
Streamlitの主要機能を使ってデータ可視化ダッシュボードを作成してみる
はじめに
データ事業本部のkobayashiです。
Pythonでデータの可視化や分析結果の共有を行う際に、フロントエンドの知識なしにインタラクティブなWebアプリケーションを作成できるStreamlitが便利です。今回はStreamlitの主要な機能を一通り試すために、日本銀行が公開している時系列統計データAPIから政府債務データを取得してダッシュボードを作成してみます。
Streamlitとは
Streamlitは、PythonスクリプトをインタラクティブなWebアプリケーションに変換するオープンソースフレームワークです。
主な特徴としては以下になります。
- Pythonだけでフロントエンドのコードを書くことなくWebアプリケーションを作成できる
- DataFrameやPlotlyなどのグラフライブラリとシームレスに統合
- スクリプトを編集するとアプリが即座に更新されるライブ編集機能
st.cache_dataによるデータキャッシュで外部APIリクエストなどの結果を効率的に再利用- Apache 2.0ライセンスで完全無料・オープンソース
サンプルデータ: 日本銀行 時系列統計データAPI
今回のサンプルデータとして、2026年2月に提供が開始された日本銀行の時系列統計データAPIを使用します。認証不要でJSON形式のデータを取得できるため、Streamlitの動作確認用データとして手軽に使えます。
コードAPIのエンドポイントは以下です。
https://www.stat-search.boj.or.jp/api/v1/getDataCode?<パラメータ>
今回使用するデータ(DB名: PF02 / 政府債務)の系列コードは以下の通りです。
| 系列コード | 名称 | 用途 |
|---|---|---|
| PFGD1 | 政府債務合計 | 時系列推移 |
| PFGD11 | 内国債 | 種類別内訳 |
| PFGD@01 | 国庫短期証券 | 種類別内訳 |
| PFGD18 | 借入金 | 種類別内訳 |
| PFGD210 | 所有者内訳/政府 | 保有者別 |
| PFGD220 | 所有者内訳/日本銀行 | 保有者別 |
| PFGD230 | 所有者内訳/その他 | 保有者別 |
例えば政府債務合計(PFGD1)の2025年1月〜2026年1月のデータを取得する場合、以下のようにリクエストします。
$ curl -s "https://www.stat-search.boj.or.jp/api/v1/getDataCode?format=json&lang=jp&db=PF02&code=PFGD1&startDate=202501&endDate=202601" | python3 -m json.tool
{
"STATUS": 200,
"MESSAGE": "正常に終了しました。",
"RESULTSET": [
{
"SERIES_CODE": "PFGD1",
"NAME_OF_TIME_SERIES_J": "政府債務合計",
"UNIT_J": "億円",
"FREQUENCY": "MONTHLY",
"VALUES": {
"SURVEY_DATES": [202501, 202502, ... , 202601],
"VALUES": [13196380, 13257276, ... , 13400334]
}
}
]
}
RESULTSET内の各系列にVALUESオブジェクトがあり、SURVEY_DATES(年月の配列)とVALUES(数値の配列)のペアで時系列データが格納されています。
では早速試してみます。
環境
今回使用した環境は以下の通りです。
Python 3.13.9
streamlit 1.56.0
requests 2.32.3
pandas 2.2.3
plotly 5.24.1
セットアップ
uvでライブラリをインストールします。
$ uv add streamlit requests pandas plotly
ダッシュボードを作成してみる
以下がapp.pyの全量コードです。サイドバーのレンジスライダーで期間を選択し、タブで「時系列推移」と「保有者別内訳」を切り替えられるダッシュボードになっています。
from datetime import date
import requests
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import streamlit as st
BOJ_API_BASE = "https://www.stat-search.boj.or.jp/api/v1/getDataCode"
@st.cache_data(ttl=3600)
def fetch_boj_data(codes: tuple[str, ...], start_date: str, end_date: str) -> dict:
"""日本銀行の時系列統計データAPIからデータを取得する"""
params = {
"format": "json",
"lang": "jp",
"db": "PF02",
"code": ",".join(codes),
"startDate": start_date,
"endDate": end_date,
}
try:
response = requests.get(BOJ_API_BASE, params=params, timeout=30)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
return {"STATUS": 0, "MESSAGE": f"APIリクエストに失敗しました: {e}"}
def parse_time_series(result: dict) -> pd.DataFrame:
"""APIレスポンスの1系列をDataFrameに変換する"""
dates = result["VALUES"]["SURVEY_DATES"]
values = result["VALUES"]["VALUES"]
df = pd.DataFrame({"date": dates, "value": values})
df["date"] = pd.to_datetime(df["date"].astype(str), format="%Y%m")
df["value"] = pd.to_numeric(df["value"], errors="coerce")
df = df.dropna(subset=["value"])
return df
def main():
st.set_page_config(page_title="政府債務データダッシュボード", layout="wide")
st.title("政府債務データダッシュボード")
st.caption("データソース: 日本銀行 時系列統計データ検索サイト API")
# サイドバーで期間設定
st.sidebar.header("データ取得条件")
min_date = date(1982, 4, 1)
max_date = date(2026, 12, 1)
date_range = st.sidebar.slider(
"期間",
min_value=min_date,
max_value=max_date,
value=(min_date, max_date),
format="YYYY年MM月",
)
start_date = date_range[0].strftime("%Y%m")
end_date = date_range[1].strftime("%Y%m")
# タブで表示を切り替え
tab1, tab2 = st.tabs(["政府債務の時系列推移", "保有者別内訳"])
# --- タブ1: 政府債務の時系列推移 ---
with tab1:
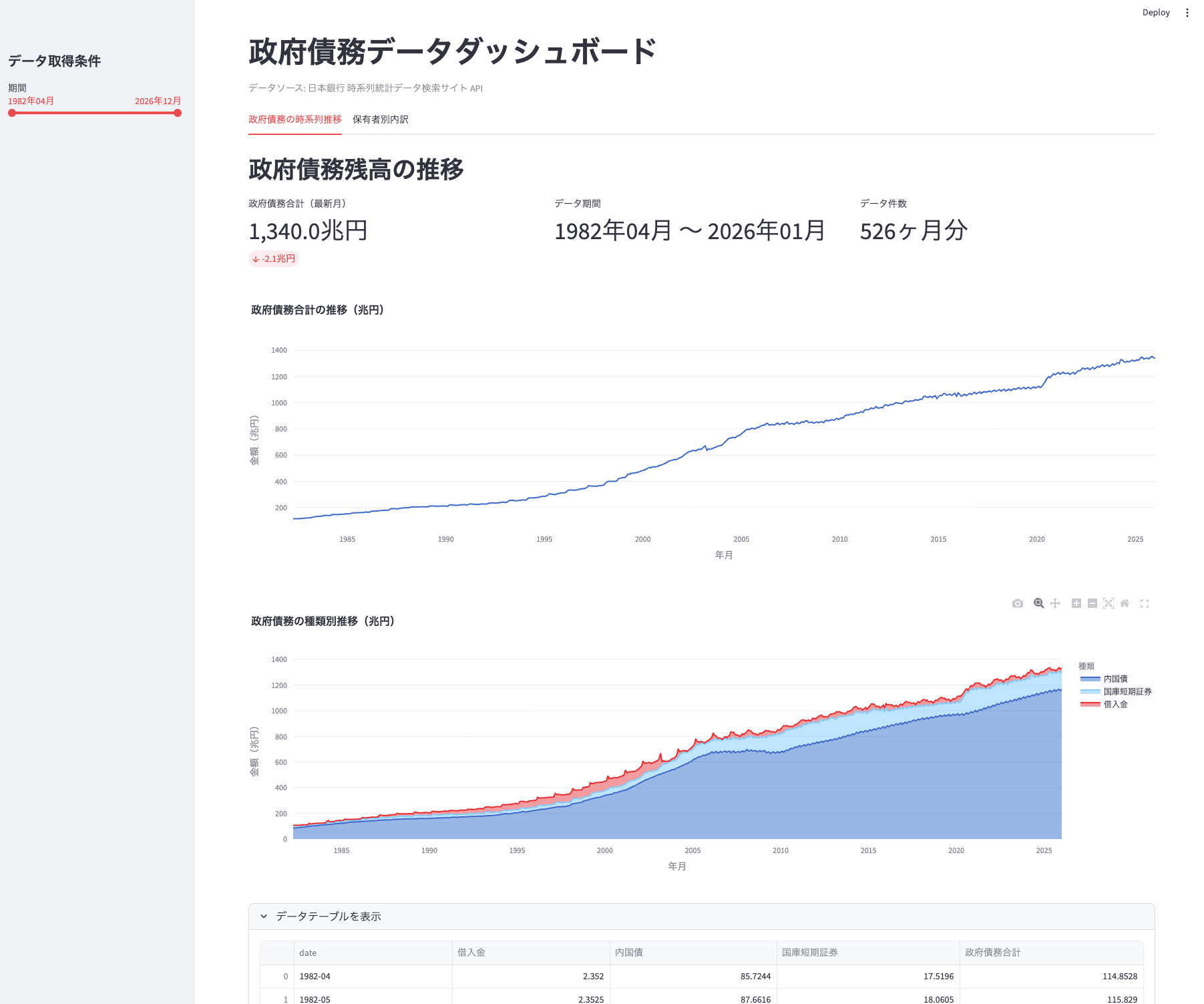
st.header("政府債務残高の推移")
debt_codes = ("PFGD1", "PFGD11", "PFGD@01", "PFGD18")
code_names = {
"PFGD1": "政府債務合計",
"PFGD11": "内国債",
"PFGD@01": "国庫短期証券",
"PFGD18": "借入金",
}
with st.spinner("日本銀行APIからデータを取得中..."):
data = fetch_boj_data(debt_codes, start_date, end_date)
if data["STATUS"] != 200:
st.error(f"APIエラー: {data['MESSAGE']}")
return
# 各系列のDataFrameを結合
dfs = []
for result in data["RESULTSET"]:
code = result["SERIES_CODE"]
name = code_names.get(code, result["NAME_OF_TIME_SERIES_J"])
df = parse_time_series(result)
df["series"] = name
df["value_cho"] = df["value"] / 10000 # 億円 → 兆円
dfs.append(df)
combined_df = pd.concat(dfs, ignore_index=True)
# 最新月の政府債務合計をメトリクスで表示
total_df = combined_df[combined_df["series"] == "政府債務合計"].sort_values(
"date"
)
if not total_df.empty:
latest = total_df.iloc[-1]
prev = total_df.iloc[-2] if len(total_df) > 1 else None
delta = (
f"{latest['value_cho'] - prev['value_cho']:.1f}兆円"
if prev is not None
else None
)
col1, col2, col3 = st.columns(3)
with col1:
st.metric(
label="政府債務合計(最新月)",
value=f"{latest['value_cho']:,.1f}兆円",
delta=delta,
)
with col2:
st.metric(
label="データ期間",
value=f"{total_df['date'].min().strftime('%Y年%m月')} 〜 {latest['date'].strftime('%Y年%m月')}",
)
with col3:
st.metric(label="データ件数", value=f"{len(total_df)}ヶ月分")
# 折れ線グラフ: 政府債務合計の推移
fig_total = px.line(
combined_df[combined_df["series"] == "政府債務合計"],
x="date",
y="value_cho",
title="政府債務合計の推移(兆円)",
labels={"date": "年月", "value_cho": "金額(兆円)"},
)
fig_total.update_layout(hovermode="x unified")
st.plotly_chart(fig_total, use_container_width=True)
# 内訳の推移
fig_breakdown = px.area(
combined_df[combined_df["series"] != "政府債務合計"],
x="date",
y="value_cho",
color="series",
title="政府債務の種類別推移(兆円)",
labels={"date": "年月", "value_cho": "金額(兆円)", "series": "種類"},
)
fig_breakdown.update_layout(hovermode="x unified")
st.plotly_chart(fig_breakdown, use_container_width=True)
# データテーブル
with st.expander("データテーブルを表示"):
pivot_df = combined_df.pivot_table(
index="date", columns="series", values="value_cho"
).reset_index()
pivot_df["date"] = pivot_df["date"].dt.strftime("%Y-%m")
st.dataframe(pivot_df, use_container_width=True)
# --- タブ2: 保有者別内訳 ---
with tab2:
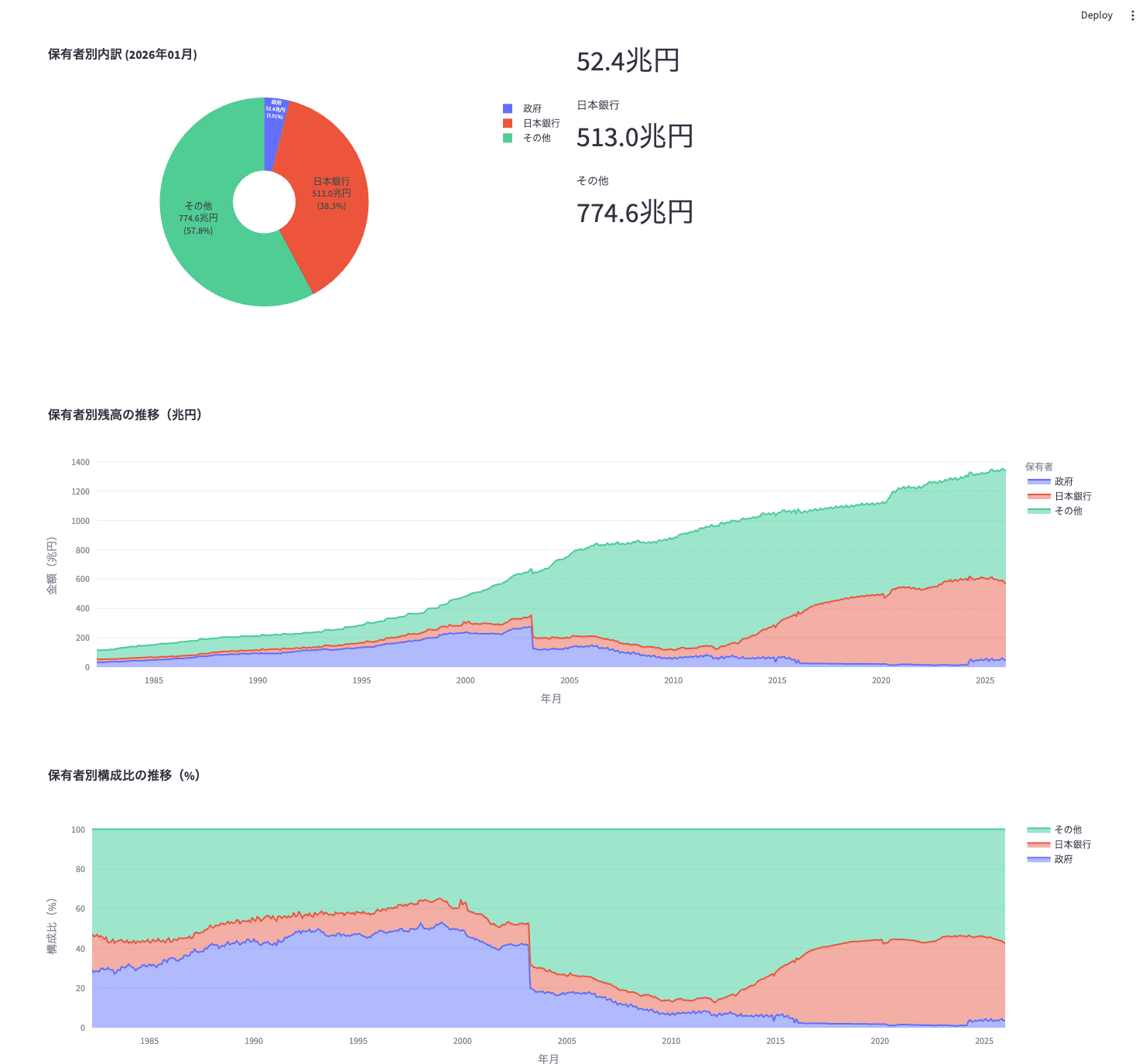
st.header("国債の保有者別内訳")
holder_codes = ("PFGD210", "PFGD220", "PFGD230")
holder_names = {
"PFGD210": "政府",
"PFGD220": "日本銀行",
"PFGD230": "その他",
}
holder_order = ["政府", "日本銀行", "その他"]
holder_colors = {"政府": "#636EFA", "日本銀行": "#EF553B", "その他": "#00CC96"}
with st.spinner("日本銀行APIからデータを取得中..."):
holder_data = fetch_boj_data(holder_codes, start_date, end_date)
if holder_data["STATUS"] != 200:
st.error(f"APIエラー: {holder_data['MESSAGE']}")
return
holder_dfs = []
for result in holder_data["RESULTSET"]:
code = result["SERIES_CODE"]
name = holder_names.get(code, result["NAME_OF_TIME_SERIES_J"])
df = parse_time_series(result)
df["holder"] = name
df["value_cho"] = df["value"] / 10000
holder_dfs.append(df)
holder_combined = pd.concat(holder_dfs, ignore_index=True)
# 最新月の保有者内訳を円グラフで表示
latest_date = holder_combined["date"].max()
latest_holder = holder_combined[holder_combined["date"] == latest_date]
col1, col2 = st.columns(2)
with col1:
fig_pie = px.pie(
latest_holder,
values="value_cho",
names="holder",
title=f"保有者別内訳 ({latest_date.strftime('%Y年%m月')})",
hole=0.3,
color="holder",
color_discrete_map=holder_colors,
category_orders={"holder": holder_order},
)
fig_pie.update_traces(
textposition="inside",
textinfo="label+percent+value",
texttemplate="%{label}<br>%{value:,.1f}兆円<br>(%{percent})",
)
st.plotly_chart(fig_pie, use_container_width=True)
with col2:
# メトリクス表示
for _, row in latest_holder.iterrows():
st.metric(
label=f"{row['holder']}",
value=f"{row['value_cho']:,.1f}兆円",
)
# 保有者別の推移(積み上げ面グラフ)
fig_holder_area = px.area(
holder_combined,
x="date",
y="value_cho",
color="holder",
title="保有者別残高の推移(兆円)",
labels={"date": "年月", "value_cho": "金額(兆円)", "holder": "保有者"},
color_discrete_map=holder_colors,
category_orders={"holder": holder_order},
)
fig_holder_area.update_layout(hovermode="x unified")
st.plotly_chart(fig_holder_area, use_container_width=True)
# 保有者別の構成比推移
holder_pivot = holder_combined.pivot_table(
index="date", columns="holder", values="value_cho"
)
holder_pct = holder_pivot.div(holder_pivot.sum(axis=1), axis=0) * 100
fig_pct = go.Figure()
for name in holder_order:
if name in holder_pct.columns:
fig_pct.add_trace(
go.Scatter(
x=holder_pct.index,
y=holder_pct[name],
name=name,
stackgroup="one",
hovertemplate="%{y:.1f}%",
line=dict(color=holder_colors[name]),
)
)
fig_pct.update_layout(
title="保有者別構成比の推移(%)",
xaxis_title="年月",
yaxis_title="構成比(%)",
hovermode="x unified",
)
st.plotly_chart(fig_pct, use_container_width=True)
# データテーブル
with st.expander("データテーブルを表示"):
holder_table = holder_combined.pivot_table(
index="date", columns="holder", values="value_cho"
).reset_index()
holder_table["date"] = holder_table["date"].dt.strftime("%Y-%m")
st.dataframe(holder_table, use_container_width=True)
if __name__ == "__main__":
main()
以下のコマンドで起動します。
$ streamlit run app.py
ブラウザが自動で開き、ダッシュボードが表示されます。サイドバーのスライダーで取得期間を変更すると、グラフが自動更新されます。
コードの解説
ここからはコードの上から順に、使用しているStreamlit機能を解説していきます。
st.cache_data: 外部APIリクエストのキャッシュ
@st.cache_data(ttl=3600)
def fetch_boj_data(codes: tuple[str, ...], start_date: str, end_date: str) -> dict:
@st.cache_data(ttl=3600)は同じ引数での関数呼び出し結果を1時間キャッシュするデコレータです。Streamlitはユーザー操作のたびにスクリプト全体を再実行する仕組みのため、外部APIへのリクエストなど重い処理にはキャッシュが必須です。なお引数にはハッシュ可能なtupleを使用しています(listはミュータブルなためキャッシュキーとして非推奨)。
st.set_page_config: ページ設定
st.set_page_config(page_title="政府債務データダッシュボード", layout="wide")
layout="wide"を指定することで、画面全体の幅を使ったワイドレイアウトになります。ダッシュボードのように横並びでグラフを表示する場合に便利です。この関数はスクリプトの最初に呼び出す必要があります。
st.sidebar.slider: サイドバーのレンジスライダー
date_range = st.sidebar.slider(
"期間",
min_value=min_date,
max_value=max_date,
value=(min_date, max_date),
format="YYYY年MM月",
)
st.sidebar配下にウィジェットを配置すると、画面左側のサイドバーに表示されます。date型の値をタプルで渡すとレンジスライダーになり、開始・終了を1つのスライダーで操作できます。format="YYYY年MM月"で「2020年01月」のように日本語表示されます。
st.tabs: タブ切り替え
tab1, tab2 = st.tabs(["政府債務の時系列推移", "保有者別内訳"])
st.tabsでタブUIを作成し、コンテンツを切り替えられます。注意点として、表示されていないタブのコードも毎回実行されます。そのため各タブ内で重いデータ処理を行う場合は@st.cache_dataでキャッシュしておくことが重要です。
st.spinner / st.error: ローディング表示とエラー表示
with st.spinner("日本銀行APIからデータを取得中..."):
data = fetch_boj_data(debt_codes, start_date, end_date)
if data["STATUS"] != 200:
st.error(f"APIエラー: {data['MESSAGE']}")
return
st.spinnerはwith句で囲むだけでローディングメッセージを表示するコンテキストマネージャです。st.errorでエラーメッセージを赤いボックスで表示しています。
st.columns + st.metric: KPIカードの横並び表示
col1, col2, col3 = st.columns(3)
with col1:
st.metric(
label="政府債務合計(最新月)",
value=f"{latest['value_cho']:,.1f}兆円",
delta=delta,
)
st.columnsでカラムレイアウトを作り、st.metricでKPIカード風の表示ができます。deltaパラメータに前月との差額を渡すと、自動的に上向き/下向きの矢印と色が付きます。
st.plotly_chart: Plotlyグラフの表示
fig_total = px.line(
combined_df[combined_df["series"] == "政府債務合計"],
x="date",
y="value_cho",
title="政府債務合計の推移(兆円)",
labels={"date": "年月", "value_cho": "金額(兆円)"},
)
fig_total.update_layout(hovermode="x unified")
st.plotly_chart(fig_total, use_container_width=True)
Streamlitの組み込みのst.line_chartは簡易的なグラフには便利ですが、ツールチップのカスタマイズやズーム操作などのインタラクティブ性が限られます。複数系列の時系列データを扱う場合はst.plotly_chartでPlotlyを使う方が適しています。use_container_width=Trueでグラフが画面幅に合わせてレスポンシブに表示されます。hovermode="x unified"を設定すると、マウスオーバー時に全系列の値を一覧で確認できます。
今回使用しているPlotlyのグラフタイプは以下の通りです。
| 関数 | グラフ種類 | 用途 |
|---|---|---|
px.line |
折れ線グラフ | 政府債務合計の推移 |
px.area |
積み上げ面グラフ | 種類別・保有者別の推移 |
px.pie |
ドーナツチャート(hole=0.3) |
保有者別の構成比 |
go.Scatter |
100%積み上げ面グラフ | 保有者別の構成比推移 |
px.area(Plotly Express)では100%正規化の制御が限られるため、構成比推移にはpandasでパーセント計算した値をgo.Scatter(Graph Objects)のstackgroup="one"で積み上げ表示しています。
st.expander + st.dataframe: 折りたたみ可能なデータテーブル
with st.expander("データテーブルを表示"):
pivot_df = combined_df.pivot_table(
index="date", columns="series", values="value_cho"
).reset_index()
pivot_df["date"] = pivot_df["date"].dt.strftime("%Y-%m")
st.dataframe(pivot_df, use_container_width=True)
st.expanderで折りたたみセクションを作り、st.dataframeでDataFrameをインタラクティブなテーブルとして表示できます。デフォルトでは閉じた状態で表示され、クリックで展開されます。グラフの補足としてデータテーブルを提供する場合に便利です。
color_discrete_map: グラフ間の凡例色統一
holder_order = ["政府", "日本銀行", "その他"]
holder_colors = {"政府": "#636EFA", "日本銀行": "#EF553B", "その他": "#00CC96"}
複数のグラフで同じカテゴリを表示する場合、Plotlyはグラフごとに独立して色を割り当てるため、凡例の色がバラバラになることがあります。color_discrete_mapとcategory_ordersで全グラフに共通のカラーマップと表示順序を指定することで統一できます。go.Scatterの場合はline=dict(color=holder_colors[name])で個別に指定します。
今回試したStreamlit機能のまとめ
| 機能 | 使い所 | ポイント |
|---|---|---|
st.cache_data |
外部API呼び出し | ttlでキャッシュ有効期限を設定。引数はハッシュ可能な型(tuple等)を使う |
st.sidebar |
フィルタ条件の配置 | メインコンテンツと分離してUIがすっきりする |
st.tabs |
複数ビューの切り替え | 非表示タブのコードも実行される点に注意 |
st.columns |
横並びレイアウト | 3〜4カラムが視認性が高い |
st.metric |
KPI表示 | deltaで変化量を自動で色付き表示 |
st.plotly_chart |
インタラクティブグラフ | use_container_width=Trueでレスポンシブ化 |
st.expander |
補足情報の折りたたみ | デフォルト閉じで画面をすっきり保つ |
st.spinner |
ローディング表示 | with句で囲むだけで表示 |
st.error |
エラー表示 | 赤いボックスでユーザーに通知 |
まとめ
Streamlitの主要な機能を一通り試してみました。
Pythonのコードだけでサイドバー、タブ、カラムレイアウト、KPIカード、インタラクティブなグラフといったダッシュボードに必要な要素を約250行で実装できました。特にPlotlyとの統合が強力で、st.plotly_chartに渡すだけでズームやツールチップが動作するインタラクティブなグラフが表示できます。
また、@st.cache_dataによるキャッシュはStreamlitの「操作のたびにスクリプト全体を再実行する」という仕組みを理解した上で適切に設定することが重要です。
最後まで読んで頂いてありがとうございました。







