Textractを使用してブログに使う画像をマスキングしてみた
はじめに
こんにちは、山本翔大です。
ブログを書く際に画像を多く掲載することを心がけていますが、画像に含まれる個人情報を一つ一つ確認してマスキングする作業が煩雑だと感じるようになりました。そこで今回は AI を利用してマスキングを行いたいと思います。
当初は AI サービスに画像をアップロードして「個人情報を含む箇所をマスキングしてください」と依頼していましたが、マスキング漏れと画質の劣化が問題点でした。
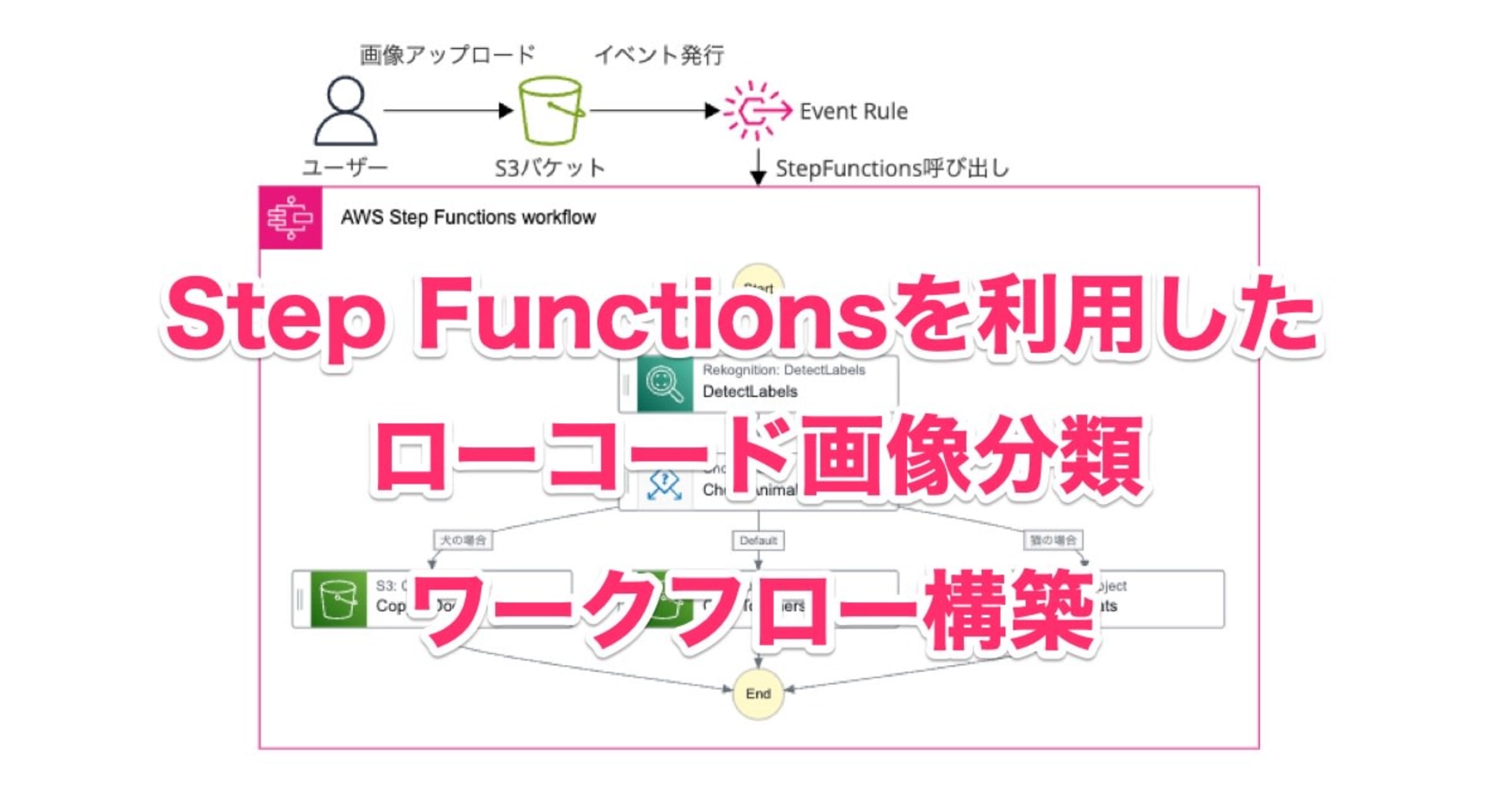
そのため今回は、以下の流れで自動マスキングシステムを構築します。
- S3 バケットに画像をアップロード
- AWS Lambda を使用して Amazon Textract で文字の認識と座標を取得
- Lambda 関数内で取得した座標を基に画像を黒塗りしてマスキング
- マスキング済みの画像を S3 バケットにアップロード
1.S3の作成
バケットの作成
画像を保存するための S3 バケットを作成します。
今回はマスキング済みの画像が再度マスキングされることを防ぐためにアップロード用とダウンロード用の 2 つのバケットを用意しました。
今回は以下のようにバケット名を設定しました。
input と output がわかりやすい名前に設定してください
1 つ目のバケット
- 名前: blog-masking-input-source
2 つ目のバケット
- 名前: blog-masking-output-dest
その他の設定はデフォルトのままで問題ありません。
2.Lambda設定
関数作成
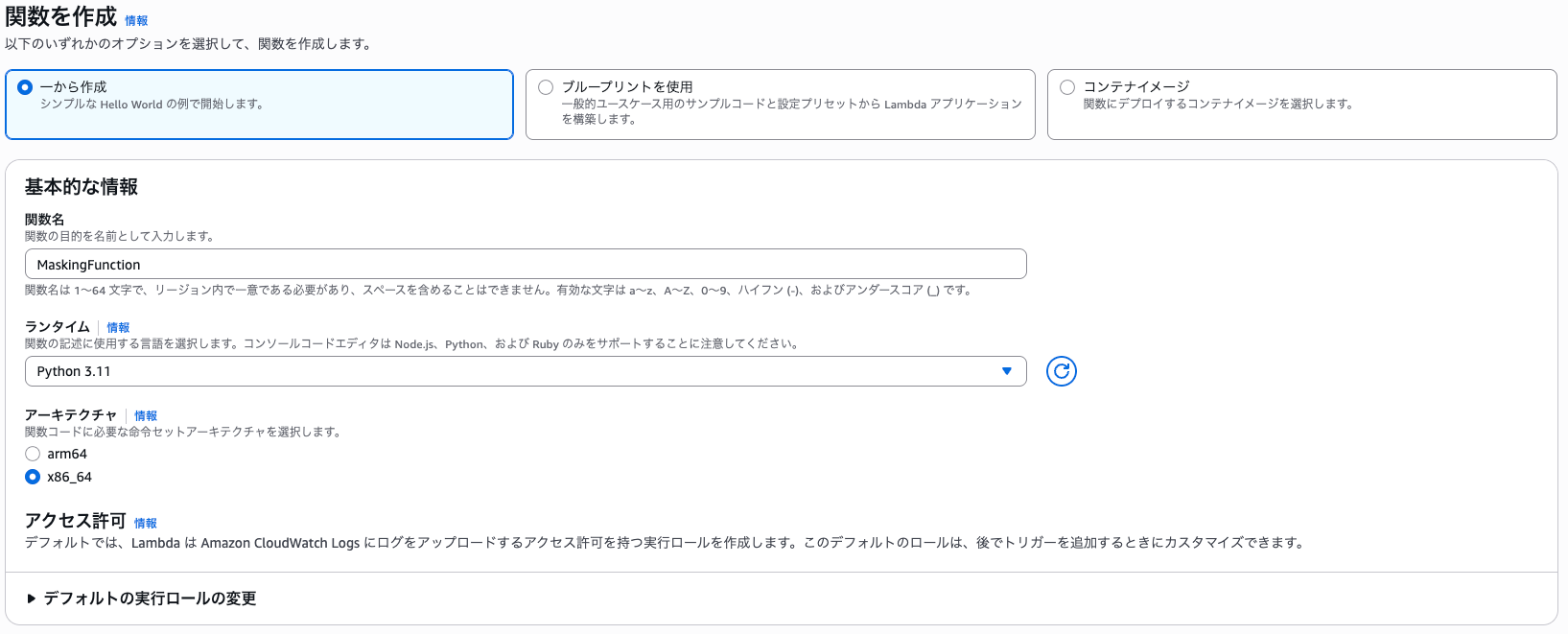
まずは関数を作成します。以下の設定で Lambda 関数を作成してください。
- 関数名:MaskingFunction
- ランタイム:Python 3.11
- アーキテクチャ:x86_64
コードの追加
コードには以下の内容を記述してください。
import json
import boto3
import os
import re
import io
import urllib.parse
import unicodedata
from PIL import Image, ImageDraw
s3 = boto3.client('s3')
# Textractを指定
textract = boto3.client('textract', region_name='us-east-1')
def normalize_text(text):
"""
判定精度を上げるためにテキストを掃除する関数
1. 全角を半角に変換 (例: 123 -> 123)
2. スペースを削除 (例: 12 34 -> 1234)
"""
# NFKC正規化(全角英数などを半角に)
text = unicodedata.normalize('NFKC', text)
# スペース削除
text_nospace = text.replace(" ", "").replace(" ", "")
return text, text_nospace
def lambda_handler(event, context):
input_bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
print(f"Processing: {key}")
try:
# 画像取得
response = s3.get_object(Bucket=input_bucket, Key=key)
image_bytes = response['Body'].read()
image = Image.open(io.BytesIO(image_bytes))
# Textract実行
textract_response = textract.detect_document_text(Document={'Bytes': image_bytes})
draw = ImageDraw.Draw(image)
width, height = image.size
# --- マスキング条件 ---
patterns = [
# 1. AWS Account ID (12桁の数字)
# ハイフンやスペースが混じっていても、数字が12個並んでいれば検知
r'\d[\d\s-]{10,}\d',
# 2. Email Address
r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}',
# 3. 特定のキーワード
r'Admin',
r'Secret',
r'AccessKey',
r'Password'
]
# 検出されたブロックを走査
for block in textract_response['Blocks']:
if block['BlockType'] == 'LINE':
raw_text = block['Text']
# 正規化
_, text_nospace = normalize_text(raw_text)
# 判定ロジック
is_hit = False
for pattern in patterns:
# 元のテキストでチェック
if re.search(pattern, raw_text, re.IGNORECASE):
is_hit = True
# スペース無し版でチェック
elif re.search(pattern, text_nospace, re.IGNORECASE):
is_hit = True
if is_hit:
print(f"Masking HIT: {raw_text}")
box = block['Geometry']['BoundingBox']
# 座標計算
left = width * box['Left']
top = height * box['Top']
w = width * box['Width']
h = height * box['Height']
# マージンを少し広めにとる (上下左右 +7px)
margin = 7
shape = [
left - margin,
top - margin,
left + w + margin,
top + h + margin
]
draw.rectangle(shape, fill="black")
# 保存処理
output_buffer = io.BytesIO()
image.save(output_buffer, format='PNG')
output_buffer.seek(0)
output_bucket = os.environ['OUTPUT_BUCKET']
# ファイル名に "masked_" をつける
output_key = f"masked_{key.split('/')[-1]}"
if not output_key.endswith('.png'):
output_key += '.png'
s3.put_object(
Bucket=output_bucket,
Key=output_key,
Body=output_buffer,
ContentType='image/png'
)
return "Success"
except Exception as e:
print(f"Error: {e}")
raise e
こちらのコードは対象の S3 バケットにアップロードされた画像から AWS の Textract サービスで文字を読み取り、特定情報(メール・パスワード・管理系キーワード・AWSアカウント ID らしき数字など)を黒塗りマスクし、別の S3 バケットへ保存する処理をしています。
Amazon Textract は 2025年12月時点で東京リージョン( ap-northeast-1 )では利用できません。そのため、コード内で明示的に us-east-1 リージョンを指定しています。
textract = boto3.client('textract', region_name='us-east-1')
コードを書き終えたら設定タブから環境変数をクリックし OUTPUT_BUCKET キーを作成しアウトプット用バケットの名前を追加してください。

レイヤーの追加
次にレイヤーを追加します。
Lambda の Python ランタイムには画像処理ライブラリの Pillow がデフォルトで含まれていないため、Lambda レイヤーを使用して追加する必要があります。
今回は Klayers から Python 3.11 に対応している Pillow レイヤーの ARN を取得しました。
手順:
- Klayers のリポジトリ にアクセス
- 使用するリージョン(例: ap-northeast-1)のファイルを開く
- Pillow の最新 ARN をコピー
- Lambda 関数の「レイヤーを追加」から「ARN を指定」を選択
- コピーした ARN を貼り付けて追加

ロールの作成
次に Lambda が他のサービスに接続するためのポリシーを設定します。
Lambda が S3 バケットと Textract に接続するために以下のポリシーを追加してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::blog-masking-input-source/*",
"arn:aws:s3:::blog-masking-output-dest/*"
]
},
{
"Effect": "Allow",
"Action": [
"textract:DetectDocumentText"
],
"Resource": "*"
}
]
}
トリガー設定
次にトリガーを追加します。
設定のトリガーから S3 を選択し、作成した blog-masking-input-source を選びます。
イベントタイプは全てのオブジェクト作成イベントを選択し、サフィックスオプションは今回はPNG形式の画像を指定したいため.pngにします。
その他設定
画像処理には時間、メモリが多くかかるためメモリと時間を以下のように設定します
- メモリ: 128 MB → 512 MB
- タイムアウト:3秒 → 60秒
3.テスト
構築が完了したので実際にテストします。
作成した blog-masking-input-source バケットに PNG 画像をアップロードすると Lambda が実行され、マスキング済みの画像が blog-masking-output-dest バケットにアップロードされます。
おわりに
本記事では、AWS Lambda と Amazon Textract を使用した画像の自動マスキングシステムを構築しました。
このシステムにより、ブログ記事作成時の画像マスキング作業を効率化できます。現時点では日本語テキストには対応していませんが、英数字やメールアドレスなどの自動マスキングが可能です。
参考資料
アノテーション株式会社について
アノテーション株式会社はクラスメソッドグループのオペレーション専門特化企業です。サポート・運用・開発保守・情シス・バックオフィスの専門チームが、最新 IT テクノロジー、高い技術力、蓄積されたノウハウをフル活用し、お客様の課題解決を行っています。当社は様々な職種でメンバーを募集しています。「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、アノテーション株式会社 採用サイトをぜひご覧ください。