![[レポート]SNOWFLAKE WORLD TOUR 2025 - TOKYO:Day2 KEYNOTE #SWTTokyo25](https://images.ctfassets.net/ct0aopd36mqt/4c23cKcRWSfL7fbZjZSEYa/9a2f285542f7937bedd49a78ad421a45/eyecatch_snowflakeworldtourtokyo2025_1200x630.png?w=3840&fm=webp)
[レポート]SNOWFLAKE WORLD TOUR 2025 - TOKYO:Day2 KEYNOTE #SWTTokyo25
かわばたです。
2025年9月11日~2025年9月12日に、「SNOWFLAKE WORLD TOUR 2025 - TOKYO」が開催されました。
本記事はセッション「Day2 KEYNOTE」のレポートブログとなります。
「Day1 KEYNOTE」については下記よりご確認ください。
登壇者
- クリスチャン・クライナマン 氏
- Snowflake プロダクト担当上席副社長 (EVP)
- 井口 和弘 氏
- Snowflake 執行役員 ソリューションエンジニアリング統括本部長
- スー リー 氏
- Snowflake シニア テクノロジー エバンジェリスト
- トリスタン・ハンディ氏
- dbt Labs,inc CEO
- 佐藤 隆明 氏
- NTTドコモ 代表取締役副社長 CTO


Snowflake井口氏よりイベント初日のハイライトについて説明
- キーノートは満席で、非常に盛況でした。各ゲストスピーカーセッションやブレイクアウトセッション、そして弊社のセッションにおいても、満席が非常に多い状況でした。
- 展示ブースも大変な賑わいでした。ご来場いただいたお客様とスタッフが熱心に話し込んでいる様子を拝見しました。


クリスチャン・クライナマン 氏から
AI活用のための3つのテーマ
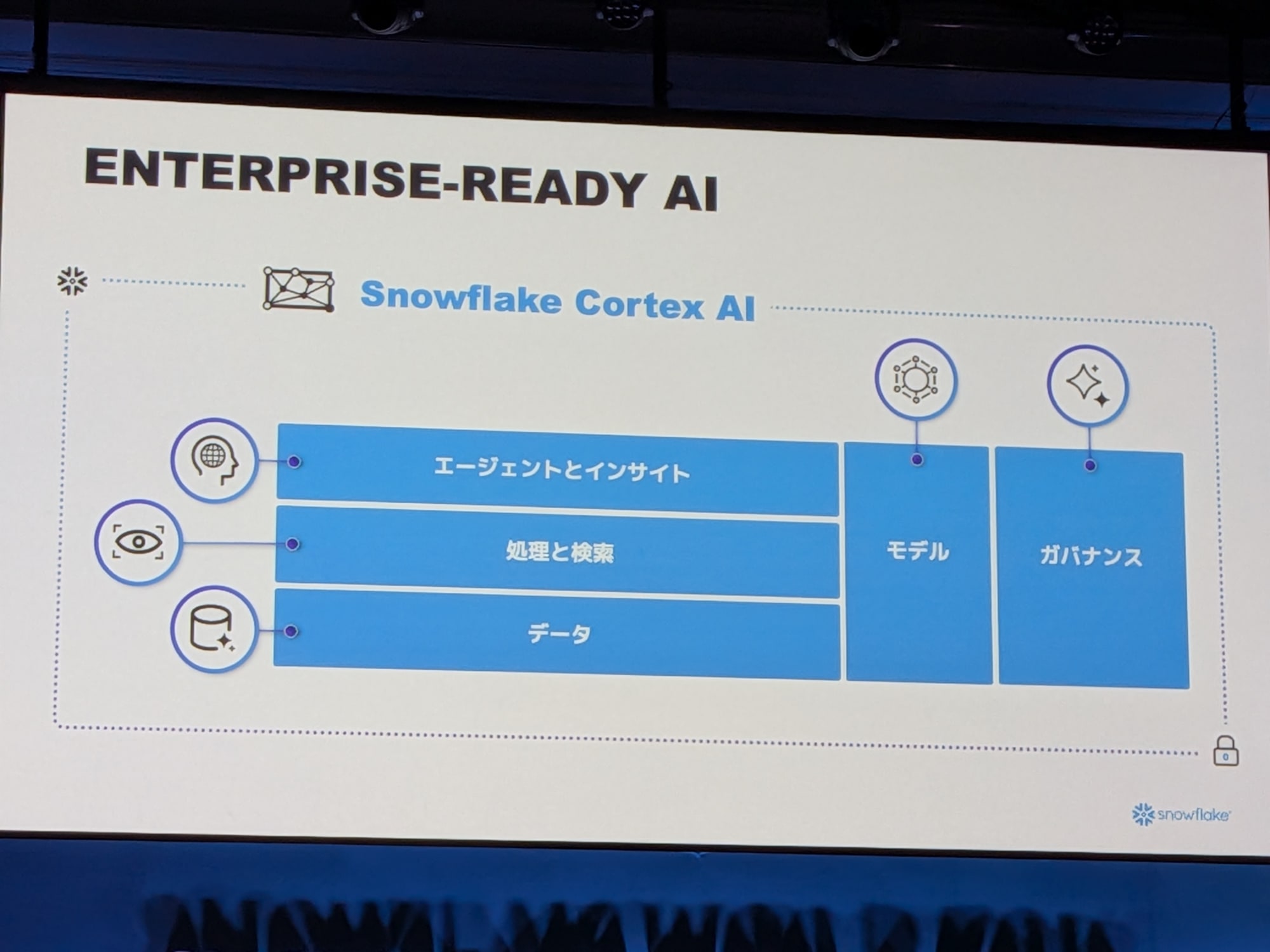
Snowflake Cortex AI:統合されたAIプラットフォーム
「Snowflake Cortex AI」と呼ばれるプラットフォームを通じて統合されています。Cortex AIは、データ処理と検索、エージェント、そしてモデル選択の自由度とガバナンスといった、数多くの要素で構成されています。

高品質なデータがAIの鍵
高品質なデータなくして、優れたAIのアウトプットは出来ません。Snowflakeが提供する価値の多くは、皆様が高品質で十分に管理されたデータを保有できるよう支援することにあります。

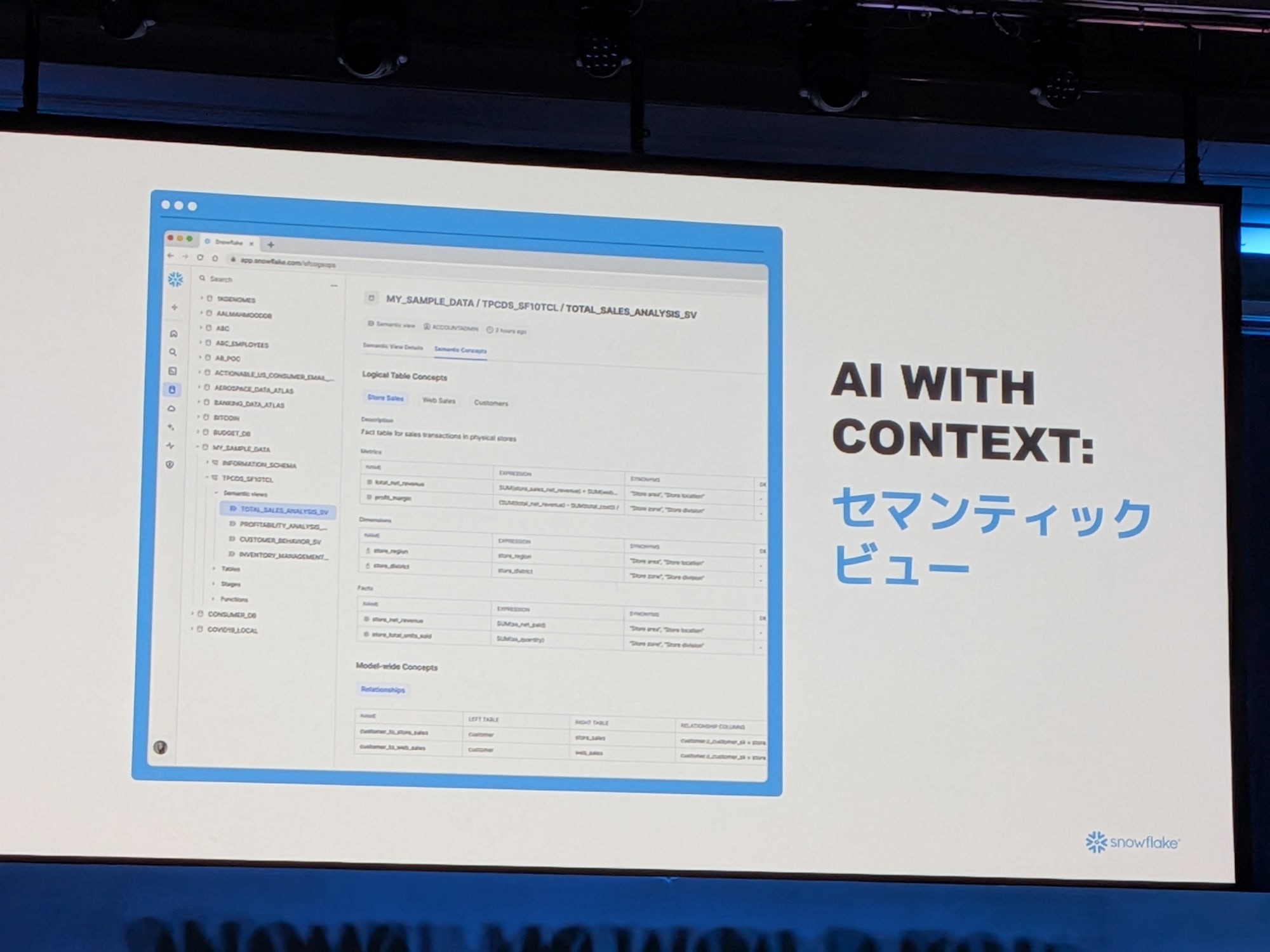
セマンティックビュー:ビジネスとデータの橋渡し
Snowflakeでは「セマンティックビュー」という概念を導入しました。セマンティックビューでは、ユーザーが使用するビジネス用語が、物理的なデータスキーマにどのように関連付けられるかを定義できます。
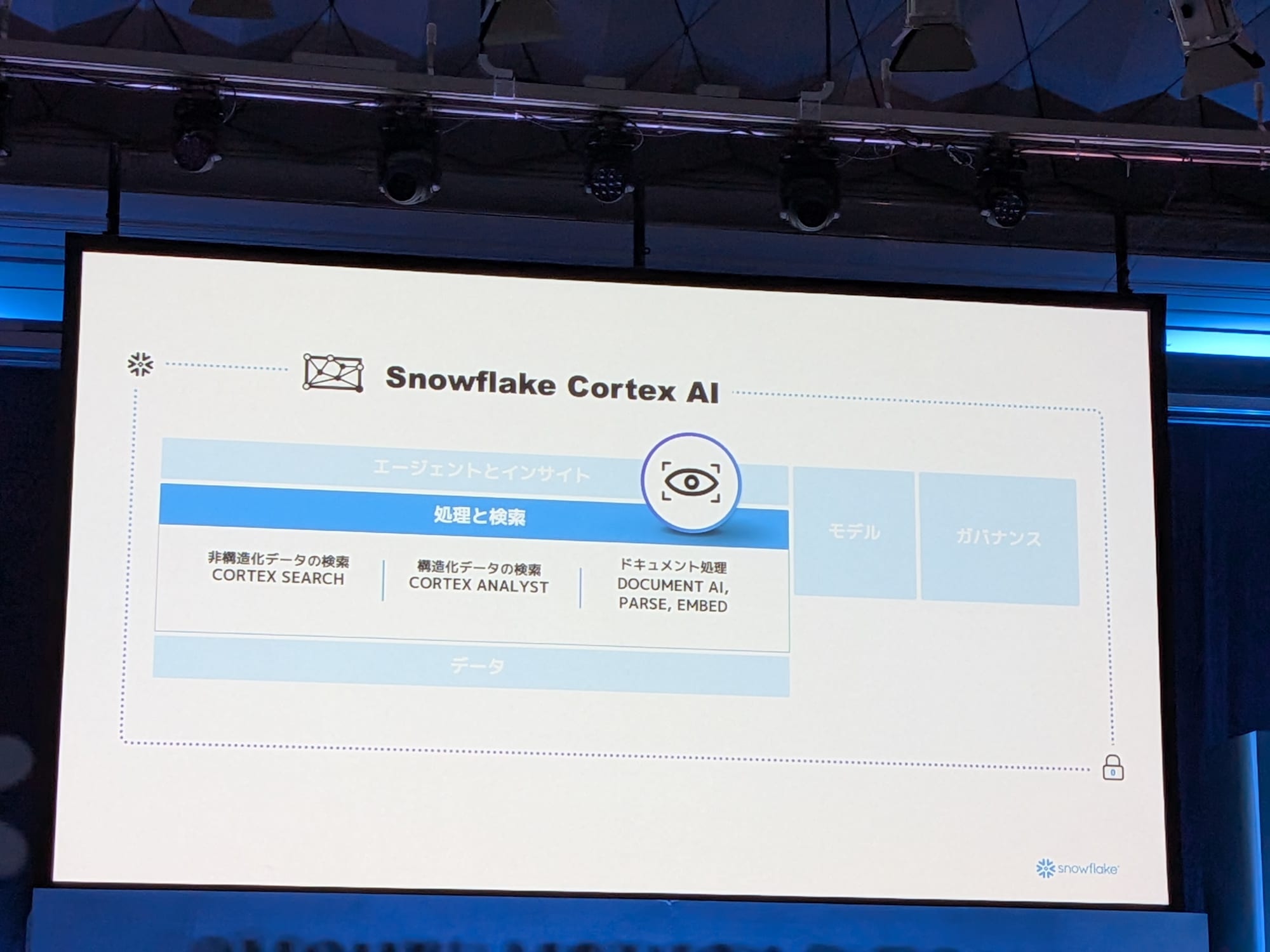
データ処理と検索を容易にする機能群
-
Cortex Search:テキストなどの非構造化データに対して、最も簡単に会話型エクスペリエンスを構築する方法です。データセットを指定するだけで、Snowflakeがデータをベクトル化し、ルックアップインデックスを作成して、データに対する質問を容易にします。キーワード検索、セマンティック検索、ハイブリッド検索に基づき、最適な結果を提供します。
-
Cortex Analyst:構造化データ向けの同様の技術です。こちらは、ユーザーからのリクエストを受け取り、先ほど述べたセマンティックビューを活用して、結果を返すSQLを生成します。
-
各種関数:ドキュメントからのテキスト抽出、画像の解析など、ドキュメントの取り扱いを容易にする多くの機能を備えています。
Cortex AgentsとSnowflake Intelligenceによるインサイト提供
組織の誰もがAIを利用できるようにするSQL拡張機能「Cortex AISQL関数」があります。これにより、テキストの分類や要約といった単純なタスクから、音声の文字起こしや画像の比較といった高度なタスクまで実行できます。このAISQL関数群を進化させ続けており、構造化データ、非構造化データ、マルチモーダルデータを問わずAIを活用できます。

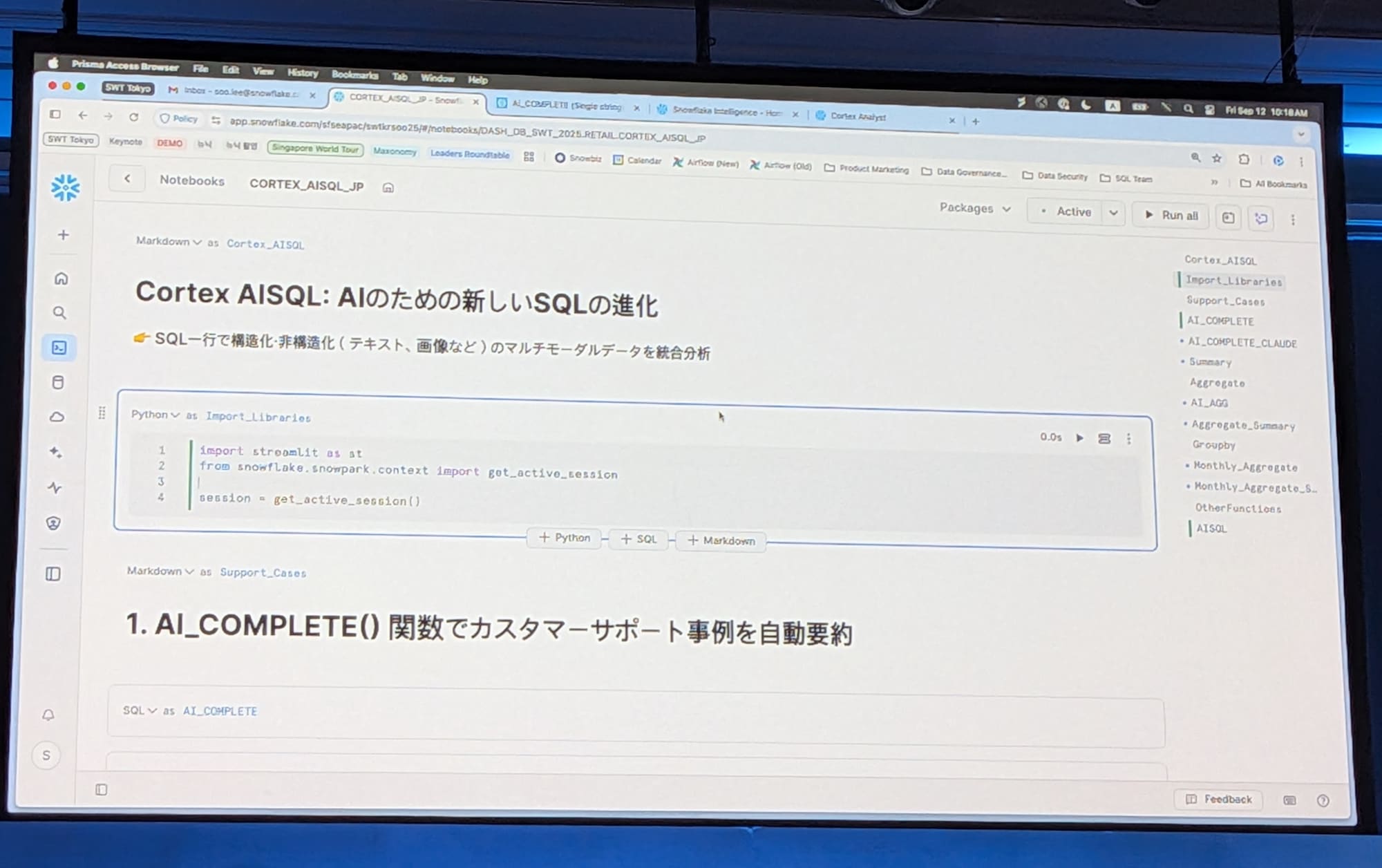
スー リー 氏からデモンストレーション

以下の内容をデモンストレーション
AISQL関数を使って、非構造化データをより良く活用する方法- 自然言語でデータに質問し、分析する方法 (Snowflake Intelligence)
- セマンティックモデル を使って、ビジネスの一貫性を管理する方法

AISQL関数
多くの企業が非構造化データの活用を検討しており、驚くべきことに、企業データの約80%は非構造化データで構成されていると言われています。
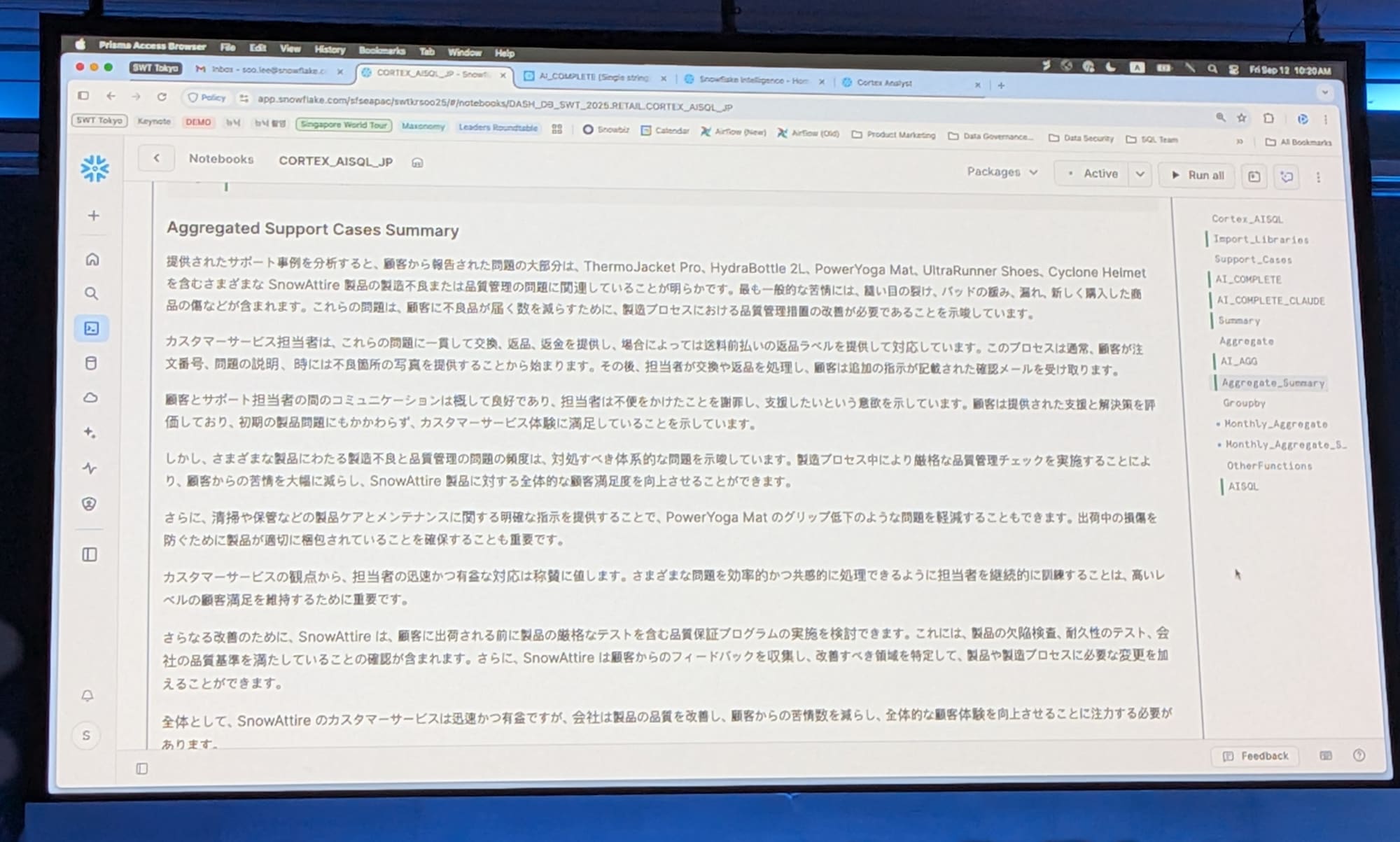
例として、非構造化データである通話記録に対してCOMPLETE関数を使用します。必要なパラメータは2つで、モデル名とプロンプトです。ここでは「2つの段落で要約してください」とリクエストしました。
実行すると、左側に元の記録、右側に要約が表示されます。
※実行結果の写真撮れていませんでした。
SUMMARIZE関数について、このパラメータはデータとプロンプトの2つを挿入し、今回は「5000文字以上で要約を作成してください」と指示しました。
実行結果例
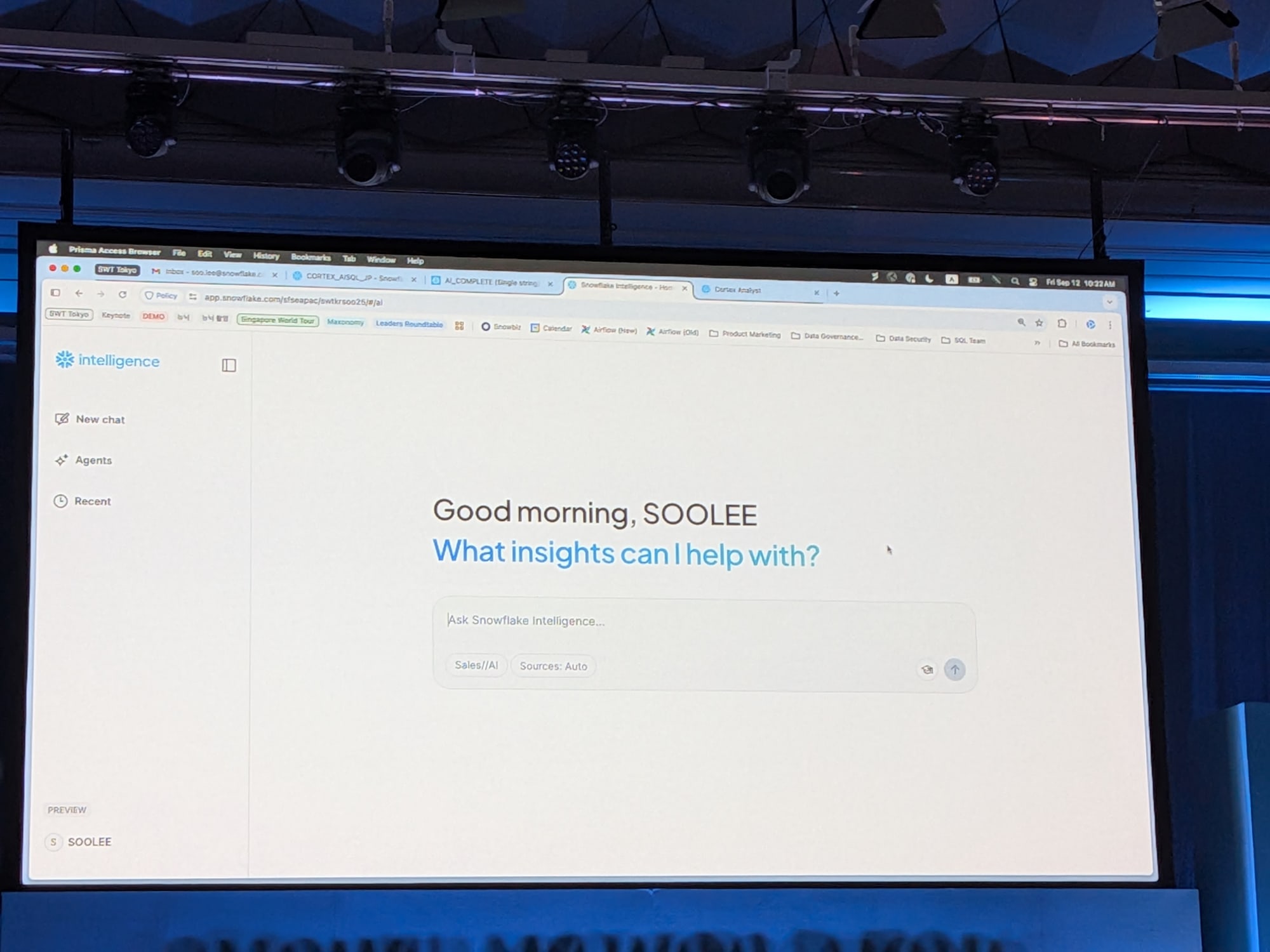
Snowflake Intelligence:セマンティックモデルを使用し自然言語でデータと対話する
Snowflake Intelligenceは、Snowflakeによって完全に管理・信頼・保護された、新しい対話型のAIエクスペリエンスのためのUIです。自分だけのAIエージェントを持ち、構造化データだけでなく非構造化データ、さらには外部ツールやカスタムツールなど、様々なソースに接続できます。
添付のように自然言語での問いに回答を出します。
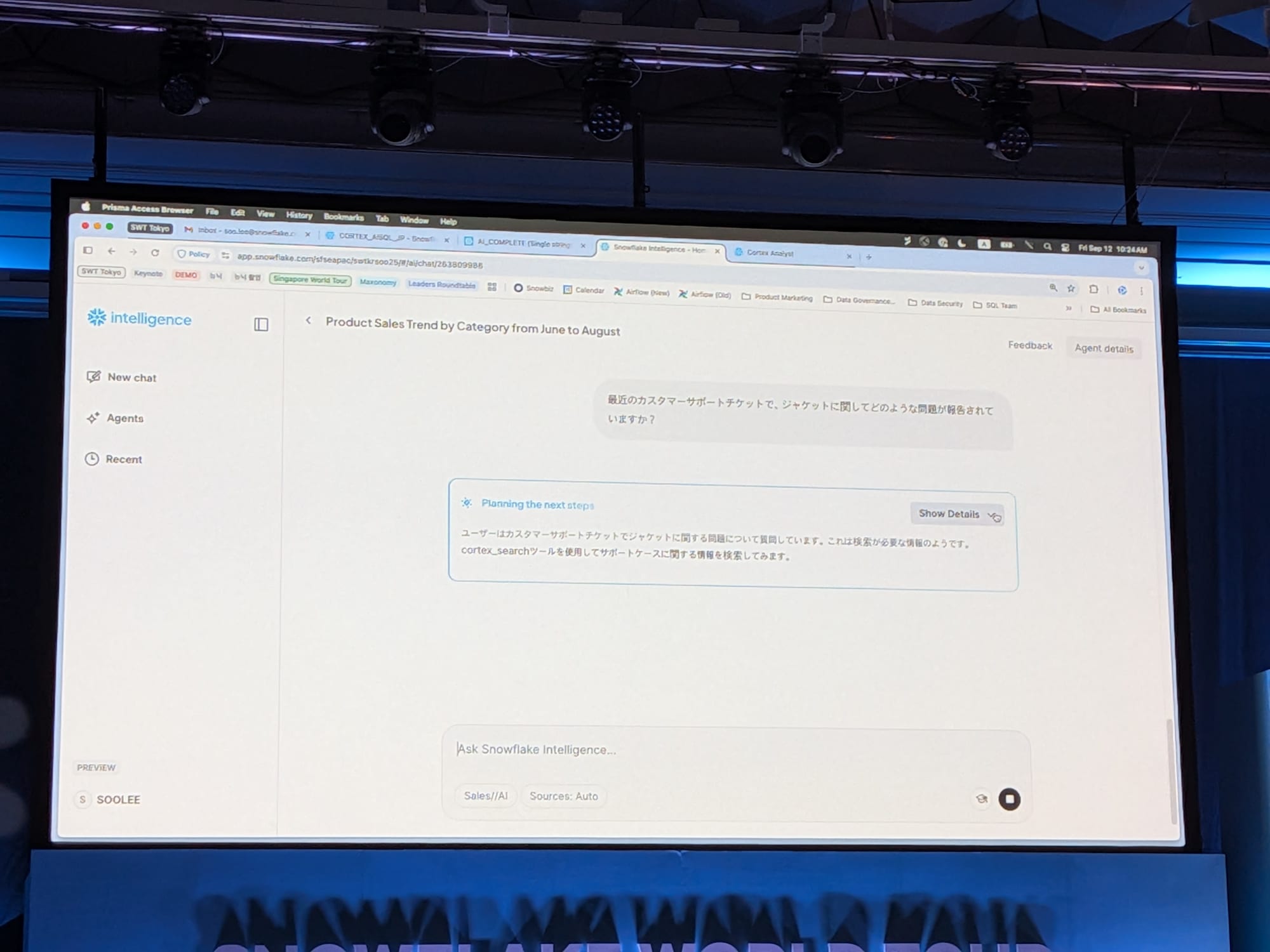
たった1行のコード、自然言語だけで、非構造化データを価値あるものに変換し、ビジネスに活用できます。
再びクリスチャン・クライナマン 氏から
データ統合:ライフサイクル全体をシームレスに
Snowflakeは、データが生成されてから、取り込み、変換され、インサイトや分析、そしてAIのために活用されるまでのライフサイクル全体を支援したいと考えています。
Snowflake OpenflowはApache NiFiをベースにしたマネージドプラットフォームで、様々なソースからのデータ抽出ワークフローを構築するのに役立ちます。
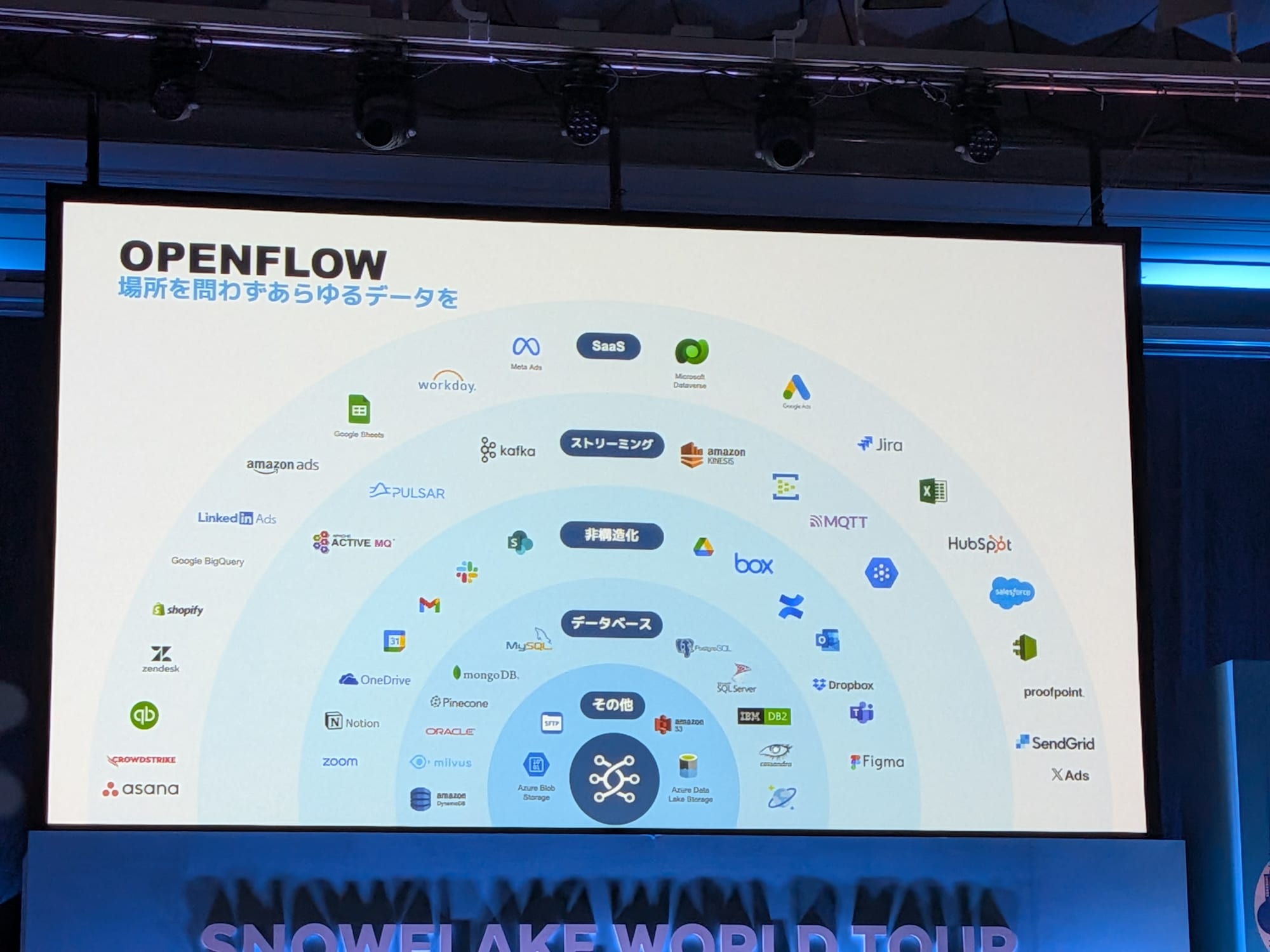
データを抽出しSnowflakeにストリーミングしたいケースについて、ストリーミングソリューションであるSnowpipe Streamingがあります。
最新版では、単一のデータストリームで毎秒10メガバイトを簡単に取り込むことができ、5秒から10秒というオーダーでクエリ可能な状態になることです。

トリスタン・ハンディ氏から

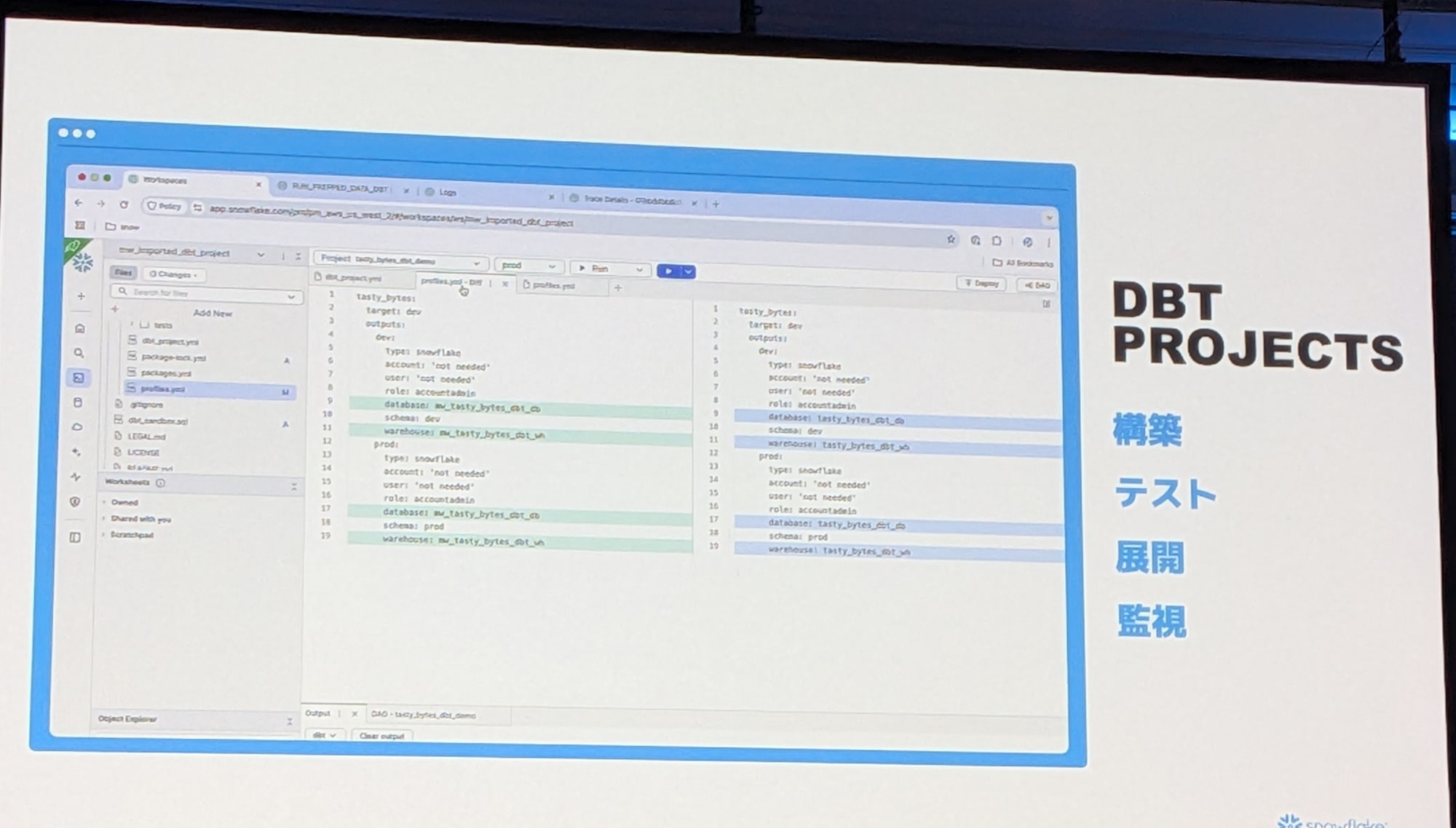

Snowflake Native dbt Projectが実現するスケール
データパイプラインをマイクロサービスのように扱うための dbt Mesh のような機能を構築し、dbt Core のパフォーマンスを向上させ、そしてSnowflakeのDynamic Tablesのようなストリーミング機能もサポートしてきました。
AI時代におけるdbtの役割
- AIとエージェントは、高品質なデータパイプラインの構築を信じられないほど加速させる。
- dbtは構造化データに関するコンテキストをAIに与えます。セマンティックレイヤーや
dbt Explorerを通じてAIやエージェントに提供します。
さらに、AWS東京リージョンをローンチするとのことです!
再びクリスチャン・クライナマン 氏から
パフォーマンスの進化:Gen 2ウェアハウス
Gen 2ウェアハウスについて、前世代のウェアハウスと比較して、一部のワークロードは2.1倍高速に、データ変換ワークロードは1.9倍高速に実行されることを確認しました。

コラボレーションの促進:Marketplaceの活用

Internal Marketplaceは組織内の個人がデータプロダクトやStreamlitアプリケーションを公開できる場です。公開されると、組織内の他の人がそれを発見し、再利用し、応用することができます。
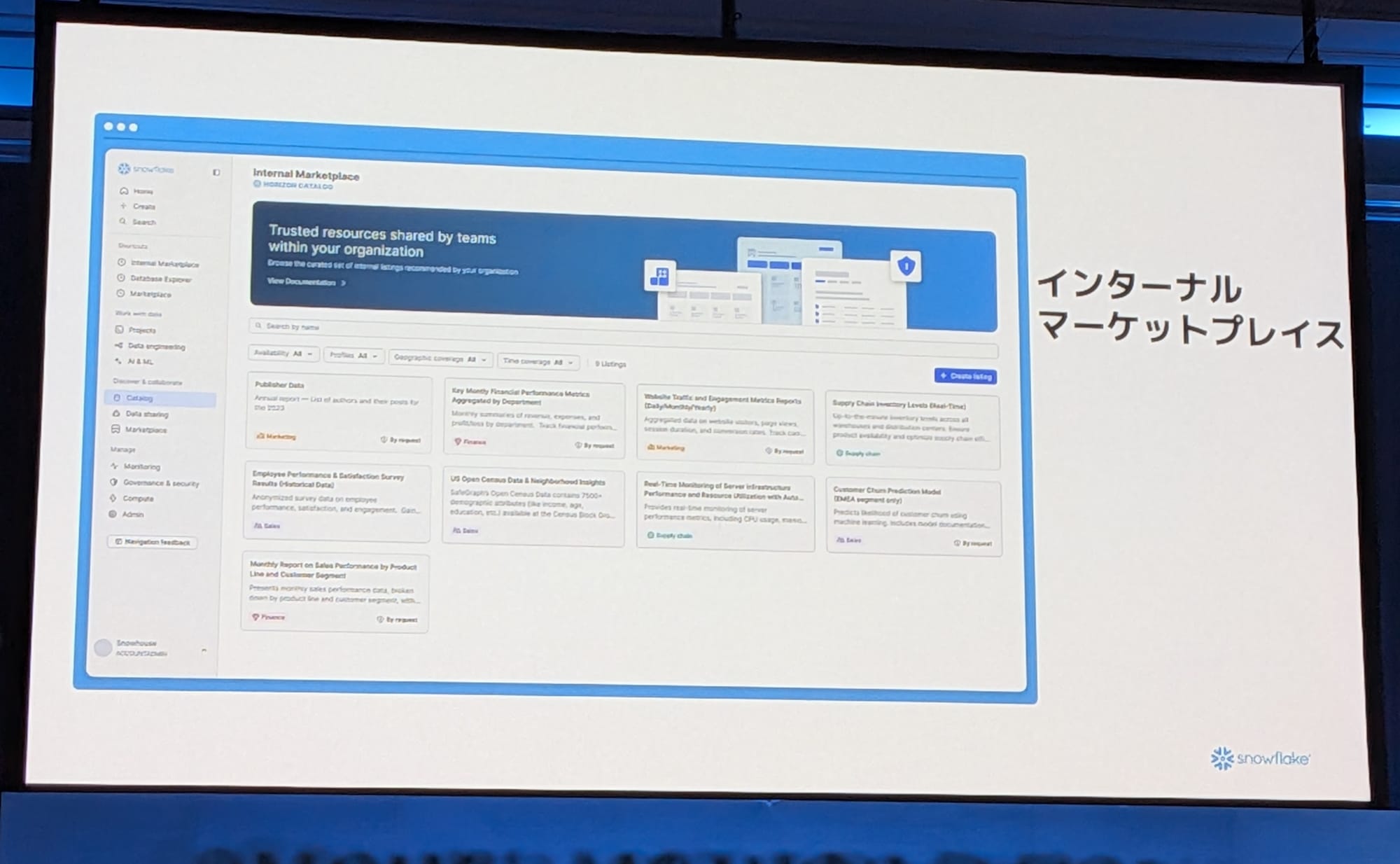
Snowflake Marketplaceは他の組織とコラボレーションするための場です。商用ベンダーからデータやアプリケーションを購入したり、無料のデータセットを活用して自社の分析に役立てたりすることができます。
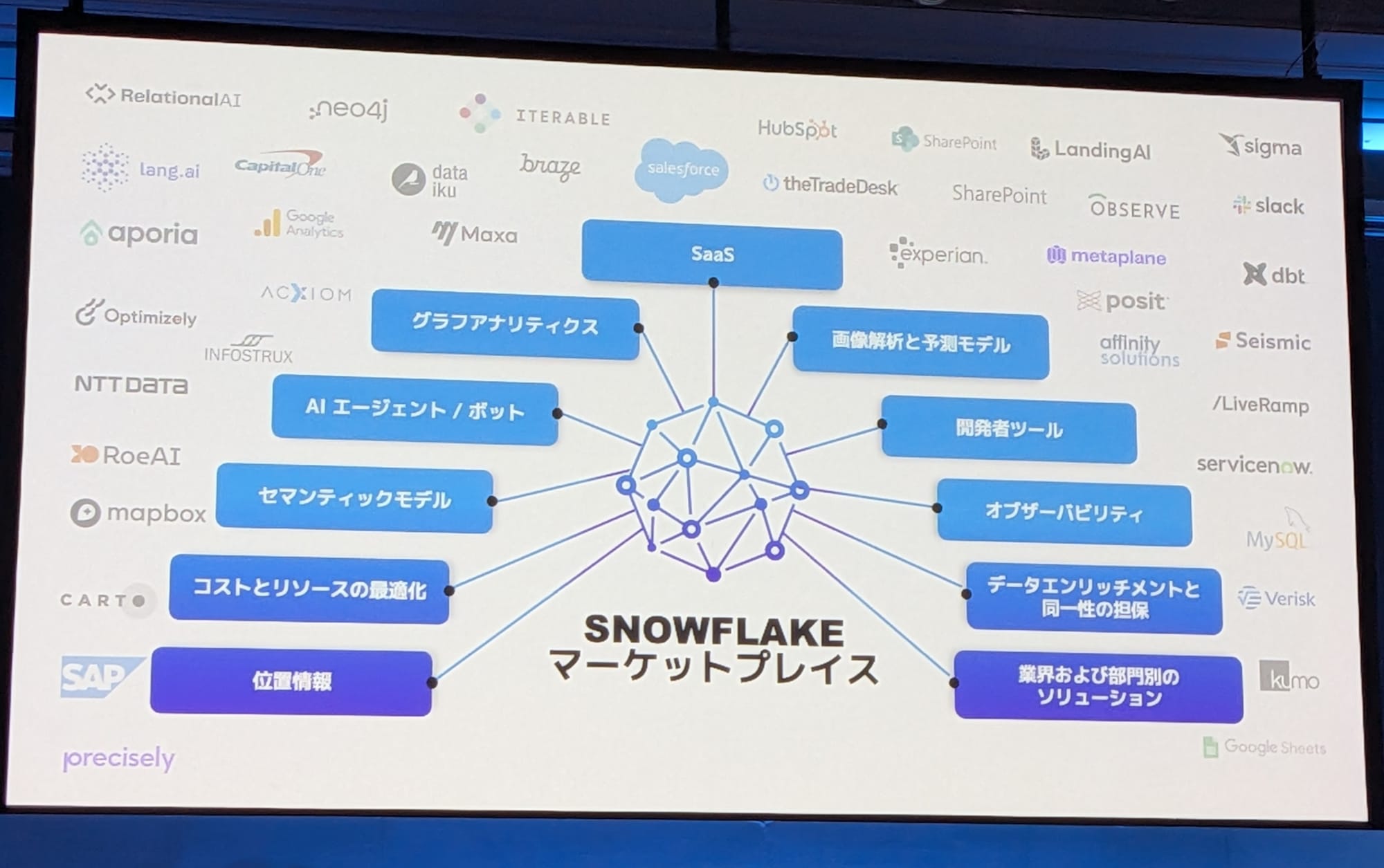
Snowflakeは、単一の統合データプラットフォームを提供することに強みがあります。
データで価値を創造するという皆様の重要なタスクを、シンプルで簡単にしたいのです。

Snowflakeは、単一のアーキテクチャがリージョンやクラウドをまたいで機能します。

データ:構造化、非構造化、そしてオープン性
特定のテクノロジーにロックインされることを望まないお客様のために、Apache Iceberg 標準に多大なエネルギーを注いでいます。さらに、真にオープンソースなカタログであるPolaris Catalogをインキュベートし、Apacheソフトウェア財団に寄贈しました。

新発表:Snowpark Connector for Apache Spark
Snowpark Connector for Apache Spark の提供を発表します。
これまでSnowparkは、Sparkユーザーには馴染みのあるデータフレームAPIを提供していましたが、完全な互換性はありませんでした。しかし、Spark自体が Spark Connectという、リクエストを異なるバックエンドに送るためのAPIを導入し、Spark ConnectからのリクエストをSnowparkで処理するようにしました。APIの互換性を保ちながら、バックエンドでは平均して10倍以上高速なSnowparkの処理能力を活用できます。

AI:Snowflakeプラットフォーム自身への組み込み
AIを活用してSnowflakeのあらゆる側面をより良く、よりシンプルにしています。
データサイエンスを容易にするエージェント、ガバナンスを簡素化するSnowflake Horizonの運用を助けるCopilot、ノートブック内でのコーディングを支援するインラインCopilotなど、多くの機能があります。

Snowflake Horizon Catalog
Horizonは、コンプライアンス、セキュリティ、プライバシー、データセットのディスカバリー、そしてコラボレーションといった機能を網羅しています。
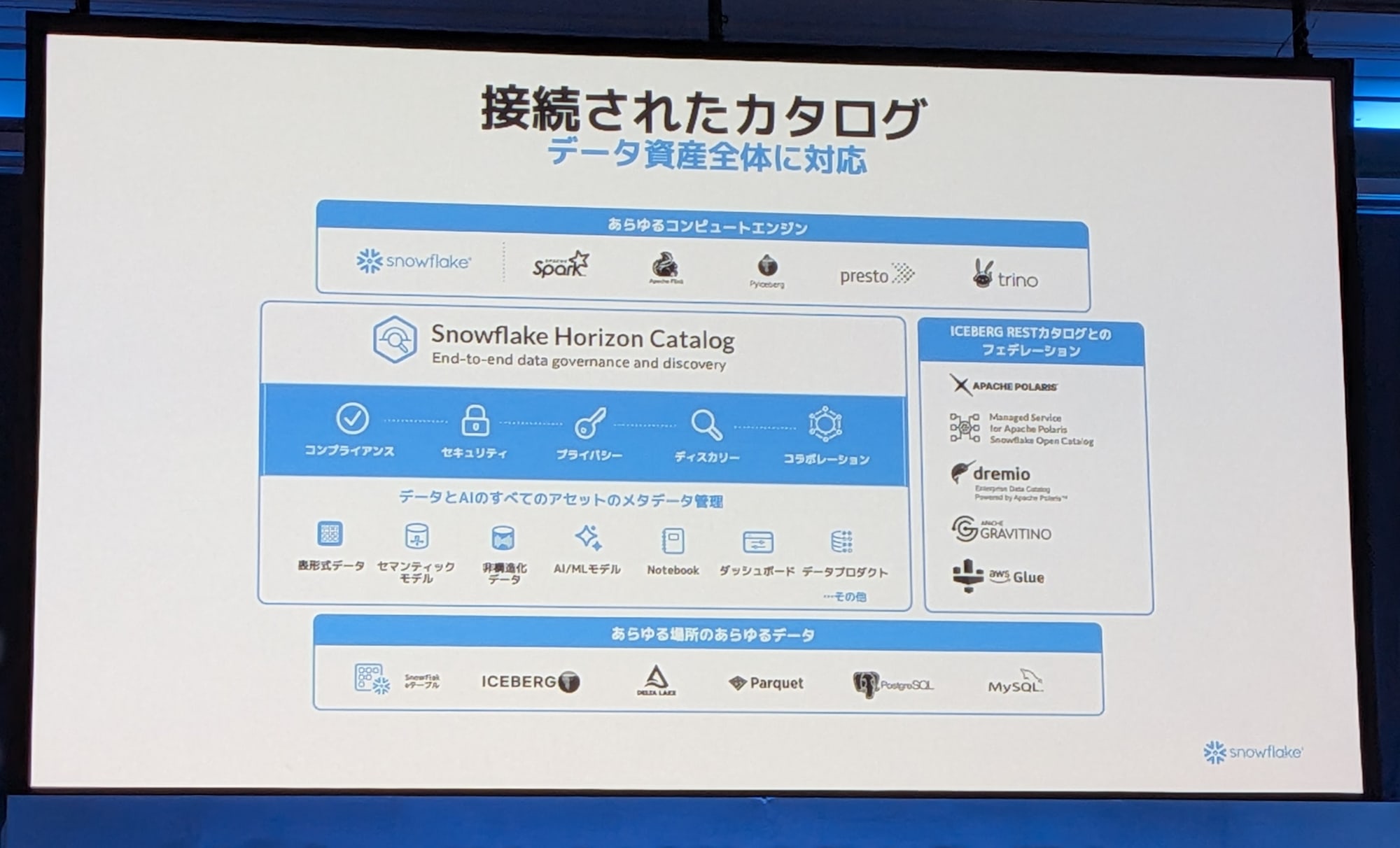
機密データの管理

リスク検知
パスキーや認証アプリの追加など、認証メカニズムの革新も続けています。これらすべてがHorizonの一部であり、皆様のデータセキュリティを確保しています。

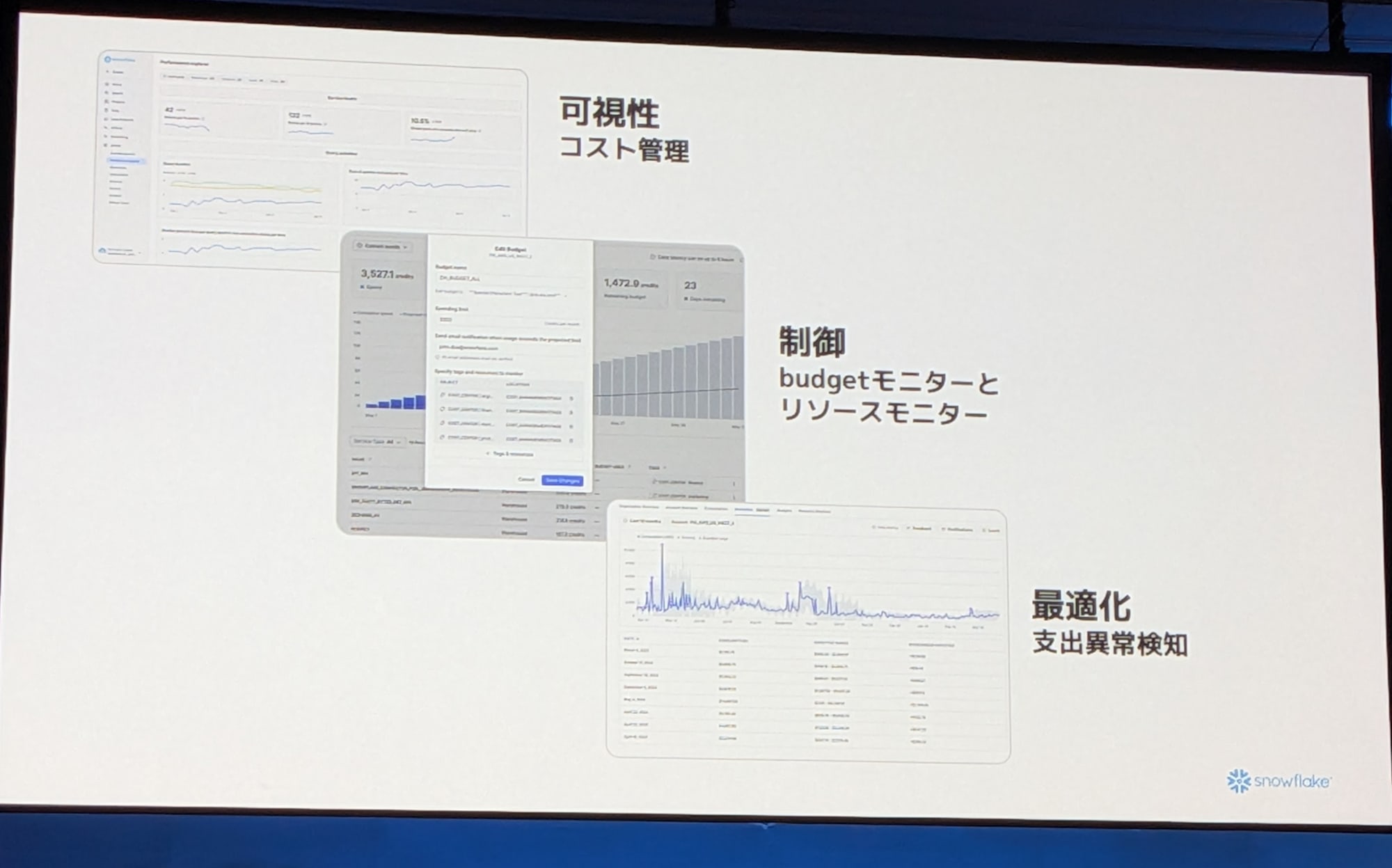
コスト管理:可視性とコントロール
添付のスライドのようにコストを可視化することや、どのタイミングで支出に異常が出たのかを検知しコスト管理することが可能です。
まとめ:AIデータクラウドが拓く未来
「AIを活用したい」「より速く結果を出したい」「将来のニーズに対応できるアーキテクチャを構築したい」という願望を、Snowflakeは現実に変えたいのです。
「データがより価値を生む」

NTTドコモ 佐藤 隆明 氏から

ご経歴

NTTドコモの強みとデータ循環戦略
NTTドコモの強み
- 1億を超える会員基盤
- リアルタイムで新鮮なネットワークデータ
- 位置情報やdポイントといった決済情報
多面的なデータを連携させることで、お客様の行動や関心を深く理解し推測することが可能。
さらに、パートナー様のデータやAIを掛け合わせることで、新しい価値の創造を目指している。

NTTドコモのデータ基盤
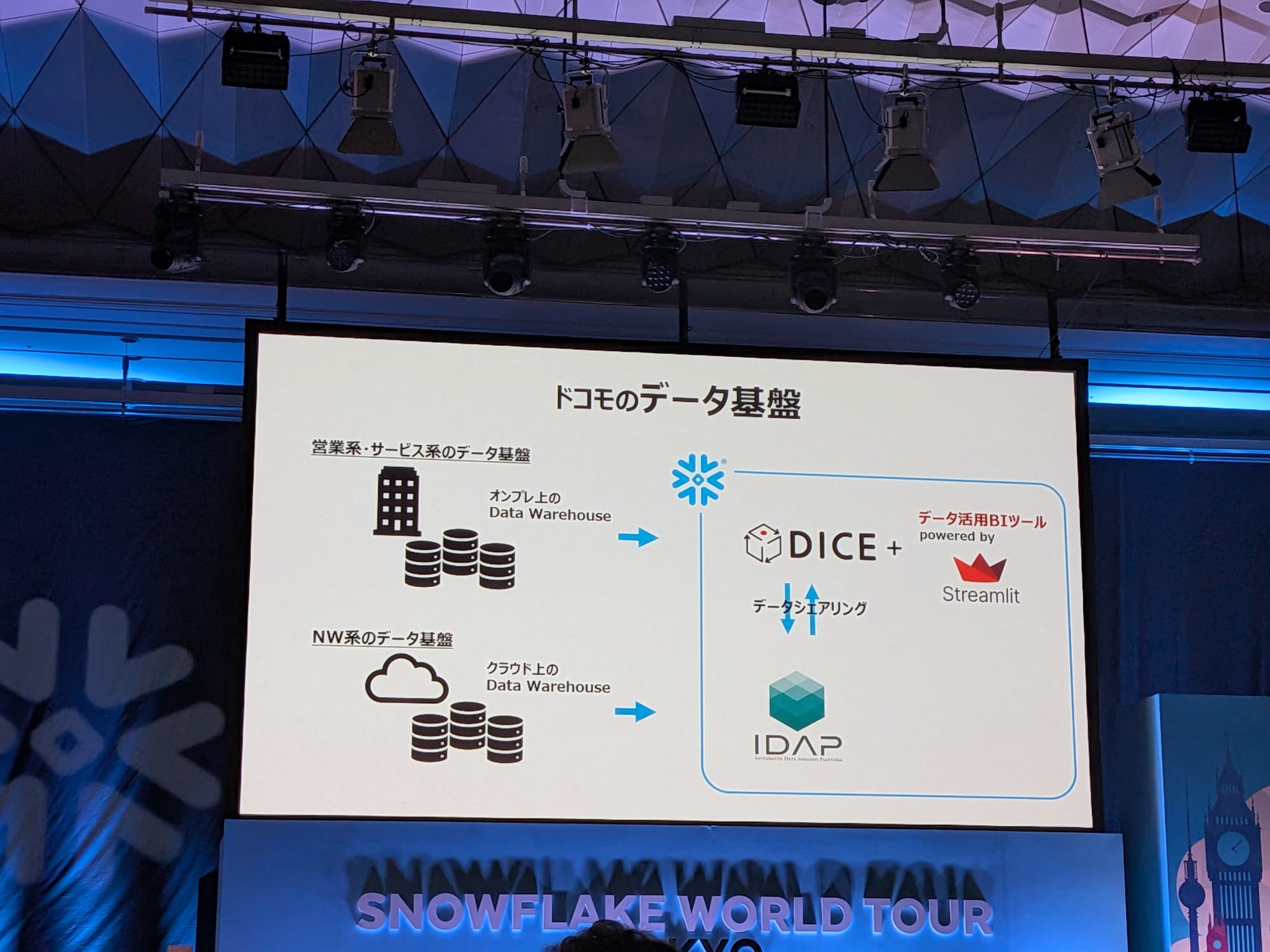
「守り」から「攻め」へ転換する筋肉質な基盤
- 「保守の効率化」:従来は巨大で複雑な基盤だったため、保守や障害対応に多くの時間と稼働を要していました。Snowflake導入後は、その「守り」の業務から解放された。
- 「コストの見える化」:従来はどのプロジェクトがどれだけコストを使っているか正確に分かりませんでした。これが解消され、プロジェクト単位で利用状況を把握し、投資対効果(ROI)を議論することが可能に。
- 「処理の高速化」:従来は複数の処理が競合すると速度低下が発生していましたが、Snowflakeのストレージとコンピュートが分離したアーキテクチャにより、これが解消されました。

BIツールによるデータ活用の民主化
-
Snowflake基盤の上にStreamlitを活用したBIツールを自社開発しGUI操作で簡単にデータ抽出、分析、可視化が可能になり、業務のスピード感が格段に向上しました。
-
特徴的なツールが生まれた秘訣は、【現場社員とデータサイエンティストが協働】し、現場のリアルな課題に基づいて開発していることがポイント。
-
現在では127個のBIツールが生まれ、利用者数(MAU)は約4,700人、年間利用回数は82万回に達しています。

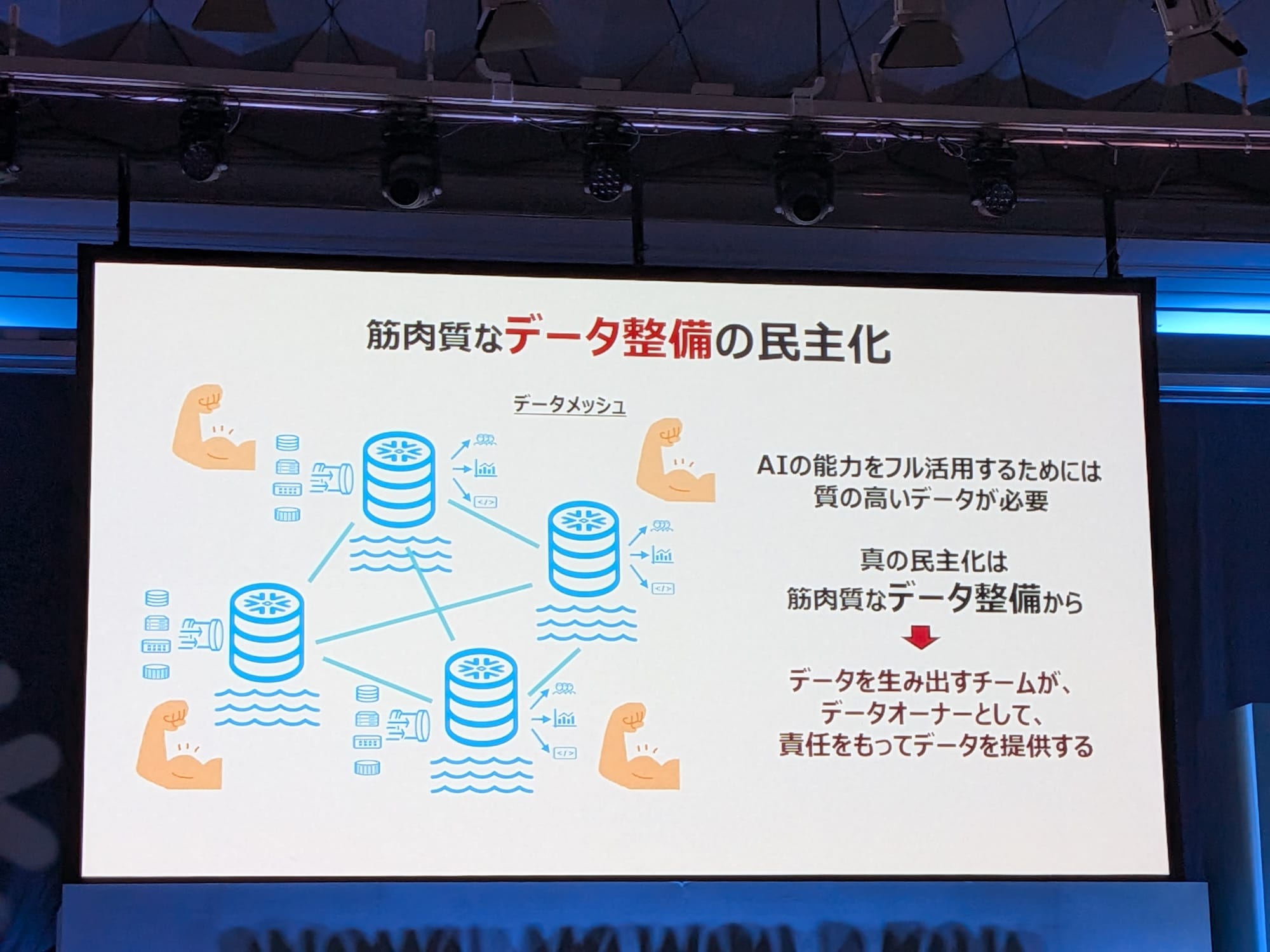
真の民主化の鍵となる「データメッシュ」
データ活用の民主化を大規模に展開するためには、データ整備と品質が非常に重要です。
データメッシュという考え方から真の民主化が始まると考えており、これはデータを生み出す現場チーム自身がデータオーナーとなり、品質と提供に責任を持つ仕組みです。
「人が使う基盤」から「AIが使う基盤」へ

AIが利用するデータ基盤
- 更なるリアルタイム化
- マルチモーダルな統合判断
- AIエージェントによる自律化

現状のAIは、「良いハサミ」です。
AIが単独でゼロから真の満足を生み出すにはまだ限定的です。重要なのは、「信頼できるデータ」、そして「人間の課題認識力、想像力、エンゲージメント」です。


所感
Day1のKEYNOTEでも話されていましたが、AI時代におけるデータ基盤の重要性を改めて感じました。
NTTドコモ様のたとえに出ていた「良いハサミ」を活かすためにもその材料や工程が重要になってくると思いました。
また、Snowflakeをはじめ様々な機能がリリースされるなかで、これらを活かすためにも現場の課題感の理解が不可欠だと思います。
ソフト面とハード面の両軸を捉えて進めていくことが何よりも大切であると改めて気づかされました!









