
【登壇レポート】Splunk Experience Day 2025 で「Splunk Federated Search for S3 ✕ AWS連携」というタイトルで登壇しました
2025年7月17日、Splunk Experience Day 2025において「Splunk Federated Search for S3 × AWS連携〜実践的データパイプライン構築のポイントを公開〜」というテーマで登壇させていただきました。
本記事では、登壇資料の共有をいたします。
Splunk Experience Day 2025 開催情報
登壇資料
Splunk Federated Search for S3(FSS3)とは
FSS3は、Splunk Cloudに直接データを取り込むことなく、Amazon S3上のデータに対してダイレクトクエリを実行できる機能です。主な特徴は以下の通りです:
主な特徴
- 直接クエリ:データをSplunkに取り込まずS3上のファイルを直接検索
- DSUライセンス:データスキャン量に応じたライセンス消費(1DSU = 10TB Scan)
- AWS Glue連携:AWS Glue Data Catalogを利用したメタデータ管理
- パーティション対応:効率的な検索を実現するパーティショニング機能
想定ユースケース
| 場面 | 説明 |
|---|---|
| 低頻度アクセス | 普段は利用しないが、万が一のセキュリティ調査時にアクセス |
| 過去データの分析 | セキュリティインシデント時の侵入経路調査等 |
| 長期レポート | 過去データの統計分析 |
| コンプライアンス | 規制を満たすための長期保管データの活用 |
| ログ分析の中央化 | クエリ実行を中央化し、簡便性・迅速性・アクセス性を向上 |
アーキテクチャ
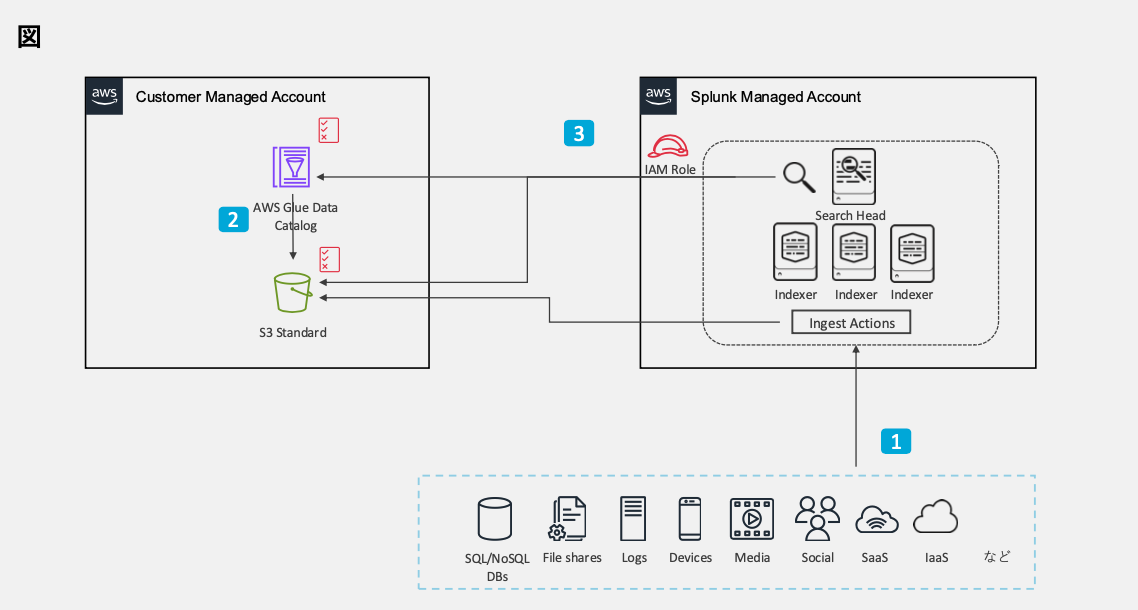
データパイプライン構築の実践
FSS3を効果的に活用するためには、適切なデータパイプラインの構築が重要です。構築手順は以下の3段階に分けられます。
1. データの送信(Splunk Cloud側)
インジェストアクションを活用して、データ取り込み前に以下の処理を実行:
- データの変換
- フィルタリング
- データマスキング
- データの転送
- Amazon S3転送時の自動パーティショニング
- ※フィルタリング・転送されたデータはライセンスカウント対象外
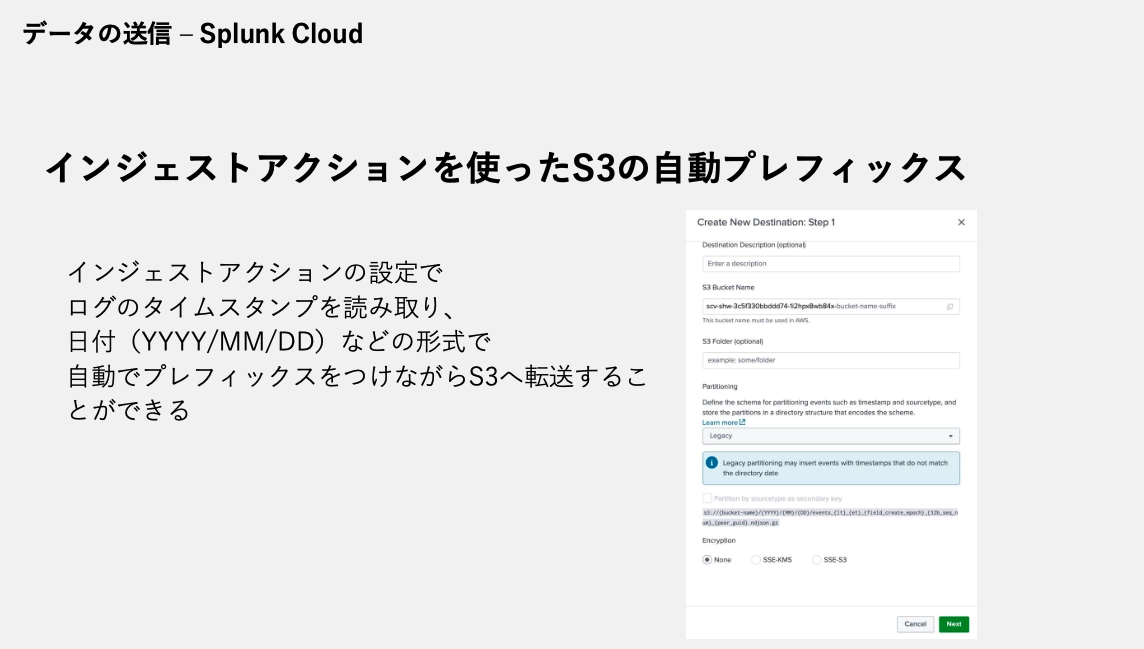
重要なポイントとして:Splunkには自動プレフィックス設定を行ってくれる機能があります
インジェストアクションの設定により、ログのタイムスタンプを読み取って日付(YYYY/MM/DD)形式で自動的にプレフィックスを付与できます。これにより効率的なパーティショニングが実現されます。
2. メタデータの登録(AWS側)
AWS Glue Data Catalogへのメタデータ登録方法:
- AWS Glue Data Catalog直接設定
- AWS Glue Crawler自動検出
- Amazon Athena DDL実行(今回はこちらを紹介)
Apache Access Logの設定例:
CREATE EXTERNAL TABLE apache_logs (
`client_ip` string,
`client_id` string,
`user_id` string,
`request_received_time` string,
`method` string,
-- 他のフィールド定義...
)
PARTITIONED BY (
`day` string
)
ROW FORMAT SERDE 'com.amazonaws.glue.serde.GrokSerDe'
WITH SERDEPROPERTIES (
'input.format'='^%{IPORHOST:client_ip} %{USER:client_id} ...'
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<bucket>/<path>/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.day.type'='date',
'projection.day.range'='2025/01/20,2025/03/18',
'projection.day.format'='yyyy/MM/dd',
'projection.day.interval'='1',
'projection.day.interval.unit'='DAYS',
'storage.location.template'='s3://<bucket>/<path>/${day}'
);
Partition Projectionの活用
従来のパーティション管理では、新しいパーティションが追加されるたびにALTER TABLEでロードする必要がありました。Partition Projectionを使用することで:
- パーティション値と場所を自動算出
- GetPartitions API呼び出し不要
- メモリ内計算による高速処理
3. データアクセス権限とマッピング(Splunk Cloud側)
Federated Providers設定:
- Splunk CloudからGlue Data Catalogへのアクセス権限
- S3バケットへのアクセス権限
Federated Index設定:
- 時間フィールドのマッピング
- パーティションフィールドの識別設定
パフォーマンステスト結果
実際の検証では、3つの異なるデータセットでテストを実施しました:
| S3パーティション | オブジェクト数 | データ量 | 圧縮形式 | 検索時間 |
|---|---|---|---|---|
| /2025/01/27 | 567 | 475 MB | gzip | 29.038秒 |
| /2025/01/28 | 2,695 | 3.4 GB | gzip | 51.904秒 |
| /2025/01/29 | 5 | 1.7 MB | gzip | 2.352秒 |
AWSコスト試算(月額)
AWSは従量課金という特性上、正確な料金算出ではありませんが、3.4GBデータの場合の概算月額費用をシミュレートしてみました。

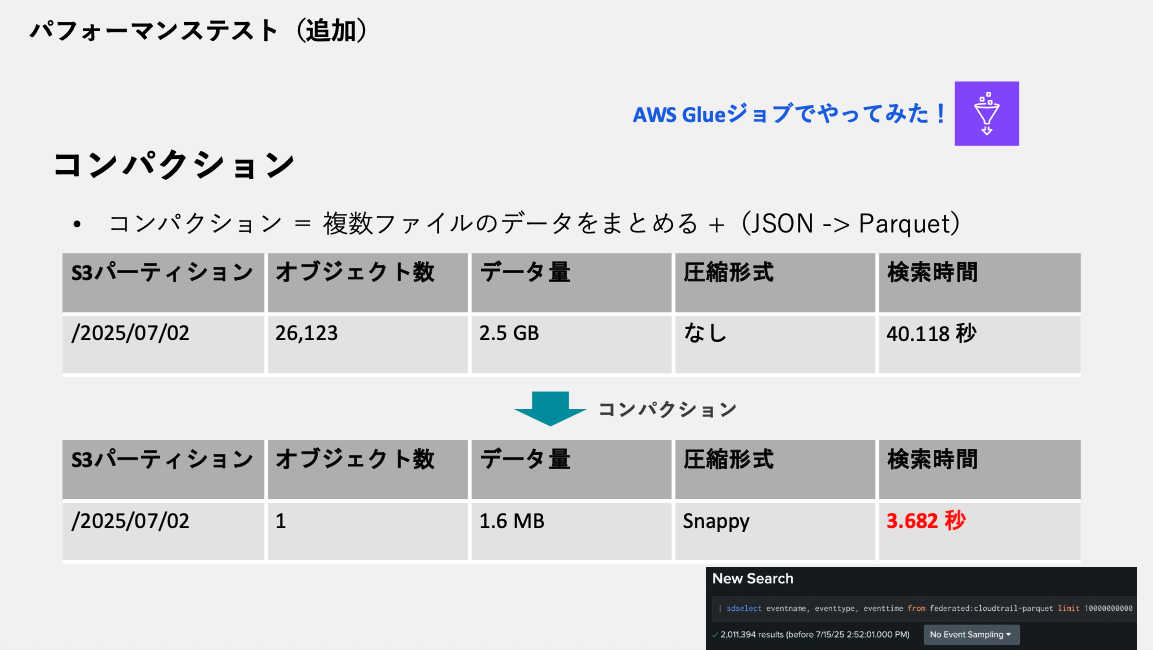
コンパクションの効果
先程のパフォーマンスでは、ファイル数の多いデータでは使いづらい結果となり、もう少し何かできないか考えてみました!
AWS Glueジョブを使用してデータのコンパクション(JSON→Parquet変換 + ファイル統合)を実施:
コンパクション前:
- オブジェクト数:26,123個
- データ量:2.5GB
- 検索時間:40.118秒
コンパクション後:
- オブジェクト数:1個
- データ量:1.6MB(Snappy圧縮)
- 検索時間:3.682秒
そうしたところ劇的な改善を確認!
検証から得られた知見
1. 構文の特徴
- SQLライクな
sdselectコマンドを使用 - 従来のSPLとは構文が異なるものの、敷居は比較的低い
2. パフォーマンスの考慮点
- 検索時間が30秒を超えると実際の調査には不向き
- ファイル数の増加に伴い検索時間も延びる傾向
- コンパクションにより大幅な性能改善が可能
3. 最適化のポイント
- 適切なパーティショニング設計
- Partition Projectionの活用
- 定期的なデータコンパクション
- Parquet形式への変換
まとめ
FSS3は、以下の利点を持つ画期的なソリューションです:
✅ コスト効率性:データを直接取り込まないダイレクトクエリ
✅ 柔軟性:S3とGlueを活用したパーティショニング
✅ 拡張性:未活用データの有効活用
ただし、検索パフォーマンスの面では使いどころの見極めが重要かと思います。










