Google Cloud Translation API で PowerPoint を丸ごと翻訳してみた
こんにちは、けーまです。
PowerPoint で作った提案資料やスライドを、レイアウトを保ったまま別の言語に翻訳したい場面があります。
図形やフロー図、グラフを使ったプレゼン資料を、見た目を崩さずに英語化したい、といった要件です。
ただ、スライドからテキストだけを抜いて翻訳すると、図形の配置やフロー図が崩れてしまいます。
さらに、製品名やキャラクター名のような独自の固有名詞は、毎回決まった訳に揃えたいことも多いです。
以前、Google Cloud の Cloud Translation API が持つ Document Translation 機能で PDF を翻訳する記事を書きました。
この機能は PDF だけでなく、Word・Excel・PowerPoint にも対応しています。
そこで本記事では、同じ機能を使って PowerPoint(PPTX)をファイルのまま翻訳し、図形やテキストボックス、スピーカーノートがどう扱われるのか、用語集で独自用語を固定できるのかを、実際に動かして確かめました。
本記事は、ドキュメント翻訳を形式別に検証するシリーズの PowerPoint 編です。
仕様や挙動は Google Cloud の公式ドキュメントで確認し、該当箇所を引用しています。
そのうえで、公式の記載どおりになるかを実際に動かして検証しました。
シリーズ記事
| 形式 | 記事 |
|---|---|
| PDF 編 | Cloud Translation API で PDF をレイアウトを保ったまま翻訳する |
| Word 編 | Cloud Translation API で Word をレイアウトを保ったまま翻訳する |
| Excel 編 | Cloud Translation API で Excel をレイアウトを保ったまま翻訳する |
| PowerPoint 編(本記事) | - |
対象読者:PowerPoint 資料の翻訳自動化を検討している方
1. 結論:公式ドキュメントの記載と実証結果
急いで結論だけ知りたい方向けに、PowerPoint(PPTX)の翻訳について、Google Cloud 公式ドキュメントの記載と、実際に翻訳して確認した結果を先にまとめます。
詳しい手順や翻訳前後の画像は §3 以降にあります。
| 観点 | 公式ドキュメントの記載 | 実証結果(本記事で確認) |
|---|---|---|
| タイトル・箇条書き・表・レイアウト | フォーマットとレイアウトを保持して翻訳する | 保持されて翻訳された |
| 図形・テキストボックスの中身 | (Word は「翻訳されない」と明記。PPTX は明記なし) | 翻訳された |
| スピーカーノート | (明記なし) | 翻訳された |
| グラフ・画像 | (明記なし) | グラフ(タイトル・軸・凡例・カテゴリ)も、画像として貼った図も日本語のまま |
| 用語集(独自用語の固定) | 用語集で訳語を固定できる | タイトル・箇条書き・表・図形・テキストボックス・スピーカーノートまで、スライド全体に一貫適用された |
Word・Excel と大きく違うのは、図形・テキストボックスの中身まで翻訳される点です。
加えて、PowerPoint 固有のスピーカーノートも翻訳され、用語集はこれら全体に一貫して適用されました。
急ぎの方は、この表と §4 の画像で概要がつかめます。
シリーズ最終回として、3形式の違いを §8 に表でまとめています。
2. Cloud Translation API のドキュメント翻訳とは
Cloud Translation API の Document Translation は、ファイルをそのまま渡すと書式やレイアウトを保ったまま翻訳して返す機能です。
DOCX や PPTX、XLSX、PDF に対応しています。
機能の概要や認証、用語集の作り方は、前回までの記事で扱いました。
引用元: DevelopersIO: Cloud Translation API で PDF をレイアウトを保ったまま翻訳する
PowerPoint で特に確かめたいのは、図形やテキストボックスの扱いです。
Word・Excel ではテキストボックスや図形の中身は翻訳されませんでしたが、PowerPoint は図形が主要な構成要素になるため、挙動が変わるかどうかを検証します。
3. 検証の準備
3.1 前提環境
前提環境は Word 編・Excel 編と同じです(macOS、Python 3.12 系の venv、google-cloud-translate 3.26.0、課金を有効化した個人プロジェクト)。
API の有効化、ADC 認証、venv へのライブラリ導入の手順も共通です。
3.2 サンプル文書(オリジナルの架空アニメ)
検証用に、架空アニメ「星霊物語 ルミナ・クロニクル」の紹介スライドという体で、PowerPoint を Claude に作ってもらいました。
PDF 編・Word 編・Excel 編と同じ世界観で、固有名詞(造語)も揃えています。
実在の作品・人物・団体とは一切関係のない、完全オリジナルの内容です。
スライドは7枚で構成し、PowerPoint ならではの検証要素を詰め込んでいます。
- タイトル、箇条書き、表
- 角丸図形と矢印で作った「共鳴進化のステップ」のフロー図
- 楕円・六角形・星・吹き出し・矢印・雲など、形のちがう図形に入れた文章
- 世界設定スライドのテキストボックス(メモ)
- Excel から取り込んだ棒グラフ(埋め込みチャート)
- 各スライドのスピーカーノート(発表者用メモ)
今回翻訳した PowerPoint は、全7スライドの構成です。
翻訳前の全スライドを載せておきます。

翻訳前のPowerPoint 1枚目:タイトルとサブタイトル、キービジュアル画像
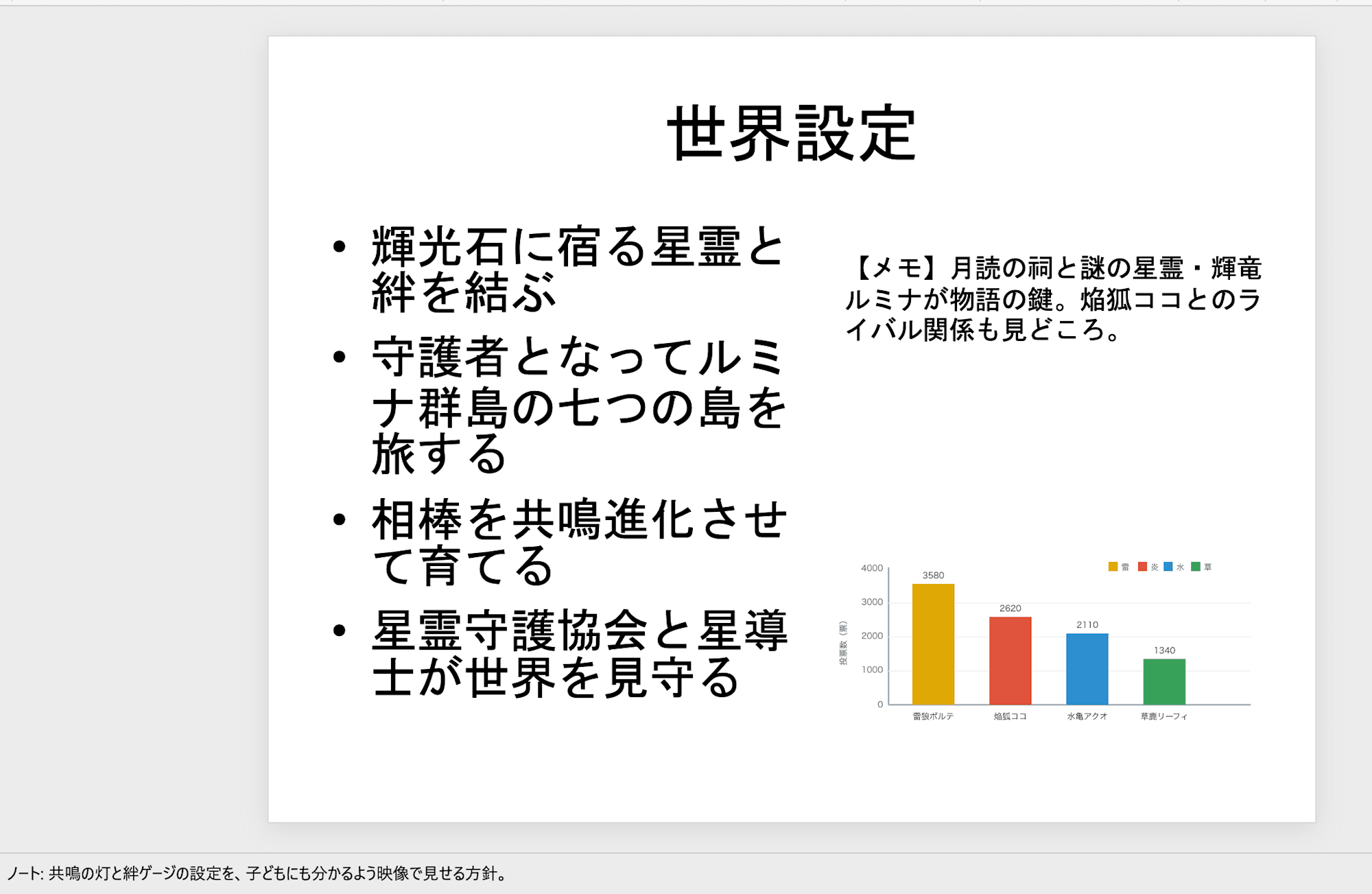
翻訳前のPowerPoint 2枚目:箇条書きの世界設定、テキストボックス(メモ)、グラフ画像
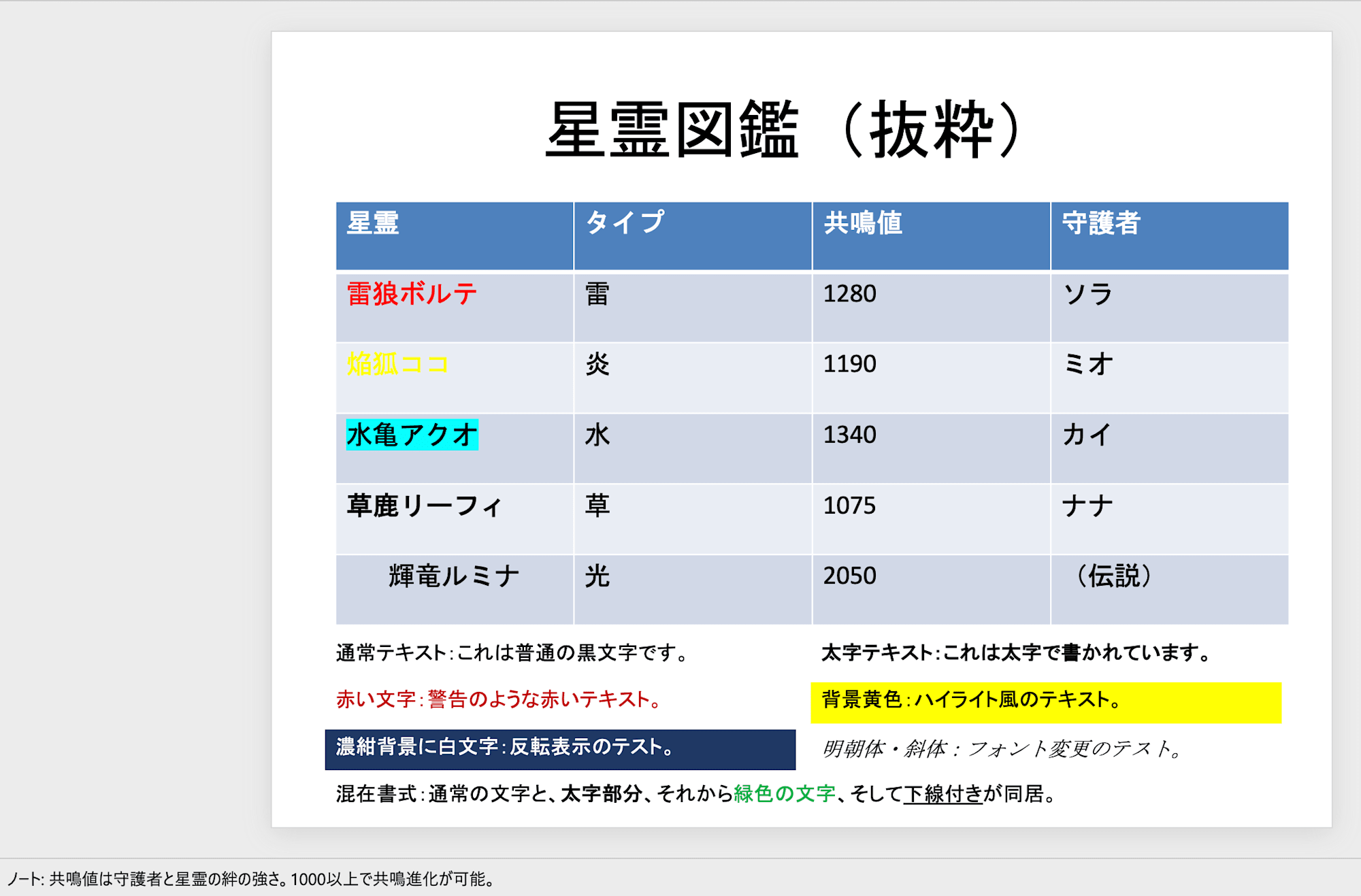
翻訳前のPowerPoint 3枚目:星霊図鑑の表
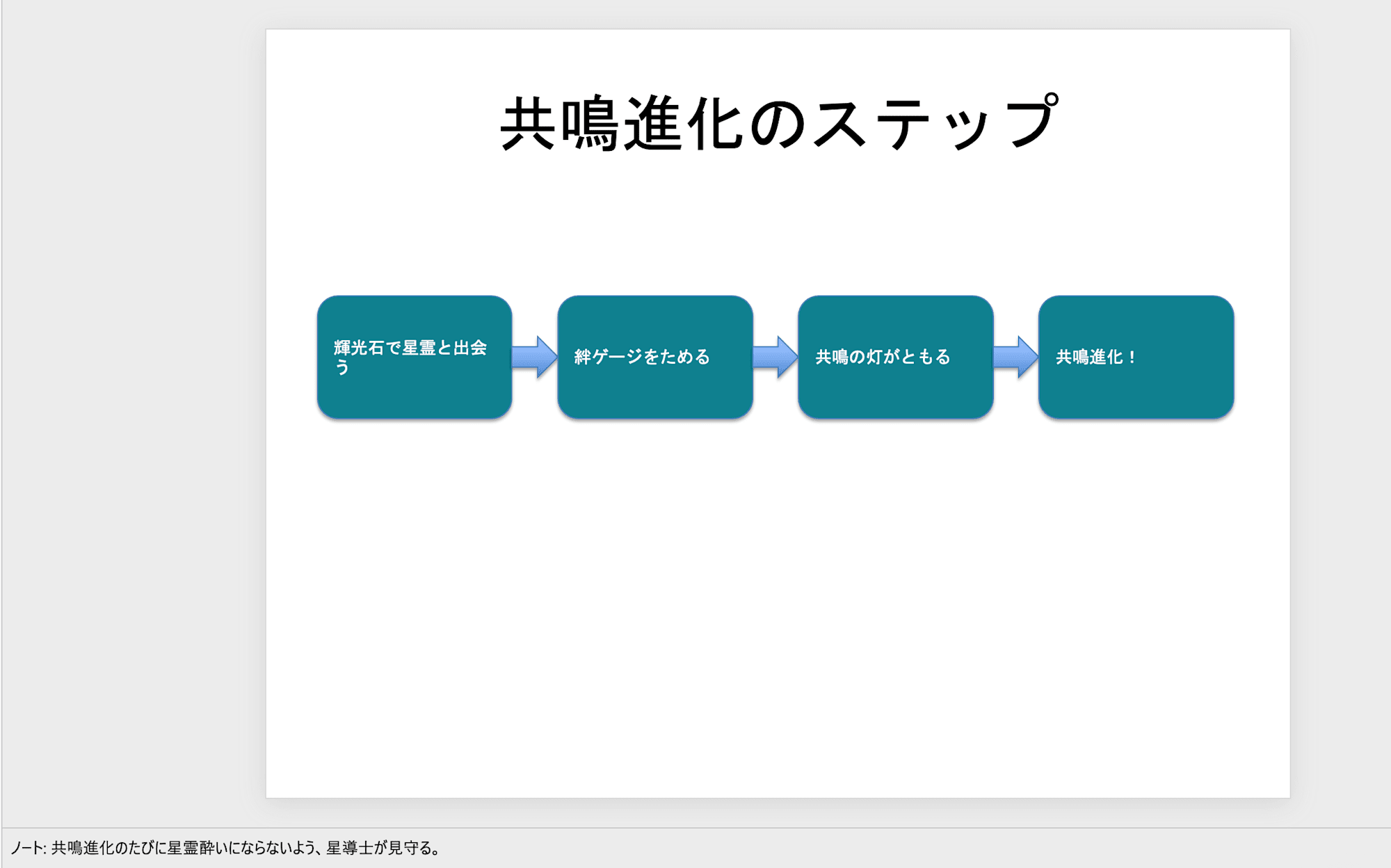
翻訳前のPowerPoint 4枚目:角丸図形と矢印で作った「共鳴進化のステップ」のフロー図
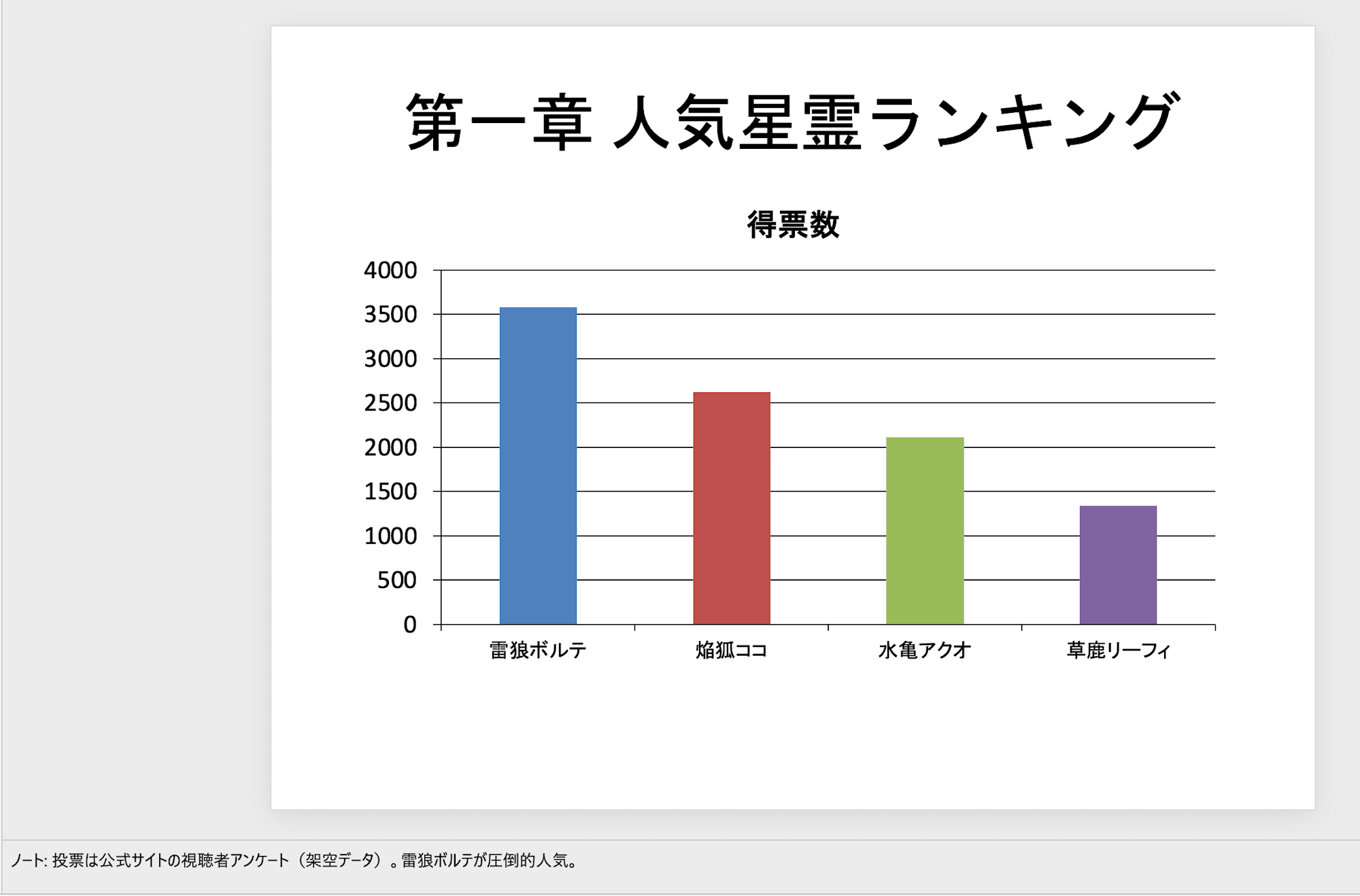
翻訳前のPowerPoint 5枚目:人気ランキングの棒グラフ(埋め込みチャート)
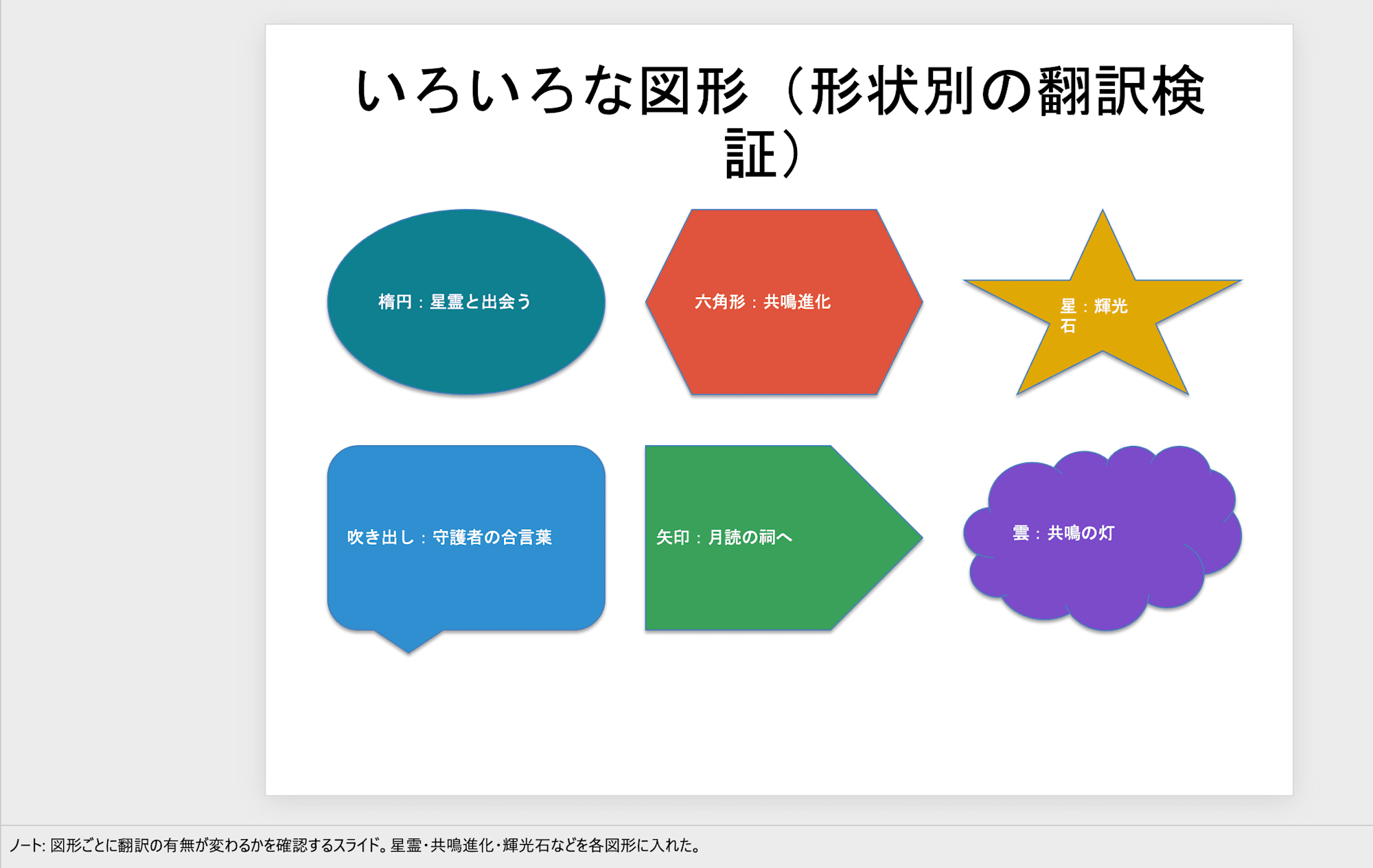
翻訳前のPowerPoint 6枚目:楕円・六角形・星・吹き出し・矢印・雲の図形に入れた文章

翻訳前のPowerPoint 7枚目:まとめのカード(角丸図形)とテキストボックス
4. PowerPoint(PPTX)を翻訳してみる
翻訳に使うスクリプトは、Word 編と同じものです。拡張子から MIME タイプを判定するので、入力を PPTX にするだけで動きます。
記事だけで完結するよう、全文を再掲します。
translate_document_handson.py の全文(クリックすると展開します)
from __future__ import annotations
import argparse
import time
from pathlib import Path
from google.cloud import translate_v3 as translate
# 用語集・カスタムモデルは us-central1 に置く必要がある。
DEFAULT_LOCATION = "us-central1"
# 拡張子 → MIME タイプ(Document Translation 対応形式)
MIME_BY_SUFFIX = {
".pdf": "application/pdf",
".docx": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
".pptx": "application/vnd.openxmlformats-officedocument.presentationml.presentation",
".xlsx": "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
}
def mime_for(path: str) -> str:
"""入力ファイルの拡張子から MIME タイプを返す。未対応拡張子は ValueError。"""
suffix = Path(path).suffix.lower()
if suffix not in MIME_BY_SUFFIX:
raise ValueError(f"未対応の拡張子: {suffix}(対応: {', '.join(MIME_BY_SUFFIX)})")
return MIME_BY_SUFFIX[suffix]
def parse_args() -> argparse.Namespace:
p = argparse.ArgumentParser(description="Cloud Translation API ドキュメント翻訳(同期)")
p.add_argument("--project", required=True, help="GCP プロジェクト ID")
p.add_argument("--input", required=True, help="入力ファイルパス")
p.add_argument("--output", required=True, help="出力ファイルパス(用語集なしの結果)")
p.add_argument("--source", default="ja", help="原文言語コード(既定: ja)")
p.add_argument("--target", default="en", help="訳文言語コード(既定: en)")
p.add_argument("--location", default=DEFAULT_LOCATION, help=f"ロケーション(既定: {DEFAULT_LOCATION})")
p.add_argument("--glossary-id", default=None, help="用語集 ID(指定時は用語集あり/なし両方を出力)")
return p.parse_args()
def build_request(args: argparse.Namespace, content: bytes) -> dict:
"""translate_document のリクエスト辞書を組み立てる。
用語集を指定する場合は原文言語の指定が必須(公式仕様)。
"""
parent = f"projects/{args.project}/locations/{args.location}"
mime_type = mime_for(args.input)
request: dict = {
"parent": parent,
"source_language_code": args.source,
"target_language_code": args.target,
"document_input_config": {"content": content, "mime_type": mime_type},
}
if args.glossary_id:
glossary_path = (
f"projects/{args.project}/locations/{args.location}"
f"/glossaries/{args.glossary_id}"
)
request["glossary_config"] = translate.TranslateTextGlossaryConfig(glossary=glossary_path)
return request
def write_bytes(path: str, data: bytes) -> None:
Path(path).parent.mkdir(parents=True, exist_ok=True)
Path(path).write_bytes(data)
def main() -> None:
args = parse_args()
content = Path(args.input).read_bytes()
print(f"入力: {args.input}({len(content):,} bytes, {args.source}→{args.target})")
client = translate.TranslationServiceClient()
request = build_request(args, content)
started = time.perf_counter()
response = client.translate_document(request=request)
elapsed = time.perf_counter() - started
base = response.document_translation
write_bytes(args.output, base.byte_stream_outputs[0])
print(f"処理時間: {elapsed:.2f} 秒")
print(f"出力(用語集なし): {args.output}({len(base.byte_stream_outputs[0]):,} bytes)")
# 用語集あり: 1回の呼び出しで glossary_document_translation に別出力が返る
if args.glossary_id and response.glossary_document_translation.byte_stream_outputs:
out = Path(args.output)
glossary_out = str(out.with_name(f"{out.stem}_glossary{out.suffix}"))
write_bytes(glossary_out, response.glossary_document_translation.byte_stream_outputs[0])
print(f"出力(用語集あり): {glossary_out}")
if __name__ == "__main__":
main()
まずは用語集なしで翻訳します。
python translate_document_handson.py \
--project <YOUR_PROJECT_ID> \
--input hoshirei_ja.pptx \
--output hoshirei_en.pptx
# 出力例
入力: hoshirei_ja.pptx(146,984 bytes, ja→en)
処理時間: 1.32 秒
出力(用語集なし): hoshirei_en.pptx(138,328 bytes)
翻訳後を確認すると、タイトル・箇条書き・表が英訳され、レイアウトも保たれていました。
まず、全7スライドの翻訳前後を並べます。
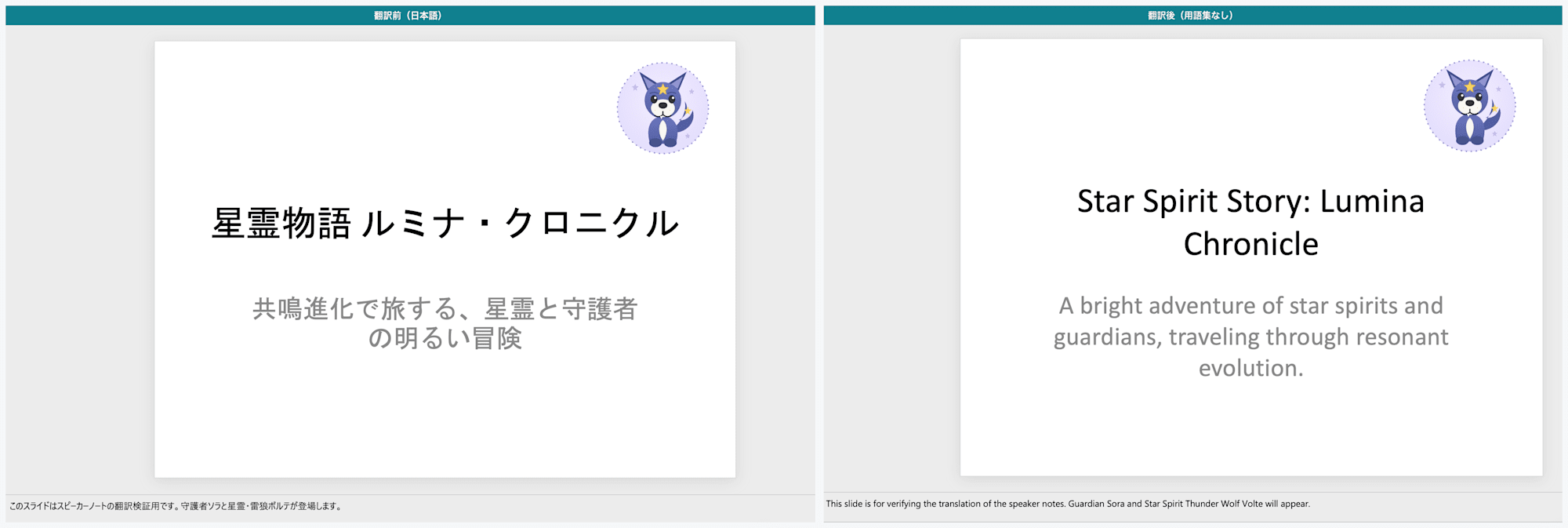
1枚目:左が翻訳前(日本語)、右が翻訳後。タイトルとサブタイトルが英訳される

2枚目:左が翻訳前、右が翻訳後。箇条書きも、右側のテキストボックス(メモ)も翻訳される
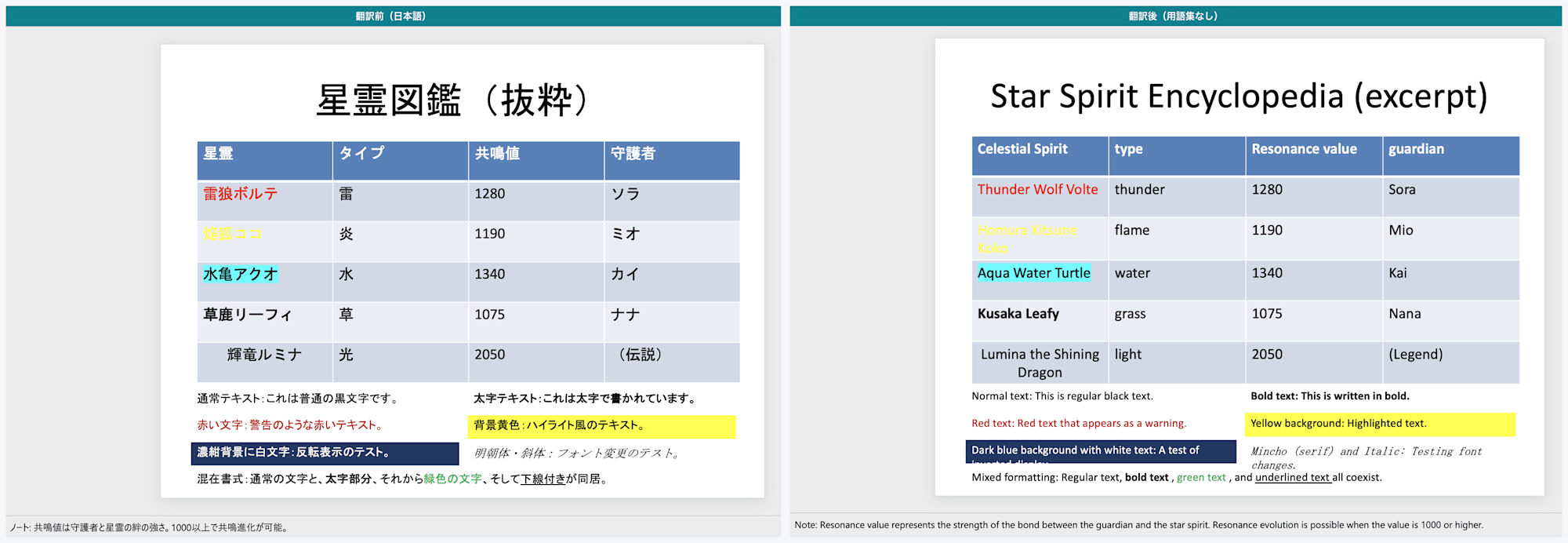
3枚目:左が翻訳前、右が翻訳後。表のデータが英訳される

4枚目:左が翻訳前、右が翻訳後。角丸図形と矢印のフロー図で、図形の中の文章も翻訳される
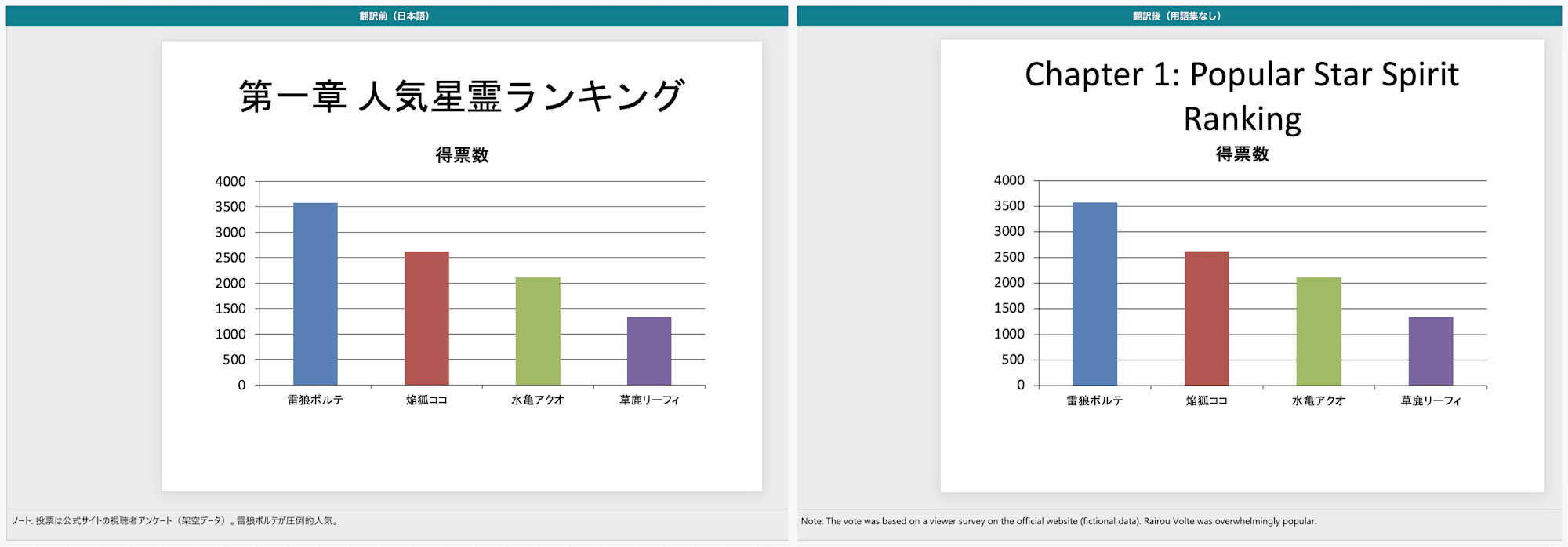
5枚目:左が翻訳前、右が翻訳後。グラフのタイトル・軸・凡例・カテゴリは日本語のまま残る

6枚目:左が翻訳前、右が翻訳後。楕円・六角形・星・吹き出し・矢印・雲、どの形の図形でも中の文章が翻訳される

7枚目:左が翻訳前、右が翻訳後。まとめのカード(角丸図形)の中の文章も翻訳される
ここで Word・Excel と大きく違ったのが、図形とテキストボックスの扱いです。
4.1 図形・テキストボックスの中身も翻訳される
「共鳴進化のステップ」のフロー図(4枚目)は、角丸図形の中の文章まで翻訳されていました。
楕円・六角形・星・吹き出し・矢印・雲など、形のちがう図形に入れた文章(6枚目)も、すべて翻訳されました。
世界設定スライド(2枚目)のテキストボックス(メモ)や、まとめ(7枚目)のカードの中身も翻訳されています。
Word・Excel ではテキストボックスや図形の中身は翻訳されませんでしたが、PowerPoint では図形・テキストボックスの中身が翻訳されました。
同じ Document Translation でも、形式によって図形の扱いが逆になります。
4.2 スピーカーノートも翻訳される
スピーカーノート(発表者用メモ)も確認しました。
全スライドのノートが英訳されていました。
ノートは Word・Excel にはない PowerPoint 固有の要素ですが、本文や図形と同じように翻訳対象になります。
用語集も、ノートを含むスライド全体に一貫して効きます(詳しくは §5.3 で扱います)。
4.3 グラフや画像は翻訳されない
グラフと画像は、Excel と同じく翻訳されませんでした。
人気ランキングスライド(5枚目)の埋め込みグラフは、上の比較画像のとおり、タイトル・軸・凡例・カテゴリがすべて日本語のまま残っています。
また、タイトルスライド(1枚目)のキービジュアルや、世界設定スライド(2枚目)に画像として貼ったグラフのように、画像として配置したものは、中の文字も画像の一部なので翻訳されません。
5. 用語集で独自用語を固定する
固有名詞や独自用語を、決まった訳に固定できるかを確かめます。
用語集を使うには、(1) 原文と訳語の対応を書いた TSV を用意し、(2) それを Cloud Storage に置いて、(3) 用語集リソースを作成します。
5.1 用語集の TSV を用意する
用語集は、原文(日本語)と訳語(英語)をタブ区切りで1行ずつ並べた TSV ファイルとして用意します。
ヘッダー行は不要で、左が原文の造語、右が固定したい訳語です。
今回は、サンプルに散りばめた造語20語を glossary_ja_en.tsv として用意しました。
星霊 Hoshirei
共鳴進化 Reso-Evolution
輝光石 Lumina Shard
雷狼ボルテ Voltefang
焔狐ココ Pyrofox Coco
水亀アクオ Aquortle
草鹿リーフィ Leafawn
輝竜ルミナ Lumidragon
月読の祠 Moonread Shrine
守護者 Warden
星導士 Starwright
星霊守護協会 Hoshirei Warden Guild
共鳴値 Reso-Value
共鳴の灯 Resonance Flame
絆ゲージ Bond Gauge
星霊酔い Hoshirei-sickness
星霊図鑑 Hoshirei Codex
ルミナ群島 Lumina Archipelago
七つの祠 Seven Shrines
共鳴結界 Reso-Barrier
5.2 TSV を Cloud Storage に置いて用語集リソースを作成する
用語集リソースは TSV を直接アップロードするのではなく、いったん Cloud Storage に置き、その GCS の URI を指定して作成します。
バケットは用語集と同じ us-central1 に作っておきます。
# バケットを作成(既にあれば不要)
gcloud storage buckets create gs://<YOUR_BUCKET> \
--project <YOUR_PROJECT_ID> --location us-central1
# TSV をアップロード
gcloud storage cp glossary_ja_en.tsv \
gs://<YOUR_BUCKET>/glossaries/glossary_ja_en.tsv
次に、アップロードした TSV から用語集リソースを作成します。
作成は長時間オペレーション(LRO)なので、クライアントライブラリから実行して完了を待ちます。
次のコードを setup_glossary.py として保存し、venv のまま実行します。
setup_glossary.py の全文(クリックすると展開します)
from google.cloud import translate_v3 as translate
PROJECT_ID = "<YOUR_PROJECT_ID>"
LOCATION = "us-central1" # 用語集は us-central1 のみ
GLOSSARY_ID = "hoshirei-ja-en"
INPUT_URI = "gs://<YOUR_BUCKET>/glossaries/glossary_ja_en.tsv"
client = translate.TranslationServiceClient()
name = client.glossary_path(PROJECT_ID, LOCATION, GLOSSARY_ID)
glossary = translate.Glossary(
name=name,
# 単方向(ja→en)の用語集
language_pair=translate.Glossary.LanguageCodePair(
source_language_code="ja", target_language_code="en"
),
input_config=translate.GlossaryInputConfig(
gcs_source=translate.GcsSource(input_uri=INPUT_URI)
),
)
parent = f"projects/{PROJECT_ID}/locations/{LOCATION}"
operation = client.create_glossary(parent=parent, glossary=glossary)
result = operation.result(180) # 完了を最大180秒待つ
print(f"作成完了: {result.name}(エントリ数: {result.entry_count})")
python setup_glossary.py
# 出力例
作成完了: projects/.../locations/us-central1/glossaries/hoshirei-ja-en(エントリ数: 20)
公式ドキュメントにも、カスタムリソースは us-central1 を使う必要があると明記されています。
Note: All of your resources in a single request to Cloud Translation - Advanced must have the same location. Currently, only global and us-central1 locations are supported. For all custom resources—AutoML models, glossaries, long-running-operations—you must use us-central1.
引用元: 公式ドキュメント: Migrate to Cloud Translation - Advanced (v3) | Google Cloud
5.3 用語集あり/なしを比べる
作成した用語集を指定して翻訳します。
--glossary-id に 5.2 で作成した用語集 ID を渡すと、1回の応答に「用語集なし」と「用語集あり」の両方の結果が返ります。
以降の翻訳結果やスピーカーノートで「星霊 が Hoshirei に、星導士 が Starwright になる」といった固定は、この登録内容に対応しています。
python translate_document_handson.py \
--project <YOUR_PROJECT_ID> \
--input hoshirei_ja.pptx \
--output hoshirei_en.pptx \
--glossary-id <YOUR_GLOSSARY_ID>
まず用語集なしの結果を見ると、固有名詞の訳がバラついていました(Claude調べ)。
原文に16回出てくる 星霊 を、用語集なしの英訳(スピーカーノートを含む)で数えると、主な訳語の内訳は次のとおりでした。
星霊 の訳(用語集なし) |
出現回数 |
|---|---|
| Star Spirit | 6 |
| Star Spirits | 4 |
| star spirit | 2 |
| Celestial Spirit | 2 |
| star spirits | 1 |
| その他の表記 | 数件 |
同じ単語が、大文字小文字や単複も含めて何通りにも分かれています。
用語集ありに切り替えると、これがきれいに統一されました。
訳が実際に変わったのは、タイトルスライドです。
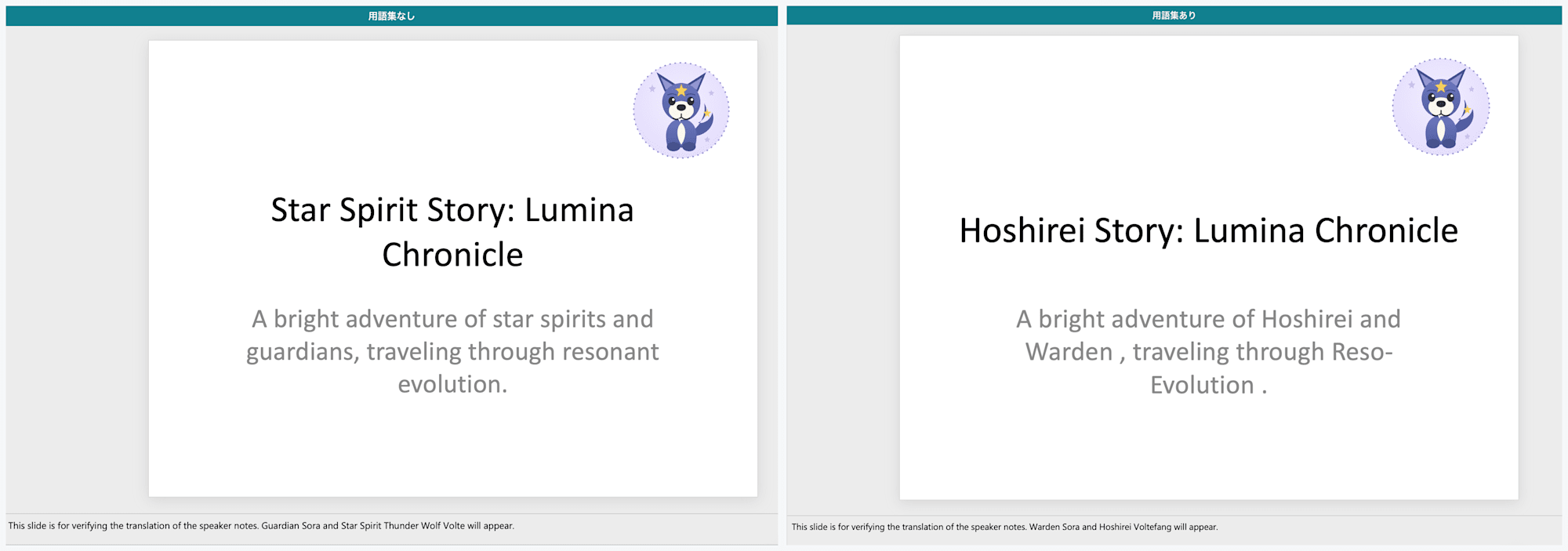
左が用語集なし(タイトルが「Star Spirit Story」)、右が用語集あり(「Hoshirei Story」に固定され 星霊 が Hoshirei に統一される)
用語集ありでは、星霊 は Hoshirei、守護者 は Warden、共鳴進化 は Reso-Evolution、輝光石 は Lumina Shard と、登録したとおりの訳に固定されました。
用語集は、タイトルや箇条書き、表、図形やテキストボックスの中身、さらにスピーカーノートまで、スライド全体に一貫して適用されました。
たとえばスピーカーノート内の 星導士 は、用語集なしでは Star Guide と字義訳されますが、用語集ありでは Starwright に固定されました。
用語集ありの出力を全文で調べたところ、PowerPoint では登録した造語がすべて固定訳に揃っていました(Claude調べ)。
Word 編では 星霊 が1か所だけ取りこぼされましたが、今回の PowerPoint のサンプルでは字義訳の残りは見つかりませんでした。
ただし、取りこぼしは前後の文脈によってまれに起こるため、用語集ありでも完全に100%とは限らない点には注意が必要です。
6. 料金と処理時間
ドキュメント翻訳の料金は、使う翻訳モデルによって単価が変わります。
標準の NMT モデルの場合、ドキュメント翻訳はページ単位で、PowerPoint ではスライドがページにあたります。
| 項目 | 単価 |
|---|---|
| NMT ドキュメント翻訳 | 0.08 ドル / ページ |
引用元: 料金ページ: Pricing | Google Cloud
今回のサンプル(7スライド)は、用語集あり/なしを合わせても 1 ドルに満たない規模でした。
処理時間は実測で約 1〜2 秒でした。
7. 帰属表示(Machine Translated by Google)について
PDF 編では、翻訳後の PDF の左上に「Machine Translated by Google」という帰属表示が入りました。
今回の PowerPoint(PPTX)では、同じく帰属表示を指定していないにもかかわらず、翻訳後のファイルにこの表示は見当たりませんでした(Word・Excel でも同様です)。
PDF と Office で同じ条件なのに表示の有無が違ったので、仕様を確認しました。
帰属表示の文言は、API のリクエストで customizedAttribution として指定でき、指定しない場合のデフォルトが「Machine Translated by Google」です。
このフィールドは PDF 専用ではなく、translateDocument(ドキュメント翻訳)全体に共通のものです。
customizedAttribution
stringOptional. This flag is to support user customized attribution. If not provided, the default is Machine Translated by Google. Customized attribution should follow rules in https://cloud.google.com/translate/attribution#attribution_and_logos
引用元: API リファレンス: Method: projects.locations.translateDocument | Google Cloud
ここで注意したいのは、customizedAttribution が説明しているのは「帰属表示の文言」だけで、その文言がどの形式の出力に、どう反映されるか(ファイルに焼き込まれるか)は公式ドキュメントに明記が見当たらなかった点です。
形式ごとに帰属表示の有無が変わる理由は、公式には確認できませんでした。
実際に動かした範囲では、帰属表示は PDF(PDF 編ではネイティブ PDF で確認)の出力に焼き込まれ、Office 形式(DOCX/XLSX/PPTX)の出力には入りませんでした。
PDF はレイアウトを保つために訳文をページ上に重ねて再構成する形式で、編集可能な Office 形式とは出力の作られ方が違うため、と推測されますが、公式の記載で裏づけられたものではありません。
もう1点、別の軸として押さえておきたいのが、ブランドガイドライン上の明示義務です。
これは「出力ファイルに焼き込まれるか」とは別で、翻訳結果を利用者に見せるときは、形式にかかわらず機械翻訳であることを明示するよう求めています。
Whenever you display translation results from Google Translate directly to users, you must make it clear to users that they are viewing automatic translations from Google Translate using the appropriate text or brand elements.
引用元: ブランドガイドライン: Attribution requirements | Google Cloud
つまり、Office 形式の出力に帰属表示が焼き込まれないこと自体は問題ありませんが、翻訳結果を公開・配布する場面では、形式にかかわらず機械翻訳であることを明示する責任が利用者側にあります。
8. まとめ(シリーズ全体の比較)
PowerPoint(PPTX)は、タイトル・箇条書き・表に加えて、図形やテキストボックスの中身、スピーカーノートまで翻訳され、用語集も全体に適用されました。
翻訳されないのはグラフ(埋め込みチャート)と、画像として貼った図でした。
本シリーズで Word・Excel・PowerPoint の3形式を翻訳して分かった違いを、表にまとめます。
| 要素 | Word(DOCX) | Excel(XLSX) | PowerPoint(PPTX) |
|---|---|---|---|
| 本文・表・データ | 翻訳 | 翻訳 | 翻訳 |
| テキストボックス・図形の中身 | 翻訳されない | 翻訳されない | 翻訳される |
| グラフ(タイトル・軸・凡例) | - | 翻訳されない | 翻訳されない |
| 数式 | - | 保持・再計算(数式内の文字列は非翻訳) | - |
| スピーカーノート | - | - | 翻訳される |
| 用語集 | 一貫適用 | 一貫適用 | 一貫適用 |
いちばんの違いは、テキストボックス・図形の中身の扱いです。
Word・Excel では翻訳されず日本語のまま残るのに対し、PowerPoint では翻訳されます。
資料の作り方によって、翻訳前に文章をどこに置くかの判断が変わります。
- Word・Excel:翻訳したい文章は、テキストボックスではなく本文や表のセルに置く
- PowerPoint:図形やテキストボックスに置いても翻訳される。翻訳されないのはグラフと、画像として貼った図
グラフは全形式で翻訳されない点も共通でした。
グラフのタイトルや凡例を翻訳したい場合は、画像化する前にテキストとして別途用意するなどの手当てが必要です。
本シリーズを通して、PDF・Word・Excel・PowerPoint のいずれもレイアウトを保って翻訳でき、用語集で独自用語をほぼ固定できることが確認できました。
扱う資料の形式と、図形・グラフの使い方を踏まえて、翻訳の前後で手当てが必要な箇所を見極めるのがよさそうです。
本シリーズが、Office 文書の翻訳自動化を考えている方の参考になればうれしいです。






