
AWS Glue データカタログの Apache Iceberg テーブルのストレージ最適化を試す!
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。AWS Glue データカタログは、Apache Iceberg テーブルのストレージ最適化をサポートするようになりました。ストレージ最適化とは何か、実際に動作を確認します。
Apache Iceberg テーブルのストレージ最適化とは
Apache Iceberg テーブルのストレージ最適化とは、AWS Glue データカタログが提供するストレージ最適化と自動圧縮の機能です。メタデータのオーバーヘッドを削減し、ストレージコストを抑え、クエリパフォーマンスを向上させることができます。
Apache Iceberg テーブルに書き込むたびに、テーブルの新しいスナップショット、つまりバージョンが作成されます。さらに、Iceberg テーブルへの書き込み中に障害が発生すると、スナップショットで参照されない「孤立ファイル」と呼ばれるデータファイルが作成され、ストレージコストがさらに増加します。
Iceberg テーブルのストレージ最適化を試す!
検証用テーブルの作成
以下のようなAmazon Athena のクエリエディタからテーブルを作成します。
-- DROP TABLE sampledb.weather;
CREATE TABLE sampledb.weather (
device_name string,
device_ts string,
temperature int,
humidity int)
LOCATION 's3://cm-weather-tmp/weather'
TBLPROPERTIES (
'table_type'='iceberg',
'vacuum_max_snapshot_age_seconds' = '60'
);
初期状態のS3上のテーブルのデータは、メタデータ(.metadata.json)のみ存在します。
$ aws s3 ls s3://cm-weather-tmp/weather/ --recursive
2024-10-05 13:01:09 1342 weather/metadata/00000-48e4ce9d-498b-4422-9ab2-2dca4fcb75fe.metadata.json
検証用データ作成
100回INSERTのクエリを実行して、S3上のテーブルのデータ作成します。100回クエリ実行することで大量の小さなファイルが作成されます。
#!/bin/bash
# Athenaデータベース名
DATABASE="sampledb"
# 結果を保存するS3バケット
S3_OUTPUT="s3://aws-athena-query-results-ap-northeast-1-312475502108/athena-results-awscli/"
# クエリを1000回実行
for i in {1..10}
do
echo "Executing query $i"
device_name='weather'
device_ts=$(date '+%Y-%m-%d %H:%M:%S')
temperature=$(( (RANDOM % 99) + 1 ))
humidity=$(( (RANDOM % 99) + 1 ))
# クエリ文字列
QUERY="INSERT INTO weather (device_name, device_ts, temperature, humidity) VALUES('$device_name', '$device_ts', $temperature, $humidity);"
# Athenaクエリの実行
aws athena start-query-execution \
--query-string "$QUERY" \
--query-execution-context Database=$DATABASE \
--result-configuration OutputLocation=$S3_OUTPUT
# クエリ間に少し待機時間を入れる
sleep 0.1
done
echo "All queries submitted"
実際に実行するとこんな感じです。
$ ./insert.sh
Executing query 1
{
"QueryExecutionId": "fe853cf4-98f6-4f56-938d-df5289528e56"
}
Executing query 2
{
"QueryExecutionId": "8bbf2928-2dba-4d6c-ad90-ec72a556d596"
}
:
(中略)
:
Executing query 100
{
"QueryExecutionId": "5d3e1d89-9752-46f0-98eb-bc3c93a11150"
}
All queries submitted
データ追加後は、大量のファイルが生成されています。1つから453つの大量のファイルが追加されました。
$ aws s3 ls s3://cm-weather-tmp/weather/ --recursive
2024-10-05 13:02:22 735 weather/data/-0B0dQ/20241005_130220_00011_48ney-ca28ca81-d26d-4940-835d-3ada589d47db.parquet
2024-10-05 13:02:32 735 weather/data/-7MHgg/20241005_130230_00052_ia7hf-70833eca-4983-4cca-8e37-3b2b30d818c8.parquet
:
(中略)
:
2024-10-05 13:02:27 735 weather/data/zr0Eqw/20241005_130225_00009_5a9a2-8921fc3b-65a9-4f4f-9c25-8a949c6bf332.parquet
2024-10-05 13:01:09 1342 weather/metadata/00000-48e4ce9d-498b-4422-9ab2-2dca4fcb75fe.metadata.json
2024-10-05 13:02:14 2401 weather/metadata/00001-132c2a79-4a9b-4e5d-9697-b760c679362c.metadata.json
:
(中略)
:
2024-10-05 13:04:54 102118 weather/metadata/00100-d3fb3ffd-8085-4a6c-84a3-1c6ebb22f642.metadata.json
2024-10-05 13:02:38 6845 weather/metadata/01e6e8bf-dd25-49e3-b763-8fa63a805d0b-m0.avro
2024-10-05 13:03:54 6843 weather/metadata/033d9b9f-035f-424e-8a8e-f992e5dca823-m0.avro
:
(中略)
:
2024-10-05 13:04:41 6845 weather/metadata/fd275200-d981-45e2-8d32-6bdad560f753-m0.avro
2024-10-05 13:02:35 4823 weather/metadata/snap-1173644289484205432-1-12259440-3d9c-435e-9fc5-101eaa7fdfc0.avro
2024-10-05 13:04:19 7570 weather/metadata/snap-131236155111975177-1-4a8c5f8a-5d68-4d3a-9e5a-b725628d477d.avro
:
(中略)
:
2024-10-05 13:02:45 5104 weather/metadata/snap-9120035621509221568-1-7acc4ce4-7f26-455d-a6c8-b4868c0a55cd.avro
ストレージ最適化の実行
マネジメントコンソールの Glue の Data Catalog から Tables を選択します。ストレージ最適化したいテーブルを表示します。
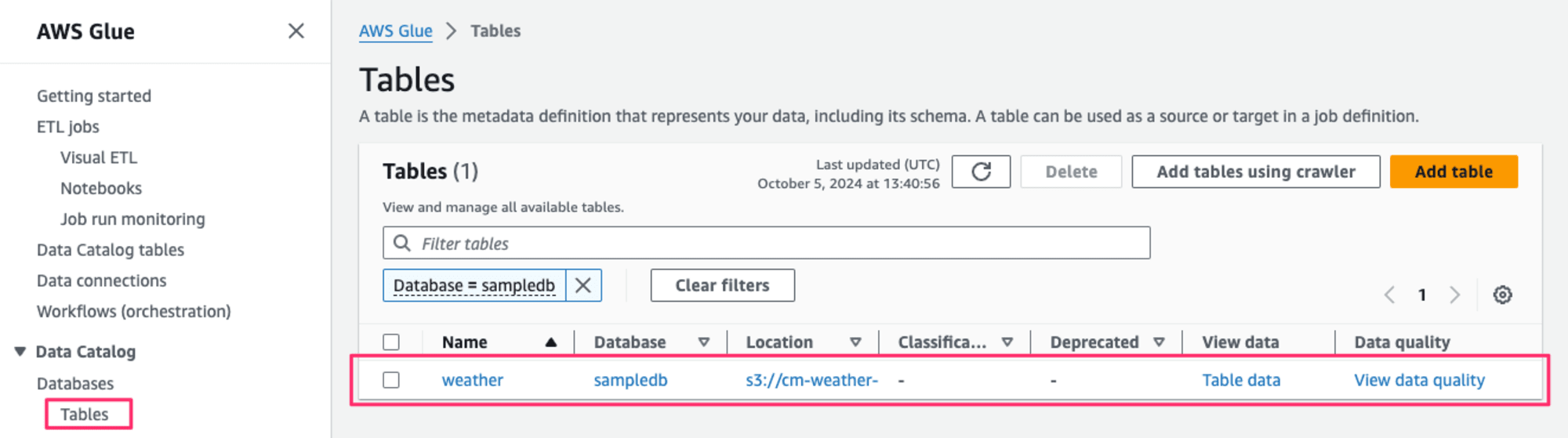
今回追加された機能は、赤枠の Snapshot retention historyとOrphan file deletion history です。[Enable snapshot retention]ボタンを押します。
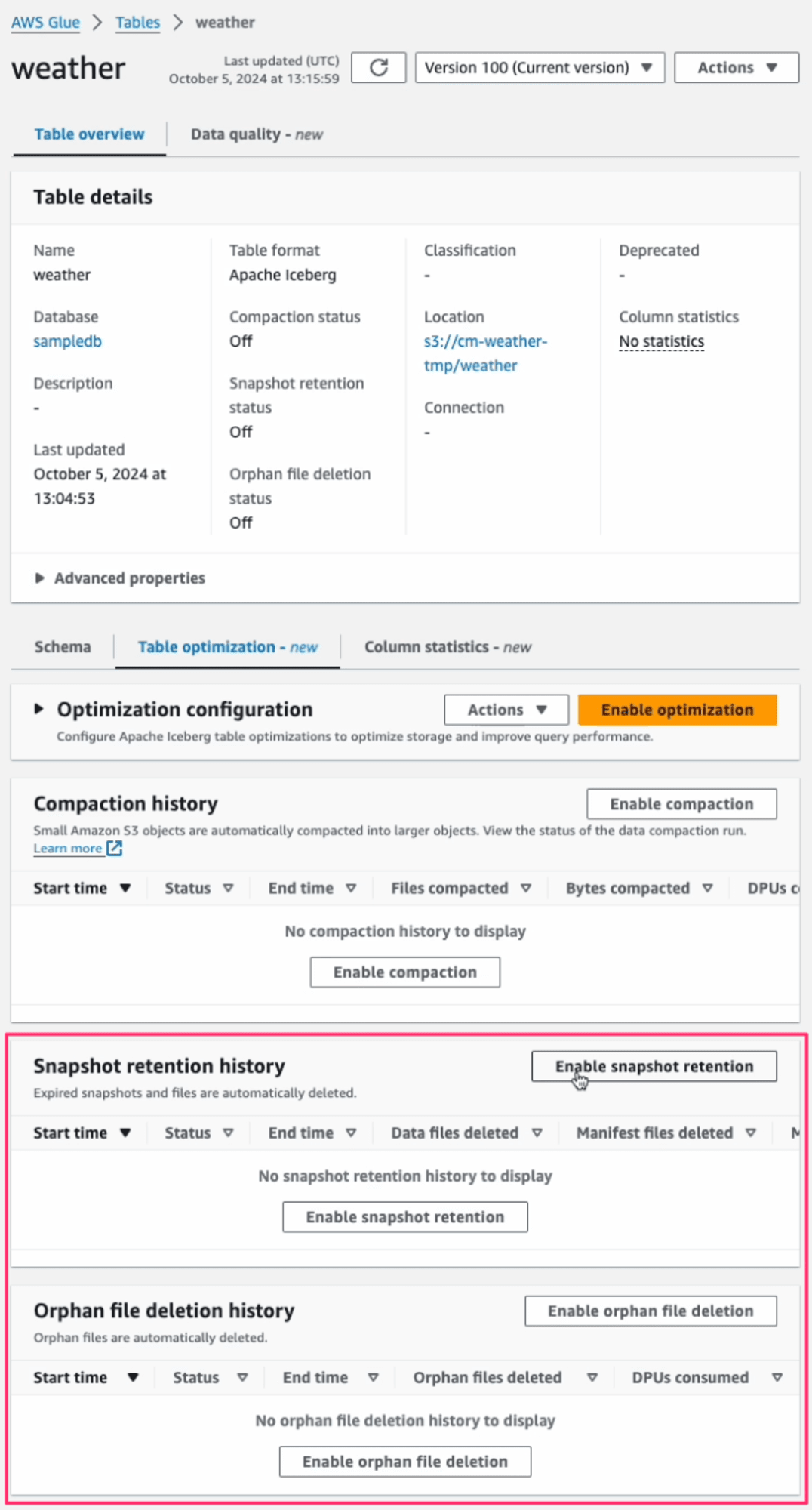
Enable optimization にて、実際のストレージ最適化の設定をします。今回は、新機能である赤枠の Snapshot retentionとOrphan file deletion にチェックを入れます。
Optimization configuration は、デフォルトでは閉じて表示されませんが、具体的にどのような設定で動作するのかを確認するため表示しました。
[Enable Optimization]ボタンを押すと開始します。
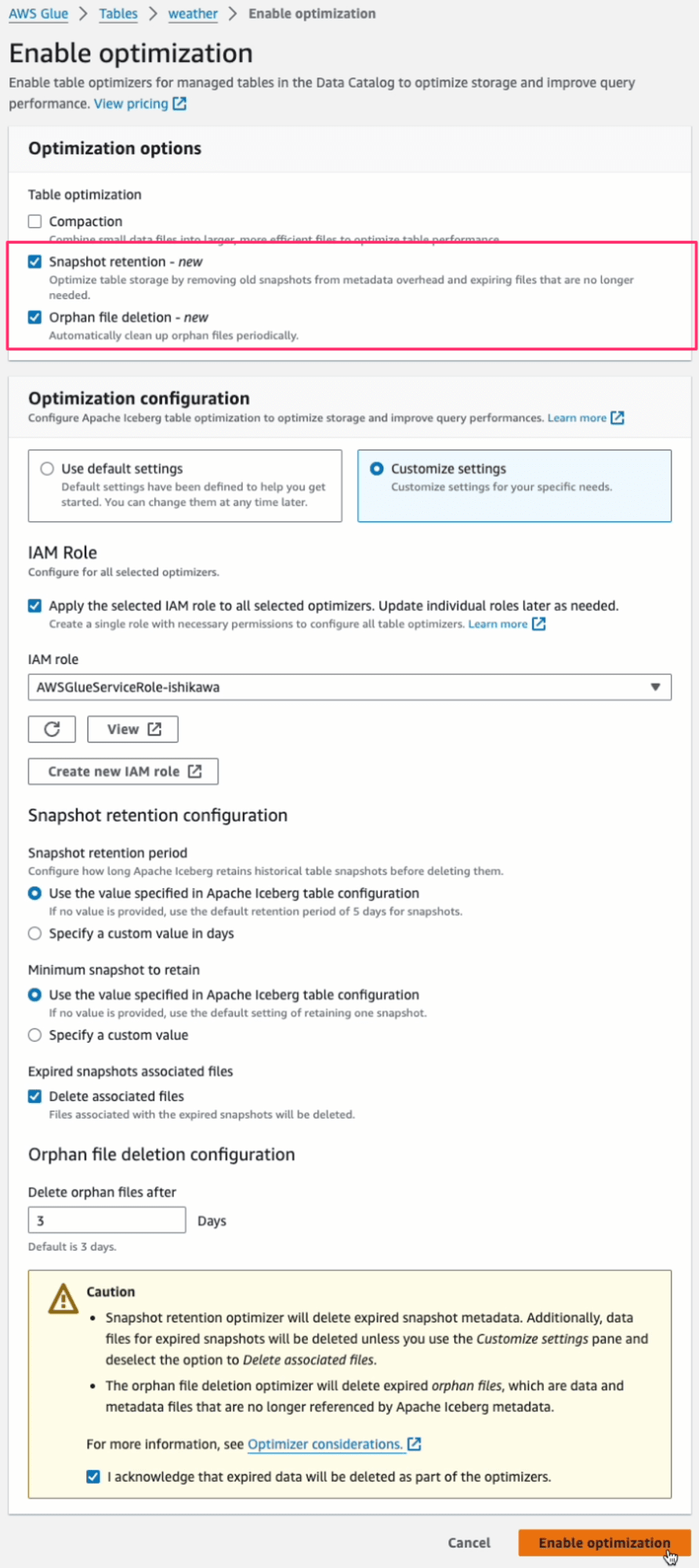
ストレージ最適化の実行が終わると、Snapshot retention history と Orphan file deletion history が更新されます。
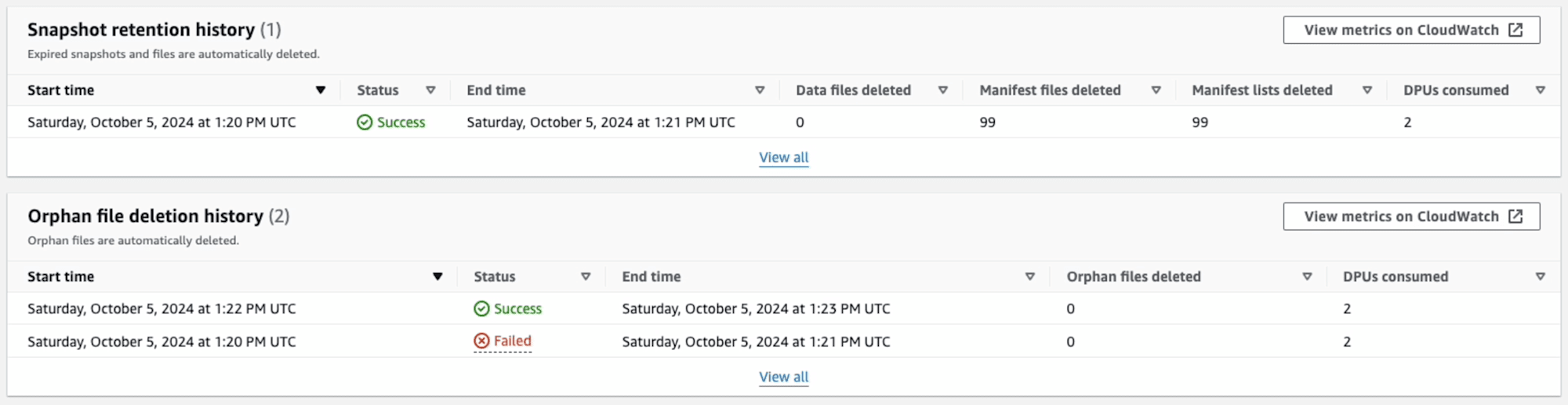
Snapshot retention が実行された結果
99のマニフェストファイルが削除された(Manifest files deleted)ことが確認できます。
Orphan file deletion が実行された結果
Orphan file deletion が実行されましたが、対象ファイルが存在しなかったため削除されていません。ちょっと気になったのが、1回目の実行が失敗(Failed)になっている点です。しかし、自動的にリトライされて最終的には成功(Success)しました。
なお、Orphan fileとは、Iceberg テーブルへの書き込み中に障害が発生すると、スナップショットで参照されない「孤立ファイル」と呼ばれるデータファイルのことです。
最後に
今回の検証では、対象ファイルが存在しなかったため、Orphan file deletion(孤立ファイル削除)は実行されませんでした。この機能が実際に作動する状況としては、主に二つのケースが考えられます。一つは、Icebergテーブルへの書き込み中に障害が発生した場合です。もう一つは、Amazon AthenaでVACUUMを実行する際に、100パーティションを超えたために処理が中断された場合です。これらの状況下で「孤立ファイル」と呼ばれるデータファイルが生成される可能性があります。したがって、Orphan file deletionは、データ管理の観点から非常に有用な機能だといえます。
今回のアップデートで、Table Optimization に機能が追加されました。これにより、Apache Iceberg テーブルに対するメンテナンスは、Athena のような100パーティションの制限なく、Glue データカタログでストレージの最適化ができるようになりました。この新機能は、Iceberg テーブルの本格運用を後押しする心強い機能といえます。











