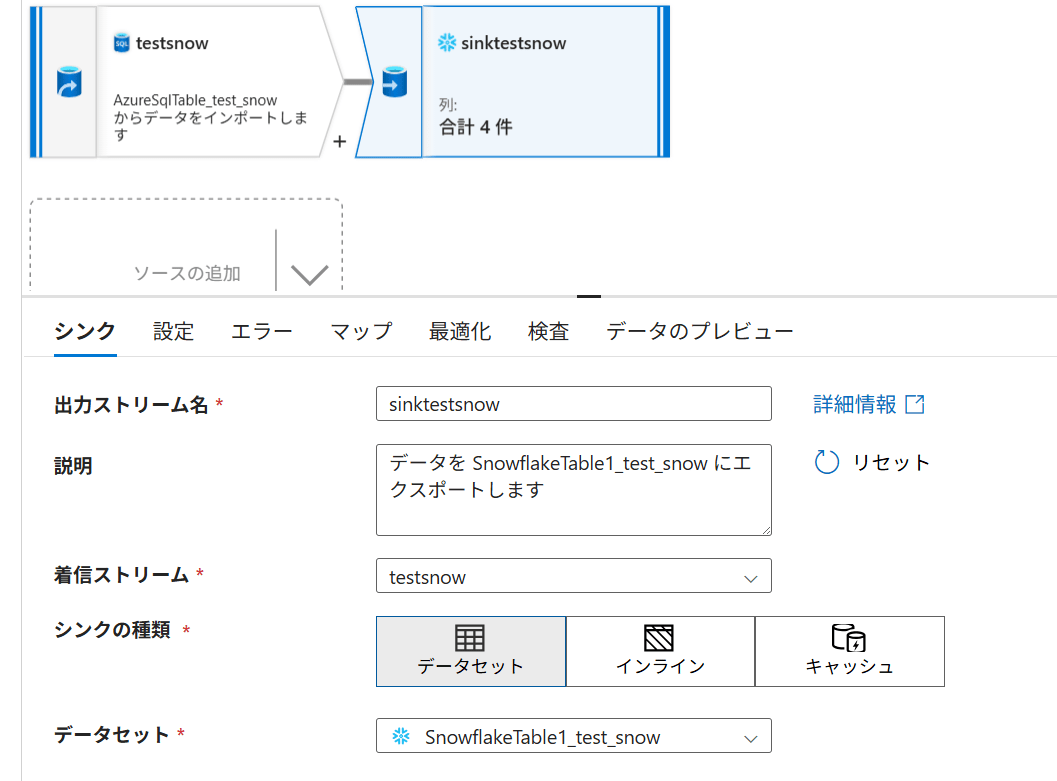
Sink の設定
Data Flow キャンバスで Add Sink を選択します。
| 項目 | 設定値 |
|---|---|
| Output stream name | sinktestsnow |
| Sink type | Dataset |
| Dataset | 先ほど作成したデータセット |
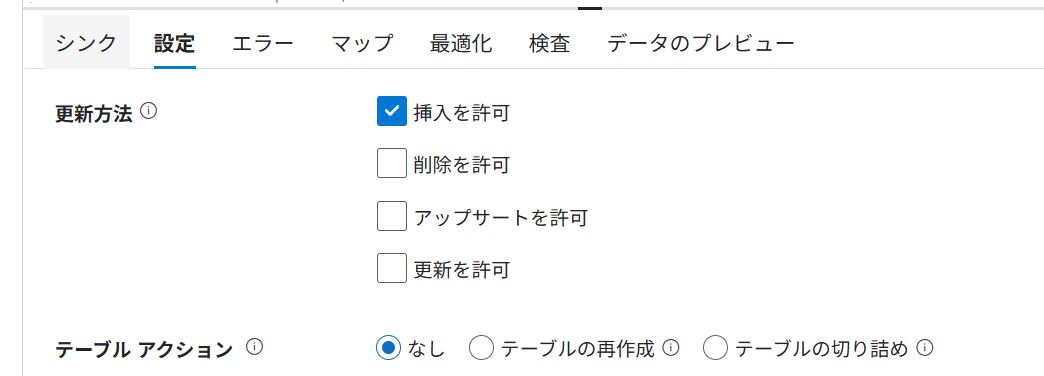
Snowflake Sink の Mapping Data Flow では、Settings タブで Insert / Update / Upsert / Delete などの書き込み動作を設定できます。
Debug 実行と確認
Pipeline の Debug を実行します。
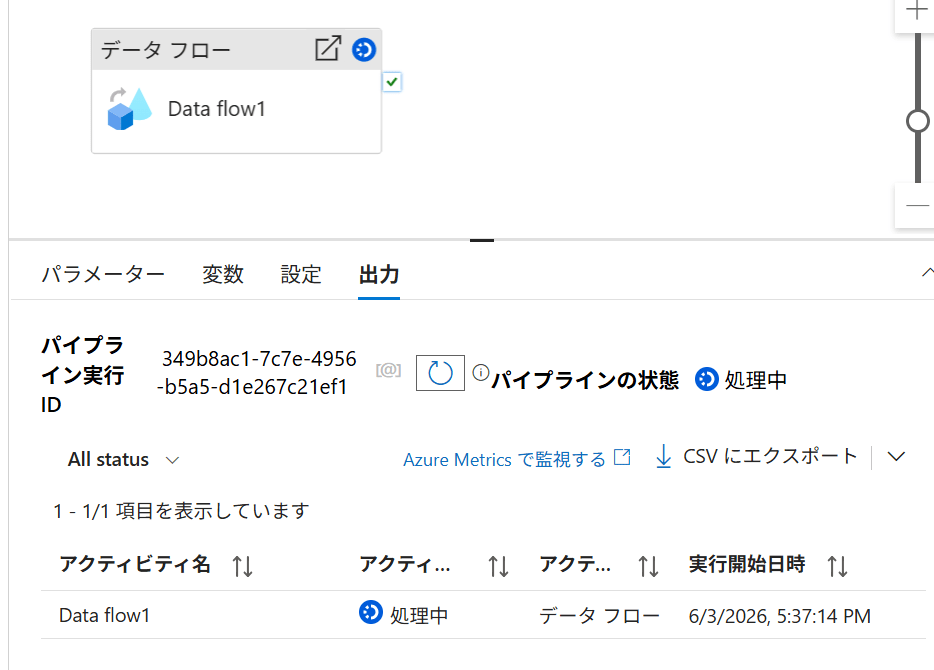
正常終了したら、Snowflake 側で件数を確認します。
USE DATABASE ADF_DEMO_DB;
USE SCHEMA RAW;
SELECT COUNT(*)
FROM test_snow;
SELECT *
FROM test_snow
LIMIT 10;
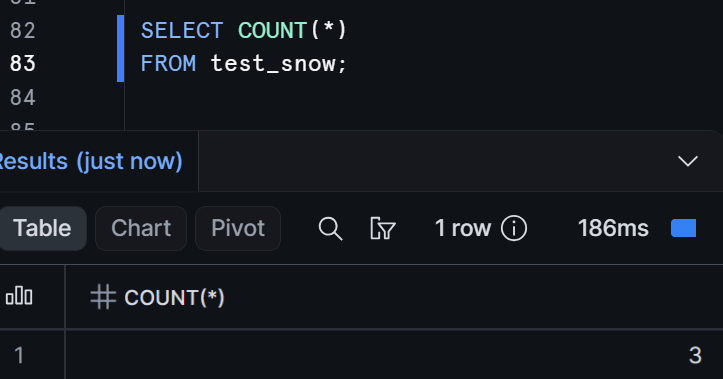
データが正しくロードされていれば問題ありません。
Snowflake 側で COPY INTO 実行を確認する
Mapping Data Flow の Snowflake Sink は、Snowflake Spark Connector の internal data transfer を利用します。この方式では、Snowflake が内部的に一時ステージを作成・管理し、データ転送時に利用します。
ADF 実行後、Snowflake の Query History で確認します。
SELECT
START_TIME,
USER_NAME,
ROLE_NAME,
WAREHOUSE_NAME,
QUERY_TYPE,
QUERY_TEXT,
EXECUTION_STATUS,
ERROR_MESSAGE
FROM TABLE(
INFORMATION_SCHEMA.QUERY_HISTORY(
END_TIME_RANGE_START => DATEADD('hour', -2, CURRENT_TIMESTAMP())
)
)
WHERE USER_NAME = 'ADF_USER'
ORDER BY START_TIME DESC;
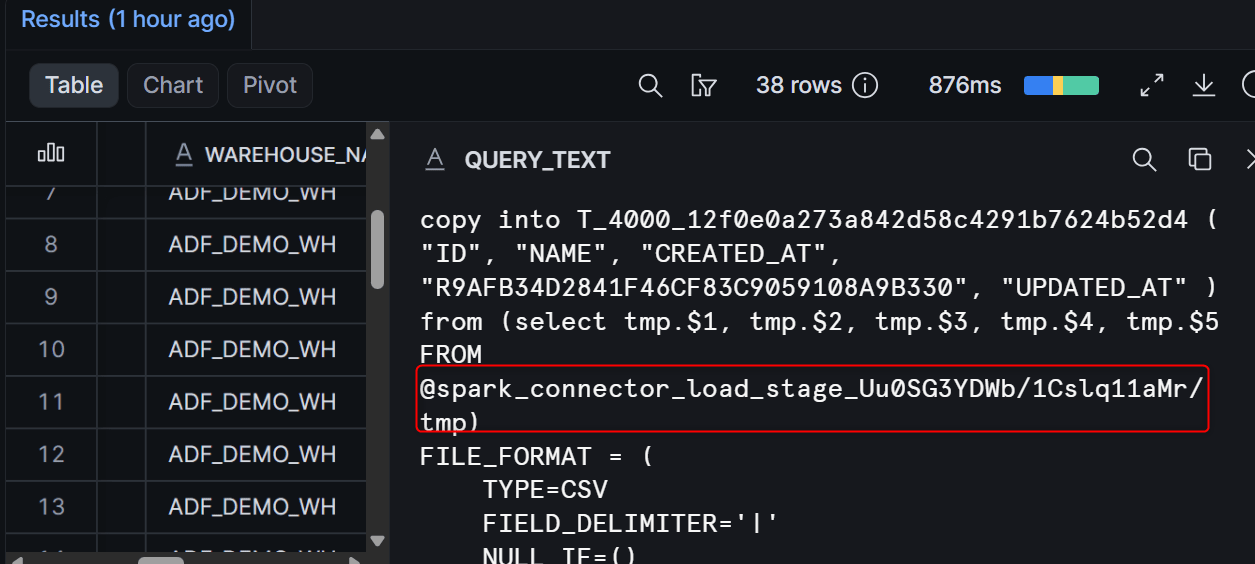
Query History に COPY INTO や内部ステージ関連のクエリが記録されていれば、Snowflake internal data transfer が利用されていることを確認できます。
補足: Copy Activity 構成との違い
参照ブログの Copy Activity 構成と、今回の Data Flow 構成の違いをまとめます。
| 項目 | Copy Activity | Mapping Data Flow |
|---|---|---|
| 主用途 | データコピー | 変換 + ロード |
| Snowflake ロード | COPY INTO <table> を利用 |
Snowflake internal data transfer を利用 |
| Azure Blob ステージング | 有効化可能 | 通常 UI で明示設定しない |
| Storage Integration | Copy Activity のステージング構成で利用 | 今回の Data Flow では基本不要 |
| 変換処理 | 限定的 | Select / Join / Derived Column / Aggregate など可能 |
| 起動コスト | 比較的軽い | Spark クラスター起動コストあり |
| 大量単純コピー | Copy Activity 推奨 | 変換が必要なら Data Flow |
Microsoft の Snowflake V2 コネクタでは、Copy Activity の Snowflake Sink が COPY INTO <table> を利用し、ステージングコピー時は Azure Blob Storage を中間ストレージとして使用する構成が説明されています。一方で、Mapping Data Flow の Snowflake Source/Sink は internal data transfer を利用すると説明されています。
最後に
ADF の Mapping Data Flow Activity を使って、Azure SQL Database から Snowflake にデータをロードする構成を試しました。Copy Activity とは異なり、Data Flow では Snowflake の internal data transfer が利用され、Azure Blob Storage ステージングや Storage Integration の明示設定が基本不要な点が大きな違いでした。
変換処理が不要で単純コピーだけなら Copy Activity が軽量で適していますが、列名変換・型変換・Upsert 制御などが必要な場合は Data Flow が便利です。
この記事が何かの参考になれば幸いです!








