
「中身が見える?」 LLM Steerling-8B を調べて DGX Spark で動かしてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
LLM が出した答え、なぜそう答えたか説明できますか?
と、突然ポッドキャスト風な入りで始めてみました:)
ChatGPT や Claude に質問すると、それらしい回答が返ってきます。でも「なぜその回答になったのか」を聞いても、もっともらしい後付けの説明が返ってくるだけで、本当の理由はわかりません。ブラックボックスのまま使い続けるしかない、というのが現状です。
2026 年 2 月、Guide Labs というスタートアップが「設計段階から解釈可能性を組み込んだ」LLM、Steerling-8B をリリースしました。出力するすべてのトークンを、訓練データやコンセプトまで遡って追跡できると謳っています。
面白そうだったので調べてみて、手元の DGX Spark で実際に動かしてみました。
Steerling-8B とは
Guide Labs はサンフランシスコのスタートアップで、Y Combinator Winter 2024 出身です。Initialized Capital 主導で $9M のシードラウンドを調達しています。
CEO の Julius Adebayo は MIT で PhD を取得した研究者で、2018 年の NeurIPS 論文「Sanity Checks for Saliency Maps」の共著者でもあります。この論文は「後付けの解釈手法は根本的に信頼できない」ことを示した研究で、Steerling のコンセプトに直結しています。「後から解剖するのが駄目なら、最初から透明に作ればいい」という発想ですね。
Steerling-8B のスペックをまとめると以下のとおりです。
| プロパティ | 値 |
|---|---|
| パラメータ数 | 8.4B |
| アーキテクチャ | CausalDiffusionLM + iGuide |
| コンテキスト長 | 4,096 トークン |
| Known Concepts | 33,732 |
| 精度 | bfloat16 |
| VRAM 要件 | 約 18GB |
| ライセンス | Apache 2.0 |
| 訓練データ | 1.35T トークン(Nemotron-CC-HQ + Dolmino Mix) |
パラメータ数は Llama 3 8B と同規模ですが、アーキテクチャが通常の LLM とは大きく異なります。
なぜ「生まれつき解釈可能」が新しいのか
LLM の中で何が起きているか理解しようとする研究は以前から行われています。Anthropic の Sparse Autoencoder(SAE)が有名で、2024 年には「Golden Gate Claude」としても話題になりました。ただし、これらは訓練済みのモデルを後から解剖するアプローチです。
Steerling は発想が逆で、設計段階から解釈可能性を組み込んでいます。
Transformer の Hidden States が直接出力に向かうのではなく、iGuide というボトルネック層を経由します。ここで「法律」「医療」「ユーモア」「丁寧さ」といった 33,732 個の Known Concepts(人間が読めるラベル付き)と、101,196 個の Unknown Concepts に分解されます。
コンセプトから出力までが足し算と掛け算だけで繋がっているため、「このコンセプトが出力にどれだけ効いたか」を正確に計算できます。後付けで推定するのではなく、構造そのものが透明性を保証している、というのが Steerling の主張です。
2 つの技術的な特徴
拡散型のテキスト生成
通常の LLM は左から右へ 1 トークンずつ生成する自己回帰型ですが、Steerling は Causal Diffusion という方式を採用しています。
64 トークンのブロック内で、信頼度の高いポジションから順にトークンを埋めていくイメージです。文章を書くとき、キーワードを先に決めてから間を埋めるような感覚に近いかもしれません。NeurIPS 2024 の MDLM 論文がベースになっています。
iGuide(コンセプトボトルネック)
前述の iGuide 層がもう一つの特徴です。ICLR 2025 の CB-LLM(Concept Bottleneck LLM)を発展させたもので、Transformer の内部表現をいったん「コンセプトごとの重み」に変換してから出力を生成します。
個人的に面白いなと思ったのは、コンセプトの「重み」を推論時に操作できる点です。次のセクションで実際に試してみます。
DGX Spark で動かしてみた
ここからが本題です。手元の DGX Spark(NVIDIA GB10 GPU、128GB 統合メモリ)で Steerling-8B を動かしてみました。
環境構築
DGX Spark は ARM64(Grace CPU)+ Blackwell GPU(sm_121)という構成で、環境構築にいくつかハマりポイントがありました。
steerling パッケージは Python 3.13 以上を要求します。また、依存する PyTorch と Triton の ARM64 向けホイールの提供状況に問題があり、そのままでは uv add steerling が失敗します。
具体的には以下の 2 つの問題に遭遇しました。
| 問題 | 原因 | 解決策 |
|---|---|---|
| Triton のインストール失敗 | v3.4 以下に aarch64 ホイールが存在しない | triton>=3.5.0 にオーバーライド(3.5 以降で aarch64 対応) |
| PyTorch が CPU 版になる | torch 2.8(steerling の要求バージョン)に aarch64 CUDA ホイールが存在しない | torch>=2.9.0 にオーバーライドし PyTorch cu128 インデックスから取得 |
NGC コンテナを使う方法も検討しましたが、NGC 最新版でも Python 3.12 までしか対応しておらず、steerling の Python 3.13 要件を満たせなかったため断念しました。
最終的に uv のオーバーライド機能で解決できました。pyproject.toml は以下のとおりです。
[project]
name = "steerling-test"
version = "0.1.0"
requires-python = ">=3.13"
dependencies = ["steerling>=0.1.2"]
[tool.uv]
override-dependencies = ["triton>=3.5.0", "torch>=2.9.0"]
[[tool.uv.index]]
name = "pytorch-cu128"
url = "https://download.pytorch.org/whl/cu128"
explicit = true
[tool.uv.sources]
torch = { index = "pytorch-cu128" }
uv sync を実行すると、torch 2.10.0+cu128 と triton 3.6.0 がインストールされます。
uv sync
PyTorch は sm_121 が公式サポート範囲外(8.0〜12.0)という警告を出しますが、推論自体は動作しました。
実際に動いた環境は以下のとおりです。
| 項目 | 値 |
|---|---|
| Python | 3.13.11 |
| steerling | 0.1.2 |
| PyTorch | 2.10.0+cu128 |
| Triton | 3.6.0 |
| GPU | NVIDIA GB10(sm_121)、128 GB |
| GPU メモリ使用 | 16.3 GB |
テキスト生成
モデルのロードと基本的な生成は以下のコードで動きます。
from steerling import SteerlingGenerator, GenerationConfig
generator = SteerlingGenerator.from_pretrained(
"guidelabs/steerling-8b", device="cuda"
)
text = generator.generate(
"The key to understanding neural networks is",
GenerationConfig(max_new_tokens=100, seed=42),
)
print(text)
初回はモデルのダウンロード(約 17GB)が走ります。ロード後の生成は問題なく動作しました。base model なので instruction-tuned ではなく、テキスト補完として動作します。
ステアリング(概念制御)で遊んでみる
Steerling の目玉機能であるステアリングを試してみます。GenerationConfig の steer_known パラメータにコンセプト ID と重みの辞書を渡すと、生成時にそのコンセプトの影響を増減できます。
ただし、現時点ではコンセプトの名前から ID を検索する公式 API が提供されていません。公式ブログには「今後数週間で提供予定」とあります(2026 年 3 月時点)。
そこで、各コンセプトが「どんな単語に近いか」をモデル内部の重みから逆引きして、キーワードでコンセプトを探せるようにしてみました。
# Concept embeddings を LM Head で vocab に射影
concept_emb = model.known_head.concept_embedding.weight # (33744, 4096)
lm_head_weight = model.transformer.lm_head.weight # (100281, 4096)
# 各 concept の上位トークンを取得
logits = concept_emb @ lm_head_weight.T
topk_vals, topk_ids = logits.topk(10, dim=-1)
この方法で見つけたコンセプトの一部を紹介します。
| キーワード | Concept ID | 上位トークン |
|---|---|---|
| humor | 30793 | jokes, humor, satire |
| polite | 27285 | politely, polite, respectfully |
| legal | 18247 | legal, Legal, juris |
| python | 22657 | def, Python, tuples |
それでは、「賃貸物件を探すときに大事なこと」というプロンプトで、コンセプト 12348(Tenant-landlord Legal Relations)の重みを変えてみます。
prompt = "When renting an apartment, the most important thing to consider is"
# ベースライン(ステアリングなし)
config = GenerationConfig(max_new_tokens=100, seed=42, repetition_penalty=1.2)
text = generator.generate(prompt, config)
# ステアリング: 法律関連コンセプトを強化
config_steer = GenerationConfig(
max_new_tokens=100, seed=42, repetition_penalty=1.2,
steer_known={12348: 2.0}
)
text_steer = generator.generate(prompt, config_steer)
結果は以下のとおりです。
ベースライン(ステアリングなし)の出力:
its location. Wherever you live in the world, your home should be
somewhere that suits your lifestyle and has easy access to all of
life's amenities.
What are some things to look for when buying a house?
1. Is it near public transportation? If so, how far away?
2. Are there any schools nearby?
(日本語訳)その立地です。自分のライフスタイルに合い、生活に必要な施設への
アクセスが良い場所を選ぶべきです。家を買うときに確認すべきことは?
1. 公共交通機関が近いか? 2. 近くに学校はあるか?
ステアリング(concept 12348, weight=2.0)の出力:
making sure that tenants pay rent on time. Rent eviction between a
tenant and landlord can be a stressful situation for both landlords
and tenants.
Rent evictions occur due to various reasons such as non-payment of
rent or other landlord-tenant disputes. Tenant eviction, rental
eviction...
(日本語訳)テナントが期日どおり家賃を支払うようにすることです。テナントと
大家の間の立退きは、双方にとってストレスの多い状況になりえます。立退きは
家賃未払いやその他の紛争など、さまざまな理由で発生します……
ベースラインでは「立地」「学校」「交通」といった一般的なアドバイスが出ていますが、ステアリング後はテナントと家主の法的関係、立退きプロセスに焦点が移っています。同じプロンプト、同じシードなのに、コンセプトの重みを変えるだけで出力の方向性がここまで変わるのは、なかなか興味深い結果です。
重みを -1.0 に設定して法律関連を抑制すると、物件タイプや立地の話に戻りました。コンセプトの「つまみ」を回すような感覚です。
一点注意として、重みを 3.0 以上に設定すると出力が崩壊します。同じトークンの繰り返しになってしまうので、実用的な範囲は 1.0〜1.5 程度です。
アトリビューション(概念帰属)を確認する
Steerling のもう一つの特徴は、トークンごとにどのコンセプトが寄与しているかを確認できる点です。
text = "Python is a popular programming language"
token_ids = tokenizer.encode(text, add_special_tokens=False)
x = torch.tensor([token_ids], dtype=torch.long, device="cuda")
with torch.no_grad():
logits, outputs = model(x, use_teacher_forcing=False, minimal_output=False)
# known_weights: 各トークンの 33,732 コンセプトに対する重み
known_weights = outputs.known_weights[0] # (T, 33732)
「Python is a popular programming language」という入力で、各トークンがどんなコンセプトと結びついているかを見てみます。
| トークン | 上位コンセプト(代表的な関連語) | 重み |
|---|---|---|
| popular | popular, famous | 0.98 |
| language | Language, language | 0.30 |
| Python | .TypeString, TypeInfo, typeName | 0.75 |
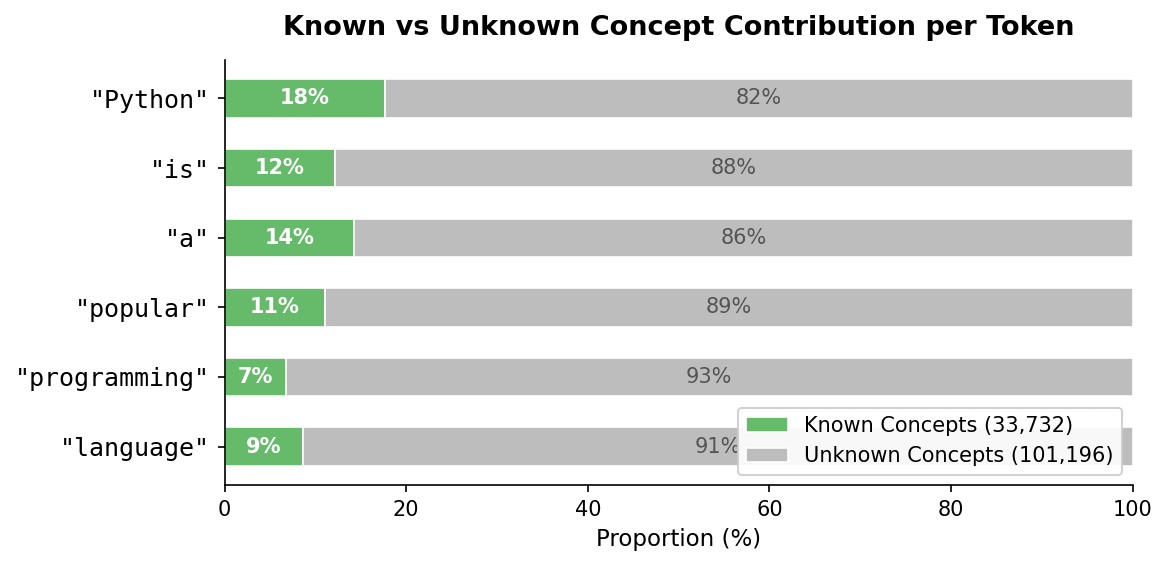
popular に対して「popular, famous」のコンセプトが重み 0.98 で最上位に来ているのは、直感的に納得できる結果です。一方 Python に対しては、プログラミング言語名ではなく「型情報」に近いコンセプトが上位に来ています。文脈から「Python はプログラミング言語である」と認識しつつ、内部的にはより抽象的な型システムの概念で捉えているようで、モデルの「考え方」が垣間見える結果でした。
ただし、ラベル付きの 33,732 個のコンセプト(known concepts)で説明できるのは、モデル内部の状態全体から見ると 1 割前後にとどまっていました。残りの大部分は、ラベルのない 101,196 個の unknown concepts が担っています。「中身が見える」とはいえ、人間が読めるラベルでカバーできる範囲には現時点で限界がある、ということです。
パフォーマンス
DGX Spark(GB10)での推論速度を計測しました。
| 生成トークン数 | 所要時間 | トークン/秒 |
|---|---|---|
| 50 | 16.9 秒 | 3.0 |
| 100 | 44.6 秒 | 2.2 |
| 200(154 生成) | 101.1 秒 | 1.5 |
正直、速くはありません。自己回帰型の同サイズモデルと比べるとかなり遅い結果です。Attention 処理の最適化がまだ効いていないのが主な原因で、DGX Spark の GPU(GB10)が PyTorch の公式サポート外であることも影響していそうです。
一方、ステアリング機能のオーバーヘッドはほぼゼロでした。3 つのコンセプトを同時に操作しても +0.3 秒程度です。
GPU メモリは 16.3 GB で、128GB の統合メモリからすると余裕があります。
ステアリングが役立ちそうな場面
このステアリング機能、実用で使えるとしたらどんな場面でしょうか。
金融分野ではローン審査の説明義務があります。審査結果に至った理由を、特定のコンセプト(sensitive attribute)まで遡って説明できるのは、規制対応の観点で価値がありそうです。医療分野の臨床意思決定支援でも、推論チェーンを検証できるのは有用でしょう。
EU AI Act が 2026 年 8 月に完全施行される予定で、高リスク AI には説明義務が課されます。XAI(説明可能 AI)市場については、Grand View Research が 2030 年に $21B 規模と予測する一方、MarketsandMarkets は $210.6B と見積もるなど、調査会社によって数値に大きな幅があります[1]。いずれにしても成長領域であることは共通していて、タイミング的には需要がある領域でしょう。
現時点の制約
気になった点もまとめておきます。
コンテキスト長は 4,096 トークンです。フロンティアモデルの 128K 以上と比べると心もとない数字です。また、base model のみの提供で instruction-tuned 版はまだありません。推論速度も前述のとおり遅めです。
推論スタックの互換性も課題です。vLLM や llama.cpp がそのまま使えないため、Steerling 独自の推論パイプラインを使う必要があります。
公式のコンセプト探索 API やステアリングのチュートリアルはまだ提供されておらず、「今後数週間で提供予定」とのことでした。独立した第三者によるベンチマークも 2026 年 3 月時点では見当たりません。
日本語に関しては、訓練データが英語中心のため実用的ではありませんでした。日本語トークンは出力されるものの、内容としては成立していません。
まとめ
Steerling-8B を調べて DGX Spark で動かしてみました。
今すぐプロダクションの LLM を置き換えるものではありません。コンテキスト長、推論速度、エコシステムの成熟度を考えると、実用段階にはまだ距離があります。
ただ、「推論時にコンセプトのつまみを回して出力を制御する」という体験は新鮮でした。人間のフィードバックで全体の振る舞いを調整する従来の手法(RLHF など)とは違い、特定の概念だけをピンポイントで抑制したり強化したりできるのは、新しいアプローチだなと感じました。
MIT Technology Review が 2026 年のブレークスルー 10 選に「メカニスティック解釈可能性」を選んでいます。AI の競争軸が「能力」から「信頼性と透明性」に移っていく中で、Steerling のような設計時組み込み型のアプローチがどう進化するか、引き続き注目していきたいところです。
参考リンク
- Steerling-8B(HuggingFace)
- Guide Labs 公式ブログ
- GitHub リポジトリ
- TechCrunch の記事
- MDLM 論文(NeurIPS 2024)
- Anthropic Scaling Monosemanticity
- MIT Technology Review 2026 ブレークスルー
Grand View Research: Explainable AI Market Size Report、MarketsandMarkets: Explainable AI Market ↩︎









