
AWS CDK で DynamoDB のグローバルセカンダリインデックス(GSI)を使ってみた

こんにちは!製造ビジネステクノロジー部の小林です。
最近、DynamoDB のグローバルセカンダリインデックス(GSI)に触れる機会がありました。これまで DynamoDB はあまり触ったことがなかったのでこれを機に勉強してみました。
グローバルセカンダリインデックス(GSI)とは?
DynamoDBテーブルのプライマリキー以外の属性で、クエリを実行するためのインデックスです。テーブル全体にまたがる検索を可能にし、プライマリキーに依存しないデータアクセスパターンを実現する機能です。テーブル作成後でも追加・削除が可能です。
プライマリーキーとは?
DynamoDB ではテーブル内のデータを扱うため、 特定の 1 つの項目を識別する「プライマリキー」を使用します 。このプライマリキーには、以下の2つのタイプがあります。
パーティションキー (Partition Key)
パーティションキーは、DynamoDB で必須の要素です。テーブル内のデータを物理的に保存するパーティションを決定するための主要なキーです。DynamoDB のデータは複数のパーティションに分散して保存されます。このときデータがどのパーティションに保存されるかは パーティションキーの値から計算したハッシュ値を元に配置されます。
例えば以下のテーブルがあるとします。
users テーブル
プライマリキー: userId (パーティションキーのみ)
userId | name | age | address | mailAddress
-------|-----------|-----|----------|-------------
1 | Tanaka | 20 | Tokyo | aaa@co.jp
2 | Suzuki | 30 | Osaka | bbb@co.jp
3 | Takahashi | 40 | Nagoya | ccc@co.jp
4 | Sato | 30 | Fukuoka | ddd@co.jp
5 | Tanaka | 20 | Sapporo | eee@co.jp
この例では、userId がパーティションキーとして機能し、各ユーザーデータがどのパーティションに保存されるかを決定します。
ソートキー (Sort Key)
ソートキーは、DynamoDB でオプションの要素です。ソートキー が設定されている場合、同じパーティションキーを持つアイテム間での並び順を決定します。
また、パーティションキーのみがプライマリキーのテーブルでは、データの取得方法は以下のとおりです。
- GetItem でパーティションキーの値を指定して 1 つの項目を取得
- Scan でテーブルの全ての項目を読み込む
- セカンダリインデックスの使用
GSI が必要になる場面
上記のテーブルでは、userId がパーティションキーとして機能し、各ユーザーを一意に識別します。しかし、以下のような検索要件が発生した場合はどうでしょうか?
- 「年齢が30歳のユーザーを検索したい」
- 「大阪在住のユーザーを検索したい」
- 「メールアドレスからユーザーを特定したい」
プライマリキーが userId のみであるため、これらの検索は Scan 操作が必要になります。
// 年齢が30歳のユーザーを検索したい
const scanParams = {
TableName: 'users',
FilterExpression: 'age = :age',
ExpressionAttributeValues: {
':age': 30
}
};
const result = await dynamodb.scan(scanParams).promise();
// 全5件を読み取ってからフィルタリング(ScannedCount: 5, Count: 2)
Scan とは?
DynamoDBテーブルまたはセカンダリインデックス内のすべてのアイテムを順次読み取り、条件に合うデータを返す操作です。
基本的な動作
- テーブル全体を1件ずつ順番に読み取り
- FilterExpressionで条件を指定可能(ただし読み取り後にフィルタリング)
- 1回の操作で最大1MBのデータまで処理
Scan は条件に関係なく全データを読み取りしてからフィルタリングします。データ量に比例して処理時間とコストが増加するため、大量データでは処理が遅くなってしまいます。このような課題を解決するのが、グローバルセカンダリインデックス(GSI)です。
GSI を CDK で定義してみる
ではAWS CDK で GSI を定義してみます。使用するテーブルは以下です。
GSIでは以下のように設定します。
パーティションキー:age
ソートキー:userId
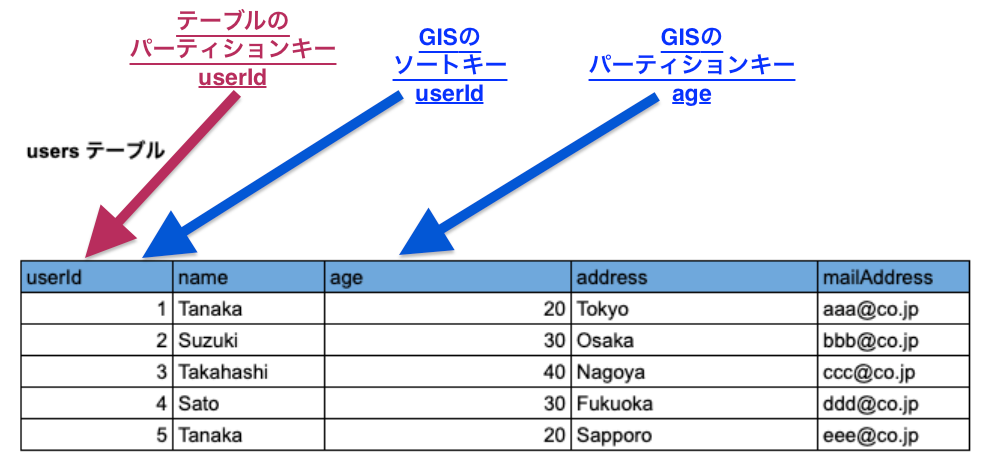
例えば、年齢が30歳のユーザーを検索する GSI を実装すると以下のようになります。
CDK での GSI 定義
/**
* able: DynamoDBテーブルを定義するためのクラス
* AttributeType: DynamoDB属性のデータ型(文字列、数値など)
* BillingMode: 課金モード(オンデマンド、プロビジョニング済み)
*/
import { Table, AttributeType, BillingMode } from 'aws-cdk-lib/aws-dynamodb';
// UsersTable'というIDで、DynamoDBのテーブルリソースを定義
const usersTable = new Table(this, 'UsersTable', {
tableName: 'users', // テーブル名を「users」に設定
partitionKey: { // テーブルのプライマリキーを定義
name: 'userId', // パーティションキーの名前を「userId」
type: AttributeType.NUMBER // データ型を数値に設定
},
billingMode: BillingMode.PAY_PER_REQUEST, // 課金モードをオンデマンド(従量課金)に設定
// グローバルセカンダリインデックス(GSI)を定義
globalSecondaryIndexes: [{
indexName: 'age-userId-index', // インデックス名を「age-userId-index」に設定
// パーティションキーを定義
partitionKey: {
name: 'age',
type: AttributeType.NUMBER
},
// ソートキーを定義
sortKey: {
name: 'userId',
type: AttributeType.NUMBER
}
}]
});
作成後のリソースを確認してみます。
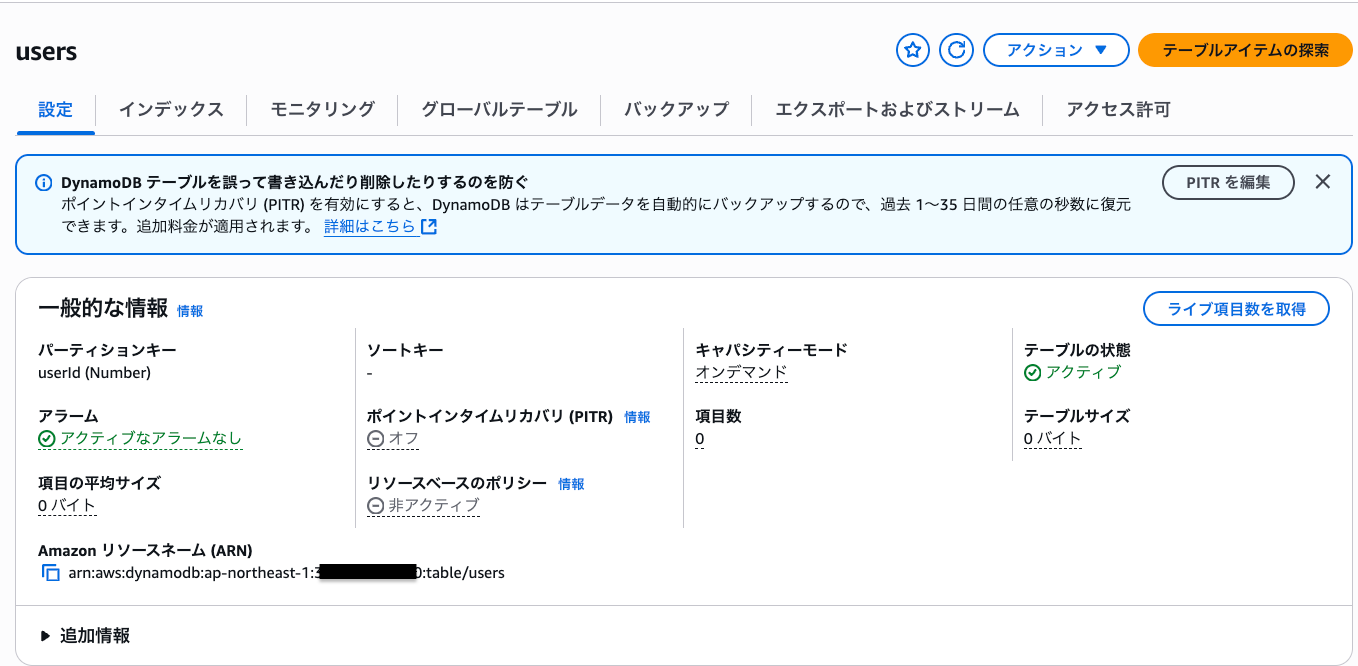
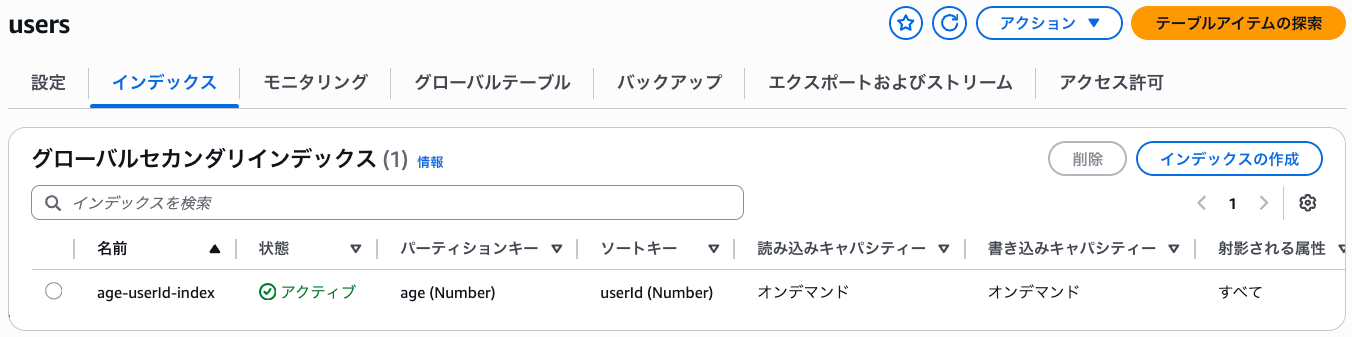
GSI が作成されていますね!
Query実行コード
const queryParams = {
TableName: 'users', // テーブルの指定
IndexName: 'age-userId-index', // GSI を指定
KeyConditionExpression: 'age = :age', // パーティションキーの条件。[age」属性が、後で指定する「:age」という値と等しいことを条件
ExpressionAttributeValues: {
':age': 30 // この例では、ageが30であるアイテムを検索する
}
};
// 特定のuserIdも指定したい場合
const queryWithSortKey = {
TableName: 'users',
IndexName: 'age-userId-index',
KeyConditionExpression: 'age = :age AND userId = :userId', // ソートキーも条件に追加
ExpressionAttributeValues: {
':age': 30,
':userId': 2
}
};
// DynamoDBに対してクエリを実行
const result = await dynamodb.query(queryParams).promise();
GSI構造(パーティション分散イメージ)
GSIを作成すると、元のテーブルとは独立した新しいパーティション構造が作られます。
以下は、元々のパーティション。
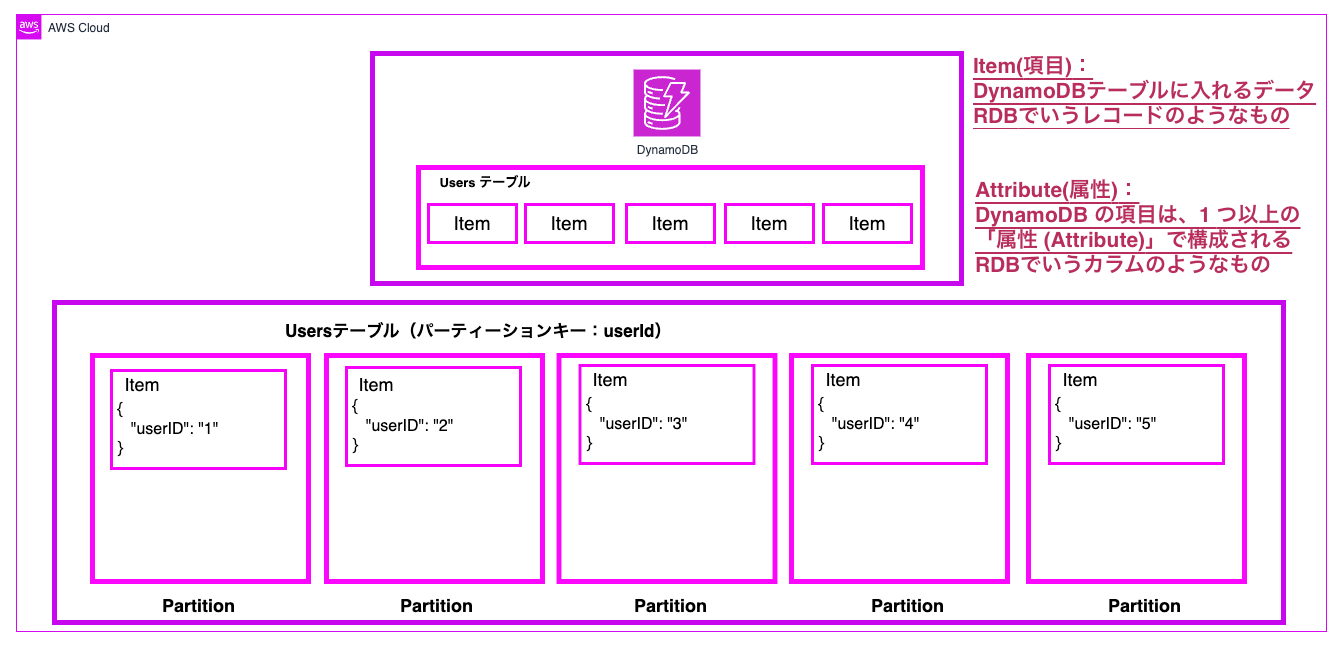
以下は、GSI 実行後に作られた新しいパーティション
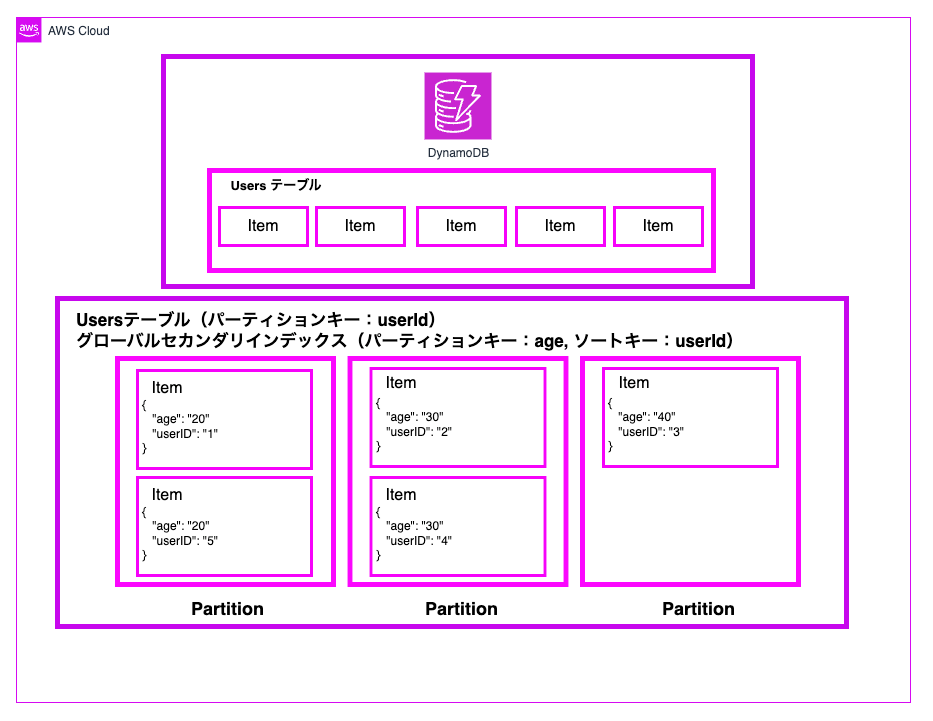
age-userId-index GSI
パーティション1 (age=20)
age | userId | name | address | mailAddress
----|-------|-----------|----------|-------------
20 | 1 | Tanaka | Tokyo | aaa@co.jp
20 | 5 | Tanaka | Sapporo | eee@co.jp
パーティション2 (age=30)
age | userId | name | address | mailAddress
----|-------|-----------|----------|-------------
30 | 2 | Suzuki | Osaka | bbb@co.jp
30 | 4 | Sato | Fukuoka | ddd@co.jp
パーティション3 (age=40)
age | userId | name | address | mailAddress
----|-------|-----------|----------|-------------
40 | 3 | Takahashi | Nagoya | ccc@co.jp
ポイント
以下は GSI 使用時に気を付けておくべきポイントです。
- GSIは物理的に別のストレージ領域に保存される
- 元テーブルとGSIで異なるパーティション構造を持つ
- データは複製される(ストレージコストが増加)
つまり、GSIは「同じデータを異なるキー構造で再配置した別テーブル」のような存在です。これにより、元のテーブル構造に影響を与えることなく、効率的な検索が可能になるんですね。
動作確認
AWSコンソールからGSIを実行してみます。
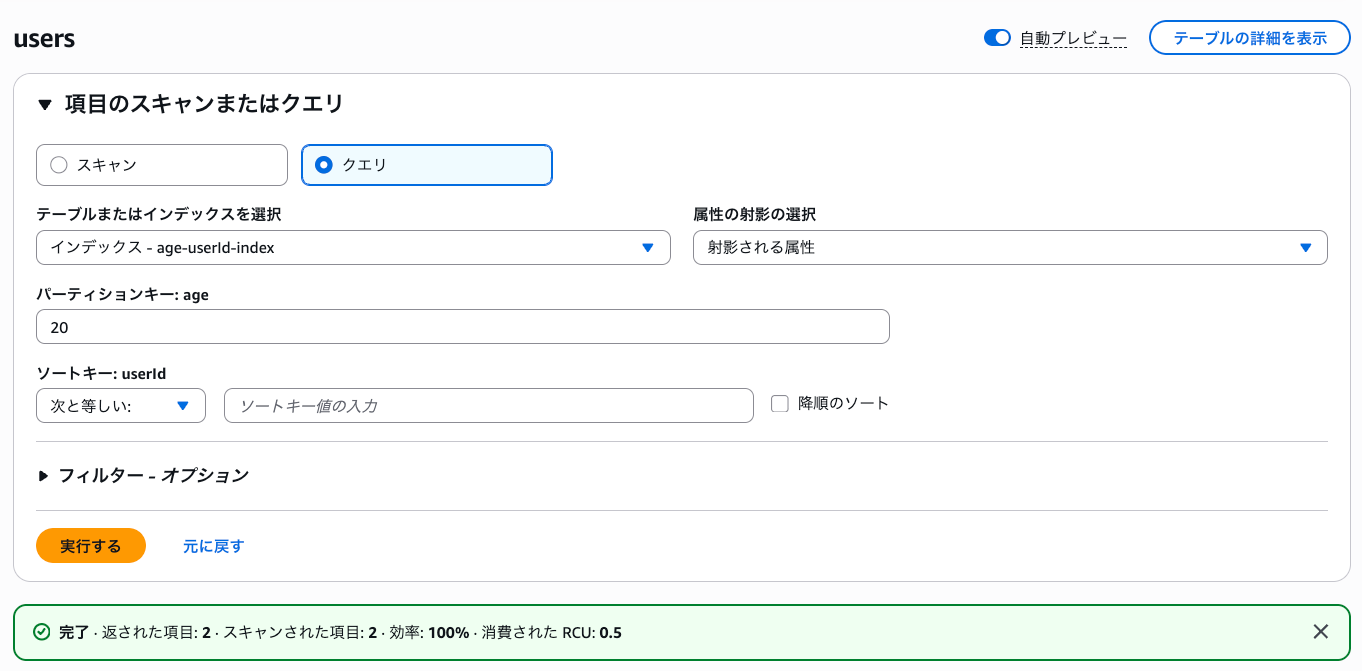
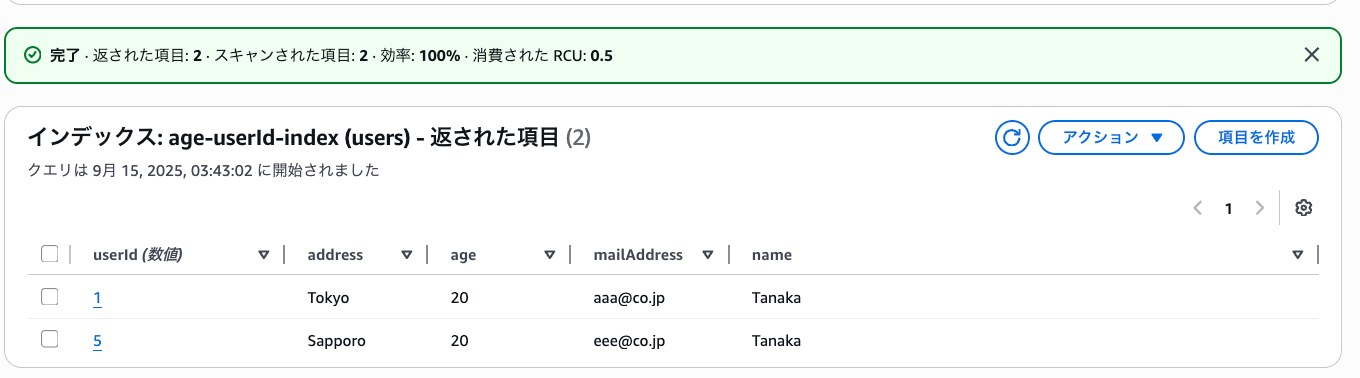
GSI が機能していますね!
おわりに
今回は、DynamoDBのグローバルセカンダリインデックス(GSI)について学習してみました。「GSIを使えばクエリが速くなる」という程度しか理解していなかったですが、GSIが単なる「検索の高速化」ではなく、「データを異なる視点で再構築する仕組み」だということは勉強になりました。DynamoDBは奥が深く、まだまだ学ぶことが多そうです!
以上
参考記事










