
SQS → Lambda → DB / SNS で 「DB は exactly-once、通知は at-least-once」 を成立させる冪等パターン
1. はじめに
こんにちは、コンサルティング部のシモンです。
皆さんは SQS から Lambda でメッセージを処理するときに、「DB への書き込みは絶対に二重化させたくないが、後続の通知は必ず 1 回は届けたい (重複は許容)」という要件を綺麗に成立させたいと思ったことはありますか?私はあります。
たとえば注文取り込みパイプラインでは、注文レコードは一意でなければなりませんが、Slack への通知は欠損よりも重複のほうが許容できる、というケースがあります。
標準 SQS は at-least-once 配信です。重複配信が起きるケースは主に 2 つあります。
1 つは Lambda が正常終了しなかった場合で、可視性タイムアウトの経過後にメッセージが再配信されます(タイムアウト・メモリ不足・AWSインフラ層のエラーなどが原因になります)。
もう 1 つは SQS の分散ストレージ構造に起因するもので、Lambda が正常にメッセージを削除した後でも稀に同じメッセージが再配信されることがあります。
この重複配信を前提に処理を組まないと、業務データの二重書き込みや通知の欠損につながります。
本記事のゴールは、この要件を 1 つの冪等パターンで両立させることです。具体的には次の 3 点を扱います。
- 状態管理テーブル (
processed_events) と業務テーブルをTransactWriteItemsで 1 つのアトミック書き込みにまとめる - 書き込み成功後に SNS publish を行い、完了したら状態管理テーブルのステータスを更新する
- 再配信時にステータスを見て 3 通りに分岐し、データ層は exactly-once、通知層は at-least-once として振る舞わせる
2. 構成図と前提
本記事で扱うアーキテクチャは SQS → Lambda → DynamoDB / SNS の構成です。
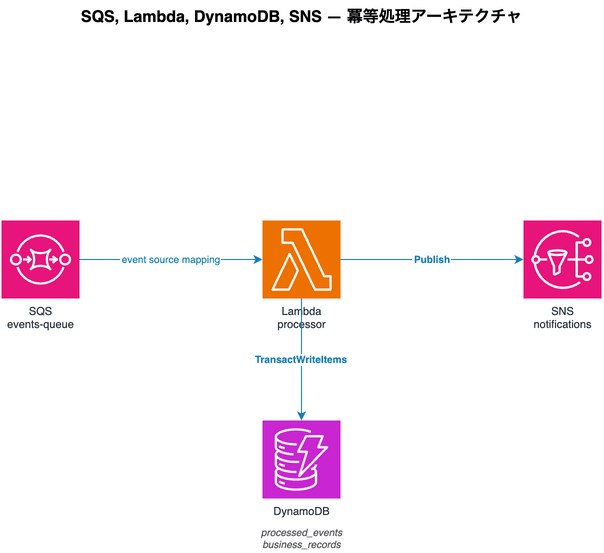
SQS へのメッセージ送信元は特定しません。S3 イベント通知、EventBridge ルール、アプリケーションからの直接 SendMessage など、任意のプロデューサーを想定しています。
実装例には DynamoDB を使いますが、パターン自体は DB 非依存です。
想定する要件は 3 つです。
- SQS に流れてきたアイテムの処理の欠損は不可
- DB への二重書き込みも不可 (同一アイテムが 2 行になってはならない)
- 通知の重複は許容 (人間が確認して読み流せる)
3. DynamoDB テーブル設計
テーブルは processed_events(状態管理)と order_records(業務データ)の 2 つに分けます。今回は状態管理と業務データの関心を分離するためにテーブルを分けることにしました。業務テーブルのスキーマが変わっても状態管理ロジックに影響が出ない構成になっています。両テーブルへの書き込みは TransactWriteItems で 1 つのアトミック操作にまとめます。
processed_events(状態管理テーブル)
パーティションキーには、プロデューサー側で採番したイベント ID (event_id) を使います。たとえば、S3 オブジェクトキー、注文 ID、リクエスト ID など、業務側で一意になる値です。SQS メッセージ ID は使いません。同一イベントがプロデューサーから再送されると SQS は新しいメッセージ ID を発番するため、メッセージ ID では同一イベントを識別できません。
status 属性は pending と sent の 2 値のみを取ります。
pending:TransactWriteItems成功済み、SNS publish 未完了sent: SNS publish 完了済み
ProcessedEventsTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: processed_events
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
- AttributeName: event_id
AttributeType: S
KeySchema:
- AttributeName: event_id
KeyType: HASH
TimeToLiveSpecification:
AttributeName: ttl
Enabled: true
order_records(業務テーブル)
業務テーブルは読者のドメインに応じて変わるため、コンセプト記事である今回は実装をスキップします。本記事では注文テーブル order_records があると仮定します。
4. 処理フロー
正常系の流れを先に確認します。
Lambda はまず TransactWriteItems で processed_events と order_records の 2 件をアトミックに書き込みます。processed_events の Put には ConditionExpression: attribute_not_exists(event_id) を付けます。このキーが既存の場合はトランザクション全体がキャンセルされるため、業務テーブルへの二重書き込みも同時に防ぎます。
try:
dynamodb.transact_write_items(
TransactItems=[
{
"Put": {
"TableName": "processed_events",
"Item": {
"event_id": {"S": event_id},
"status": {"S": "pending"},
},
"ConditionExpression": "attribute_not_exists(event_id)",
}
},
{
"Put": {
"TableName": "order_records",
"Item": {
"order_id": {"S": order_data["order_id"]},
# 業務フィールドを追加する
},
}
},
]
)
except ClientError as e:
if e.response["Error"]["Code"] != "TransactionCanceledException":
raise
# event_id が既存 → GetItem で status を確認し、pending/sent で処理を分岐する (次節で詳述)
...
TransactWriteItems が成功したら SNS に publish します。SNS は DynamoDB トランザクションに参加できないため、publish は必ずトランザクションの外で行います。
sns.publish(TopicArn=sns_topic_arn, Message=event_id)
publish が完了したら UpdateItem で status を sent に更新し、最後に SQS からメッセージを削除します。
dynamodb.update_item(
TableName="processed_events",
Key={"event_id": {"S": event_id}},
UpdateExpression="SET #s = :sent",
ExpressionAttributeNames={"#s": "status"},
ExpressionAttributeValues={":sent": {"S": "sent"}},
)
5. 再配信時の 3 分岐
TransactWriteItems が失敗した原因が TransactionCanceledException である場合、event_id が既存です。
次に GetItem で status を読み、pending か sent かで処理を分岐します。
item = dynamodb.get_item(
TableName="processed_events",
Key={"event_id": {"S": event_id}},
)["Item"]
if item["status"]["S"] == "sent":
return # パターン B へ
# status == "pending": publish へ進む
パターン A: pending — publish のみ実行
TransactWriteItems 成功後、SNS publish 前に Lambda がタイムアウト・メモリ不足・クラッシュするとこのパターンになります。業務テーブルへの書き込みは初回で完了しているためスキップし、SNS publish だけを実行します。
パターン B: sent — 全スキップ
正常終了済みのメッセージが再配信された場合です。書き込みも publish もスキップしてそのままメッセージを削除します。
6. FIFO SQS では解決しないのか
FIFO SQS には exactly-once processing という機能があり、重複排除ができると AWS ドキュメントに記載されています。「FIFO SQS を使えばいいのでは?」という疑問は自然です。
しかし、これはプロデューサー側が誤って同じメッセージを 2 回 SendMessage した場合の重複排除機能です。
コンシューマー側 (今回の Lambda) の挙動は Standard SQS と変わりません。Lambda がメッセージを処理中にタイムアウト・クラッシュすると、可視性タイムアウトの経過後にメッセージが再配信されます。FIFO でもこの再配信は発生するため、コンシューマー側 (Lambda) の冪等処理は依然として必要です。本記事のパターンは FIFO SQS にもそのまま適用できます。
FIFO 固有のトレードオフも考慮が必要です。
MessageGroupIdの設計が必要 (同一グループ内は順序保証されるが、グループをまたぐと並列処理される)- スループット上限 (高スループット FIFO モードを使っても上限あり)
- 一部のイベントソースが FIFO キューを直接送信先にできない (例: S3 イベント通知)
FIFO を選ぶべきケースは、メッセージの順序保証が必要な場合や、プロデューサー側の重複送信が頻発する場合です。「コンシューマーの冪等性さえ確保できればよい」という要件であれば、Standard SQS で十分です。
7. まとめ
本記事では SQS → Lambda → DynamoDB / SNS の構成で、データ層は exactly-once、通知層は at-least-once を同時に成立させるパターンを紹介しました。
実装の要点は 3 つです。
processed_eventsテーブルのevent_idにattribute_not_exists条件を付けたTransactWriteItemsで業務テーブルと同時に書き込み、二重書き込みをアトミックに防ぐ- SNS publish はトランザクションの外で行い、完了後に
statusをsentへ更新する - 再配信時は
statusを見て分岐し、pendingのときだけ publish をリトライする
なお、「通知の重複を許容する」という線引きはビジネス側との合意が前提です。重複通知が問題になるケースでは、SNS のサブスクライバー側でも別途重複排除の仕組みが必要になります。











