![[新機能] Snowflakeでクエリの特性に応じてコンピュートリソースが自動でスケールするAdaptive Warehouseを試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-37f4322e7cca0bb66380be0a31ceace4/0886455fd66594d3e7d8947c9c7c844d/eyecatch_snowflake?w=3840&fm=webp)
[新機能] Snowflakeでクエリの特性に応じてコンピュートリソースが自動でスケールするAdaptive Warehouseを試してみた
さがらです。
これまでSnowflakeのウェアハウスはサイズ(XS・S・M・Lなど)を自分で選んで管理する必要がありましたが、Adaptive Warehouseにより、クエリの特性に応じてコンピュートリソースが自動でスケールするようになります。手動でのウェアハウスサイジングや、スケールアップ・スケールアウトの設定が不要になる機能です。
@tshowisさんの以下の投稿で知りました。
リリースノートはまだ公開されていませんが、公式Docに詳細が掲載されています。Public Previewの対応リージョンにはAWS東京リージョン(AP Northeast 1)も含まれているため、AWS東京リージョンで利用している方はすぐに試せます。TPC-Hサンプルデータを使って実際にどのように動くか確認してみましたので、手順と確認結果をまとめます。
機能概要
Adaptive Warehouseは、ワークロードを認識してリソースを自動的に割り当てるコンピュートサービスです。アカウント専用の共有コンピュートプールを持ち、クエリの特性に応じて最適なリソースを自動で決定します。
主な特徴は以下のとおりです:
- ウェアハウスサイジング不要:手動でのサイズ選択・変更が不要
- クエリ単位の自動スケール:小さいクエリは少ないリソース、大きいクエリは多くのリソースを自動的に使用
- オンライン変換:既存の標準ウェアハウスからAdaptive Warehouseへの変換はダウンタイムなし
- 2つのパラメータで挙動を制御可能
制御できるパラメータは以下の2つです:
| パラメータ | デフォルト値 | 説明 |
|---|---|---|
MAX_QUERY_PERFORMANCE_LEVEL |
XLARGE |
1クエリあたりの上限パフォーマンス(XSMALL〜X4LARGE) |
QUERY_THROUGHPUT_MULTIPLIER |
2 |
並行実行のスケール係数(0で無制限、正の整数で上限設定) |
QUERY_THROUGHPUT_MULTIPLIERをNに設定すると、MAX_QUERY_PERFORMANCE_LEVELのリソースでN件のクエリを同時実行できる容量が確保されます。
制限事項
- 2026年4月16日時点ではPublic Previewの機能です。GAまでに仕様が変わる可能性があります
- 利用可能リージョン(Public Preview時点):US West 2(Oregon)、EU West 1(Ireland)、AP Northeast 1(Tokyo)
- 必要なエディション:Enterprise Edition以上
- X5Large・X6LargeウェアハウスからAdaptive Warehouseへの変換はサポートされていません
- Snowpark-optimizedウェアハウス・Interactiveウェアハウスとの相互変換もサポートされていません
コスト
Adaptive Warehouseはクエリベースの課金モデルを採用しています。各クエリのコストは、そのクエリが使用したコンピュートリソース量とソフトウェアリソース量に基づいて計算されます。ウェアハウス全体のコストは、実行されたすべてのクエリのコストの合計になります。
なお、ウェアハウスの作成自体にはコストは発生せず、クエリが実行された時点から課金が始まります。コスト管理にはBudgets・リソースモニターの活用、またSNOWFLAKE.ACCOUNT_USAGEのビューを使ったモニタリングが可能です。
前提条件
- Snowflake:AWS USオレゴンリージョン、Enterprise Edition
- ちょうどトライアルアカウントを持っていたので、USオレゴンリージョンで検証しています
事前準備
TPC-Hサンプルデータの確認
今回の検証では、Snowflakeに標準で提供されているTPC-Hサンプルデータを使います。TPC-Hは意思決定支援ベンチマーク用のデータセットで、複雑な結合や集計を含むクエリで大量データ処理を評価するのに適しています。
SNOWFLAKE_SAMPLE_DATAデータベース内に、スケールファクター(SF)の異なる複数のスキーマが用意されています:
| スキーマ | データ規模の目安 |
|---|---|
TPCH_SF1 |
数百万レコード |
TPCH_SF10 |
数千万レコード |
TPCH_SF100 |
数億レコード |
TPCH_SF1000 |
数十億レコード |
今回はAutomatic Scalingの挙動をより明確に確認するために、TPCH_SF1000(数十億レコード規模)を使います。
まず、サンプルデータにアクセスできることを確認しておきます。
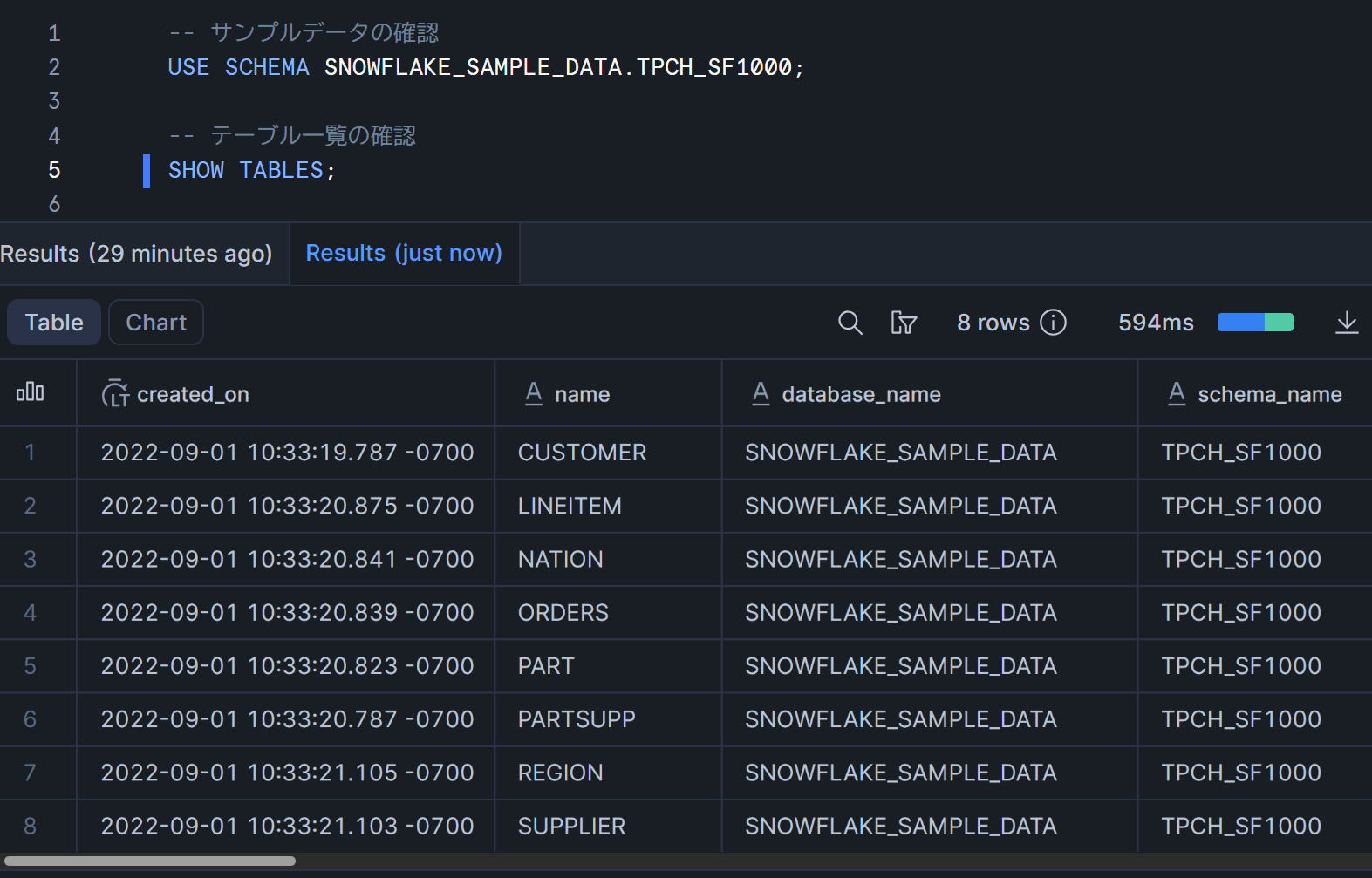
-- サンプルデータの確認
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000;
-- テーブル一覧の確認
SHOW TABLES;
8つのテーブルが表示されればOKです(LINEITEM、ORDERS、CUSTOMER、SUPPLIER、PART、PARTSUPP、NATION、REGION)。
アカウントレベルのキャッシュを無効化
パラメータのチューニング前後で実行時間を正しく比較するため、クエリ結果キャッシュを無効化しておきます。キャッシュが有効な状態だと、2回目以降の同じクエリがキャッシュから返されてしまい、実行時間の比較ができません。
アカウントレベルでキャッシュを無効化します。
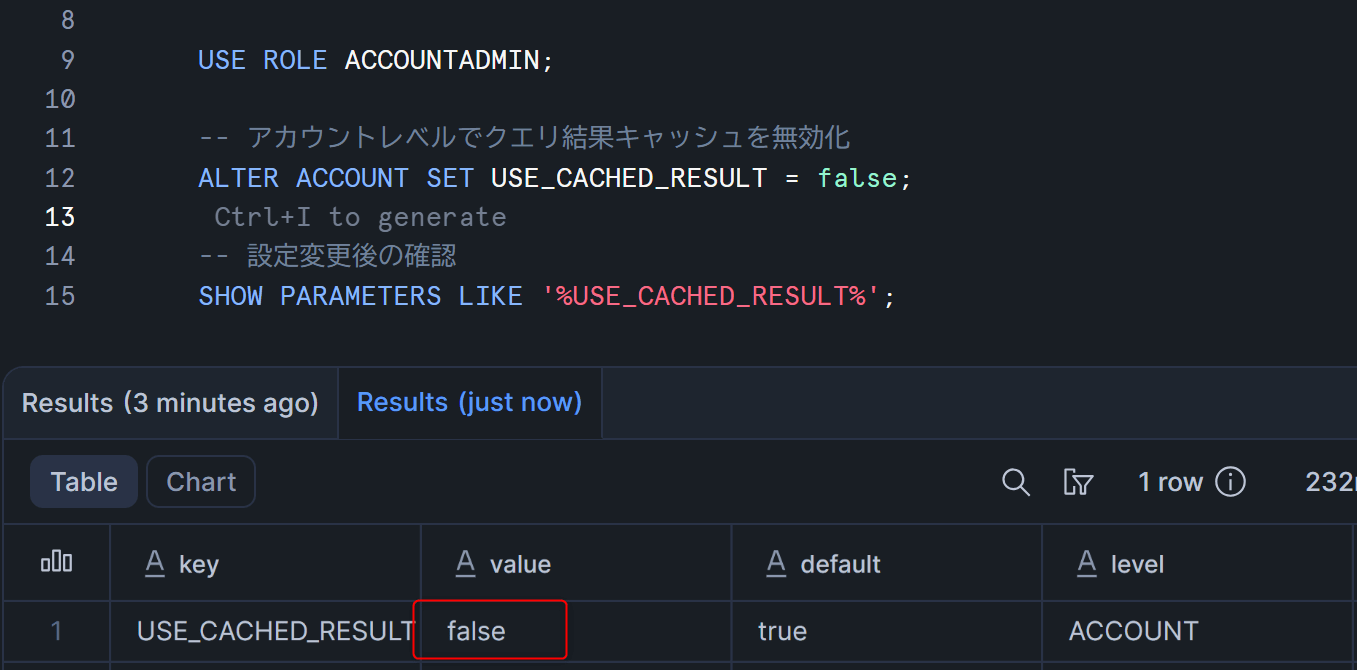
USE ROLE ACCOUNTADMIN;
-- アカウントレベルでクエリ結果キャッシュを無効化
ALTER ACCOUNT SET USE_CACHED_RESULT = false;
以下のクエリでパラメータを確認し、falseになっていればOKです。
-- 設定変更後の確認
SHOW PARAMETERS LIKE '%USE_CACHED_RESULT%';
試してみた
1. Adaptive Warehouseの作成(XLARGE設定)
まず、MAX_QUERY_PERFORMANCE_LEVEL = XLARGEのAdaptive Warehouseを新規作成します。
USE ROLE SYSADMIN;
-- XLARGE設定のAdaptive Warehouseを新規作成
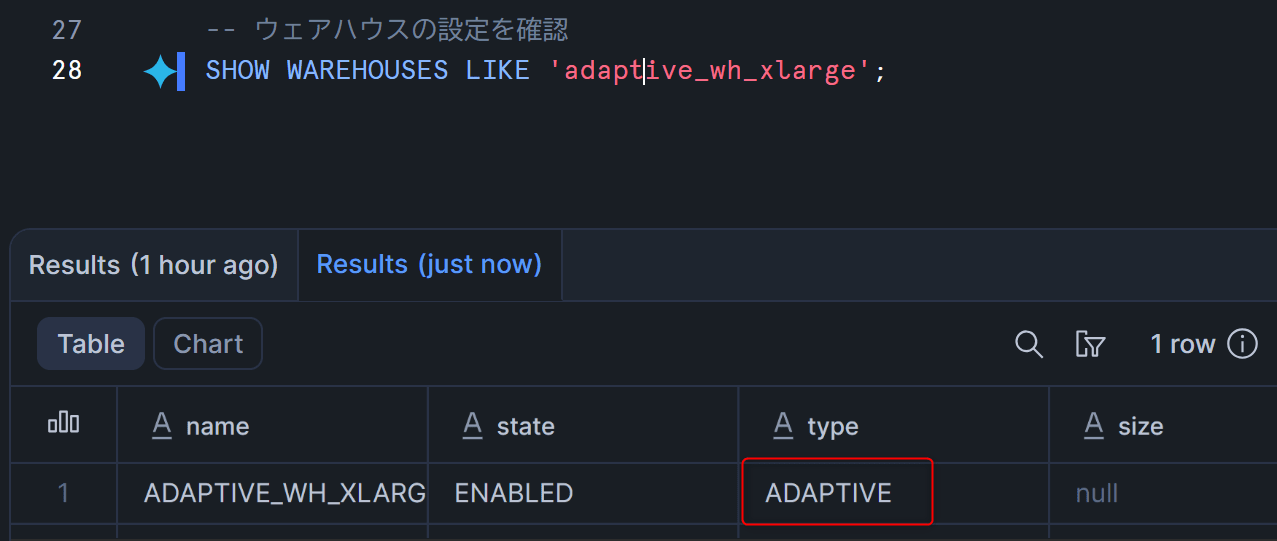
CREATE ADAPTIVE WAREHOUSE adaptive_wh_xlarge
WITH MAX_QUERY_PERFORMANCE_LEVEL = XLARGE
QUERY_THROUGHPUT_MULTIPLIER = 2;
作成後、設定を確認します。
-- ウェアハウスの設定を確認
SHOW WAREHOUSES LIKE 'adaptive_wh_xlarge';
type列がADAPTIVEになっていればOKです。
2. XLARGE設定でTPC-Hクエリを実行
作成したadaptive_wh_xlargeを使って、TPC-Hの代表的なクエリを実行してみます。
後で実行時間を比較できるように QUERY_TAG を設定します。
-- セッションにQUERY_TAGを設定(後で比較のラベルとして使用)
ALTER SESSION SET QUERY_TAG = 'adaptive_xlarge_m2';
USE WAREHOUSE adaptive_wh_xlarge;
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000;
TPC-H Q1:集計クエリ(LINEITEMテーブル全体を集計)
最初に、TPC-Hの中でも最も単純なQ1(Pricing Summary Report)を実行します。LINEITEMテーブル(SF1000では約60億レコード)を全件スキャンして集計するクエリです。
-- TPC-H Q1: Pricing Summary Report
-- SF1000のLINEITEMテーブル(約60億レコード)を集計
SELECT
L_RETURNFLAG,
L_LINESTATUS,
SUM(L_QUANTITY) AS SUM_QTY,
SUM(L_EXTENDEDPRICE) AS SUM_BASE_PRICE,
SUM(L_EXTENDEDPRICE * (1 - L_DISCOUNT)) AS SUM_DISC_PRICE,
SUM(L_EXTENDEDPRICE * (1 - L_DISCOUNT) * (1 + L_TAX)) AS SUM_CHARGE,
AVG(L_QUANTITY) AS AVG_QTY,
AVG(L_EXTENDEDPRICE) AS AVG_PRICE,
AVG(L_DISCOUNT) AS AVG_DISC,
COUNT(*) AS COUNT_ORDER
FROM
LINEITEM
WHERE
L_SHIPDATE <= DATEADD(DAY, -90, TO_DATE('1998-12-01'))
GROUP BY
L_RETURNFLAG,
L_LINESTATUS
ORDER BY
L_RETURNFLAG,
L_LINESTATUS;
5回実行して、以下の結果となりました。
| 実行回 | 実行時間 (秒) |
|---|---|
| 1 | 4.47 |
| 2 | 4.55 |
| 3 | 3.68 |
| 4 | 3.85 |
| 5 | 3.77 |
TPC-H Q5:複数テーブルの結合クエリ
次に、複数テーブルをJOINするQ5(Local Supplier Volume)を実行します。
-- TPC-H Q5: Local Supplier Volume
-- 6テーブルをJOINする複雑なクエリ
SELECT
N.N_NAME,
SUM(L.L_EXTENDEDPRICE * (1 - L.L_DISCOUNT)) AS REVENUE
FROM
CUSTOMER C,
ORDERS O,
LINEITEM L,
SUPPLIER S,
NATION N,
REGION R
WHERE
C.C_CUSTKEY = O.O_CUSTKEY
AND L.L_ORDERKEY = O.O_ORDERKEY
AND L.L_SUPPKEY = S.S_SUPPKEY
AND C.C_NATIONKEY = S.S_NATIONKEY
AND S.S_NATIONKEY = N.N_NATIONKEY
AND N.N_REGIONKEY = R.R_REGIONKEY
AND R.R_NAME = 'ASIA'
AND O.O_ORDERDATE >= TO_DATE('1994-01-01')
AND O.O_ORDERDATE < DATEADD(YEAR, 1, TO_DATE('1994-01-01'))
GROUP BY
N.N_NAME
ORDER BY
REVENUE DESC;
5回実行して、以下の結果となりました。
| 実行回 | 実行時間 (秒) |
|---|---|
| 1 | 5.74 |
| 2 | 3.17 |
| 3 | 3.03 |
| 4 | 3.03 |
| 5 | 2.83 |
3. 比較用のAdaptive Warehouseを新規作成(SMALL設定)
MAX_QUERY_PERFORMANCE_LEVEL = SMALLに設定した新しいAdaptive Warehouseを別途作成します。
USE ROLE SYSADMIN;
-- SMALL設定のAdaptive Warehouseを新規作成
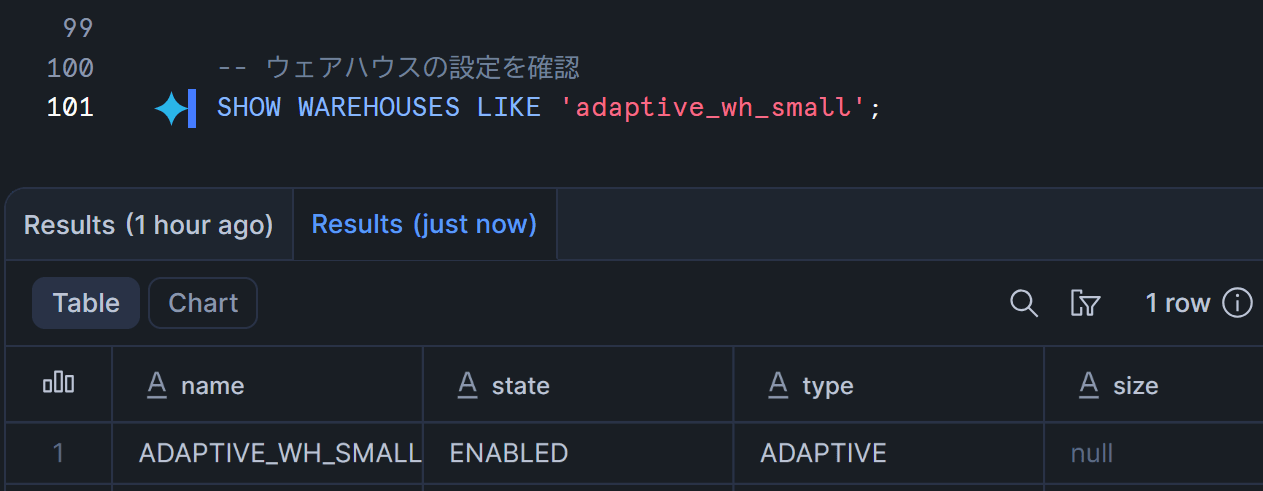
CREATE ADAPTIVE WAREHOUSE adaptive_wh_small
WITH MAX_QUERY_PERFORMANCE_LEVEL = SMALL
QUERY_THROUGHPUT_MULTIPLIER = 2;
-- ウェアハウスの設定を確認
SHOW WAREHOUSES LIKE 'adaptive_wh_small';
type列がADAPTIVEになっていればOKです。
4. SMALL設定でTPC-Hクエリを実行
作成したadaptive_wh_smallを使って、同じQ1・Q5を実行します。
-- QUERY_TAGを設定(SMALL設定での実行であることをラベル付け)
ALTER SESSION SET QUERY_TAG = 'adaptive_small_m2';
USE WAREHOUSE adaptive_wh_small;
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000;
TPC-H Q1:集計クエリ
-- Q1を実行(MAX_QUERY_PERFORMANCE_LEVEL = SMALL)
SELECT
L_RETURNFLAG,
L_LINESTATUS,
SUM(L_QUANTITY) AS SUM_QTY,
SUM(L_EXTENDEDPRICE) AS SUM_BASE_PRICE,
SUM(L_EXTENDEDPRICE * (1 - L_DISCOUNT)) AS SUM_DISC_PRICE,
SUM(L_EXTENDEDPRICE * (1 - L_DISCOUNT) * (1 + L_TAX)) AS SUM_CHARGE,
AVG(L_QUANTITY) AS AVG_QTY,
AVG(L_EXTENDEDPRICE) AS AVG_PRICE,
AVG(L_DISCOUNT) AS AVG_DISC,
COUNT(*) AS COUNT_ORDER
FROM
LINEITEM
WHERE
L_SHIPDATE <= DATEADD(DAY, -90, TO_DATE('1998-12-01'))
GROUP BY
L_RETURNFLAG,
L_LINESTATUS
ORDER BY
L_RETURNFLAG,
L_LINESTATUS;
5回実行して、以下の結果となりました。
| 実行回 | 実行時間 (秒) |
|---|---|
| 1 | 21.57 |
| 2 | 31.73 |
| 3 | 27.73 |
| 4 | 21.74 |
| 5 | 34.35 |
TPC-H Q5:複数テーブルの結合クエリ
-- Q5を実行(MAX_QUERY_PERFORMANCE_LEVEL = SMALL)
SELECT
N.N_NAME,
SUM(L.L_EXTENDEDPRICE * (1 - L.L_DISCOUNT)) AS REVENUE
FROM
CUSTOMER C,
ORDERS O,
LINEITEM L,
SUPPLIER S,
NATION N,
REGION R
WHERE
C.C_CUSTKEY = O.O_CUSTKEY
AND L.L_ORDERKEY = O.O_ORDERKEY
AND L.L_SUPPKEY = S.S_SUPPKEY
AND C.C_NATIONKEY = S.S_NATIONKEY
AND S.S_NATIONKEY = N.N_NATIONKEY
AND N.N_REGIONKEY = R.R_REGIONKEY
AND R.R_NAME = 'ASIA'
AND O.O_ORDERDATE >= TO_DATE('1994-01-01')
AND O.O_ORDERDATE < DATEADD(YEAR, 1, TO_DATE('1994-01-01'))
GROUP BY
N.N_NAME
ORDER BY
REVENUE DESC;
5回実行して、以下の結果となりました。
| 実行回 | 実行時間 (秒) |
|---|---|
| 1 | 42.18 |
| 2 | 38.49 |
| 3 | 38.41 |
| 4 | 38.69 |
| 5 | 36.97 |
5. INFORMATION_SCHEMA.QUERY_HISTORYで実行時間を比較
両ウェアハウスでの実行が完了したら、INFORMATION_SCHEMA.QUERY_HISTORY()で2つのQUERY_TAGをまとめて比較します。ACCOUNT_USAGEビューとは異なり遅延なしで参照できます。
全20回分の実行時間を一覧で確認
まず、Q1・Q5それぞれ5回ずつ×2ウェアハウス=合計20回分の実行記録を個別に確認します。QUERY_TEXTの内容からL_RETURNFLAGを含むものをQ1、N_NAMEを含むものをQ5と区別しています。
-- 全20回分の実行履歴(実行時間のみ確認)
SELECT
QUERY_TAG,
WAREHOUSE_NAME,
CASE
WHEN QUERY_TEXT ILIKE '%L_RETURNFLAG%' THEN 'Q1'
WHEN QUERY_TEXT ILIKE '%N_NAME%' THEN 'Q5'
ELSE 'OTHER'
END AS query_name,
START_TIME,
ROUND(EXECUTION_TIME / 1000, 2) AS exec_sec
FROM TABLE(
INFORMATION_SCHEMA.QUERY_HISTORY(
END_TIME_RANGE_START => DATEADD(HOUR, -2, CURRENT_TIMESTAMP()),
END_TIME_RANGE_END => CURRENT_TIMESTAMP(),
RESULT_LIMIT => 1000
)
)
WHERE WAREHOUSE_NAME IN ('ADAPTIVE_WH_XLARGE', 'ADAPTIVE_WH_SMALL')
AND QUERY_TAG IN ('adaptive_xlarge_m2', 'adaptive_small_m2')
AND EXECUTION_STATUS = 'SUCCESS'
AND QUERY_TYPE = 'SELECT'
ORDER BY QUERY_TAG, query_name, START_TIME;
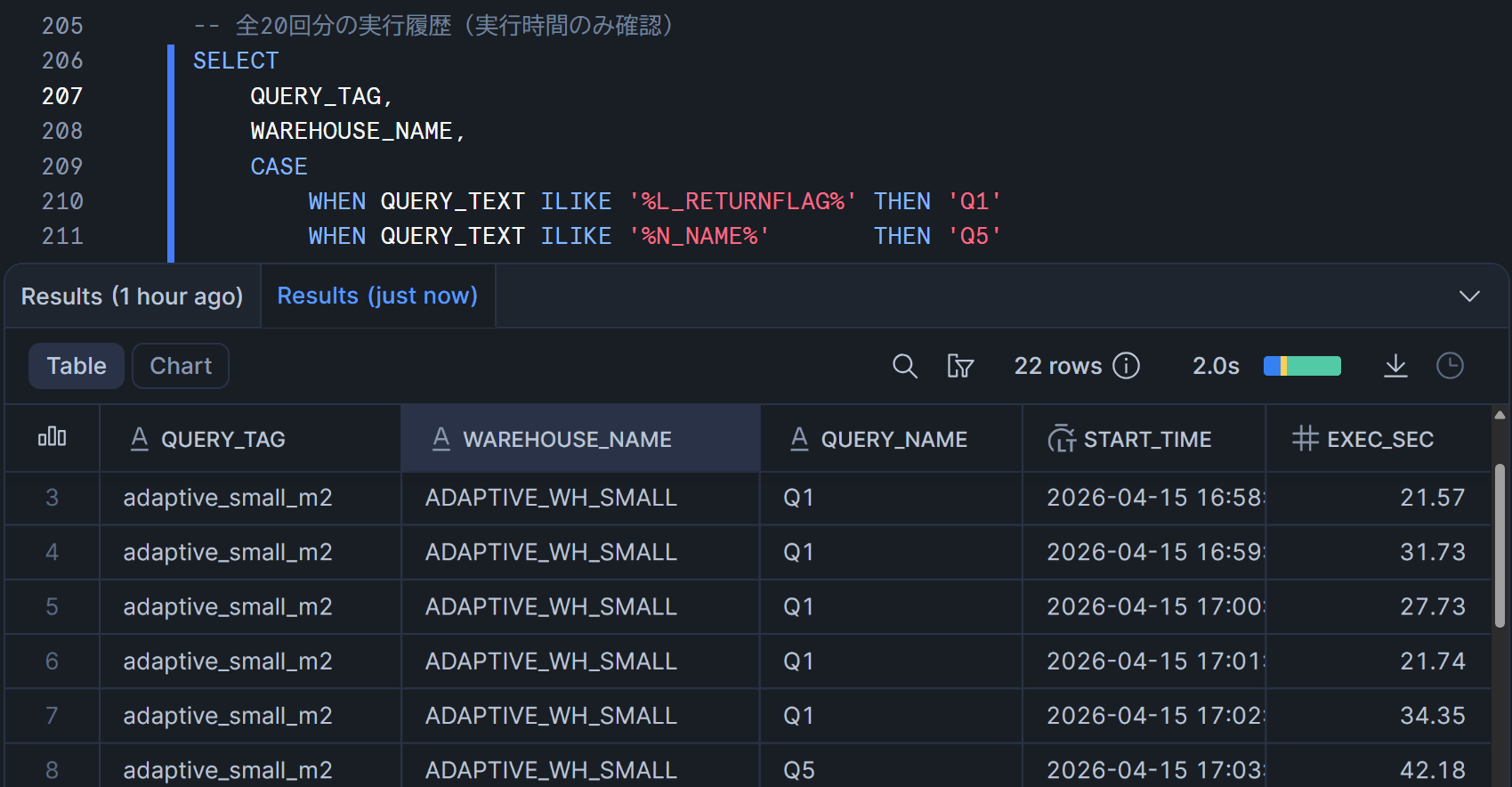
| QUERY_TAG | WAREHOUSE_NAME | クエリ種別 | 試行回数 | 実行時間 (秒) |
|---|---|---|---|---|
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q1 | 1回目 | 4.47 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q1 | 2回目 | 4.55 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q1 | 3回目 | 3.68 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q1 | 4回目 | 3.85 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q1 | 5回目 | 3.77 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q5 | 1回目 | 5.74 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q5 | 2回目 | 3.17 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q5 | 3回目 | 3.03 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q5 | 4回目 | 3.03 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q5 | 5回目 | 2.83 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q1 | 1回目 | 21.57 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q1 | 2回目 | 31.73 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q1 | 3回目 | 27.73 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q1 | 4回目 | 21.74 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q1 | 5回目 | 34.35 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q5 | 1回目 | 42.18 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q5 | 2回目 | 38.49 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q5 | 3回目 | 38.41 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q5 | 4回目 | 38.69 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q5 | 5回目 | 36.97 |
集計して比較
MAX_QUERY_PERFORMANCE_LEVELを下げた効果がexecution_timeに出ているかを確認します。キュー待ちの傾向も見たいためqueued_overload_timeも合わせて出します。
-- QUERY_TAG × クエリ種別ごとに実行時間を集計して比較
-- 各 QUERY_TAG × query_name の直近5件のSELECT文のみを対象にする
WITH ranked AS (
SELECT
QUERY_TAG,
WAREHOUSE_NAME,
CASE
WHEN QUERY_TEXT ILIKE '%L_RETURNFLAG%' THEN 'Q1'
WHEN QUERY_TEXT ILIKE '%N_NAME%' THEN 'Q5'
ELSE 'OTHER'
END AS query_name,
EXECUTION_TIME,
TOTAL_ELAPSED_TIME,
QUEUED_OVERLOAD_TIME,
ROW_NUMBER() OVER (
PARTITION BY QUERY_TAG,
CASE
WHEN QUERY_TEXT ILIKE '%L_RETURNFLAG%' THEN 'Q1'
WHEN QUERY_TEXT ILIKE '%N_NAME%' THEN 'Q5'
ELSE 'OTHER'
END
ORDER BY START_TIME DESC
) AS rn
FROM TABLE(
INFORMATION_SCHEMA.QUERY_HISTORY(
END_TIME_RANGE_START => DATEADD(HOUR, -2, CURRENT_TIMESTAMP()),
END_TIME_RANGE_END => CURRENT_TIMESTAMP(),
RESULT_LIMIT => 1000
)
)
WHERE WAREHOUSE_NAME IN ('ADAPTIVE_WH_XLARGE', 'ADAPTIVE_WH_SMALL')
AND QUERY_TAG IN ('adaptive_xlarge_m2', 'adaptive_small_m2')
AND EXECUTION_STATUS = 'SUCCESS'
AND QUERY_TYPE = 'SELECT'
)
SELECT
QUERY_TAG,
WAREHOUSE_NAME,
query_name,
COUNT(*) AS run_count,
ROUND(AVG(EXECUTION_TIME) / 1000, 2) AS avg_exec_sec,
ROUND(MIN(EXECUTION_TIME) / 1000, 2) AS min_exec_sec,
ROUND(MAX(EXECUTION_TIME) / 1000, 2) AS max_exec_sec,
ROUND(AVG(TOTAL_ELAPSED_TIME) / 1000, 2) AS avg_elapsed_sec,
ROUND(AVG(QUEUED_OVERLOAD_TIME) / 1000, 2) AS avg_queued_overload_sec
FROM ranked
WHERE rn <= 5
GROUP BY QUERY_TAG, WAREHOUSE_NAME, query_name
ORDER BY QUERY_TAG, query_name;
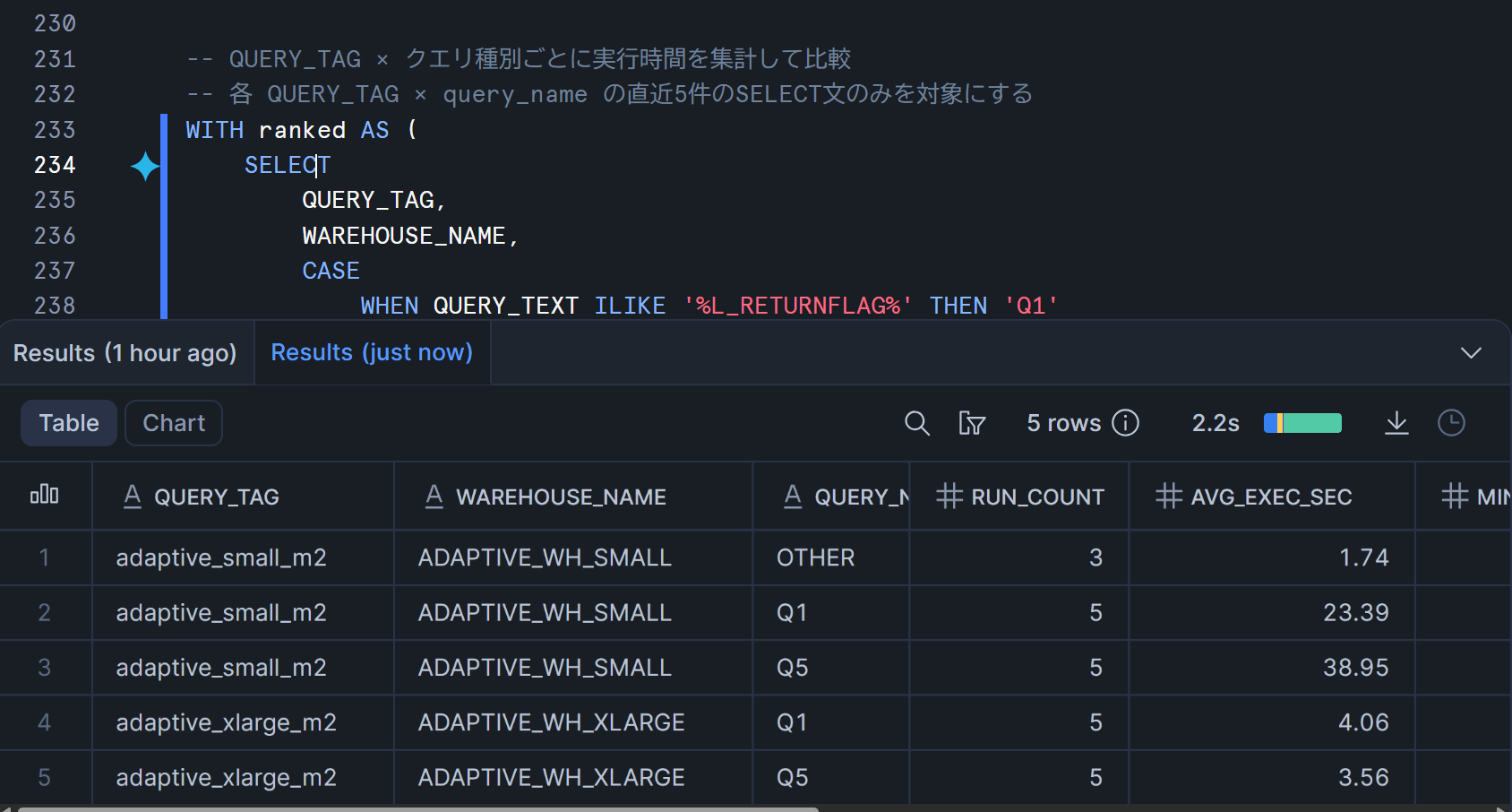
改めて表にまとめた結果が以下となります。
adaptive_xlarge_m2よりadaptive_small_m2のほうがavg_exec_secが長くなっていることがわかります。(パフォーマンス上限を下げた分、実行時間が伸びる)。
| QUERY_TAG | WAREHOUSE_NAME | クエリ種別 | 実行回数 | 平均実行時間 (秒) | 最小 (秒) | 最大 (秒) | 平均経過時間 (秒) | 平均キュー待ち (秒) |
|---|---|---|---|---|---|---|---|---|
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q1 | 5 | 4.06 | 3.68 | 4.55 | 7.17 | 0.00 |
| adaptive_xlarge_m2 | ADAPTIVE_WH_XLARGE | Q5 | 5 | 3.56 | 2.83 | 5.74 | 6.86 | 0.00 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q1 | 5 | 27.42 | 21.57 | 34.35 | 25.82 | 0.00 |
| adaptive_small_m2 | ADAPTIVE_WH_SMALL | Q5 | 5 | 38.95 | 36.97 | 42.18 | 42.72 | 0.00 |
考察
Q1・Q5ともに、XLARGEウェアハウスはSMALLウェアハウスと比較して大幅に短い実行時間になりました。
| クエリ | XLARGE 平均実行時間 | SMALL 平均実行時間 | 倍率 |
|---|---|---|---|
| Q1 | 4.06 秒 | 27.42 秒 | 約 6.8 倍 |
| Q5 | 3.56 秒 | 38.95 秒 | 約 10.9 倍 |
Q5のほうがQ1より倍率が大きくなっています。Q5は6テーブルのJOINを含む複雑なクエリであり、リソースの差がより顕著に現れたと考えられます。
検証上の注意点:ウェアハウスのデータキャッシュ
今回の検証で押さえておきたい点があります。Snowflakeのウェアハウスにはクエリ結果キャッシュとは別に、データキャッシュ(ローカルディスクキャッシュ) があります。リモートストレージから読み込んだマイクロパーティションをウェアハウスのローカルSSDに保持する仕組みです。
今回はアカウントレベルでUSE_CACHED_RESULT = falseに設定してクエリ結果キャッシュを無効化しましたが、データキャッシュは無効化していません。このため、同一ウェアハウスで同じクエリを連続実行した場合、2回目以降はローカルSSDからデータを読み込むため、基本的に初回よりも高速に結果が返ってきます。
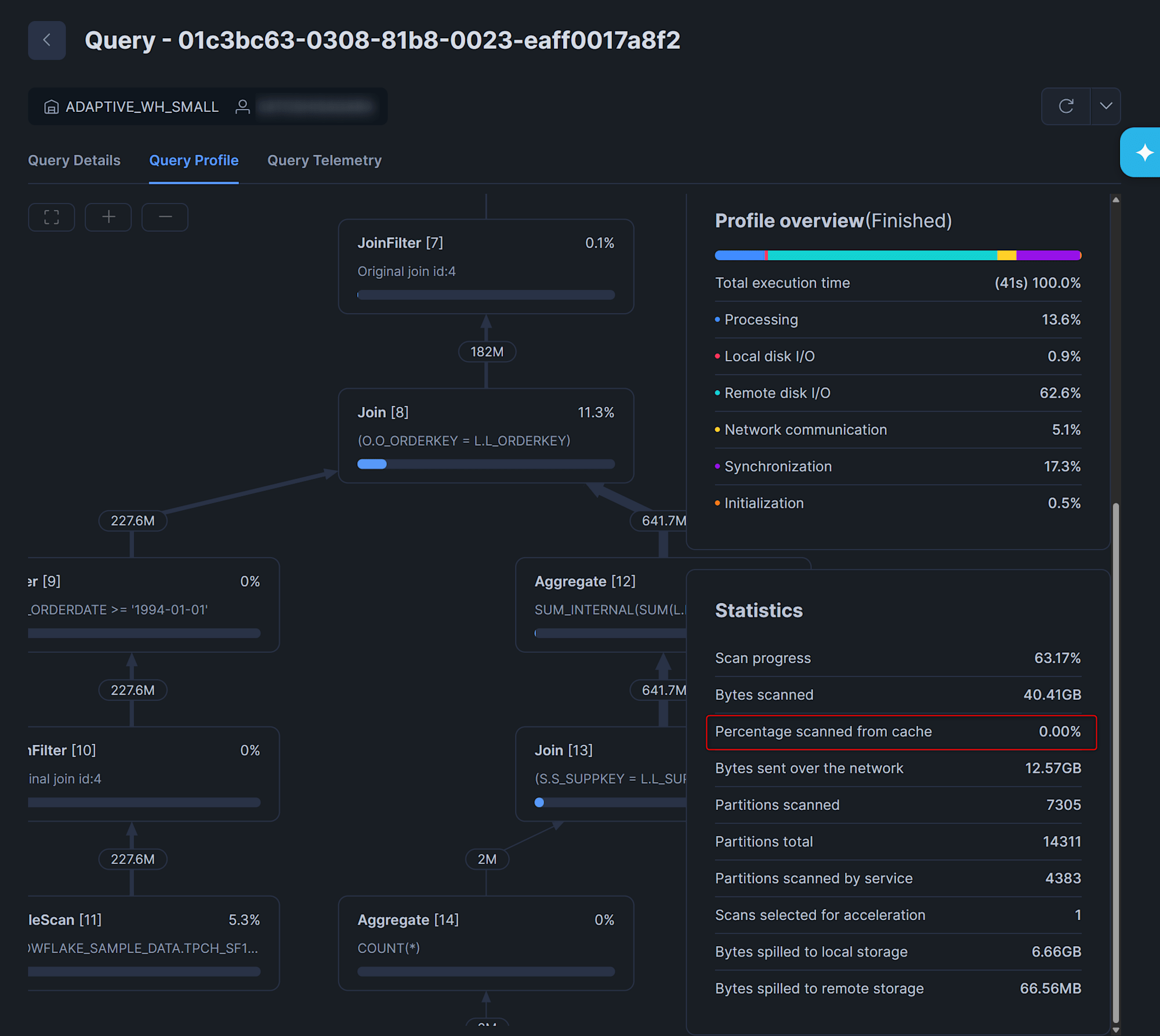
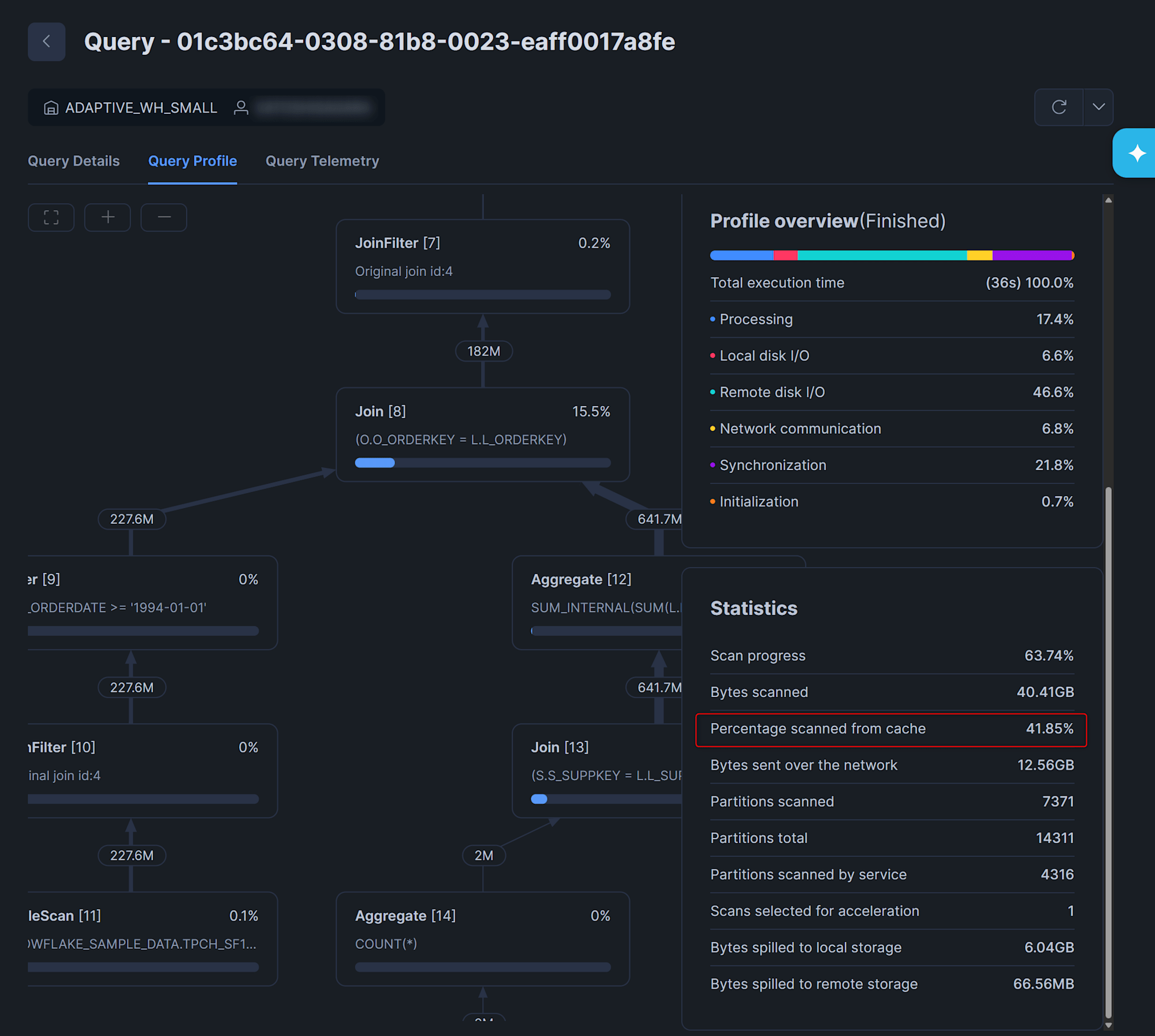
実際のデータを見るとXLARGEウェアハウスのQ5では、1回目が5.74秒なのに対し、2〜5回目は2.83〜3.17秒に短縮されており、データキャッシュの効果が確認できます。(一方で、SMALLのQ1については2回目以降が遅くなっているパターンもあります…この原因追求までは行えておりません。)
クエリプロファイルで確認すると、2回目ではPercentage scanned from cacheの割合が一定あることから、ウェアハウスのデータキャッシュが効いていることがわかります。
SMALLでのQ5:1回目のクエリプロファイル
SMALLでのQ5:2回目のクエリプロファイル
今回は「SMALLとXLARGEの相対的な差」を確認する目的だったため、両ウェアハウスとも同一条件(同じキャッシュ状態)での比較になっており、相対比較としては有効だと考えております。ただし、純粋なコールドスタート時の性能を計測したい場合は、ウェアハウスをサスペンドして再起動し、データキャッシュをクリアしてから計測する必要があることにご注意ください。
最後に
Snowflakeの新機能Adaptive WarehouseをTPC-Hサンプルデータを使って試してみました。
MAX_QUERY_PERFORMANCE_LEVELをXLARGEとSMALLで比較した結果、Q1(集計クエリ)で約6.8倍、Q5(6テーブルJOIN)で約10.9倍の実行時間差が確認できました。複雑なJOINクエリほどリソース量の差が顕著に出る傾向があり、MAX_QUERY_PERFORMANCE_LEVELの設定がパフォーマンスに直結することが実感できました。
最も印象的だったのは、ウェアハウスのサイズを一切意識せず、2つのパラメータ(MAX_QUERY_PERFORMANCE_LEVEL・QUERY_THROUGHPUT_MULTIPLIER)だけで「コストとパフォーマンスのバランス」をコントロールできる点です。これまでは「XLかXXLか」という具体的なサイズ選択が必要でしたが、Adaptive Warehouseではそこを自動化しつつ、上限だけ指定するシンプルな設計になっています。
本機能はEnterprise Edition以上でPublic Previewが利用でき、今回検証したUSオレゴンリージョン(US West 2)のほか、EU West 1(Ireland)とAP Northeast 1(東京) でも利用可能です。東京リージョンで利用している方も同様の手順ですぐに試せますので、ぜひ触ってみてください。








