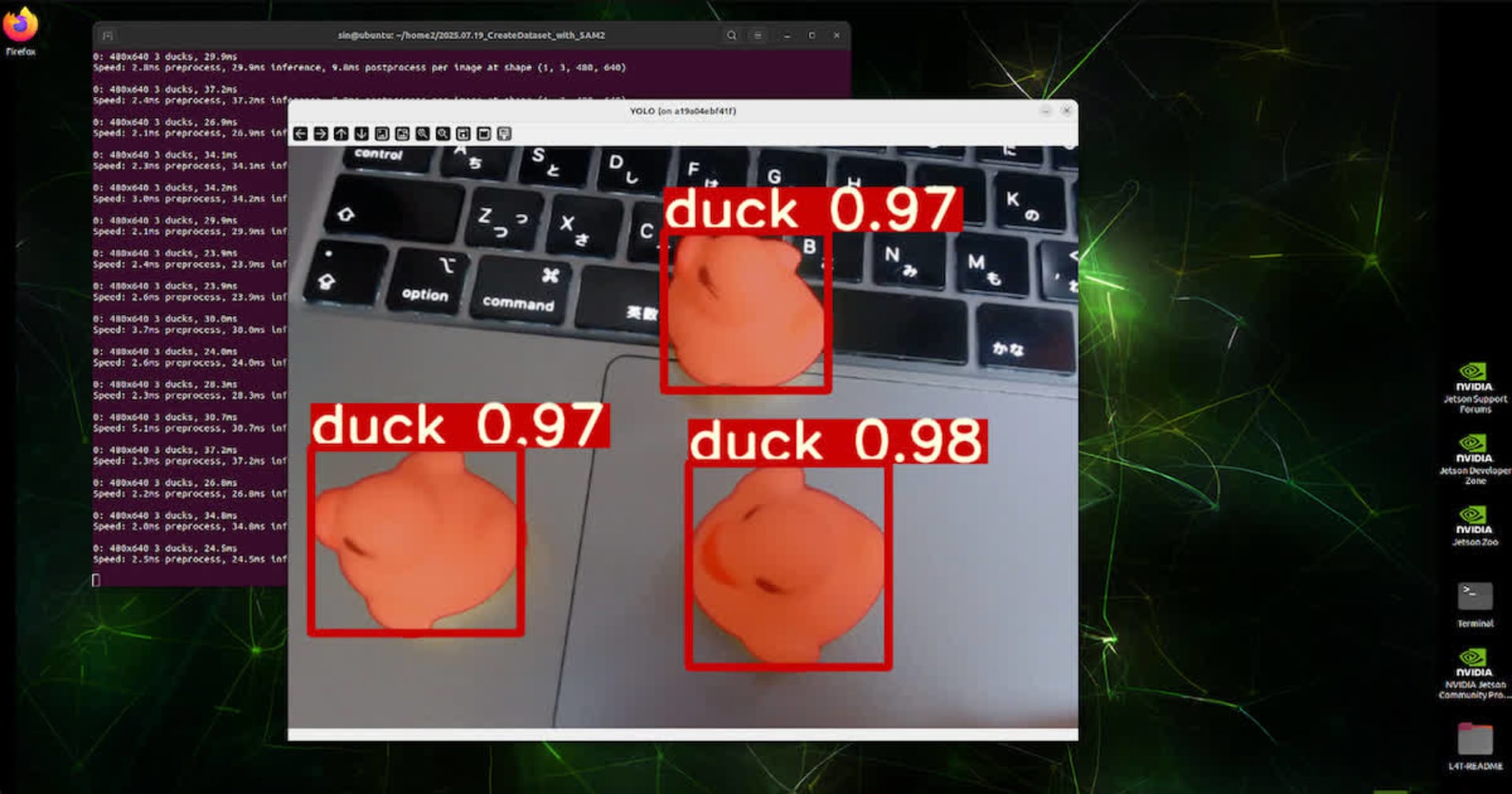
【動画あり】早速YOLOv8を使って自作データセットで物体検出してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
こんちには。
データアナリティクス事業本部 機械学習チームの中村です。
YOLOv8がUltralyticsからリリースされたようです!!!???(以下ブログの日付では2023年1月8日)
Ultralyticsは、広く使われている物体検知のリポジトリのYOLOv5の開発元です。
YOLOv8にも期待が高まりますね!!
リポジトリは以下のようです。
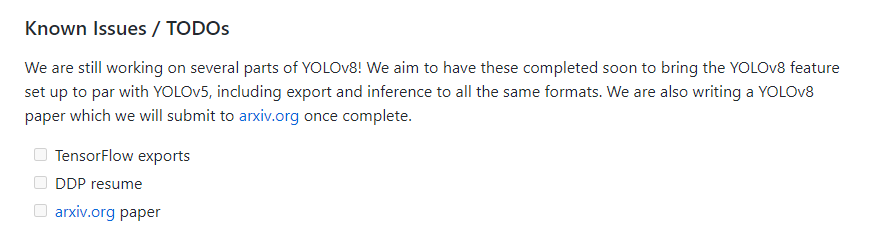
論文はリポジトリ上で以下のようにTODOとなっており存在しないようですので、続報を待ちたいと思います。
本記事では以前YOLOv7のときに使用したオレンジアメのデータセットで、
物体検出をチューニングし動かしてみたいと思います。
データセットや以前のYOLOv7の詳細は以下の記事もご覧ください。
動作環境
今回はGoogle Colaboratory環境で実行しました。
ハードウェア情報は以下の通りです。
- GPU : Tesla T4, メモリ15GB
- メモリ : 13GB
主なソフトウェア・ライブラリのバージョンは以下となります。
- Python : 3.8.16
- CUDA : 11.2
- PyTorch : 1.13.0+cu116
環境の構築と確認
以下2種類の構築方法があるようです。
- pipのみでインストール方法
- リポジトリをクローンしてpipで構築する方法
今回はWarning等で結果が見えにくかったため、リポジトリからクローンする方法を選択しました。
正式には、pipのみで構築する方が良さそうなので、今後のアップデートを待ちます。
# Warningがでるため今回は不使用 # !pip install ultralytics # Git clone method (for development) !git clone https://github.com/ultralytics/ultralytics %pip install -qe ultralytics
記録としてclone時のコミットを以下に残しておきます。
Commit: 2bc36d97ce7f0bdc0018a783ba56d3de7f0c0518 Parents: 12c87ac00c31f0682a3ff96cb3a08570ea4a58bf Author: Glenn Jocher <glenn.jocher@ultralytics.com> Committer: Glenn Jocher <glenn.jocher@ultralytics.com> Date: Fri Jan 13 2023 02:07:33 GMT+0900 (日本標準時) Created using Colaboratory
インストール後はyoloというコマンドが実行可能となります。
試しにサンプルのpredictを動かしてみます。
!yolo task=detect mode=predict model=yolov8n.pt \
source="https://ultralytics.com/images/bus.jpg"
以下のように結果が出力されました。
Downloading https://ultralytics.com/images/bus.jpg to bus.jpg... 100% 476k/476k [00:00<00:00, 108MB/s] Ultralytics YOLOv8.0.5 ? Python-3.8.16 torch-1.13.0+cu116 CUDA:0 (Tesla T4, 15110MiB) Downloading https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt to yolov8n.pt... 100% 6.24M/6.24M [00:00<00:00, 282MB/s] Fusing layers... YOLOv8n summary: 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs image 1/1 /content/bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 14.0ms Speed: 0.5ms pre-process, 14.0ms inference, 36.7ms postprocess per image at shape (1, 3, 640, 640) Results saved to runs/detect/predict
1画像あたり14.0msで推論できています。ちなみにCPUの場合は288.3msでした。
推論結果の画像を出力してみます。
from IPython.display import Image
Image("runs/detect/predict/bus.jpg")

環境構築は無事にできていそうです。
データセットの準備
こちらは以下の記事で準備したデータセットを使います。
データは以下のパスに配置したとします。
./dataset/candy/train ./dataset/candy/valid ./data.yaml
データセットの内容を表すdata.yamlも前回同様以下のように記述します。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/] train: ./dataset/candy/train val: ./dataset/candy/valid # number of classes nc: 2 # class names names: ['melon-soda', 'orange']
ちなみにdata.yamlの拡張子をymlにすると、ネットワーク経由でデータセットの取得に行ってしまうため注意が必要です。
学習の実行
以下で実行できます。3000エポックで回してみました。
# Train YOLOv8n on COCO128 for 3 epochs !yolo task=detect mode=train model=yolov8n.pt data=data.yaml epochs=300 imgsz=640
ログは以下のように出力されました。
Ultralytics YOLOv8.0.5 ? Python-3.8.16 torch-1.13.0+cu116 CUDA:0 (Tesla T4, 15110MiB)
yolo/engine/trainer: task=detect, mode=train, model=yolov8n.pt, data=data.yaml, epochs=300, patience=50, batch=16, imgsz=640, save=True, cache=False, device=, workers=8, project=None, name=None, exist_ok=False, pretrained=False, optimizer=SGD, verbose=False, seed=0, deterministic=True, single_cls=False, image_weights=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, show=False, save_txt=False, save_conf=False, save_crop=False, hide_labels=False, hide_conf=False, vid_stride=1, line_thickness=3, visualize=False, augment=False, agnostic_nms=False, retina_masks=False, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=17, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, fl_gamma=0.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0, cfg=None, hydra={'output_subdir': None, 'run': {'dir': '.'}}, v5loader=False, save_dir=runs/detect/train
Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...
100% 755k/755k [00:00<00:00, 75.0MB/s]
Overriding model.yaml nc=80 with nc=2
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.C2f [64, 64, 2, True]
5 -1 1 73984 ultralytics.nn.modules.Conv [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.C2f [128, 128, 2, True]
7 -1 1 295424 ultralytics.nn.modules.Conv [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.SPPF [256, 256, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.Concat [1]
12 -1 1 148224 ultralytics.nn.modules.C2f [384, 128, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.Concat [1]
15 -1 1 37248 ultralytics.nn.modules.C2f [192, 64, 1]
16 -1 1 36992 ultralytics.nn.modules.Conv [64, 64, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.Concat [1]
18 -1 1 123648 ultralytics.nn.modules.C2f [192, 128, 1]
19 -1 1 147712 ultralytics.nn.modules.Conv [128, 128, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.Concat [1]
21 -1 1 493056 ultralytics.nn.modules.C2f [384, 256, 1]
22 [15, 18, 21] 1 751702 ultralytics.nn.modules.Detect [2, [64, 128, 256]]
Model summary: 225 layers, 3011238 parameters, 3011222 gradients, 8.2 GFLOPs
Transferred 319/355 items from pretrained weights
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias
train: Scanning /content/dataset/candy/train/labels... 12 images, 0 backgrounds, 0 corrupt: 100% 12/12 [00:00<00:00, 416.79it/s]
train: New cache created: /content/dataset/candy/train/labels.cache
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
val: Scanning /content/dataset/candy/valid/labels... 6 images, 0 backgrounds, 0 corrupt: 100% 6/6 [00:00<00:00, 361.86it/s]
val: New cache created: /content/dataset/candy/valid/labels.cache
Image sizes 640 train, 640 val
Using 2 dataloader workers
Logging results to runs/detect/train
Starting training for 300 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/300 2.17G 1.256 3.881 1.284 209 640: 100% 1/1 [00:03<00:00, 3.78s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100% 1/1 [00:01<00:00, 1.58s/it]
all 6 33 0.00296 0.103 0.00223 0.00132
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/300 2.61G 1.507 3.909 1.395 275 640: 100% 1/1 [00:01<00:00, 1.17s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100% 1/1 [00:00<00:00, 2.20it/s]
all 6 33 0.00254 0.0862 0.0022 0.00155
... (中略) ...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
300/300 8.5G 0.5368 0.5396 0.8365 178 640: 100% 1/1 [00:00<00:00, 1.45it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100% 1/1 [00:00<00:00, 2.29it/s]
all 6 33 0.991 0.983 0.993 0.896
300 epochs completed in 0.164 hours.
Optimizer stripped from runs/detect/train/weights/last.pt, 6.3MB
Optimizer stripped from runs/detect/train/weights/best.pt, 6.3MB
Validating runs/detect/train/weights/best.pt...
Ultralytics YOLOv8.0.5 ? Python-3.8.16 torch-1.13.0+cu116 CUDA:0 (Tesla T4, 15110MiB)
Fusing layers...
Model summary: 168 layers, 3006038 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100% 1/1 [00:00<00:00, 2.37it/s]
all 6 33 0.999 0.98 0.993 0.9
melon-soda 6 4 1 0.995 0.995 0.933
orange 6 29 0.999 0.966 0.991 0.867
Speed: 0.3ms pre-process, 3.7ms inference, 0.0ms loss, 4.4ms post-process per image
Saving runs/detect/train/predictions.json...
Results saved to runs/detect/train
結果は以下に格納されます。
!ls -l runs/detect/train/weights/best.pt
-rw-r--r-- 1 root root 6258168 Jan 13 07:37 runs/detect/train/weights/best.pt
テスト動画による動作確認
以下に動画ファイルを格納します。
./dataset/candy/test
そして推論を以下で実行します。
!yolo task=detect mode=predict model=runs/detect/train/weights/best.pt conf=0.25 \
source="dataset/candy/test"
Ultralytics YOLOv8.0.5 ? Python-3.8.16 torch-1.13.0+cu116 CUDA:0 (Tesla T4, 15110MiB) Fusing layers... Model summary: 168 layers, 3006038 parameters, 0 gradients, 8.1 GFLOPs video 1/1 (1/619) /content/dataset/candy/test/2022-07-09_09-54-05.mp4: 384x640 12.6ms video 1/1 (2/619) /content/dataset/candy/test/2022-07-09_09-54-05.mp4: 384x640 1 orange, 7.9ms ... (中略) ... video 1/1 (618/619) /content/dataset/candy/test/2022-07-09_09-54-05.mp4: 384x640 2 melon-sodas, 11 oranges, 8.6ms video 1/1 (619/619) /content/dataset/candy/test/2022-07-09_09-54-05.mp4: 384x640 2 melon-sodas, 10 oranges, 12.1ms Speed: 0.4ms pre-process, 8.6ms inference, 1.2ms postprocess per image at shape (1, 3, 640, 640) Results saved to runs/detect/predict4
30fpsで約20秒の動画だったので、600枚程度の画像が処理されています。
以下がその結果の動画になります。

まとめ
いかがでしたでしょうか。
まだリリースされたばかりなので、とりあえずカスタムデータセットを1トライ学習するところだけをやってみました。
今までのYOLOv5やYOLOv7などと使用感は同じ感じで使えそうですね。
今後は比較検証やチューニング、YOLOv8の具体的な変更点などにもフォーカスした記事を出せたらと思います。
いますぐYOLOv8を試してみたいという方の参考になれば幸いです。