
Timestream for LiveAnalyticsのクエリインサイトを使ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
昨年の10月頃にTimestream for LiveAnalytics(以降Timestreamと言います)にクエリインサイトという機能が追加されていたので、実際に使ってみました。
Timestreamのクエリパフォーマンスは パーティション と 時間 を限定することでパフォーマンスが最適化されます。
図にすると、以下のように縦軸(パーティションキー)と横軸(時間)を絞ることで、必要なデータのみにアクセスするイメージです。
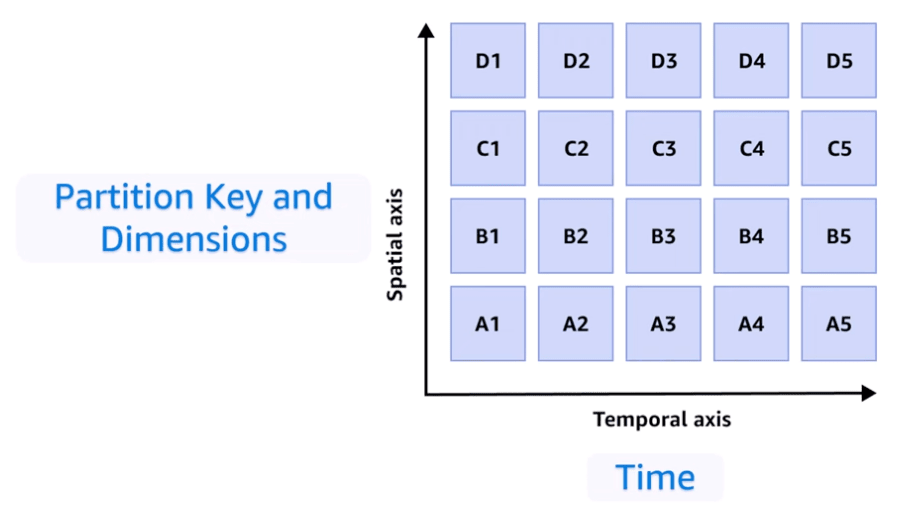
このテーブルに対してパーティションと時間を絞ったクエリを実行することでスキャン範囲が絞れる
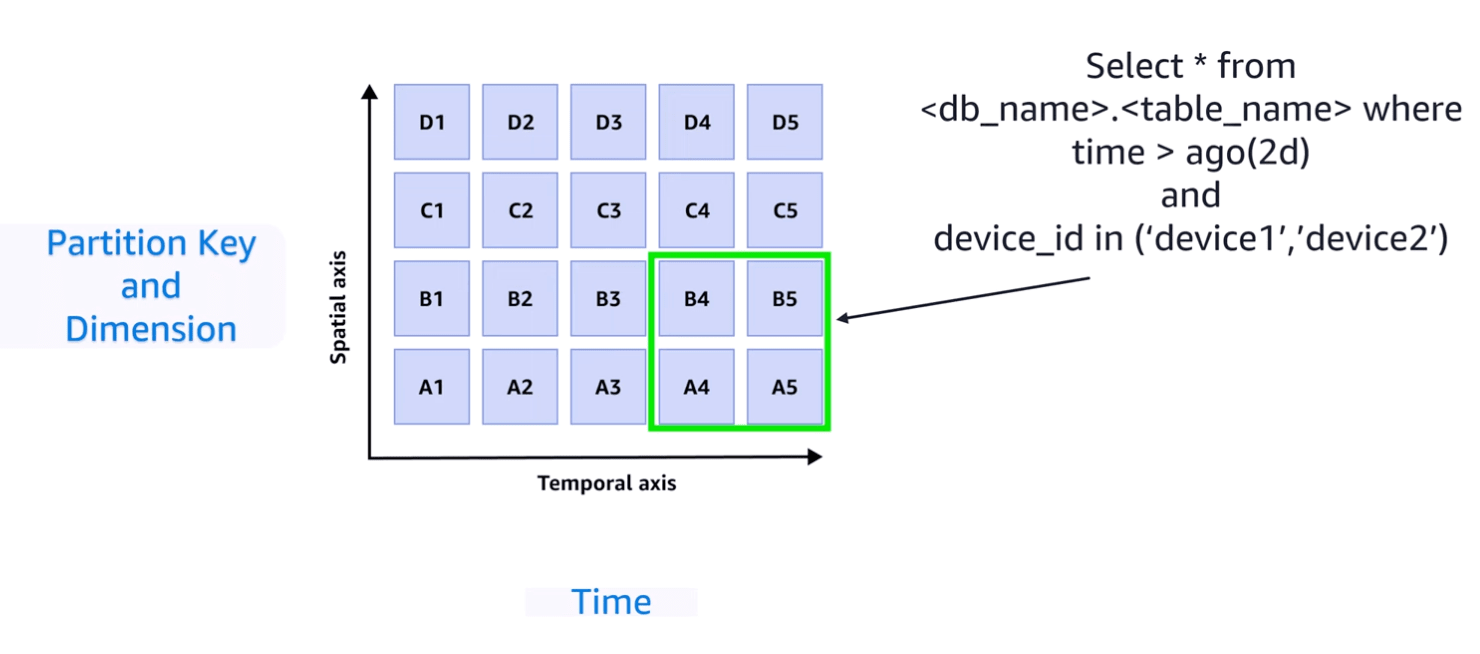
クエリインサイトを使うことで、パーティションと時間がどれだけ絞れているかを数値で教えてくれます。
上の図で言うと、緑色の四角の部分がどれだけ小さいか?を教えてくれます。
また、クエリインサイトを使用すると、改善すべきクエリを特定して最適化できるため、クエリのパフォーマンスの向上やコストの削減につながります。
こちらのAWSが配信する動画でもクエリインサイトについてデモを交えた解説がされていましたので興味がある方は見てみて下さい。
やってみる
前準備
今回は以下のようなテーブルを準備します。
ディメンション:deviceid, location
パーティションキー:deviceid
| location | deviceid | measure_name | time | level | temperature | pressure |
|---|---|---|---|---|---|---|
| osaka | abc123 | metrics | 2025-02-04 01:17:21.610000000 | 936 | 25.0 | 1011.8 |
| tokyo | def456 | metrics | 2025-02-04 01:22:22.474000000 | 840 | 22.4 | 1017.1 |
| osaka | abc123 | metrics | 2025-02-04 01:27:23.294000000 | 882 | 24.0 | 1010.5 |
| tokyo | def456 | metrics | 2025-02-04 01:32:24.104000000 | 1137 | 26.1 | 1012.1 |
| osaka | abc123 | metrics | 2025-02-04 01:33:04.197000000 | 971 | 24.9 | 1018.5 |
| tokyo | def456 | metrics | 2025-02-04 01:38:05.028000000 | 1154 | 20.4 | 1011.2 |
| … | … | … | … | … | … | … |
パーティションはテーブル作成時にカスタムパーティショニングを選択して、deviceidをパーティションキーとしています。
デフォルトパーティショニングを選択する場合、パーティンションキーは自動的にmeasure_nameが選択されます。
しかし、マルチメジャーレコードの場合measure_nameの値は被るケースが多く、デフォルトパーティションニングの場合はパーティションキーによるクエリ最適化が難しくなります。
※ 今回のテーブルはマルチメジャーレコードを想定しています。シングルメジャーレコードの場合はmeasure_nameのカーディナリティは高くなる傾向があるのでmeasure_nameをパーティションキーとする選択肢もあります。
クエリインサイトの有効化
クエリインサイトを有効化するにはいくつか方法がありますが、今回はAWS CLIを使った方法で実施します。
AWS CLIの場合は--query-insightsオプションのModeをENABLED_WITH_RATE_CONTROLに指定すると、クエリ結果の最後にクエリインサイトの結果が表示されます。
フルスキャン
まずはフルスキャンの場合にどのようなインサイト結果が見られるのか試してみます。
aws timestream-query query \
--query-string "SELECT * FROM \"demo_db\".\"demo_table\"" \
--query-insights={\"Mode\":\"ENABLED_WITH_RATE_CONTROL\"}
以下はレスポンスからクエリインサイトの結果を抜き出した内容です。
"QueryInsightsResponse": {
"QuerySpatialCoverage": {
"Max": {
"Value": 1.0, <--ここを見る
"TableArn": "arn:aws:timestream:ap-northeast-1:123456789:database/demo_db/table/demo_table",
"PartitionKey": [
"deviceid"
]
}
},
"QueryTemporalRange": {
"Max": {
"Value": 6053400000000000, <--ここを見る
"TableArn": "arn:aws:timestream:ap-northeast-1:123456789:database/demo_db/table/demo_table"
}
},
"QueryTableCount": 1,
"OutputRows": 27,
"OutputBytes": 1863
}
クエリインサイトの結果から、フルスキャンを実施した際のクエリパフォーマンスが分かります。
QuerySpatialCoverage: 1.0(100%)
QueryTemporalRange: 6053400000000000(70日と1.5時間)
QuerySpatialCoverageは言葉の意味からは少し理解が難しいですが、
クエリが「必要なデータを探すために、どれだけ無駄なデータも含めてスキャンしているか」を0~1の数値で表しています。
1に近い = 非効率(多くの無駄なデータをスキャン)
0に近い = 効率的(必要なデータを的確にスキャン)
つまり、フルスキャンでは1.0(100%)なので無駄なスキャンが多いことが分かります。
QueryTemporalRangeはスキャンした時間範囲を表しています。
今回の結果では7日と1.5時間のデータに対してスキャンしています。
この時間が想定している範囲よりも大きい場合は、時間範囲を絞ってクエリを最適化することができます。
次に、パーティションや時間を指定することでどのように値が変化するのか確認していきます。
ちなみに、コンソール画面からクエリを実行する場合は、クエリエディタの Enable Insights にチェックを入れてクエリを実行するとクエリインサイトの結果が得られます。
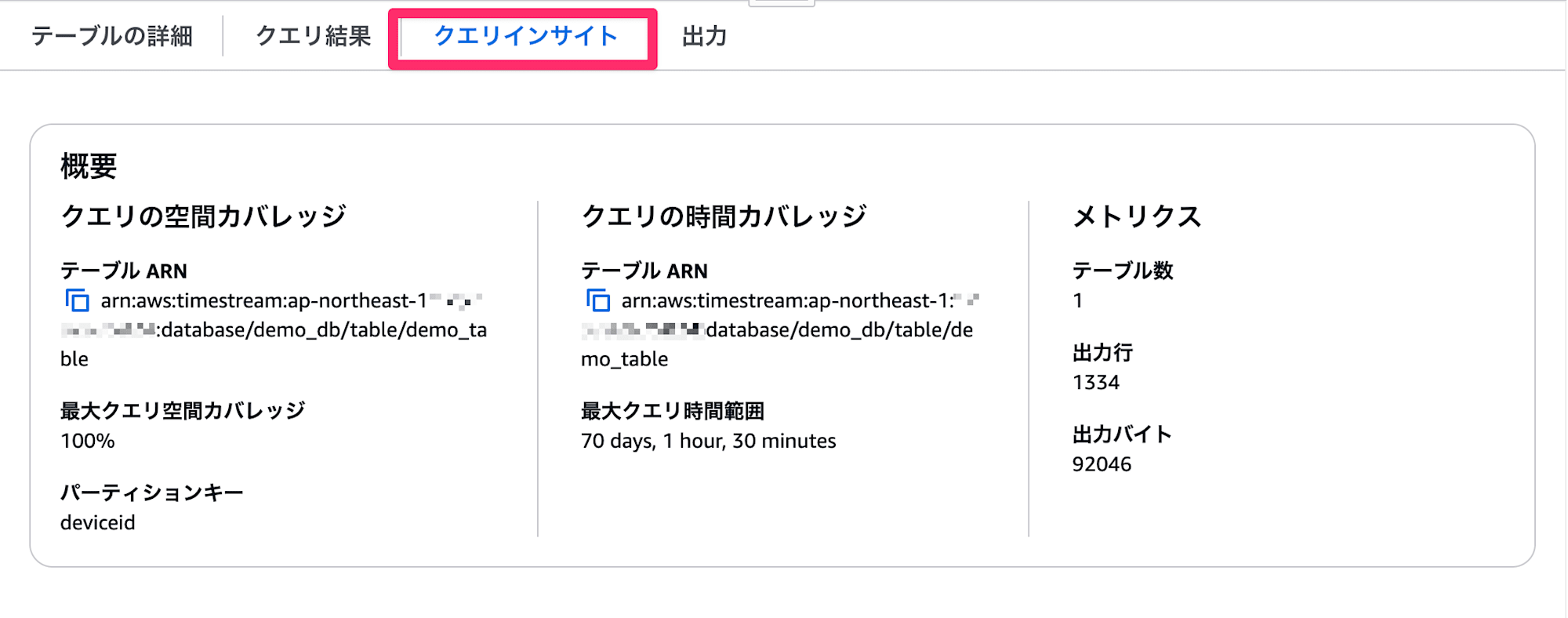
また、コンソール画面からであればクエリの持続時間とスキャンバイト数も確認できます。
スキャン時間: 0.9930秒
スキャンバイト数: 1.13KB
パーティション指定
まずはパーティションを指定してQuerySpatialCoverageの値が小さくなることを確認しましょう。
今回はWHERE区でdeviceidを指定します。
aws timestream-query query \
--query-string "SELECT * FROM \"demo_db\".\"demo_table\" WHERE deviceid='abc123' " \
--query-insights={\"Mode\":\"ENABLED_WITH_RATE_CONTROL\"}
"QueryInsightsResponse": {
"QuerySpatialCoverage": {
"Max": {
"Value": 0.0001,
"TableArn": "arn:aws:timestream:ap-northeast-1:123456789:database/demo_db/table/demo_table",
"PartitionKey": [
"deviceid"
]
}
},
"QueryTemporalRange": {
"Max": {
"Value": 6053400000000000,
"TableArn": "arn:aws:timestream:ap-northeast-1:123456789:database/demo_db/table/demo_table"
}
},
"QueryTableCount": 1,
"OutputRows": 16,
"OutputBytes": 1104
}
パーティションをdeviceidで指定したことによって QuerySpatialCoverage の値が0.0001(0.01%)まで小さくなったことが分かります。
時間範囲は指定していないので先ほどと変わりません。
クエリパフォーマンスも向上していることが分かります。
スキャン量も大きく下がっているためクエリコストも削減されます。
スキャン時間: 0.2310秒
スキャンバイト数: 688.00B
時間範囲の指定
次に時間範囲を1時間前のデータまでに指定します。
aws timestream-query query \
--query-string "SELECT * FROM \"demo_db\".\"demo_table\" WHERE deviceid='abc123' AND time > ago(1h) " \
--query-insights={\"Mode\":\"ENABLED_WITH_RATE_CONTROL\"}
"QuerySpatialCoverage": {
"Max": {
"Value": 0.0001,
"TableArn": "arn:aws:timestream:ap-northeast-1:123456789:database/demo_db/table/demo_table",
"PartitionKey": [
"deviceid"
]
}
},
"QueryTemporalRange": {
"Max": {
"Value": 5399999999999,
"TableArn": "arn:aws:timestream:ap-northeast-1:123456789:database/demo_db/table/demo_table"
}
},
"QueryTableCount": 1,
"OutputRows": 4,
"OutputBytes": 276
}
時間を指定したことでQueryTemporalRangeの値が6053400000000000から5399999999999まで小さくなりました。
クエリで設定した1時間を少し超えて1時間半くらいになっているのは気になりますが、おおよそ指定した時間範囲に絞られていることが確認できます。
(クエリ結果は1時間前までのデータしか表示されていませんでした)
クエリパフォーマンスに関しては、そもそものデータ量が少ないためスキャン時間はあまり変動はありませんでしたが、時間を絞ったことで検索したデータ量が減ってスキャンバイト数が小さくなっていることが分かります。
スキャン時間: 0.2020秒
スキャンバイト数: 215.00B
パーティションキー以外のディメンションを指定
Timestreamではパーティションキーは1つしか選択することができません。
そこでパーティションキー以外のディメンションを選択してもクエリインサイトの結果に違いがないことも確認してみます。
今回はlocationをosakaに指定してみます。
aws timestream-query query \
--query-string "SELECT * FROM \"demo_db\".\"demo_table\" WHERE location='osaka' " \
--query-insights={\"Mode\":\"ENABLED_WITH_RATE_CONTROL\"}
"QueryInsightsResponse": {
"QuerySpatialCoverage": {
"Max": {
"Value": 1.0,
"TableArn": "arn:aws:timestream:ap-northeast-1:123456789:database/demo_db/table/demo_table",
"PartitionKey": [
"deviceid"
]
}
},
"QueryTemporalRange": {
"Max": {
"Value": 6053400000000000,
"TableArn": "arn:aws:timestream:ap-northeast-1:123456789:database/demo_db/table/demo_table"
}
},
"QueryTableCount": 1,
"OutputRows": 16,
"OutputBytes": 1104
}
想定通りパーティションに指定していないディメンションではクエリインサイトの結果はフルスキャンと変わらない結果でした。
しかし、クエリの時間、スキャン量を確認するとパーティションキー(deviceid)を指定している時とほとんど差はありませんでした。
スキャン時間: 00.2840秒
スキャンバイト数: 688.00B
結果からWHERE句で特定のディメンションを指定した場合、ディメンションで絞られたデータのみがスキャンされました。
つまりディメンションの値でパーティションが切られているのだと予想されます。
Timestreamのドキュメントでも次のような記載があるので、おそらくTimestreamにデータを書き込む際にディメンション毎に自動的にパーティショニングされているとのだと思います。
Timestream for Live Analytics は、ストレージに書き込む前にデータを自動的にインデックス化してパーティション化します。
参照: https://docs.aws.amazon.com/ja_jp/timestream/latest/developerguide/architecture.html
ただし、クエリインサイトに利用できるパーティションキーは1つで、対象はテーブル作成時に指定したパーティションキーのようです。
つまり、検索に利用する頻度が高い かつ カーディナリティの高いディメンションを明示的にパーティションキーとすることで、クエリインサイトを使ったパーティションキーベースのインサイトが得られるということになります。
このことから利用頻度が高く、カーディナリティの高いディメンションがはっきりしている場合にはデフォルトではなくカスタムパーティショニングを指定することが望ましいでしょう。
まとめ
- Timestream for LiveAnalyticsでクエリインサイトが使えるようになった
- クエリインサイトではパーティショニングキーベースと時間範囲ベースのクエリ効率が確認できる
- データ登録時にディメンション毎に自動的にパーティションが切られていることもあるが、クエリインサイトで確認できるのはパーティションキーに設定している値のみ
今回はTimestreamのクエリインサイトを試してみました。
Timestreamの料金体系はクエリに利用するコンピューティングリソースに対しての従量課金のため、コストの観点でもクエリパフォーマンスは最適化されていることが望ましいです。
設計段階でデータのクエリパターンを考えていないと、パーティションキーの設定をデフォルトのまま進めてしまうこともあるかもしれませんが、今後のクエリパフォーマンスにも大きく影響する部分なので一度立ち止まって考えてみるのもいいかもしれません。










