
Web API サーバ負荷試験のすすめ方 – 観点を整理、負荷を試算、対象を選定
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
負荷試験は大事です。リリーススケジュールに押されて後回しになってしまいがちですが、ここで思わぬアーキテクチャ上の見落としや、不適切な設定項目を発見できる場合があります。いずれも、リリース後の発見だと致命傷になってしまいますね。本記事では、モバイルアプリから利用されるWeb APIサーバを構築した状況を想定し、Web APIサーバに対して負荷試験を行う段取りの一例を紹介します。「すすめ方」を重視しており、負荷試験ツールの細かい設定といった話は含まれていませんのでご注意ください。
負荷試験対象システム
以下のようなJVMのモバイルバックエンドシステムを例にとって、負荷試験を実施することを考えてみましょう。イメージとしてはSNSのようなシステムです。ユーザの投稿データを受け取ってDBへ書き込んだり、保存された投稿データを読みだしてモバイルアプリへ返します。また、イベントを管理する別のシステムと連携しており、イベントの登録や削除も可能です。
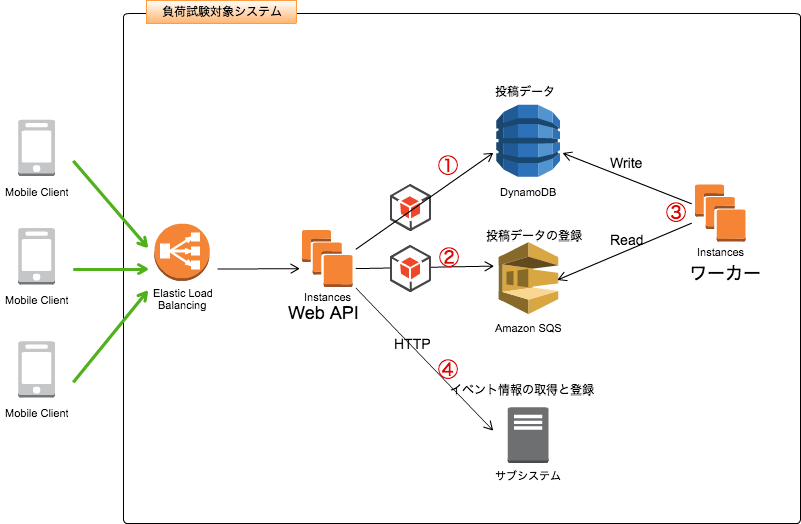
- ① 投稿データの読み出し: DynamoDBに保存されているデータを読みだすタイプのAPIです。AWS SDK(HTTPクライアント)を使います。
- ② 投稿データの書き込みキューへ登録: 書き込み処理はリアルタイム性よりも確実性を重視する考えのもと、一度キューへ登録することとします。
- ③ キューへ登録された投稿データの書き込み: ワーカーを実装して一定間隔でキューから投稿データを取り出しDynamoDBへ書き込みを行います。
- ④イベントの登録・削除: サブシステムとしてすでに構築されているサーバへリクエストします。HTTPを使ってアクセスします。
負荷試験実施にあたり、やっていくこと
さて、負荷試験を実行可能な状態へ持って行くには、いろいろと決めなくてはなりません。「どの程度の負荷をかけるか」「どれに負荷をかけるか」「どうやってかけるか」といったところでしょうか。これらを決めていく段取りとして、以下のようなすすめ方をとってみます。上から順にやります。
| やること | きめること(アウトプット) |
|---|---|
| 負荷試験対策ミーティング | 負荷試験の目的 負荷試験の観点 負荷試験の対象 |
| 負荷を試算する | ピーク時の負荷の試算値 通常時の負荷の試算値 |
| 試験実施方法を決める | 利用ツール 実施方法 結果確認方法 |
| 負荷試験実施 | 試験結果 |
負荷試験対策ミーティング
ここでは、チームメンバーを集めて、システム要件の再確認と、バックエンドのアーキテクチャを再確認をまず行います。すなわち、「求められているもの=要件」と、「提供できるもの=アーキテクチャ」の確認です。ここの認識が揃っていないと、的はずれな負荷試験を実施してしまうことになりかねません。立場や役割にかかわらず、サービス全体として考えるべきです。
負荷試験の目的
負荷試験を行うことによって、何を示したいのか決めます。今回は、以下の目的を定めます。
- サービスリリース後、想定されるピーク時のリクエストを受けた場合でも、問題なく稼働を続けられることを確認する
- システムのスループット限界値を確認する
負荷試験の観点
たいていのWebシステムの場合、昼夜を問わず稼働し続けるものとなるでしょう。今回例にとったシステムも24時間365日、リクエストを受け付けるものとします。この場合、観点はある程度共通化できます。目的と合わせて以下のような観点がありそうです。
- 時間あたりのリクエストがピーク値で、それが短い時間継続する場合のテスト
- 時間あたりのリクエストが平均的で、それが長い時間継続する場合のテスト
- 時間あたりのリクエストを徐々に大きくしていくテスト
1. 瞬間的なピーク値のテスト
リリース直後の広告やキャンペーン、テレビCMといった効果により瞬間的に負荷が増大するケースのテストです。理論上、モバイルアプリユーザすべてが一挙にアクセスする可能性があります。このとき、すべてのリクエストが正しく、かつ現実的な時間内で捌けることを確認します。また、著しく消費しているリソース(CPU、ネットワークなど)がないか確認します。
2. 長時間の平均値のテスト
通常稼働の想定です。すべてのリクエストが正しく処理できていることはもちろん、消費量が悪化しているリソースがないか時系列で追ってチェックします。具体的にはメモリリークが起きていないかなどを見ます。
3. 負荷を大きくしていくテスト
仮に、想定ピーク値を超えて負荷が増大していった場合、どの時点で性能が頭打ちになるのか、その際にボトルネックとなる箇所はどこかを確認しておきます。これをやっておくと、システムとして保証できる最大の負荷が把握できますし、リリース後サービスが成長を続けて負荷が増大していった場合にどの時点で対策を打たねばならないかわかるのでやっておいて損はありません。
負荷試験の対象
どのAPIに対して負荷をかけるか決めます。今回のように既存のサブシステムを利用する場合、担当者に負荷をかけてよいかどうか確認しましょう。「イベント管理システムは初回リリース時に負荷テストを実施しているので今回は不要」だとして、それ以外に対して負荷をかけることにしました。今回の負荷試験によって以下の挙動がわかります。
- 負荷がかかった場合の投稿読み込み処理の挙動(①)
- 負荷がかかった場合のキュー書き込み処理の挙動(②)
- キューに大量のタスクがある場合のワーカーの挙動(③)
これで、決めるべきことがすべてそろいました。次のステップへ進みます。
負荷を試算する
上述した「ピーク値」「平均値」を決めるステップです。ここは、開発者だけで決めるよりも、PM、PL、もっというと対象のドメインに詳しい方を巻き込んで値を出してみましょう。今回の場合、連携しているイベント管理システムのユーザ数がわかっていると仮定して、そこから登録見込みのユーザ数を割り出し、ピーク値と平均値を試算してみることとします。
| イベントシステムの指標 | 値 |
|---|---|
| 実績会員登録数 | 1,500,000 |
同等の会員数が登録されるものと仮定します。
| SNSシステムの指標 | 値 |
|---|---|
| 仮想会員登録数 | 1,500,000 |
この値をベースに、リクエスト毎秒を算出します。平均値は、「一日一回、すべての会員がモバイルアプリからリクエストを送る程度」、ピーク値は「一時間ですべての会員がモバイルアプリからリクエストを送る」といった状況設定をします。これを表にして毎秒まで計算すると以下のようになります。
| SNSシステムの指標 | 毎日 | 毎時 | 毎分 | 毎秒 |
|---|---|---|---|---|
| 仮想リクエスト数(通常時) | 1,500,000 | 125,000 | 2,083 | 35 |
| 仮想リクエスト数(ピーク時) | 36,000,000 | 1,500,000 | 25,000 | 417 |
この試算値から、
- 通常時の負荷の試算値: 50 req/s × 12時間
- ピーク時の負荷の試算値: 500 req/s × 10分間
とします。負荷の継続時間は仮置きです。一度これでやってみて、例えば消費量が増加傾向にあるリソースがあり、より長時間負荷を掛ける必要があると判断した場合、再度継続時間を伸ばして実行します。
... コメントを眺めていて少し気になったので追記します。確かに、負荷試験はここの試算が一番むずかしいと思います。いわゆる「定石」や「正解」がない部分です。負荷を試算する方法はいくつかあると思います。
- 今回のように、見込み会員数からの試算
- 類似サービスの負荷から試算
- 先に負荷を上げていく試験をやって限界値を把握しておき、そこから試算値を逆算して後付する(全然アリだと思ってます)
一度サービスをリリースしてしまえば、会員数の伸びや実際の負荷を見ることができるので、試算はしやすくなるでしょう。リリース前はそういった情報がないため、私は、あまり正確な試算値を出すことにこだわらなくともよいかと考えています。だからこそ、「開発者で決めるよりも、関係者を巻き込む」のが良いです。作業者だけでなくチーム全体として決めた試算値とするわけです。正確な値よりも、みんなが納得値をだすことができればOKです。
試験実施方法を決める
利用ツール
負荷試験実施にあたってはいろいろな方法がありますが、目的の試験が実施できれば何でも良いです。老舗のApache JMeterを使うことにします。手段が目的にならないよう注意しましょう。
実施方法
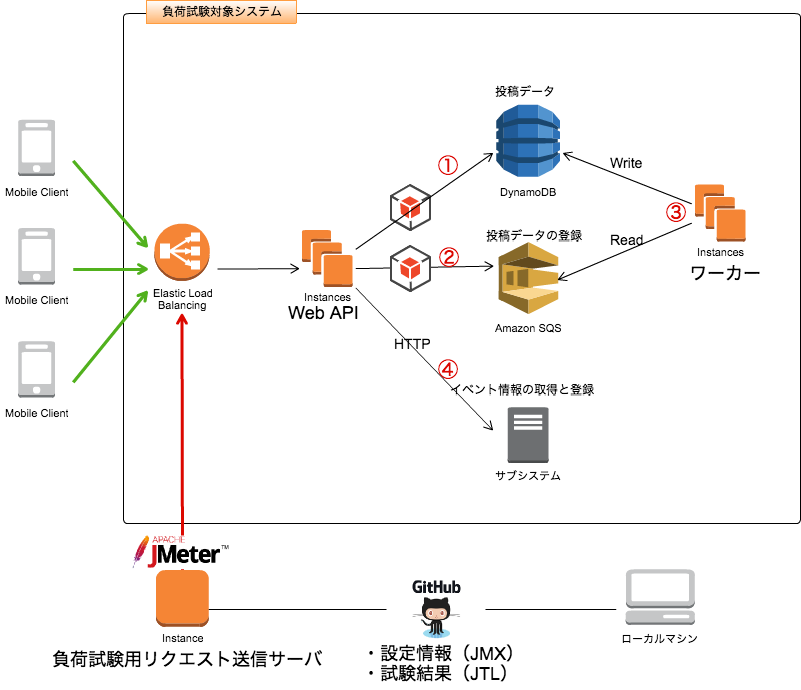
- JMeterの設定は手元で行います。弊社荒井のブログを参考にパラメータを作成しました。負荷をかける毎秒のスループットが決まっていれば計算可能です。
- 負荷用のリクエストを送るサーバを1台用意します。GitHub経由で手元のJMeterの設定やテスト結果を同期するようにします。
チェックした結果項目と、その確認方法
以下のようにしました。状況に応じて確認項目を増減してください。
| チェック項目 | 何で見るか |
|---|---|
| ラウンドトリップタイム95%upper | JMeterの出力(CSV)を統計レポートに入力します。 |
| スループット | JMeterの出力(CSV)を統計レポートに入力します。 |
| エラー率 | JMeterの出力(CSV)を統計レポートに入力します。 |
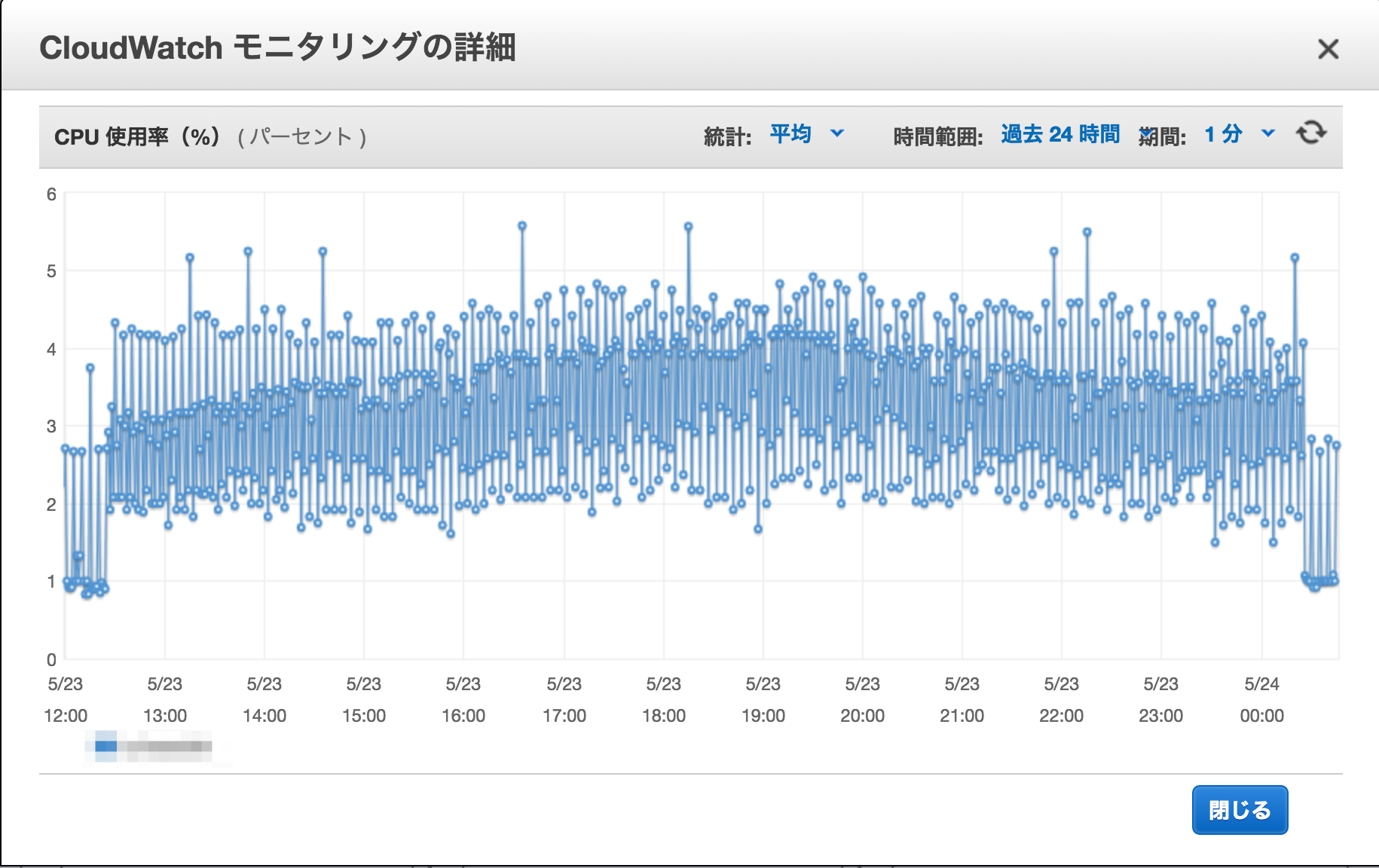
| CPU利用率 | AWSのEC2インスタンスのモニタで確認します。 |
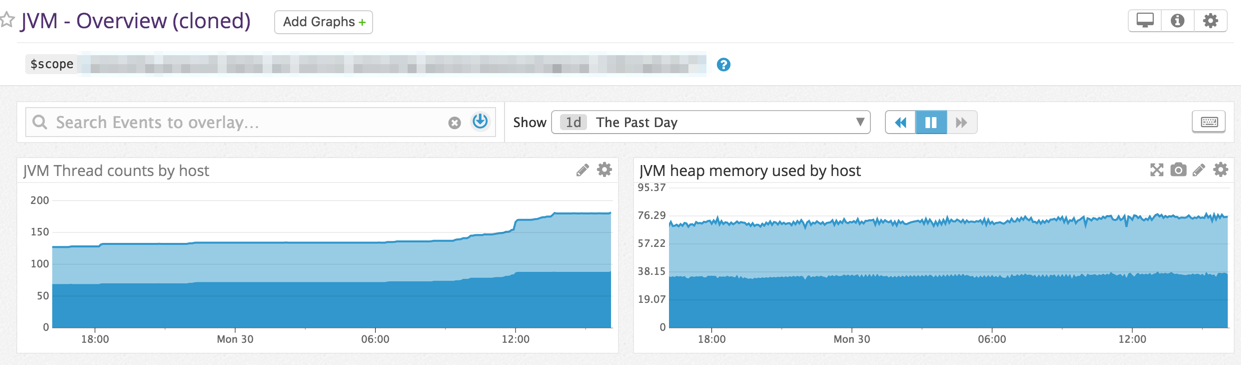
| JVMスレッド数 | APIサーバをDatadogと連携してDatadog上のダッシュボードで確認できるようにします。 |
| JVMヒープ利用量 | APIサーバをDatadogと連携してDatadog上のダッシュボードで確認できるようにします。 |
CPU利用率はAWSのEC2インスタンス管理画面のモニタから見られる利用状況グラフで十分間に合いました。拡大も可能。
JVMの情報はJMXとDatadogの連携で可視化が可能です(参考)。最終的にはEden領域やTenured領域の利用量も見られるようにしておくと、本番運用でも重宝するでしょう。
実行
さて、ここまで決まればあとは実行するだけです。作成したJMeterの設定を負荷試験リクエスト送信用サーバへ同期し、JMeterをコマンドラインで走らせ、結果をまたGitHub経由で手元に持ってきます。CPU利用率やヒープ利用量はあらかじめ定めておいた方法で確認し、テストケースごとの結果が問題ないか確認します。
JMeterのコマンドラインでの実行は簡単です。以下のようにします。
$ path/to/jmeter/bin/jmeter -n -t get-post-stress-test.jmx -l get-post-stress-test.jtl
結果
ピーク時のテストや平均値のテストはいずれも問題ありませんでした(実際はDynamoDBのチューニングを行いましたが、それは後述します)。限界まで負荷を高めるテストは、投稿読み出しAPIにおいて約2000req/sで頭打ちとなりました。
今回のシステムの場合、AWSで構築したインフラはAutoScalingを採用していたため、あらかじめ起動している台数で捌ききれなくなると、EC2インスタンスやELBが自動でスケールします。それでも負荷を上げていくとやがて限界が訪れ、スループットが伸びなくなります。実際、今回の場合はDynamoDBへのアクセス時間が支配的となり、負荷を上げていった時にJVMのスレッドが飽和することで性能の限界を迎えました。これを受け、さらに性能を上げたい場合はJVMのスレッドプールやAutoScalingの最大インスタンス数をチューニングするところですが、今回のシステムは500req/sで十分だったため、手を入れていません。
発生した問題点と、その解決方法
投稿読み出しAPIでDynamoDBのキャパシティオーバー例外が発生
DynamoDBのReadCapacityが不足していました。上限に達し、キャパシティオーバーの例外がDynamoDBのライブラリから返され、API全体が500エラーとなっていました。キャパシティオーバーにならない程度に上限を引き上げることで解決しました。DynamoDBのキャパシティの変遷はAWSコンソールから簡単に確認することができます。
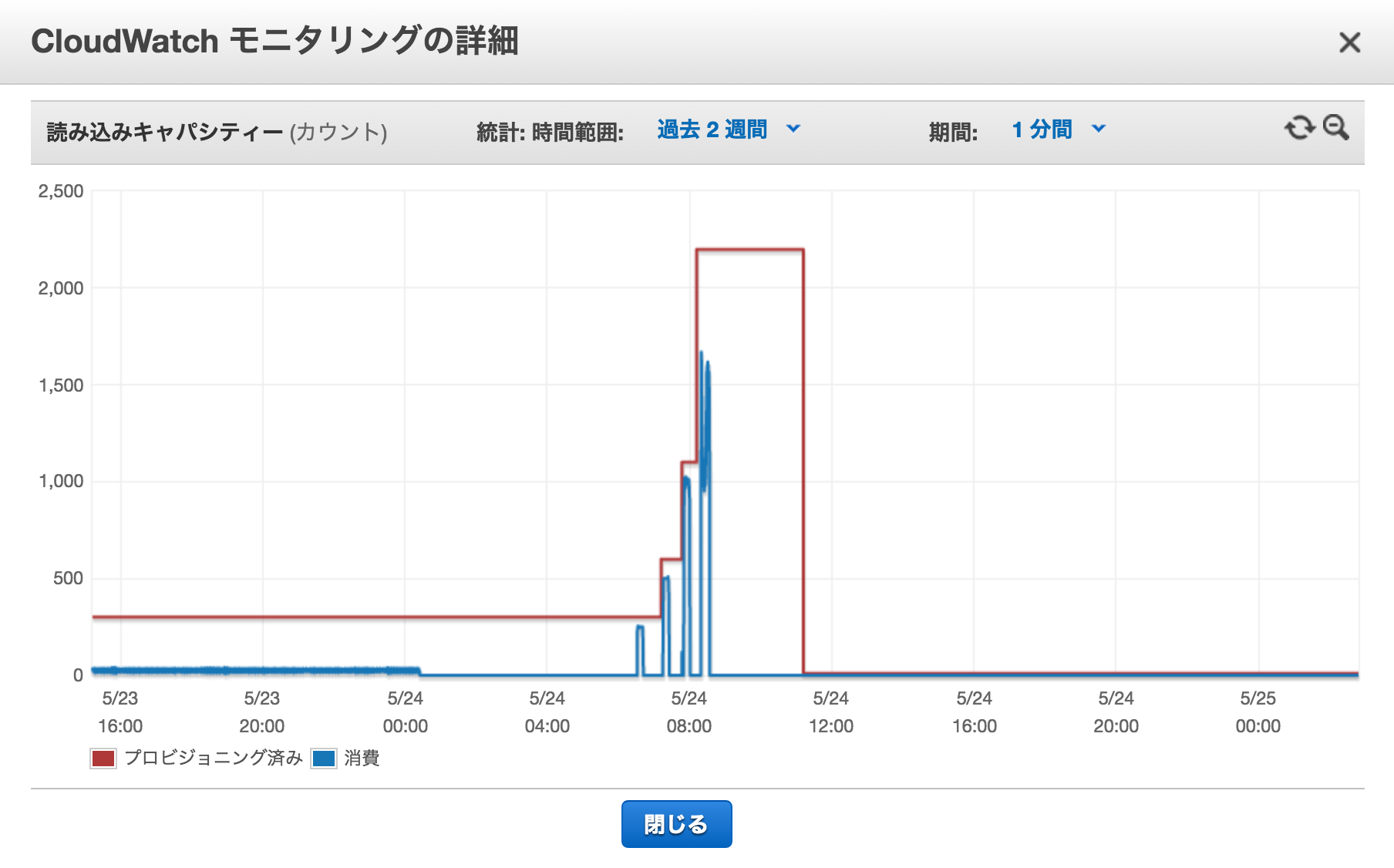
投稿データをDynamoDBへ登録するワーカーでキャパシティオーバーが発生
ワーカーは一定間隔でメッセージを読みだしてDynamoDBへ書き込むためここでキャパシティオーバーが発生することは想定外でした。単純な話で、ワーカーは確かに一定間隔で書き込んでいたのですが、それを行うインスタンスが複数台あったため高確率で例外が発生するというものでした。WriteCapacityを台数分掛け算することで解決しています。
おわりに
負荷試験では、それまでのフェーズのテスト(ユニットテスト、コンポーネントテスト)とはまったく観点が異なるため、思わぬバグや設定の不足を発見できる場合があります。一度実施しておくと、運用に入った場合の増え続けるリクエストに戦々恐々とせずに済みます。
想定する負荷をかけた時に問題ないことが確認できたのがもちろんよかったのですが、個人的にはAWSのAutoScalingが意図どおりに動作することを確認できたのも収穫でした。システムの要件を整理して、アーキテクチャがそれを満たしていることを確認するという視点を忘れなければ、良い負荷試験の設計ができると思います。皆様が負荷試験を実施する際の一助になれば幸いです。










