Sumo Logic – Scheduled View の作成方法と注意点について
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
記事の内容が古い場合は、公式サイトもご確認ください。
Sumo Logic については以下をご参照ください。
最初に
Sumo Logic では、メッセージデータ(ログ・メトリクス)を受信したときに以下の順でデータを評価します。

※ 今回はスケジュールドビュー(Scheduled View)をご紹介します!
Scheduled View について
Scheduled View は、データがインデックスされる前に事前にログデータを集計し、特定の期間内のデータを計算して出力します。
よくあるユースケースとして、トラフィックパターンや、ユーザアクティビティ、FW などの脅威傾向分析などで、高速にインサイト得るために使用されます。
そのため、中長期的なデータの傾向分析を行うことが目的になります。
Scheduled View 作成時の注意点
Scheduled View の作成には、以下の制限や、作成のベストプラクティスがあります。
Scheduled View 作成に必要なロール
- Manage Scheduled Views
Scheduled View の表示、作成、編集、削除ができます。
アカウントの管理者と、Manage Scheduled Views 権限が付与されるアカウントは、Scheduled View の設定が可能です。
また、権限がない他のすべてのユーザは、Scheduled View に対して検索は可能です。検索させたくない場合は、ログデータアクセスの制御用に検索フィルタのロールを使用して制御可能です。
① Administration > ② Users and Roles> ③ Roles > ④ + Add Role
検索フィルタでは、ロールに応じてアクセスが許可されているデータのみを表示させることが可能です。以下の場合は、labs で始まる _sourceCategory のデータにのみアクセス可能です。
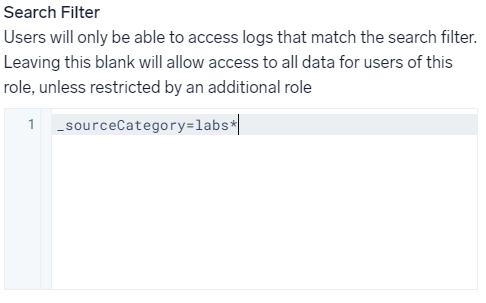
- 参考元 -
Create and Manage Roles
Understanding search filters
Scheduled View の制限
- アカウントごとに 500 件まで作成可能
- 作成した Scheduled View を編集 / 更新できない
- 作成した Scheduled View は、無効にした後、有効にできません。
- Scheduled View の検索クエリは、1分ごとに1回実行されます。
- 生のログメッセージが含まれている場合、取り込み量としてカウントされます
編集の場合、データの保持期間、データ転送のみ、変更可能です。
また、既定の保持期間を短縮する場合は、7 日後に短縮するか、即時短縮するか選択可能です。
スケジュールドビューは、一時停止 / 再開が選択できるようになっております。
また、使用しないと判断したスケジュールドビューは、無効化が可能です。無効化した場合、再開させることが出来ません。
生データを含んでいる場合、取集するメッセージデータを取り込み量として、カウントされます。
Scheduled View のベストプラクティス
- 適切な保持期間を設けて、傾向分析に使用する
- スケジュールビューと、パーティションを併用すると最速でのクエリ検索が可能です。
- 変更される可能性のあるクエリ検索式は作成しない
- クエリ検索式には、柔軟性を持たせて定義する
Scheduled View は、一度に大量のログデータを分析するのではなく、決められた保持期間のデータに対してクエリ検索するため、アドホックな検索が可能です。
メタデータの変更で、クエリが崩れないようにしてください。
例)
_sourceCategory=*/apache/*
Scheduled View の作成方法
① Manage Data > ② Logs > ③ Scheduled Views > ④ + Add Scheduled View

すると、以下の Scheduled View 作成メニューが右側に表示されます。

① Scheduled View name
作成する Scheduled View の名前を入力します。
英数字(大・小文字)と、数字、アンダースコア( _ )が使用可能です。
② Query
Parse Operators と、Search Operators を使用して、インデックスされるデータへのクエリ文を書きます。
オペレータの詳細は、Scheduled Views Best Practices and Examplesをご確認ください。
group operator もしくは、aggregate operator、さらには、timeslice Search Operator を使用することを推奨しています。
これらにより、小規模のデータに対して Scheduled View を作成できるようになります。
・group operator と、aggregate operator
両方とも、集計するデータを区画化するという特徴があります。
・timeslice Search Operator
集計するデータの期間を指定できます。
ここで、期間を指定しなければ、Receipt Time を使用して、期間を指定する必要があります。
③ Search Mode
メッセージデータの解析方法を選択します。
- Auto Paarse Mode
- Manual Mode
SumoLoigc がメッセージデータを自動解析して、パースしてくれます。この機能を使う場合に選択するモードです。
Parse 構文や、正規表現を組み合わせて、手動で書いてパースさせたいときに選択するモードです。
④ Start Date
インデックスデータの開始日を指定します。 選択した日付以降のデータは、Scheduled View のデータとしてインデックス化されます。
⑤ Retention Period(in days)
1 ~ 5000 日以内で、インデックスするデータの保持期間を設定します。
Apply the retention period of Default Partition
こちらにチェックを入れると、データ保持期間にデフォルトの 30 日が設定されます。
⑥ Data Forwarding
Data Forwarding のチェックボックスを有効にすると、以下の設定画面が表示されます。

6-1. Forwarding Destination
転送先として、S3 への「既存の転送先」か、「新規の転送先を作成する」か選択します。
新規の転送先を選択した場合、同じ画面でバケット名や、アクセス方式、ARN などの設定が必要になります。
6-2. Amazon S3 Destination
既存の転送先を選択した場合のみ表示されます。
設定済みの転送先が列挙されますので、選択してください。
6-3. File Format
S3 バケット内のディレクトリへのパスを設定します。
パスの書式については、こちら Forward data to S3 をご確認ください。
別のリージョンに転送させる場合は、転送量が必要です。
まとめ
スケジュールドビューと、パーティションは、どちらもクエリ検索の高速化を叶えるよく似た機能になります。
しかし、目的が異なります。パーティションは、現在以降のメッセージデータについて区画化を行い、インデックス化します。対して、スケジュールドビューは、過去のデータも含めてインデックス化して、中長期的なクエリ検索に使用できます。
データを分析して、パターンや、傾向を知りたいケースに向いていると言えます。






