
TROCCO と Athena を連携しデータ転送してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは!クラウド事業本部コンサルティング部のたかくに(@takakuni_)です。
先日、TROCCO を Amazon Athena と接続する機会がありました。
作業の中で少し工夫が必要だったため、今後迷うことがないよう、手順を残しておきます。
TROCCO
TROCCO は、分析基盤向けのデータ統合を自動化してくれる SaaS 製品です。
たとえば、Amazon S3 のデータを Google BigQuery に TROCCO で統合して、分析するといったことができます。
クラウドをはじめとしたプロバイダーの垣根を超えて、転送元/先を設定できるのがウリです。
やってみる
というわけで、今回は Athena を転送元としたケースです。
Athena を転送元とする場合、TROCCO で Athena に対してクエリを実行し、その結果を転送先にダンプできます。TROCCO を利用した転送ジョブは次のステップで作成します。
- 接続元設定(Athena からの取得)
- 接続先設定(Azure Blob Storage への送信)
- 転送設定(転送を行うジョブの設定)
本エントリでは転送元である Athena にフォーカスしたいですが、せっかくなので転送先は Azure Blob Storage を選択しました。
接続元設定
S3 バケットの作成
TROCCO の Athena 連携は図にすると次のイメージです。そのため、クエリ結果の一時置き場として S3 バケットが必要になります。

一時的なクエリ置き場として、 S3 バケットを作成しておきましょう。

利用用途の性質上、ライフサイクルポリシーを設定しておくと良いです。
IAM ユーザーの作成
続いて TROCCO が AWS へ接続できるよう、IAM ユーザーを作成します。
必要な権限は次のとおりです。TROCCO の tmp 領域として書き込む S3 バケット には、先ほど作成した S3 バケットを指定します。
{
"Statement": [
{
"Sid": "AthenaQueryStatement",
"Action": [
"athena:StartQueryExecution",
"athena:StopQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults",
"athena:GetQueryResultsStream",
"glue:GetTable",
"glue:GetDatabase"
],
"Effect": "Allow",
"Resource": "*"
},
{
"Sid": "S3BucketForTroccoStatement",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucketMultipartUploads",
"s3:AbortMultipartUpload",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListMultipartUploadParts"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::TROCCO の tmp 領域として書き込む S3 バケット/*",
"arn:aws:s3:::TROCCO の tmp 領域として書き込む S3 バケット"
]
},
{
"Sid": "S3BucketForAthenaStatement",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::Athena 経由で読み込む S3 バケット/*",
"arn:aws:s3:::Athena 経由で読み込む S3 バケット"
]
}
],
"Version": "2012-10-17"
}
作成された IAM ユーザーから、アクセスキーを払い出してメモしておきます。

テーブルの作成
Athena のテーブルを作成します。
今回は以下のようなサンプルファイルを作成し、 Athena で読み取る側の S3 バケットにアップロードしました。
氏名,氏名(ひらがな),年齢,生年月日
大平 誠司,おおひら せいじ,35,1990年1月21日
木村 俊司,きむら しゅんじ,40,1984年5月30日
斎藤 隆弘,さいとう たかひろ,25,1999年5月19日
岡島 憲,おかじま ただし,80,1944年7月16日
桜田 茂,さくらだ しげる,55,1969年9月14日
大野 俊,おおの しゅん,52,1972年4月2日
立川 翔,たちかわ しょう,55,1969年12月15日
鶴見 祥太郎,つるみ しょうたろう,65,1959年7月11日
高倉 純子,たかくら じゅんこ,76,1948年9月16日
新名 智樹,にいな ともき,23,2002年3月15日
テーブルを作成します。Athena 経由で読み込む S3 バケット は適宜変更します。
CREATE EXTERNAL TABLE trocco (
full_name string,
full_name_hiragana string,
age int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION
's3://Athena 経由で読み込む S3 バケット/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
試しにマネジメントコンソール上の Athena 経由でクエリして見ましたが、うまく出力できているようです。
SELECT * FROM trocco
LIMIT 5;

接続元設定
一時的な S3 バケット、IAM の作成、Athena の動作確認が取れたところで、 TROCCO 側の接続設定に移ります。AthenaエンドポイントURL には jdbc:awsathena://athena.リージョン名.amazonaws.com:443 の形式で URL を入力します。
私の場合は東京リージョンのため、jdbc:awsathena://athena.ap-northeast-1.amazonaws.com:443 としました。
参考:Athena input plugin for Embulk

一時出力先Amazon S3バケット・パス, AWSアクセスキーID, AWSシークレットアクセスキー は先ほど作成した内容を入力しましょう。

接続先設定
続いて転送先設定です。ストレージアカウント/コンテナ作成後、アクセスキーを取得します。

Blob Stroage 側は非常にシンプルで、先ほど作成したストレージアカウント、アカウントキーを入力します。

接続を確認 をクリックすると、認証できていると表示されていますね。

転送設定
最後に転送設定です。転送元に Amazon Athena、転送先に Azure Blob Storage を指定します。

名前やメモを指定できるようです。マークダウンで h6 まで指定できました。

接続元設定で先ほどの Athena の設定を選び、SQL の内容を記述します。カラムも追加しておきましょう。
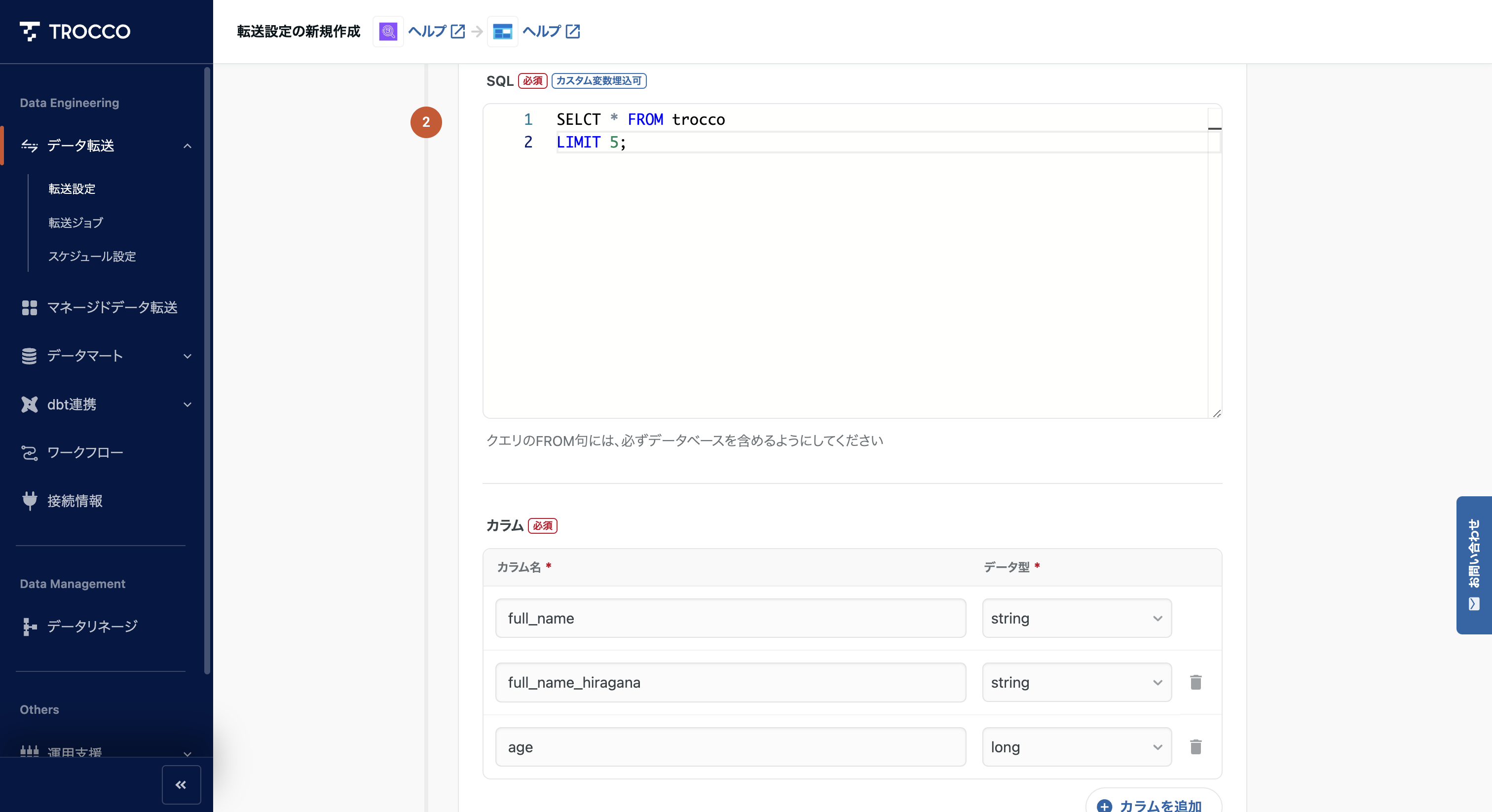
プレビューに映ると、先ほどの SQL で定義した内容が表示されました。想定通りですね。

最後に確認画面です。最終的な設定は YAML の形式でバージョン管理されるようです。見やすくて便利ですね。

ジョブの作成が完了しました。UI はこのようなイメージでみやすいですね。

先ほど設定した、ジョブの内容が表示されていますね。

実行プレビューも表示されているため、複数ジョブを組んでいる場合だと、便利そうな気がしました。

ジョブを実行してみました。うまく成功していますね。

Blob Storage 側にもオブジェクトが保管されています。

まとめ
以上、「TROCCO と Athena を連携しデータ転送してみた」でした。
どなたかの参考になれば幸いです。
クラウド事業本部コンサルティング部のたかくに(@takakuni_)でした!











