
レガシー CUR から CUR 2.0 利用への移行を支援する query-converter と migrate-cur1 を試してみた
AWS のコストと使用状況に関する最も詳細な情報として提供されている Cost and Usage Report(CUR)は 2025年8月6日時点ではレガシー CUR と CUR2.0 の 二つが提供されています。
従来の CUR がレガシー CUR となり、アカウント名の追加や特定列をネストした値となる等の変更が加わったのが CUR 2.0 となります。二つの詳細な説明は公式ドキュメントをご確認ください。
これから新しく CUR を利用する場合には CUR 2.0 の利用が推奨されますが、レガシー CUR をベースとしたアセットや業務がある場合には CUR 2.0 への対応が必要となります。
具体的に想定される対応としては CUR 2.0 フォーマットに対応したデータの準備と SQL クエリ(とそれらを利用する処理)の変換が必要となります。データに関してはレガシー CUR フォーマットのデータを何らかの処理で変換するよりも既存フォーマット(列情報)を元に CUR 2.0 フォーマットで出力する方法が負担が少ないとされています。
そんなレガシー CUR から CUR 2.0 への移行を支援するツールセットが AWS から提供されているため、試してみたいと思います。(今回 hard_coded_query_converter.py は検証対象外)
- query-converter - SQLクエリをCUR 2.0形式に変換するGen AIアシスタント。変換されたクエリを実行するには、 Athena統合による標準のCUR 2.0エクスポートが必要です。
- migrate-cur1 - レガシーCUR形式と互換性のあるCUR 2.0エクスポートを作成するためのスクリプトです。サードパーティ製ツールとの既存の統合があり、まだCUR 2.0にアップデートされていない場合にご利用ください。
- hard_coded_query_converter.py - CURレガシークエリをAIを使用しないCUR 2.0に変換するツールです。主に、制限事項によりBedrockをご利用いただけないお客様向けです。
migrate-cur1
最初にレガシー CUR でのフォーマット(列情報)を元に CUR 2.0 フォーマットでの出力設定を作成するツールである migrate-cur1 を下記リンクを参考に進めていきます。
前提条件
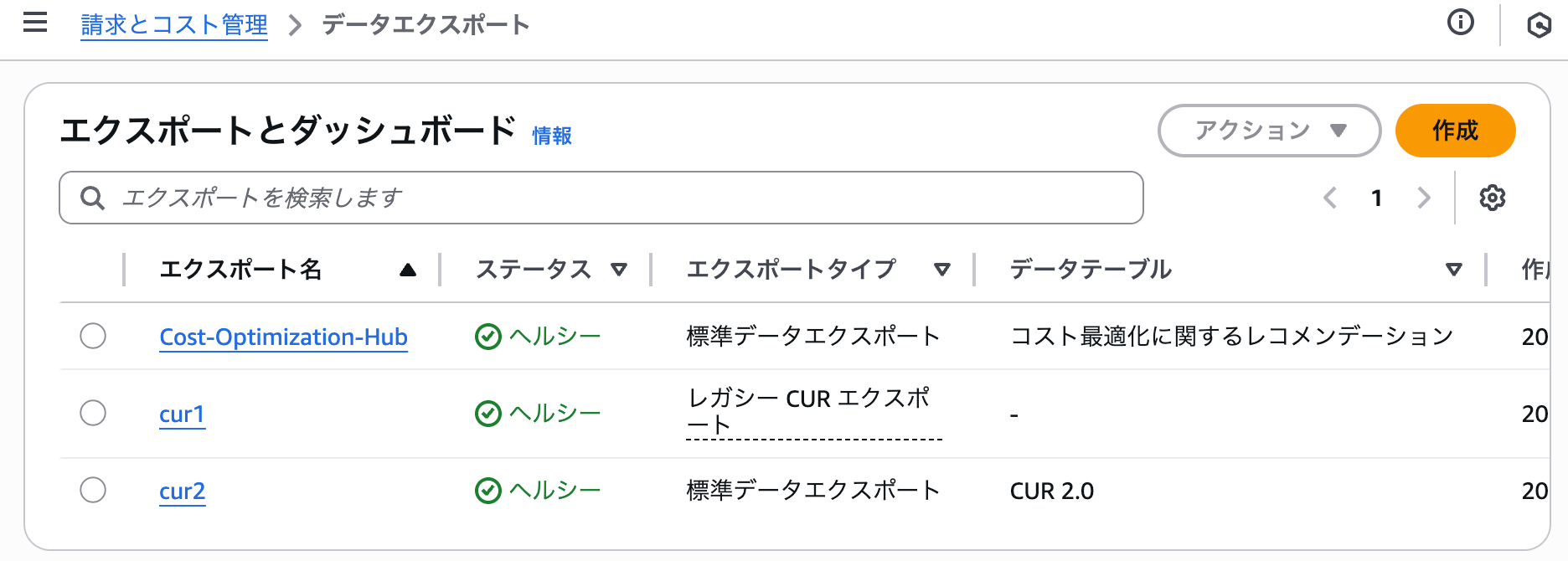
- データエクスポート機能を利用した レガシー CUR 出力設定がある
検証
- マネジメントコンソールへログイン後にバージニア北部リージョンへ変更
※ migrate-cur1 は任意のリージョンで問題ありませんが、この後の query-converter のデフォルトがバージニア北部リージョンのため変更しています
-
CloudShell を起動
-
ツールをインストール
~ $ pip3 install -U git+https://github.com/aws-samples/aws-data-exports-setup
Defaulting to user installation because normal site-packages is not writeable
Collecting git+https://github.com/aws-samples/aws-data-exports-setup
〜 中略 〜
Successfully built convertur
Installing collected packages: python-dateutil, wcwidth, tzdata, prompt-toolkit, numpy, questionary, pyarrow, pandas, convertur
Successfully installed convertur-0.1.3 numpy-2.0.2 pandas-2.3.1 prompt-toolkit-3.0.51 pyarrow-21.0.0 python-dateutil-2.9.0.post0 questionary-2.1.0 tzdata-2025.2 wcwidth-0.2.13
~ $
migrate-cur1コマンドから対話的に実行
※ Step 1 でベースとなるレガシー CUR のエクスポート名を指定します。前提条件の画像の通り、検証環境では cur1 という名称のレガシー CUR 向けのエクスポート設定が存在しています。
~ $ migrate-cur1
Step 1/5: choosing legacy CUR report
? select cur1
Step 2/5: Pulling the latest parquet file
Step 3/5: Generating SQL
SELECT
identity_line_item_id
, identity_time_interval
, bill_invoice_id
〜 中略 〜
, bill_payer_account_name
, line_item_usage_account_name
FROM COST_AND_USAGE_REPORT
Step 4/5: Updating bucket policy
Bucket Policy is already set
Step 5/5: Creating CUR 2.0
CUR 2.0 created
Done. CUR will be populated in 24 hours.
- データエクスポートに エクスポート名「cur1-2」が追加
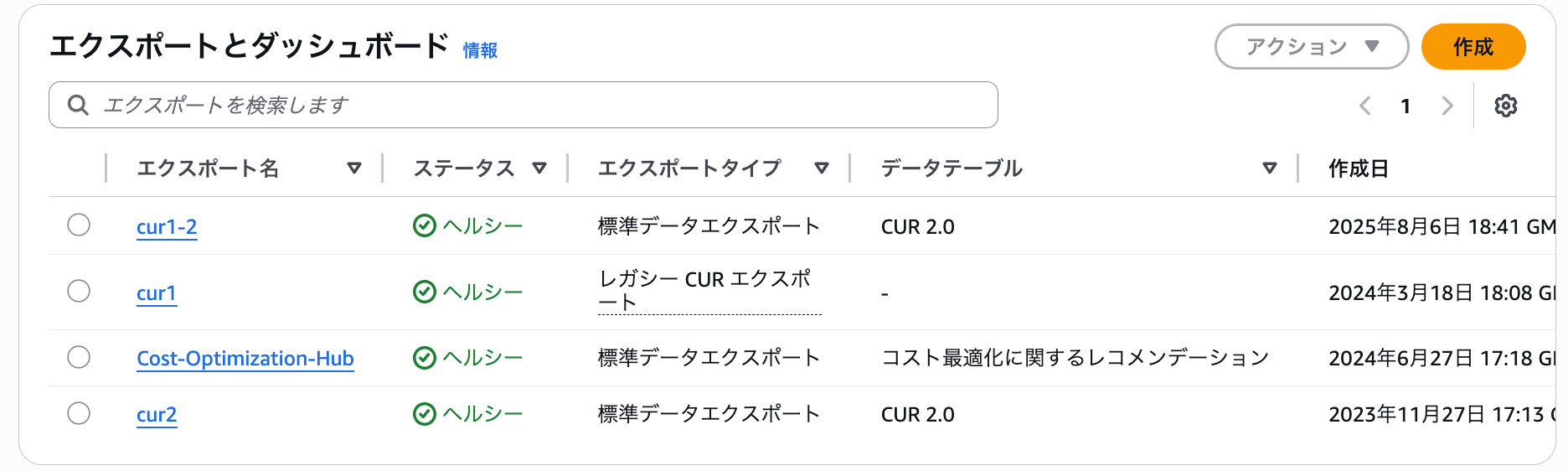
- (24時間以内に)指定したレガシー CUR と同じバケットに CUR 2.0 のデータが出力
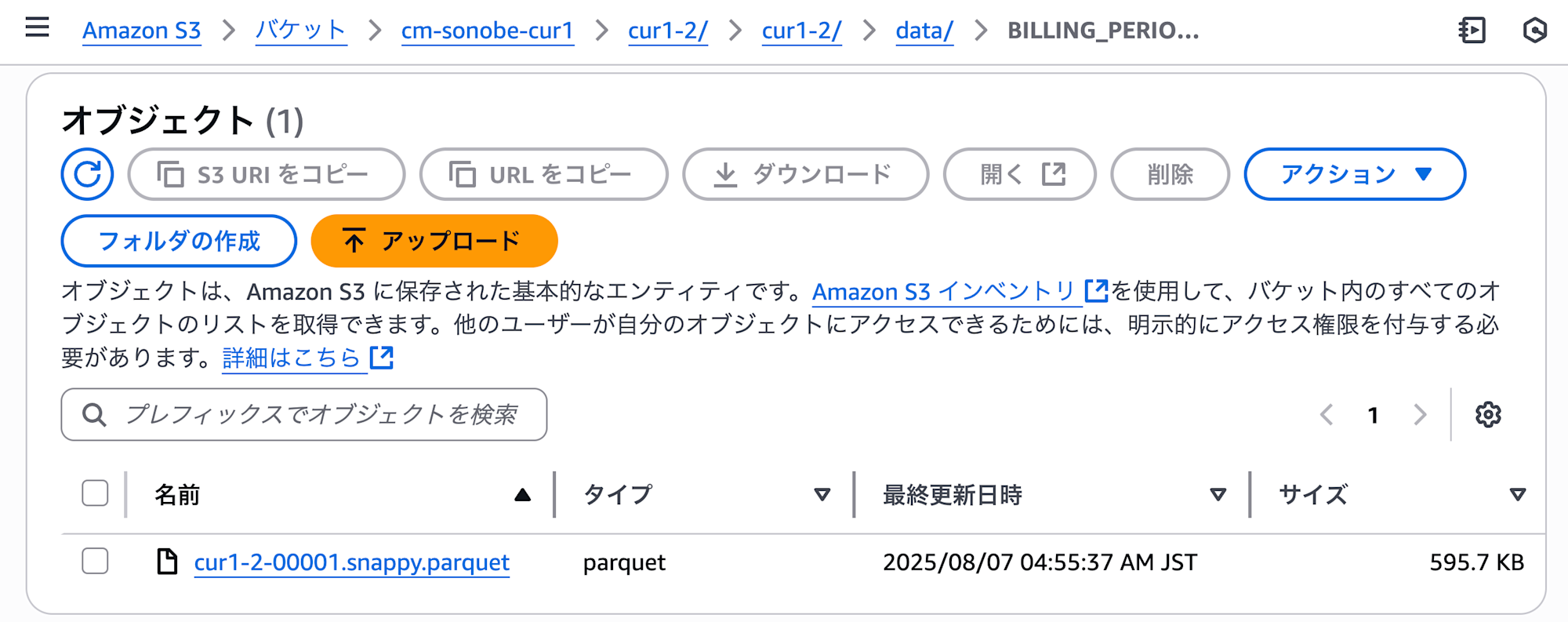
CUR 2.0 としてのパスにデータが出力されました。
query-converter
次は、ダッシュボードや作業用クエリなど既存アセットで利用している CUR に対する SQL クエリをレガシー CUR から CUR 2.0 へ変換する query-converter を下記リンクを参考に進めていきます。
クエリ変換の確認には、レガシー CUR と CUR 2.0 が併記されている以下のクエリライブラリを用いて確認します。
- https://catalog.workshops.aws/well-architected-cost-optimization/en-US/2-expenditure-and-usage-awareness/70-cost-and-usage-analysis-sql/cur-2-0-analysis
- https://catalog.workshops.aws/cur-query-library/en-US
前提条件
- Amazon Bedrock(anthropic.claude-3-sonnet-20240229-v1:0)が利用可能
デフォルトだと /home/cloudshell-user/.local/lib/python3.9/site-packages/convertur にインストールされるため、このディレクトリにある query_converter.py ファイルに記載されたモデルIDを変更することで他のモデルも利用可能でした。
検証
-
マネジメントコンソールへログイン後にバージニア北部リージョンへ変更
-
CloudShell を起動
-
ツールをインストール
migrate-cur1 の実施時にインストールしている場合はこの手順は不要です。query-converter のみ実施する場合は同じ手順でインストールしてください。
準備完了です。早速、変換してみましょう。
query-converterコマンドから対話的に実行
~ $ query-converter
Enter CUR1 SQL query or GitHub URL then Press Escape + Enter (r=retry, q=quit):
>
- レガシー CUR 向け SQL クエリを貼り付けて ESC + Enter で実行
一つ目はこちらに記載のある Legacy CUR クエリで確認してみましょう。
Enter CUR1 SQL query or GitHub URL then Press Escape + Enter (r=retry, q=quit):
>SELECT
bill_payer_account_id,
product_product_name,
line_item_usage_type,
line_item_line_item_description,
resource_tags_user_cost_center,
ROUND(SUM(line_item_unblended_cost),2) AS cost
FROM
${table_name}
WHERE
length(resource_tags_user_cost_center) >0
GROUP BY
resource_tags_user_cost_center,
bill_payer_account_id,
product_product_name,
line_item_usage_type,
line_item_line_item_description
ORDER BY
cost DESC
LIMIT 20
Processing..
Bedrock assistant:
SELECT
bill_payer_account_id,
product['product_name'],
line_item_usage_type,
line_item_line_item_description,
resource_tags['user_cost_center'],
ROUND(SUM(line_item_unblended_cost),2) AS cost
FROM
${table_name}
WHERE
length(resource_tags['user_cost_center']) >0
GROUP BY
resource_tags['user_cost_center'],
bill_payer_account_id,
product['product_name'],
line_item_usage_type,
line_item_line_item_description
ORDER BY
cost DESC
LIMIT 20
Explanation: The main differences in the transformed query are:
1. The resource_tags fields have been changed from the format resource_tags_XXX to resource_tags['XXX']. Specifically, resource_tags_user_cost_center became resource_tags['user_cost_center'].
2. The product_product_name field has been changed to product['product_name'] to match the new table format.
3. These changes were applied in the SELECT, WHERE, and GROUP BY clauses.
4. No changes were made to the table name, date filter, or overall query structure as per the instructions.
5. The year and month fields were not present in this query, so no changes were required for those.
先ほどのクエリを対比する CUR 2.0 クエリと比較します。
SELECT
bill_payer_account_id,
bill_payer_account_name,
product['product_name'],
line_item_usage_type,
line_item_line_item_description,
resource_tags['cost_center'],
ROUND(SUM(line_item_unblended_cost), 2) AS cost
FROM
${table_name}
WHERE
resource_tags['cost_center'] IS NOT NULL
GROUP BY
bill_payer_account_id,
bill_payer_account_name,
product['product_name'],
line_item_usage_type,
line_item_line_item_description,
resource_tags['cost_center']
ORDER BY
cost DESC
LIMIT 20;
良いですね。bill_payer_account_name のような追加された項目は付与されていませんが、product や resource_tags といった既存クエリで変換が必要な部分での対応がされています。Explanation(説明)が あり、処理の内容が確認できるところも良いですね。
ではもう一つ、下記を用いて変換してみます。
Enter CUR1 SQL query or GitHub URL then Press Escape + Enter (r=retry, q=quit):
>SELECT
bill_payer_account_id,
line_item_usage_account_id,
SPLIT_PART(line_item_resource_id, ':', 6) AS split_line_item_resource_id,
product_region,
pricing_unit,
sum_line_item_usage_amount,
CAST(cost_per_resource AS DECIMAL(16, 8)) AS sum_line_item_unblended_cost
FROM
(
SELECT
line_item_resource_id,
product_region,
pricing_unit,
line_item_usage_account_id,
bill_payer_account_id,
SUM(line_item_usage_amount) AS sum_line_item_usage_amount,
SUM(SUM(line_item_unblended_cost)) OVER (PARTITION BY line_item_resource_id) AS cost_per_resource,
SUM(SUM(line_item_usage_amount)) OVER (PARTITION BY line_item_resource_id, pricing_unit) AS usage_per_resource_and_pricing_unit,
COUNT(pricing_unit) OVER (PARTITION BY line_item_resource_id) AS pricing_unit_per_resource
FROM
${table_name}
WHERE
line_item_product_code = 'AmazonEC2'
AND line_item_usage_type LIKE '%Nat%'
-- get previous month
AND month = CAST(month(current_timestamp + -1 * INTERVAL '1' MONTH) AS VARCHAR)
-- get year for previous month
AND year = CAST(year(current_timestamp + -1 * INTERVAL '1' MONTH) AS VARCHAR)
AND line_item_line_item_type = 'Usage'
GROUP BY
line_item_resource_id,
product_region,
pricing_unit,
line_item_usage_account_id,
bill_payer_account_id
)
WHERE
-- filter only resources which ran more than half month (336 hrs)
usage_per_resource_and_pricing_unit > 336
AND pricing_unit_per_resource = 1
ORDER BY
cost_per_resource DESC;
Processing..
Bedrock assistant:
Here's the transformed query for Table2:
SELECT
bill_payer_account_id,
line_item_usage_account_id,
SPLIT_PART(line_item_resource_id, ':', 6) AS split_line_item_resource_id,
product['region'],
pricing_unit,
sum_line_item_usage_amount,
CAST(cost_per_resource AS DECIMAL(16, 8)) AS sum_line_item_unblended_cost
FROM
(
SELECT
line_item_resource_id,
product['region'],
pricing_unit,
line_item_usage_account_id,
bill_payer_account_id,
SUM(line_item_usage_amount) AS sum_line_item_usage_amount,
SUM(SUM(line_item_unblended_cost)) OVER (PARTITION BY line_item_resource_id) AS cost_per_resource,
SUM(SUM(line_item_usage_amount)) OVER (PARTITION BY line_item_resource_id, pricing_unit) AS usage_per_resource_and_pricing_unit,
COUNT(pricing_unit) OVER (PARTITION BY line_item_resource_id) AS pricing_unit_per_resource
FROM
${table_name}
WHERE
line_item_product_code = 'AmazonEC2'
AND line_item_usage_type LIKE '%Nat%'
-- get previous month
AND split_part("billing_period", '-', 2) = CAST(month(current_timestamp + -1 * INTERVAL '1' MONTH) AS VARCHAR)
-- get year for previous month
AND split_part("billing_period", '-', 1) = CAST(year(current_timestamp + -1 * INTERVAL '1' MONTH) AS VARCHAR)
AND line_item_line_item_type = 'Usage'
GROUP BY
line_item_resource_id,
product['region'],
pricing_unit,
line_item_usage_account_id,
bill_payer_account_id
)
WHERE
-- filter only resources which ran more than half month (336 hrs)
usage_per_resource_and_pricing_unit > 336
AND pricing_unit_per_resource = 1
ORDER BY
cost_per_resource DESC;
Explanation:
1. Changed `product_region` to `product['region']` in both the outer SELECT and inner subquery.
2. Replaced `year` and `month` conditions in the WHERE clause with `split_part("billing_period", '-', 1)` and `split_part("billing_period", '-', 2)` respectively.
3. All other fields remained the same as they were already in the correct format for Table2.
4. The overall structure and logic of the query remained unchanged.
先ほどのクエリを対比する CUR 2.0 クエリと比較します。
SELECT
bill_payer_account_id,
line_item_usage_account_id,
SPLIT_PART(line_item_resource_id, ':', 6) AS split_line_item_resource_id,
product_region_code,
pricing_unit,
sum_line_item_usage_amount,
CAST(cost_per_resource AS DECIMAL(16, 8)) AS sum_line_item_unblended_cost
FROM
(
SELECT
line_item_resource_id,
product_region_code,
pricing_unit,
line_item_usage_account_id,
bill_payer_account_id,
SUM(line_item_usage_amount) AS sum_line_item_usage_amount,
SUM(SUM(line_item_unblended_cost)) OVER (PARTITION BY line_item_resource_id) AS cost_per_resource,
SUM(SUM(line_item_usage_amount)) OVER (PARTITION BY line_item_resource_id, pricing_unit) AS usage_per_resource_and_pricing_unit,
COUNT(pricing_unit) OVER (PARTITION BY line_item_resource_id) AS pricing_unit_per_resource
FROM
${table_name}
WHERE
line_item_product_code = 'AmazonEC2'
AND line_item_usage_type LIKE '%Nat%'
-- get previous month
AND SPLIT(billing_period, '-') [ 2 ] = CAST(month(current_timestamp + -1 * INTERVAL '1' MONTH) AS VARCHAR)
-- get year for previous month
AND SPLIT(billing_period, '-') [ 1 ] = CAST(year(current_timestamp + -1 * INTERVAL '1' MONTH) AS VARCHAR)
AND line_item_line_item_type = 'Usage'
GROUP BY
line_item_resource_id,
product_region_code,
pricing_unit,
line_item_usage_account_id,
bill_payer_account_id
)
WHERE
-- filter only resources which ran more than half month (336 hrs)
usage_per_resource_and_pricing_unit > 336
AND pricing_unit_per_resource = 1
ORDER BY
cost_per_resource DESC;
year や month が billing_period を利用した内容へ変換されていますね。
サンプルクエリでは product_region を product_region_code に置き換えていますがここは変換の範疇を超えているかなと思うので product['region'] への変換でも十分な結果ではないかと個人的には思います。
まとめ
今回、レガシー CUR から CUR 2.0 利用へ移行を支援するツールを検証しました。容易に利用でき、結果も変更点を理解した対応がされており有効ではないかと思います。
query-converter に関しては、あくまで生成 AI や対比表をベースに変換しているため、必ずしも正しい結果が出るとは限らないという点に注意が必要です。検証をする中で期待する結果が得られないケースもありました。とはいえ全てのクエリを手作業で修正するよりは、このようなツールで大まかに実施することや一度変換してみて検証することで更新の規模感を把握するなどのユースケースで有効なツールではないかと思います。









