
YOLOv7を完全に理解した(YOLOv7の論文を読んでみた)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データアナリティクス事業本部機械学習チームの中村です。
先日、「YOLOv7を使ってみた」について記事を書きました。
今回はこの続編で論文読んでみましたので、その内容についての投稿です。
参考までに論文リンクです。
論文を読む際にソースコードも参考にしました。
なお、タイトルはネタですのでご了承頂ければと思います...
YOLOv7の概要
YOLOv7は、YOLOv4、Scaled-YOLOv4, YOLORと同じグループが開発した最新の物体検出処理です。
MS COCOデータセットでは既存手法を大きく上回る結果と報告されています。

以下のような部分がポイントとなっています。
- ELAN, E-ELAN
- 基本アーキテクチャにELAN, E-ELANを使用
- DenseNetやCSPDarknetなどのconcatenateベースのモデルを進化させたもの
- 複合スケーリング
- concatenateモデルに適した複合スケーリング方法の提案
- re-parameterizationの適用
- 近年研究されているRepVGGなどと同じ手法の適用
- ラベル割り当て戦略の最適化
- 近年研究されているOTAなどに関する部分
- 本論文では、Auxiliary Lossと併用したラベル割り当てを検討
それぞれ詳細を見ていきましょう!
モデル構造の全体観
詳細の前に、モデル構造の全体観を把握しておきます。
モデル規模により多少変動しますが、YOLOv7-無印など典型的な場合では以下のような構成になっています。

3段階に分かれるピラミッド構造を持ちます。
色のついた四角はそれぞれの出力されるデータ、矢印はそれらを変換する複数のconv層とみなしてください。
一番左側の青色ピラミッド構造は、入力画像を最初に処理するピラミッドです。
- C1⇒C5と番号が増えるに従って、より入力画像の縮小した特徴量マップとなります。
- また番号が増えるにしたがって、よりノード数(チャンネル数)の多い特徴量となります。
次のオレンジ色ピラミッド構造は、アップサンプリングをするピラミッドです。
- こちらはP5⇒P3と番号が減るにしたがって、画像が拡大された特徴量マップとなります。
- また、途中でC4,C3などの青色ピラミッドの途中の特徴量マップを混合します。
最後の緑色ピラミッド構造は再度縮小処理をするピラミッドです。
- これにより、N4~N5が作成されます。
最終的にはP3, N4, N5の特徴量マップを使い、3種類の解像度で検出処理を行います。
YOLOv7は、アンカーボックスを使用する方式ですので、この3種類の解像度の特徴量マップに対して、
それぞれ3つのanchor boxを割り当てています。
(上記は、YOLOv7-無印をベースにした場合で、最も規模の大きいモデルは4種類の解像度を使用します)
ELAN, E-ELANアーキテクチャ
前節の全体観の図でいうところの矢印にあたる変換処理、
その一つ一つがELANもしくはE-ELANで構成されます。
この部分がYOLOv7のアーキテクチャの根幹と言ってよいと考えられます。
(実装を見る限り、これ以外の工夫点は、一部のモデルにしか適用されていないため)
ELANは、より分岐が増えたconcatenateベースのネットワークという位置づけのものです。
ELANおよびE-ELANは論文では以下の図の(c)(d)で表されています。
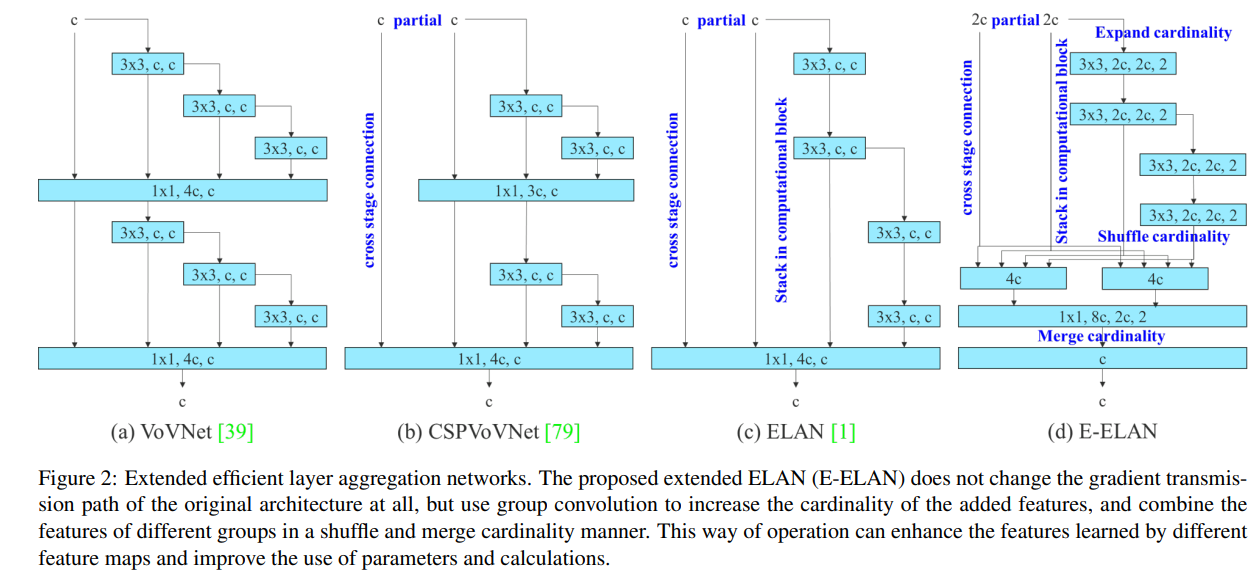
ELANの詳細
論文の図では細部が分からなかったため、実装から一部を書き下してみました。
以下がYOLOv7-無印のC5を出力する矢印の構造になります。

このブロックの#43~#49がELANに該当します。
このように4つに分岐させることで、ひとつひとつの畳み込みのチャネル数を少なくすることが
可能になっています。
これによりYOLOv7は高速な処理が可能と考えられます。
またこの図の#45~#48をcomputational blockと呼ばれます。
E-ELANの詳細
次に、E-ELANですが、こちらは公開されている中でもっとも複雑なモデルである
YOLOv7-E6Eにのみ使用されています。
同様に、YOLOv7-E6EのC5を出力する構造を実装から書き下してみました。

要するに、E-ELANではELANが2つの構成になり、2つのELANが最終的にaddで混合されている形となります。
より精度を向上させるためには、E-ELAN側を使用する形となっていそうですが、
適用されているのはYOLOv7-E6Eのみですので、注意が必要です。
補足
この論文のポイントですが、実際にはELANは従来技術として扱われ、E-ELANが提案手法として扱われています。
ELANは参考文献としては以下のように書かれています。
[1] anonymous. Designing network design strategies. anonymous submission, 2022. 3
GitHubのIssueでも、別の論文があるように記述されています。
ELAN paper will be released after accept at the latest.
詳細は、続報を待つ必要がありそうですが、現状の実装はELAN, E-ELANともに
YOLOv7の主要なアーキテクチャとなっています。
複合スケーリングの提案
YOLOv7では、concatenateベースのネットワークに適した複合スケーリング方法が提案されています。
複合スケーリングは、EfficientNetなどでも登場する概念で、モデルをスケーリングする際に
その一部だけではなく、モデルのdepth(層数)とwidth(ノード数)などの、全体を同時に
スケーリングさせる手法のことです。
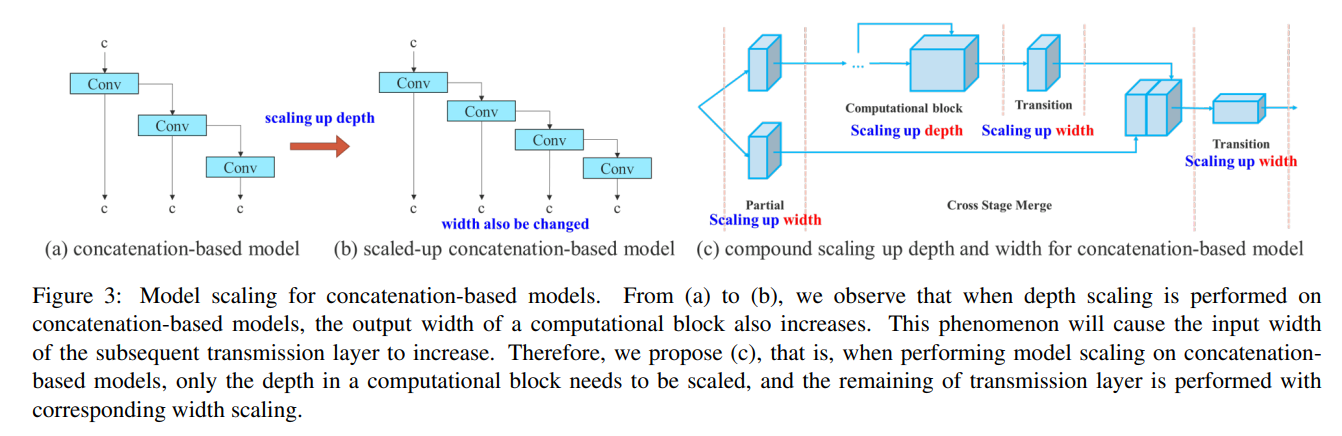
concatenateベースの場合、上記の図(a)⇒(b)のように、depthを増やすと自動的にwidthも増加してしまいます。
そのため本論文では、depthのファクターはcomputational blockを変化させるファクターとして考え、
computational block以外の畳み込みのノード数をwidthにより変化させるファクターとして、
複合スケーリングを提案しています。
具体的な評価結果としては以下の表で示されています。
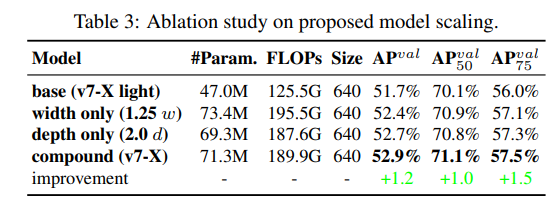
compoundが論文での提案手法になります。
実際には、depthを1.5倍するのに対してwidthを1.25倍にするという倍率でスケールさせているようです。
具体的に上記のスケールは、YOLOv7-無印に対するYOLOv7-Xがそれに該当します。
以下にYOLOv7-XのC5を出力する構造を書き出してみました。

YOLOv7-無印と比較すると、#45,#46,#47や#58などの部分のconv層のチャネル数が1.25倍となっています。
こちらがwidthのスケーリングになります。
またYOLOv7-無印と比較すると、#55,#56が増えています。こちらがdepthのスケーリングになります。
re-parameterizationの適用
re-parameterizationについて
re-parameterizationは、近年研究されているRepVGGなどに代表される手法になります。
より詳しくは、以下の論文に記載されています。
理論としては、この文献にある以下の図が良い説明となっています。
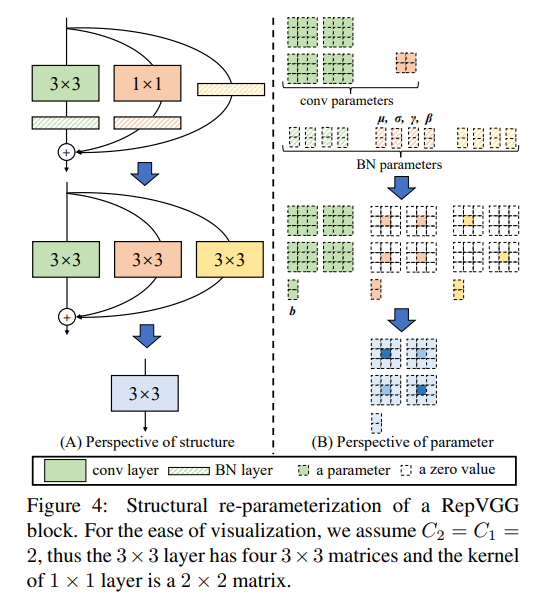
re-parameterizationは、学習時は推論時と別の構造を持つネットワークを学習します。
図でいうところの(A)の一番上の構造が、学習時の構造です。
そして推論時は同等の計算を(A)の一番下の構造に置き換えて推論します。
置き換えは以下の流れで行うことができます。
- BatchNormlizationは、offsetを調整し、scaleを乗算する演算のため、convのbiasとconv1x1の係数に置き換えが可能
- さらにconv1x1の係数は、周囲を0で埋めれば、conv3x3の係数におきかえることが可能
- 以上により、図のすべての接続は、conv3x3のbias付きconv層に置き換えが可能 (それを表したのが中段の部分になります)
- 最後にそれぞれの係数を加算すれば、一つのconv3x3のbias付きconv層に置き換えが可能
YOLOv7におけるre-parameterization
YOLOv7の論文では、以下のような記述があり、最終的にはidentity connection無しの構造にしたいようです。
(先ほどの図でいう黄色の接続のない構造)
After analyzing the combination and corresponding performance of RepConv and different architectures, we find that the identity connection in RepConv destroys the residual in ResNet and the concatenation in DenseNet, which provides more diversity of gradients for different feature maps. For the above reasons, we use RepConv without identity connection (RepConvN) to design the architecture of planned re-parameterized convolution. In our thinking, when a convolutional layer with residual or concatenation is replaced by re-parameterized convolution, there should be no identity connection.
これをRepConvNと呼んでいるようですが、現状のソースコードでは通常のRepConvのみが導入されています。
またRepConv自体も、YOLOv7-無印の最終部分の畳み込みにのみ使用されていますので、
この点もご注意が必要です。
まだYOLOv7は公開されたばかりですので、この点は今後アップデート等が実施されるかもしれません。
ラベル割り当て戦略の最適化
YOLOv7では、ラベル割り当て戦略の検討として、Auxiliary Lossも同時に考慮している点が特徴です。
ラベル割り当て戦略について
ベースのラベル割り当て戦略は、OTAを使用しています。
OTAの論文は以下になります。
OTAは、ground truthをどのgridからのbounding boxに割り当てるかを、
最適輸送(Optimal Transport)問題で解く手法です。
最適輸送問題におけるsupplierをground truth、demanderを各gridの推定結果とします。
そして輸送コストをロス関数として、Sinkhorn-Knopp法などで、最適輸送問題を解きます。
最適輸送問題は、総供給量と総需要量が等しい必要があるため、backgroundラベル用のsupplierも準備します。
Auxiliary Lossについて
Auxiliary Loss自体は近年のものではなく、2014年のGoogLeNetのアーキテクチャでも登場しています。
Auxiliary Lossは、層の途中に最終出力と同じ形状を得るためのheadを付与することで、
ここでも推論ができるようにします。
この推論結果と正解から求められるロスを補助的なロスとして考慮する手法です。
YOLOv7の実装では、Auxiliary Lossに0.25の係数をかけて、もともとのLossに加算して使用します。
YOLOv7におけるラベル割り当て戦略
まず、論文内でAuxiliary Lossは、以下の図の(b)として表現されています。
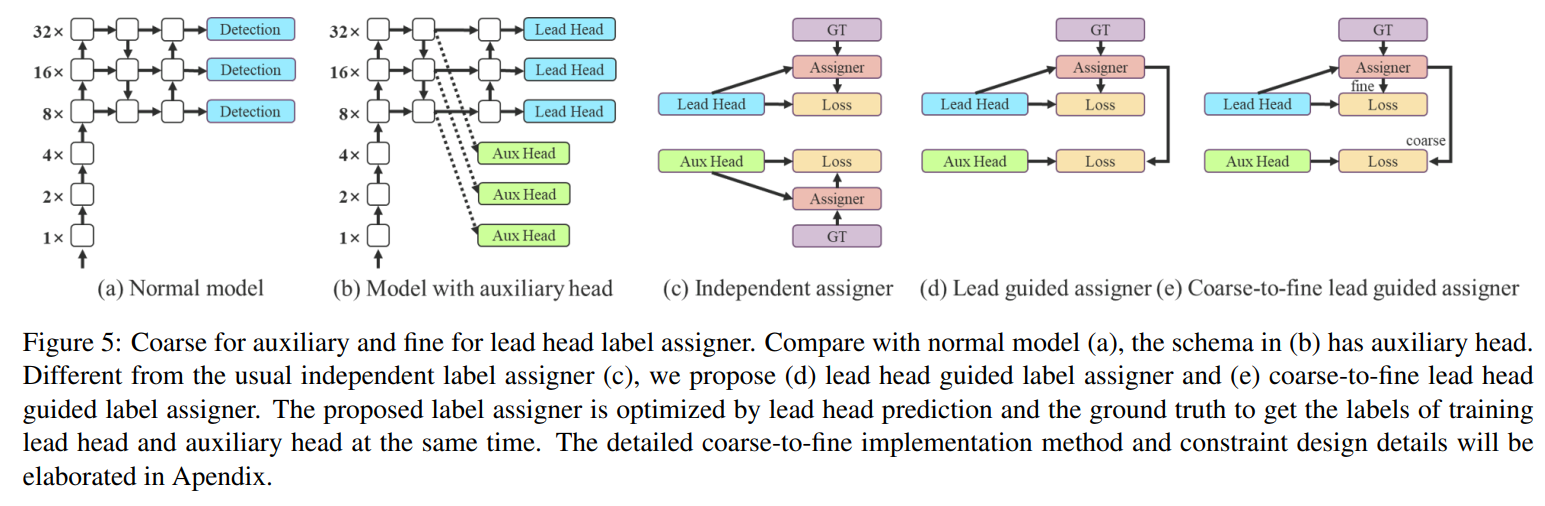
YOLOv7では実際に、冒頭にお示ししたピラミッド構造のP5,P4,P3などに対して、
convを接続してAuxiliary Lossを計算できるようにします。
これをAux Headと呼び、通常の最終のheadをLead Headと呼びます。
最も単純な従来法は、図の(c)のようにAux HeadとLead Headをそれぞれ独立にラベル割り当てを決めます。
本論文の提案手法は、図の(d)(e)となります。
図(d)はAux HeadとLead Head双方ともにLead Head側の割り当て結果を使用する方法です。
図(e)は発展形で、Aux Head側のソフトラベルをより緩和して多くの正例を扱えるようにしたものです。
これにより、表現力の小さいAux Head側が学習すべき情報を見失わないために、
Recallの向上を目的として使用されています。
その他の工夫点
その他、YOLOv7特有ではありませんが、いくつか工夫点が導入されています。
これらについてはそれぞれの論文をご参照ください。
- YOLORと同様のImplicit Knowledgeを使用
- Mean Teacherと同様のExpornential Moving Averageを最終的なモデルとする
まとめ
いかがでしたでしょうか。かなり手法が盛りだくさんですので、
多少元から読んだことがある部分があったものの、整理するのには時間がかかりました。
今後は実装面での解説についてもブログ記事にしていきたいと思います。
本記事が物体検出の理解の助けになれば幸いです。











