
Database ใช้อะไรดีระหว่าง Aurora กับ RDS
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
สวัสดีครับผมต้า วันนี้เราจะมาคุยกันในหัวข้อที่ว่า ระหว่าง Amazon Aurora กับ Amazon RDS เราจะใช้ Database อะไรดี โดยจะคุยกันถึงคุณสมบัติต่างๆที่แตกต่างกันของเจ้าตัวนี้ และ Use Case ต่างๆ ที่เกิดขึ้นจริงในการใช้งาน
เนื้อหาในบทความนี้เหมาะสำหรับผู้ที่มีความเข้าใจใน Database หรือ AWS ในระดับนึง เพื่อที่จะสามารถเข้าใจเนื้อหาในบทความนี้ได้อย่างครบถ้วน หากต้องการทำความเข้าใจความแตกต่างระหว่าง Aurora กับ RDS โดยง่ายสามารถดูได้ที่บทความด้านต่อไปนี้ Aurora vs RDS แตกต่างกันอย่างไร ? | DevelopersIO
เป้าหมายของบทความ
เข้าใจความแตกต่างระหว่าง Aurora กับ RDS และสามารถแยกแยะการเลือกใช้งานได้อย่างเหมาะสม
RDS คืออะไร

อาจจะมีใครหลายคนรู้กันแล้วว่า RDS นั้นย่อมาจาก Amazon Relational Database Service ครับ เป็น fully managed service ซึ่งหมายความว่าในส่วนการจัดการ Database ที่ยุ่งยากนั้น AWS จะเป็นคนดูแลให้เองนั่นเองครับ
สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับ RDS นั้นสามารถดูเพิ่มเติมได้ที่ลิ้งค์ด้านล่างนี้ครับ
Aurora คืออะไร

Aurora คือ RDB Service(Relational Database) ที่ AWS สร้างมาเพื่อใช้งานกับ Cloud โดยเฉพาะครับ มีตัวที่มีความเข้ากันได้(compatibility)กับ MySQL และ PostgreSQL โดย AWS รับรองว่าจะเร็วกว่า MySQL ได้มากสุด 5 เท่า และ PostgreSQL 3 เท่า ครับ
สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับ Aurora นั้นสามารถดูเพิ่มเติมได้ที่ลิ้งค์ด้านล่างนี้ครับ
หน้าต่างใน AWS Console ที่ทำให้หลายๆคนสับสน

เมื่อเราเข้าไป Create Database ในหน้าต่าง RDS จะพบว่า ในส่วนของ Engine type จะมีให้เราเลือกระหว่าง ชนิดของ RDS ที่สามารถเลือกได้ และ Aurora ซึ่งทำให้เราเข้าใจผิดได้ว่า Aurora เป็นส่วนนึงของ RDS
ซึ่งความหมายที่แท้จริงของหน้าต่างนี้คือให้เราเลือก Engine ที่มีความเข้ากันได้ของ Aurora(MySQL, PostgreSQL) หรือ Engine ของ RDS นั่นเองครับ
ความแตกต่างระหว่าง RDS กับ Aurora
สำหรับความแตกต่างระหว่าง RDS กับ Aurora เราจะแบ่งออกเป็น 2 หัวข้อคือ architecture และ ฟังก์ชันเฉพาะที่มีแค่ใน Aurora ครับ
ความแตกต่างของ architecture
ในส่วนนี้เราจะพูดถึงข้อที่สำคัญไว้ครับ
RDS
ก่อนอื่น เรามาดูเกี่ยวกับ architecture ของ RDS กันครับ
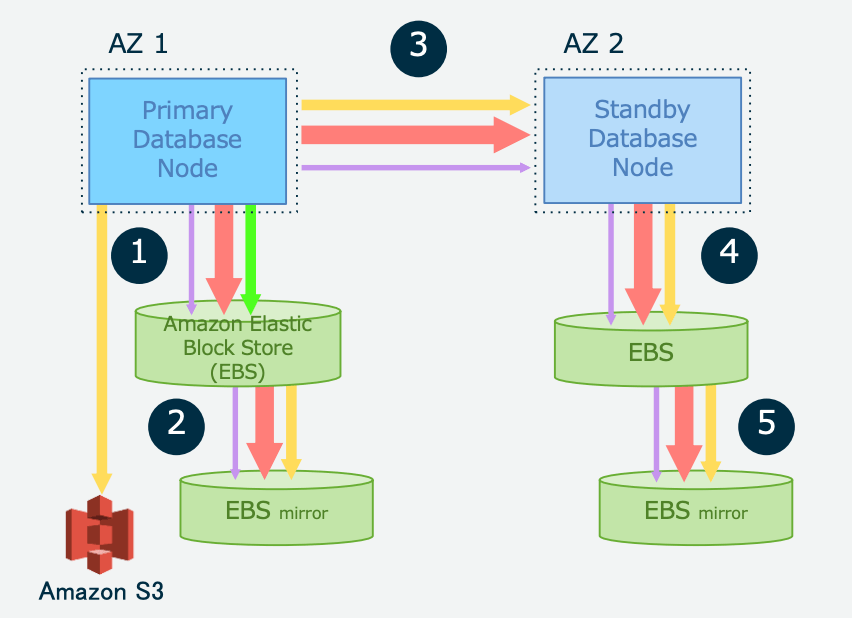
อ้างอิง: 20190828 AWS Black Belt Online Seminar Amazon Aurora with PostgreSQL …(ภาษาญี่ปุ่น)
ในกรณีของ RDS Architecture ให้คิดว่าคล้ายกับการ Install MySQL หรือ PostgreSQL ใน EC2 ครับ ไม่มีข้อแตกต่างกันมาก สี่เหลี่ยมสีฟ้าด้านบนคือ DB Instance ที่เป็น Computer Resource คล้ายๆกับ EC2 Instance ครับ และเชื่อมต่อกับ EBS ที่ทำหน้าที่เป็น Storage โดยมี EBS อยู่ 2 ตัว ทำการ Mirroring(ก๊อบปี้ตัวเอง) เพื่อเพิ่มความทนทานในการใช้งาน
ในกรณีที่สร้าง Replica จะมี Insntance + EBS 2 ตัว ถูกสร้างขึ้นเหมือนภาพด้านบน
Replica จะอัพเดท Data ของ Storage ของตัวเองด้วย Log ที่เชื่อมต่ออยู่กับ Primary และทำการ Sync กับ Primary ครับ
Aurora
แผนภาพด้านล่างจะแสดงถึงระบบของ Aurora DB Cluster ครับ Aurora DB Cluster คือ Component โดยรวทที่จะถูกสร้างขึ้นในตอนสร้าง Aurora Database ครับ
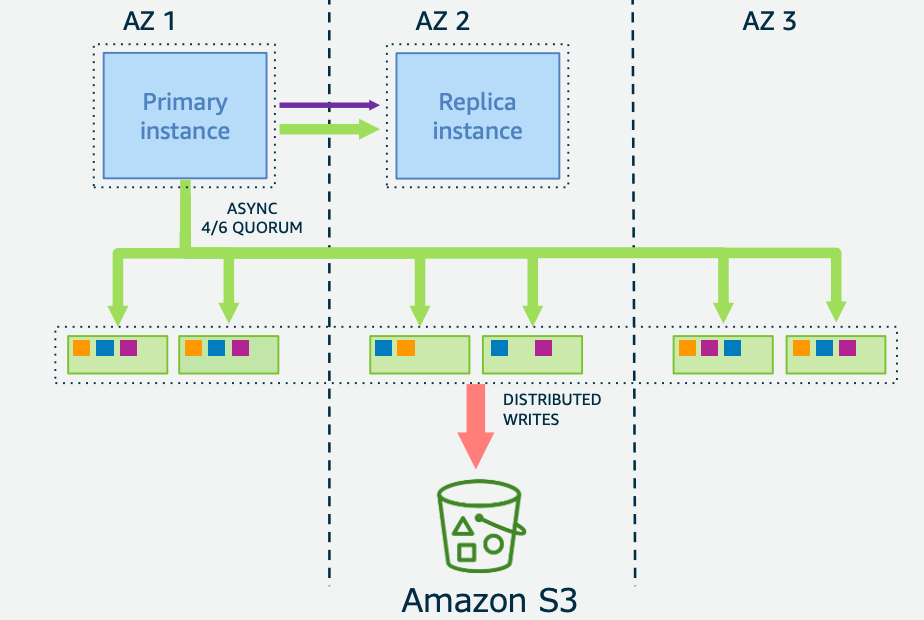
อ้างอิง: 20190828 AWS Black Belt Online Seminar Amazon Aurora with PostgreSQL …(ภาษาญี่ปุ่น)
ขอแตกต่างที่เห็นได้ชัดคือ มีการแบ่ง insntance กับ storage ออกจากกันครับ โดยที่ 1 AZ จะมีการก็อบปี้ไว้ทั้งหมด 2 กล่อง และทำแบบนี้ทั้ง 3 AZ ซึ่งหมายความว่า Storage จะถูกก๊อปปี้ 2✖︎3=6 ที่ นั่นเองครับ โดยทั้ง 6 Storage volume นี้จะทำการสื่อสารกัน หากข้อมูลใน Storage เกิดสูญหาจะทำการซ่อมเซมด้วยตัวมันเองครับ
คุณผู้อ่านอาจจะคิดว่า หาก instance ทำการใช้ storage ทั้งหมด ซึ่งต้องอ่านและเขียน ตั้ง 6 ที่ อาจจะทำให้การประมวลช้าลง แต่การเชื่อมต่อไปยัง 6 ที่นี้นั้นเป็นแบบขนาน(parallel access) ทำให้ไม่ช้าลงครับ
นอกจากนี้ เราไม่จำเป็นต้องรอผลลัพท์จากทุก Storage ก็สามารประมวลผลต่อได้ เพื่อป้องกันการเกิดปัญหาเวลา Client ทำการ Request เข้ามา ในสถานการณ์ที่ Storage เกิดปัญหาเชื่อมต่อ Internet หรือ Disk พัง
และถ้าเกิดปัญหาขึ้นจริงๆ Storage ก็จะทำการพื้นฟูตัวเองตามที่เขียนไว้ด้านบน
ฟังก์ชันที่มีแค่ Aurora
ในหัวข้อนี้เราจะมาแนะนำฟังก์ชันที่น่าสนใจที่มีแค่ Aurora มาแนะนำให้รู้จักกันครับ
Protection Groups
ในหัวข้อที่แล้ว Aurora จะทำการ Copy 6 อย่างไว้ใน 3 AZ โดยถ้าให้ลงรายละเอียดลงไปอีกคือโครงสร้าง Storage จะถูกแบ่งเป็น Protection Group ที่เป็น 10 GB

อ้างอิง: Introducing the Aurora Storage Engine | AWS Database Blog
ยกตัวอย่างเช่น ตามภาพด้านบน ข้อมูลด้านซ้ายจะมี 10 GB ครอบไว้ 3 AZ ถูกสร้างไว้ 6 ก๊อปปี้ ส่วนด้านขวาก็คือ 10 GB ครอบไว้ 3 AZ ถูกสร้างไว้ 6 ก๊อปปี้เหมือนกัน รวมกันได้ 20 GB
ซึ่งโครงสร้างแบบนี้ทำให้เราสามารถเชื่อมต่อแบบขนาน(parallel access)ไปยังแต่ละ Protection Group ได้นั่นเอง

อ้างอิง: 20190828 AWS Black Belt Online Seminar Amazon Aurora with PostgreSQL …(ภาษาญี่ปุ่น)
โดยแผนภาพนี้จะแสดงให้เห็นถึงการประมวลผล Recovery ของ RDS และ Aurora โดยฝั่งซ้ายจะเป็นของ RDS ครับ หากเกิด Crash ในจุด T0 จะทำการ Recovery จากรอย log ของ Snapshot Data อันล่าสุด โดยถ้าปริมาณ log มีเยอะก็จะใช้เวลาในการ Recovery นาน ถึงจะเสร็จ
แต่หากเป็นกรณีของ Aurora ล่ะก็ Snapshot จะมีการเก็บ log แบบ Protection Group ขนานไว้ ซึ่งแต่ละตัวก็มีขนาดมากสุดแค่ 10GB ทำให้ไม่เสียเวลานานในการประมวลผล โดยรูปด้านบนแสดงให้เห็นในตอนที่ Recovery ซึ่งสามารถนำไปคิดแบบเดียวกันได้กับการ Backup และ Restore ได้ด้วย
BackTrack
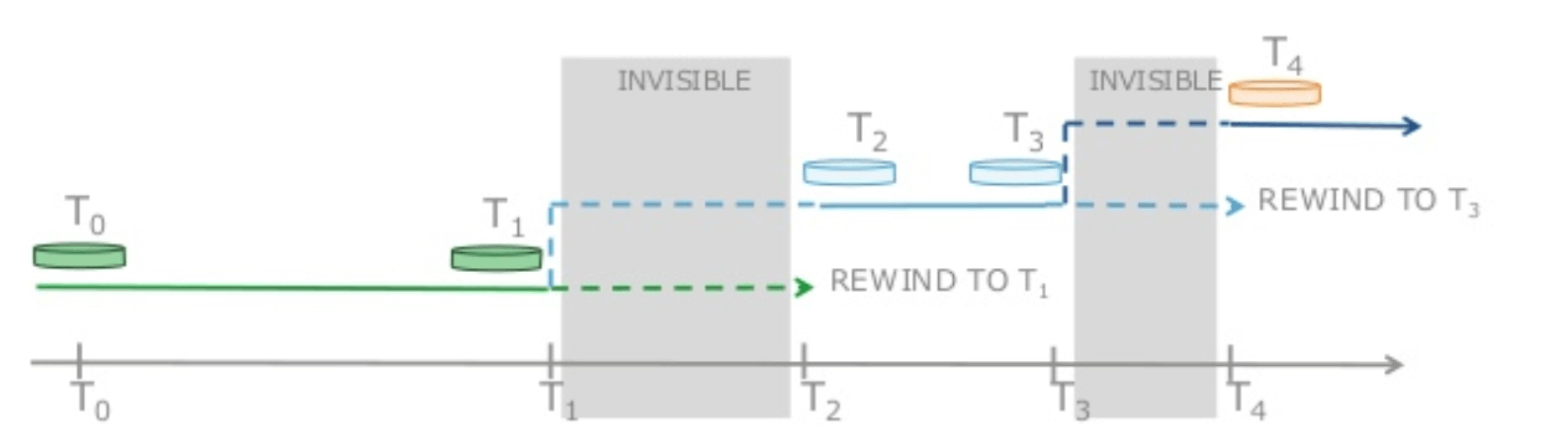
อ้างอิง: 20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL(ภาษาญี่ปุ่น)
นี่เป็นฟังก์ชันการ "ย้อนกลับข้อมูลคืน" อีกแบบนึงที่ไม่ใช่การ Backup หรือ Recovery ที่กล่าวไปในหัวข้อที่แล้วครับ โดยดูจากภาพด้านบนจะเห็นได้ว่า เราสามารถย้อนไปมาระหว่าง T4 กับ T3 หรือ T2 กับ T1 ได้ครับ
โดยตัวอย่าง Usecase ได้แก่ กรณีที่เราเผลอไปทำบางอย่างผิดพลาดเช่นการเผลอไป Drop Table สำคัญทิ้ง หรือ DELETE ข้อมูลสำคัญไป ก็สามารถใช้ BackTrack เพื่อย้อนไปก่อนที่จะทำผิดได้ หรือเอาง่ายก็คือค้ลายๆกับการ Undo(Ctrl + Z) กับ Redo(Ctrl + Y, Ctrl + Shift + Z) ที่เป็นฟังก์ชันที่อยู่ในหลายๆโปรแกรมนั่นเองครับ
Fast recovery after failover with cluster cache management
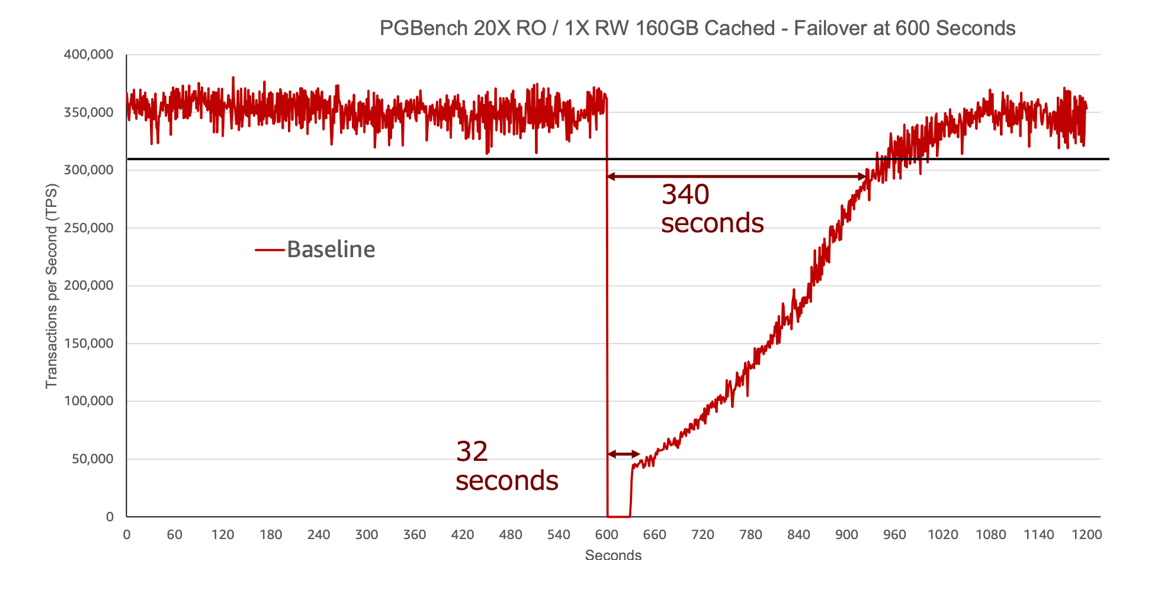
อ้างอิง: PowerPoint Presentation(ภาษาญี่ปุ่น)
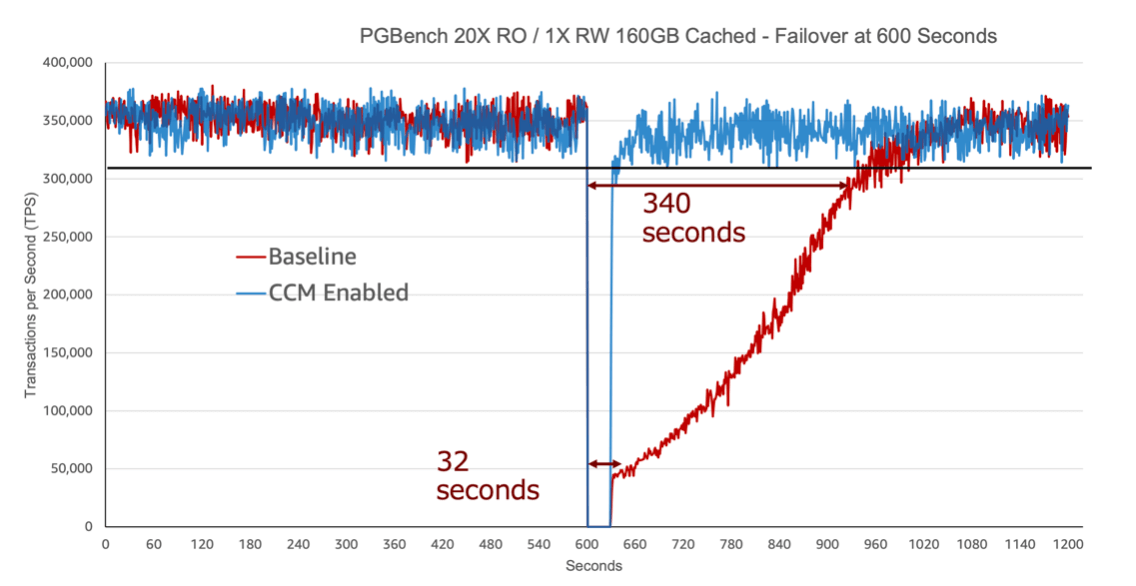
แผนภาพนี้แนวนอนแสดงถึงเวลา(วินาที) ส่วนแนวตั้งแสดงถึง Transactions Per Second(TPS) ที่เป็น Performance ของ DB เส้นสีแดงที่ตกลงมาแสดงให้เห็นถึงช่วงเวลาที่เกิด Failover ครับ
ในกรณีที่ Primary ของ Aurora เกิดการ Crash แล้ว Read Replica จะสามารถทำการเลื่อนขั้นตัวเองให้เป็น Primary ตัวใหม่ได้ ซึ่งในตัวอย่างนี้ เกิดการ Failover โดยใช้เวลาแค่ 32 วินาทีในการกลับมาทำงานต่อ ซึ่งถือว่าเร็วมาก
แต่ก็ใช้เวลาเพิ่มอีก 340 วินาทีถึงจะสามารถกลับมาใช้งานได้มีประสิทธิภาพเหมือนเดิม ซึ่งมาดูสาเหตุกันในหัวข้อต่อไป
นั่นเป็นเพราะว่า Instance ที่มาเป็น Primary ตัวใหม่นั้นไม่มี Cahce เหมือนกับ Primary ตัวเก่านั่นเอง การไม่มี Cahce ทำให้เราต้อง I/O Disk บ่อย ทำให้ TPS ต่ำลงนั่นเองครับ
และ Aurora เองก็ได้มีฟังก์ชันที่เข้ามาแกไขเรื่องนี้คือฟังก์ชัน cluster cache management ครับ ฟังก์ชันนี้จะทำการแชร์ Cahce ที่ Primary instance มีอยู่กับ Replica ครับ
หาก Primary instance เกิด Crash แล้ว Failover แล้ว Replica ทำการเลื่อนขั้นตัวเองให้เป็น Primary ตัวใหม่ จะสามารถทำ TPS ได้เท่ากับตัวเดิมได้ทันทีเพราะมี Cahce ที่แชร์จากตัวเดิมอยู่แล้ว
อ้างอิง: PowerPoint Presentation(ภาษาญี่ปุ่น)
Parallel Query
ในหัวข้อนี้เรามาคุยกันเกี่ยวกับ Query แบบขนาน หรือ Parallel Query กันครับ
อ้างอิง: PowerPoint Presentation(ภาษาญี่ปุ่น)
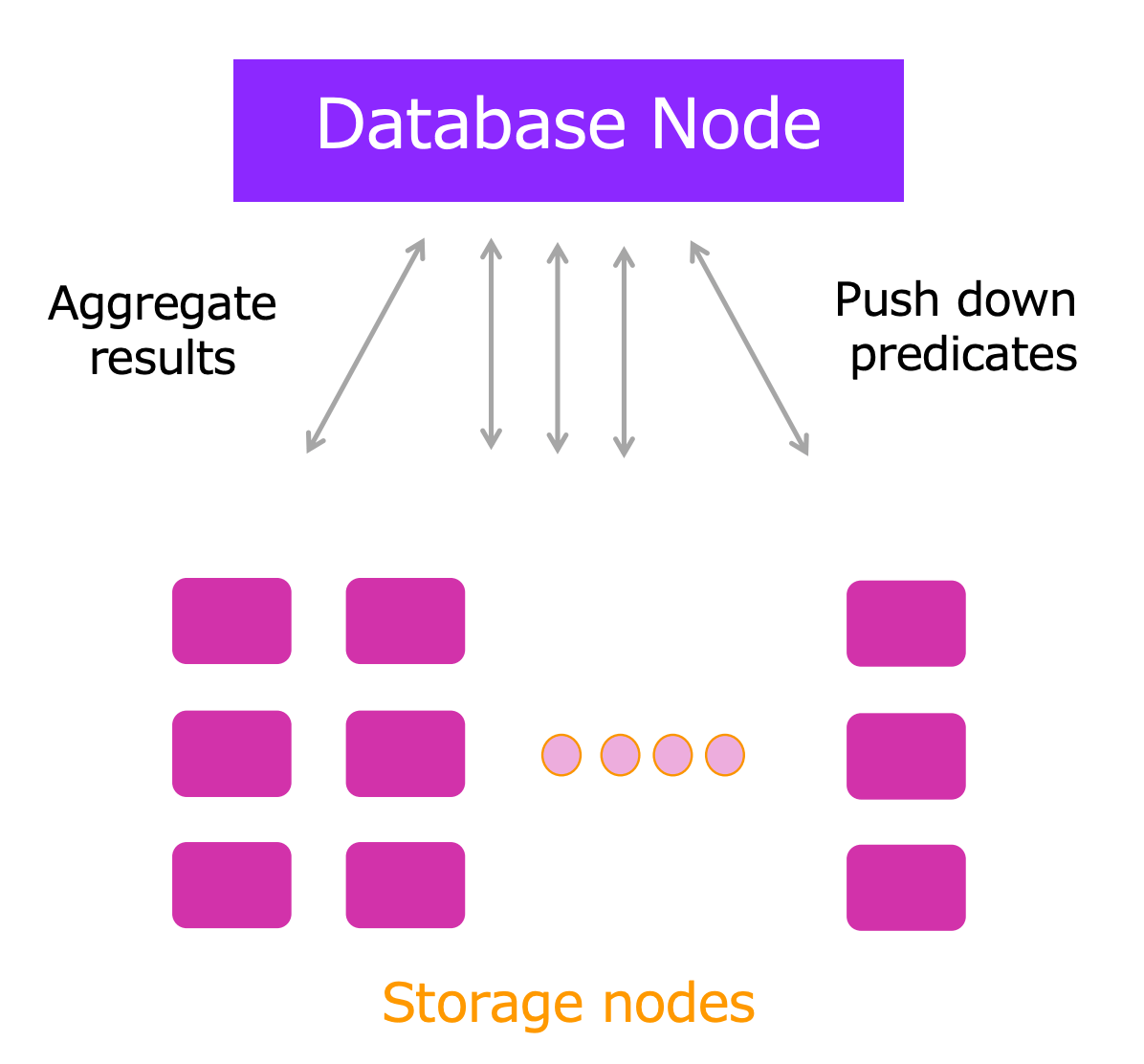
แผนภาพด้านบนนี้แสดงให้เห็นถึง Aurora DB Cluster ครับ
Database Node ที่เขียนอยู่ด้านบนคือ Instance zone ส่วนด้านล่างคือ Storage zone ครับ
การดำเนินการ query หรือการจัดการ transaction จะเป็นงานของ Instance zone(Database Node) ครับ แต่ว่าในฝั่ง Storage zone ก็มี CPU อยู่เหมือนกันครับ ซึ่งมีอยู่จำนวนมากเป็นหลักพัน ซึ่งโดยปกติแล้วจะทำหน้าที่อ่านหรือเขียน เราสามารถ Off-road qurey ที่ Instance zone จัดการอยู่ ไปยัง Resource ที่ Storage zone ได้ โดยการกระทำเช่นนี้เรียกว่า Parallel Query ครับ
การทำเช่นนี้จะทำให้การจัดการ query เร็วขึ้นอย่างมหาศาลครับ
มีตัวอย่างจากบริษัท NETFLIX เลยเอามาเล่าให้ทุกคนฟังกันครับ
NETFLIX ทำการใช้ฟังก์ชัน Parallel Query ทำให้ query นั้นมีความเร็วมากกว่าเดิมถึง 120 เท่ากันทีเดียวครับ
และจากที่เราได้ลองใช้เองก็ได้พบว่า 8 query จาก 22 qurey มีความเร็วมากกว่าเดิมมากกว่า 10 เท่า+ กันเลยทีเดียว
การใช้ Parallel Query ไม่ได้ทำให้ทุก query เร็วขึ้นหมด เพราะจะมีตัวที่เหมาะและไม่เหมาะกับ Parallel Query
แต่ถึงอย่างงั้นก็ทำให้เร็วขึ้นได้อย่างมาก แล้วด้วยผลลัพท์นี้ทำให้ NETFLIX สามารถลดขนาด instance type ของ Aurora จาก r3.8xlarge เป็น r3.2xlarge ได้
Global Database
ต่อมาคือ Global Database ครับ ถ้าจะให้สรุปเจ้านี่สั้นๆก็คือ "Storage layer สำหรับ Replication ระหว่าง Region" ครับ
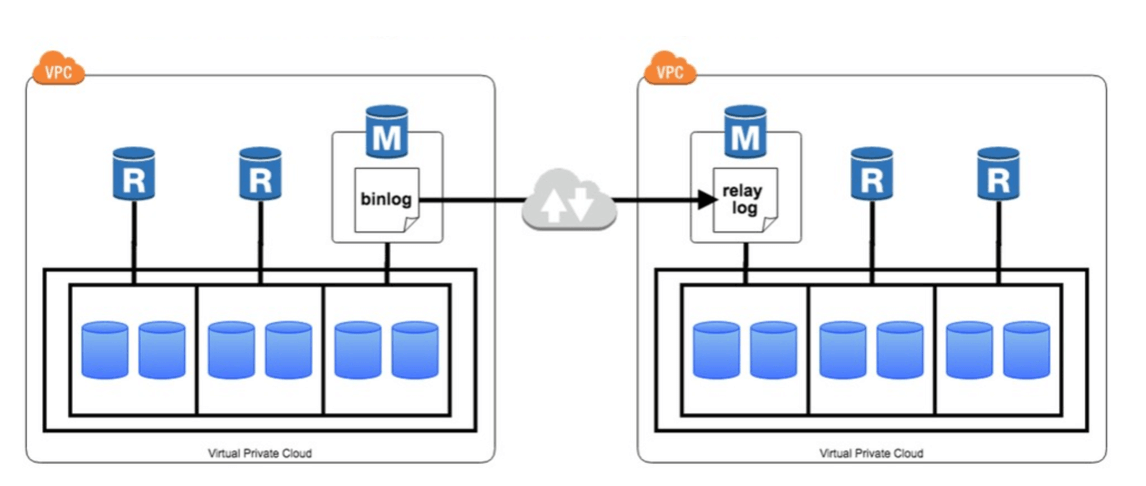
ซึ่งความจริงแล้วก่อนที่จะมี Global Database ได้มีฟังก์ชัน Cross-region replication ที่เรียกว่า Cross-Region Read Replica อยู่ครับ
อ้างอิง: お手軽にリージョン間DRができるAurora Global Databaseの実力を見てみた - Speaker Deck(ภาษาญี่ปุ่น)
โดย Cross-Region Read Replica จะทำการเชื่อม Log file ระหว่าง Instance ทำการอัพเดท Storage ของตนเอง ผ่าน Replica instance ที่ได้รับข้อมูลครับ
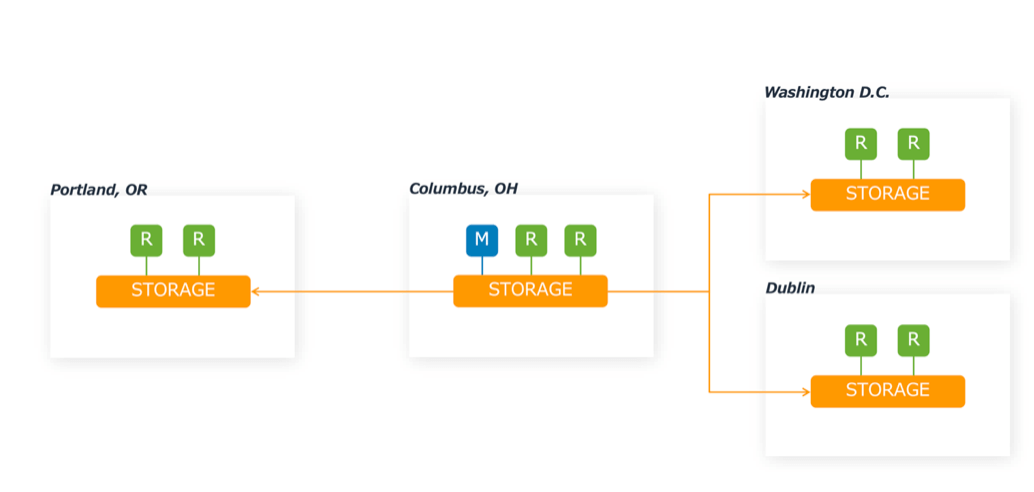
ส่วน Global Database จะทำให้การสามารถ replication ในส่วน Storage zone(เท่านั้น) ครับ
อ้างอิง: PowerPoint Presentation(ภาษาญี่ปุ่น)
นี่ทำให้ช่วยลดระยะเวลาการเชื่อมต่อให้เหลือต่ำกว่า 1 วินาทีสำหรับ Cross-region replication ครับ
นอกจากนี้ ต่อให้ Primary instance ที่อยู่ใน Region หยุดการทำงานไป ก็สามารถใช้ Primary instance ที่อยู่ใน Region อื่นกู้กลับคืนมาทำงานได้ภายใน 1 วินาที และการ replication ยังยังใช้ Storage เท่านั้น ทำให้ต่อให้ปลายทาง replication ไม่มี instance อยู่ก็สามารถ replication ได้ ซึ่งทำให้สามารถทำโครงสร้างรับมือ Disaster Recovery(DR) ได้ ในราคาที่ต่ำ
Aurora Serverless
ต่อมาคือ Aurora Serverless ครับ ภาพด้านล่างที่เห็นอยู่นี้เป็นแผนภาพ Aurora DB Cluster ครับ
สีฟ้าที่เขียนว่า "SCALABLE DB CAPACITY" คือ Instance zone
ด้านล่างสีส้มที่เขียนว่า "DB STROAGE" คือ Stroage zone
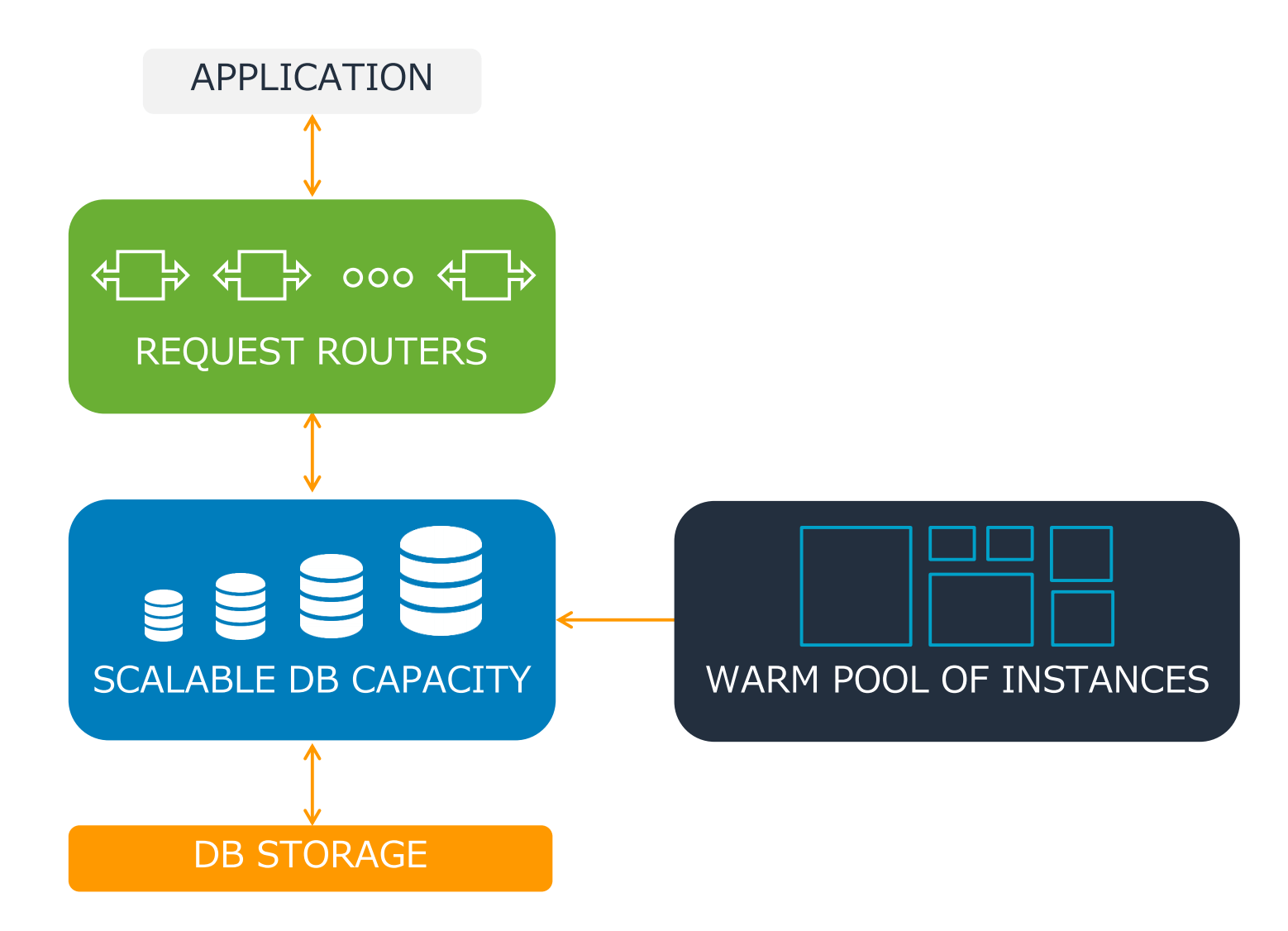
อ้างอิง: PowerPoint Presentation(ภาษาญี่ปุ่น)
Aurora Serverless คือฟังก์ชันที่สามารถปรับขนาดให้พอเหมาะกับความต้องการโดยอัตโนมัติ ในกรณีที่ไม่ได้ใช้ Instance จะทำการ Shutdown ตัวเอง และเสียค่าใช้จ่ายจะเป็น 0 ในส่วนของ instance ได้(แต่ยังคงเสียค่าใช้จ่ายในส่วนของ Storage ตามปกติ)
Usecase ที่เหมาะสมจะใช้คือ สภาพแวดล้อมที่ใช้สำหรับทดสอบ หรือ พัฒนา ที่ไม่ได้ใช้งานตลอดทั้งวัน หรือสำหรับ Workload ที่ม่สามารถคาดเดาความต้องการได้
Aurora Serverless Data API
ชื่อ Aurora Serverless อาจจะทำให้คุณเข้าใจผิดว่า เป็น Service ที่เหมาะไปพ่วงกับ Serverless service อื่นๆ เช่น Lambda แล้วจะใช้งานได้ดี แต่จริงๆแล้วจุดที่แตกต่างจาก Aurora ปกติมีแค่ส่วนที่สามารถปรับขนาดโดยอัตโนมัติแค่นั้นเอง นอกจากนั้นก็สร้างใน VPC เหมือนเดิม Port ที่ใช้เชื่อมต่อก็คือ Port MySQL หรือ PostgreSQL เหมือนเดิม
แต่มีอีกอย่างที่เพิ่มมาคือมีการเพิ่ม Aurora Serverless Data API เข้ามาครับ เราสามารถ Public Access ได้ผ่านรูปแบบ REST หรือ SDK จากในแต่ล่ะ ภาษา โดยจะมี HTTPS Endpoint ถูกสร้างขึ้นสำหรับการเชื่อมต่อไปยัง Aurora DB Cluster ครับ ทำให้การเชื่อมต่อจากภายนอก VPC ยกตัวอย่างเช่น อุปกรณ์ IoT สามารถทำได้ง่ายขึ้น และเวลาใช้งาน Lambda ก็ไม่จำเป็นต้องใช้ VPC Lambda อีกต่อไป
เราได้นำเสนอฟังก์ชันที่มีแค่ Aurora กันไปแล้ว
หากใครต้องการศึกษาเพิ่มเติม กรุณาตรวจสอบลิ้งค์ด้านล่างก่อน เพราะบางฟังก์ชันก็มีข้อแตกต่างกันไปตาม DB Engine (เป็นของ MySQL หรือ PostgreSQL) What is Amazon Aurora? - Amazon Aurora
ควรจะเลือกอะไรดีระหว่าง RDS หรือ Aurora
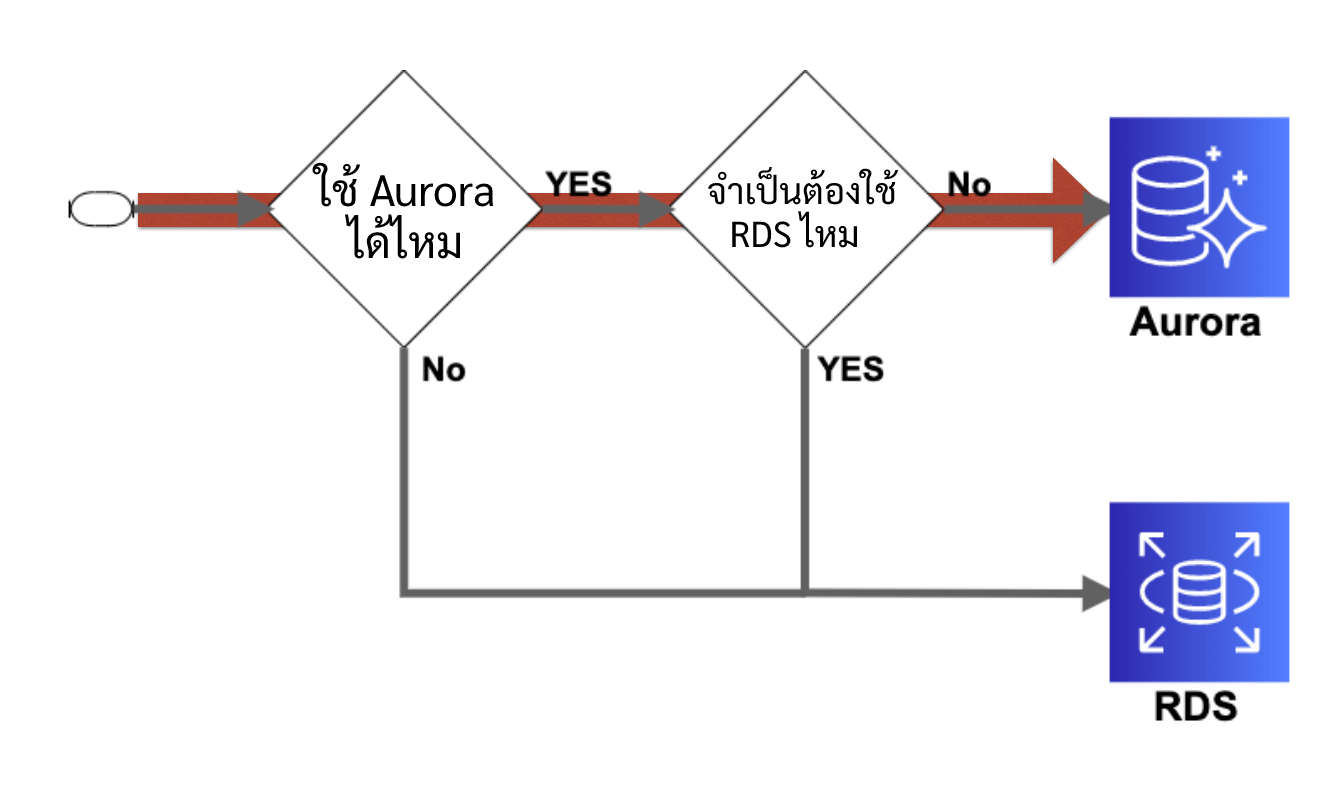
โดยพื้นฐานเราจะแนะนำให้ใช้ Aurora ครับ เพราะ มี Performance ความพร้อมใช้งาน ความทนทาน ที่สูงกว่าและมีฟังก์ชันต่างๆที่สะดวกสบายตามที่ได้เขียนไว้ในหัวข้อที่ผ่านๆมา แต่ก็มีเคสที่ Aurora ไม่สามารถใช้งานได้ หรือใช้ Aurora ได้ แต่ก็เลือกที่จะใช้ RDS ที่เราจะมาคุยกันในหัวข้อต่อไปครับ
ก่อนอื่น
แต่ว่าก่อนอื่นให้เราตรวจสอบก่อนว่าจำเป็นต้องใช้ Relational Database จริงๆรึเปล่าครับ
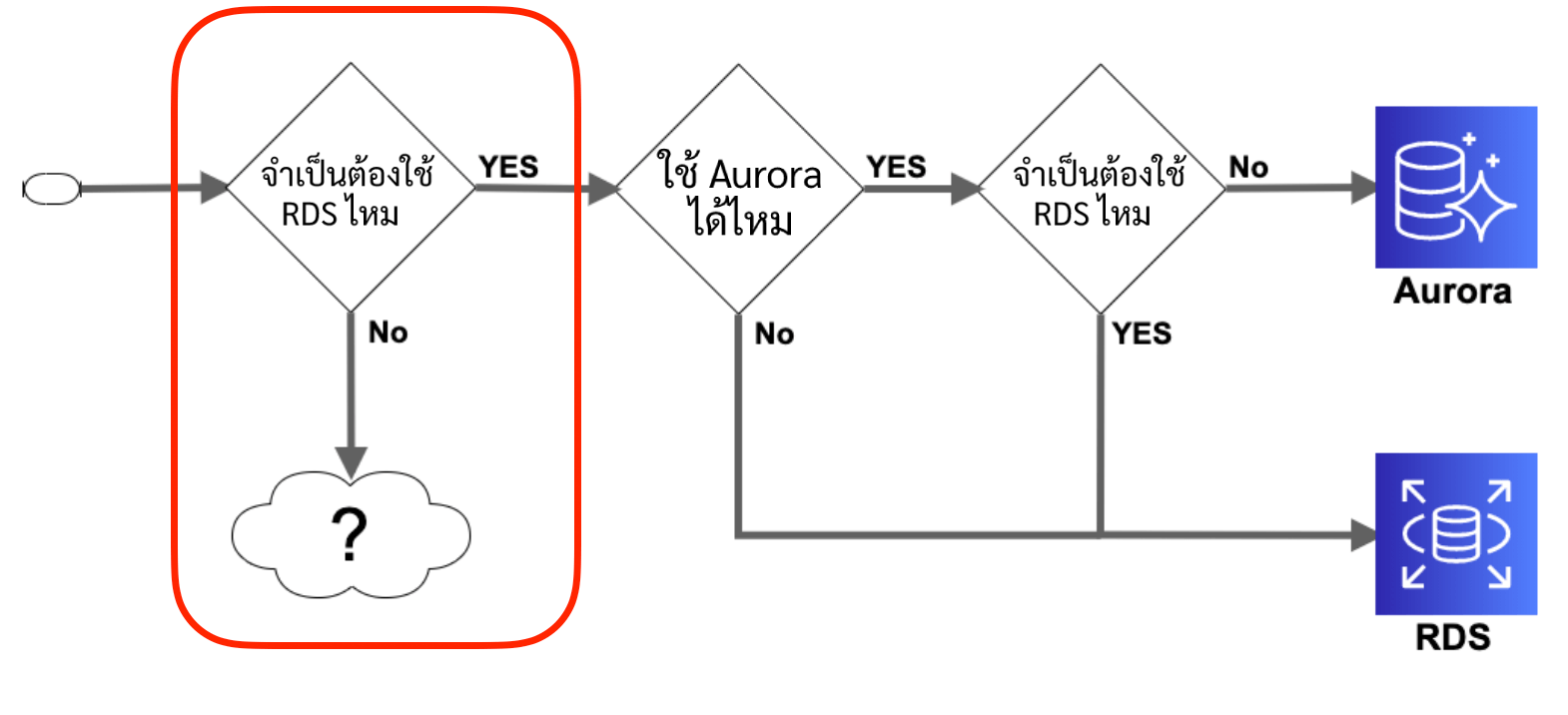
จริงอยู่ที่ RDS มีความยืดหยุ่นและประสิทธิภาพที่สูง แต่ว่า AWS ก็ยังมี Database Service นอกจาก RDS/Aurora อยู่ครับ
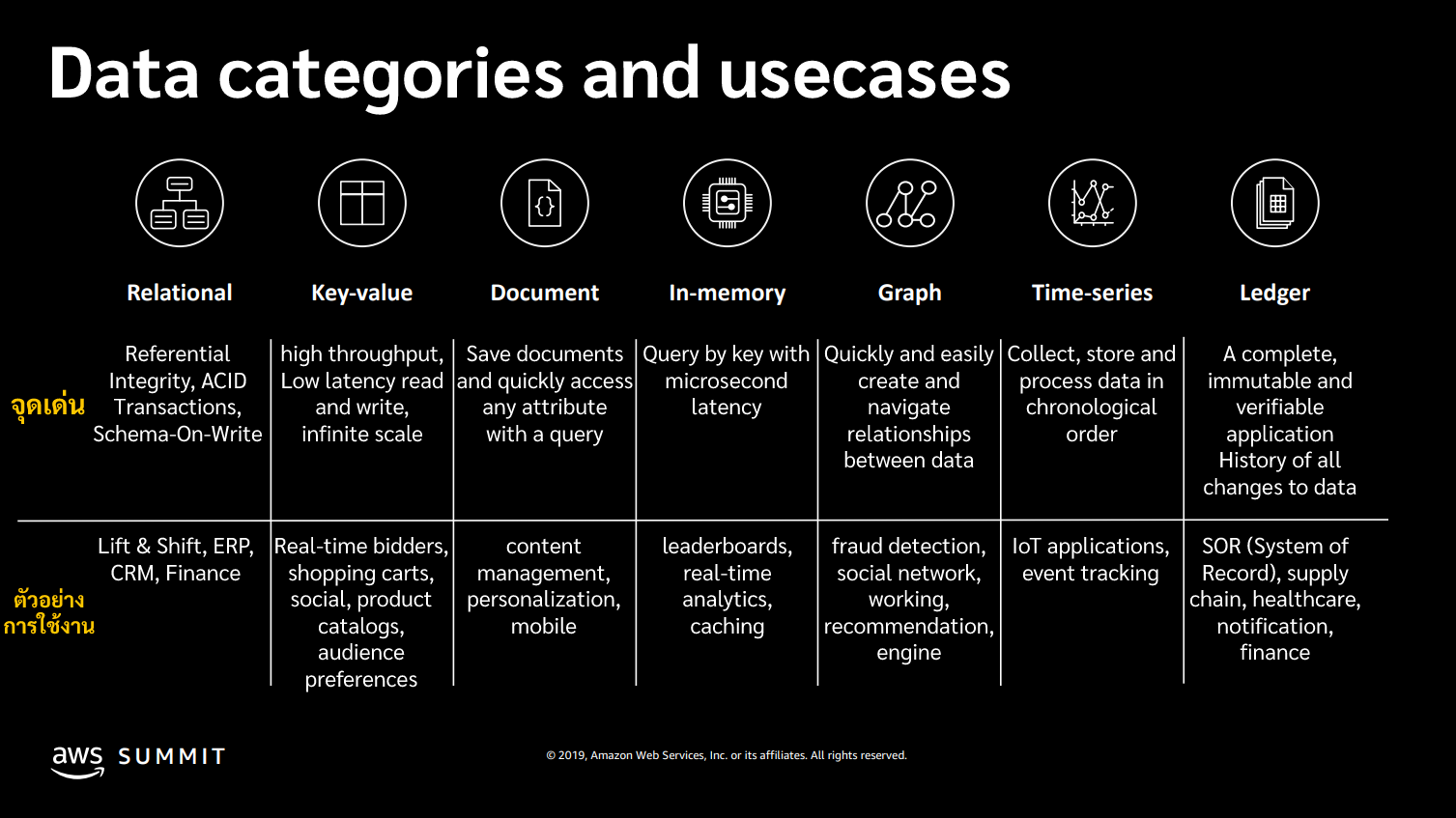

โดยเราสามารถดูรายละเอีดยของ AWS Database Service ได้ที่ลิ้งค์ด้านล่างนี้
กรณีที่ Aurora ไม่สามารถใช้งานได้
ก่อนอื่นเรามาคุยกันเกี่ยวกับ กรณีที่ Aurora ไม่สามารถใช้งานได้ครับ
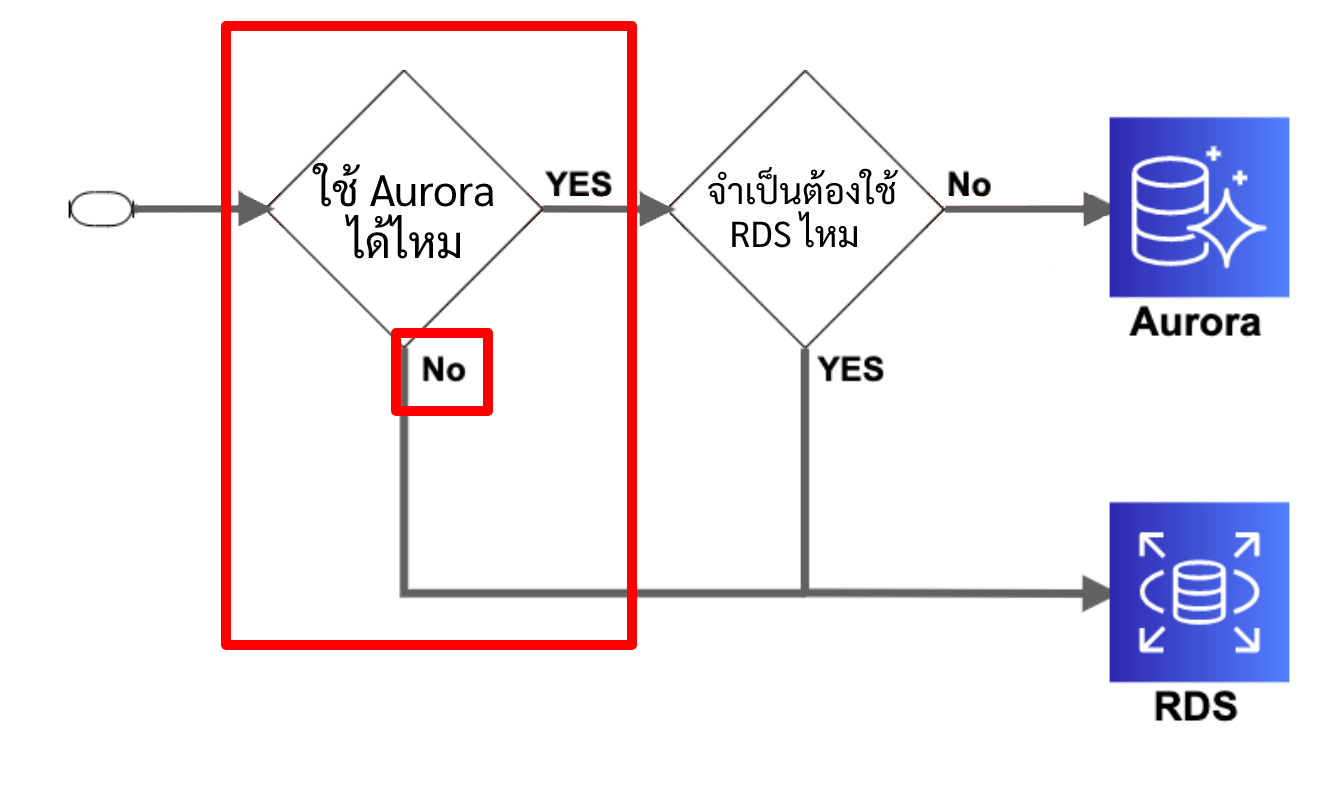
ตัวอย่างที่ Aurora ไม่สามารถใช้งานได้ได้แก่ Case ต่อไปนี้
- ไม่มี DB engine ที่ใช้ได้
- ไม่มี version ที่ใช้ได้
- ไม่มี Storage engine ที่ใช้ได้(กรณีของ MySQL)
- ไม่มี instance type ที่ใช้ได้
ไม่มี DB engine ที่ใช้ได้
ปัจจุบัน DB engine ที่ RDS ใช้ได้มี 5 อย่างต่อไปนี้ครับ
- MySQL
- PostgreSQL
- MariaDB
- Oracle
- SQL Server
แต่ว่า DB engine ที่ Aurora ใช้ได้มีแค่ MySQL กับ PostgreSQL เท่านั้น หากต้องการใข้ MariaDB, Oracle, SQL Server จำเป็นต้องใช้ RDS เท่านั้น
ไม่มี version ที่ใช้ได้
ต่อให้เลือกใช้ MySQL กับ PostgreSQL ก็ต้องมาดูกันต่ออีกครับเพราะ Major version ที่ RDS และ Aurora ใช้ได้ก็ไม่เหมือนกันครับ ด้านล่างนี่คือตัวอย่าง version ที่ RDS ใช้ได้ครับ(2022/11)
- MySQL
- 5.7
- 8.0
- PostgreSQL
- 14.1
- 14.2
- 14.3
- 14.4
ส่วนด่านล่างนี่คือ ตัวอย่าง version ที่ Aurora ใช้ได้
- MySQL
- 5.6
- 5.7
- 8.0
- PostgreSQL
- 14.3
เพราะงั้นกรุณาตรวจสอบ version ที่ support ก่อน เพราะ RDS และ Aurora มีเวอร์ชั่นที่ใช้ได้ไม่เหมือนกัน
ไม่มี Storage engine ที่ใช้ได้(กรณีของ MySQL)
ปัจจุบัน Storage engine ที่ Aurora รองรับอยู่มีแค่ InnoDB เท่านั้นครับ ทำให้หากต้องการใช้ MyISAM หรือ Storage อื่นๆ จำเป็นต้องเลือก RDS ครับ
จากที่ตรวจสอบ AWS Document ในหัวข้อของ RDS จะพบ RDS นั้นก็มีแนะนำให้ใช้ InnoDB เหมือนกัน และก็มี Storage ที่ไม่รองรับเหมือนกัน หากต้องการใช้ Storage engine อื่นนอกจาก InnoDB กรุณาตรวจสอบที่ AWS Document ด้านล่างนี้
ไม่มี instance type ที่ใช้ได้
นี่อาจจะไม่ใช่หัวข้อที่คิดจะเปลี่ยนไป RDS แบบเด็ดขาดเลยสักทีเดียว แต่สิ่งที่เราต้องการบอกก็คือ RDS กับ Aurora มี Instance type ที่ใช้ได้แตกต่างกันครับ โดยสามารถตรวจสอบเองได้บน AWS Management Console หรือ CLI ครับ
กรณีที่ใช้ Aurora ได้ แต่ก็เลือกใช้ RDS
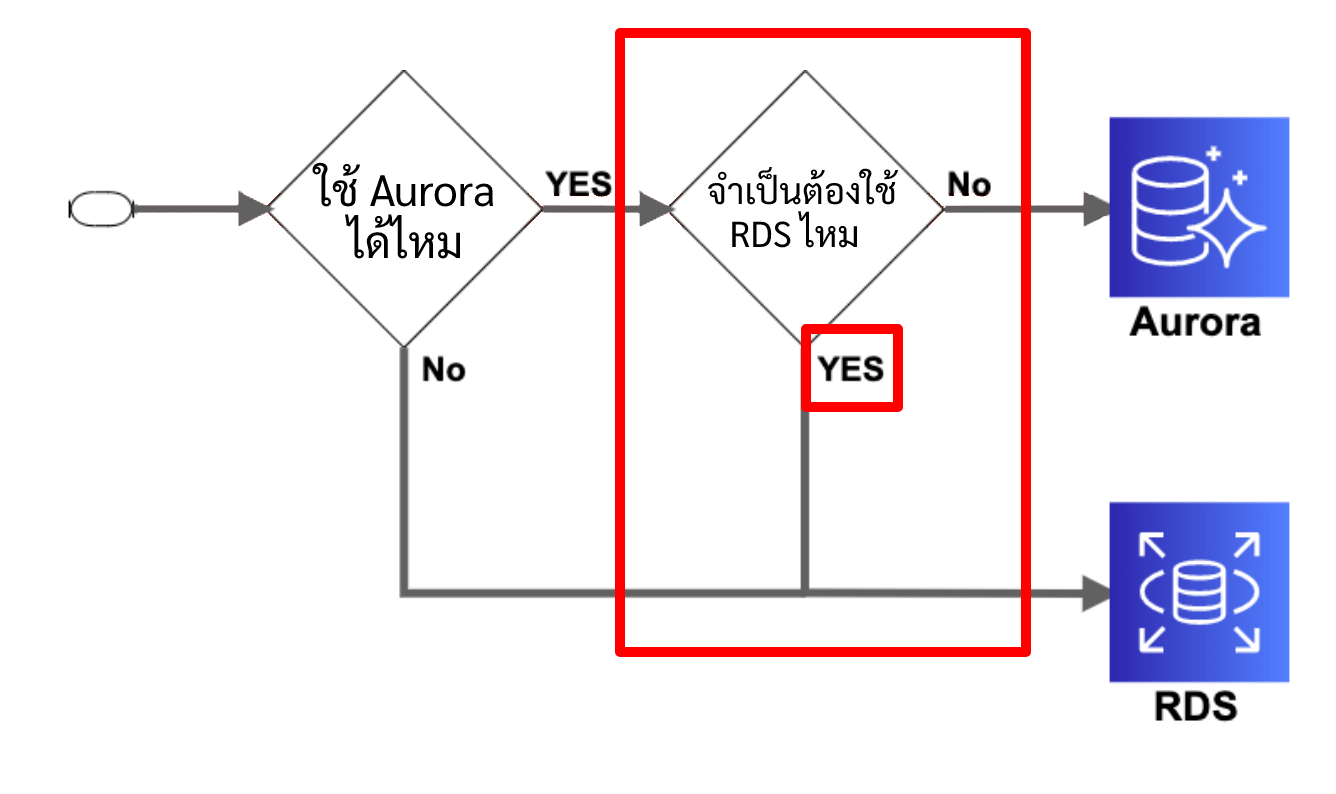
ต่อมาเราจะมาคุยกันเกี่ยวกับหัวข้อที่ใช้ Aurora ได้ แต่ก็เลือกใช้ RDS กันครับ
ต้องการใช้ฟังก์ชันใหม่ของ DB engine เร็วๆ
ยกตัวอย่างการรองรับ DB Engine verison ของ RDS กับ Aurora ครับ
| ตัวอย่างที่ 1: การรองรับ PostgreSQL 10 | |
|---|---|
| RDS | 27/02/2018 (10.1), 25/07/2018 (10.4) |
| Aurora | 25/09/2018 (10.4 Compatible) |
| ตัวอย่างที่ 2: การรองรับ MySQL 5.7 | |
|---|---|
| RDS | 22/02/2016 |
| Aurora | 06/02/2018 |
จะสังเกตเห็นว่า RDS มีการรองรับก่อนทั้ง 2 อัน เพราะ Aurora นั้นเป็นการเข้ากันได้(Compatible) ของ MySQL และ PostgreSQL เท่านั้นครับ หากมีการ Release เวอร์ชั่นใหม่ของ MySQL หรือ PostgreSQL AWS จำเป็นต้องแก้ไข engine ข้างใน Aurora ก่อน ถึงจะสามารถทำงานได้ ซึ่งจำเป็นต้องใช้เวลาในการเข้าไปแก้ไข
นั่นหมายความว่าหากเราต้องการใช้ฟังก์ชันที่มากับ DB Engine ใหม่ๆ ก็แนะนำให้ใช้ RDS จะได้ใช้เร็วกว่า Aurora ครับ หรือจะให้เร็วกว่านั้นก็ install MySQL หรือ PostgreSQL ลงใน EC2 เลยครับ
จำเป็นต้องใช้ parameter ที่ไม่รองรับ
ใน Aurora นั้น มี architecture ที่ไม่เหมือนกับ MySQL หรือ PostgreSQL ปกติ ทำให้บาง Parameter ถูก Disable ถ้าหากเราต้องการใช้ Parameter ที่ถูก Disable นั้น ก็แนะนำให้ใช้ RDS ครับ
ยกตัวอย่างเช่น parameter innodb_change_buffering ของ MySQL นั้น disable ใน Aurora ครับ
เนื้อหาของ parameter นี้คือ ฟังก์ชันชลอการเขียนข้อมูลลงใน Disk เมื่อมีการอัพเดทข้อมูล การเขียนข้อมูลงใน Disk จะเกิด performance bottleneck ได้ง่าย แล้วฟังก์ชันนี้จะชลอการเขียนข้อมูลลงใน Disk เมื่อมีการอัพเดทข้อมูล แล้วใช้เวลานั้นอัพเดทแคชบน memory เพื่อเพิ่มความเร็วในการประมวลผลการเขียนข้อมูล และการเขียนข้อมูลจะเริ่มขึ้นหลังจากนั้น เป็นฟังก์ชันที่จะเปลี่ยนการประมวลผล write-through เป็น write-back
ซึ่ง parameter ที่กล่าวมาด้านบนนั้นได้ disable ใน Aurora ทำให้การประมวลผลอาจจะช้าลงได้หากเกิด Random disk access จำนวนมาก เช่น การประมวลผลการอัพเดท Secondaery Disk จำนวนมาก แต่ถึงอย่างงั้น Aurora ก็ยังมี Base performance ที่ดีอยู่ ซึ่งหากใครสงสัยว่าอันไหนดีกว่า ก็ให้ทดลองเองกับ Database ของตัวเองดูครับ
ต้องการใช้ของถูก
โดยรวมแล้ว Aurora มีราคาที่สูงกว่าครับ โดยเราจะมาแนะนำ 2 สาเหตุที่ทำให้ aurora ถึงแพงกว่ากันครับ
รูปแบบการคิดเงินที่ต่างกัน
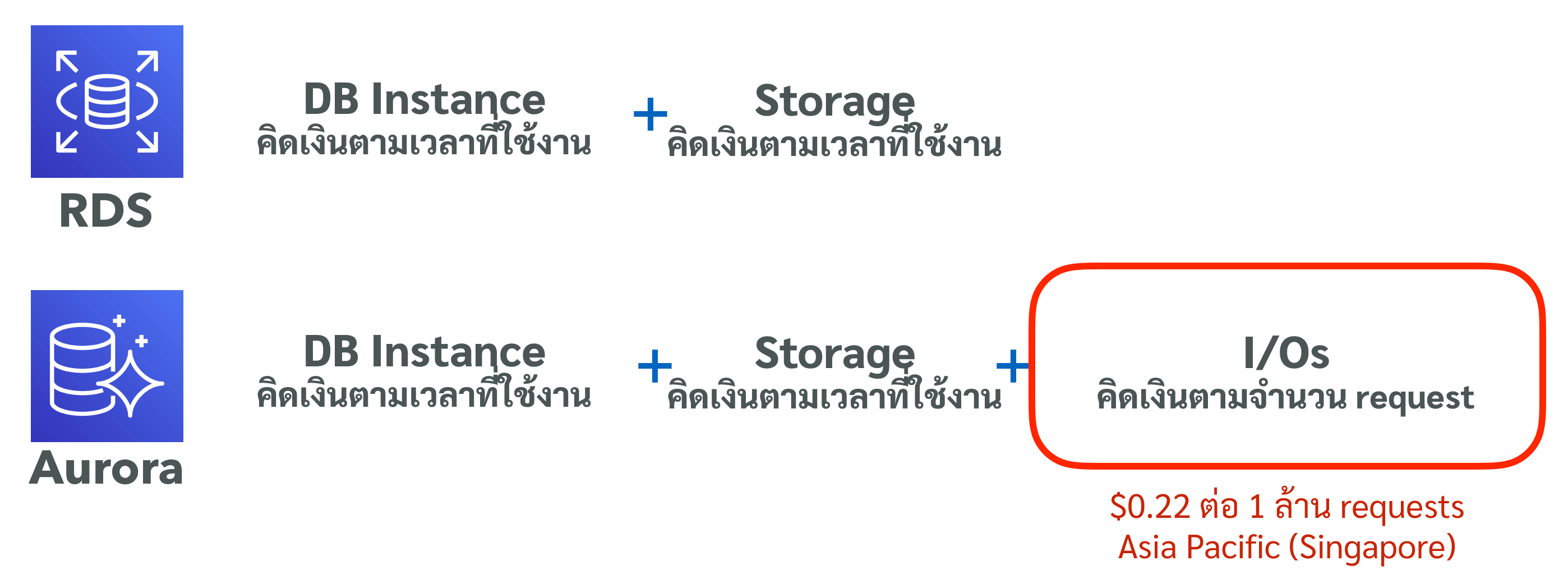
การคิดเงินค่าใช้จ่ายของ RDS มีอยู่ 2 หัวข้อใหญ่ๆด้วยกันได้แก่ DB Instance + Storage แต่ว่า Aurora จะมีส่วนที่เพิ่มมาคือ จำนวน I/O Request โดยจะคิดเงิน $0.22 ต่อ 1 ล้าน Request(Singpore region)
ค่าใช้จ่ายของ DB Instance
อีกสาเหตุนึงที่ Aurora แพงอยู่ที่หน่วยค่าใช้จ่ายต่อชั่วโมงของ DB Instance นั้นแพงอยู๋แล้วนั่นเอง เมื่อเราเปรียบเทียบ Aurora กับ RDS ในหัวข้อSingpore Region MySQL Single AZ(Single instance) Instance Type: r5 ดู จะพบว่ามีราคาต่างกันดังนี้
| RDS(USD/ชั่วโมง) | Aurora(USD/ชั่วโมง) | ความแตกต่างของราคา | |
|---|---|---|---|
| r5.large | 0.285 | 0.35 | 122.81% |
| r5.xlarge | 0.57 | 0.7 | 122.81% |
| r5.2xlarge | 1.14 | 1.4 | 122.81% |
| r5.4xlarge | 2.28 | 2.8 | 122.81% |
| r5.12xlarge | 6.84 | 8.4 | 122.81% | |
จะเห็นได้ว่า Aurora แพงกว่าประมาณ 20 % เมื่อเทียบกับ RDS โดยนี่เป็นผลลัพท์ของ r5 Instance ส่วนของ t type instance ผลลัพท์ก็ไม่ต่างกันมากนักครับ
แต่ก็พูดได้ไม่เต็มปากว่า RDS จะถูกกว่าเสมอ
จากสาเหตุ 2 อย่างที่กล่าไปทำให้เคสส่วนให่ญ Aurora จะแพงกว่า RDS ครับ แต่ก็มีบางจุดที่ Aurora ถูกกว่า RDS ครับ ไปดูกันเลย
เคสที่ไม่จำเป็นต้องใช้ Multi-AZ
ในกรณีของ Aurora เราอาจจะไม่จำเป็นต้องใช้โครงสร้าง Multi-AZ ก็ได้ครับ
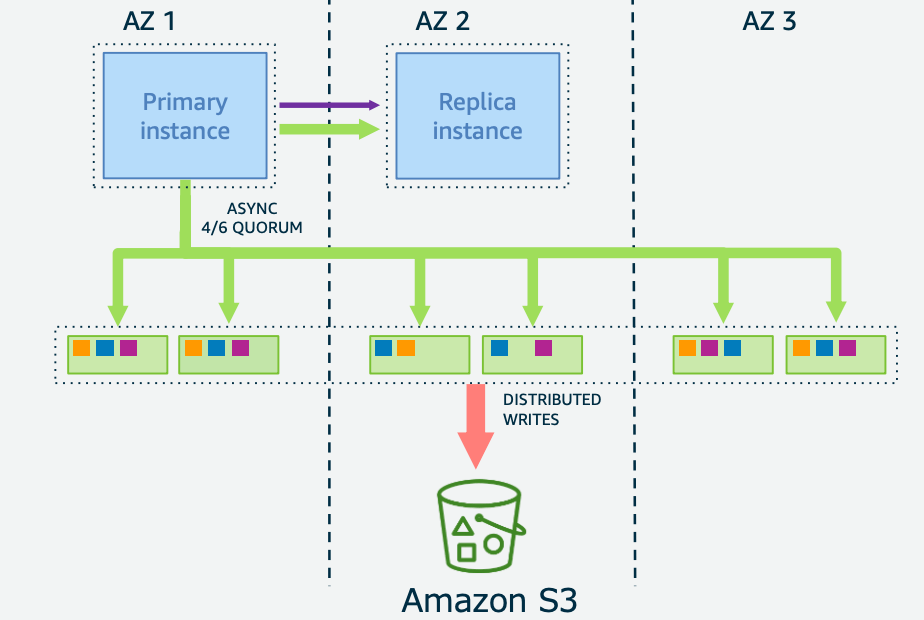
ตามที่เราได้คุยกันไปในหัวข้อที่แล้วๆ ต่อให้ Aurora มี DB Instance แค่ 1 ตัวเป็น Single AZ ในส่วน Storage ก็จะถูกก็อปปี้เป็น 6 ส่วน ผ่าน 3AZ ทำให้ถือว่ามีความทนทานเพียงพอ เพราะ sotrage ที่เก็บอยู่ใน S3 ที่มีความทนทาน 99.99999999999%(Eleven 9) ครับ
แต่ต่อให้เกิดปัญหา Instance Crash ในโครงสร้าง Single AZ Aurora Instance ก็จะทำการฟื้นฟูสภาพด้วยตนเอง โดยปกติแล้วจะเสร็จภายใน 10 นาที หากคุณคิดว่า 10 นาทีนี้ไม่เป็นไร ก็ไม่จำเป็นต้องใช้ Multi-AZ ก็ได้ นั่นหมายความว่า หากเราเปรียบเทียบ RDS Multi AZ กับ Aurora Single-AZ แล้ว Aurora Single-AZ จะถูกกว่าครับ
ไม่จำเป็นต้องใช้ StandBy Replica
เราได่คุยกันไปแล้วในหัวข้อ "Fast recovery after failover with cluster cache management" ในกรณีที่ Primary Instance ของ Aurora crash, Aurora จะทำการเลื่อนขั้น Replica ให้กลายเป็น Primary Instance โดยอัตโนมัติ ซึ่ง RDS ไม่สามารถทำแบบนี้ได้ ในกรณีของ RDS Multi-AZ จะมีการสร้าง Standby Instance แต่ Instance นี้ มีหน้าที่แค่เป็น Standby Instance เท่านั้นไม่สามารถใช้เป็น Read Replica ได้
หมายความว่า RDS ทำเป็นโครงสร้าง Multi-AZ + Read Replica จำเป็นต้องมีอย่างน้อย 3 Instances (Primary, Stand by, Read Replica) แต่ Aurora สร้างเริ่มได้ตั้งแต่ 2 Instances (Primary, Read Replica(ทำหน้าที่ Stand by))ไปด้วย
ไม่มีค่าใช้จ่ายในส่วนของ Replica instance storage
Stroage ของ Aurora ไม่ได้ยึดติดกับ DB Instance ตัวใดตัวนึง แต่จะยึดติดกับ Aurora DB Cluster โดยรวม ซึ่งหมายความว่าต่อให้เราเพิ่ม Read Replica จนถึง 15 ตัว(ได้มากสุด 15 ตัว) Storage จะไม่เพิ่มขึ้น สิ่งที่เพิ่มขึ้นก็มีแค่ DB Instance เท่านั้นครับ
ส่วน RDS จะมี Storage แยกแบ่งไปตาม Instance ทุกครั้งที่สร้าง Read Replica เพิ่มก็จะเพิ่มค่าใช้จ่ายในส่วนของ Storage ไปด้วยครับ
หากลดจำนวน Read Replica แล้ว Spec อาจจะถูกลดลงได้
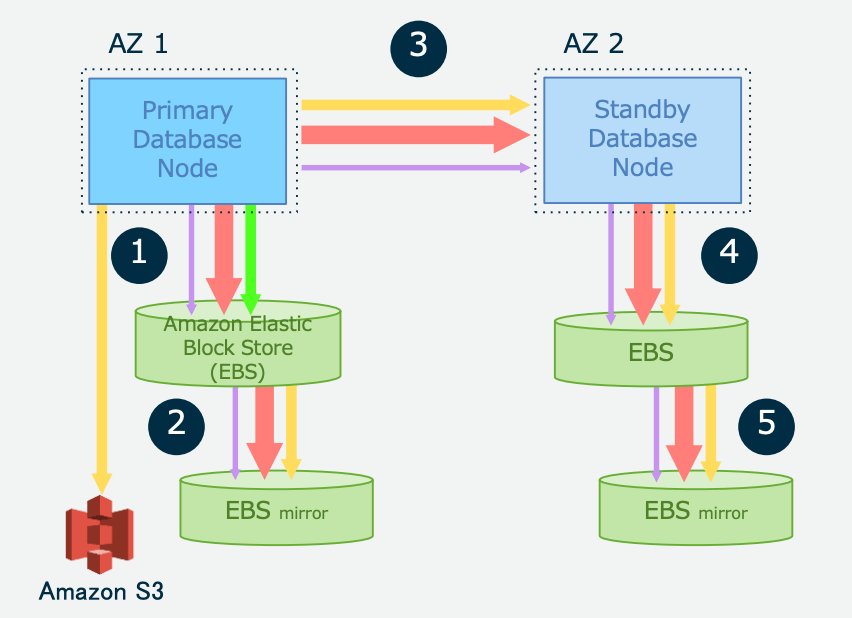
ภาพตัวอย่าง RDS architecture ครับ ลองคิดเกี่ยวกับการประมวลผลโดย Read Replica กันครับ ตามชื่อของมัน Primary Instance จะทำหน้าที่ประกวลการเขียนและอ่าน ส่วน Read Replica จะช่วยแบ่งเบาภาระ ของ Primary ด้วยการประมวลผลการอ่านแทน และจริงๆแล้ว Read Replica ยังทำการอ่านด้วยครับ นั่นเป็นเเพราะ Read Replica ของ RDS มี Storage เป็นของตัวเองและทำการประมวลผลการเขียนที่เขียนลงใน Primary ลงใน ฝั่ง Read Replica เพื่อให้ sync กับ Primary instance
ซึ่งสรุปได้ว่า Read Replica ทำทั้งการประมวลผลการเขียน และ อ่านครับ
ส่วนฝั่ง Aurora นั้น ตามที่ได้เขียนไปว่า Storage จะเชื่อมกับ Instance ทั้งหมด ทำให้ Read Replica ไม่จำเป็นต้องประมวลผลการเขียนข้อมูลครับ สามารถจดจ่อกับการประมวลผลการอ่านข้อมูลได้ครับ การใช้ Aurora จะช่วยให้เราลดจำนวน Resource ที่ใช้ในการประมวลผล ทำให้ลดจำนวน Read Replica ได้ ทำให้อาจจะลดค่าใช้จ่ายลงก็เป็นได้ครับ
นอกจากนี้ Read Replica ของ Aurora สามารถใช้ Auto Scaling ได้ ทำให้สามารถเพิ่มลดจำนวน Instance ได้ตามความต้องการ ทำให้ลดค่าใช้จ่ายที่ไม่จำเป็นได้
คิดถึง total cost
ถึงแม้ Aurora จะมีค่าใช้จ่ายที่สูงกว่าแต่ก็มีหลากหลายฟังก์ชันที่ช่วยลดภาระต่างๆลงได้ เช่น มี Performance ที่ดีเร็ว โดยไม่ต้อง qurey tunning, Read replica ใช้ Autoscaling ได้ ทำให้ไม่ต้องมีทดสอบว่าจะใช้ instance กี่ตัวดี สามารถย้อนกลับได้โดยใช้ Backtrack มีฟังก์ชันหลายอย่างทำให้เราสามารถจดจ่อกับงานจริงๆได้ ซึ่งก็อาจจะช่วยลดค่าใช้จ่ายได้ครับ
สรุป
เราได้คุยกันไปแล้วกับในหัวข้อต่างๆที่จะทำให้ท่านผู้อ่านแยกแยะความแตกต่างระหว่าง Aurora กับ RDS ครับ(ตามหัวข้อด้านล่างนี้)
- ความแตกต่างของ architecture
- ฟังก์ชันที่มีแค่ Aurora
- กรณีที่ Aurora ไม่สามารถใช้งานได้
- กรณีที่ใช้ Aurora ได้ แต่ก็เลือกใช้ RDS
โดยถ้าจะให้สรุปง่ายๆว่าจะใช้อย่างไหนดีก็คือ
Aurora นั้นเจ๋งมาก ทุกคนไปลองใช้ Aurora กัน!!
Aurora ที่ AWS เอาจริงในยุคที่สร้าง Cloud เป็น RDB ที่ผมคิดว่าต้องมีส่วนที่เข้ากับ Workload ได้แน่ ก่อนอื่นให้ไปลองใช้กันดูว่าจะมีส่วนไหนที่จะเป็นประโยชน์ได้บ้าง
และผมหวังว่าทุกท่านจะได้รับรู้เกี่ยวกับความสุดยอดของ aurora ผ่านบทความนี้กันครับ
แล้วพบกันใหม่ในบทความต่อไปครับ ขอบคุณครับ สวัสดีครับ
บทความต้นฉบับ
บทความอ้างอิง
- บริการฐานข้อมูลที่มีการจัดการซึ่งใช้งานร่วมกับ MySQL และ PostgreSQL ได้อย่างเต็มรูปแบบ | Amazon Aurora | AWS
- ฐานข้อมูลเชิงสัมพันธ์ของระบบคลาวด์ - Amazon RDS - Amazon Web Services
- Amazon Relational Database Service Documentation
- Amazon Aurora Serverless – The Sleeping Beauty - Percona Database Performance Blog
- When Should I Use Amazon Aurora and When Should I use RDS MySQL? - Percona Database Performance Blog
- Aurora vs RDS, what's the difference? : aws
อ้างอิงภาษาญี่ปุ่น
- When Should I Use Amazon Aurora and When Should I use RDS MySQL?
- Aurora vs RDS, what's the difference?
- BASEのメインDBをAurora(MySQL)に移行しました - BASE開発チームブログ(ภาษาญี่ปุ่น)
- Hatena Engineer Seminar #11で「MySQL自前運用やめてAurora導入する話」した - 角待ちは対空(ภาษาญี่ปุ่น)
- RDSとAuroraで比較してみた|スクショはつらいよ(ภาษาญี่ปุ่น)
- Amazon Auroraがなぜ高速か解説する - OthloBlog - オスロブログ -(ภาษาญี่ปุ่น)
- [Amazon Aurora]クエリキャッシュ検証:高速となった理由の考察(ภาษาญี่ปุ่น)
- Amazon Aurora : パラメーターから見るその詳細(Percona Data Performance Blogより)(ภาษาญี่ปุ่น)
- サービス責任者が語る Amazon Aurora MySQL/PostgreSQL の詳細と内部構造 | AWS Summit Tokyo 2019(ภาษาญี่ปุ่น)
- 同YouTube版(ภาษาญี่ปุ่น)
- 20180425 AWS Black Belt Online Seminar Amazon Relational Database Service (Amazon RDS)(ภาษาญี่ปุ่น)
- 20190828 AWS Black Belt Online Seminar Amazon Aurora with PostgreSQL Compatibility(ภาษาญี่ปุ่น)
- 同YouTube版(ภาษาญี่ปุ่น)
- 20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL(ภาษาญี่ปุ่น)
- 同YouTube版(ภาษาญี่ปุ่น)
- Amazon Aurora 概要(ภาษาญี่ปุ่น)
- Amazon Relational Database Service (Amazon RDS) とは?(ภาษาญี่ปุ่น)
- Amazon Aurora とは(ภาษาญี่ปุ่น)
- Amazon RDS FAQ(ภาษาญี่ปุ่น)
- Amazon Aurora FAQ(ภาษาญี่ปุ่น)
- Amazon Aurora - Auroraの止まらない進化とその中身(ภาษาญี่ปุ่น)
- AWS Database Blog Introducing the Aurora Storage Engine(ภาษาญี่ปุ่น)
- Amazon Aurora Backtrack – 時間を巻き戻す Amazon Web Services ブログ(ภาษาญี่ปุ่น)
- PostgreSQL 準拠の Amazon Aurora がクラスタキャッシュ管理をサポート(ภาษาญี่ปุ่น)
- Amazon Aurora 1.18.0がリリースされ並列クエリとOOM回避が実装されました(ภาษาญี่ปุ่น)
- [アップデート] Auroraのストレージベースのリージョン間レプリケーションAurora Global Databaseが利用可能になりました #reinvent(ภาษาญี่ปุ่น)
- re:Growth 2018でAurora Global Databaseの使い所を話してきました #reinvent #cmregrowth(ภาษาญี่ปุ่น)
- Aurora Serverlessが一般利用可能になったので試してみた(ภาษาญี่ปุ่น)
- [アップデート] Aurora Serverless の Data API が東京リージョンでもサポートされました(ภาษาญี่ปุ่น)
- Aurora サーバーレスの Data API の使用(ภาษาญี่ปุ่น)
- Amazon RDS Aurora MySQL – Differences Among Editions(ภาษาญี่ปุ่น)
- mysqlのストレージエンジンの種類について - しがないエンジニアのブログ(ภาษาญี่ปุ่น)
- Amazon RDS で MySQL に対してサポートされているストレージエンジン(ภาษาญี่ปุ่น)
- MySQL ストレージエンジンを使用するためのベストプラクティス(ภาษาญี่ปุ่น)
- 適切ではない MySQL パラメータおよびステータス変数(ภาษาญี่ปุ่น)
- Amazon Aurora PostgreSQL のパラメータ(ภาษาญี่ปุ่น)
- 漢(オトコ)のコンピュータ道: MySQL 5.5新機能徹底解説(ภาษาญี่ปุ่น)
- 漢(オトコ)のコンピュータ道: 知って得するInnoDBセカンダリインデックス活用術!(ภาษาญี่ปุ่น)
- Amazon RDS における MySQL の既知の問題と制限(ภาษาญี่ปุ่น)
- Amazon RDS for MySQL 料金(ภาษาญี่ปุ่น)
- Amazon Aurora 料金(ภาษาญี่ปุ่น)
- ちょっと待って!Auroraを使う時にMulti-AZが本当に必要ですか?(ภาษาญี่ปุ่น)
- Amazon Auroraの耐障害性について調べてみた(ภาษาญี่ปุ่น)
- オーロラは雲の上 — RDBのScalabilityとAvailability(ภาษาญี่ปุ่น)
- 【AWS Summit Tokyo 2019 セッションレポート】サービス責任者が語る Amazon Aurora MySQL/PostgreSQL の詳細と内部構造 #AWSSummit(ภาษาญี่ปุ่น)
- Amazon Aurora MySQL を使用する際のベストプラクティス(ภาษาญี่ปุ่น)
- 【レポート】クラウド時代に再設計されたRDBMS・Amazon Auroraの最新情報から内部アーキテクチャ、運用Tipsまで #AWSSummit(ภาษาญี่ปุ่น)
- Auroraの凄さを振り返る(ภาษาญี่ปุ่น)
- RDS for MySQL データベースを Amazon Aurora へ移行するためのベストプラクティス | Amazon Web Services(ภาษาญี่ปุ่น)
- 東京リージョンでVPC Lambdaの高速起動が確認できたので改善効果を計測してみた(ภาษาญี่ปุ่น)
- 【速報】もうアンチパターンとは呼ばせない!!VPC Lambdaのコールドスタート改善が正式アナウンスされました!!(ภาษาญี่ปุ่น)
- Serverless Meetup Osaka #5 で「VPC Lambda×RDSのデメリットについて正しく理解しよう!!」というテーマで発表してきました #serverlessosaka(ภาษาญี่ปุ่น)












