
Snowflake Quickstartの「Snowflake入門 - ゼロからはじめるSnowflake」を行いながらSnowsightの新UIを確認してみた
かわばたです。
Snowflake Quickstartの「Snowflake入門 - ゼロからはじめるSnowflake」を試していきます。
このセッションの中に、Snowflakeのユーザーインターフェース(Snowsight)を確認する項目がありますが、直近で新しくなっているので確認しながら進めていきたいと思います。
【Snowflake Quickstartドキュメント】
アジェンダ
- 概要
- ラボ環境の準備
- Snowflakeのユーザーインターフェイスとラボストーリー
- データロードの準備
- データのロード
- クエリ、結果キャッシュ、クローンの操作
- 半構造化データ、ビュー、結合の操作
- タイムトラベルの使用
- ロール、アカウント管理者、アカウント使用状況の操作
- データの安全な共有とマーケットプレイス
- Snowflake環境のリセット
- まとめ
概要
前提条件
- Snowflakeトライアル環境の使用
- かわばたはEnterprise版を使用しています。
- SQL、データベース構想、オブジェクトについての基本知識
- CSVカンマ区切りのファイルおよびJSON半構造化データに精通していること
とドキュメントに記載があります。
学習内容
- ステージ、データベース、テーブル、ビュー、仮想ウェアハウスの作成方法
- 構造化データおよび半構造化データのロード方法
- テーブル間の結合を含む、Snowflake内のデータに対する分析クエリの実行方法
- オブジェクトのクローン方法
- タイムトラベルを使用してユーザーエラーを元に戻す方法
- ロールおよびユーザーを作成し、権限を付与する方法
- 他のアカウントと安全かつ簡単にデータを共有する方法
- Snowflakeマーケットプレイスでデータセットを利用する方法
ラボ環境の準備
こちらのセクションではトライアルアカウントの登録方法となります。
上記URLから該当項目を入力し進めていきます。
Snowflakeエディションは最も人気のあるEnterprise版をQuickstartでは推奨しています。
Snowflakeのユーザーインターフェイスとラボストーリー
このセクションではSnowflakeのUIについて説明を行っていきます。
※各項目でどのようなことが可能か記載していきますが、かわばたが把握していない項目もあるため簡単な解説となります。
-
ログイン画面のUI。登録時に指定したユーザー名とパスワードを入力します。
-
Snowflakeのホーム画面。ドキュメント時とUIに差異があります、2025年9月17日時点のものです。
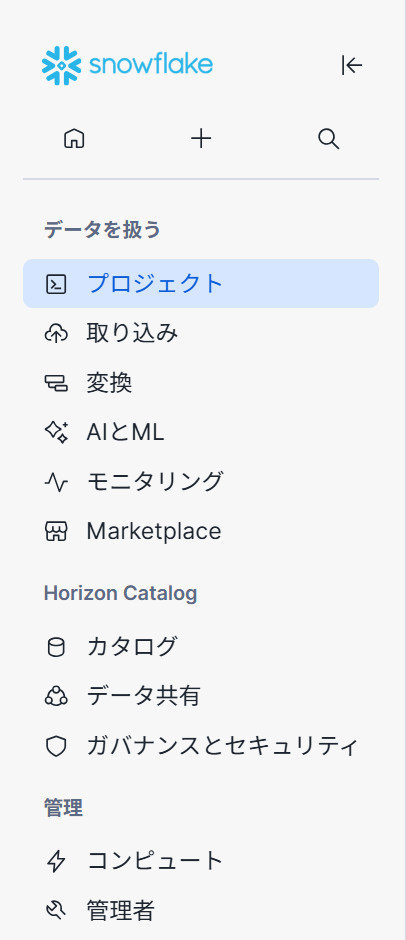
各項目について簡単に解説します。
プロジェクト
ワークシート
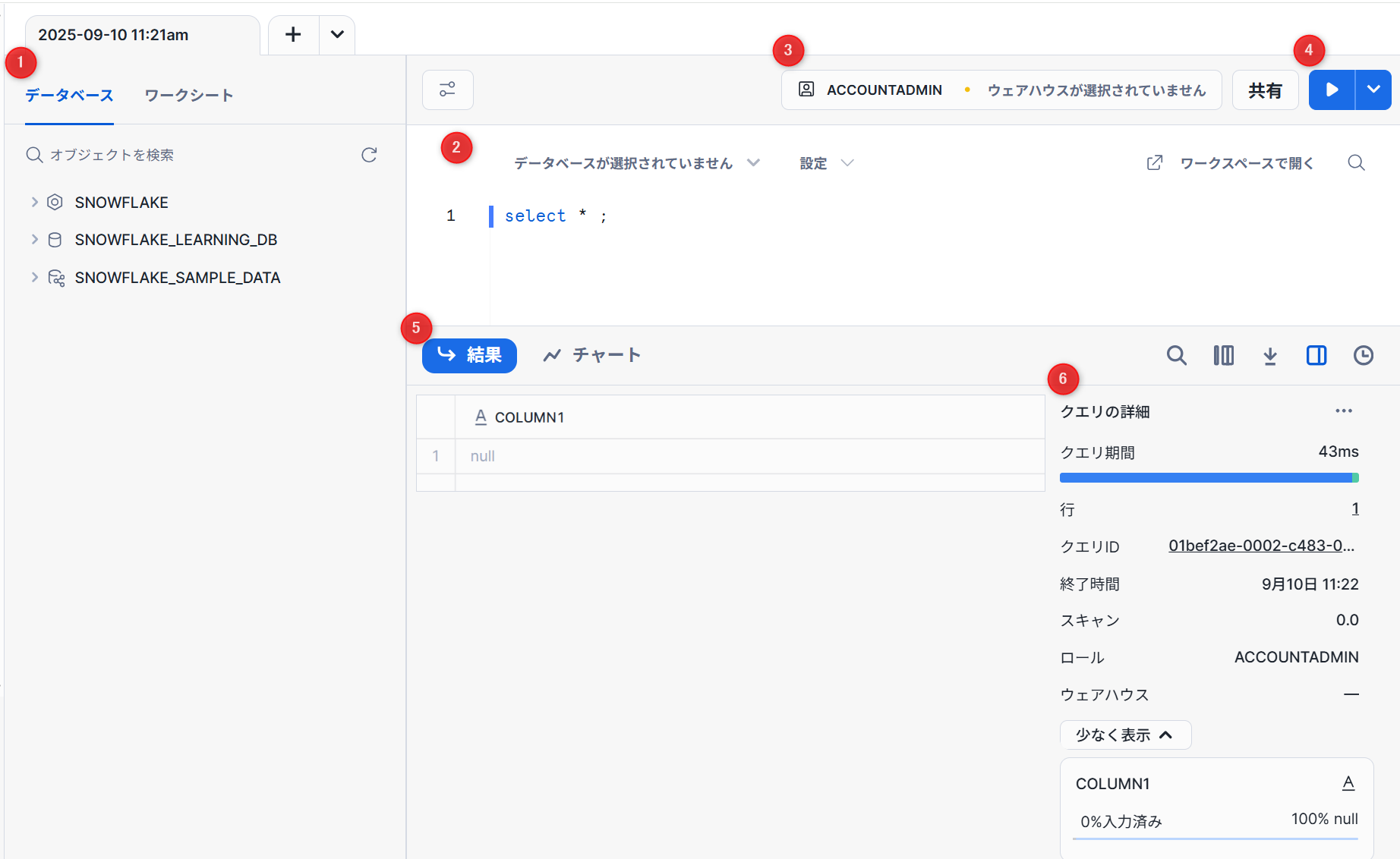
ワークシートは、Snowflakeプラットフォーム内で SQLクエリやPythonコードを実行したり、その他のSnowflakeデータのロード、定義、操作タスクを実行したりするための強力で汎用性の高い方法を提供します。
-
データベース・ワークシート:データベース等のオブジェクトを確認したり、ワークシートを管理したりできます。
※ワークシート名は、ワークシート作成時のタイムスタンプとなります。 -
クエリおよびその他のSQLステートメントを入力および実行する一般的な作業領域です。
-
使用するロールとウェアハウスの設定できます。
-
クエリの実行。すべて実行することも可能です。
-
クエリ結果を確認できます。チャートタブではワークシートデータの視覚化を行うことができます。
【チャートに関するドキュメント】
- クエリ結果の詳細を確認できる画面。
- クエリ実行の期間。
- 結果内の行数。
- 実行が完了した時刻。
- クエリによってスキャンされたデータの量。
- クエリの実行に使用されるロール。
- クエリの実行に使用されるウェアハウス。
一部のクエリの詳細は、14日間のみ利用できます。
ノートブック
Snowflake Notebooks は、Python、 SQL 、Markdown用の対話的なセルベースのプログラミング環境を提供する、 Snowsight の統一開発インターフェイスです。Notebooksでは、Snowflakeデータを活用して、探索的データ分析、機械学習モデルの開発、その他のデータサイエンスおよびデータエンジニアリングのワークフローを、すべて同じインターフェイス内で実行できます。
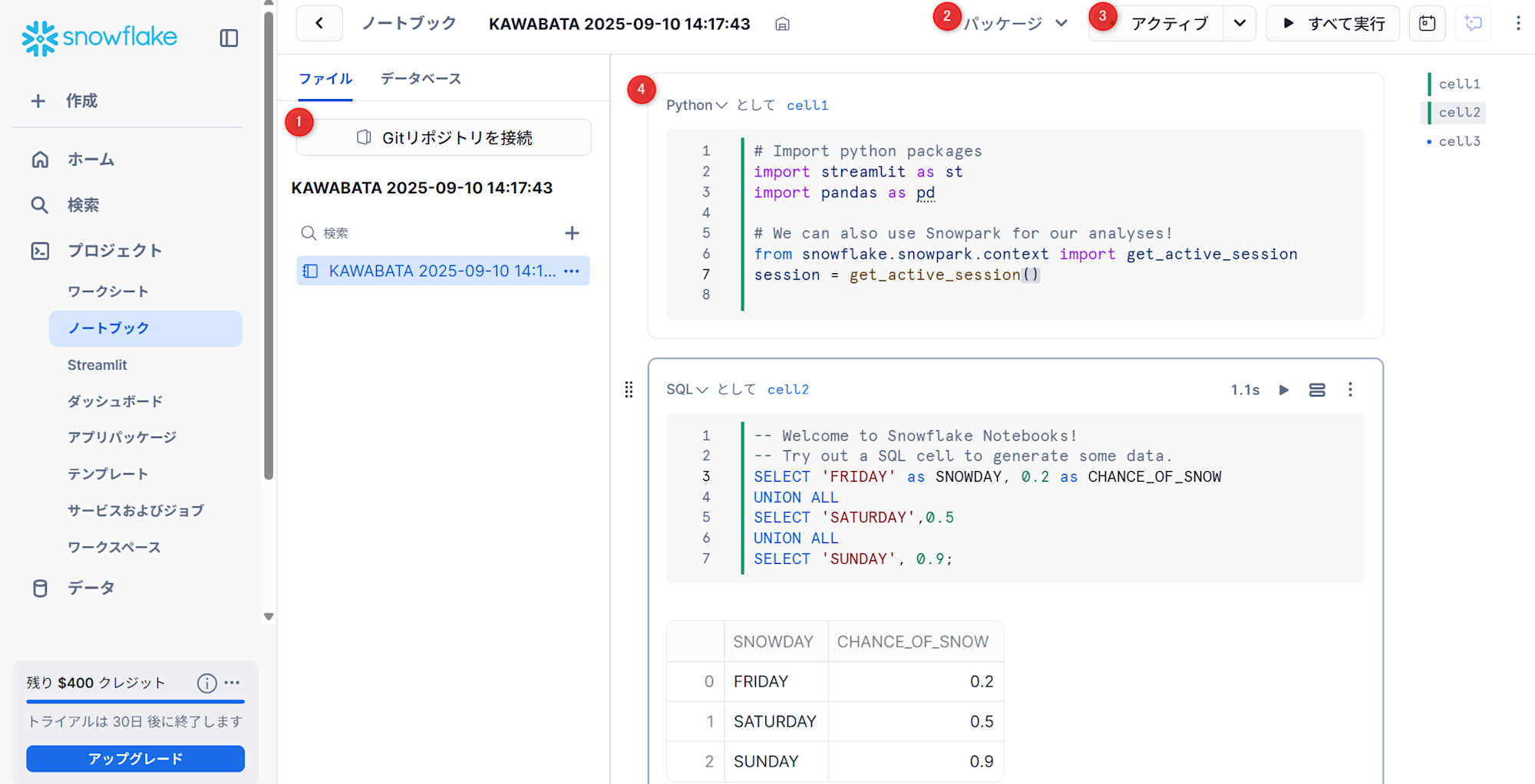
- ノートブックとバージョン管理を行うGitリポジトリを接続することが可能です。
【ノートブックとGitリポジトリの同期】
- パッケージをインストールすることができます。
- ノートブックをアクティブ化できます。ウェアハウスを起動させることになるので、使用しないときはセッションを終了することを推奨しています。
- Python,SQL,Markdownについて、セルベースで実行することが可能です。
Streamlit
Streamlit はオープンソースのPythonライブラリで、機械学習やデータサイエンスのためのカスタムウェブアプリを簡単に作成・共有できます。Streamlitを使用することで、強力なデータアプリケーションを迅速に構築し、展開することができます。
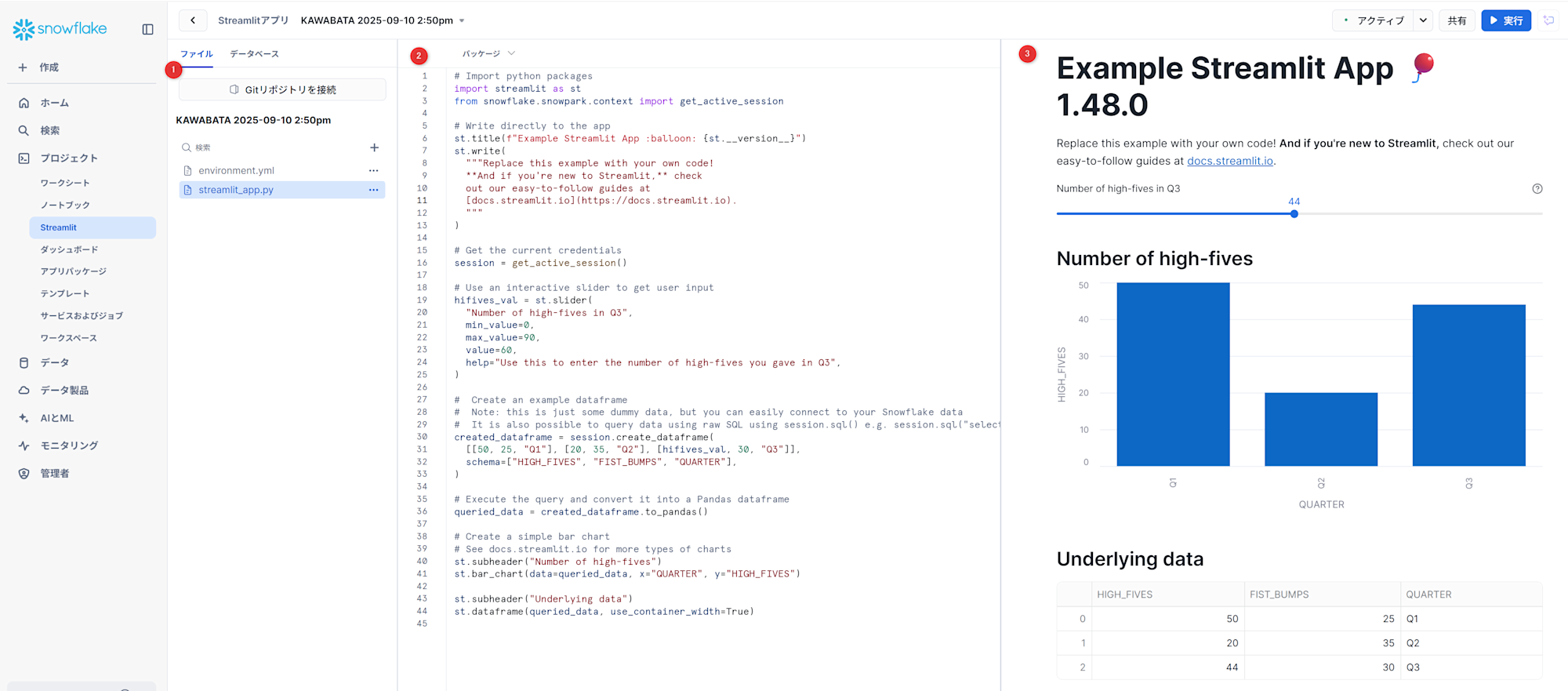
- ワークシートと同様にGitリポジトリとの連携やファイル管理をする画面です。
- 実際にエディタでコードを作成する画面です。
- 作成したアプリを実行し確認する画面です。
ダッシュボード
ダッシュボードを使用すると、Snowsightのチャートを使用してクエリ結果を視覚化し、伝達できます。ダッシュボードは、タイルとして配置されたチャートの柔軟なコレクションです。チャートはクエリ結果によって生成され、カスタマイズできます。ワークシートのチャートからダッシュボードタイルを作成することもできます。
詳細なダッシュボードの使用方法については、下記記事を参考にいただくと幸いです。
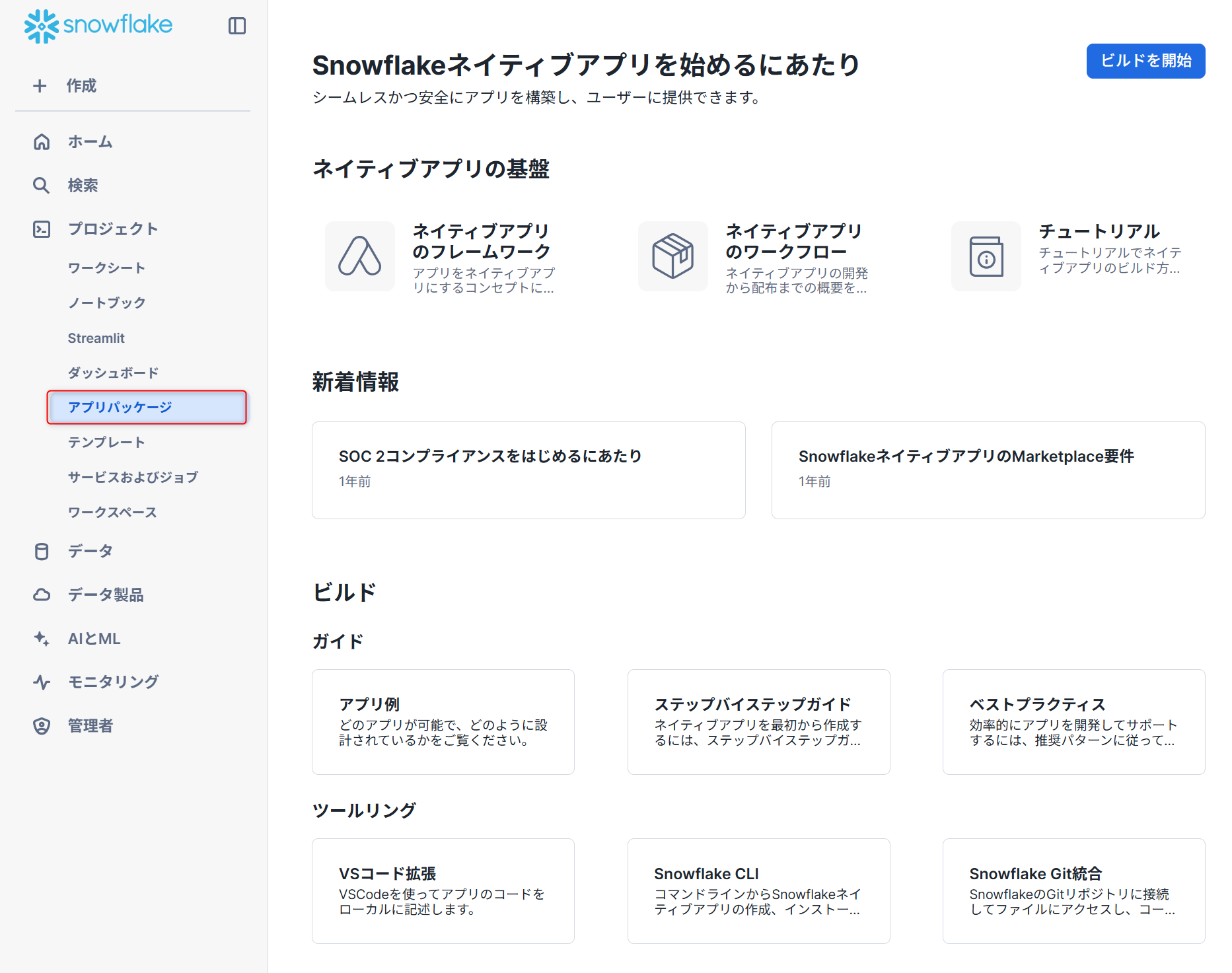
アプリパッケージ
Snowflake上で直接実行できるアプリケーション(Snowflake Native App)を開発し、配布・販売するための仕組みです。開発者(プロバイダー)が作成したアプリケーションを、利用者(コンシューマー)がSnowflakeマーケットプレイスなどを通じて入手し、自身のSnowflakeアカウント内で直接利用できます。
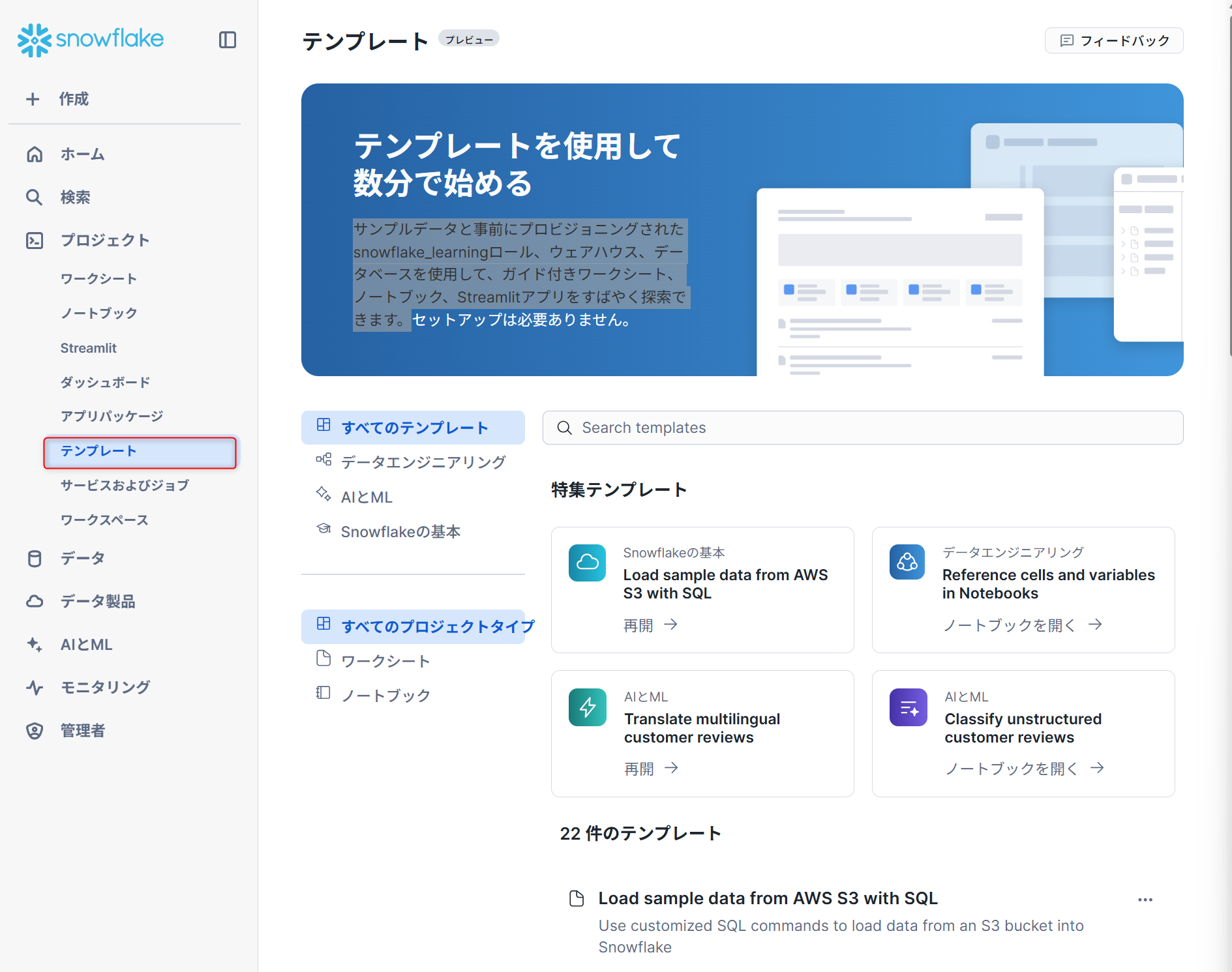
テンプレート※プレビュー版
サンプルデータと事前にプロビジョニングされたsnowflake_learningロール、ウェアハウス、データベースを使用して、ガイド付きワークシート、ノートブック、Streamlitアプリをすばやく探索できます。
ワークスペース
ワークスペースは、データ分析、モデル開発、パイプライン構築に使用できる、複数のファイルタイプにまたがるコードを作成、整理、管理するための統一エディターを提供します。
ワークスペース はあなただけのもので、あなたの作品を構築、実験、テストできる開発環境を提供します。ワークスペースのコンテンツはすべてファイルベースになるため、より複雑なプロジェクトに取り組むことができます。Gitと容易に統合することで、バージョン管理、コラボレーション、既存ワークフローとの調整を行えます。
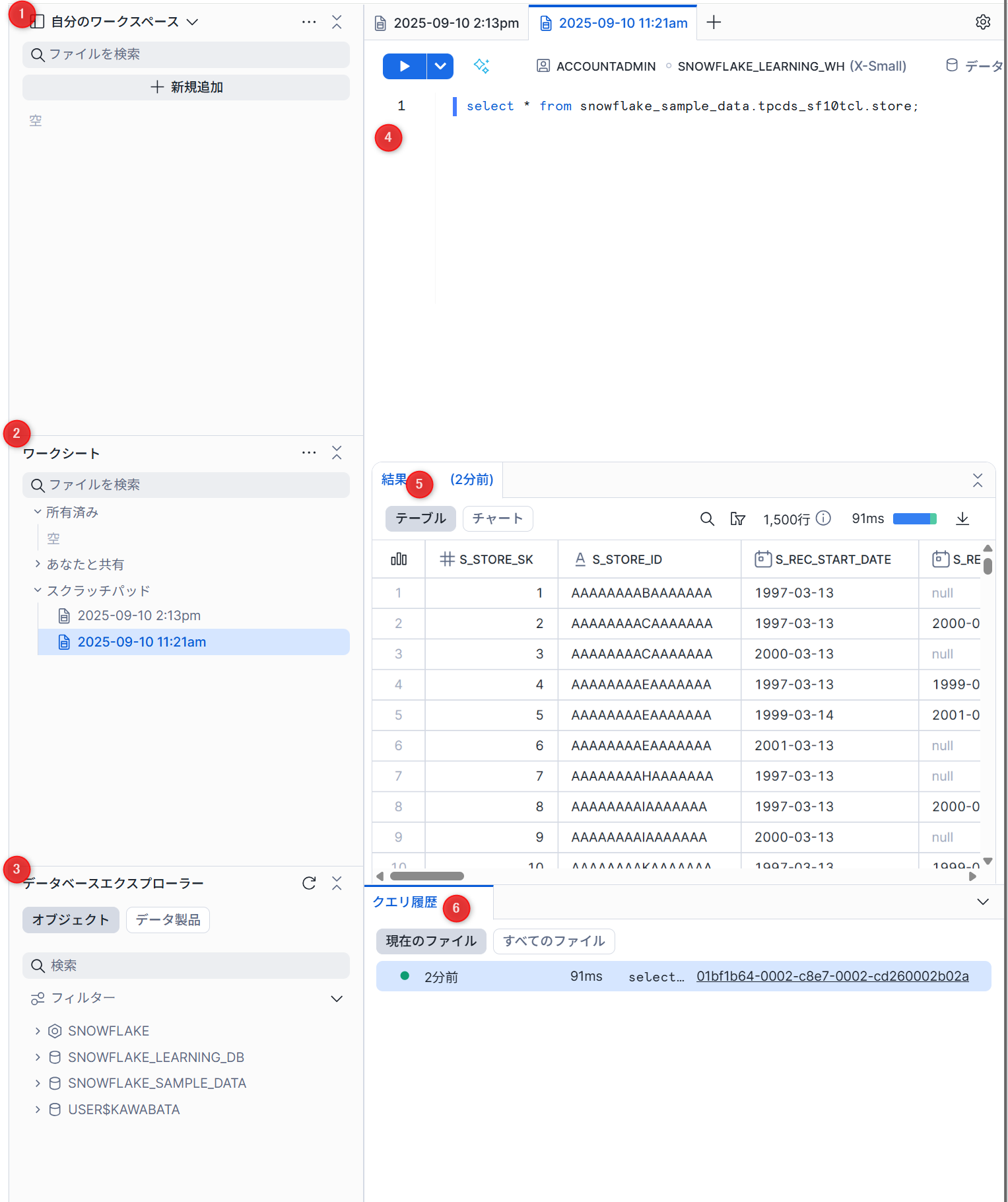
- ワークスペース: ファイルやフォルダを1つの領域で管理できます。
- ワークシート:ワークシートを開いて編集できます。
- オブジェクトエクスプローラ: アカウント内のすべてのデータベース、各データベースのスキーマ、その他のオブジェクトをタイプ別に階層表示します。
- エディター: クエリを編集し、横に分割して複数のファイルを同時に表示します。
- 結果: 結果を横に並べたり、ピン留めして簡単に比較できます。
- クエリの履歴: 実行したクエリの履歴を表示します。
取り込み
データ追加
Snowflakeにデータをロード(取り込む)するUI画面となります。データをロードする方法は様々ありますが、ここにGUIで設定できるようにまとめられています。
コピー履歴
SnowsightのCopy HistoryページまたはSNOWFLAKEデータベースのACCOUNT_USAGEスキーマのCOPY_HISTORYビュー を使用して、アカウント内のすべてのテーブルについて、過去365日間に発生したデータロードのアクティビティを確認できます。
移行
Oracle、Teradata、SQL ServerなどのプラットフォームのSQLコードをSnowflakeSQLに変換したり、Sparkのコードを SnowparkAPIに変換します
変換
dbtプロジェクト※プレビュー版
dbt Projects on Snowflakeの画面。実際の編集はワークスペースで行うが、こちらは過去一週間の履歴を確認することが出来ます。
ダイナミックテーブル
ダイナミックテーブルは、定義されたクエリとターゲットの鮮度に基づいて自動的に更新されるテーブルであり、手動更新やカスタム スケジュールを必要とせずにデータ変換とパイプライン管理を簡素化します。こちらはGUIでダイナミックの作成・確認ができる画面。
タスク
タスクはスケジュールされた時間に実行することも、ストリームに新しいデータが到着したときなどのイベントによってトリガーすることもできます。各タスクの実行状況を確認する画面。
Snowflake AI & ML Studio
Snowflake AI & ML Studio
Snowflake AI & ML Studioは、専門家でなくてもノーコードでAIや機械学習モデルの開発・活用ができるように設計された開発インターフェースです。
Cortex Analyst
Cortex Analyst は完全に管理され、 LLM-powered Snowflake Cortex 機能で、Snowflake の構造化データに基づいてビジネス上の質問に確実に回答できるアプリケーションの作成を支援します。
Cortex Search ※プレビュー版
Cortex Searchは、Snowflakeデータに対して低遅延で高品質な「ファジー」検索を可能にします。Cortex Searchは、 検索拡張世代(RAG) 大規模言語モデル(LLMs)を活用したアプリケーションなど、Snowflakeユーザーのための幅広い検索体験を提供します。
Snowflake Feature Store ※Enterprise Editionが必要。
Snowflake特徴ストアは、機械学習モデルの開発と本番運用を効率化するためのサービスです。データサイエンティストや機械学習エンジニアが、モデルの学習や推論に使用する「特徴量」を一元的に管理、共有、再利用できるようにします。
Models
モデルをトレーニングした後、Snowflakeでモデルを運用化し、推論を実行するには、まずSnowflakeモデルレジストリにモデルを記録する必要があります。モデルレジストリを使用すると、モデルとそのメタデータを、その出所や種類を問わずSnowflake内で安全に管理できます。
Evaluations
AIアプリケーションの評価
-
アプリケーションをビルドし、Trulens SDK を使用して計測します。
-
Snowflakeにアプリを登録します。
-
入力データセットを指定して実行を作成します。
-
実行を実行してトレースを生成し、評価メトリクスを計算します。
-
Snowsightで評価結果を表示。

Document AI
Document AI は、独自の大規模言語モデル(LLM)である Arctic-TILT を使用して、ドキュメントからデータを抽出するSnowflake AI 機能です。
Cortex Agents
Cortexエージェントは、構造化データソースと非構造化データソースの両方を統合してインサイトを提供します。タスクを計画し、ツールを使用してタスクを実行し、レスポンスを生成します。
Snowflake Intelligence
Snowflake Intelligence では、以下のことが可能になります。
-
自然言語を使ってグラフを作成し、瞬時に回答を得ることができます。技術的な専門知識がなくても、カスタムダッシュボードを待つことなく、トレンドを発見し、データを分析できます。
-
構造化データと非構造化データを含む数千ものデータソースにアクセスし、分析できます。スプレッドシート、ドキュメント、画像、データベースから同時にインサイトを抽出できます。
モニタリング
クエリ履歴
Snowsight のクエリ履歴ページでは、次のことができます。
-
アカウント内のユーザーによって実行される個別のクエリまたはグループ化されたクエリを監視します。
-
クエリの詳細(パフォーマンスデータを含む)を表示します。
-
クエリプロファイルで実行されたクエリの各ステップを調べます。
クエリ履歴ページでは、過去 14 日間に Snowflake アカウントで実行されたクエリを調べることができます。
サービスとジョブ
Snowpark Container Servicesは、Snowflakeエコシステム内におけるコンテナー化されたアプリケーションの展開、管理、スケーリングを容易にするように設計されたフルマネージドコンテナーサービスです。
【チュートリアル】
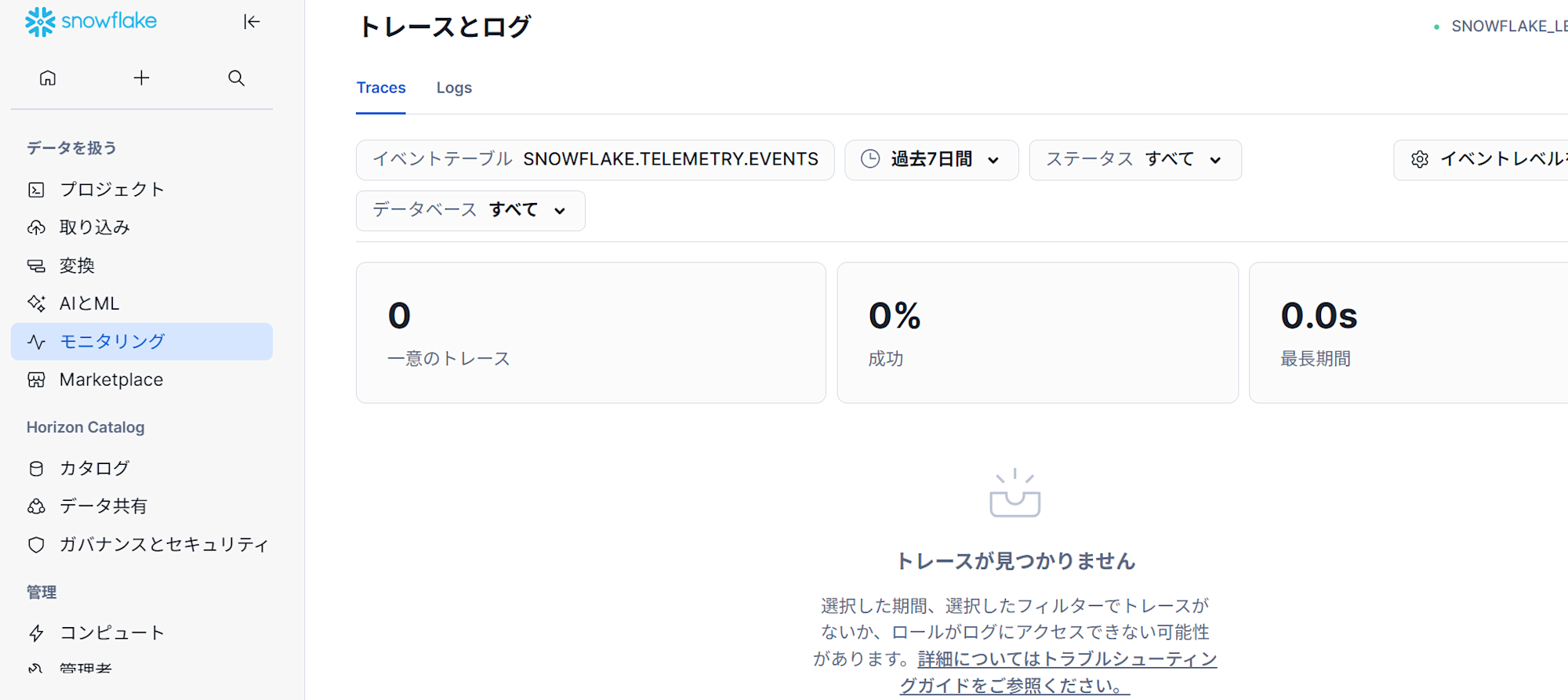
トレースとログ
プロシージャや UDFs を含むSnowflakeオブジェクトがテレメトリーデータを出力すると、Snowflakeはそのデータをイベントテーブルに収集し、そのデータはクエリで利用可能となります。
Snowflake Marketplace
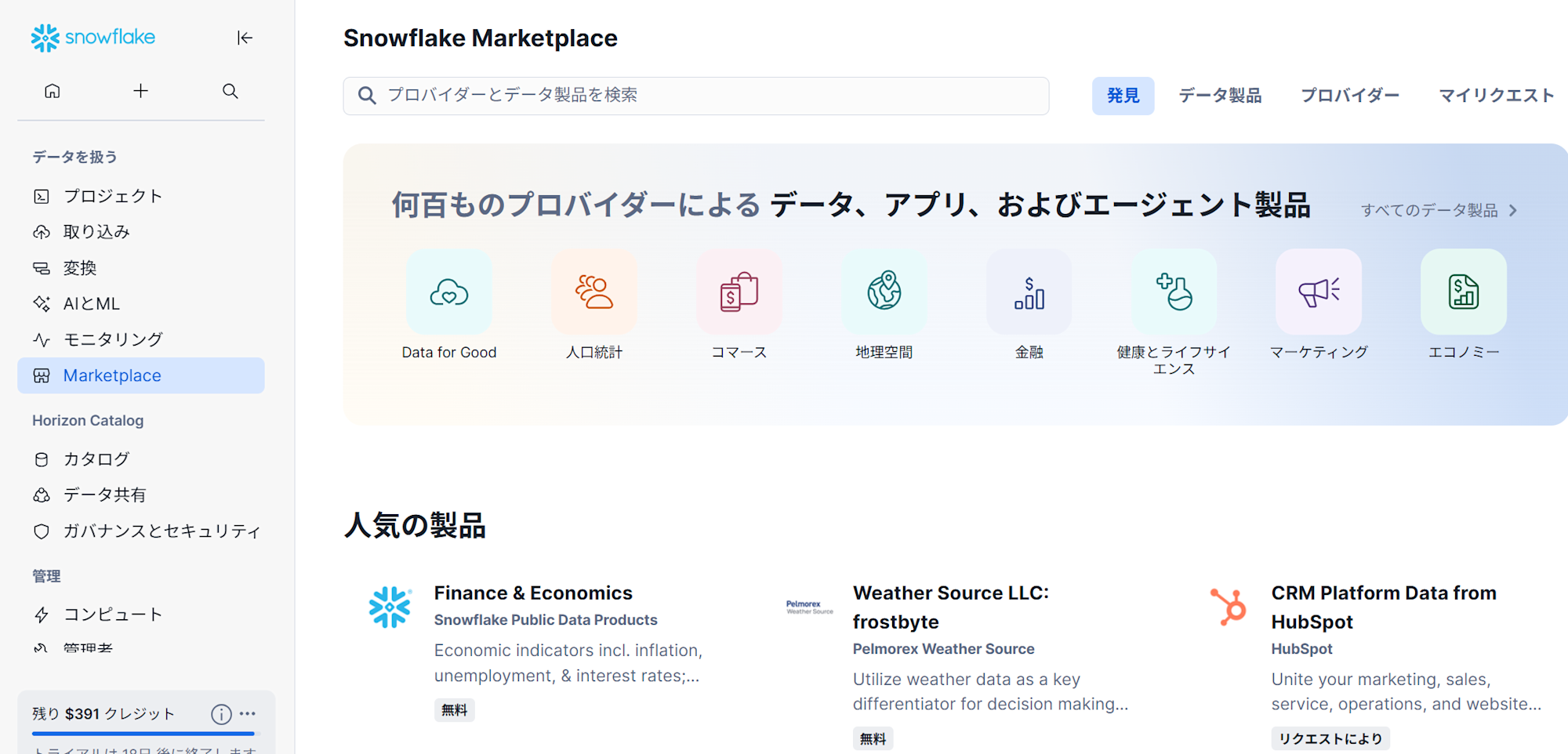
Snowflake Marketplace
Snowflake Marketplaceは、リストを探して、アクセスし、コンシューマーに提供できる場所です。 Snowflake Marketplaceを使用して、サードパーティのデータやサービスを探して、アクセスしたり、Snowflake Data Cloud全体で自社のデータ製品を売り込んだりすることもできます。
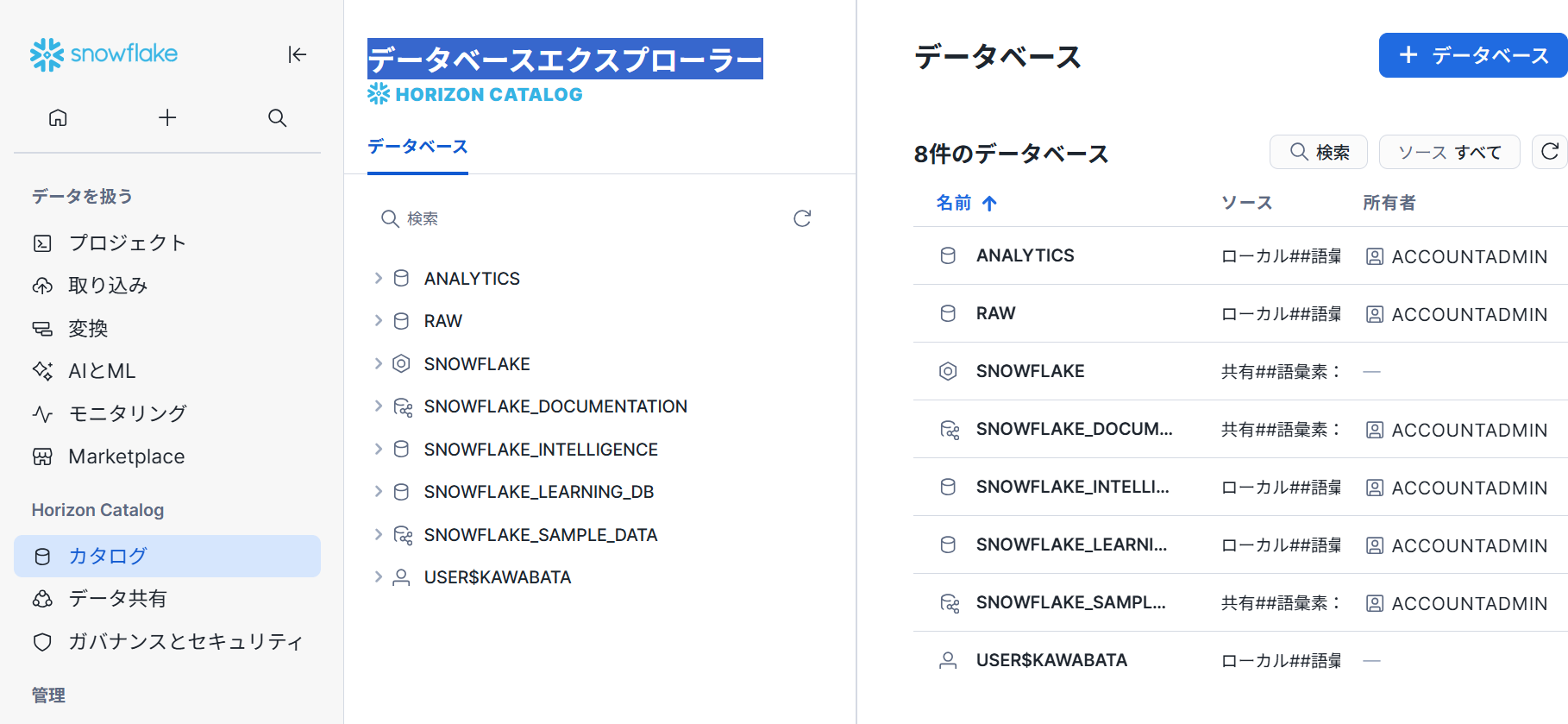
カタログ
データベースエクスプローラー
データベースオブジェクトエクスプローラ を使用して、 Snowsight でデータベースオブジェクトを探索および管理できます。データベースオブジェクトエクスプローラには、アカウント内のすべてのデータベース、各データベースのスキーマ、および各データベースとスキーマに含まれるオブジェクトがタイプ別に階層表示されます。
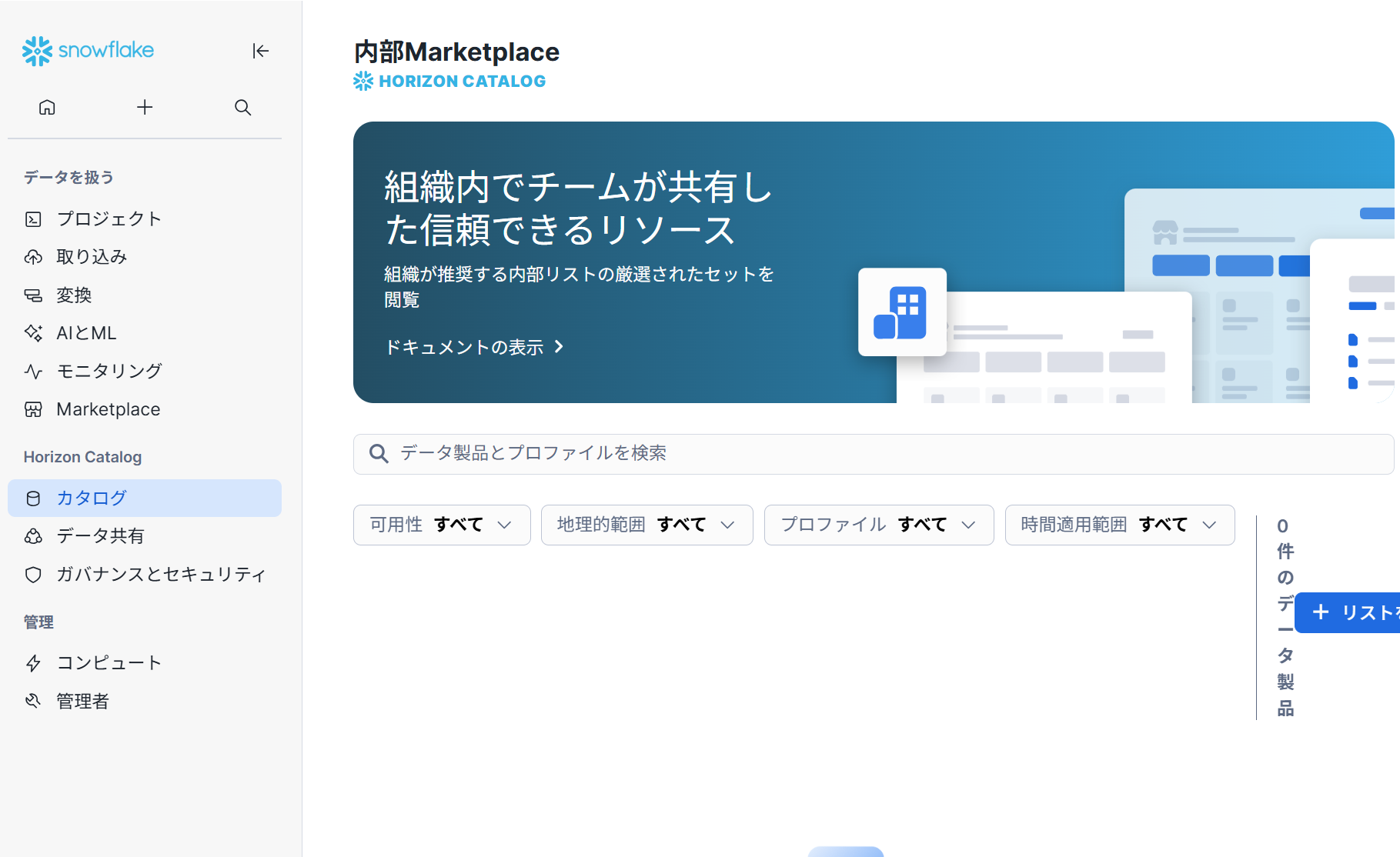
内部Marketplace
SnowflakeのInternal Marketplaceは、組織内での共同データ共有のための、キュレーションされた安全なスペースです。社内で利用可能なデータ製品を一元管理することで、チームは外部のマーケットプレイスを経由することなく、リソースを発見、信頼、適用できます。Internal Marketplaceは、データ製品を体系的に発見できる方法を提供することで、社内全体のコラボレーションとデータドリブンな意思決定をサポートします。
アプリ
Snowflake Marketplace に公開されたアプリやプライベートリストを使用して共有されたアプリが確認できる画面。

データ共有
Provider Studio
Provider Studioは、Snowflake Marketplaceでのデータ製品の提供者向けの統合管理ツールです。
- リスティング管理: データ製品のリスティングの作成、公開、修正
- アナリティクス: データ製品のパフォーマンス、エンゲージメント、利用状況の詳細な分析
- プロファイル管理: プロバイダープロファイルの作成・管理
- 利用状況監視: 消費者によるクエリ実行数、ユニーク消費者数、トレンド分析
- 収益管理: 収益履歴、課金タイプ別の料金累計、購入数の追跡
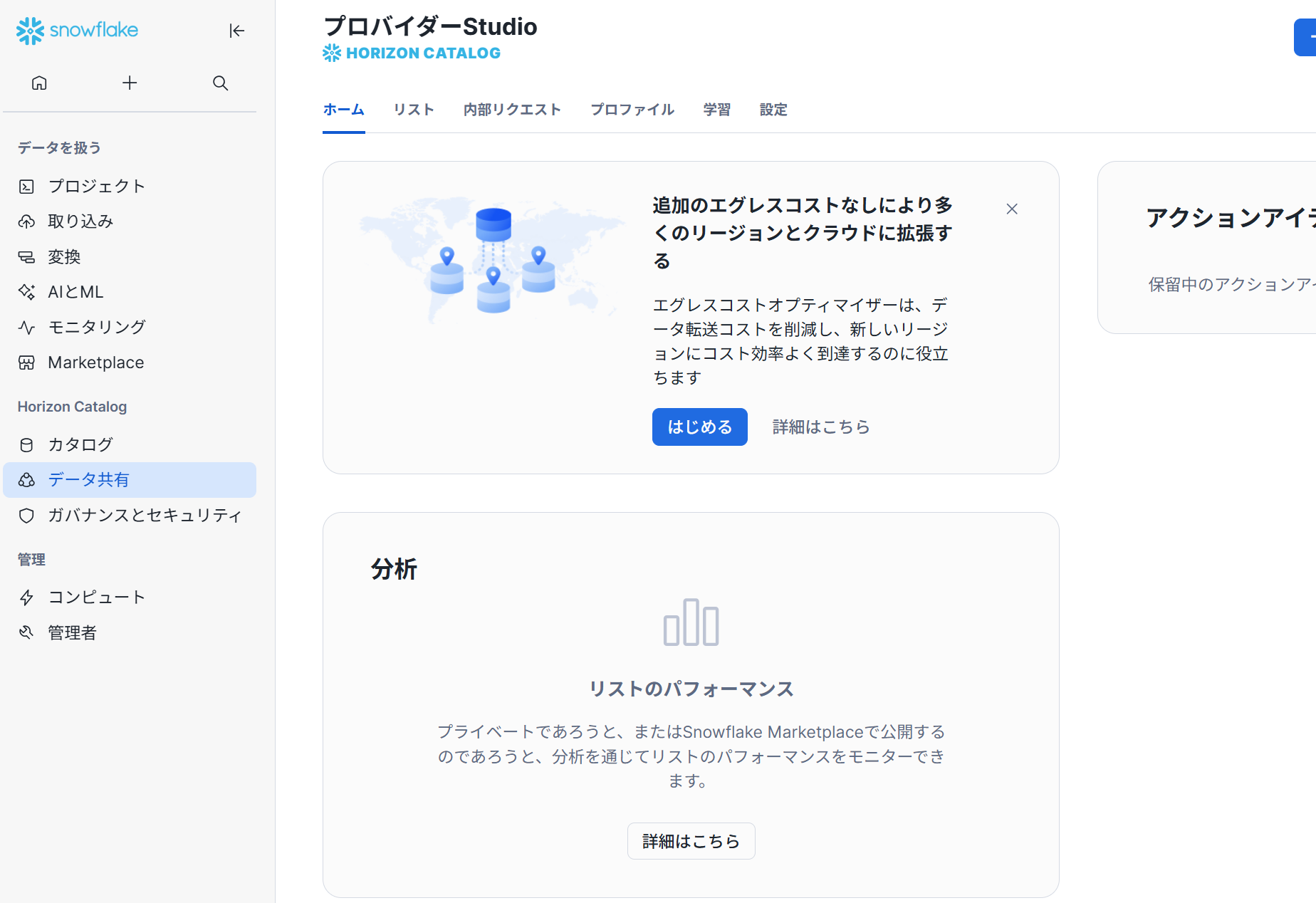
プライベート共有
プライベート共有により、組織間でのセキュアなデータ共有とコラボレーションが可能になります。
具体的には、データアクセス機能として、「Shared with You」タブで利用可能なリスティングを参照したりすることが出来ます。
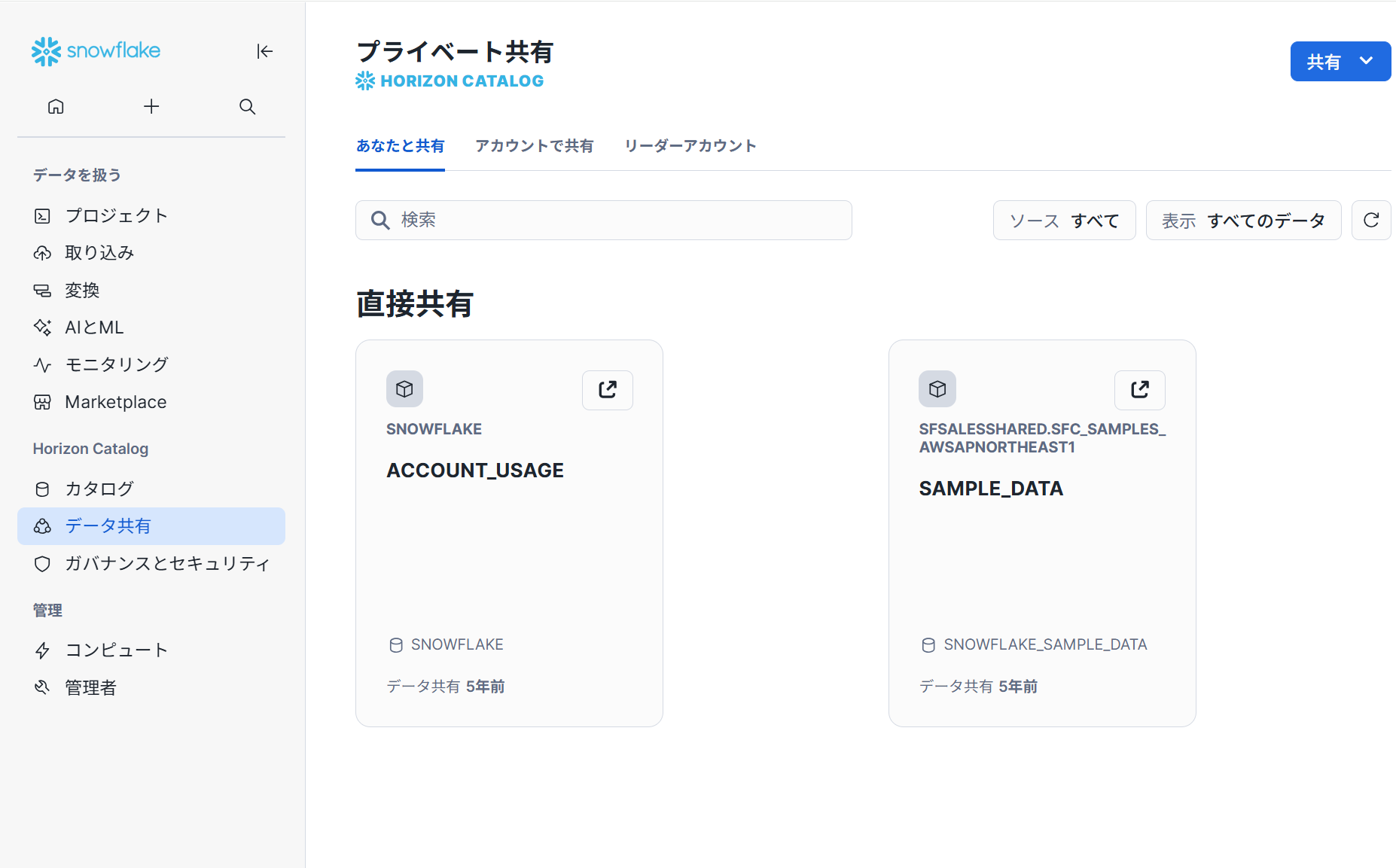
ガバナンスとセキュリティ
ユーザーとロール
ユーザー管理画面では、ユーザーの作成・編集・削除等行えます。また、ロールの管理画面では、ロールの継承関係をグラフで表示や権限管理することが出来ます。
【ユーザー管理】
【ロール】
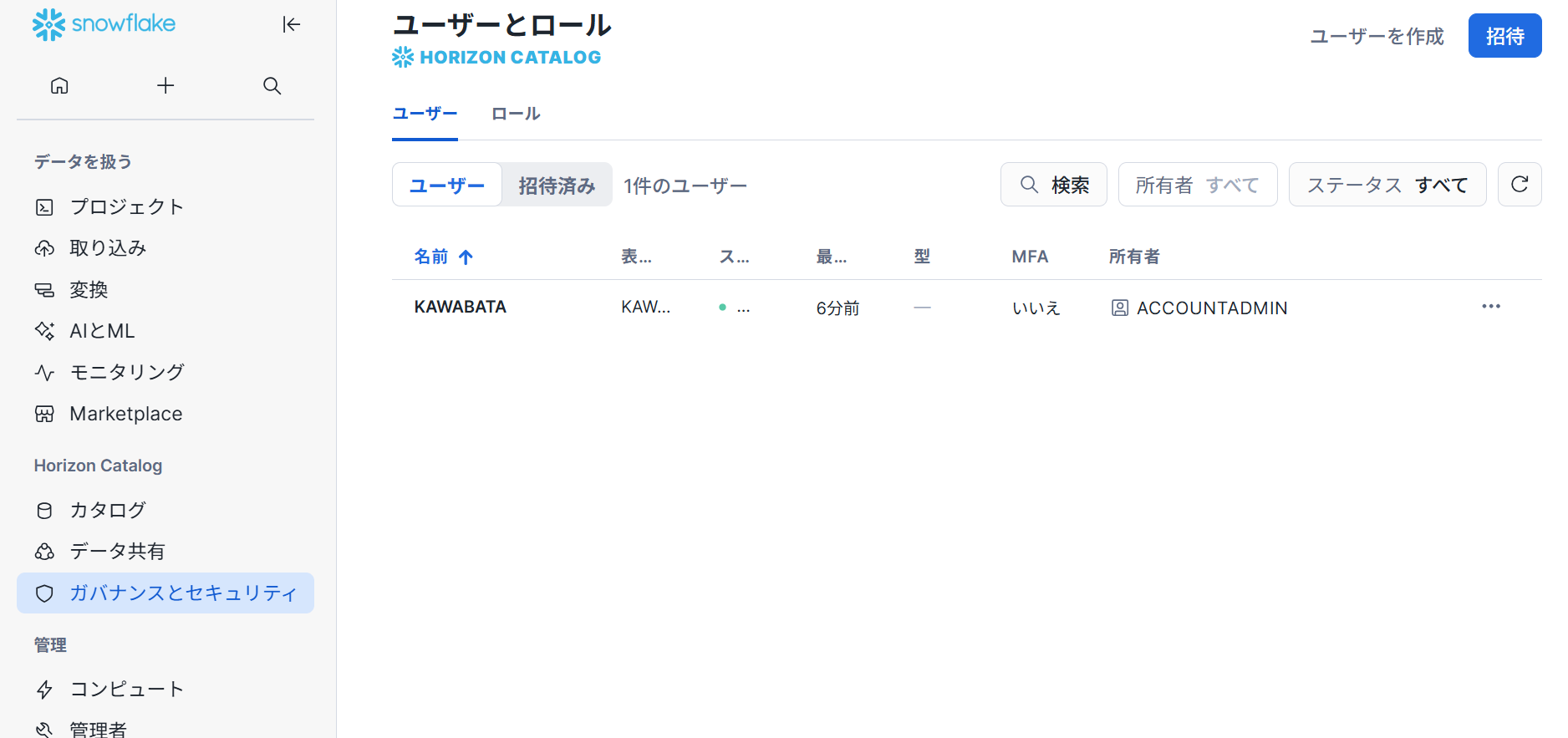
トラストセンター
トラストセンターを使用して、セキュリティリスクについて、アカウントを評価しモニターすることができます。Trust Centerは、スケジュールに従って スキャナー で指定された推奨事項に対してアカウントを評価しますが、 スキャナーの実行頻度を変更することができます。
ネットワークポリシー
ネットワークポリシーを使用して、Snowflakeサービスおよび内部ステージへの インバウンド アクセスを制御できます。
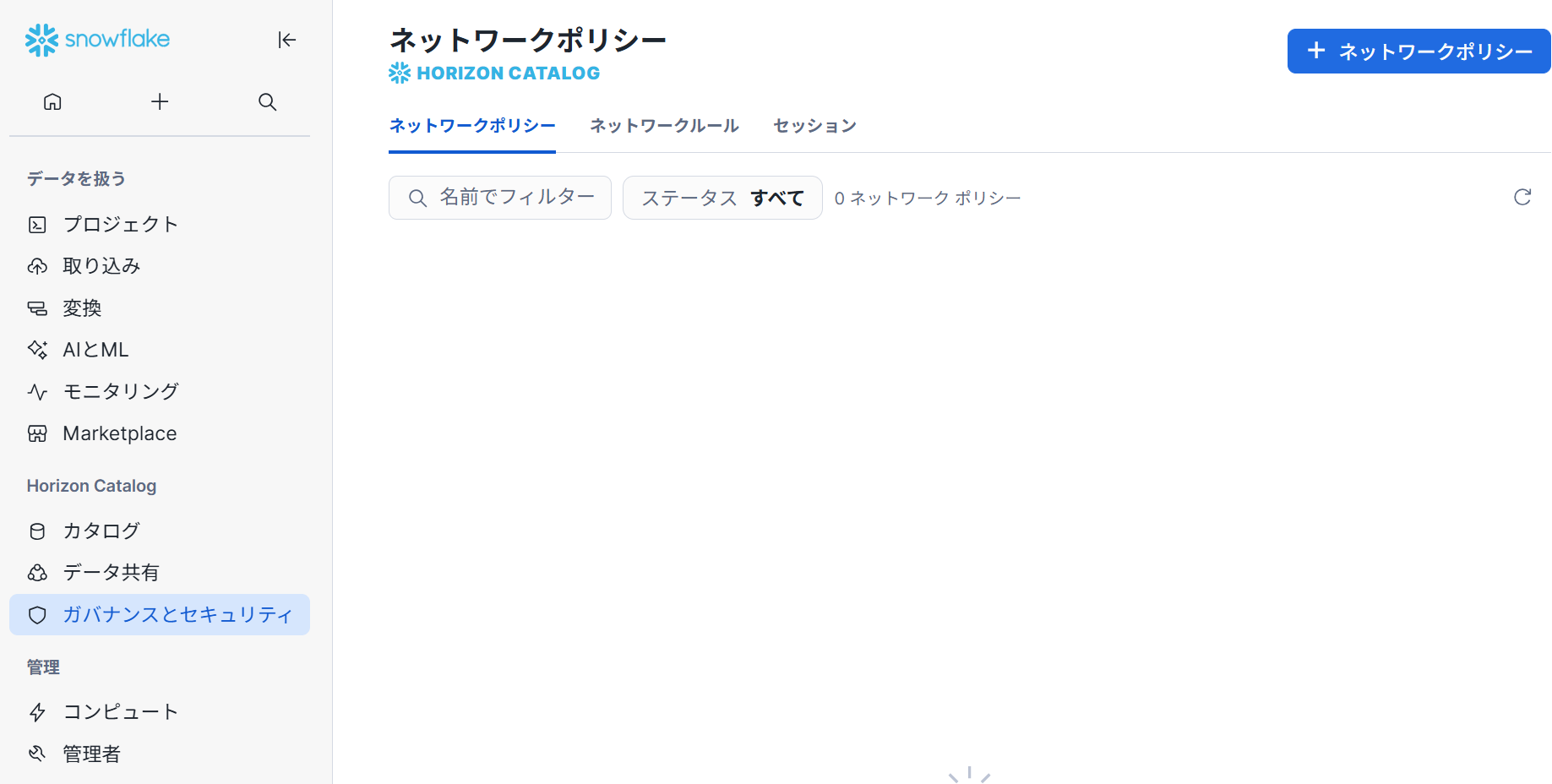
タグおよびポリシー
Dashboardタブでは、最も頻繁に使用されるマスキングポリシーの表示など使用頻度を監視できたり、Tagged Objectsタブでは、タグ有り/無し/特定タグでのフィルタリング等が可能です。
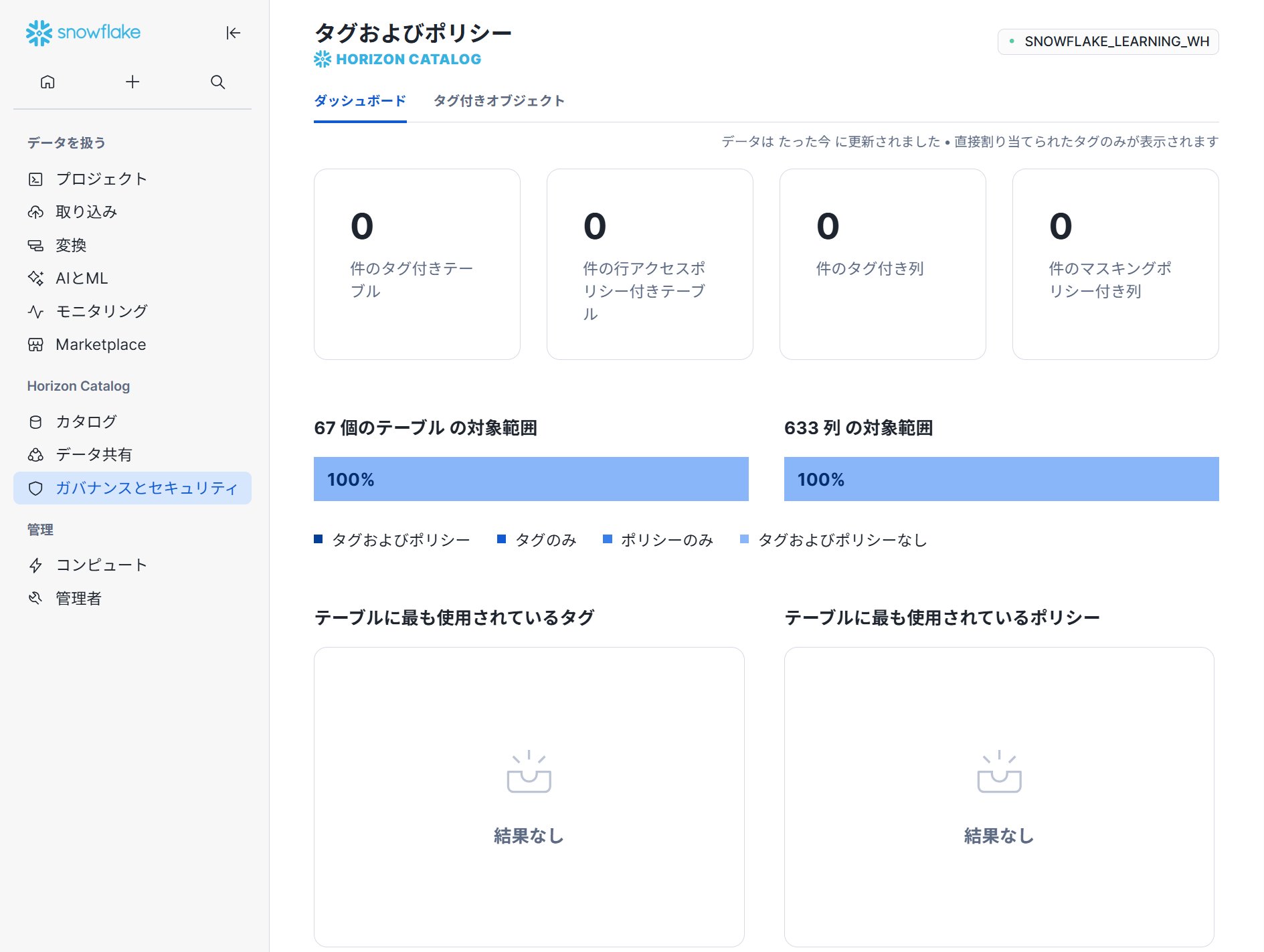
コンピュート
ウェアハウス
Snowsightのウェアハウス管理では、ウェアハウスの作成・編集・削除、開始・停止・サイズ変更がリアルタイムで可能です。自動サスペンド・再開設定、マルチクラスター機能(最大10クラスター)、スケーリングポリシー(Standard/Economy)の管理ができます。
管理者
管理者の項目にある、管理者連絡先・請求・規約・統合の項目は割愛させていただきます。
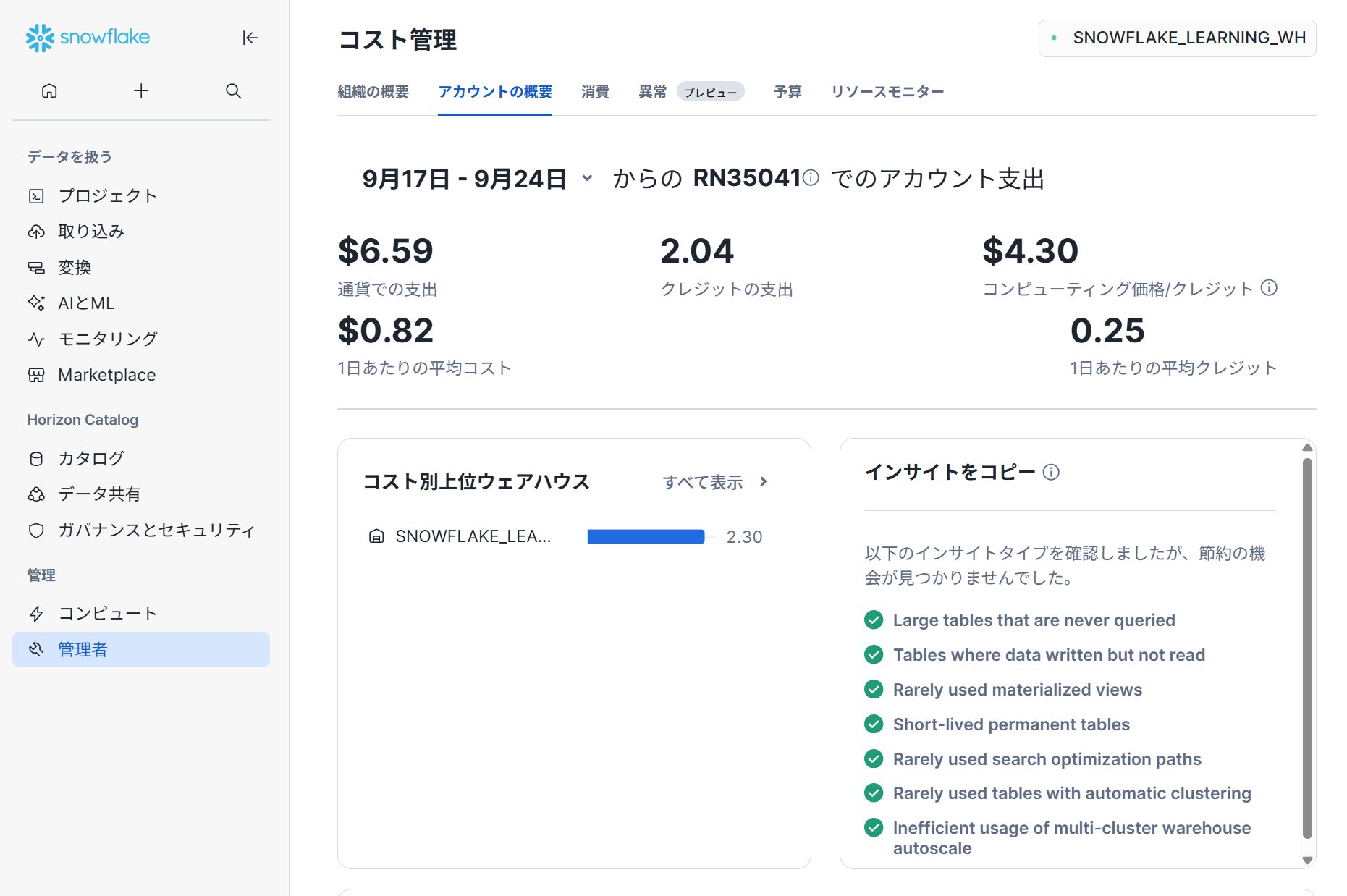
コスト管理
ウェアハウスの作成・起動・停止等の操作を行える画面です。Snowsightのコスト管理では、アカウント全体のコスト概要を確認し、ドルとクレジット単位での総支出を表示できます。Consumptionタブでコンピュート・ストレージ・データ転送コストの詳細分析、最も費用のかかるウェアハウスやクエリの特定が可能です。
アカウント
Snowsightのアカウント管理では、組織内の全アカウントを表示・管理できます。ORGADMINロールで新しいアカウントの作成、アクティブ・削除済みアカウントの検索・フィルタリングが可能です。

Partner Connect
SnowsightのPartner Connectでは、Snowflakeビジネスパートナーとの統合を簡単に行えます。BI(Tableau、Power BI等)、データ統合(dbt Cloud、Matillion等)、機械学習・データサイエンス、セキュリティ・ガバナンス分野の様々なサードパーティツールのトライアルアカウントを作成し、Snowflakeと自動統合できます。

データロードの準備
このセクションでは下記内容を行います。
- データベースとテーブルを作成する。
- 外部ステージを作成する。
- データのファイル形式を作成する。
使用するデータは、Citi Bike(NYC)によって提供された自転車シェアのデータとなります。
データベースとテーブルの作成
- 画面左側最下部から「ロールの切り替え」→「SYSADMIN」を選択し、ロールを切り替えます。
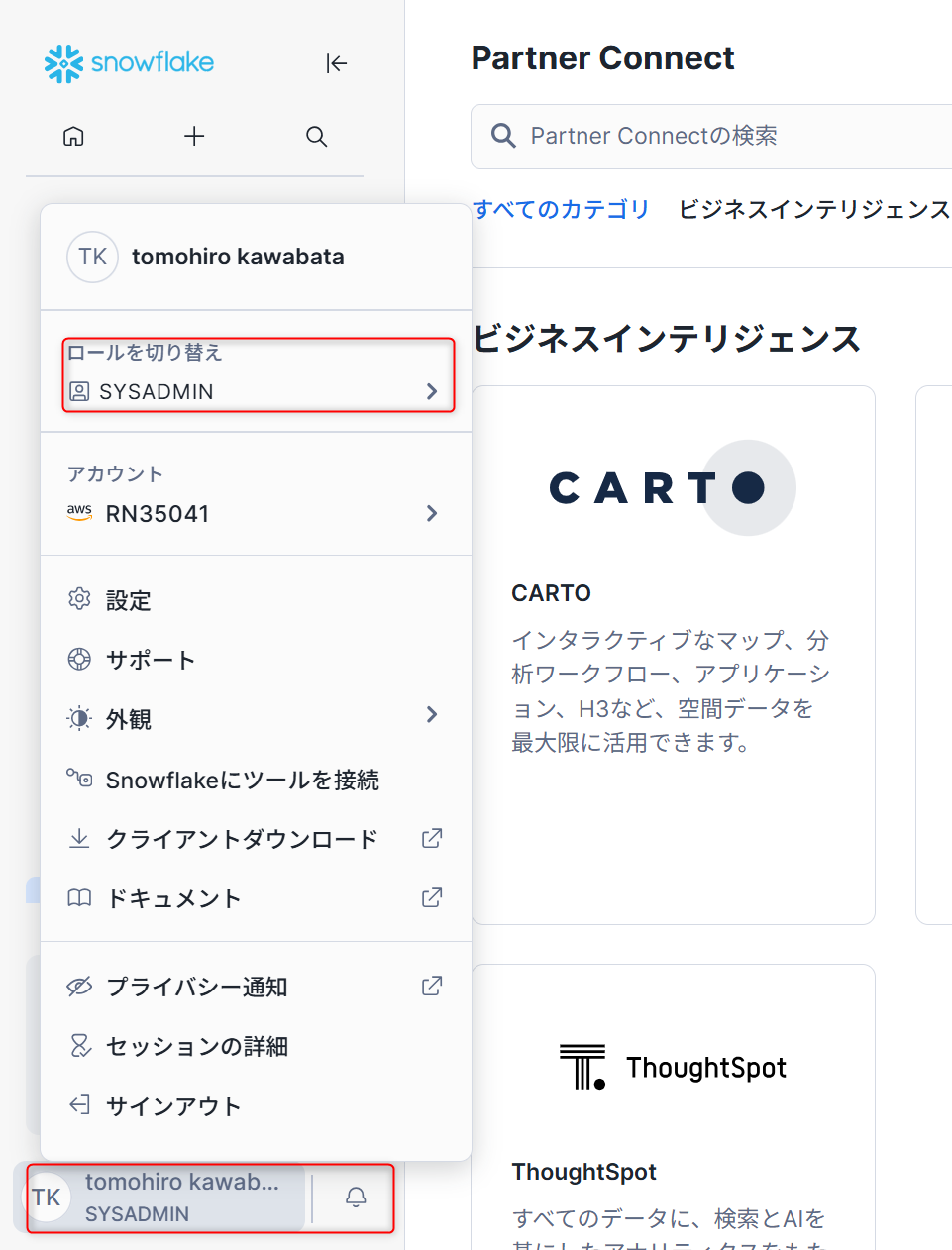
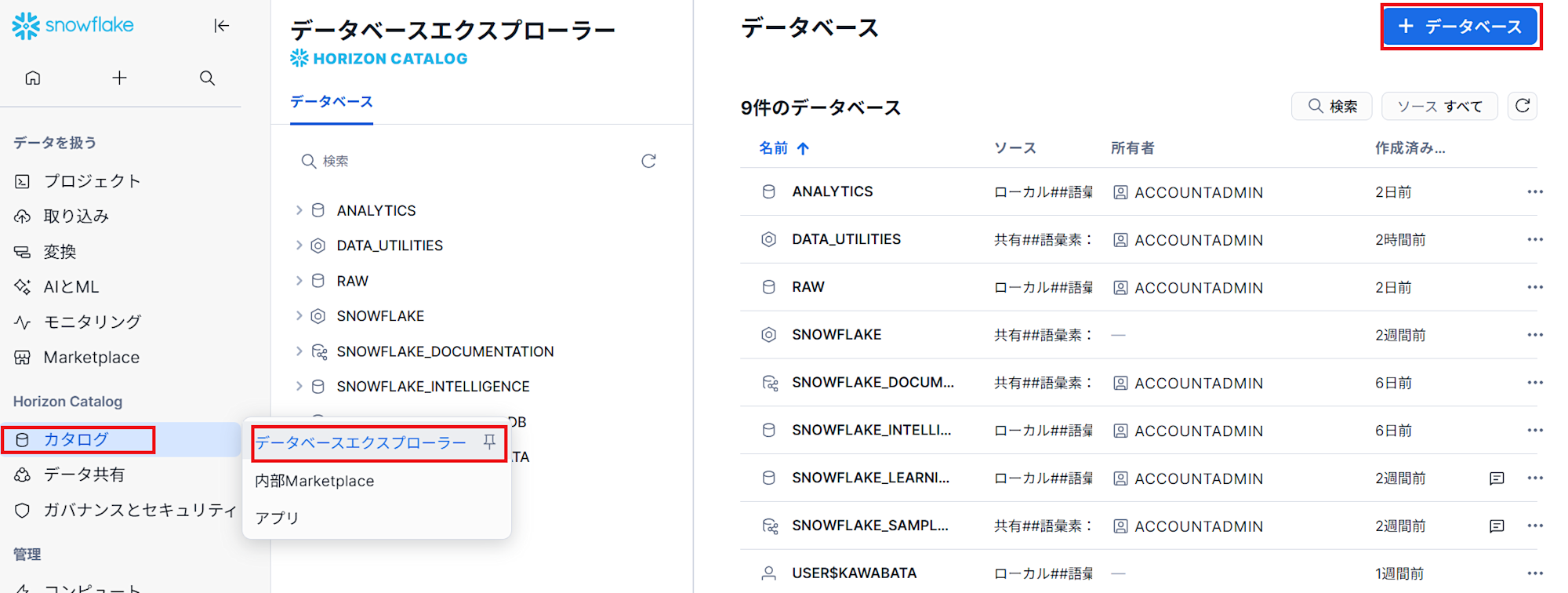
- 「カタログ」→「データベースエクスプローラー」から、右上側の「+データベース」をクリックし、出てきたポップアップに
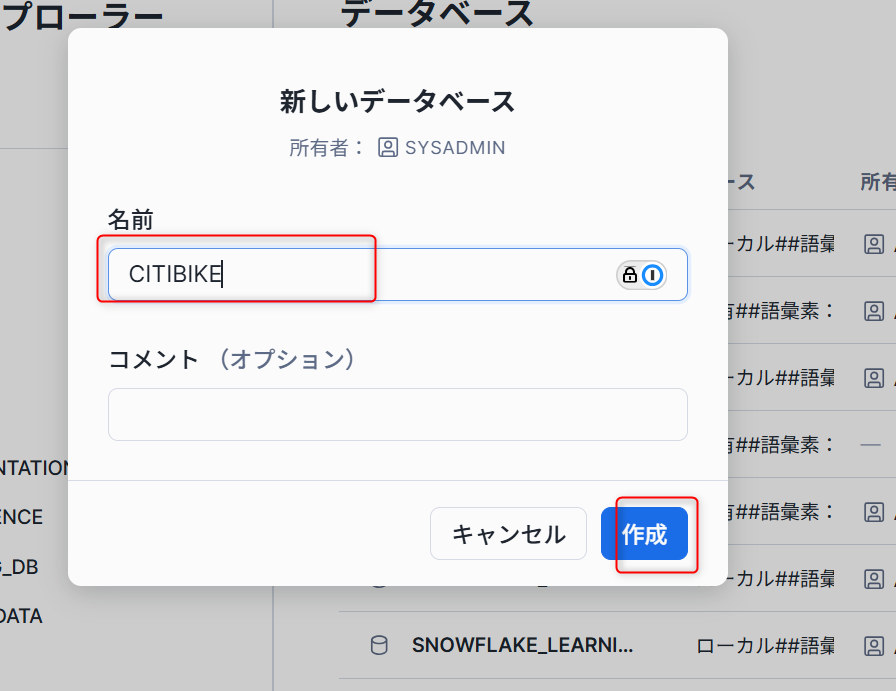
CITIBIKEと名称をつけデータベースを作成します。
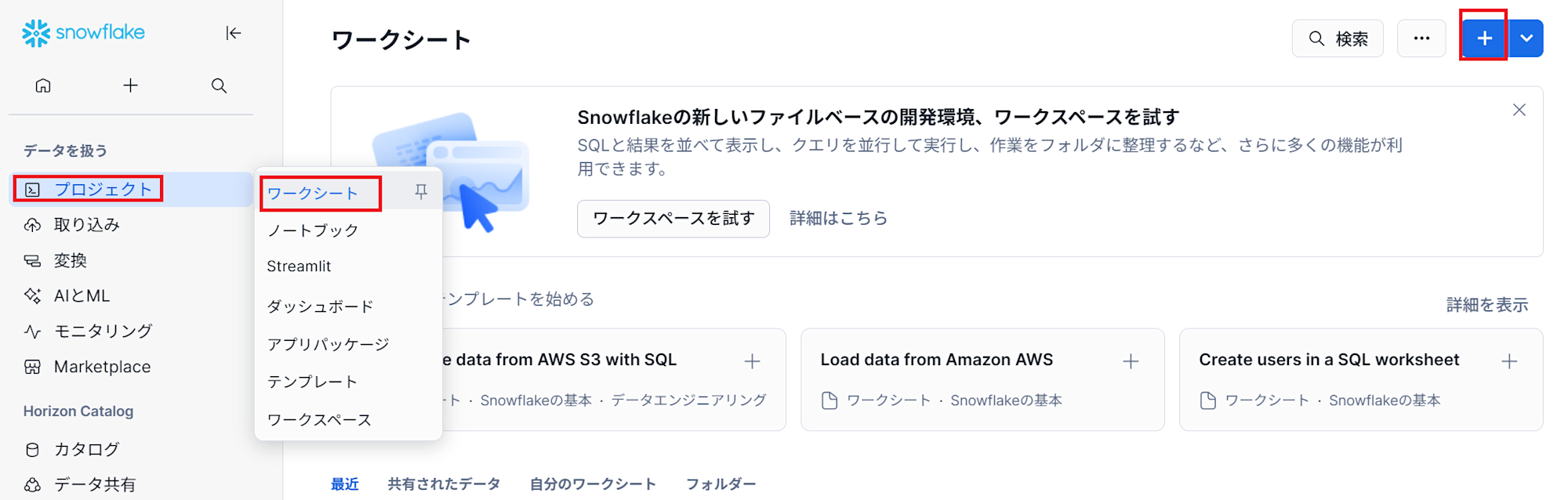
- ワークシートを作成するために、 「プロジェクト」→「ワークシート」から、右上側の「+データベース」をクリックします。
- ワークシート画面で、「ロール」→「SYSADMIN」、「ウェアハウス」→「SNOWFLAKE_LEARNING_WH」、「データベース」→「CITIBIKE」、「スキーマ」→「PUBLIC」に設定します。
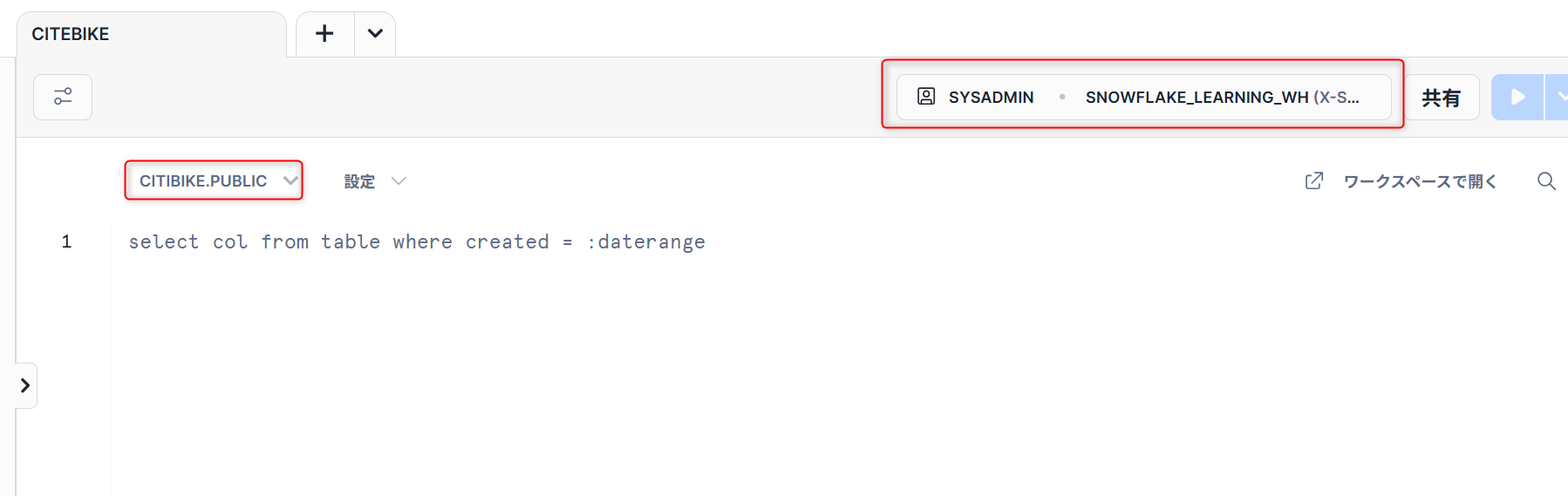
- カンマ区切りのデータのロードに使用する
TRIPSという名前のテーブルを作成します。
以下のコードをワークシートにコピーし実行します。
create or replace table trips
(tripduration integer,
starttime timestamp,
stoptime timestamp,
start_station_id integer,
start_station_name string,
start_station_latitude float,
start_station_longitude float,
end_station_id integer,
end_station_name string,
end_station_latitude float,
end_station_longitude float,
bikeid integer,
membership_type string,
usertype string,
birth_year integer,
gender integer);
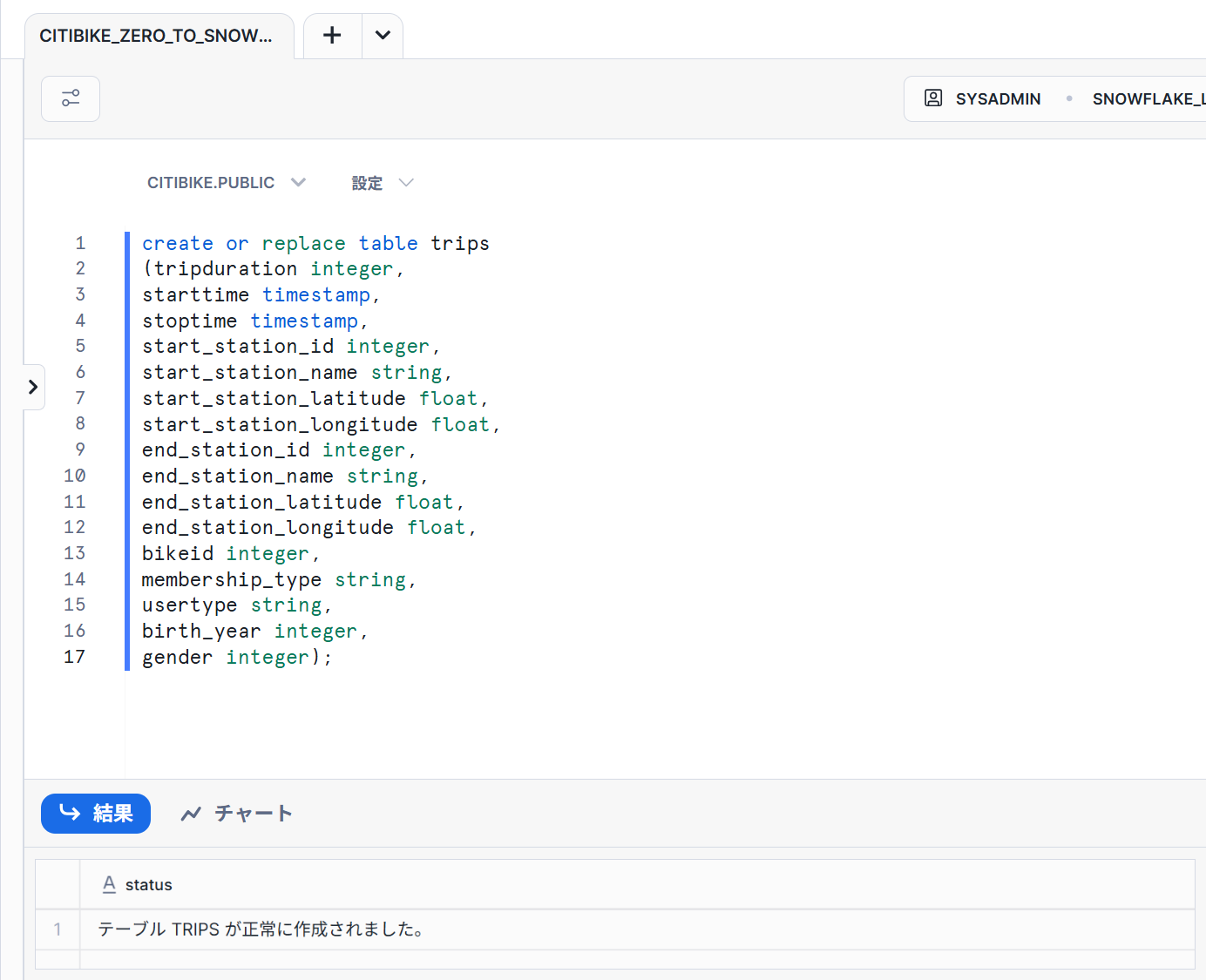
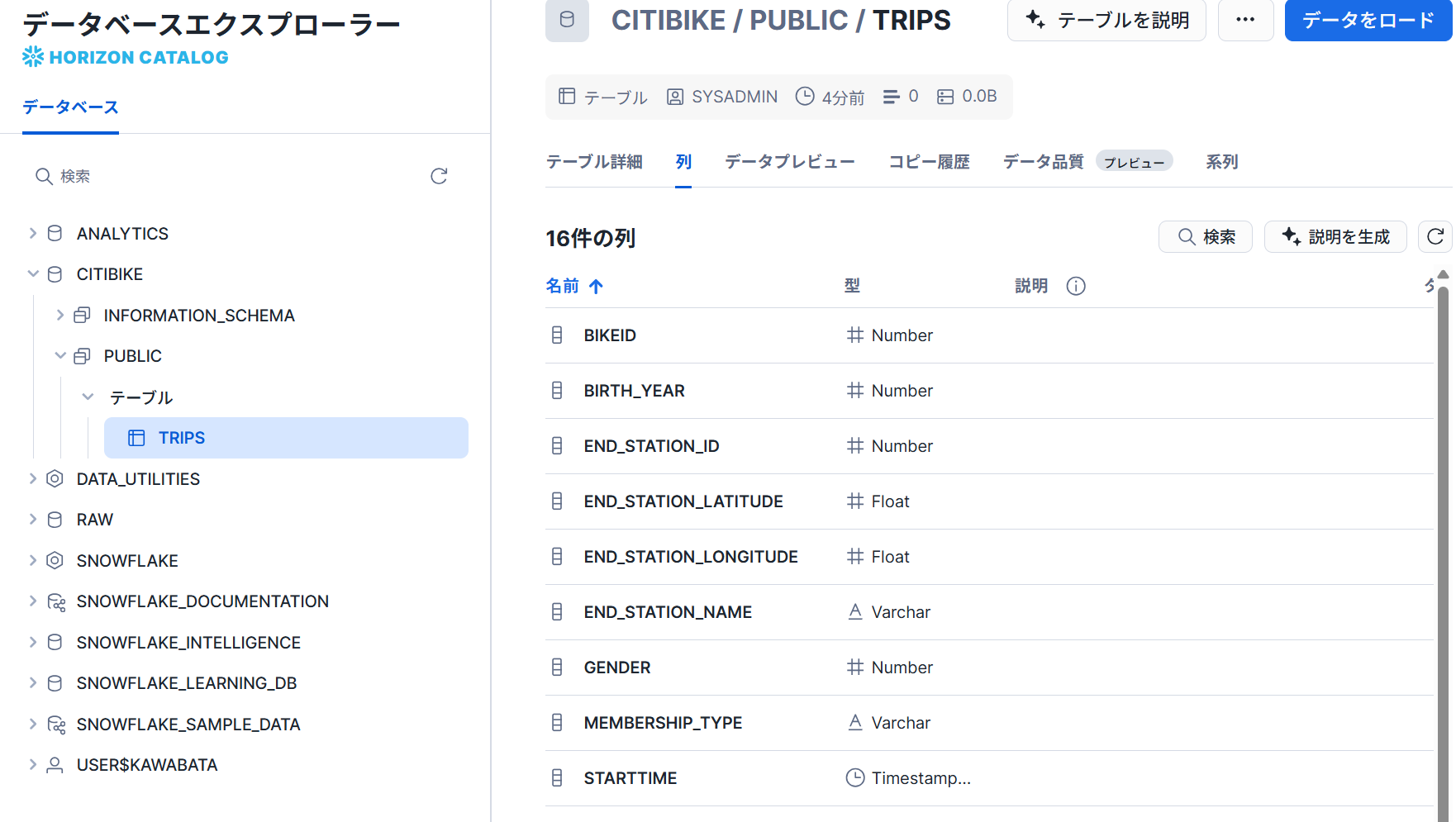
- 以下のようにテーブルが作成できていることが確認できました。
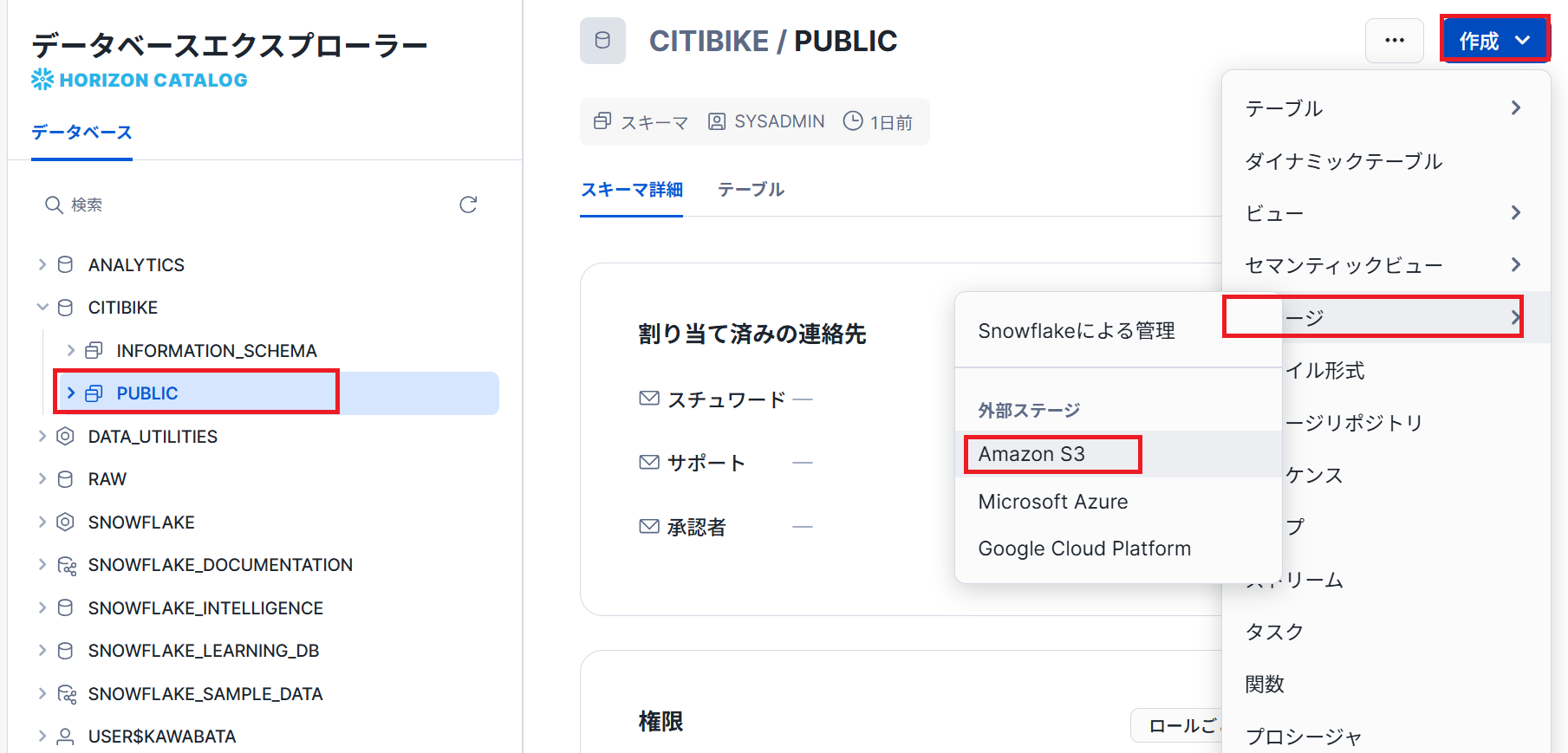
外部ステージの作成
さきほど作成したテーブルにデータをロードするためにステージを作成します。今回は公開されている外部のS3からデータをロードしたいので、外部ステージを作成します。
- 「データベースエクスプローラー」→「CITIBIKE」データベース→「PUBLIC」スキーマを選択し、右上側の作成タブからステージを選択し、プルダウンメニューから
Amazon S3をクリックします。
- ポップアップした画面を下記のように記載し、外部ステージを作成します。
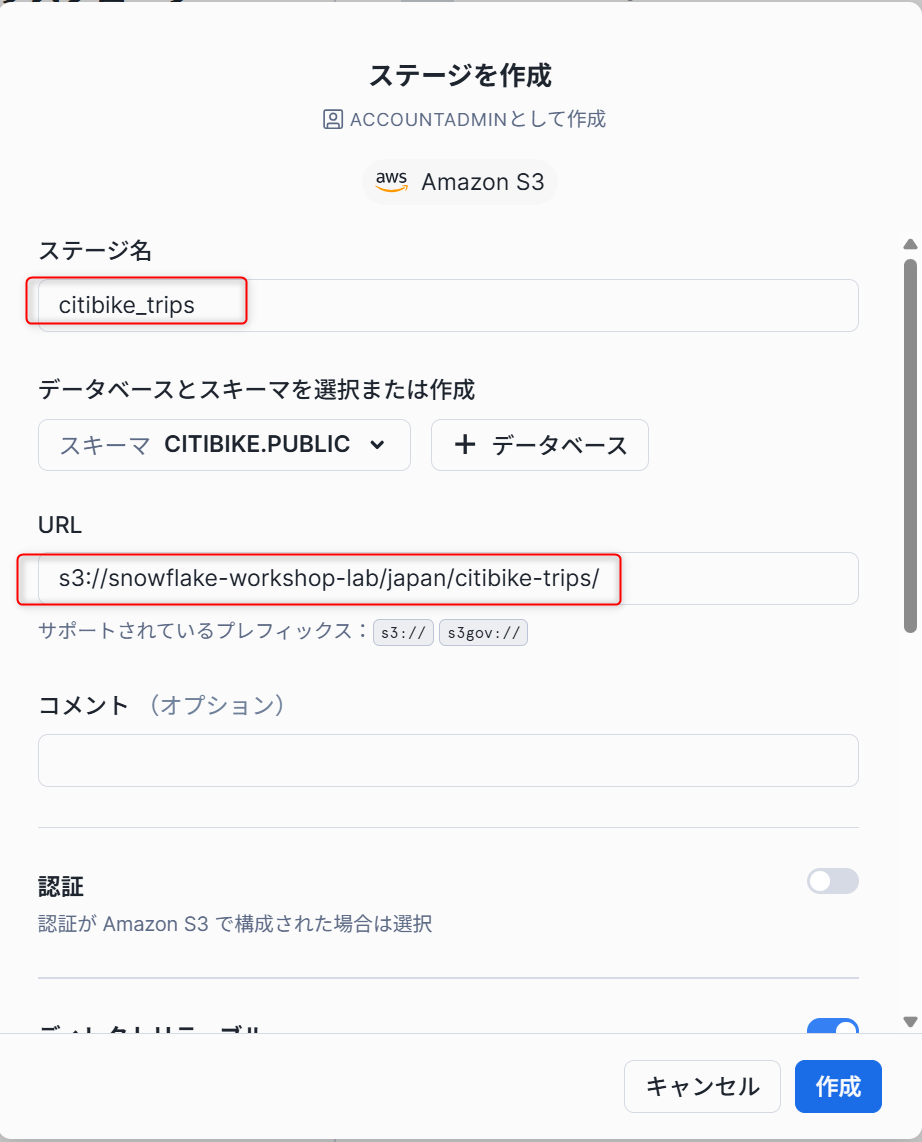
## ステージ名
citibike_trips
## URL
s3://snowflake-workshop-lab/japan/citibike-trips/
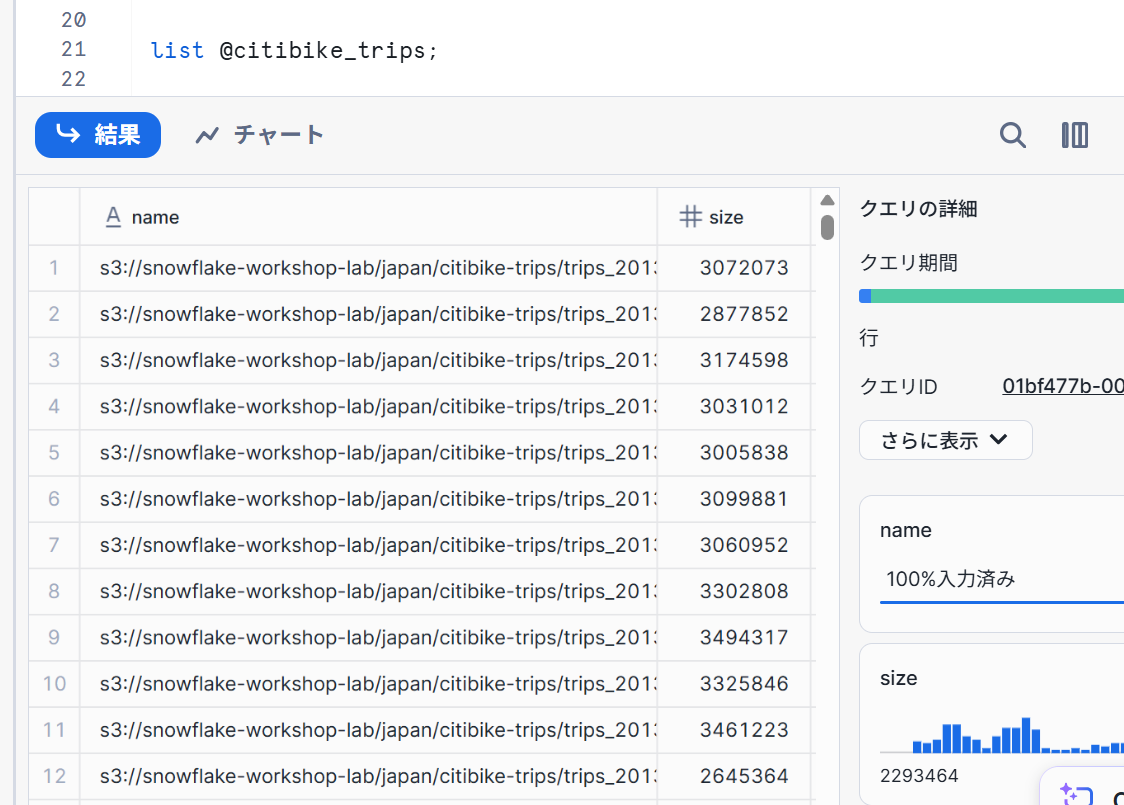
- ワークシートで下記コマンドを実行するとステージ内のファイルのリストが確認できます。
list @citibike_trips;
ファイル形式の作成
ここでは、データをロードする前にデータ構造をfile formatとして指定するフェーズです。
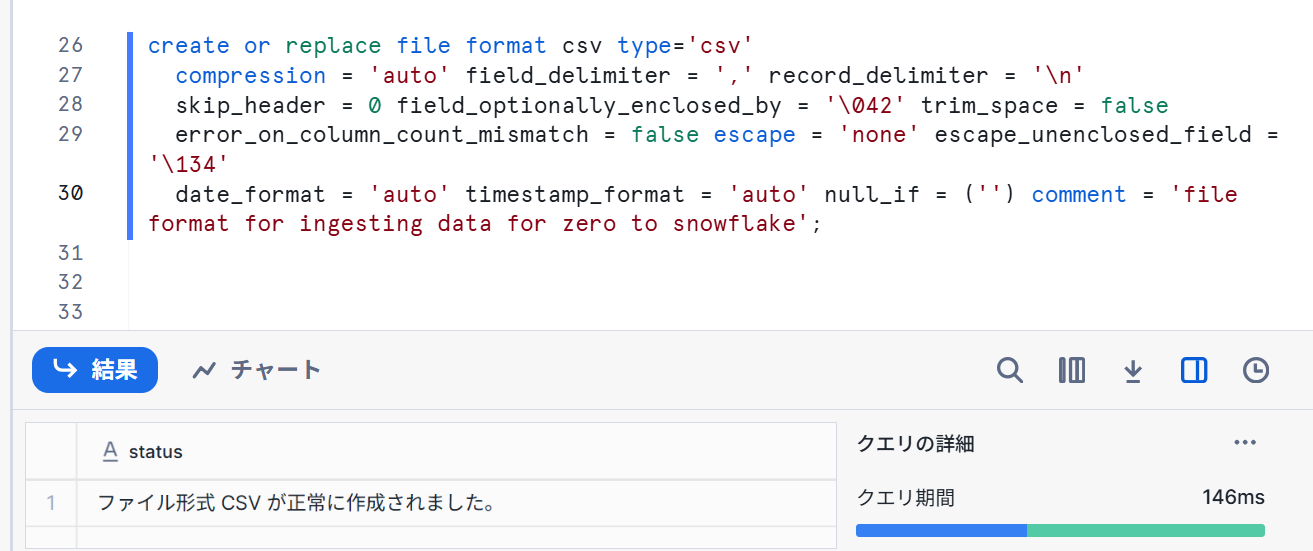
- 以下コマンドを実行します。
--create file format
create or replace file format csv type='csv'
compression = 'auto' field_delimiter = ',' record_delimiter = '\n'
skip_header = 0 field_optionally_enclosed_by = '\042' trim_space = false
error_on_column_count_mismatch = false escape = 'none' escape_unenclosed_field = '\134'
date_format = 'auto' timestamp_format = 'auto' null_if = ('') comment = 'file format for ingesting data for zero to snowflake';
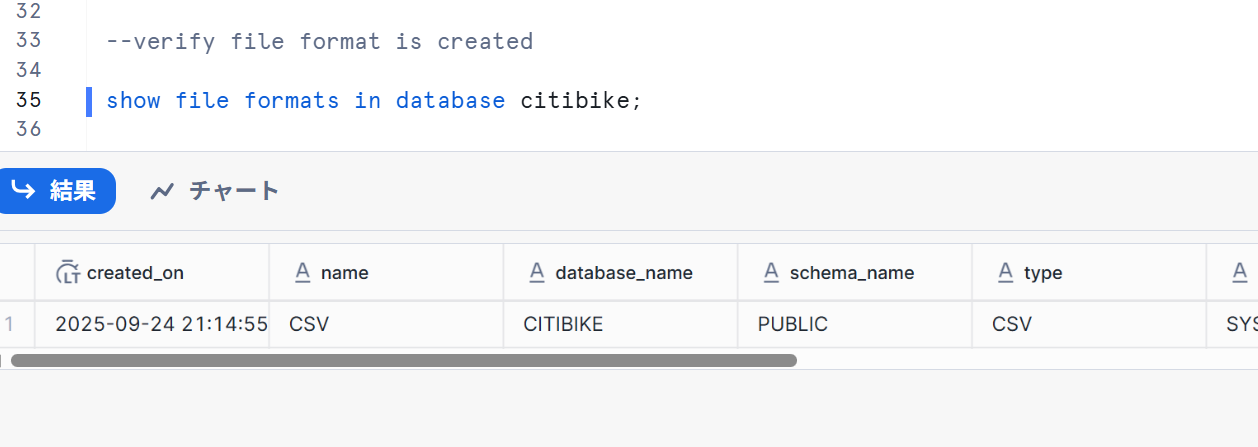
- ファイル形式が正しい設定で作成されていることを確認します。
--verify file format is created
show file formats in database citibike;
データのロード
このセクションでは、仮想ウェアハウスとCOPYコマンドを使用して、前のセクションで作成したSnowflakeテーブルへの構造化データの一括ロードを開始します。
ウェアハウスのサイズ変更
- 「コンピュート」→「ウェアハウス」→「SNOWFLAKE_LEARNING_WH」を選択し、右上側の三点コードから編集を選択します。
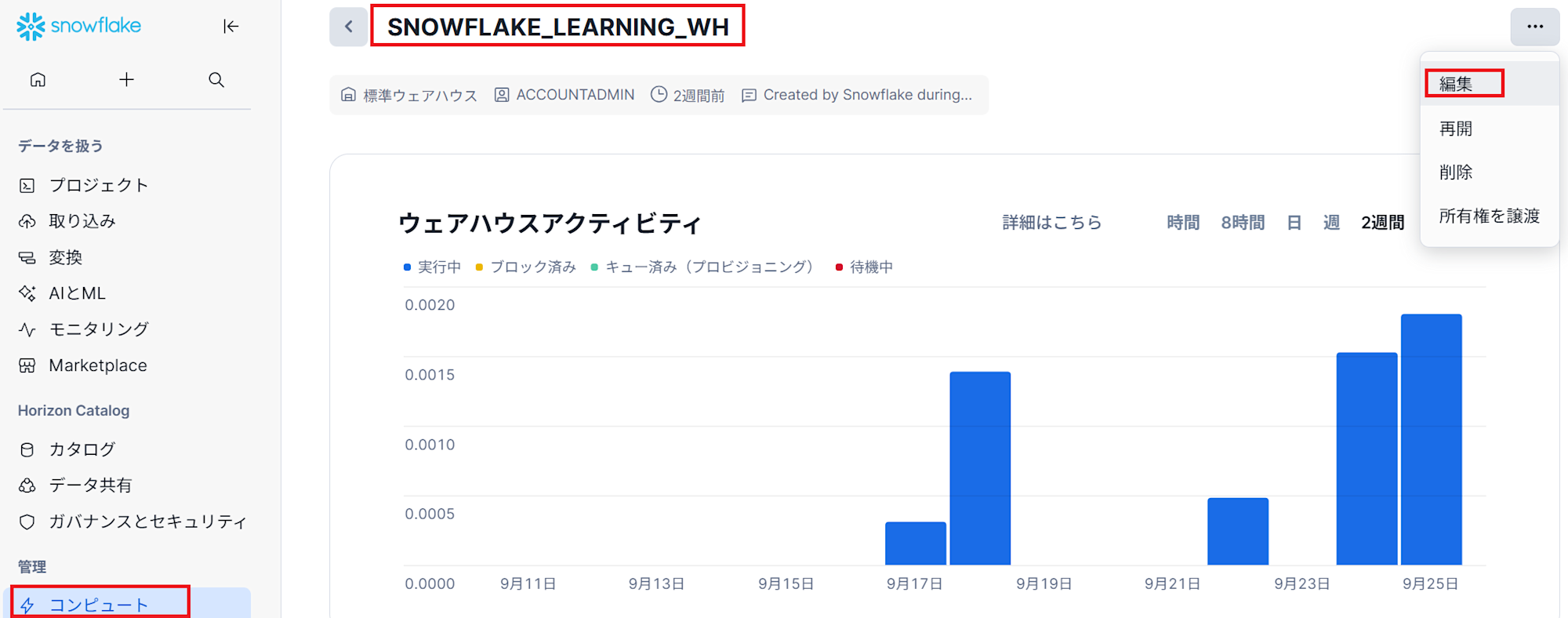
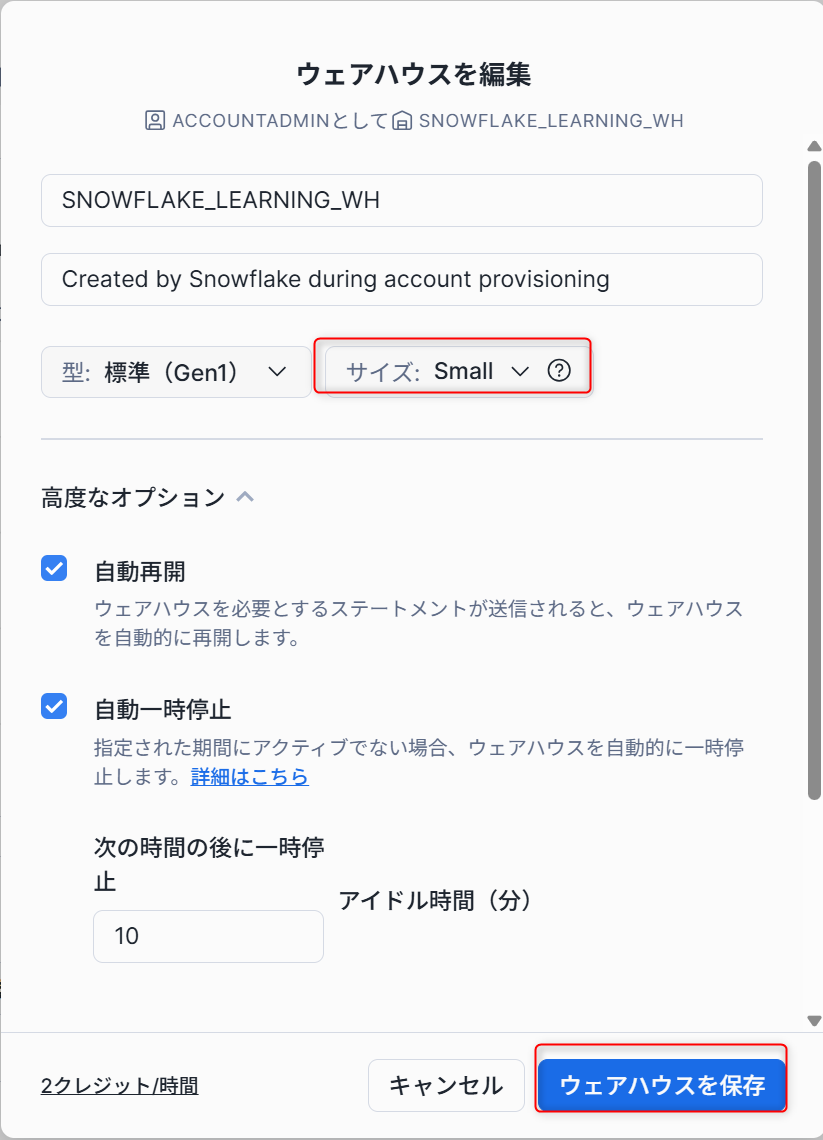
- ポップアップした内容をサイズを
Smallに変更し、ウェアハウスを保存します。
データのロード
- ワークシートで下記クエリを実行し、データをロードしていきます。
copy into trips from @citibike_trips file_format=csv PATTERN = '.*csv.*' ;
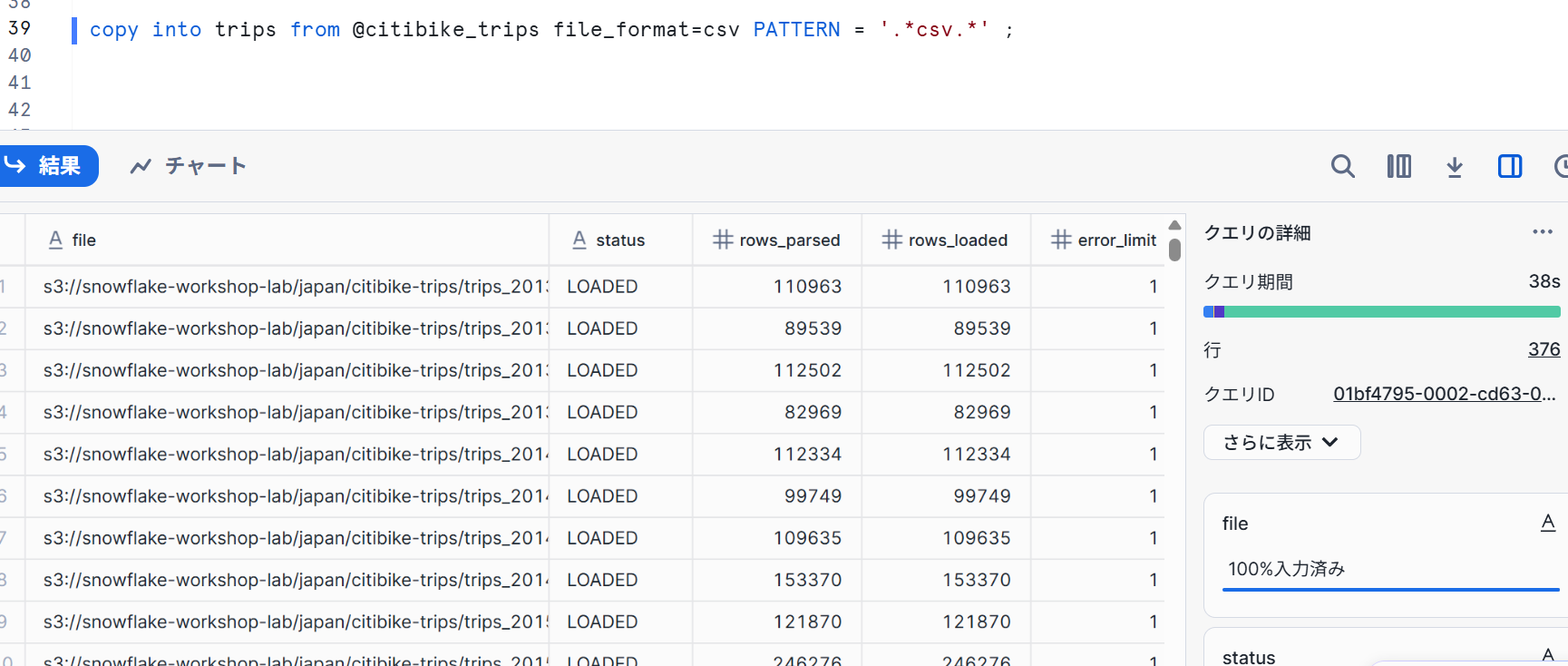
実行時間は38秒でした。
- ウェアハウスのサイズを変更して実行時間が変わるか確認していきます。
-- テーブルからデータおよびメタデータの削除
truncate table trips;
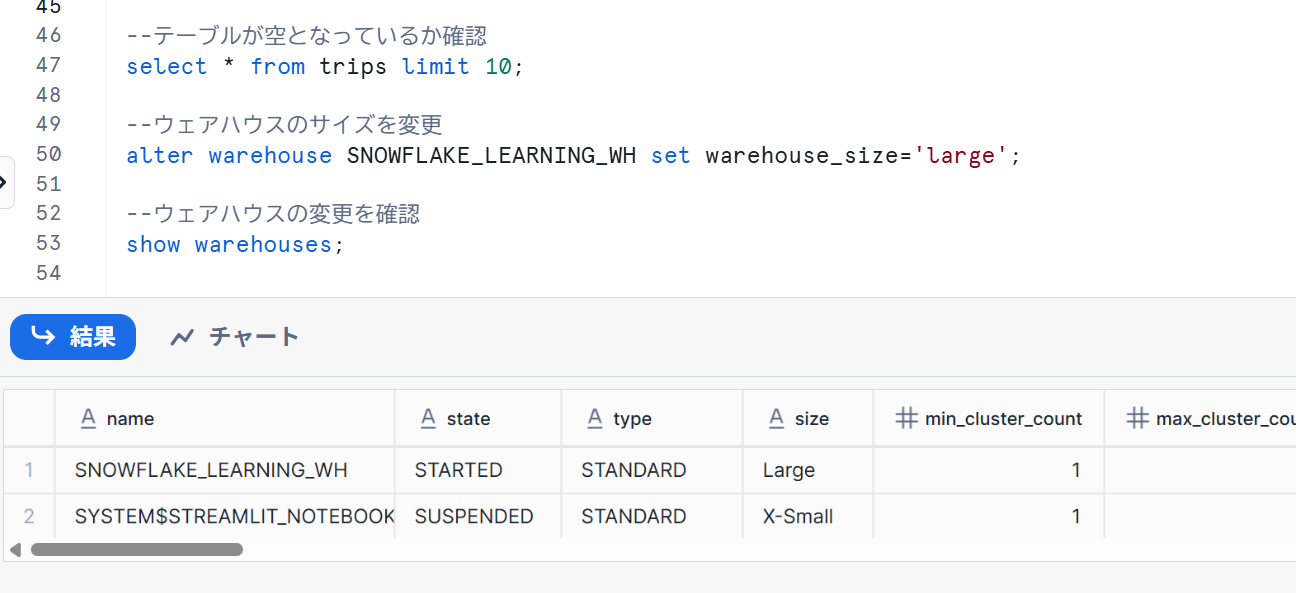
--テーブルが空となっているか確認
select * from trips limit 10;
--ウェアハウスのサイズを変更
alter warehouse SNOWFLAKE_LEARNING_WH set warehouse_size='large';
--ウェアハウスの変更を確認
show warehouses;
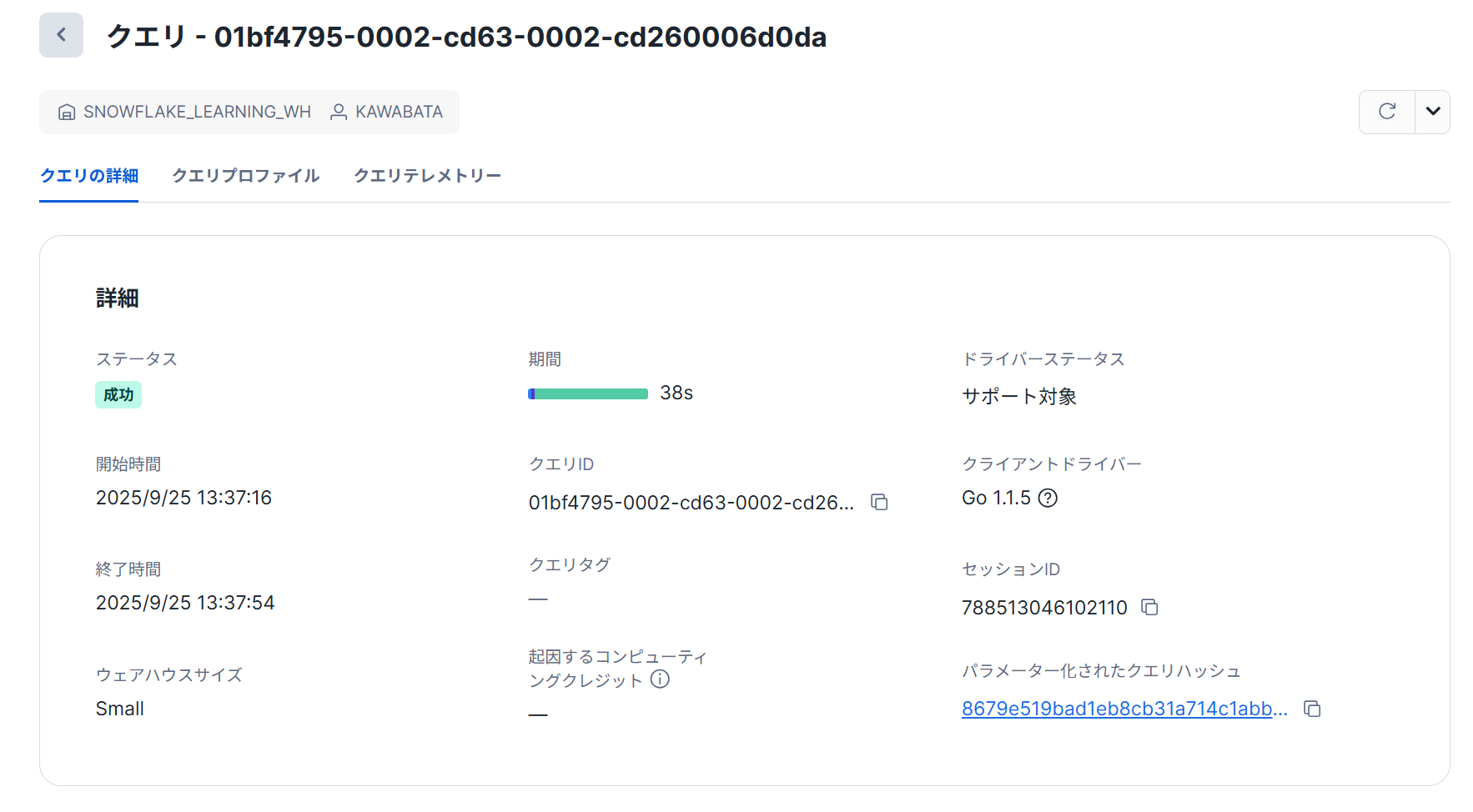
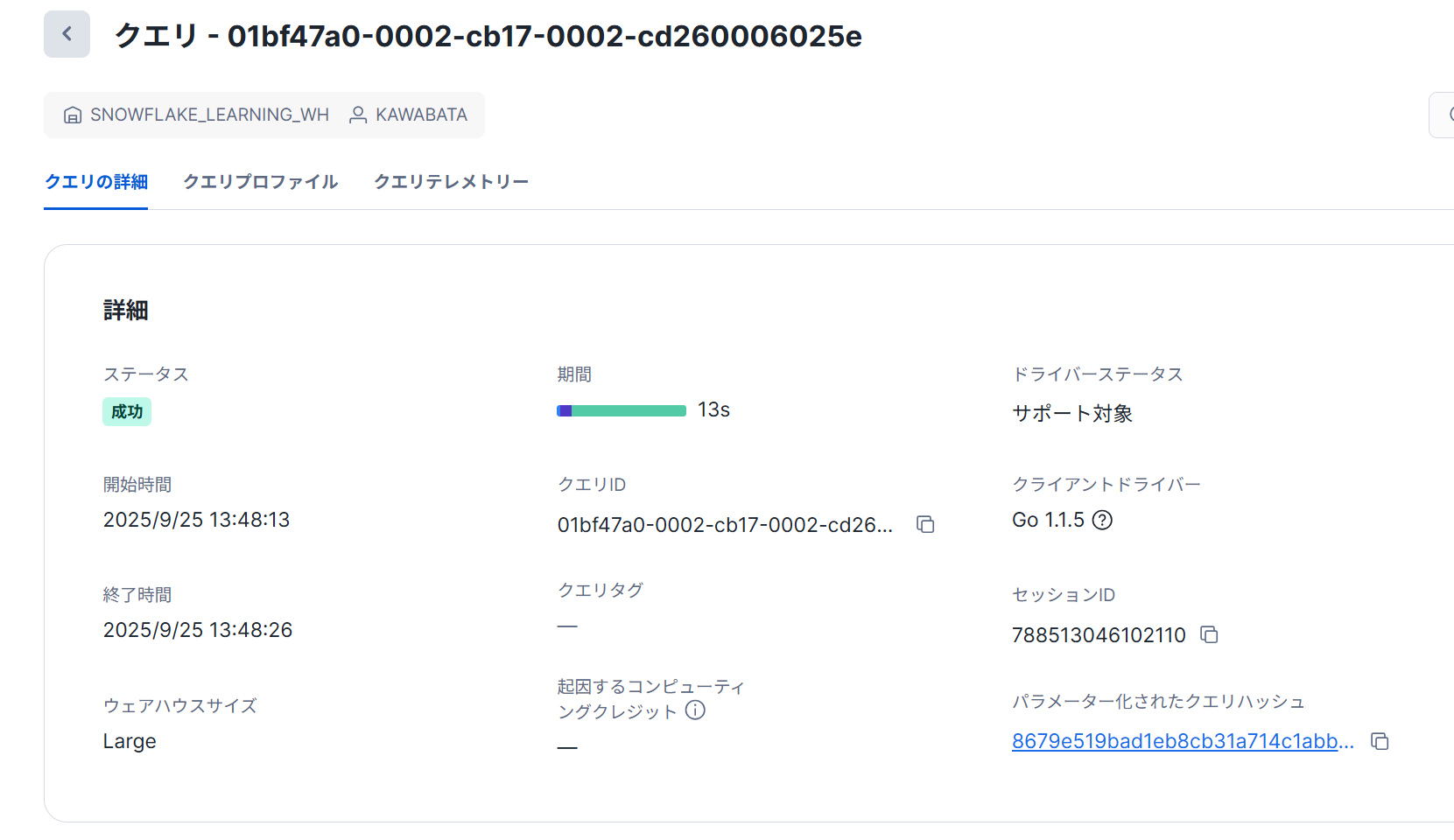
- 再度1を実行します。「モニタリング」→「クエリ履歴」→直近のクエリIDを選択します。
実行時間が13秒となっており、およそ1/3となっていました。
注意点として、ウェアハウスのサイズが1つ上がるとクレジットが倍になるので、実行時間とコストとの兼ね合いを考える必要があります。
この場合は60秒以下は60秒としてクレジットがかかるので、コストは4倍で実行時間が1/3となります。
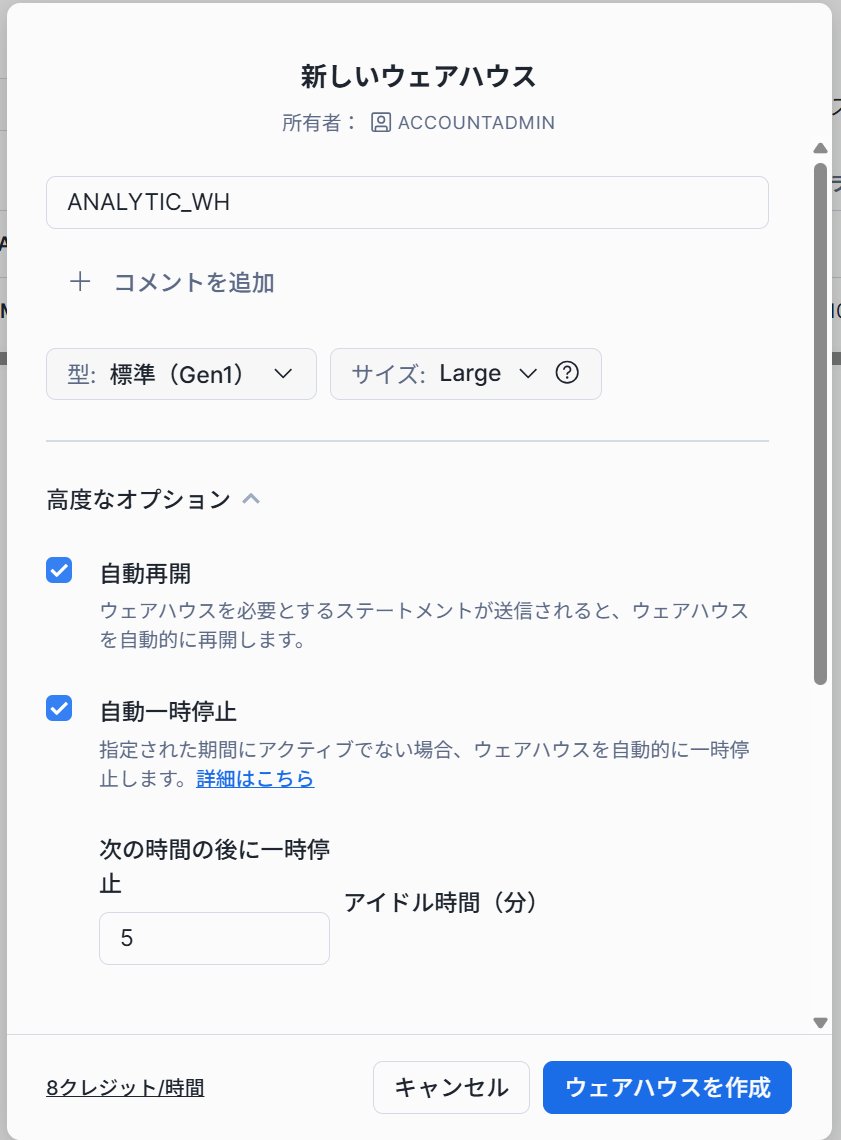
データアナリティクス用の新しいウェアハウスの作成
以下のようにデータアナリティクス用にウェアハウスを作成しておきます。
クエリ、結果キャッシュ、クローンの操作
クエリの実行
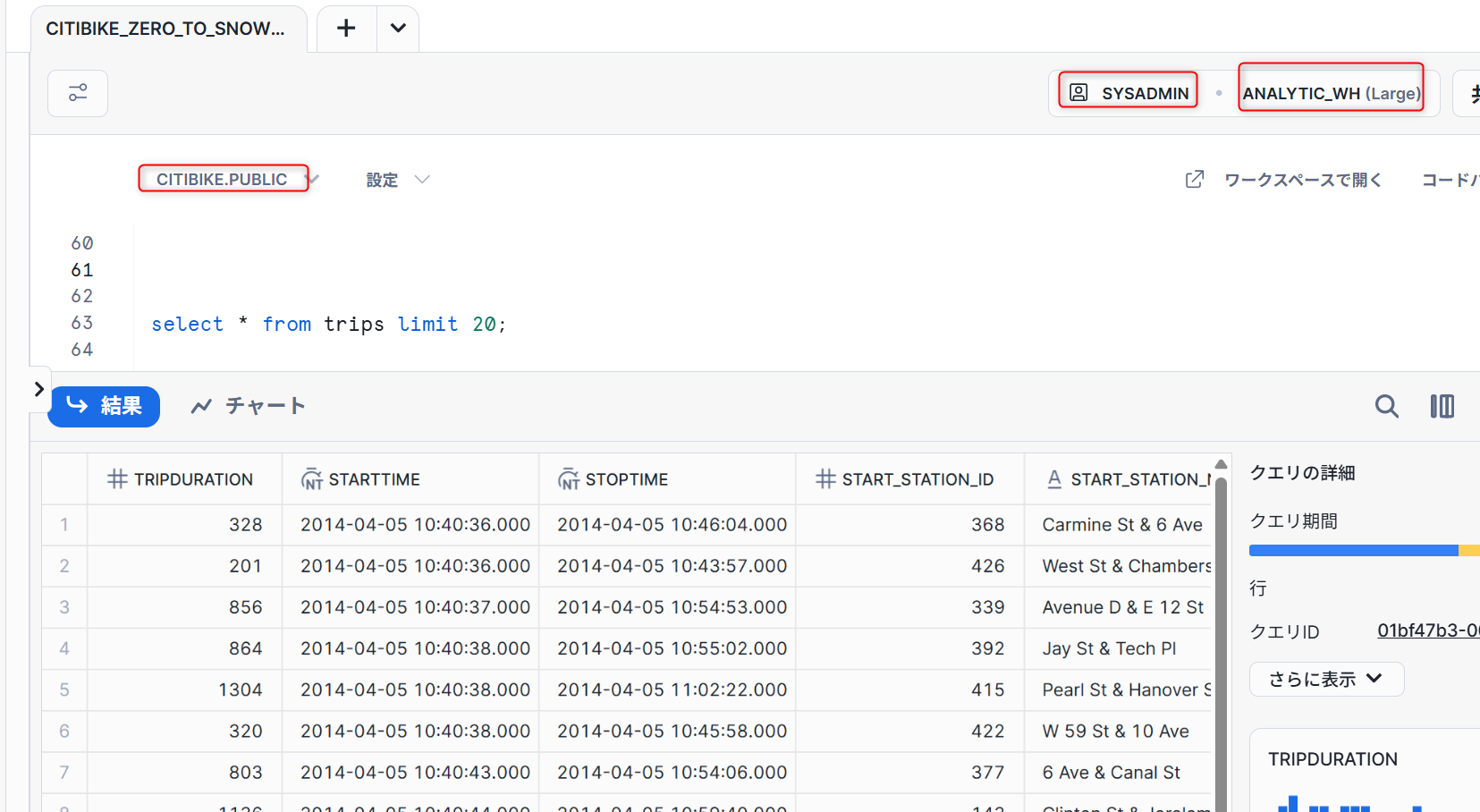
- ワークシート画面で、「ロール」→「SYSADMIN」、「ウェアハウス」→「ANALYTICS_WH」、「データベース」→「CITIBIKE」、「スキーマ」→「PUBLIC」に設定します。
以下クエリを実行しデータを確認します。
select * from trips limit 20;
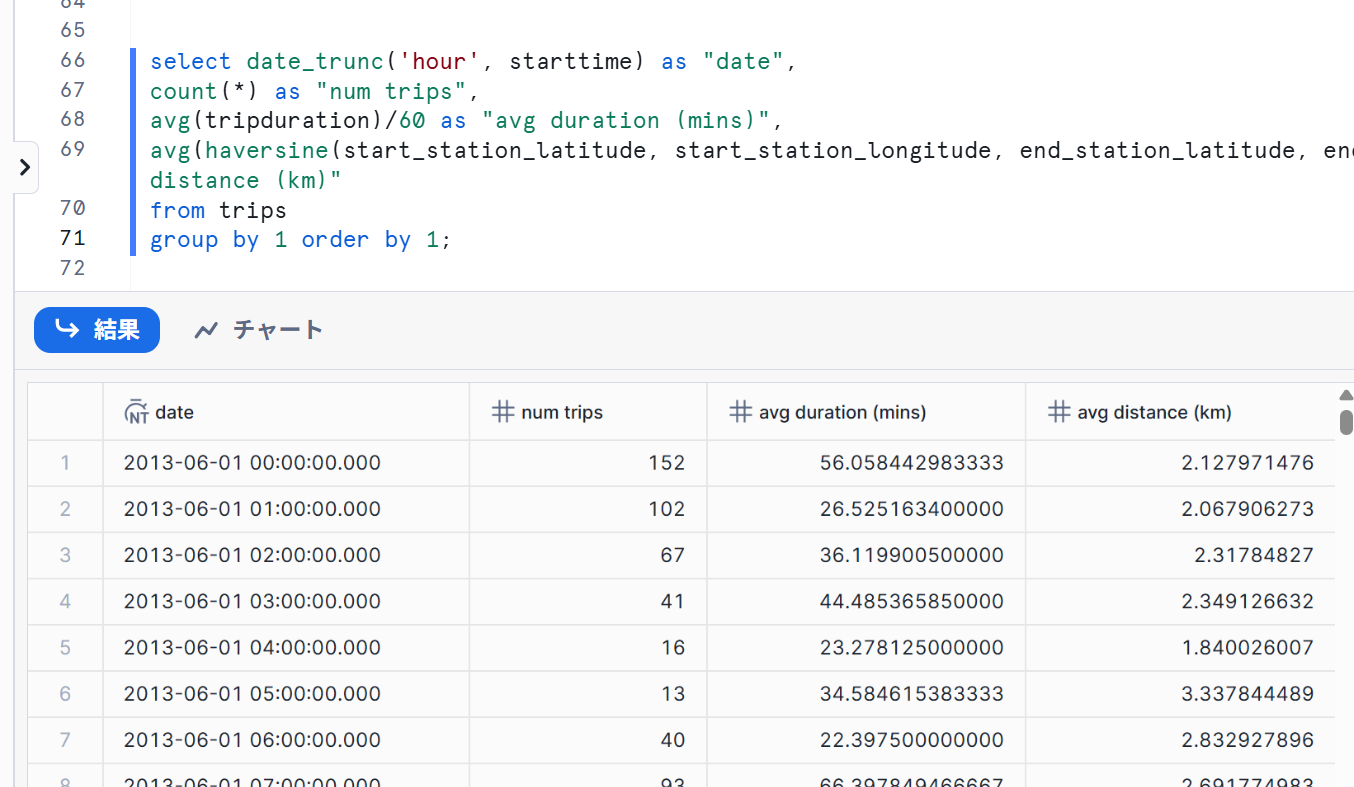
- それぞれの時間の走行回数、平均走行時間、平均走行距離を以下クエリで確認します。
select date_trunc('hour', starttime) as "date",
count(*) as "num trips",
avg(tripduration)/60 as "avg duration (mins)",
avg(haversine(start_station_latitude, start_station_longitude, end_station_latitude, end_station_longitude)) as "avg distance (km)"
from trips
group by 1 order by 1;
結果キャッシュの使用
Snowflakeには、過去24時間に実行されたすべてのクエリの結果を保持する結果キャッシュがあります。これはウェアハウスをまたいで利用可能であるため、あるユーザーに返されたクエリ結果を、基礎データが変更されていない限り、同じクエリを実行したシステム上の他のどのユーザーでも利用することができます。このようにクエリ結果を繰り返し返すことで、クエリの実行が非常に高速になるだけでなく、コンピュートクレジットの消費も回避できます。
上記のとおり結果キャッシュの動作を確認するため、先ほどのクエリを再度実行します。
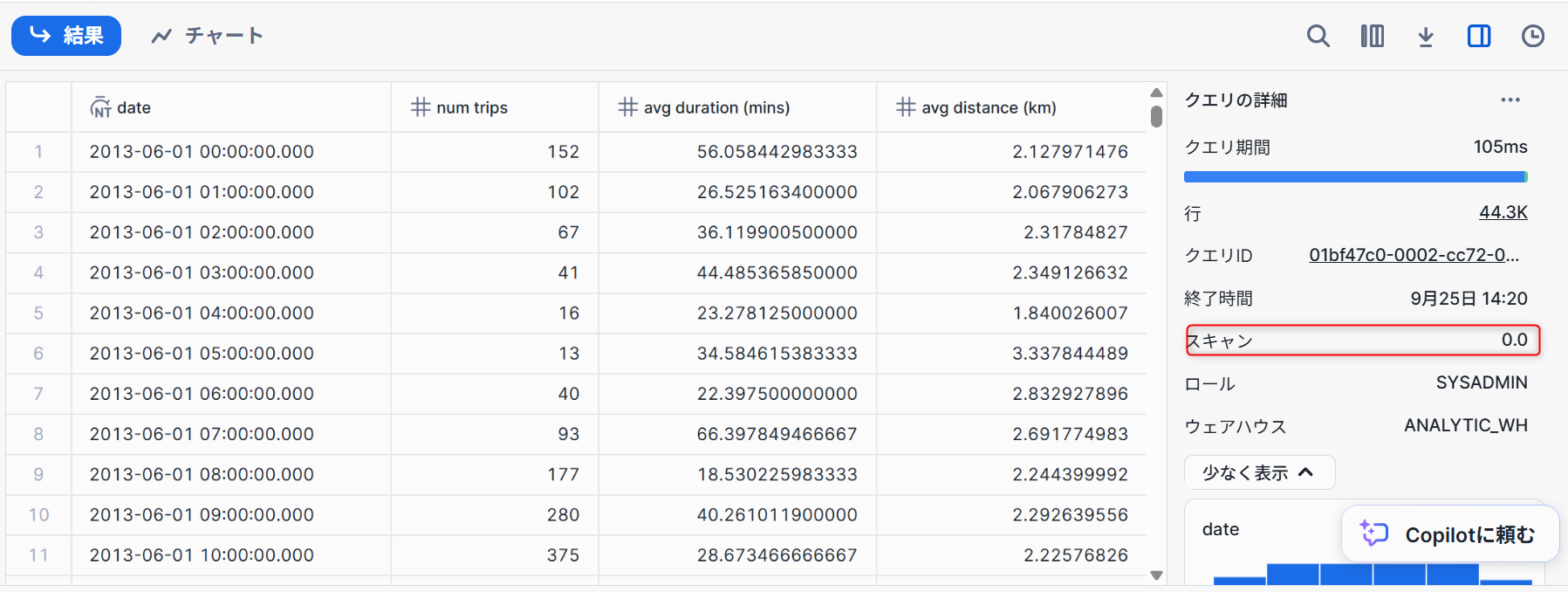
スキャンが0と記載があるため、元のテーブルを参照せずに結果を出力することが出来ています。
クローン
クローン
Snowflakeを使用すると、テーブル、スキーマ、およびデータベースのクローンを数秒で作成できます。これは、「ゼロコピークローン」とも呼ばれます。クローンが作成されると、Snowflakeは、ソースオブジェクト内に存在するデータのスナップショットを取得し、クローンオブジェクトでそれを利用できるようにします。クローンオブジェクトは書き込み可能であり、クローン元から独立しています。つまり、ソースオブジェクトまたはクローンオブジェクトのどちらかに加えられた変更は、もう一方のオブジェクトには反映されないということです。
実際にクローンを試していきます。以下クエリを実行します。
create table trips_dev clone trips;
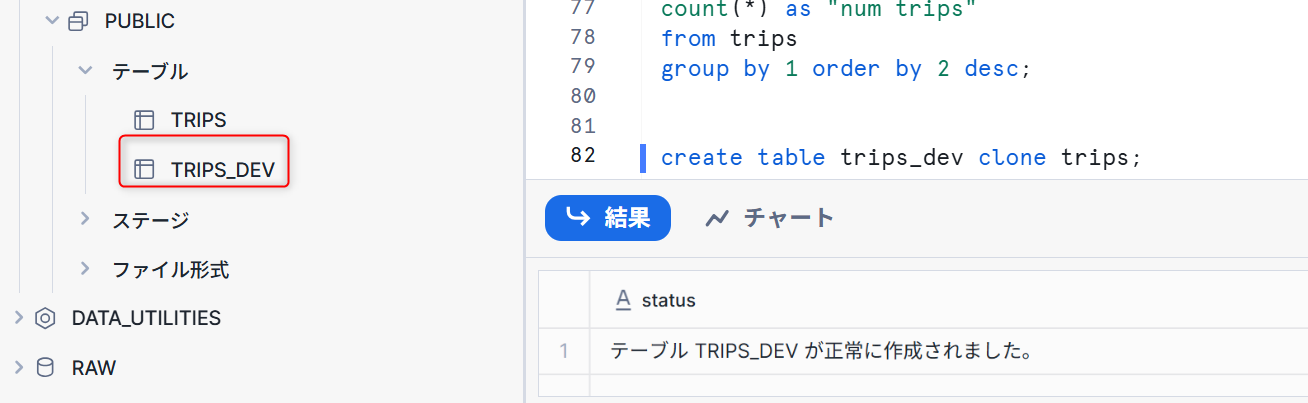
上記のとおりクローンを作成することが出来ました。
半構造化データ、ビュー、結合の操作
このセクションでは以下の内容を確認します。
- 公開されているS3バケットにある半構造化JSON形式の気象データをロードする。
- ビューを作成し、SQLドット表記を使用してJSONデータをクエリする。
- 前にロードした
TRIPSデータにJSONデータを結合するクエリを実行する。 - 気象データと自転車の利用回数データを分析し、それらの関係を見極める。
新しいデータベースとテーブルを作成
- 新しく
WEATHERデータベースを作成します。
create database weather;
- 以下クエリを実行し、使用する項目を指定します。
use role sysadmin;
use warehouse SNOWFLAKE_LEARNING_WH;
use database weather;
use schema public;
- 半構造化データを扱うため、
VARIANTというデータ型の列でテーブルを作成します。
create table json_weather_data (v variant);
外部ステージの作成
先ほどと同様に外部ステージを作成します。今回はコマンドで作成をしていきます。
create stage nyc_weather
url = 's3://snowflake-workshop-lab/zero-weather-nyc';
半構造化データのロード
- 以下コマンドで、テーブルへデータをロードします。
copy into json_weather_data
from @nyc_weather
file_format = (type = json strip_outer_array = true);
- 実際にロードされた結果を確認します。
select * from json_weather_data limit 10;
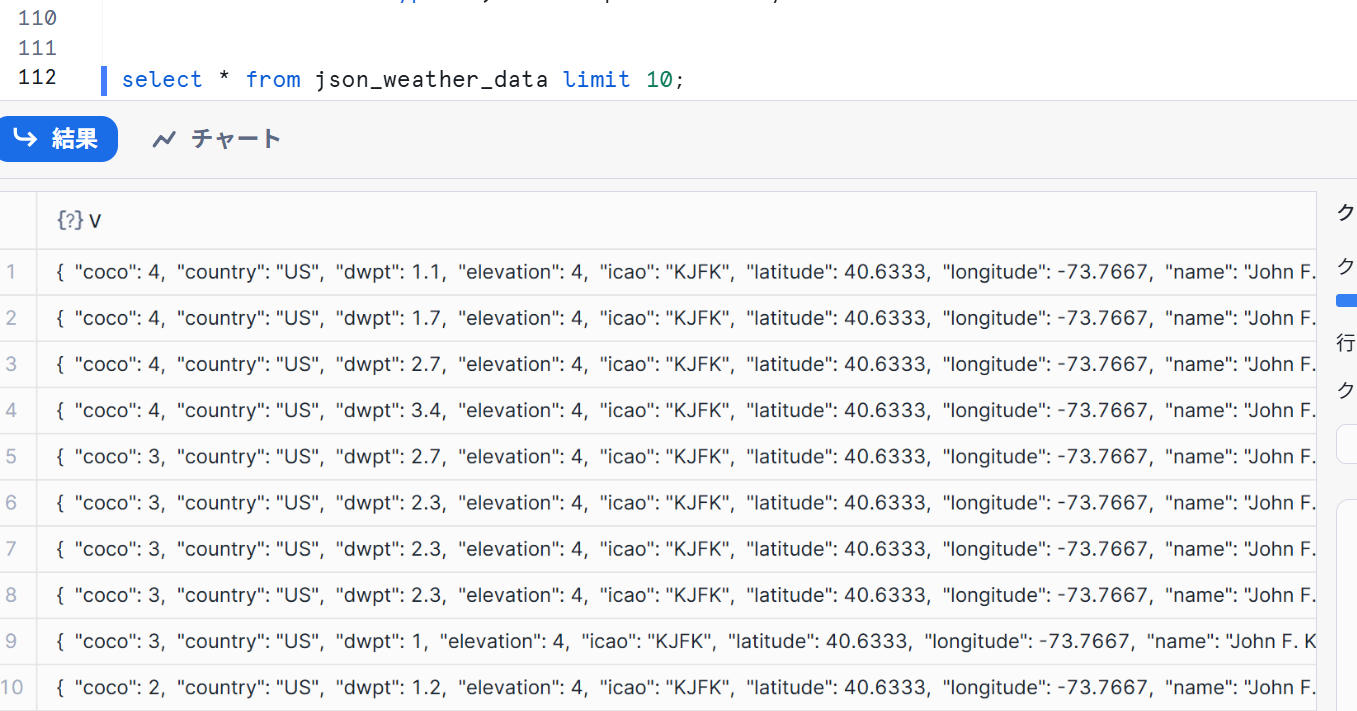
JSON形式でデータが格納されていることが確認できました。
ビューの作成と半構造化データのクエリ
Snowflakeでビューを作成し、SQLを使用してJSONデータを直接クエリする方法を確認していきます。
- 以下のコマンドを実行して、半構造化JSON気象データの列ビューを作成します。
SQLドット表記であるv:tempを使用してJSONオブジェクト階層内の下位レベルの値を取得しています。
// 半構造化データに構造を与えるビューを作成する
create or replace view json_weather_data_view as
select
v:obsTime::timestamp as observation_time,
v:station::string as station_id,
v:name::string as city_name,
v:country::string as country,
v:latitude::float as city_lat,
v:longitude::float as city_lon,
v:weatherCondition::string as weather_conditions,
v:coco::int as weather_conditions_code,
v:temp::float as temp,
v:prcp::float as rain,
v:tsun::float as tsun,
v:wdir::float as wind_dir,
v:wspd::float as wind_speed,
v:dwpt::float as dew_point,
v:rhum::float as relative_humidity,
v:pres::float as pressure
from
json_weather_data
where
station_id = '72502';
- 実際にクエリでビューを作成していきます。
select * from json_weather_data_view
where date_trunc('month',observation_time) = '2018-01-01'
limit 20;
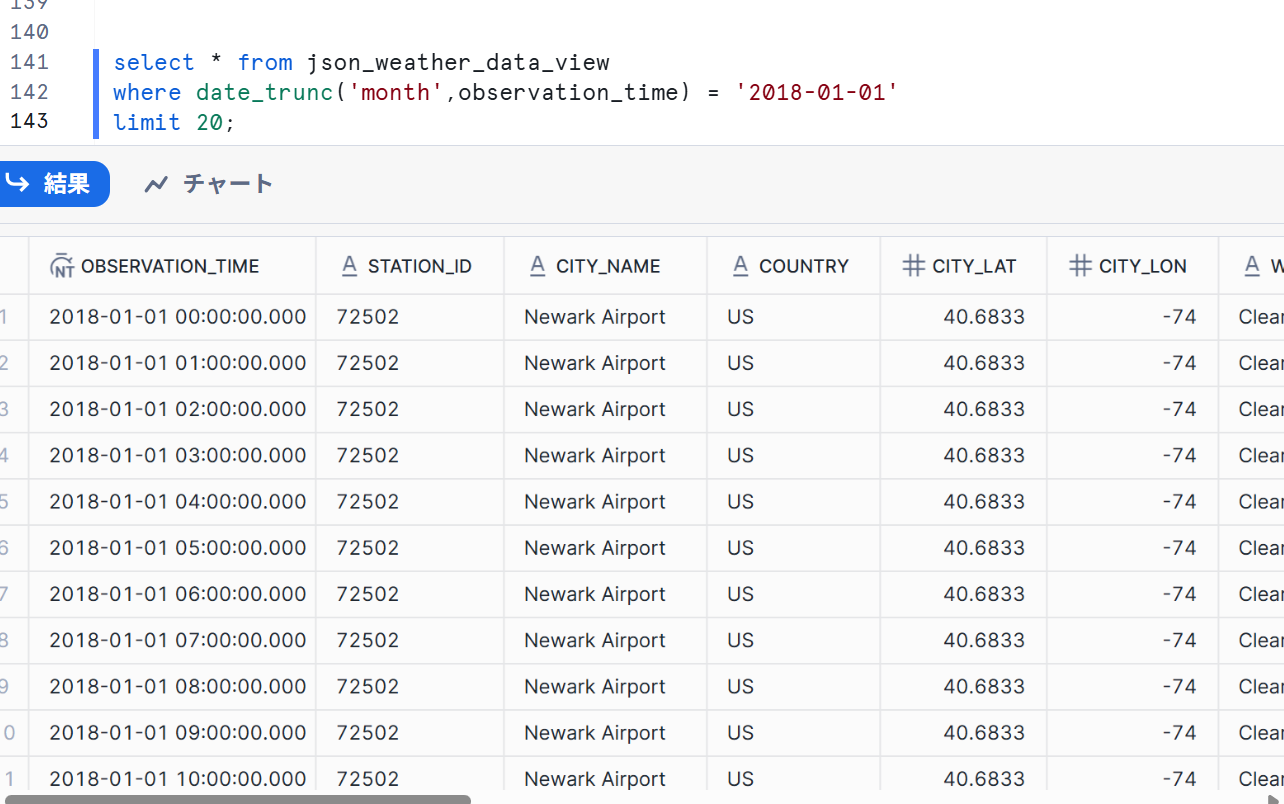
上記のように、構造化されてデータが作成されていることが確認できました。
結合処理
JSON形式の気象データをCITIBIKE.PUBLIC.TRIPSデータに結合します。
以下のクエリを実行して、WEATHERをTRIPSに結合し、特定の天候条件に関連する走行回数をカウントします。
select weather_conditions as conditions
,count(*) as num_trips
from citibike.public.trips
left outer join json_weather_data_view
on date_trunc('hour', observation_time) = date_trunc('hour', starttime)
where conditions is not null
group by 1 order by 2 desc;
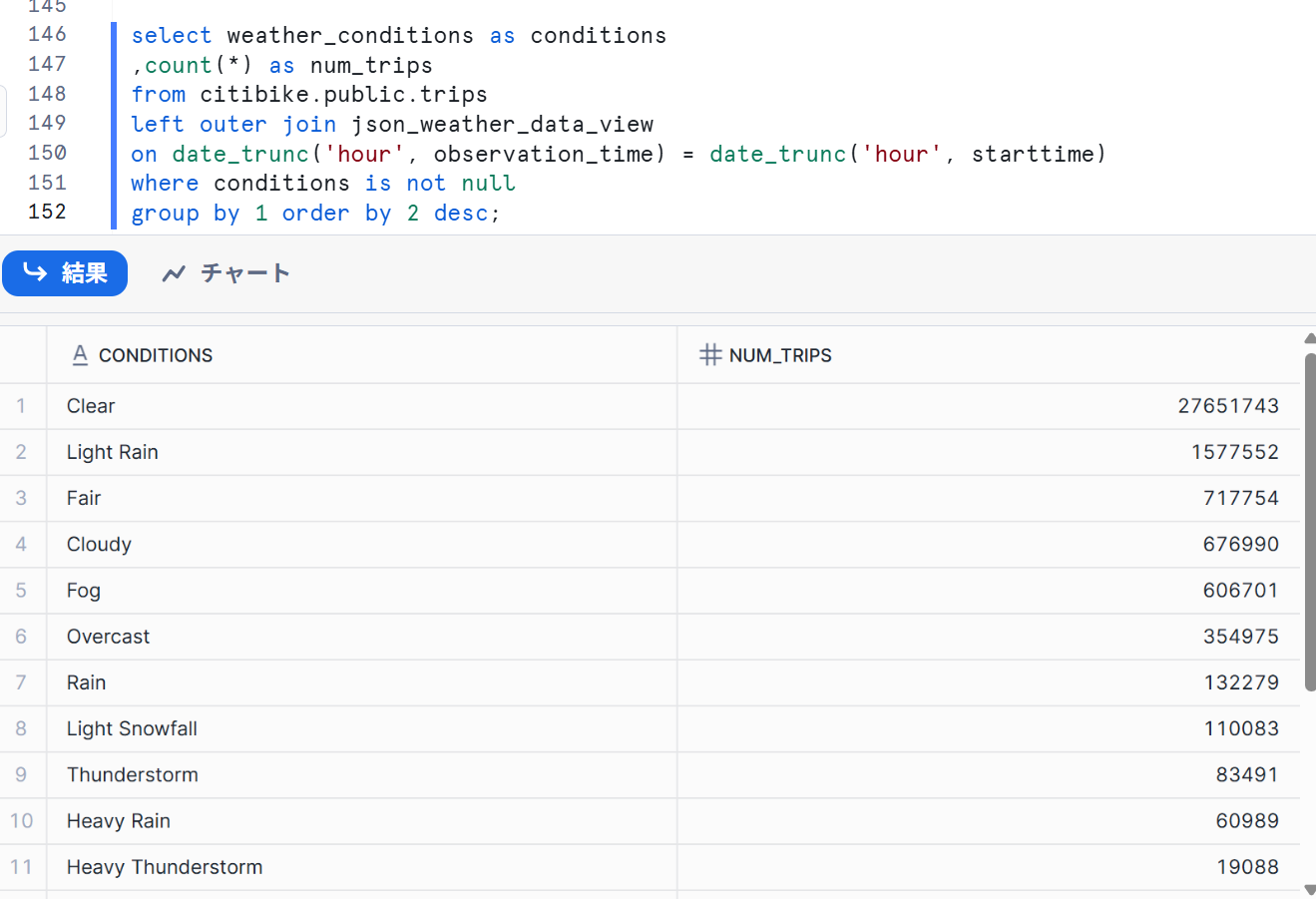
上記のとおり、天候に応じた自転車に乗る回数を確認することができました。
タイムトラベルの使用
タイムトラベル
Snowflakeの強力なタイムトラベル機能を使用すると、履歴データや、データを格納するオブジェクトに、一定期間内の任意の時点でアクセスすることができます。デフォルトの期間の幅は24時間ですが、Snowflakeエンタープライズエディションを使用している場合は、最大90日間まで増やすことができます。
テーブルのドロップとドロップ解除
- 実際にタイムトラベルを使用するために、意図的にテーブルを削除します。
drop table json_weather_data;
select * from json_weather_data limit 10;
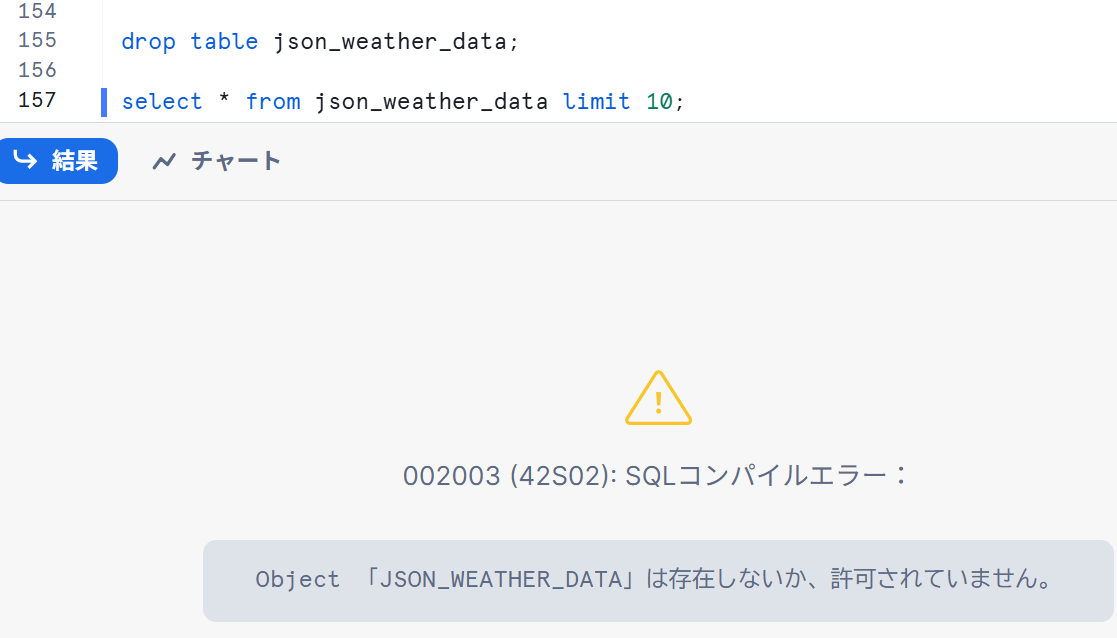
上記のように削除されたことが確認できました。
- テーブルを復元します。
undrop table json_weather_data;
セレクト文で確認すると以下のように、テーブルが復元されていることが確認できました。
テーブルのロールバック
タイムトラベルでは以前の状態にロールバックすることができます。
- 以下のコマンドを実行し使用する項目を指定します。
use role sysadmin;
use warehouse SNOWFLAKE_LEARNING_WH;
use database citibike;
use schema public;
- 意図的にテーブル内の駅名をすべて
oopsとします。
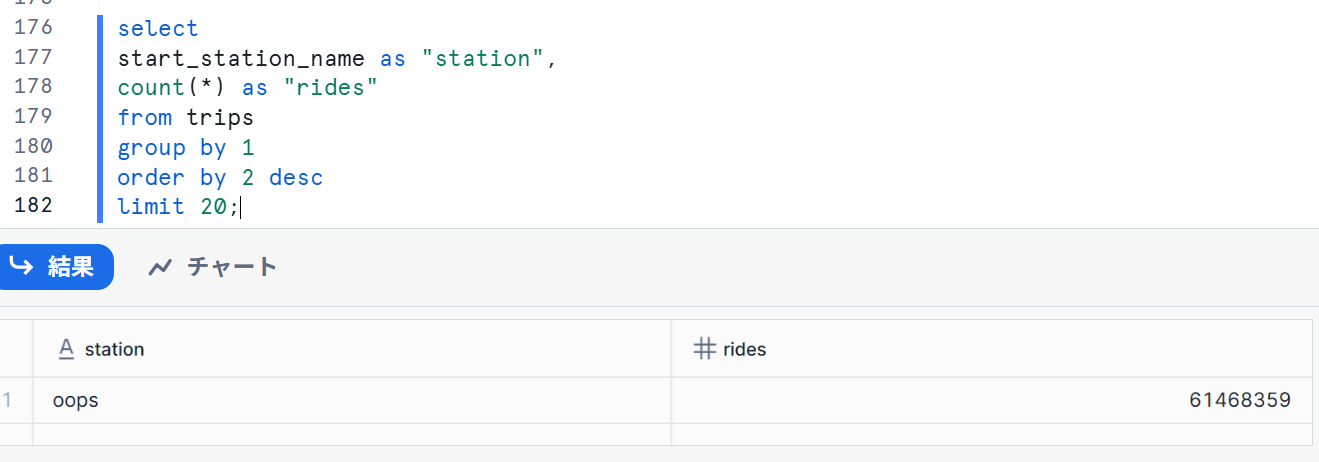
update trips set start_station_name = 'oops';
- 自転車の利用回数の上位20ステーションを返すクエリを実行します。当然先ほどすべての駅名が
oopsなので1行しか結果は返ってきません。
select
start_station_name as "station",
count(*) as "rides"
from trips
group by 1
order by 2 desc
limit 20;
- 直近のUPDATEコマンドのクエリIDを見つけ、それを$QUERY_IDという名前の変数に格納します。
set query_id =
(select query_id from table(information_schema.query_history_by_session (result_limit=>5))
where query_text like 'update%' order by start_time desc limit 1);
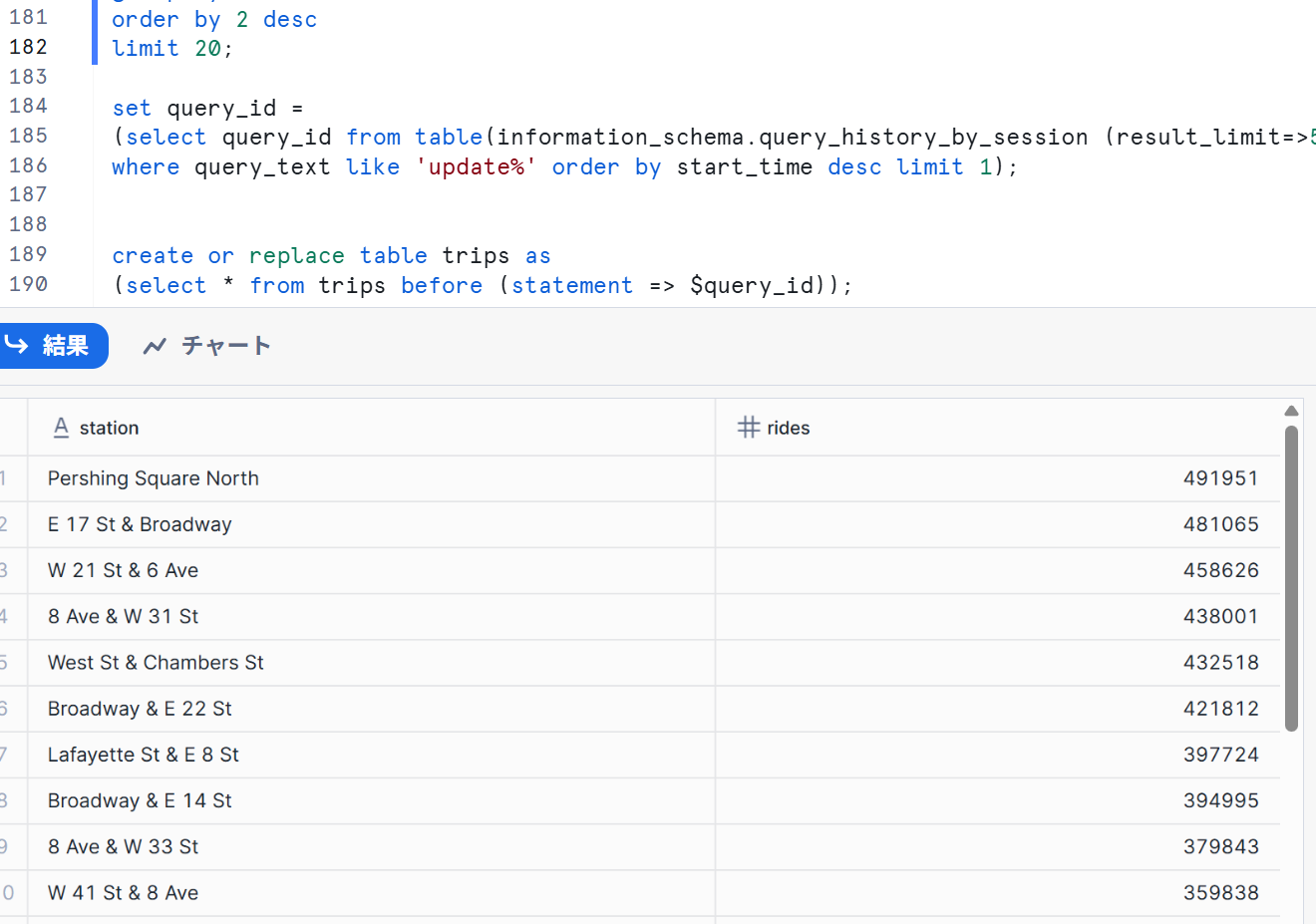
そのクエリIDを使用し、以前の状態へ復元させます。
create or replace table trips as
(select * from trips before (statement => $query_id));
再び3を実行すると以下のように復元できていることが確認できました。
ロール、アカウント管理者、アカウント使用状況の操作
このセクションでは、ロールの作成やロールへの特定の権限の付与など、Snowflakeのアクセス制御セキュリティモデルについて確認します。
新しいロールの作成とユーザーの追加
accountadmin権限を利用するため、下記コマンドを実行します。
use role accountadmin;
※強力な権限をもつロールなので使用の際は注意してください。
junior_dbaロールを作成し、自分に割り当てます。
create role junior_dba;
-- YOUR_USERNAME_GOES_HEREにはご自身のユーザー名を記載してください
grant role junior_dba to user YOUR_USERNAME_GOES_HERE;
junior_dbaロールを使用します。
use role junior_dba;
ここでウェアハウスやデータベースを確認して、先ほど作成したものが表示されていなければ成功ですが、最近のSnowflakeでは、DEFAULT_SECONDARY_ROLESがデフォルトで'ALL'に設定されています。
そのため、セカンダリーロールが機能してjunior_dbaに権限がなくても確認できてしまう可能性があります。
-- 現在のセカンダリロールを確認
SELECT CURRENT_SECONDARY_ROLES();
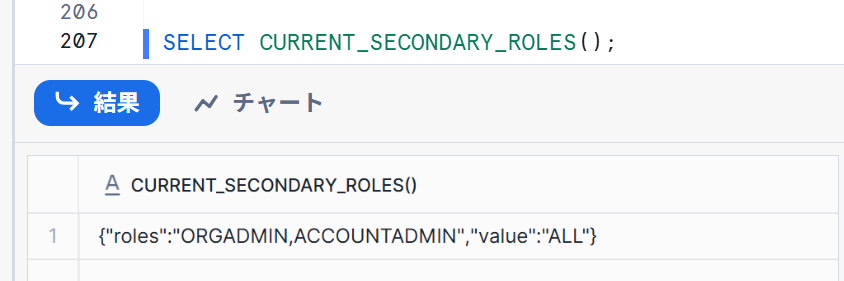
ALLだったため、セカンダリロールを無効にします。
-- セカンダリロールを無効
USE SECONDARY ROLES NONE;
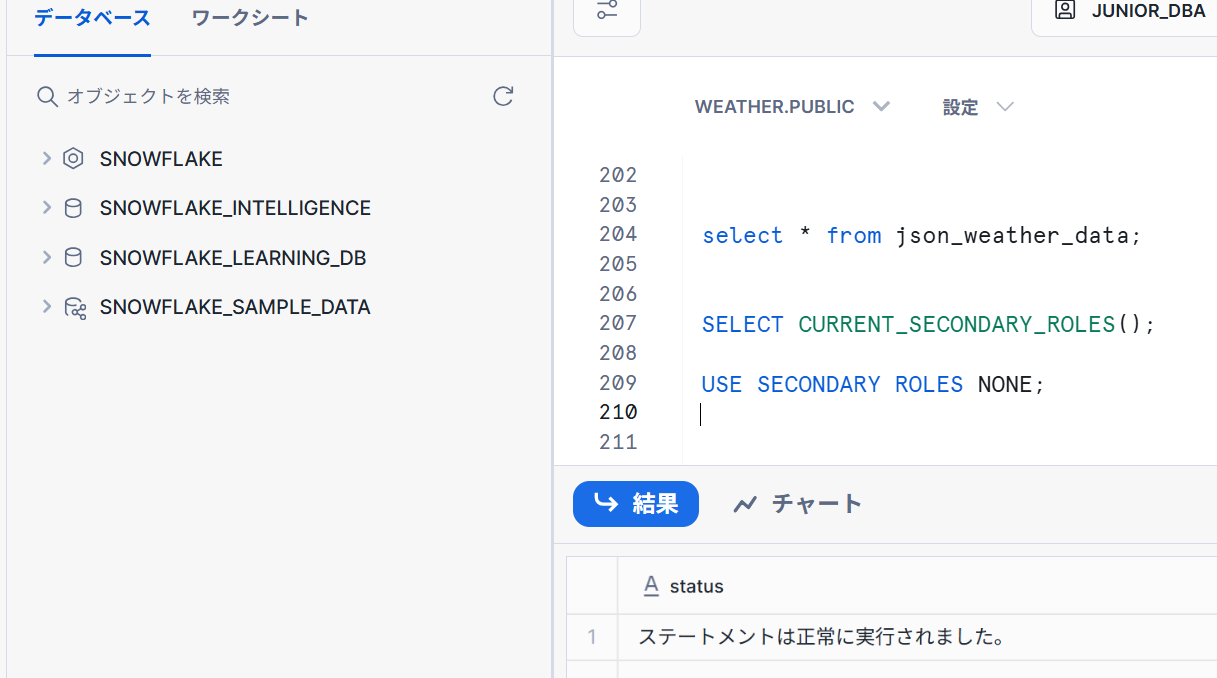
権限のないものが確認できなくなりました。
junior_dbaロールへ各種権限を付与します。
use role accountadmin;
grant usage on warehouse SNOWFLAKE_LEARNING_WH to role junior_dba;
grant usage on database citibike to role junior_dba;
grant usage on database weather to role junior_dba;
junior_dbaロールへ切り替えます。
use role junior_dba;
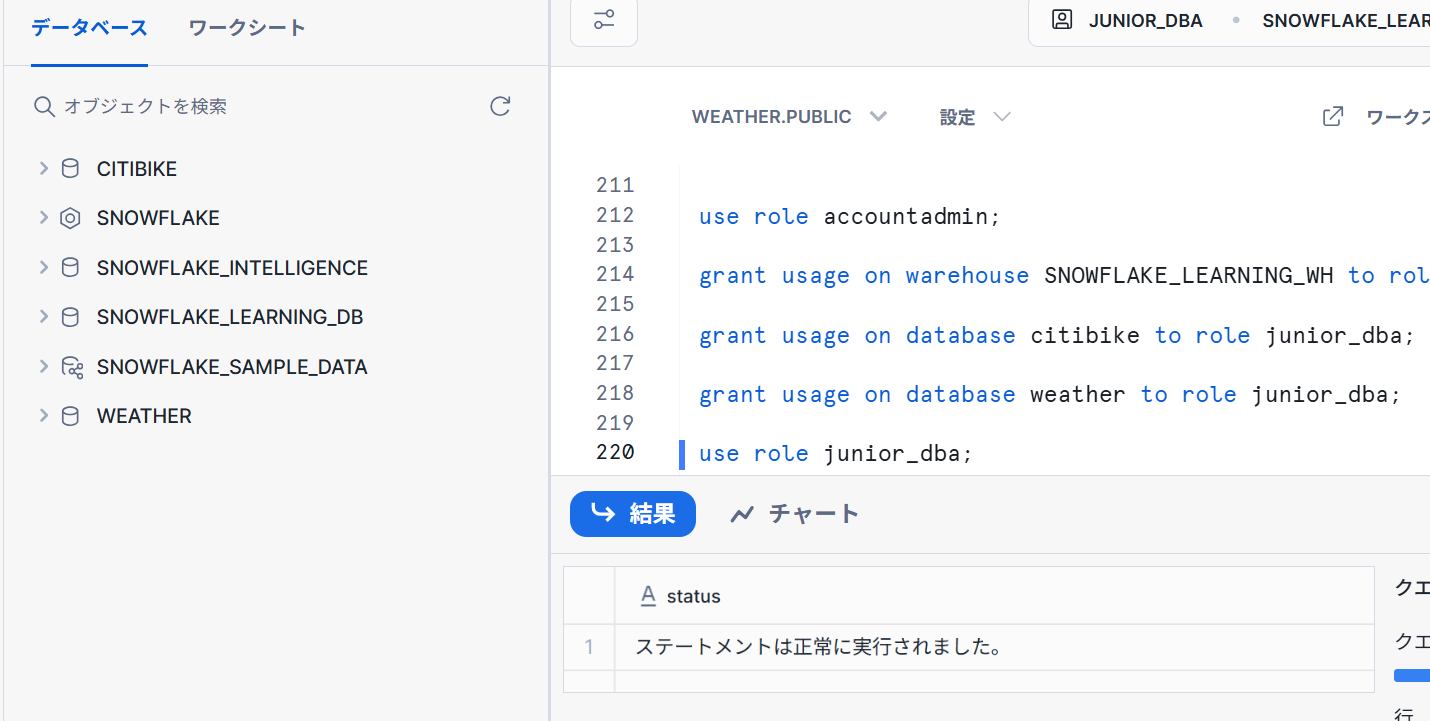
CITIBIKEおよびWEATHERデータベースが権限が付与されたことにより確認することができます。
データの安全な共有とマーケットプレイス
Secure Data Sharing
Snowflakeは、安全なデータシェアリング機能を通じて、アカウント間でのデータアクセスを実現します。共有は、データプロバイダーによって作成され、データコンシューマーにより、自身のSnowflakeアカウントまたはプロビジョニングされたSnowflakeリーダーアカウントを通じてインポートされます。
既存の共有を表示
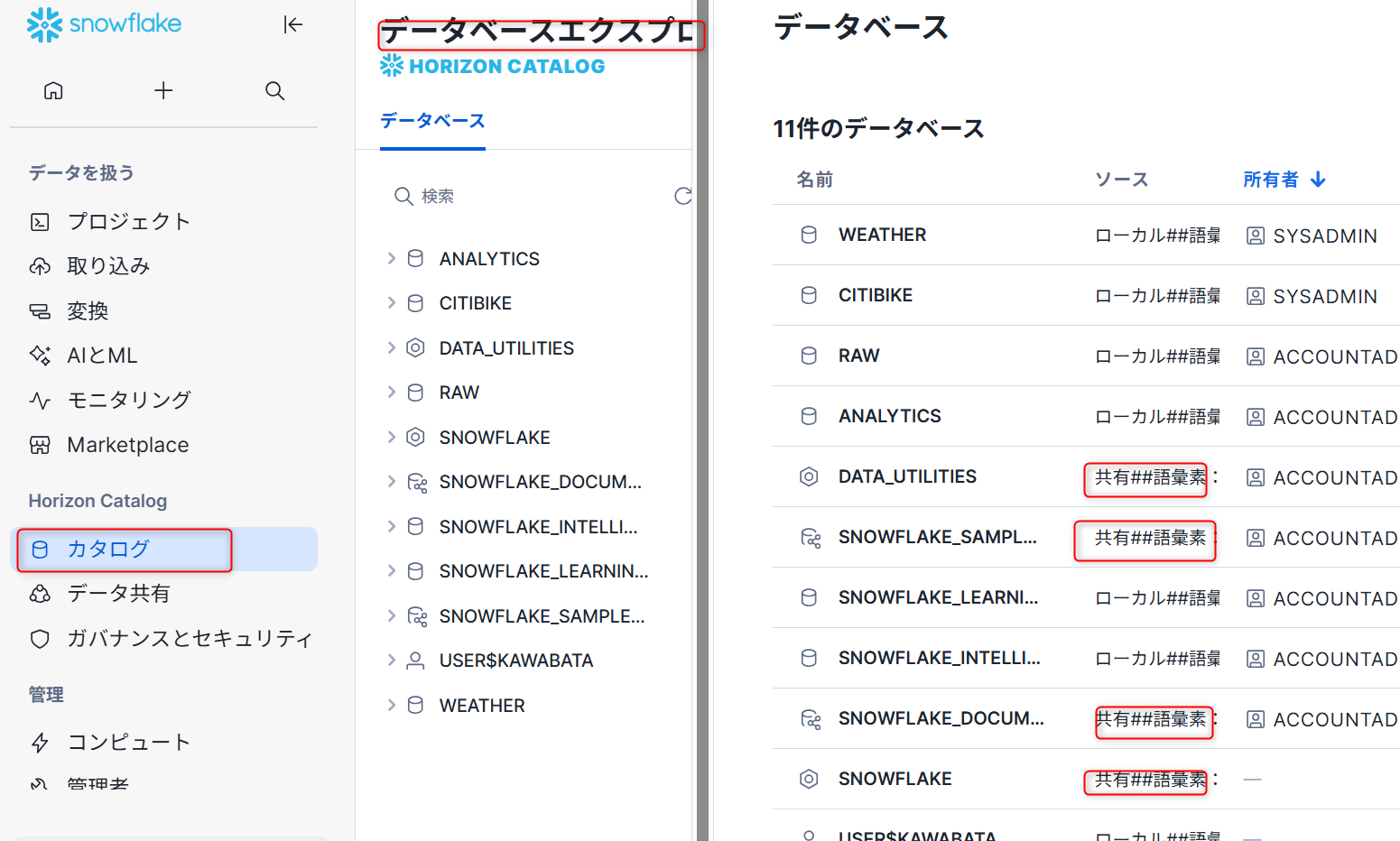
「カタログ」→「データベースエクスプローラー」を選択すると下記のような画面が表示されます。
ソース部分で「共有」となっている部分が、プロバイダーから共有されている既存のものです。
アウトバウンド共有の作成
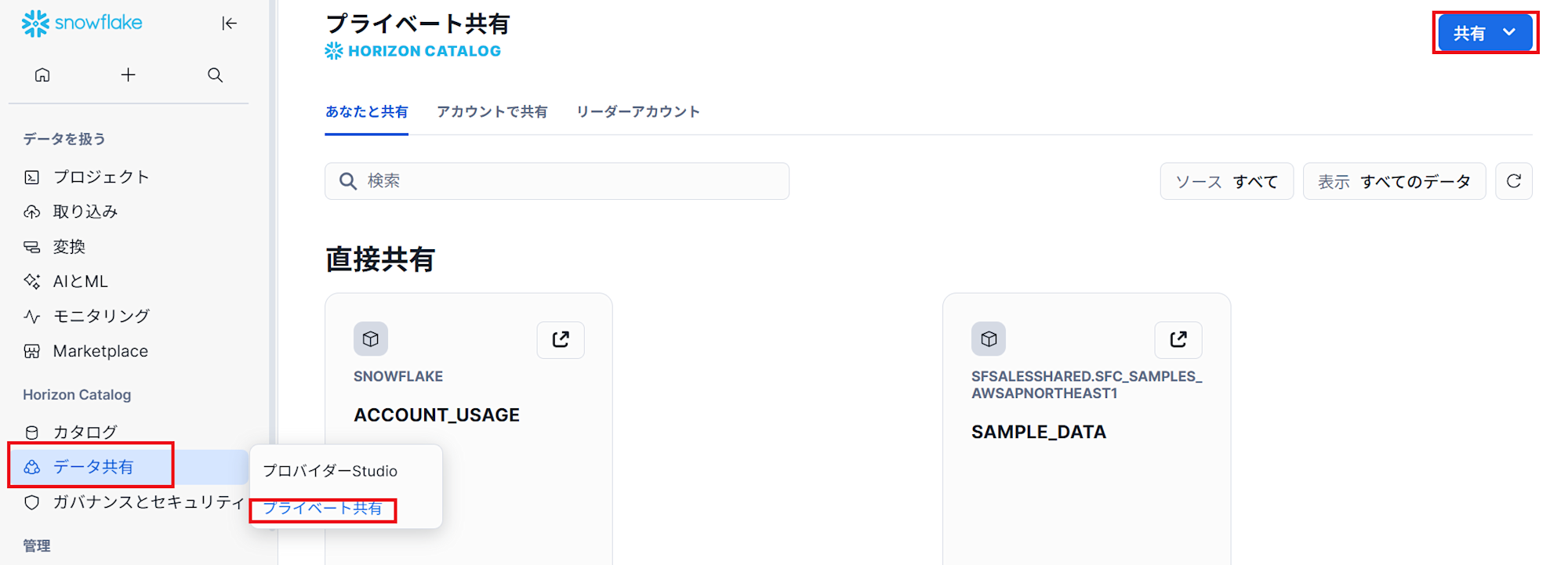
安全なデータシェアリングを使って、パートナーがこの情報にアクセスできるようにしていきます。
- 「データ共有」→「プライベート共有」へ進み、右上側の「共有」から「直接共有の作成」を選択します。
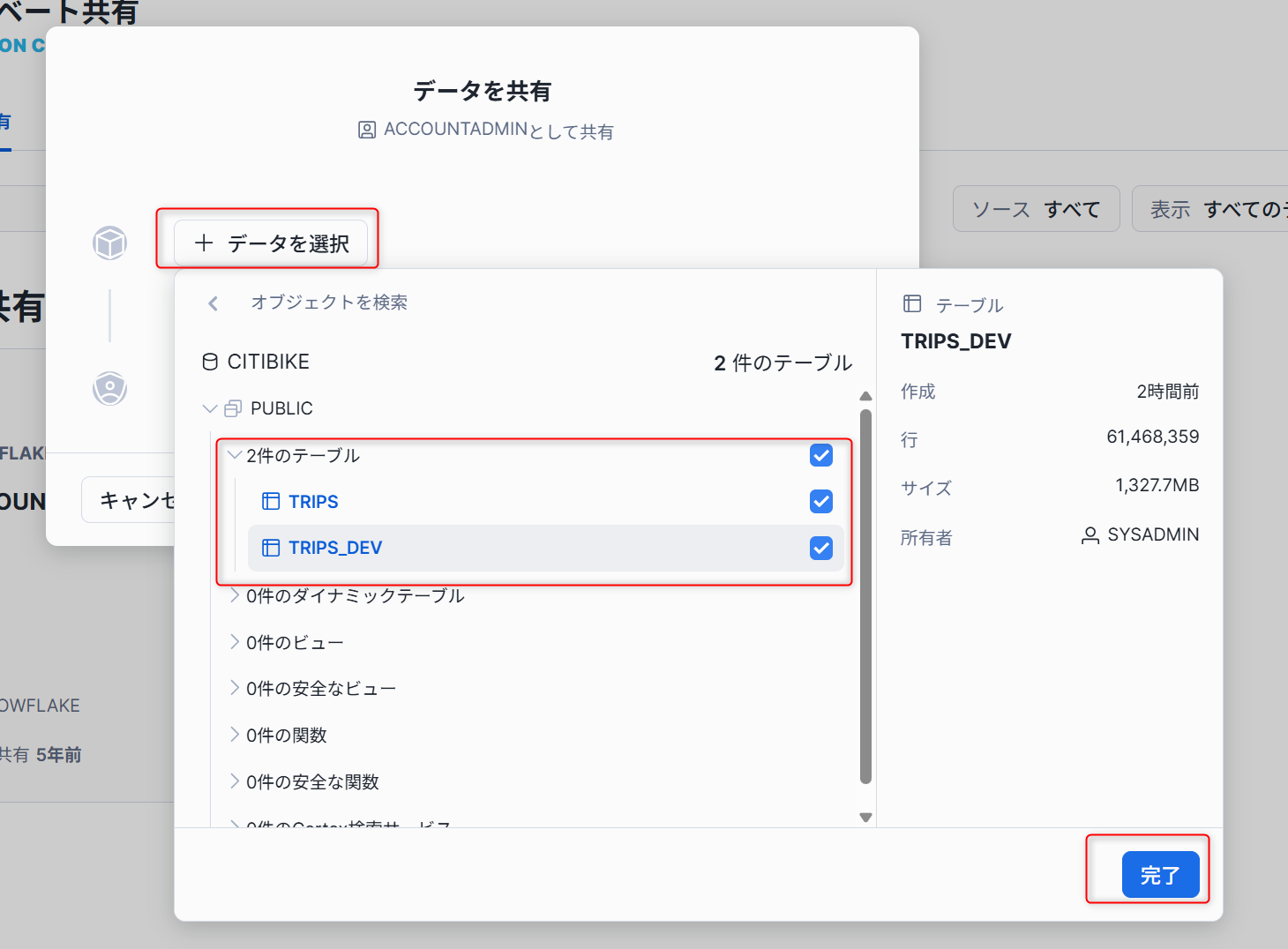
-
ポップアップした画面から「+データの選択」をクリックし、
CITIBIKEデータベースとPUBLICスキーマから記載のテーブルを選択します。
-
名称を
ZERO_TO_SNOWFLAKE_SHARED_DATAとし、共有を作成します。
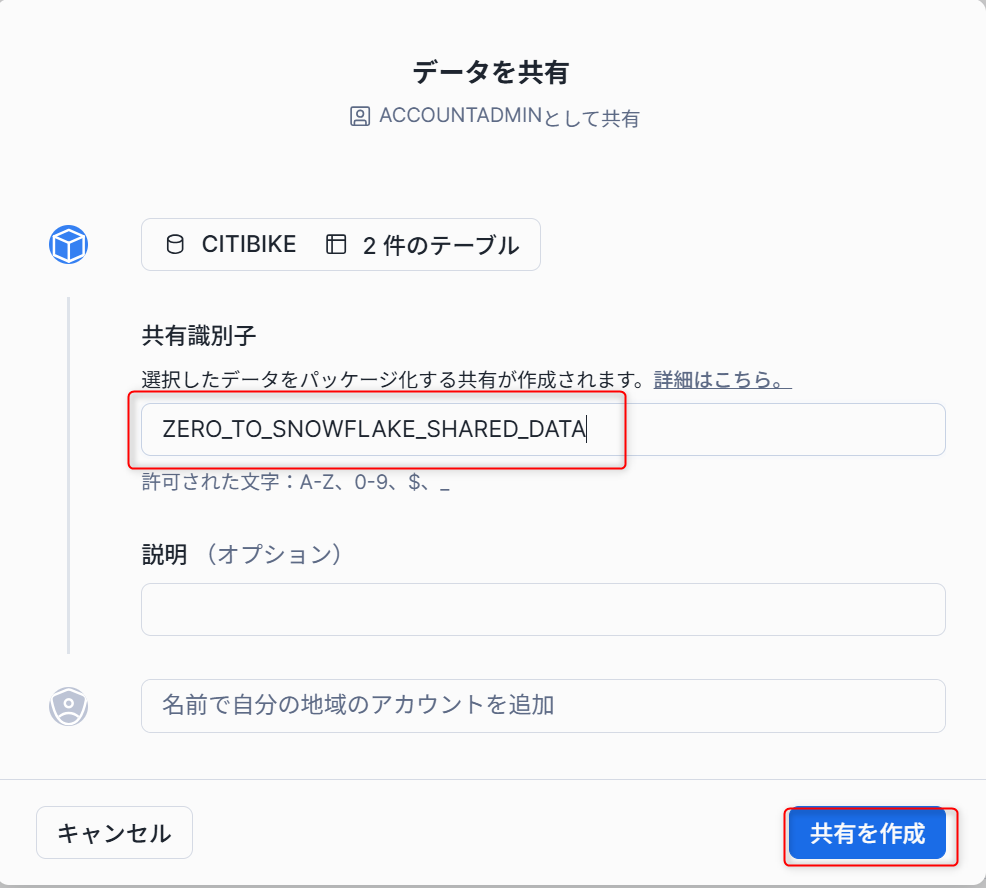
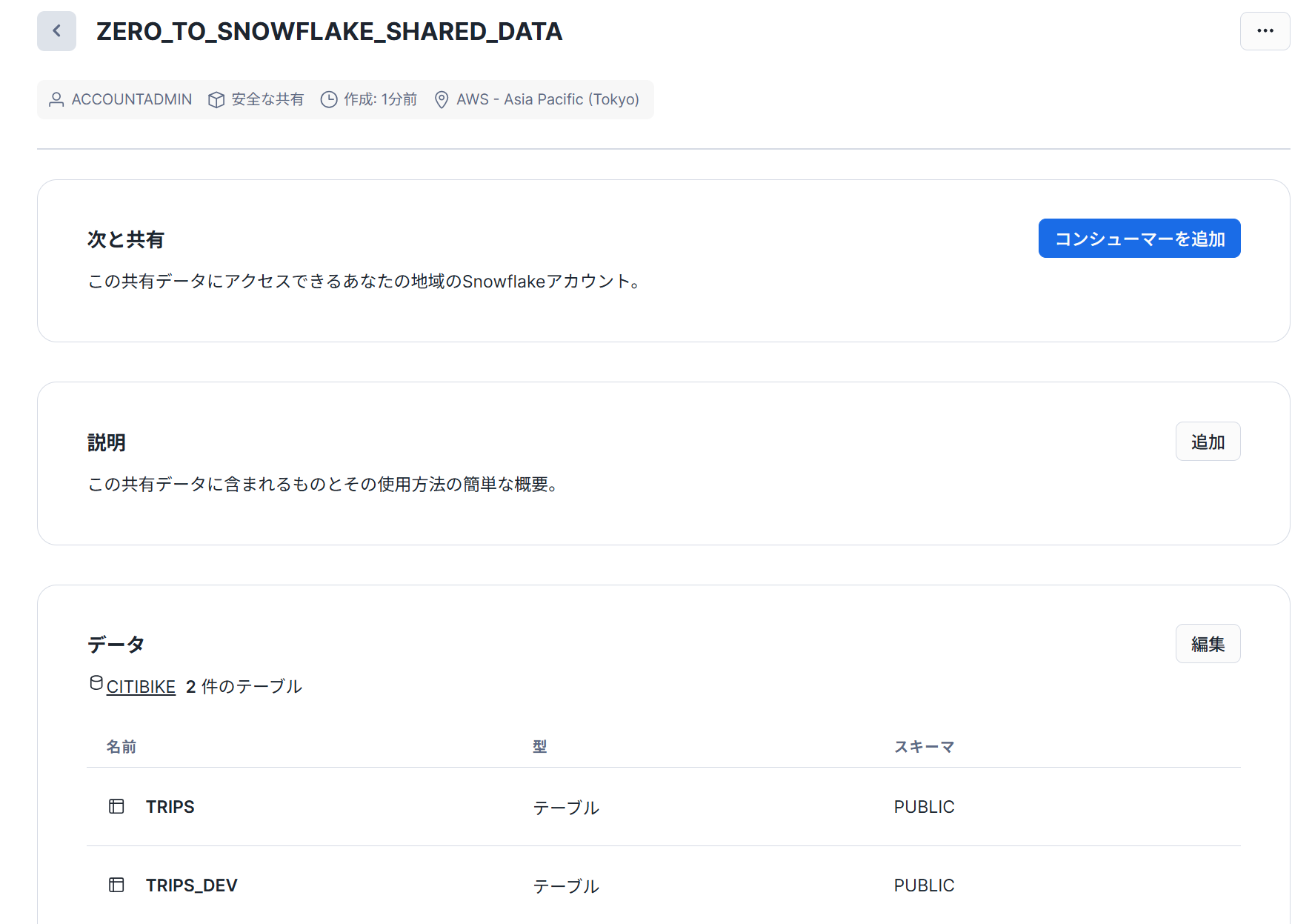
以下のように共有ページが作成されます。コンシューマーを追加することで、対象のアカウントに共有することができます。
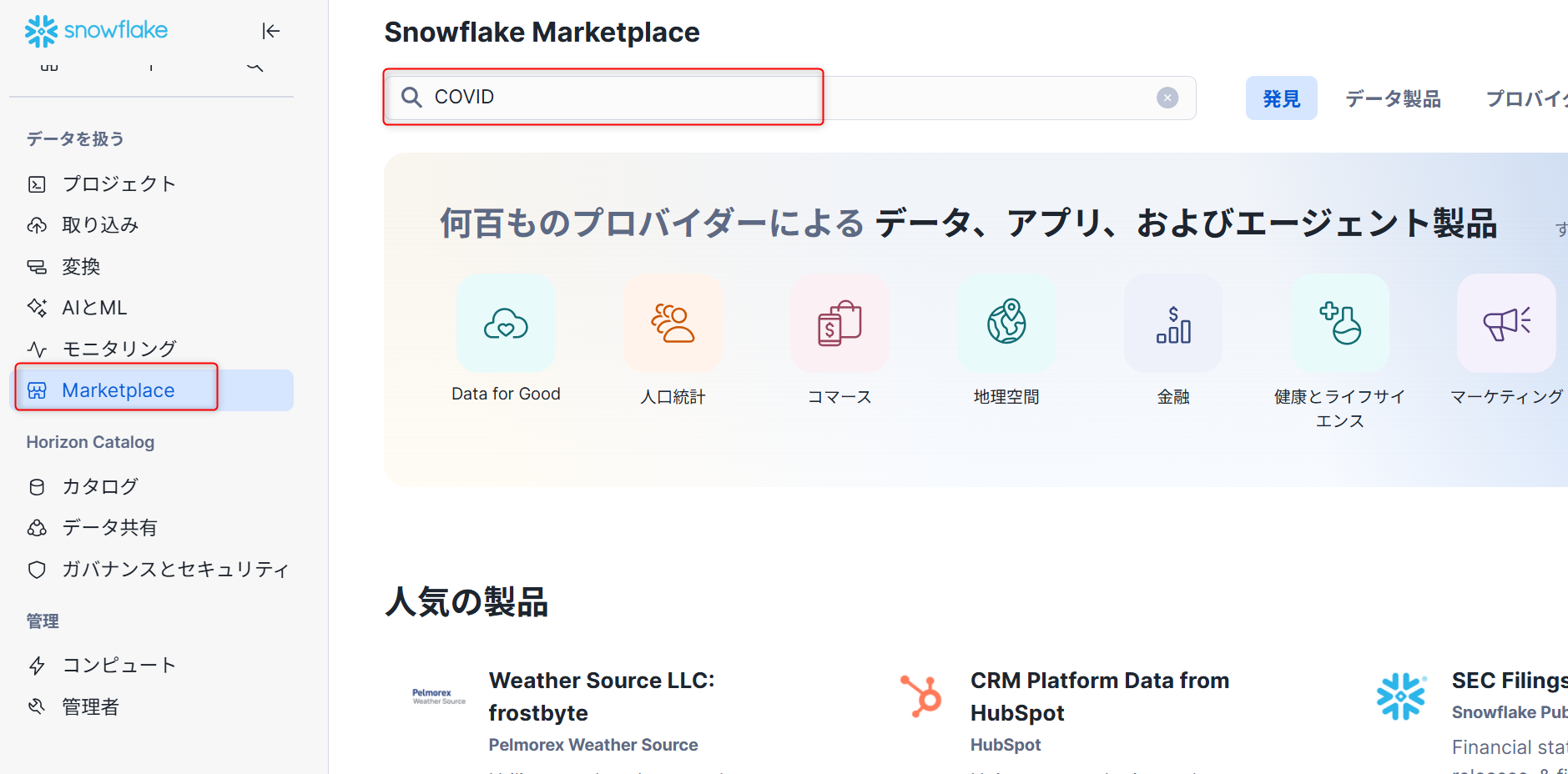
Snowflakeマーケットプレイス
ACCOUNTADMINロールでマーケットプレイスへ移動します。検索ボックスに「COVID」と入力し検索します。
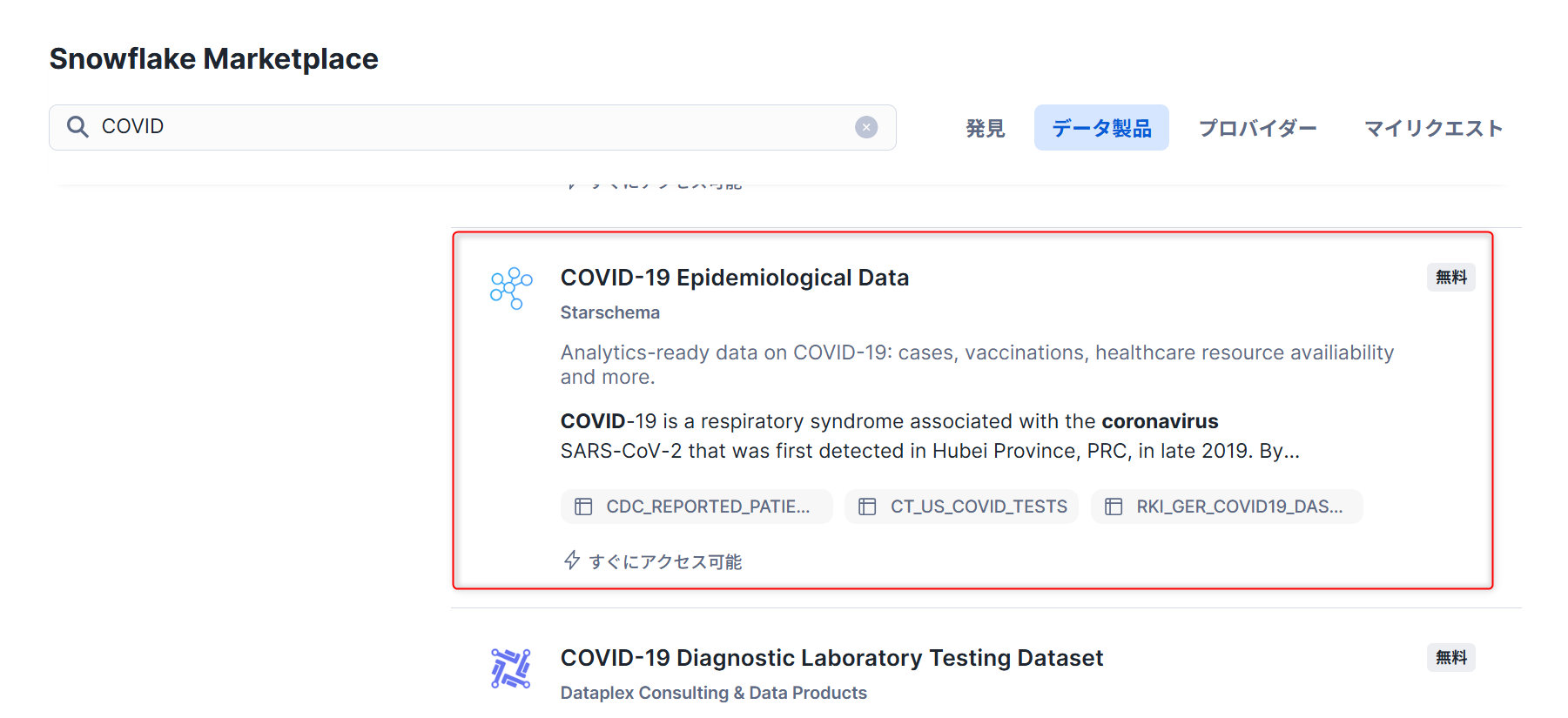
以下のように、「COVID-19疫学データ(提供:Starschema)」を選択します。
ポップアップした画面で「取得」をクリックします。
インストール完了画面で「開く」を選択すると下記ワークシートが作成されます。
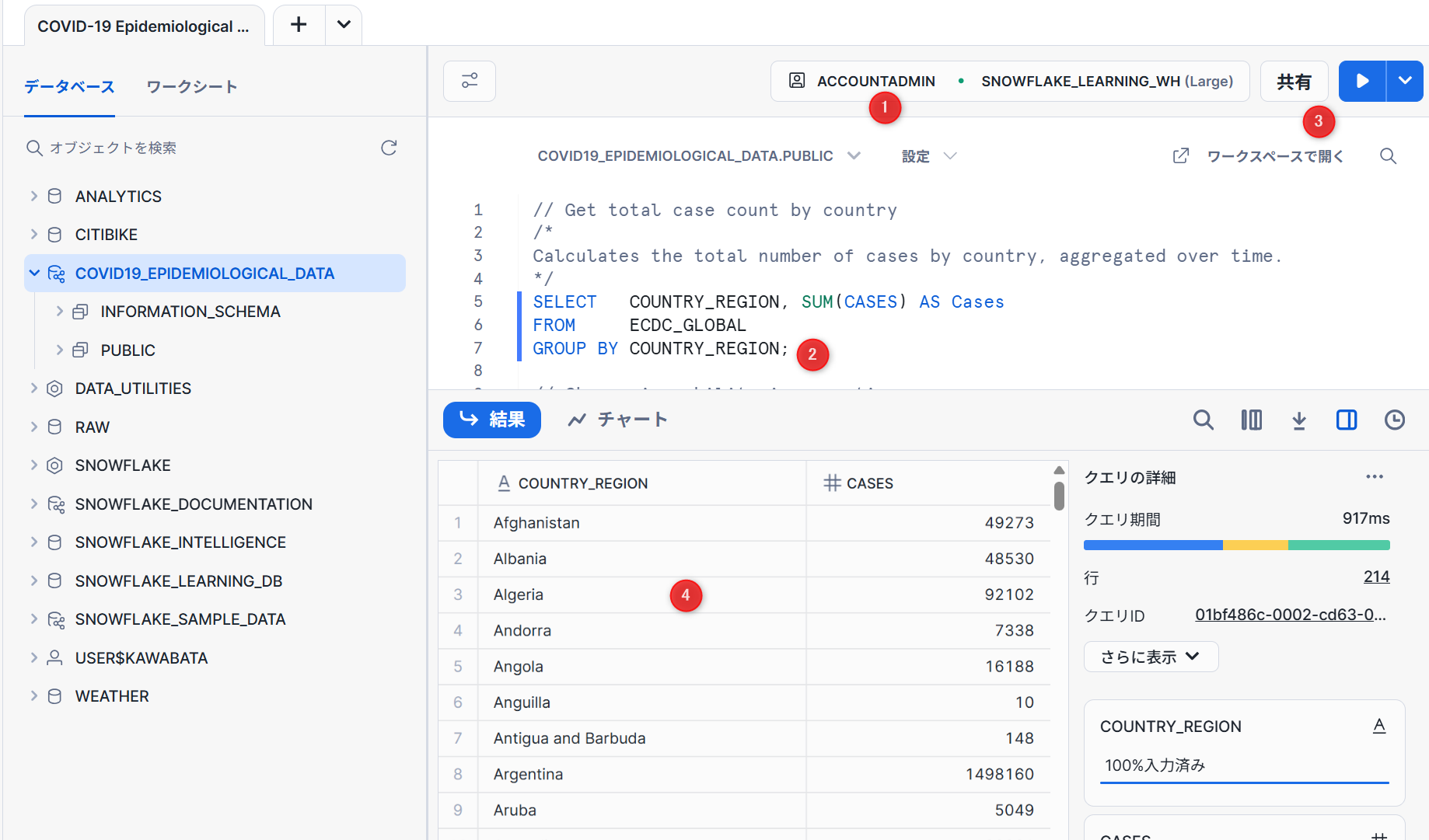
- コンテキストの設定
- 実行したいクエリを選択します。
- 「実行/再生」ボタンをクリックします。
- 最下部でデータ結果を確認できます。
Snowflakeマーケットプレイスの共有データを検索し、アクセスするだけで世界的なCOVIDのデータを取得することができます。
Snowflake環境のリセット
以下コマンドを実行すると、Quickstartで作成したデータベース等を削除することができます。
drop share if exists zero_to_snowflake_shared_data;
-- If necessary, replace "zero_to_snowflake-shared_data" with the name you used for the share
drop database if exists citibike;
drop database if exists weather;
drop warehouse if exists analytics_wh;
drop role if exists junior_dba;
最後に
個人的にはQuickstartに記載のUIと現在のSnowsightのUIが変わっており苦慮しましたが、この機会に確認することができてよかったです。特に「AI&ML」の項目や現在プレビューの項目はまだ試せていないものが多いので実際に試してみようと思います。
「ゼロからはじめるSnowflake」2025年9月版として、実施する際の参考になれば幸いです。







