Since we received spike access from AI, we tried to take measures that don't exclude AI as much as possible, such as adjusting robots.txt
This article was published more than one year ago. Please be aware that the information may be outdated.
This page has been translated by machine translation. View original
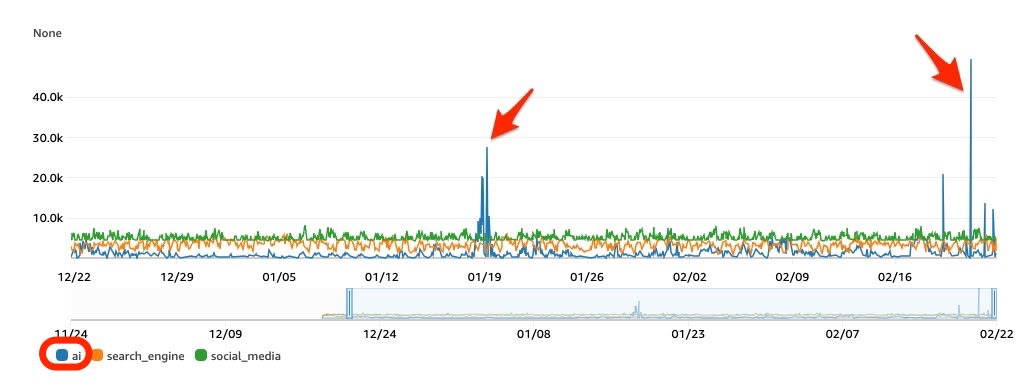
A spike in Bot Control rule of AWS WAF was observed in the AI category.
Requests to dynamically generated article pages reached 50,000 per hour, with peaks of 1,500 per minute.
I'll introduce the investigation into the cause of these requests, which were comparable to the total number of articles (over 50,000) published on our site, and the countermeasures we implemented.
CloudWatch Metrics Analysis
We analyzed AWS WAF metrics to identify the cause.
Surge in bot:category AI
Requests in the AI category increased significantly to 50,000 per hour.
No major fluctuations were observed in other categories (search_engine: Google, Bing, etc., social_media: X, Facebook, etc.).
- LabelNamespace="awswaf:managed:aws:bot-control:bot:category"
- LabelName="ai",search_engine, social_media
bot:name claudebot
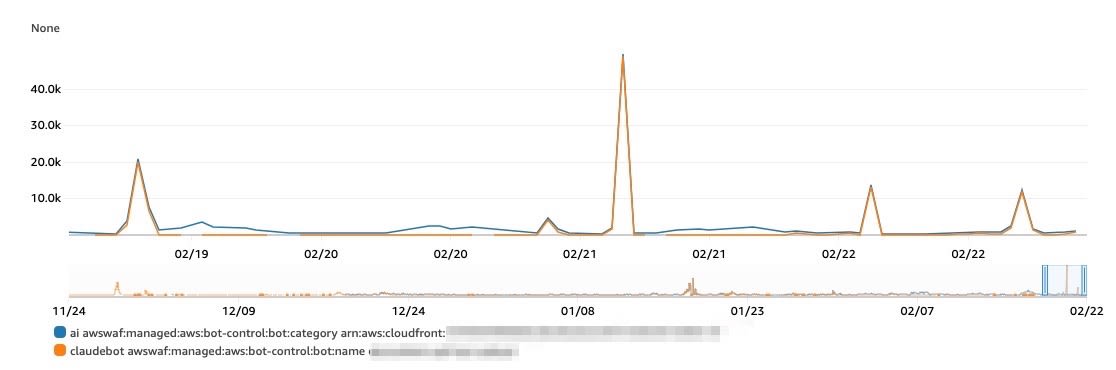
During the surge, the "AI" category matched with the bot:name "ClaudeBot".
This led us to determine that the spike was due to requests from Anthropic.
- LabelNamespace="awswaf:managed:aws:bot-control:bot:name"
- LabelName="claudebot"
Access Log Analysis
For more detailed analysis and consideration of countermeasures, we analyzed CloudFront access logs (standard access logs v2) stored in CloudWatch Logs using Logs Insights.
IP and UserAgent Summary
We identified IP addresses with ClaudeBot UserAgent during the surge period.
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"c-ip\":\"(?<clientip>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| parse @message /\"x-edge-response-result-type\":\"(?<edge_response_result_type>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by clientip,useragent
| sort request_count desc
| limit 10000
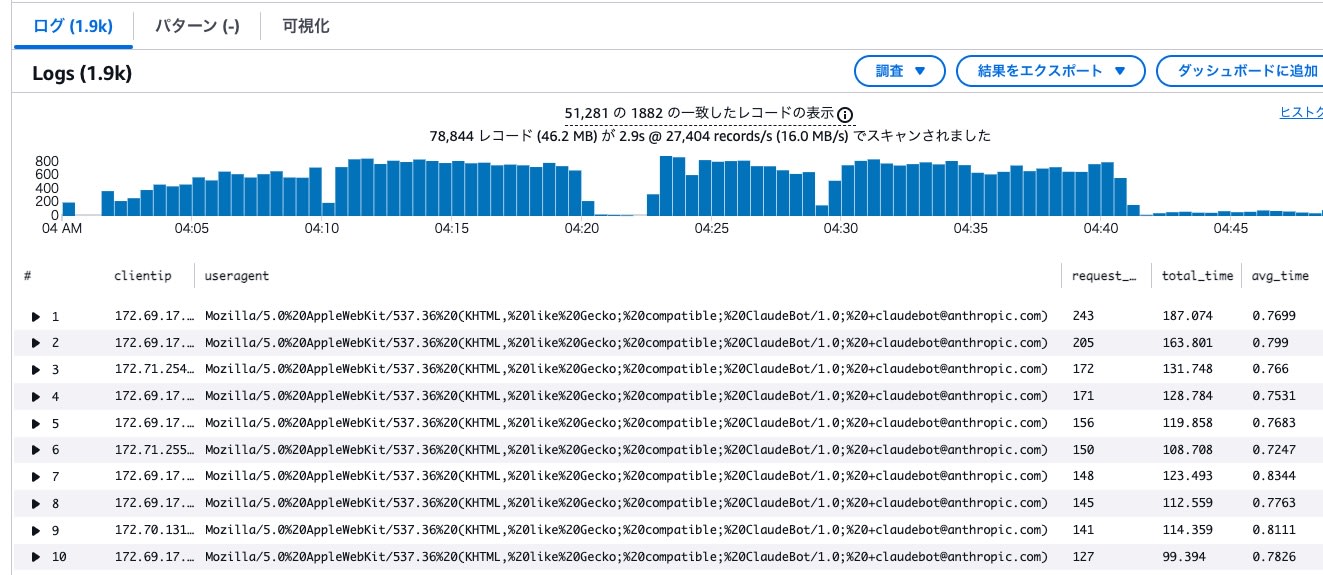
- 1,888 IP addresses were recorded
- Each IP address generated approximately 100-200 requests
Concurrent IP Access
We checked the number of unique IP addresses per second for ClaudeBot logs.
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"c-ip\":\"(?<clientip>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| stats count(*) as total_requests,
count_distinct(clientip) as unique_ips
by bin(1s)
| sort by unique_ips desc
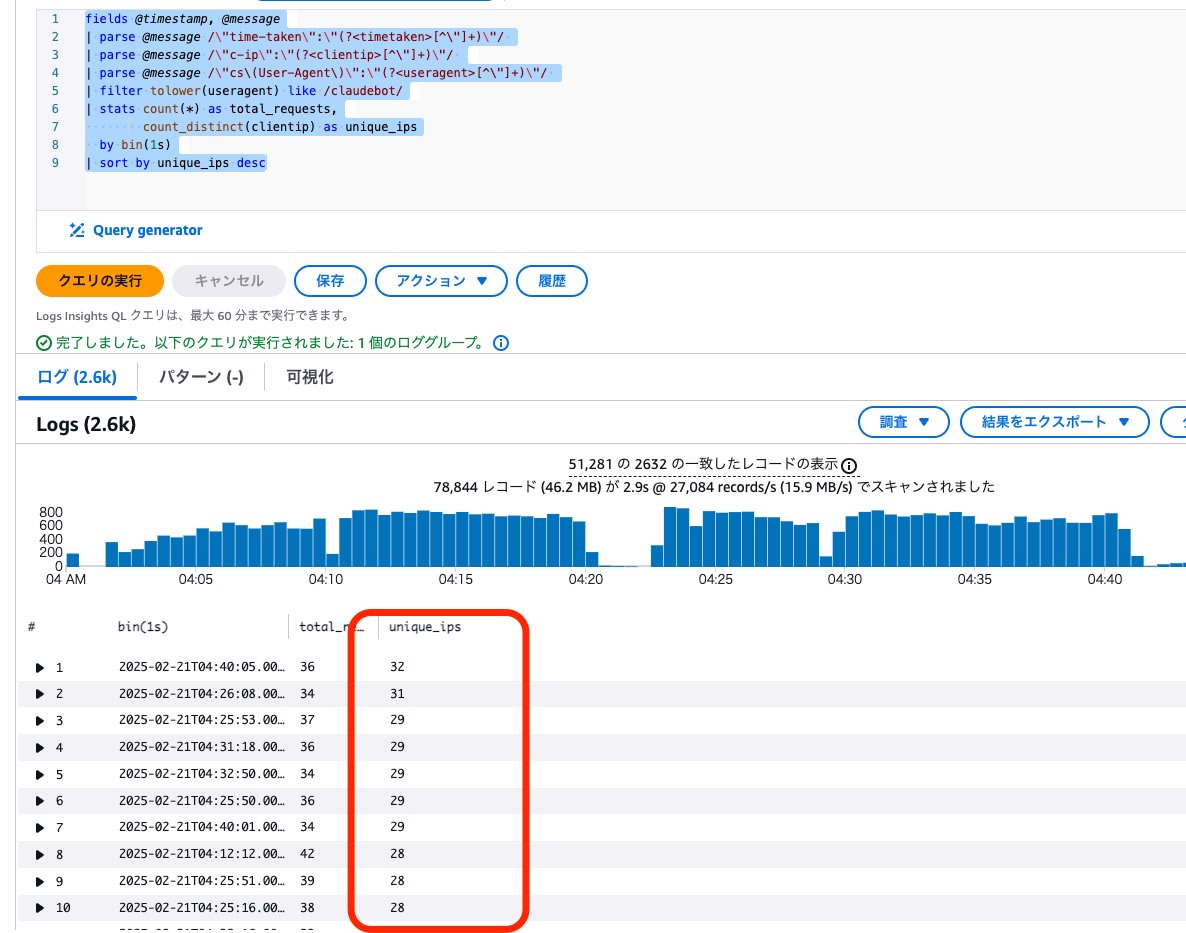
- A maximum of 32 unique IP addresses accessed simultaneously, suggesting requests were made with parallelism of around 30.
URL Summary
We attempted to check the requested URIs.
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| parse @message /\"cs-uri-stem\":\"(?<uri>[^\"]+)\"/
| parse @message /\"sc-status\":\"(?<status>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by uri,useragent, status
| sort total_time desc
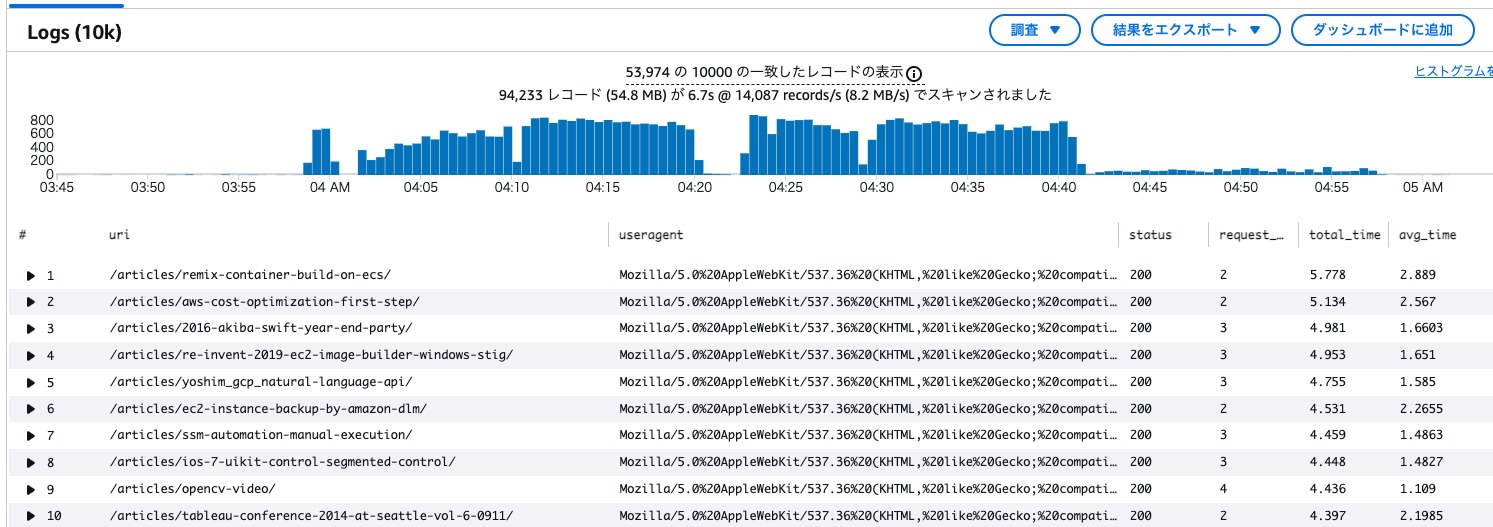
- 25,000 requests to regular article pages were confirmed.
x_host_header Summary
Since multiple accesses to the same articles were confirmed, we attempted to aggregate by request destination host (host header).
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| parse @message /\"x-host-header\":\"(?<x_host_header>[^\"]+)\"/
| parse @message /\"sc-status\":\"(?<status>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by x_host_header,useragent, status
| sort total_time desc
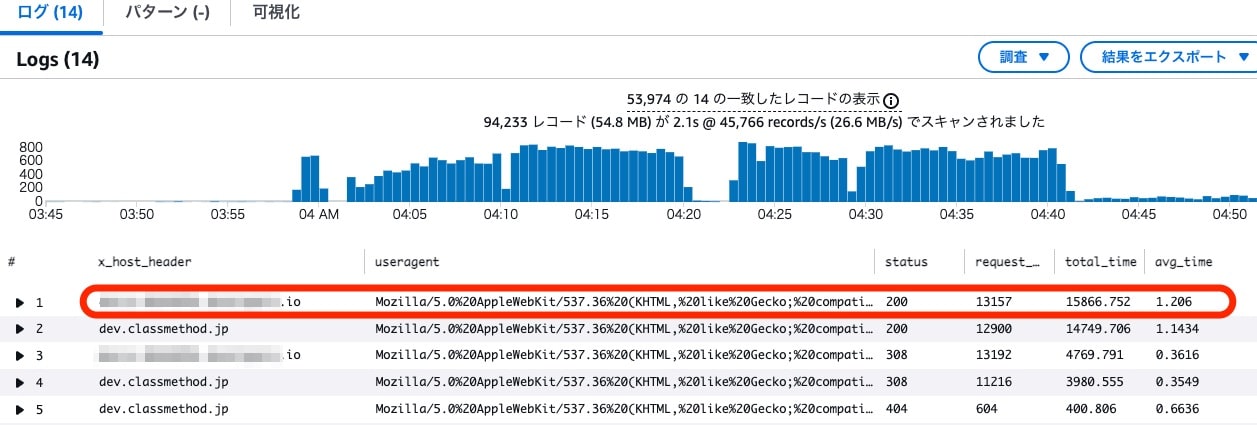
We confirmed requests with hostnames different from the public URL hostname.
Individual Requests
We identified IP addresses with "claudebot" in the UserAgent and checked their request contents.
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"c-ip\":\"(?<clientip>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| filter clientip like /172.71.##.##/
| limit 100
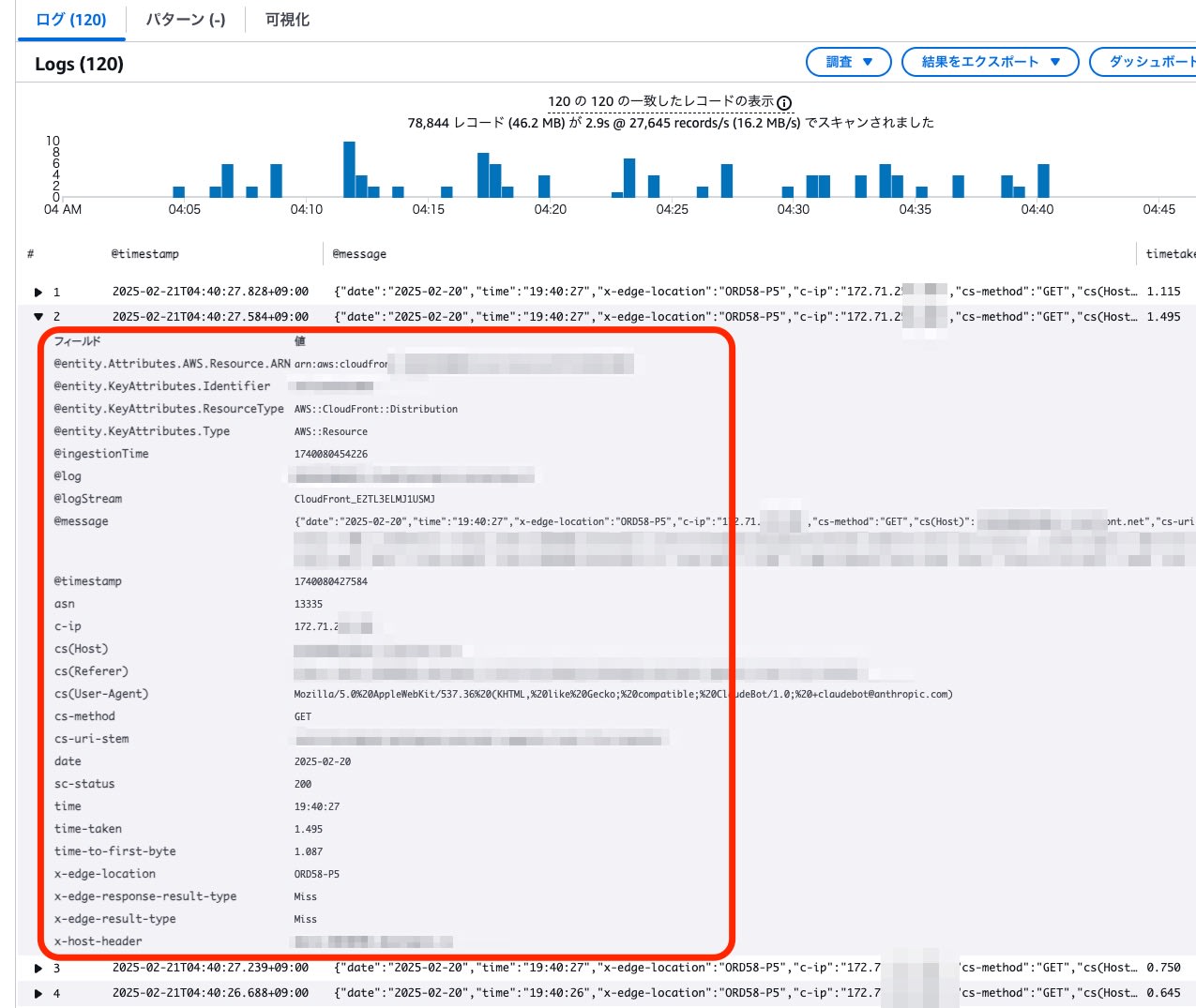
- Approximately 10 requests per minute from a single IP address
Countermeasures
robots.txt
Following Anthropic's guidelines, we added a setting to robots.txt requesting a 1-second crawl delay (Crawl-delay) to suppress excessive crawling.
$ curl -s https://dev.classmethod.jp/robots.txt | grep 'Crawl-delay:'
Crawl-delay: 1
We support the non-standard Crawl-delay extension in robots.txt to limit crawling activity. For example:
User-agent: ClaudeBot
Crawl-delay: 1Is Anthropic crawling data from the web, and how can site owners block crawlers?
Alternative Domain
About half of the spike requests were to an alternative URL, not the regular public FQDN. This alternative URL was used for verification by related parties before service launch and for external monitoring after launch.
Previously, we had set "x-robots-tag: noindex".
< HTTP/2 200
< date: Fri, 21 Feb 2025 **:**:** GMT
< content-type: text/plain
(...)
< x-robots-tag: noindex
As it was ineffective for AI crawlers, we adjusted the Cloudflare rule to 301 redirect to the regular site.
< HTTP/2 301
< date: Fri, 21 Feb 2025 **:**:** GMT
< content-type: text/html
(...)
< location: https://dev.classmethod.jp/
After the number of redirects stabilizes, we plan to discontinue the FQDN.
Block
Using AWS WAF's rate rules and custom keys, it's possible to block requests if a certain number occur within a specified period.
Currently, we aim to avoid blocking as much as possible, but in case robots.txt has no effect and spike access continues, we prepared the following rule to add to AWS WAF ALCs:
- Rate limiting using bot-control judgment label (Block activates at over 100 per minute)
{
"Name": "rate-limit-claudebot",
"Priority": 250,
"Statement": {
"AndStatement": {
"Statements": [
{
"LabelMatchStatement": {
"Scope": "LABEL",
"Key": "awswaf:managed:aws:bot-control:bot:name:claudebot"
}
},
{
"RateBasedStatement": {
"Limit": 100,
"AggregateKeyType": "CUSTOM_KEYS",
"CustomKeys": [
{
"Type": "LABEL_NAMESPACE",
"Key": "awswaf:managed:aws:bot-control:bot:name"
}
],
"TimeWindow": 60
}
}
]
}
},
"Action": {
"Block": {}
},
"VisibilityConfig": {
"SampledRequestsEnabled": true,
"CloudWatchMetricsEnabled": true,
"MetricName": "RateLimitClaudeBotRule"
}
}
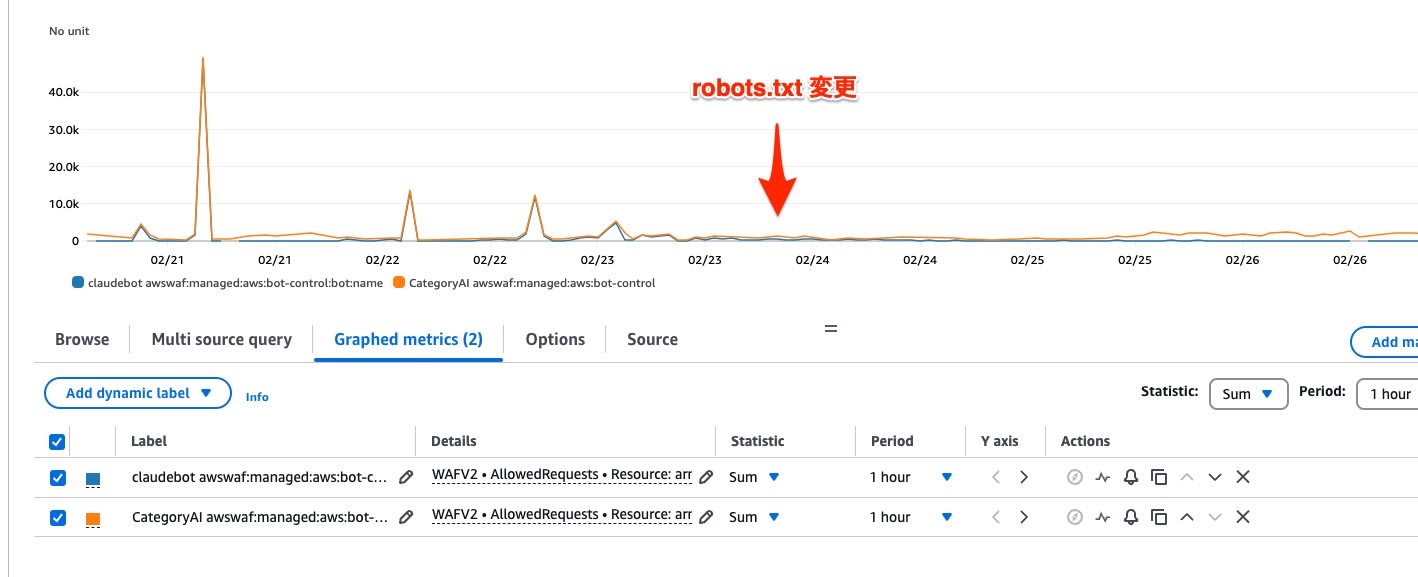
Effect (2/27 Update)
After updating robots.txt, the number of requests from ClaudeBot decreased to around 20-50 per hour.
On social media, a case was shared where iFixit received millions of requests from ClaudeBot and addressed it using robots.txt.
Proper robots.txt configuration appears effective in controlling ClaudeBot crawling.
Summary
While it's easy to configure AWS WAF to exclude AI agents, our site avoids blocking measures as much as possible because it could remove our article content from AI-powered search results or prevent the latest updates from being reflected, potentially disadvantaging both readers and writers.
This time, we attempted to control crawl frequency using robots.txt, but we've also prepared "llms.txt" with instructions for LLMs (Large Language Models) to guide AI crawlers.
Additionally, this spike access revealed areas for infrastructure improvement. Future measures include optimizing backend systems, using CloudFront VPC support to prevent direct access to the origin, advanced AWS WAF configurations, and other comprehensive approaches to enhance overall system robustness.