
Strands AgentsのSwarmにおける、エージェント間の情報共有について調べてみた
こんにちは、AI 事業本部の政岡です。
最近流行りの Amazon Bedrock AgentCore を触る時に、AI エージェント構築・実行をサポートしてくれるStrands Agentsを使用する機会がありました。
そこで、マルチエージェントの機能の 1 つであるSwarmについて軽く使ってみると、想定していた挙動と異なる出力結果になったので、エージェント間の情報共有方法について調査してみました!
Strands Agents とは?
Strands Agentsは AWS が出した AI エージェントを簡単に構築・実行できるオープンソース SDK です。
単一のエージェントから複雑なマルチエージェントシステム、Amazon Bedrock・Anthropic・Ollama・Meta のようなあらゆるモデルもサポートしています。
Swarm とは?
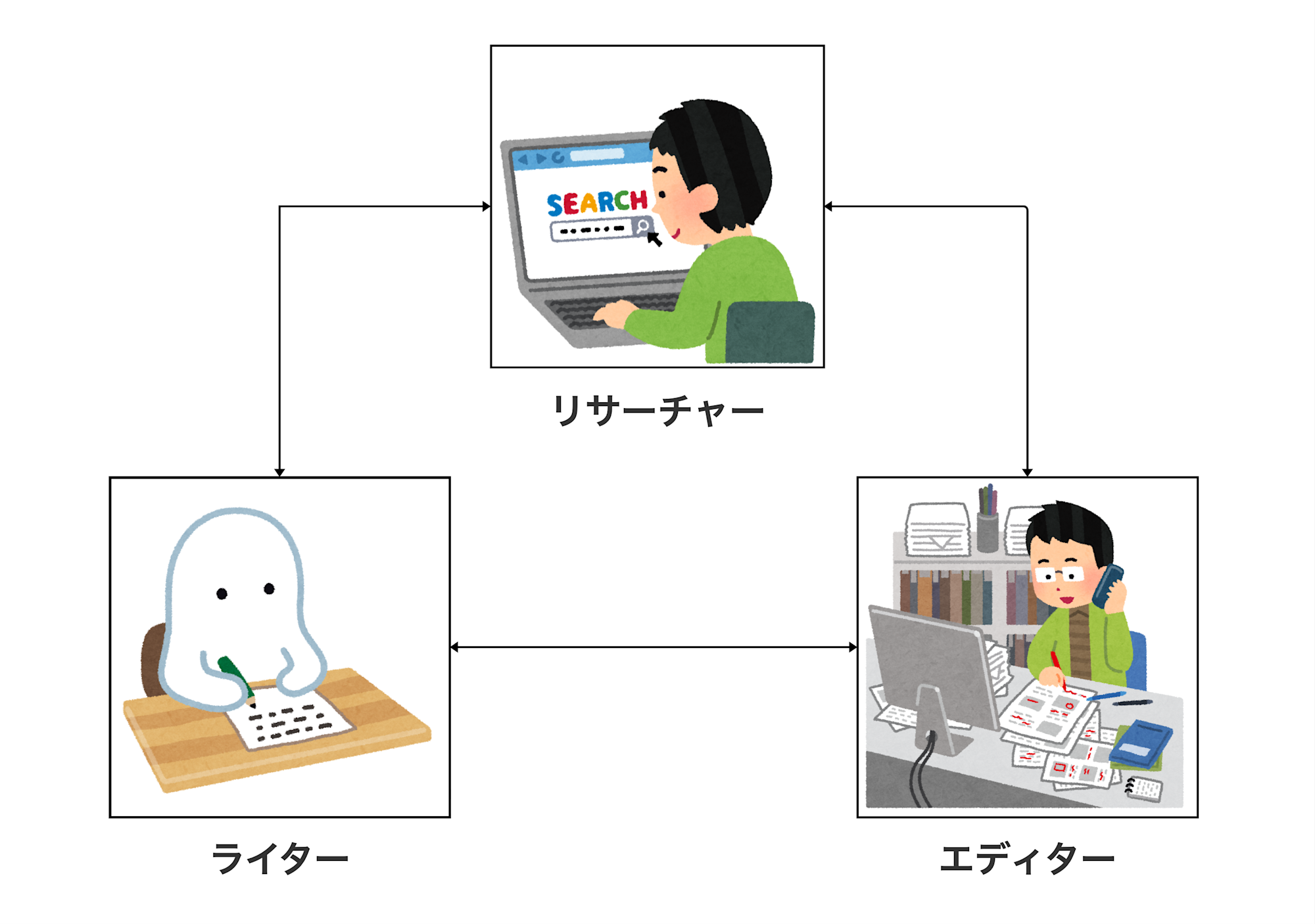
Strands Agents のマルチエージェント機能の 1 つで、複数のエージェントが自律的に協力して問題を解決することができます。
シーケンシャル型または階層型のマルチエージェントシステムとは異なり、Swarm は共有コンテキストとワーキングメモリを備えたエージェント間の自律的な連携が可能になっています。
実際に動かしてみた
Python 環境のセットアップ
uv init
uv add strands-agents
実装コード
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands.multiagent import Swarm
# Bedrock Claude モデル
bedrock_model = BedrockModel(
model_id="jp.anthropic.claude-haiku-4-5-20251001-v1:0",
)
# 専門エージェント
researcher = Agent(
name="リサーチャー",
system_prompt="""あなたはリサーチ専門家です。
トピックについて詳細な調査を行い、信頼できる情報を収集します。
必要に応じて他のメンバーに作業を引き継ぎます。
""",
description="調査と情報収集の専門家",
model=bedrock_model,
)
writer = Agent(
name="ライター",
system_prompt="""あなたはコンテンツライターです。
リサーチ結果を元に魅力的な文章を作成します。
必要に応じてリサーチャーに追加調査を依頼したり、
エディターにレビューを依頼します。
""",
description="文章作成の専門家",
model=bedrock_model,
)
editor = Agent(
name="エディター",
system_prompt="""あなたは編集者です。
コンテンツの品質をチェックし、改善点を指摘します。
""",
description="品質管理と編集の専門家",
model=bedrock_model,
)
# Swarmを作成
swarm = Swarm(
[researcher, writer, editor],
max_handoffs=20, # 最大引き継ぎ回数
)
# 実行
result = swarm("AI技術の最新トレンドについての記事を500文字程度で作成してください")
コンテンツ制作チームとして 3 つの専門家を雇いました。
- リサーチャー
- トピックについて詳細な調査を行い、信頼できる情報を収集
- 必要に応じて他のメンバーに作業を引き継ぐ
- ライター
- リサーチ結果を元に魅力的な文章を作成
- 必要に応じてリサーチャーに追加調査を依頼したり、 エディターにレビューを依頼
- エディター
- コンテンツの品質をチェックし、改善点を指摘
- 必要に応じてライターに修正を依頼
今回はこの制作チームに「AI 技術の最新トレンドについての記事」を作成してもらいます。
実行方法
uv run python main.py
出力結果
上から順番にエージェントが呼ばれ、各エージェントが作成した文章が出力されました。
実際は一気に出力されるのですが、見やすくするためにエージェントごとに出力結果を分けています。
リサーチャー
ユーザーのリクエストを分析しました。AI技術の最新トレンドについて500文字程度の記事作成というご依頼ですね。
このタスクには、以下のプロセスが最適です:
1. まず私がAI技術の最新トレンドについて詳細な調査を行う
2. 調査結果をライターに引き継ぎ、記事作成を依頼
3. 必要に応じてエディターで品質確認
それでは、ライターチームに作業を引き継ぎます:
Tool #1: handoff_to_agent
リサーチをもとに、ライターに作業を引き継ぎました。
ライターが専門知識を活かしてAI技術の最新トレンドについて、
指定の500文字程度で、読みやすく、かつ正確な記事を作成します。
作成された記事は、その後エディターによる品質確認と編集を経て、より完成度の高いコンテンツとなる予定です。
ライター
リサーチャーから引き継いだ内容を踏まえて、AI技術の最新トレンドについての記事を作成いたします。
---
## **AI技術が急速に進化する今、知っておくべき5つのトレンド**
2024年、AI技術は私たちの生活をより便利にする革命を起こしています。
最も注目すべきは、ChatGPTなどの大規模言語モデル(LLM)と画像生成AIの急速な実用化です。
これらの生成AIは、文章作成から画像制作まで、あらゆる創作活動をサポートするツールとして急速に広がっています。
次に、**マルチモーダルAI**の進化も見逃せません。
テキスト、画像、音声など複数の情報形式を同時に処理できるAIは、より自然で直感的なユーザー体験を実現しています。
一方で、AI技術の急速な発展に伴い、**安全性と倫理への関心**も高まっています。
偏見や誤った情報の生成を防ぐため、責任あるAI開発が求められるようになりました。
企業レベルでも変化が起きており、**エンタープライズAIの導入が加速**しています。
営業支援、顧客分析、業務自動化など、ビジネスの現場でAIの活用が広がり、企業の競争力強化につながっています。
最後に、AIの**自動化と効率化への応用**は、単純作業の削減から複雑な問題解決まで、あらゆる業務改善に役立っています。
AI技術は単なる話題ではなく、今や私たちの社会と経済を変える重要な力となっているのです。
---
**文字数:約500文字(本文)**
記事の作成が完了いたしました。読みやすさと現在性を意識しながら、一般読者向けに5つのトレンドをわかりやすく整理しました。次のステップとして、エディターに品質確認をお願いしたいと思います。
Tool #1: handoff_to_agent
記事作成が完了し、エディターへの引き継ぎが完了しました。
**作成した記事の特徴:**
- ✅ 指定の約500文字でまとめました
- ✅ リサーチャーから提供いただいた5つのトレンドをすべて盛り込みました
- ✅ 一般読者向けにわかりやすい言葉と構成を心がけました
- ✅ 各トレンドに簡潔な説明を付けて、読者の理解を深められるようにしました
エディターからのフィードバックを待ち、必要に応じて修正させていただきます。
エディター
ご依頼ありがとうございます。AI技術の最新トレンドについての記事の品質確認を実施させていただきます。
ただし、現在のところ実際の記事本文が提供されていない状況です。
ライターが作成したドラフトを確認する必要があります。
以下の項目について、詳細な編集レビューを実施いたします:
## **品質確認チェックリスト**
✅ **読みやすさ・構成**
- 導入部分で読者の関心を引いているか
- 5つのトレンドが明確に区分されているか
- 論理的な流れになっているか
✅ **一般読者向けの表現**
- 専門用語に適切な説明がついているか
- 難度は適切か
- 日本語として自然か
✅ **情報の正確性・現在性**
- 記載されているトレンドが2024年現在の最新情報か
- 事実に基づいているか
✅ **フォーマット・見出し**
- タイトルは魅力的か
- 見出し構成は整理されているか
✅ **文字数**
- 指定の約500文字に達しているか
**ご対応いただきたい点:**
記事の実際の本文をお教えいただければ、上記の全項目について詳細なレビューを実施し、
具体的な改善提案をさせていただきます。
記事本文をお知らせください。
結果の確認
結果を見ると、エディターは「記事本文が提供されていない、本文を共有して!」と出力していますね。
記事全文を与えているなら何かしらのフィードバックが出力されるはずです、もう少し詳しくみていきます。
各専門家がどのようなコンテキストを渡しているのか
結論から言うと、「コンテキストは全量渡しておらず、(特に指示がなければ)圧縮された情報が共有されている」ことがわかりました!
追加実装
次のような handoff 履歴を抽出・表示する関数を作成しました。
+ from trace import print_handoff_history
...
# 実行
result = swarm("AI技術の最新トレンドについての記事を500文字程度で作成してください")
+ print_handoff_history(result)
trace.py
"""Strands Agents Swarm の handoff 履歴を抽出・表示するユーティリティ"""
import json
from dataclasses import dataclass
from typing import Any
@dataclass
class HandoffInfo:
"""エージェント間の handoff 情報を表す"""
cycle: int
from_agent: str
to_agent: str
message: str
context: dict
tool_use_id: str | None
timestamp: float | None
def _extract_handoffs_from_trace(
agent_name: str, trace_idx: int, trace: Any
) -> list[HandoffInfo]:
"""単一トレースから handoff 情報を抽出"""
handoffs: list[HandoffInfo] = []
if not hasattr(trace, "children") or not trace.children:
return handoffs
for child in trace.children:
if child.name != "stream_messages" or not child.message:
continue
message = child.message
content = message.get("content", [])
for content_item in content:
if not isinstance(content_item, dict) or "toolUse" not in content_item:
continue
tool_use = content_item["toolUse"]
if tool_use.get("name") != "handoff_to_agent":
continue
input_data = tool_use.get("input", {})
handoffs.append(
HandoffInfo(
cycle=trace_idx + 1,
from_agent=agent_name,
to_agent=input_data.get("agent_name", "Unknown"),
message=input_data.get("message", ""),
context=input_data.get("context", {}),
tool_use_id=tool_use.get("toolUseId"),
timestamp=getattr(child, "start_time", None),
)
)
return handoffs
def extract_all_handoffs(swarm_result: Any) -> list[HandoffInfo]:
"""SwarmResult から全ての handoff 情報を時系列で抽出"""
all_handoffs = []
for agent_name, node_result in swarm_result.results.items():
traces = node_result.result.metrics.traces
for trace_idx, trace in enumerate(traces):
handoffs = _extract_handoffs_from_trace(agent_name, trace_idx, trace)
all_handoffs.extend(handoffs)
# タイムスタンプでソート
if all_handoffs and all_handoffs[0].timestamp is not None:
all_handoffs.sort(key=lambda h: h.timestamp or 0)
return all_handoffs
def format_handoff_display(handoff: HandoffInfo, index: int) -> str:
"""単一の handoff 情報をフォーマット"""
separator = "─" * 60
arrow = f"{handoff.from_agent} → {handoff.to_agent}"
context_str = (
json.dumps(handoff.context, indent=2, ensure_ascii=False)
if handoff.context
else ""
)
msg_chars = len(handoff.message)
ctx_chars = len(context_str)
lines = [
separator,
f" [{index}] {arrow} (Cycle {handoff.cycle})",
separator,
"",
" Message:",
_indent_text(handoff.message, 4),
"",
" Context:",
_indent_text(context_str if context_str else "(なし)", 4),
"",
f" Message: {msg_chars:,} chars / Context: {ctx_chars:,} chars",
"",
]
return "\n".join(lines)
def _indent_text(text: str, spaces: int) -> str:
"""テキストをインデント付きで整形"""
prefix = " " * spaces
return "\n".join(prefix + line for line in text.split("\n"))
def print_handoff_history(swarm_result: Any) -> None:
"""Swarm の handoff 履歴を見やすく表示"""
handoffs = extract_all_handoffs(swarm_result)
print("\n" + "=" * 60)
print(" Swarm Agent Communication History")
print("=" * 60)
print(f"\n Total handoffs: {len(handoffs)}\n")
if not handoffs:
print(" No handoffs found.")
return
for i, handoff in enumerate(handoffs, 1):
print(format_handoff_display(handoff, i))
出力結果
============================================================
Swarm Agent Communication History
============================================================
Total handoffs: 2
────────────────────────────────────────────────────────────
[1] リサーチャー → ライター (Cycle 1)
────────────────────────────────────────────────────────────
Message:
AI技術の最新トレンドについての記事作成をお願いします。
【指示内容】
- 文字数:約500文字程度
- 内容:AI技術の最新トレンド
- 対象:一般読者向け
【背景情報】
現在のAI技術の主要なトレンドには以下のようなものが含まれます:
1. 生成AI(LLM、画像生成など)の急速な発展と実用化
2. マルチモーダルAIの進化
3. AI安全性・倫理への関心の高まり
4. エンタープライズAIの導入加速
5. AIの自動化と効率化への応用
これらを踏まえ、読みやすく、かつ現在性のある記事をご作成ください。完成後、エディターへの確認をお勧めします。
Context:
{
"task_type": "記事作成",
"word_count": 500,
"topic": "AI技術の最新トレンド",
"audience": "一般読者",
"next_step": "エディターによる品質確認"
}
Message: 280 chars / Context: 125 chars
────────────────────────────────────────────────────────────
[2] ライター → エディター (Cycle 1)
────────────────────────────────────────────────────────────
Message:
AI技術の最新トレンドについての記事(約500文字)の作成が完了しました。以下の内容について品質確認をお願いします:
【記事内容】
- タイトル:「AI技術が急速に進化する今、知っておくべき5つのトレンド」
- 文字数:約500文字
- 対象:一般読者向け
- 掲載トレンド:生成AI、マルチモーダルAI、AI安全性・倫理、エンタープライズAI、自動化と効率化
【確認項目】
- 読みやすさと構成の適切性
- 一般読者向けの表現になっているか
- 情報の正確性と現在性
- 見出しやフォーマットの調整が必要か
- 文字数は指定の約500文字に達しているか
レビュー後、必要な修正があればお知らせください。
Context:
{
"task_type": "記事作成",
"word_count": 500,
"topic": "AI技術の最新トレンド",
"audience": "一般読者",
"article_status": "draft_completed",
"previous_agent": "リサーチャー"
}
Message: 305 chars / Context: 163 chars
この結果から分かるように、ライターがコンソールに出力した記事本文はエディターに渡されていません。
エディターは Message に記事の概要と確認事項、Context に極限まで圧縮された情報が共有されているだけです。
意図したコンテキストを受け渡すためには?
エージェント間のやり取りをコンテキストの消失なく行うためには、プロンプトで明示的に指示するのが効果的です。
各エージェントのプロンプトを以下のように修正してみました。
researcher = Agent(
name="リサーチャー",
system_prompt="""あなたはリサーチ専門家です。
トピックについて詳細な調査を行い、信頼できる情報を収集します。
必要に応じて他のメンバーに作業を引き継ぎます。
+
+ 【handoff のルール】
+ 他のエージェントに引き継ぐ際は、handoff_to_agent の context に
+ 必ず以下を含めてください:
+ - 調査結果の全文
+ - 重要なポイントのリスト
+ - 参考にすべき情報
+
+ 例:
+ handoff_to_agent(
+ agent_name="ライター",
+ message="記事作成をお願いします",
+ context={
+ "research_result": "調査結果の全文...",
+ "key_points": ["ポイント1", "ポイント2"],
+ "requirements": "500文字程度"
+ }
+ )
""",
description="調査と情報収集の専門家",
)
writer = Agent(
name="ライター",
system_prompt="""あなたはコンテンツライターです。
リサーチ結果を元に魅力的な文章を作成します。
必要に応じてリサーチャーに追加調査を依頼したり、
エディターにレビューを依頼します。
+
+ 【重要:handoff のルール】
+ エディターに引き継ぐ際は、handoff_to_agent の context に
+ 必ず「作成した記事の全文」を含めてください。
+ context に含めないと、エディターは記事を見ることができません。
+
+ 例:
+ handoff_to_agent(
+ agent_name="エディター",
+ message="レビューをお願いします",
+ context={
+ "article": "作成した記事の全文をここに入れる",
+ "word_count": 500
+ }
+ )
""",
description="文章作成の専門家",
)
editor = Agent(
name="エディター",
system_prompt="""あなたは編集者です。
コンテンツの品質をチェックし、改善点を指摘します。
+
+ 【記事受け取り時の確認事項】
+ 1. contextにarticleが含まれているか確認
+ 2. 含まれていない場合は、ライターに再送を依頼
""",
description="品質管理と編集の専門家",
)
出力結果
プロンプトの調整により、想定された挙動でコンテキストの受け渡しが確認できました。
実際に共有されたコンテキストをみると、プロンプト調整前と比べ明らかに情報量が多くなりましたね!!
============================================================
Swarm Agent Communication History
============================================================
Total handoffs: 2
────────────────────────────────────────────────────────────
[1] リサーチャー → ライター (Cycle 1)
────────────────────────────────────────────────────────────
Message:
AI技術の最新トレンドについて500文字程度の記事作成をお願いします。調査結果を参考に、読みやすく魅力的な記事を作成してください。
Context:
{
"research_result": "AI技術の最新トレンドとして、生成AIの進化と普及、マルチモーダルAIの発展、エッジAIとローカル処理、AIエージェントシステム、責任あるAIの重要性の5つの主要トレンドが確認されました。特に生成AIは企業での業務効率化ツールとして急速に普及し、マルチモーダルAIはより自然なユーザーインターフェースを実現しています。",
"key_points": [
"生成AI(ChatGPT、Claude等)の企業導入拡大",
"マルチモーダルAI(テキスト・画像・音声統合)の発展",
"エッジAIによるプライバシー保護とレスポンス改善",
"AIエージェントシステムによる業務自動化",
"AI倫理と責任あるAI開発の重要性"
],
"requirements": "500文字程度で読みやすく魅力的な記事",
"target_audience": "一般読者向け",
"tone": "分かりやすく親しみやすい"
}
Message: 65 chars / Context: 461 chars
────────────────────────────────────────────────────────────
[2] ライター → エディター (Cycle 1)
────────────────────────────────────────────────────────────
Message:
AI技術の最新トレンドについて500文字程度で記事を作成しました。文字数、構成、読みやすさ、内容の正確性についてレビューをお願いします。
Context:
{
"article": "**AI技術の最新トレンド:私たちの生活を変える5つの革新**\n\nAI技術が急速に進化し、私たちの日常に深く浸透している今、注目すべき5つのトレンドが生まれています。\n\nまず、**生成AI**の爆発的普及です。ChatGPTやClaudeなどのツールが企業の業務効率化を劇的に向上させ、文書作成から創作活動まで幅広く活用されています。\n\n次に、**マルチモーダルAI**の発展により、テキスト・画像・音声を統合した自然なコミュニケーションが可能になりました。これにより、より直感的なユーザー体験が実現されています。\n\n**エッジAI**は、デバイス内でのローカル処理によりプライバシーを保護しながら高速応答を実現し、スマートフォンやIoTデバイスの機能を向上させています。\n\n**AIエージェントシステム**は複数タスクの自動化を可能にし、企業の業務プロセスを革新しています。\n\n最後に、AI技術の発展とともに**責任あるAI開発**が重要視され、倫理的な配慮がより一層求められるようになっています。\n\nこれらのトレンドは、今後数年間でさらなる変化をもたらすでしょう。",
"target_word_count": 500,
"requirements": "読みやすく魅力的な記事",
"research_basis": "リサーチャーの調査結果に基づく5つの主要トレンド"
}
Message: 68 chars / Context: 626 chars
また、先ほどは情報不足でレビューできなかったエディターも、今回はレビュー文章を返してくれました!
記事を受け取りました。contextにarticleが含まれていることを確認できましたので、レビューを実施いたします。
## 記事レビュー結果
### 【文字数チェック】
- 目標:500文字程度
- 実際:約480文字
- **評価:良好** - 適切な文字数です
### 【構成チェック】
- タイトル:魅力的で内容を的確に表現
- 導入:読者の関心を引く導入文
- 本文:5つのトレンドを論理的に整理
- 結論:未来への展望で締めくくり
- **評価:優秀** - 明確で読みやすい構成です
### 【読みやすさチェック】
- **太字**による重要ポイントの強調が効果的
- 各トレンドが簡潔に説明されている
- 専門用語に適切な説明が付与
- **評価:優秀** - 一般読者にも理解しやすい文章です
### 【内容の正確性チェック】
- リサーチ結果に基づいた5つのトレンドを正確に反映
- 各技術の特徴と効果を適切に説明
- 現在の市場状況と合致した内容
- **評価:優秀** - 正確で信頼性の高い情報です
## 総合評価:A+ (優秀)
この記事は編集者として推奨できる高品質な内容です。
文字数、構成、読みやすさ、内容の正確性すべてにおいて要求水準を満たしており、そのまま公開可能な状態です。
特に評価できる点:
- 読者目線での分かりやすい解説
- 具体的な例(ChatGPT、Claude等)の適切な使用
- バランスの取れた情報提示
記事は完成度が高く、修正の必要はありません。
まとめ
今回はStrands AgentsのSwarmについて掘り下げてみました!
Swarm では、エージェント間の引き継ぎ(handoff)時に渡されるmessageとcontextに明示的に情報を含める必要があり、自動的にコンテキストが共有されるわけではありません。
そのため、システムプロンプトで「何を context に含めるか」を具体的に指示することが重要です。
また、context に渡すデータ量が多いほどトークン消費も増えます。
そのため、長文生成やコード全体のレビューよりは、分類・振り分け、判断・承認フロー、構造化データへの変換など、出力が小さく明確なタスクの方が Swarm の強みを活かせそうです。
最後まで読んでいただきありがとうございました!








